基于注意力機制的深度學習推薦研究進展*
2021-03-01 03:33:44陳海涵吳國棟李景霞王靜雅
計算機工程與科學 2021年2期
陳海涵,吳國棟,李景霞,王靜雅,陶 鴻
(安徽農業大學信息與計算機學院,安徽 合肥 230036)
1 引言
當前,深度學習在計算機視覺、自然語言處理和語音識別等領域得到了廣泛的應用,許多學者也將其用于推薦系統研究。針對傳統協同過濾算法中存在的數據稀疏性和冷啟動問題,深度學習具有良好的對數據集本質特征進行學習的能力,一定程度上克服了推薦過程中的數據稀疏問題。但是,深度學習具有黑盒特性,很難對推薦系統的最終決策做出解釋,而沒有解釋性的推薦是缺乏說服力的,會對提升用戶的信任度帶來負面影響。因此,如何在提高推薦性能的前提下,提升深度學習推薦系統的可解釋性和透明度受到了工業界與學術界的廣泛關注。
注意力機制通過對關注事物的不同部分賦予不同的權重,從而降低其它無關部分的作用。從注意力機制可解釋性的角度看,它允許直接檢查深度學習體系的內部工作,通過可視化輸入與對應輸出的注意權重,達到增強深度模型可解釋性的效果[1]。在推薦算法中融入注意力機制,對每個潛在因素或特征的重要性進行區分,在提升推薦性能的同時,也提高了推薦系統內部的可解釋性。本文主要分析了基于注意力機制的深度神經網絡DNN(Deep Neural Network)、卷積神經網絡CNN(Convolutional Neural Network)、循環神經網絡RNN(Recurrent Neural Network)和圖神經網絡GNN(Graph Neural Network)等幾種深度學習推薦的研究進展,指出了各自的優點與不足,并指出了相關研究難點與未來主要研究方向。
2 注意力機制及其分類
注意力機制是一種模擬人腦注意力的模型,最初由Treisman等人[2]提出,其本質是利用注意力的概率分布,捕捉某個關鍵輸入對輸出的影響[3]。以Bahdanau等人[4]提出的注意力機制模型為例,求解注意力的計算過程可以抽象為3個階段,如圖1所示。
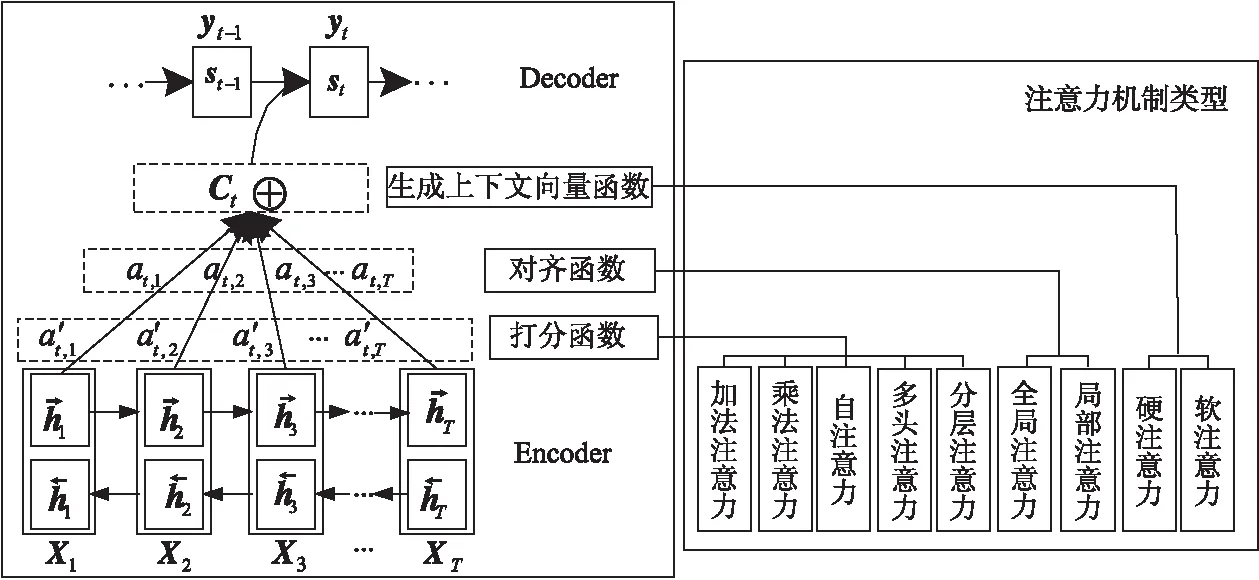
Figure 1 Structure and classification of attention mechanisms
圖1中,注意力機制的3個階段包括:計算打分函數階段,主要根據解碼器(Decoder)端和編碼器(Encoder)端隱狀態進行相似度計算;計算對齊函數階段,主要通過歸一化處理,將輸出的相關性值進行數值轉換;計算生成上下文向量函數階段,主要對輸入序列進行加權求和。
按照注意力機制在圖1中3個階段的不同變換,得到注意力機制的不同類型。根據不同的打分函數,將注意力機制分為加法注意力、乘法注意力、自注意力[5]、多頭注意力[6]和分層注意力[7];根據不同的對齊函數,注意力機制可分為全局注意力和局部注意力[8];根據不同的生成上下文向量函數,得到硬注意力與軟注意力[9]。
其中,圖1的核心步驟是注意力分數a′t,j的計算,XT是輸入序列,hj是Encoder端第j個詞的隱向量,st-1是Decoder端在t-1時刻的隱狀態,yt-1表示t-1時刻的目標詞,Ct表示上下文向量。
3 基于注意力機制的深度學習推薦相關研究
將注意力機制融入深度學習推薦過程中,主要思路是先利用各類深度學習模型學習用戶或項目的隱特征,結合注意力機制學習隱特征的權重;其次構建優化函數對參數進行訓練,得到用戶和項目隱向量;最后利用隱向量信息得到項目排序結果,對用戶進行推薦。對于不同的深度學習模型,本文將基于注意力機制的深度學習推薦研究主要分為4類,如表1所示。
3.1 基于注意力機制的DNN推薦方法
DNN即深度神經網絡,由多層感知機MLP(Multi-Layer Perceptron)發展而來,但DNN比MLP的激活函數種類更多,層數更深,其網絡層數可以達到一百多層乃至更高,一定程度上改善了MLP優化函數的梯度消失和局部最優解問題。
針對當前的音樂推薦系統只能從不同歌曲中學習到相同的上下文權重問題,張全貴等人[10]利用注意力機制給每個用戶的歷史交互歌曲動態分配不同的注意力權重,得到更符合用戶偏好的推薦結果,增加了對用戶偏好分析的可解釋性。沈冬東等人[11]加入平滑系數減輕對長歷史活動用戶的懲罰,并通過多層感知機參數化注意力函數改進注意力網絡,解決了傳統ItemCF(Item Collaboration Filter)算法難以充分挖掘數據間隱含信息的問題。針對傳統推薦算法未充分提取用戶行為中的隱式反饋特征問題,郭旭等人[12]利用自注意力機制生成用戶短期動態項目的向量化表示,提高了推薦質量,但該方法對用戶的向量化表示比較粗糙,未考慮融入用戶的畫像屬性。

Table 1 Research on deep learning recommendation based on attention mechanism
文獻[13]為了解決基于矩陣分解的協同過濾算法不能獲取用戶歷史交互中復雜的非線性特征問題,構建了DeepCF-A(Deep Collaborative Filtering model based on Attention)模型,提取線性與非線性特征。DeepCF-A模型如圖2所示。具體步驟主要有:
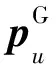
(1)
(2)非線性特征提取。在MLP中融入注意力機制得到用戶和項目間歷史交互數據的非線性特征φMLP-A,如式(2)所示:
(2)
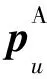
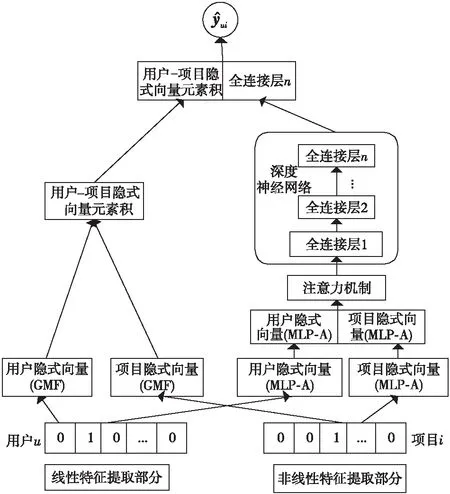
Figure 2 DeepCF-A recommendation model
(3)注意力機制層。在非線性特征提取部分,將嵌入層的m維特征向量Xm送入Softmax函數,得到每個維度特征的關注度Am,如式(3)所示;再將Am與相應維度的特征向量對應相乘,得到更新權重的特征向量Aout,如式(4)所示:
Am=Softmax(Xm)
(3)
Aout=Am⊙Xm
(4)
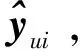
(5)
該模型提升了協同過濾方法處理隱式反饋數據的效果,適用于解決推薦系統中數據量龐大、難以捕捉深層非線性關系的推薦問題。但是,在深度神經網絡中,高效地捕捉用戶和項目隱向量間的交互信息,是以不斷提升網絡層數為代價的,深度神經網絡層數的增加會導致新的參數數量膨脹問題[14]。此外,DNN無法對時間序列上的變化進行建模,不能反映用戶興趣的動態變化,而樣本出現的時間順序對推薦任務又有著非常重要的意義。
3.2 基于注意力機制的CNN推薦方法
CNN即卷積神經網絡,具有限制參數個數和挖掘模型局部結構的特點。為了解決DNN訓練數據時帶來的參數數量膨脹問題,有學者將注意力機制和CNN結合用在推薦系統研究中。

Figure 3 ACoNN recommendation model
針對微博的話題標簽推薦任務,經常需要大量人工進行分類這一問題,Gong等人[15]提出了一種基于注意力機制的CNN微博標簽推薦模型。該模型使用全局和局部注意力2個通道,有效提高了推薦性能;但推薦數據僅使用了微博文本標簽,未考慮使用圖像等其它形式數據提取微博特征。針對這一問題,Zhang等人[16]加入協同注意力機制對標簽與圖像、文本中的局部關聯性進行建模,相較于僅使用文本信息的模型,推薦效果更好。不足之處是作者僅驗證了1層和2層的協同注意力機制對推薦結果的影響,沒有在層數上做更多的嘗試。針對在線新聞網站中,平臺編輯手動挑選推薦候選文章的耗時問題,Wang等人[17]構建了一種動態注意力深度模型DADM(Dynamic Attention Deep Model),DADM將專業與時間2個潛在因素加入注意力機制,自適應地為編輯分配偏好權重,使模型在處理動態數據和編輯行為方面擁有很小的方差。但是,文章中的文字和圖像對編輯選擇行為的影響應該是不同的,此模型未加以區分。
針對傳統推薦算法對評論文本信息提取能力有限的問題,文獻[18]提出了一種融合注意力機制對評論文本深度建模的推薦模型ACoNN(deep Cooperative Neural Networks based on Attention),通過注意力機制設計一層權值更新層對文本矩陣進行重新賦權,再使用一組并行的CNN,充分挖掘用戶和項目的隱含特征。推薦流程如圖3所示。
ACoNN推薦模型的主要實現步驟:
(1)輸入層:利用詞嵌入模型,將用戶與項目的評論文本表示成詞嵌入矩陣Mu和Mi。
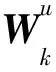
(6)
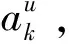
(7)
最后對目標用戶詞向量矩陣進行加權,得到更新權值后的矩陣Su,如式(8)所示:
Su=A(u)×Mu
(8)
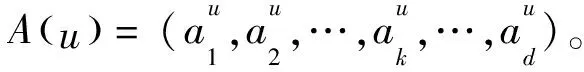
(3)CNN層:利用CNN對詞向量矩陣Su進行卷積、池化和全連接操作得到用戶向量outputu,同理可得項目向量outputi。
(4)推薦:連接outputu、outputi,構建用戶-項目特征向量z;向向量z加入因子分解機,根據最小化損失函數進行訓練,完成參數更新,如式(9)所示:
(9)
其中,yreal為用戶對項目的真實評分值,w0為全局偏置量,wi表示向量z中第i個分量的權重值,zi和zj分別表示向量z的第i和第j個分量,wij表示z中第i個與第j個特征向量的交互值。
相比深度神經網絡,該模型訓練階段參數較少、復雜度較低。此外,注意力權值更新層的設計有助于捕捉文本中的重點信息,結合CNN具有共享權值和局部連接的特性,更加易于模型的優化[19]。此方法適用于解決圖像視覺領域的圖像分類和文本處理等問題,運用注意力機制能使CNN在每一步關注圖像或者文本上的不同位置,提高對重點特征的提取效率。雖然基于注意力機制的CNN推薦方法能從輸入中獲取最有效的信息[20],但是這種方法也不能表示動態變化的用戶興趣。
3.3 基于注意力機制的RNN推薦方法
RNN即循環神經網絡,是一類用以處理序列數據的神經網絡。針對DNN和CNN不能解決時序數據的問題,一些研究者將注意力機制和RNN結合應用于推薦任務中,刻畫用戶興趣的動態變化。LSTM(Long Short-Term Memory)和GRU(Gated Recurrent Unit)是RNN的2種改進版本,它們在簡化RNN內部循環結構的同時,緩解了RNN無法檢測長序列的問題[21]。
針對微博的話題標簽推薦沒有考慮文本的時序特征問題,Li等人[22]構建了一種基于主題注意力機制的LSTM模型,該模型與文獻[15]中的CNN推薦模型相比,加入了時序特征的影響,有效提升了推薦性能。不足之處是忽略了用戶信息、時間信息等數據對標簽推薦的影響。Xing等人[23]提出了基于詞級與語句級注意力機制的用戶-項目推薦模型,在Yelp和Amazon數據集上的實驗中,推薦性能皆提升了近2%,驗證了考慮語義層面的推薦是有效的。但是,這種方法只有當目標用戶為目標項目編寫的評論可用時,才表現出最佳性能,數據量較少時會降低推薦效果。馮興杰等人[24]提出了深度協同模型DeepCLFM(Deep Collaborative Latent Factor Model),解決了用戶與項目的深層抽象特征挖掘不充分問題,通過對評論文本信息作全局偏倚項的補充,有效緩解了冷啟動問題。但是,DeepCLFM學習到的用戶偏好向量是靜態的,而同一用戶對不同項目的偏好向量是不同的,此模型未加以區分。
為了解決標簽推薦中存在的微博噪聲問題,文獻[25]提出了基于LSTM的時態增強語句級注意力模型。通過在語句級注意力層引入時間信息,減少了噪聲數據對分類器的影響。其推薦模型如圖4所示。其中,Mi(i=1,2,…,N)表示第i條微博的詞向量矩陣。
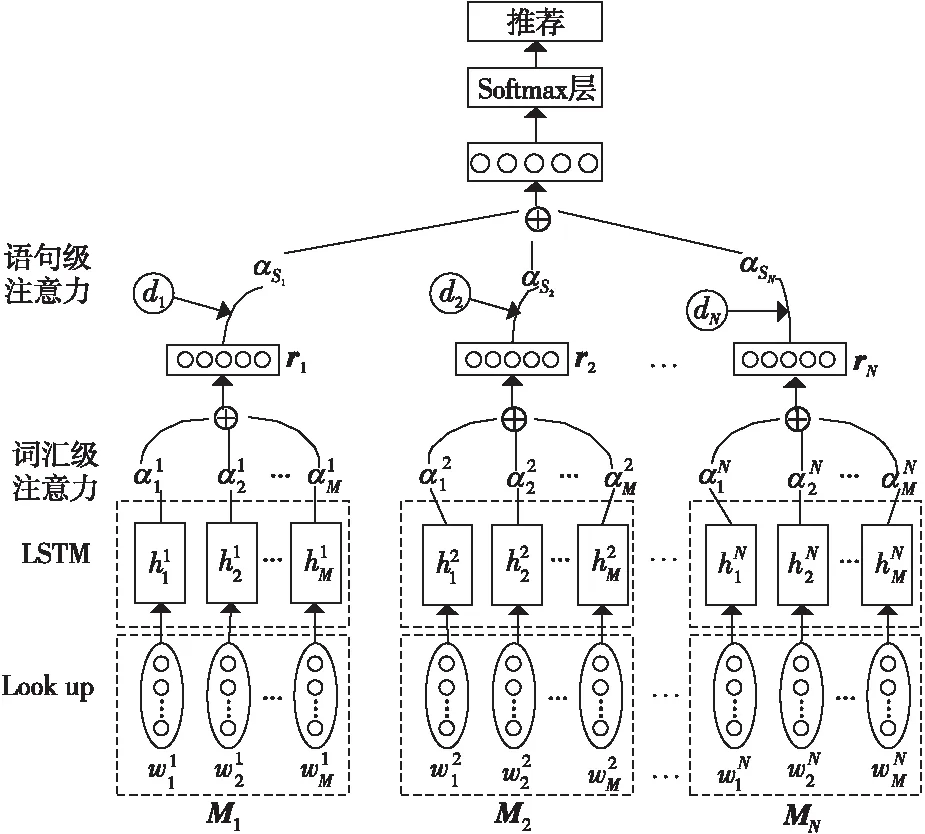
Figure 4 Temporal enhanced sentence-level attention model based on LSTM
基于LSTM的時態增強語句級注意力模型的主要實現步驟如下所示:
(1)Lookup層:將微博中的單詞wi映射到一個低維向量中,得到嵌入向量ei。
(2)LSTM層:將實值嵌入向量序列bN={e1,ei,…,eN}輸入LSTM,獲得微博的高級語義表示H,且H={h1,h2,…,hM}。其中,N和M分別表示微博條數和最大長度。
(3)詞匯級注意力層:通過更新每個隱狀態hj的注意力分數,得到詞匯級注意力矩陣αW,然后求解隱狀態的加權和,得到語句向量r,如式(10)~式(11)所示:
αW=Softmax(ωTtanh(H))
(10)
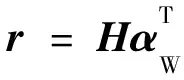
(11)
其中,ω是一個訓練好的參數向量,ωT是它的轉置,通過預訓練得到。
(4)語句級注意力層:將詞匯級注意力層輸出的句子向量集合S={r1,r2,…,rN}輸入語句級注意力層,先計算語句向量ri與標簽查詢向量t的匹配分數mi;然后加入時間信息di,得到每個語句向量ri的注意力權重αMi;最后求解集合S中語句向量的加權和,記為R,如式(12)~式(14)所示:
mi=riAt
(12)
(13)
(14)
其中,di表示時間元素,當給定一個〈microblogMi,hashtagh〉的元組時,根據微博詞向量矩陣Mi和標簽,可以從一個需要訓練的二維矩陣B∈R|time|×|hashtag|中查找對應的di。|time|是時間節點的個數,|hashtag|是標簽的個數,A是一個加權對角矩陣。
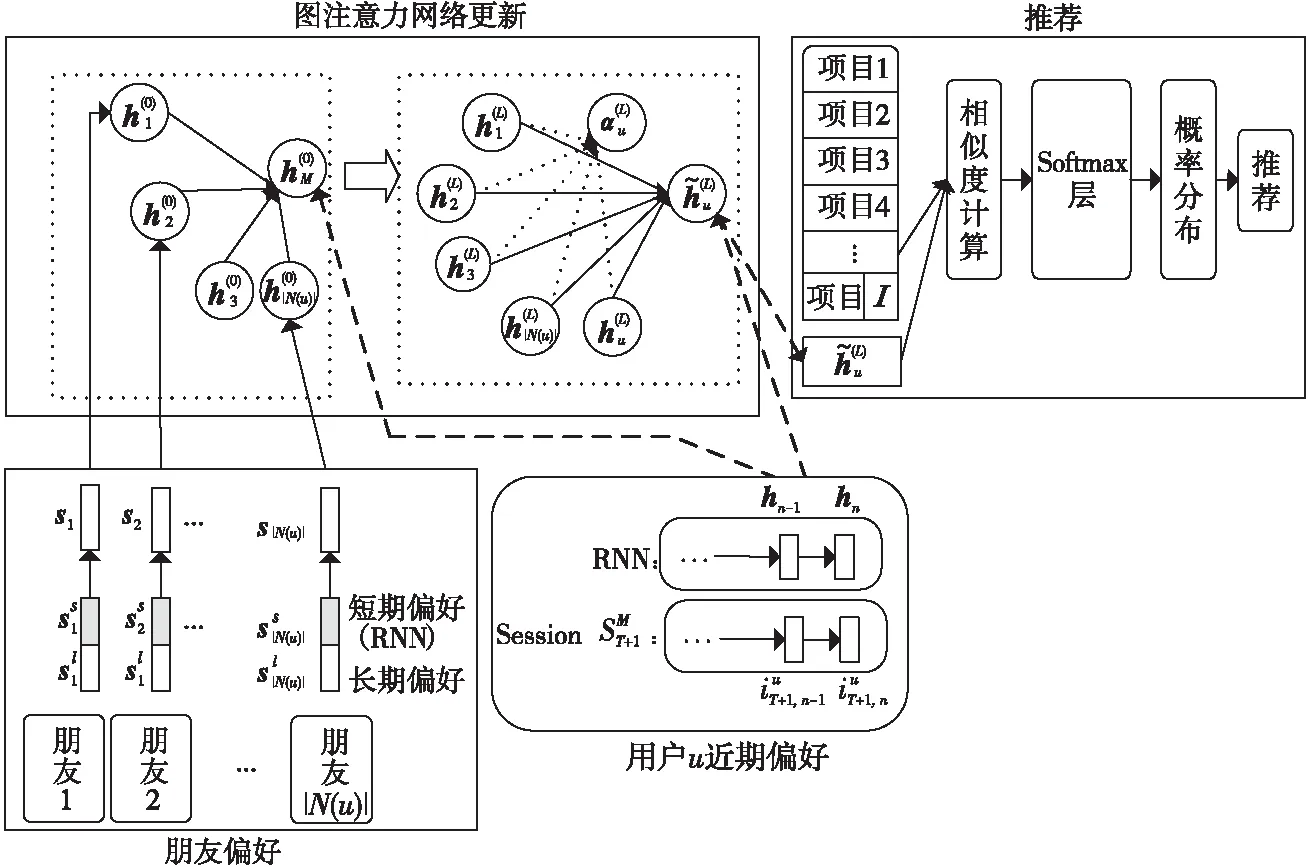
Figure 5 Dynamic graph attention network social recommendation model
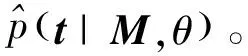
(15)
其中,θ是模型的所有參數,Mi和ti分別表示第i個微博向量和標簽向量。
該模型不僅從詞匯和語句2個級別對微博特征進行分層刻畫和關聯,還將時間信息引入注意力機制模型,彌補了文獻[22]未考慮時間信息的不足,更形象地刻畫了微博數據的動態性。因此,適用于解決文本翻譯、語言識別和推薦中的序列預測問題,應用注意力機制使RNN能夠將輸出序列中的每一項與輸入序列相關項對應,克服傳統循環神經網絡在學習超長序列上的限制問題[26]。但是,LSTM和GRU等作為RNN的衍生,只可以處理歐幾里得空間數據,對非歐空間數據的處理存在一定局限性,也無法解決非歐空間的推薦問題。
3.4 基于注意力機制的GNN推薦方法
GNN即圖神經網絡,不僅對數據具有強大的特征提取和表示能力,還可以表示非歐幾里得結構數據,可用于解決非歐空間的推薦問題[27]。針對傳統協同過濾方法的稀疏性問題,Wu等人[28]提出了一種雙圖注意力網絡協作學習雙重社會效應的推薦方法。該方法一方面由用戶特定的注意力權重建模,另一方面由動態的、上下文感知的注意力權重建模,通過將用戶領域的社會效應擴展到項目領域,緩解了數據稀疏性問題。模型可學習多方面社會影響的有效表示,具有良好的表達性,但社會圖網絡的構建相應增加了模型的時間復雜度。考慮當前網絡社區推薦未充分考慮用戶會受朋友偏好影響的問題,Song等人[29]提出了一種基于動態圖注意力神經網絡的社區推薦模型,圖注意力網絡用來捕獲朋友的短期與長期偏好對用戶的影響。其模型圖如圖5所示。詳細步驟主要有:
(1)用戶動態偏好建模:通過RNN對用戶近期的瀏覽內容進行建模,得到用戶的偏好hn。
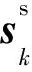
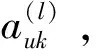
(16)
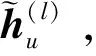
(17)
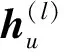
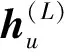
(18)
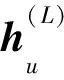
之后由Softmax函數得到項目y的概率,表示用戶對項目y可能感興趣的程度,如式(19)所示。最終根據這個概率的大小,向用戶進行推薦。
(19)
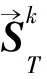
該模型能充分利用朋友的短期與長期偏好,獲取社會關系對用戶偏好的影響,但項目的特征提取過程過于粗糙,忽略了用戶和項目之間的互動關系。將注意力機制應用到GNN鄰近節點上,能夠學習每個鄰近節點與該節點之間的影響[30]。此外,基于圖結構的廣義神經網絡能夠表示除語言、視頻和圖像之外的非歐幾里得結構數據,通過對圖數據進行處理,可深入挖掘其內部的特征和規律,解決如社交網絡、信息網絡和基礎設施網絡等領域中的推薦問題。
4 基于注意力機制的深度學習推薦的難點
4.1 提取注意力方法的選擇問題
在一些場景下,可選擇的注意力方法可能有多種。如文獻[6]中,引入多頭注意力與單層自注意力皆可提升分類任務的性能,但較使用自注意力而言,多頭注意力更能提升模型在語句層面的特征表達能力,在SemEval-2010數據集上的實驗中,多頭注意力模型的F1值相對自注意力模型的提高了2.0%左右,說明不同的注意力方法對提升模型性能的貢獻是不同的。近年來,許多研究者在不同任務場景下又提出了不同注意力機制的新變體,如雙注意力[31]、雙向分塊自注意力[32]等,如何結合這些新變體,選擇適合當前推薦任務的注意力方法仍具有一定的復雜性。
4.2 注意力融入時機的選擇問題
在注意力機制與CNN相結合的工作中,Yin等人[33]和Santos等人[34]通過實驗證實了注意力機制用于池化層的效果比卷積層好。在此基礎上,文獻[35]將注意力與CNN池化層、項目潛在向量層及MLP輸入層相結合進行對比實驗,發現在稠密數據集上,注意力與池化層相結合的模型表現得更加穩定;而在稀疏數據集上,注意力與隱藏層相結合模型預測效果更佳,說明注意力引入時機的差異、數據集稠密度差別,都會影響最終的推薦結果。CNN相對神經網絡,結構較簡單,而在更加復雜的任務場景下,使用的神經網絡也更加復雜,增加了注意力機制融入深度神經網絡中的時機的難度。
4.3 融入注意力機制引起推薦模型復雜度增加問題
雖然注意力機制可以改善傳統編碼器-解碼器的部分問題,但引入注意力機制獲得注意力分配權重時,需要計算源語言句子中所有詞語的權重,該過程計算資源耗費大,增大了推薦模型復雜度,還會導致模型的訓練速度和推斷速度下降。同時,引入注意力機制可能需要更多的存儲資源,例如對于自注意來說,需要很大的存儲空間來保存元素的對齊分數,需要的存儲空間隨序列長度呈二次方增長,因此在保證效率的前提下降低推薦模型的復雜度存在一定的難度。
4.4 融入注意力機制的推薦效果評價問題
注意力機制應用范圍廣,但并不是對所有模型引入注意力機制都可以提高性能。例如,因子分解機FM(Factorization Machine)利用同一特征向量表示某個特征和其它特征間的交互顯然是不合理的。于是Juan等人[36]和Xiao等人[37]分別提出了FFM(Field-aware Factorization Machine)和AFM(Attentional FM)2種新的方法。FFM通過引入“域”的概念,對不同域使用不同的向量來解決這一問題。而AFM通過引入注意力機制對不同的交互項計算注意力權重,區分特征的重要程度。比較來看,AFM雖然和FFM效果相當,但是AFM通過引入新參數來彌補某方面的擬合能力,可能會造成過擬合現象。所以,對模型引入注意力機制后的推薦效果進行多方面的評價,也是當前基于注意力機制的深度學習推薦的一個難點。
5 基于注意力機制的深度學習推薦未來研究方向
5.1 多特征交互的注意力機制深度學習推薦
當涉及多特征交互時,通常采用矩陣分解模型來實現,如文獻[37]利用一個神經注意力網絡對不同交互特征的重要程度進行區分,改善了因子分解機的性能,并在真實數據集上將回歸任務的性能提高了8.6%。但是,基于矩陣分解的協同過濾方法僅使用評分信息,不能捕捉更深層的特征信息。而文獻[38]利用多層交互的非線性網絡結構獲取不同層次的交互結果,將RMSE指標的值降低了2%左右。但是,這種基于深度學習的推薦模型在提升推薦效果的同時,難以對推薦效果做出合理的解釋。所以,考慮在多特征交互的推薦模型中加入注意力機制,以提高模型的可解釋性,是值得研究的重要課題之一。
5.2 多模態注意力機制的深度學習推薦
信息的媒介有音頻、文字、語音和圖像等多種模態,目前對多模態信息的使用仍不夠廣泛,在多模態注意力機制中,主要使用語音和圖像信息。文獻[39]認為不同模態對于情感狀態的影響是不同的,作者通過多模態注意力機制,將視頻特征和音頻特征進行融合,相比一些采用主流深度學習方法進行情感分析的任務,在性能上提高了2%左右。在深度學習的推薦研究中,除了利用文本、評分等信息外,還可以從視頻和它模態信息中提取用戶的偏好特征。所以,將多模態注意力機制結合深度學習技術,用于推薦系統也是未來的一個研究方向。
5.3 注意力機制的GNN推薦和其他推薦方法融合
由于GNN可以用來表示其它神經網絡無法表示的非歐幾里得結構數據,將其作為輔助工具應用在推薦系統領域,可有效緩解數據稀疏性問題[40]。文獻[28]引入雙圖注意力網絡來協作學習用戶的靜態和動態雙重社會效應,同時考慮到用戶領域和項目領域中不同的社會效應會相互作用,提出了基于多臂賭博機的一種新的融合策略來衡量這種交互作用,在真實數據集上的實驗表明,其推薦精度最高提高了9.33%。因此,將注意力機制的GNN推薦融合其它推薦算法或深度學習技術,有利于提高推薦的效果。
5.4 基于注意力機制的深度學習群組推薦
大多數推薦技術應用于個性化推薦,但在很多情況下,推薦的產品或服務被一群用戶所消費[41]。文獻[42]提出了一種AGR(Attention-based Group Recommendation)模型,利用注意力機制學習群體中每個用戶的影響權重,相較于基準模型其推薦性能提高了3%以上。但是,作者只在模型中使用了項目的ID信息,得到的信息非常有限,對模型性能的提升也有一定的限制。而李振新[43]提出的基于Phrase-LDA模型從評論中提取用戶主題,更細致地從語義層面描述了用戶的偏好,在群組推薦領域中具有一定的新穎性。考慮在AGR模型的基礎上,將諸如社交關系、文本信息(例如事件描述)或時間等上下文信息用來學習群組推薦中的注意力模型,也是未來的一個研究方向。
5.5 基于注意力機制和深度學習的跨領域推薦
單領域個性化推薦中容易出現數據稀疏性和冷啟動問題,使得推薦效果不夠理想。而在跨領域推薦中,其它輔助域信息可以為目標域推薦提供幫助,從而解決傳統單域推薦中數據稀疏和冷啟動問題,因此逐漸成為學術界的研究熱點。文獻[44]構建了一個基于注意力機制和知識遷移方法的卷積-雙向長短期記憶AC-BiLSTM(Convolution-Bi-directional Long Short-Term Memory based on Attention mechanism)模型,向BiLSTM中引入注意力機制得到不同詞匯對文本的貢獻程度,并且在目標函數中加入了正則約束項,避免在遷移過程中出現負遷移現象,使跨領域情感分類的平均準確率在2個數據集上分別提高了6.5%和2.2%。結合相關情感分類模型,將注意力機制應用到跨領域推薦研究中也是未來的一個研究方向。
6 結束語
注意力機制的特點是能主動從海量輸入信息中選擇對當前目標任務更重要的信息,在提高推薦模型性能的同時,提升深度學習可解釋性。將注意力機制應用到深度學習推薦研究中,擴展了推薦模型中神經網絡的能力。本文圍繞注意力機制的結構、分類以及注意力機制在深度學習推薦中的研究等角度展開,并針對深度學習推薦模型中存在的注意力機制的選擇、階段融入、評價和模型復雜度增加等難點與挑戰進行了分析,最后指出了基于注意力機制的深度學習推薦未來的研究方向。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年21期)2018-11-09 01:23:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
