基于U-Net結構改進的醫學影像分割技術綜述*
2021-03-06 09:29:08殷曉航王永才李德英
軟件學報 2021年2期
殷曉航,王永才,李德英
(中國人民大學 信息學院,北京 100872)
隨著深度學習技術的快速發展,深度學習在醫學影像領域的應用吸引了廣泛的研究和關注.其中,如何自動識別和分割醫學影像中的病灶是最受關注的問題之一.為解決這一問題,2015 年,Ronneberger 等人在MICCAI會議發表 U-Net[1],是深度學習在醫學影像分割中的突破性的進展.U-Net 是基于 FCN(fully convolutional network)改進而成,包括編碼器、瓶頸(bottleneck)模塊、解碼器幾部分組成,由于其U 型結構結合上下文信息和訓練速度快、使用數據量小,滿足醫學影像分割的訴求,而在醫學影像分割中廣泛應用.U-Net 的結構如圖1 所示.由于病灶的形狀的多樣性和不同器官結構的差異性,僅使用U-Net 結構分割病灶無法滿足對于精準度、速度等的需求.
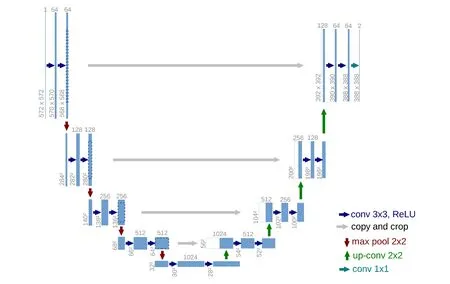
Fig.1 U-Net network structure diagram[1]圖1 U-Net 網絡結構圖[1]
U-Net 自發表以來,其編碼器-解碼器-跳連的網絡結構啟發了大量基于U-Net 結構改進的醫學影像分割方法.隨著深度學習技術的發展,包括注意力機制、稠密模塊、特征增強、評價函數改進等基于U-Net 的基礎結構,將這些深度神經網絡發展的最新技術引入到醫學影像分割應用中,成為被廣泛采取的改進方法.這些相關工作或者面向不同的優化目標,或者通過結構改進、添加新模塊等手段,提高醫學影像分割的準確性、運算效率、適用范圍等.由于相關工作眾多,而且大多數工作是結合實際問題,不斷地加入新的思想,現有文獻中對U-Net 結構改進的相關工作尚缺少較好的綜述和總結的工作.本文擬從改進目的和改進手段兩個方面對近幾年基于U-Net 結構改進的醫學影像分割的工作進行綜述.
· 面向性能優化的改進工作主要包括:(1) 將U-Net 擴展到3D 圖像[2,3];(2) 增強相關特征,抑制無關特征[4-13];(3) 改進計算速度、內存占用[14-22];(4) 改進特征融合方法[19,23-30];(5) 針對小樣本訓練數據集的改進[31-34];(6) 提高泛化能力的改進[35,36].
· 針對U-Net 模塊結構的改進主要包括:(1) 針對編碼器、解碼器結構的改進[37-45];(2) 針對損失函數的改進[2,7,32,41,46-49];(3) 對瓶頸(bottleneck)模塊結構的改進[9,31,50];(4) 增加數據流路徑的改進[49,51];(5) 采用自動結構搜索的改進[52]等方面.
圖2 給出了本文對U-Net 相關研究工作的分類方法.雖然有的相關工作同時被兩個層面包含,但這種分類總結能使得我們更清晰地了解該工作的改進目的和實現目的的改進手段.針對每類改進的具體方法,本文較詳細的介紹了方法的主要設計思想、改進效果、所使用的數據集、評價指標等,并最后給出對相關方法的整體的總結和比較.此外,本文還提煉出U-Net 結構改進中一些常見的基礎結構模塊,這些基礎結構模塊對深度學習網絡結構的改進具有較為普遍的借鑒意義.
本文第1 節介紹醫學影像分割深度神經網絡中的一些常見的損失函數和評價參數.第2 節、第3 節從兩個方面、11 個子類總結和介紹基于U-Net 結構改進的醫學影像分割的相關研究工作.第4 節提煉醫學影像分割研究中常見的一些特殊結構.第5 節對文中所提的算法進行總結、對比和展望.
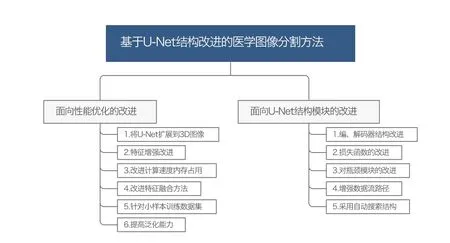
Fig.2 Medical image segmentation method based on U-Net structure improvement圖2 基于U-Net 結構改進的醫學影像分割方法
1 醫學影像分割中神經網絡常采用的評價參數和損失函數
損失函數和評價參數是訓練網絡是必不可少的部分:損失函數表示預測和目標之間的差異,常用交叉熵、Dice loss 等判斷訓練模型與真值之間的差異;分割評價參數是評價圖像分割好壞的重要參數,常用Dice 等評價網絡模型的優劣.本節主要列舉幾個圖像分割神經網絡中常用的評價參數和損失函數.
1.1 評價參數
在評價參數之前,先要介紹一下機器學習中的混淆矩陣.混淆矩陣主要是解決二分類問題[53].其中,TP=True Positive=真陽性,FP=False Positive=假陽性,FN=False Negative=假陰性,TN=True Negative=真陰性.
1.1.1 精確率(precision)
精確率表示的是預測為正的樣本中有多少被預測正確.

1.1.2 召回率(recall)
召回率就是召回目標類別,即表示樣本中的正樣本有多少被預測正確.

1.1.3 準確率(accuracy)
準確率是評估獲得所有成果中目標成果所占的比率.

1.1.4 綜合評價指標(F-measure)
F-Measure 是綜合精確率和召回率的評估指標,用于反映整體的情況.

當α=1 時,

1.1.5 IoU(intersection over union)/Jaccard Index
IoU 又稱為Jaccard Index[54],是目標檢測常用到的評價參數,通過預測邊框和真實邊框的比值計算兩個樣本的相似度或者重疊度.我們分別用Vseg,Vgt表示兩個輪廓區域所包含的點集(Vseg為預測,Vgt為真實標簽),范圍[0,1],則
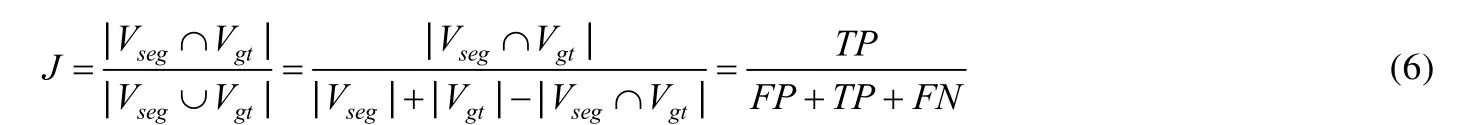
1.1.6 mIoU(mean intersection over union)
mIoU 為語義分割的標準度量,在每個類上計算IoU 之后進行平均.由于其簡潔、代表性強,大多數研究人員都采用該標準報告結果.假設共有k+1 個類(從L0到Lk,其中包含一個空類或背景),pij表示本屬于類i但被預測為類j的像素數量.即pii表示真正的數量,而pij,pji表示假正、假負,則MIoU 定義為
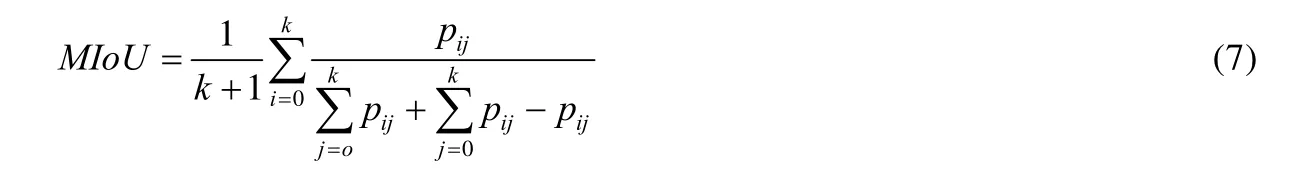
1.1.7 Dice coefficient
Dice 是一種評估兩個輪廓區域相似度的函數,通常用于計算兩個樣本的相似度或者重疊度,其范圍為[0,1].

Jaccard Index 和Dice coefficient 之間的換算公式為

1.1.8 SSIM
SSIM 是圖像質量評價結構相似性指標,是基于樣本x和y之間對于亮度、對比度、結構這3 個方面進行比較,其范圍為[0,1],值越大,兩圖像之間的差異越小[55].
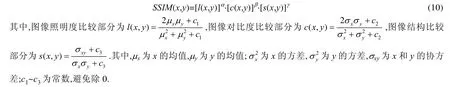
1.2 損失函數
損失函數的設計常要考慮數據集的特點,比方說,Focal loss 就是用來處理數據集中的難分樣本.Dice 系數可以用來處理數據分類不均衡的情況,其中,不均衡很多情況下是由于背景和待分割區域之間的面積對比不均衡導致的.對于二分類,可以只考慮待分割區域,即是本文中的Dice loss 函數;那么當對于多種類的分割時,同樣可以只計算待分割區域的Dice 系數,這樣就可以避免背景占比太大,造成的數據集分類不均的情況.
1.2.1 交叉熵損失函數
設y′是模型的輸出,在0-1 之間.對于正樣本而言,輸出越大,意味著損失越小;對于負樣本而言,越小,則損失越小.所以,交叉熵的定義為
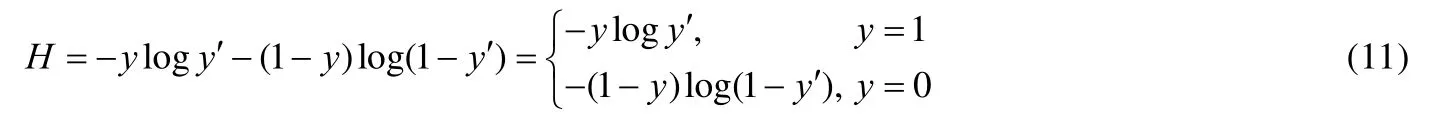
1.2.2 Focal loss
Focal loss[56]是在交叉熵損失函數基礎上進行的修改,主要是為了解決one-stage 目標檢測中正負樣本比例嚴重失衡的問題.該損失函數降低了大量簡單負樣本在訓練中所占的權重,也可理解為一種困難樣本挖掘.

γ>0 減少易分類樣本的損失,使得更關注于困難的、錯分的樣本.平衡因子α用來平衡正負樣本.實驗證明,γ=2 最優.
1.2.3 Dice loss
Dice loss[2]在感興趣的解剖結構僅占據掃描的非常小的區域,從而使學習過程陷入損失函數的局部最小值.所以,要加大前景區域的權重.

1.2.4 Tversky loss
Tversky[57]系數是Dice 系數和Jaccard 系數的一種廣義系數,Vseg為預測標簽,Vgt為真實標簽,公式定義為
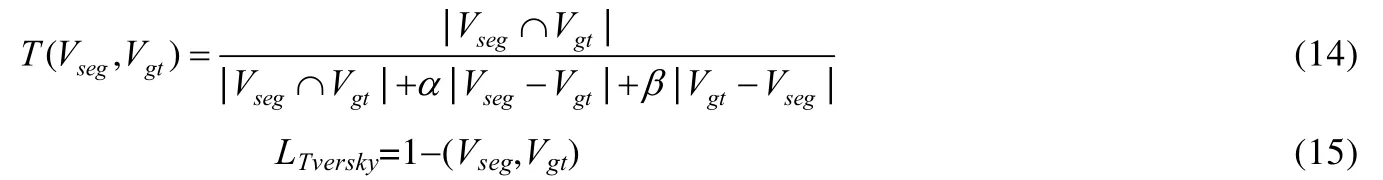
當α=β=0.5 時,Tversky loss 為Dice loss;當α=β=1 時,Tversky 系數就是Jaccard 系數.A-B則意味著是FP(假陽性),而B-A則意味著是FN(假陰性);α和β分別控制假陰性和假陽性.通過調整α和β,可以控制假陽性和假陰性之間的權衡[58].
2 基于U-Net 面向性能優化的改進方法
本節和第3 節將重點介紹基于U-Net 改進的各類的圖像分割方法,本節介紹面向性能優化的改進方法.現有的工作主要在應用范圍、特征增強、訓練速度優化、訓練精度、特征融合、小樣本訓練集以及泛化能力提升幾方面對U-Net 提出各種改進進行研究,這些工作對網絡結構進行了不同的變體,或是針對不同的問題加入了不同的結構.
2.1 將U-Net擴展到3D圖像
生物醫學影像是不同位置的切片構成的一組三維圖,所以傳統的2D 圖像處理模型處理3D 的醫學影像時會存在問題:一是效率不高,二是會丟失大量的上下文.針對這一問題,Ozgun Cicek 等人基于U-Net 提出了3D U-net[3],其網絡結構如圖3 所示.3D U-net 輸入輸出是三維圖像,提升了U-Net 模型對三維圖像的分割準確性.
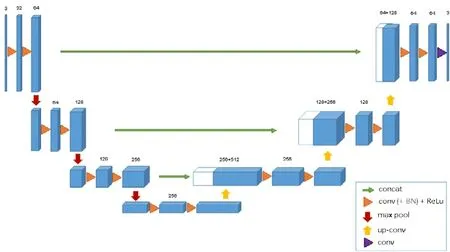
Fig.3 3D U-Net structure diagram[3]圖3 3D U-Net 結構圖[3]
另一個代表性工作是Fausto Millemari 等人提出的V-net[2],結構如圖4 所示.在輸入3D 圖像按照通道拆分的同時,在每一層加入殘差結構,以確保短時間收斂.降采樣采用卷積操作替換最大池化操作,有利于在接下來的網絡層中減小輸入信號的尺寸的同時擴大特征感受野范圍,并提出Dice-based loss 這個新的損失函數.
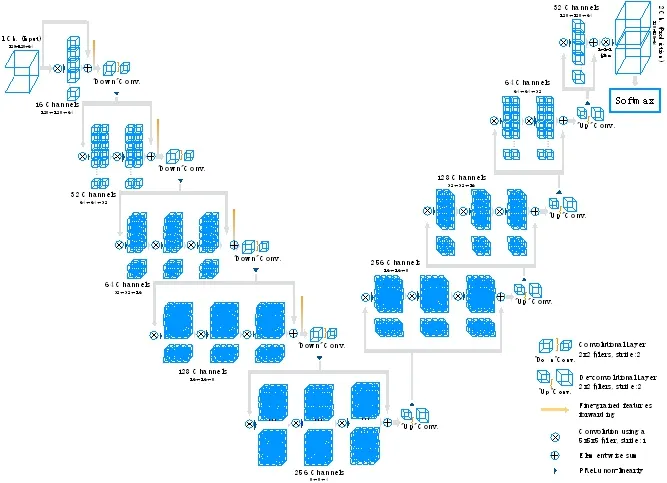
Fig.4 V-Net structure diagram[2]圖4 V-Net 結構圖[2]
2.2 針對增強相關特征,抑制無關特征的改進方
醫學影像中,由于病變區的位置較其他無關特征更多,那么在分割過程中,聚焦目標特征、抑制無關特征就極為重要.一般在編解碼器和瓶頸處加入SE 或者attention 模塊,這兩個模塊都可以從空間和通道兩個方面進行激勵,以達到增強特征的效果.
2.2.1 加入SE 模塊
SE(squeeze-and-excitation)是在2018 年CVPR 上提出通過學習的方式來自動獲取到每個特征通道的重要程度,然后依照這個重要程度去提升有用的特征,并抑制對當前任務用處不大的特征[59].Roy 等人[4]引入3 個SE模型擴展結構分,別串聯在U-Net 的編碼和解碼結構中.
(1) 第1 種是信道SE(cSE),通過全局池化提取最能表現特征的通道,再將信息融合到原有的tensor 中.
(2) 第2 種是空間SE(sSE),提取一張特征圖劃分特征區域,再將特征區域信息融合到原有的tensor 中.
(3) 第3 種同時進行空間和信道SE(scSE),是cSE 與sSE 的合并輸出.
實驗結果表明:空間激勵要比通道激勵產生更高的對分割更為重要的增益;與標準的網絡相比,scSE 雖然增加了一些計算復雜度,但是分割性能更好.
2.2.2 加入attention 塊
Attention 可以解釋為將計算資源偏向信號最具信息性的部分的方法.一般在圖像分割中,由于病灶較小且形狀變化較大,常在encoder 和decoder 對應特征拼接之前,或是在U-Net 的瓶頸處增加attention 模塊來減少假陽性預測.
(1) 在encoder 和decoder 之間加入attention 模塊
Oktay O 等人在2018 年提出的Attention U-net[5]在U-Net 在encoder 和decoder 中對應的特征進行拼接之前加入了一個集成注意力門(AGs),重新調整了encoder 的輸出特征.該模塊將生成一個門控信號g,用以消除不相關和嘈雜的歧義在跳過連接中的響應,以突出通過跳過連接傳遞的顯著特征.attention 模塊的內部結構如圖5所示.
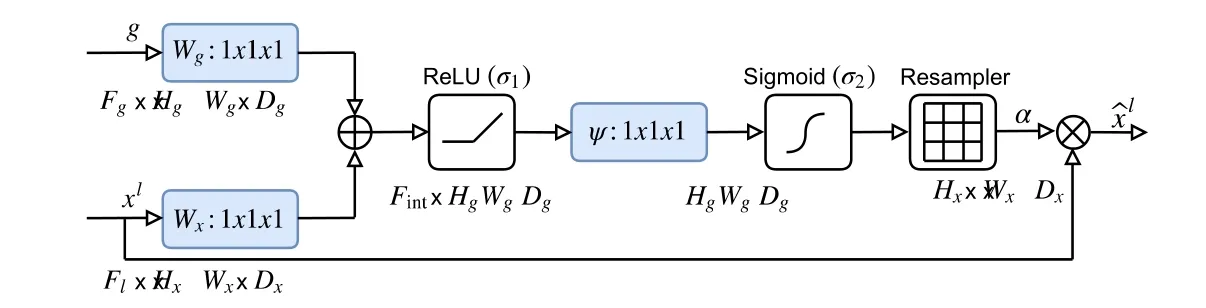
Fig.5 Internal structure of Attention module in Attention U-net[5]圖5 Attention U-net 中Attention 模塊內部結構[5]
Li 等人在2019 年提出了敏感連接注意力U-net(CASU)[6],用于視網膜血管的精細分割.CASU 的網絡結構與Attention U-net 的網絡結構相同,但是在Attention 模塊的結構上,CASU 采用不同的設計方式,如圖6 所示.G是并行編碼模塊的輸出,X是前一個解碼模塊的輸出.G和X經過Attention 門的處理后,再同G拼接.由于注意門的參數更新不僅取決于解碼層傳遞的梯度,而且還取決于編碼器層傳遞的梯度,其AGs 最終采用的是可以提高訓練過程中細節特征的質量和影響的Up-link.實驗結果表明,該方法能夠有效地提高分割模型的注意權重.
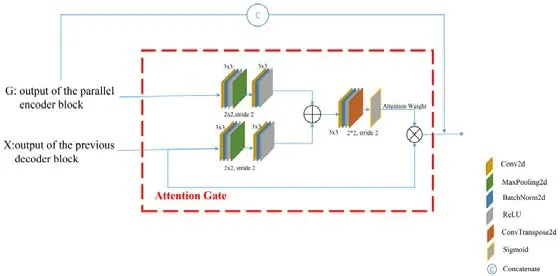
Fig.6 Structure diagram of Attention module in CASU[6]圖6 CASU 中Attention 模塊的結構圖[6]
Ni 等人在2019 年提出的RAUNet[7]加入了增強注意力模塊(AAM)用于融合多層次特征和捕獲上下文信息,來解決白內障手術器械分割中的鏡面反射問題.RAUNet 的增強注意力模塊(AAM)結構如圖7 所示.
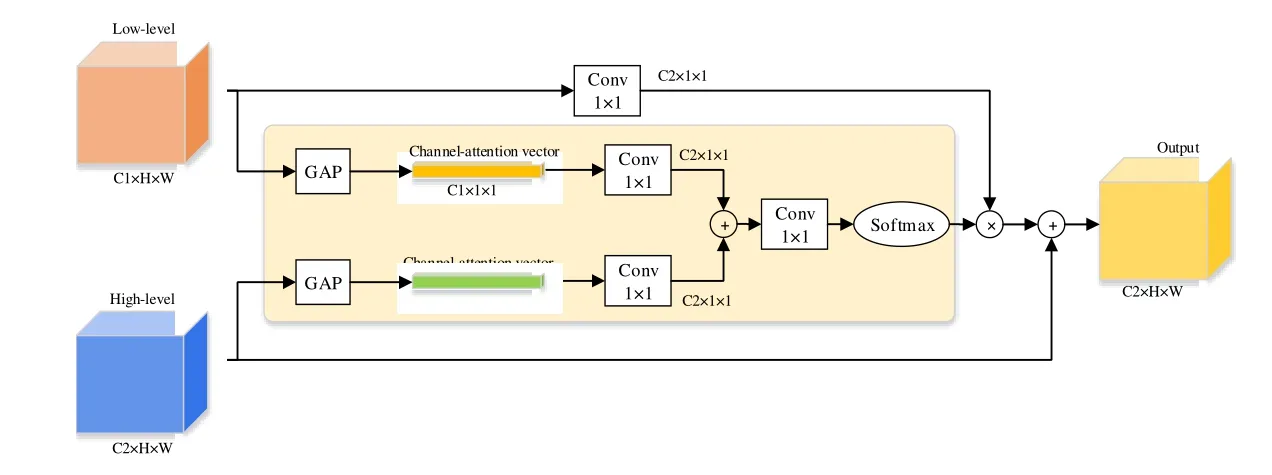
Fig.7 Structure diagram of AAM in RAUNet[7]圖7 RAUNet 中AAM 的結構圖[7]
AAM 對語意依賴進行建模,以強調目標通道.其主要通過全局平均池化分別提取高層和低層的全局上下文信息和語義特征,并分別壓縮成一個attention 向量后對語意依賴項進行編碼,突出關鍵特征并過濾背景信息.
Zhou 等人提出了輪廓感知信息聚合網絡CIA-Net[8],用于解決細胞核簇和不同器官形狀的差異性的問題.CIA-Net 在編解碼器之間建立多層次的橫向連接,分層地充分利用金字塔特征,通過encoder 早期層的紋理信息,可以幫助Nuclei decoder 中分辨率低但具有強語義的層來細化細節,如圖8(a)所示.
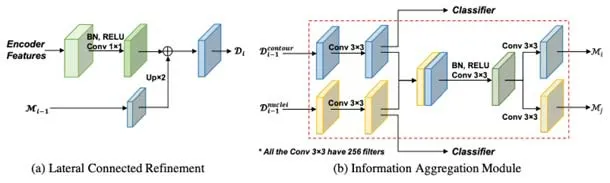
Fig.8 Structure diagram of IAM in CIA-Net[8]圖8 CIA-Net 中IAM 結構圖[8]
CIA-Net 將decoder 分為Nuclei decoder 和Contour decoder,兩者之間加入信息聚合模塊(IAM),將核信息和輪廓信息雙向融合(如圖8(b)所示).此外,為了防止網絡依賴于單一層次的區分特征,在每個階段引入深度監控機制[60],加強對多層次上下文信息的學習,這也有利于通過縮短反向傳播路徑來訓練更深層次的網絡體系結構.
(2) 在bottleneck 處加入Attention 模塊
bottleneck 是 U 型網絡收縮路徑和擴張路徑中間的部分.Wang 等人提出的鞏膜分割模型——ScleraSegNet[9]采用丟棄了全聯接層的VGG16 作為encoder,瓶頸處增加了bottleneck 模塊用以編碼最有區別的語義特征,其信息特征按照空間和信道進行分解,采用4 個attention 模塊:(1) Channel attention module(CAM),由SEnet[59]引出,結構圖如圖9(b)所示;(2) Spatial attention module(SAM)[61],結構如圖9(c)所示;(3) Parallel channel attention and spatial attention module[61],將CAM 和SAM 并聯后相加,結構如圖9(d)所示;(4) Sequential channel attention and spatial attention module[62]在平均池化層增加了最大池化層,然后將CAM 和SAM 模型順序串聯起來所得到,結構圖如圖9(e)所示.經過在不同數據集上驗證,作者提出了的這個方法在準確性上和泛化能力上都取得了顯著的效果.
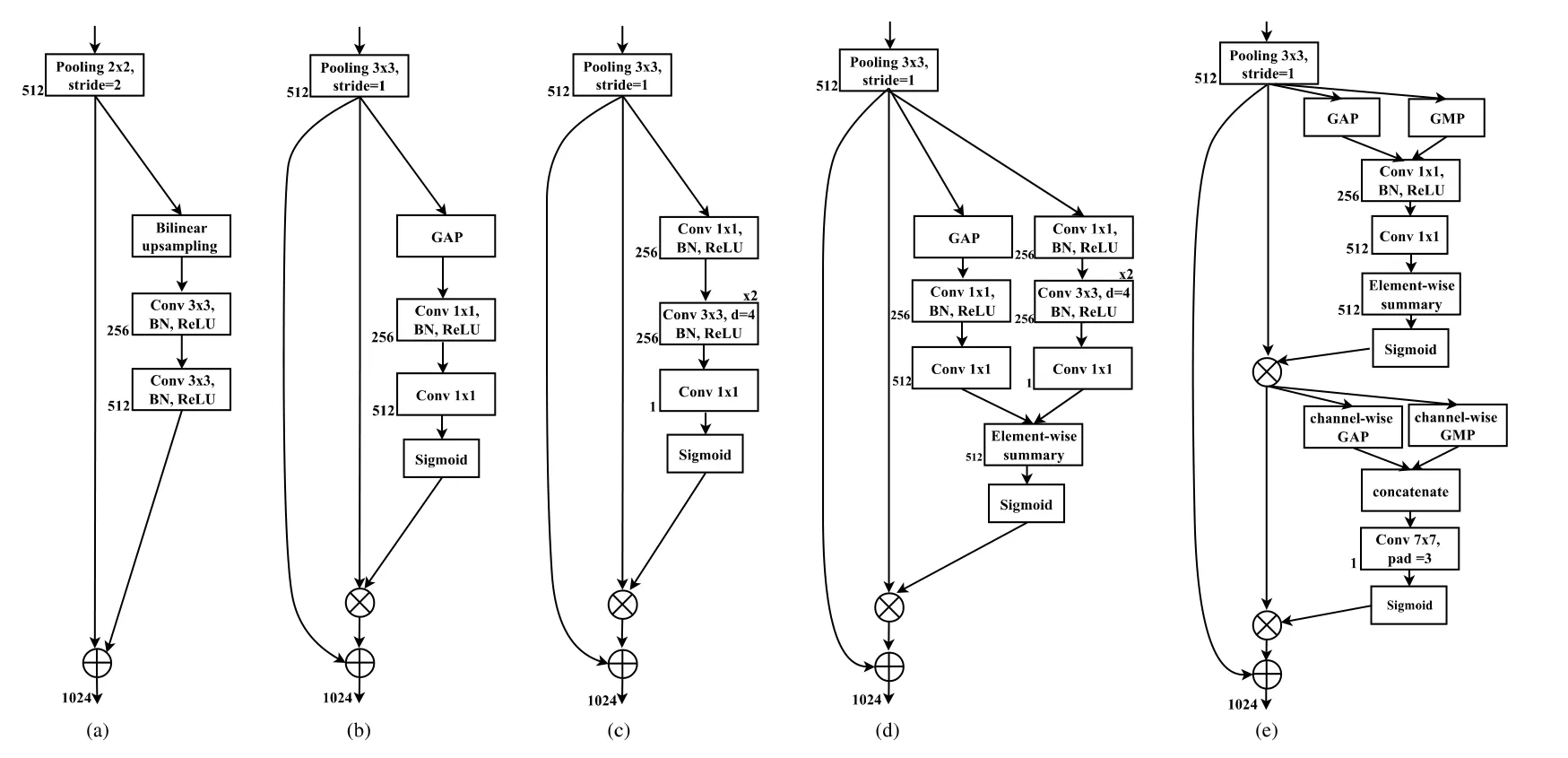
Fig.9 Internal structure diagram of Bottleneck in ScleraSegNet[9]圖9 ScleraSegNet 的bottleneck 內部結構圖[9]
(3) 在decoder 中加入attention 模塊
DA 3D-UNet[10]在3D Unet 的基礎上將上采樣替換成DUpsampling[63],以提高解碼器中圖像的質量.在解碼器的最后兩層加入由空間attention 和通道attention 組合而成的雙注意力模塊,將大范圍的、多通道的特征集中在關鍵位置、通道中.
(4) 在跳連中加入attention 模塊
Li 等人提出的ANU-Net[11]在Unet++的跳連中加入了Attention Gate,以提升網絡對于形狀多樣性病灶的分割效果.Attention Gate 的輸入分為兩個部分:解碼器的上采樣特征(g)和編碼器中相應的特征(f),其上采樣特征(g)作為門信號來增強編碼器中相應的深度特征,從而增強相關特征、抑制無關特征,結構圖如圖10 所示.
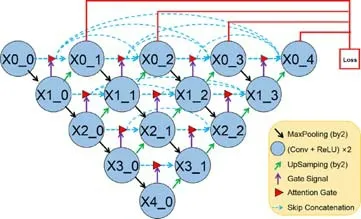
Fig.10 ANU-Net structure diagram[11]圖10 ANU-Net 的結構圖[11]
(5) 在編解碼器單元中加入attention 模塊
徐宏偉等人提出的RDA-Unet[12]采用殘差雙注意力(RAD)模塊作為編解碼器單元,RAD 將通道注意力機制和空間注意力機制相結合,保證特征提取的準確性,并加入殘差結構以防止梯度消失,更好地定位腎臟的邊界.
2.2.3 其他方法
Liu 等人在U-Net 的基礎上加深網絡層數至7 層,并將編碼器的池化層直接與解碼器對應的層級聯,以減少信息的損失,并稱此網絡為IU-Net[64].由于分割復雜的肝臟切片容易產生低質量的分割,其采用圖割算法[65],在前景和背景選取種子點,建立一個圖,利用最大流算法找到加權圖的最小割集,最終得到分割較好的圖像.他們將IU-Net 和圖割相結合的網絡最終命名為GIU-Net[64].Mu-net[13]將經過下采樣后不同尺度的特征圖分別輸入U-Net,再將不同尺度的U-Net 的輸出經過上采樣到上一層U-net 的輸入,幫助上一層減少對于低頻信息的計算,從而更加聚焦于病灶的分割.
2.3 針對內存占用、計算速度的改進方法
由于2D 卷積容易丟失上下文信息,而3D 卷積占用CPU 量過大,為了減少內存,一種方法是擴大patch 中的volume,另一種方法是用較小的batch size 訓練.這些方法畢竟是有局限性的,因而以下幾個工作改進網絡中部分模塊,減少內存,提升運算速度.
2.3.1 加入稠密卷積塊
Li等人于2018 年提出由有效提取切片的2D Dense Net 和提取肝臟病灶分割中上下文信息的3D Dense Net組成H-DenseUNet[14],即稠密融合U 型網絡.該網絡先采用ResNet 粗略的分割肝臟圖像,然后在感興趣區域(ROI)中,利用2D Dense Net 和3D Dense Net[66,67]有效探測切片內和切片間的特征.在H-DenseUNet 的結構上,MMMDF[15]將2D/3D DenseNet 替換成多模態2D-ResUNet 和3D-ResUNet,以2D 網絡的快速分割結果來指導3D 模型的學習并實施分割.
另一方面,光聲成像(PAT)測量用的聲波經過稀疏采樣后可以用于圖像重建,但會導致較為嚴重的圖像信息缺失[68].Steven Guan 針對這一問題提出一種全密集連接的FD-UNet[16],用于重建稀疏采樣的2D PAT 圖像,其基于U-Net,在編解碼器引入Dense connectivity 密集連接,避免了冗余特征的學習,增強了信息流動,在性能接近的前提下進一步減少了網絡參數,降低了計算成本,進行圖像重建時可更加快捷(如圖11 所示).
Fig.11 2D dense connection in FD-Net[16]圖11 FD-Net 中2D 稠密連接[16]
2.3.2 加入可逆結構
Robin 等人提出了Partially Reversible U-Net[17],將U-Net 的編解碼器每個單元采用可逆序列[69],同時使用傳統的不可逆操作來進行下采樣和上采樣以及跳躍連接.這種完全可逆的體系結構比傳統的U-Net 節省了大量的內存,因為激活只需要在每個可逆序列的末尾和不可逆的組件上保存.
2.3.3 加入SE 殘差塊
Zhu 等人提出的AnatomyNet[46](如圖12 所示)以端到端的方式聯合分割所有organs-at-risks(OARs),接收一個原始的全容積CT 圖像作為輸入,并將所有OARs 的掩模與圖像一起返回.該結構與U-Net 的不同在于:只在第1 個編碼塊中采樣了下采樣層,使得下一層中的特征映射和梯度比其他網絡結構占用更少的GPU 內存.移除第2~第4 個編碼器塊中的下采樣層,采用了SE 殘差塊[59]學習有效特征,以提升分割小解剖結構的性能.
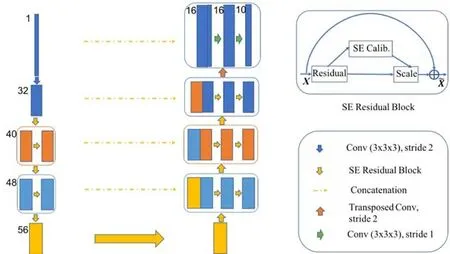
Fig.12 Anatomynet structure diagram.The first layer is down sampling,and the rest is replaced by SE residual block[46]圖12 AnatomyNet 結構圖.第1 層是下采樣,其余由SE residual block 代替[46]
2.3.4 通道分組
Chen 等人在2019 年為彌補三維MRI 腦腫瘤分割模型效率和準確性不可共存的問題,提出一種新的三維擴張多纖維網絡(DMFNet)[18].DMFNet 建立在多光纖單元(MF)[70]的基礎上,利用有效的群卷積,引入加權的三維擴展卷積運算,獲得多尺度的圖像分割表示,從而減少參數以提升運算效率.
圖13(a)、圖13(b)采用通道分組思想,將循環通道分成多個組,這樣可以減少特征映射和核心之間的連接,從而顯著地節省參數.而圖13(c)中的Multiplexer 主要是用于不同的fiber 之間交換信息.在圖13(d)中增加了擴張卷積,這種加權求和策略可以從不同視角自動選擇有價值的信息.
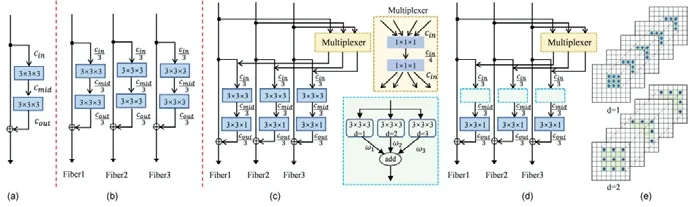
Fig.13 MF unit of dilated multi-fiber net (DMFnet)[18]圖13 DMFnet 多纖維網絡的MF 單元[18]
2.3.5 加入Inception 塊
Nabil 等人在MultiResUNet[19]中提出了MultiRes 模塊代替U-Net 的每一層解決多分辨率分析同時又節省內存、提高速度,其將U-Net 編解碼器的每個單元替換為MultiRes 模塊.受inception[71]啟發,作者先將大小為3×3,5×5,7×7 的卷積層并聯,以實現多層分辨率的分析(如圖14(a)所示),然后采用更小、更輕量級的3×3 卷積塊近似代替5×5,7×7 的卷積操作以減少存儲(如圖14(b)所示),再將filter 的個數從1 逐漸增加3 來減少前一層濾波器數量帶來的二次效應[72],并且增加1×1 卷積層的殘差連接以更好地保證空間信息,最后構成MultiRes 模塊.
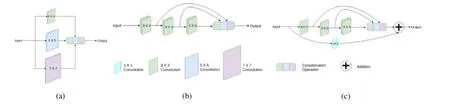
Fig.14 MultiRes model of MultiResUnet[19]圖14 MultiResUnet 中MultiRes 模塊[19]
DENSE-Inception U-net[20]將inception 和殘差模塊以及稠密模塊相結合,如圖15 所示,其中,采用Inception-Res 取代標準的卷積來增加網絡寬度;采用Dense-Inception 模塊,在增加網絡深度的同時,又不會增加參數的數量;上下采樣采用Inception 模塊,保證圖像分割的準確性.其在肺部圖像分割和血管圖像分割、腦腫瘤圖像分割方面都有很好的性能.
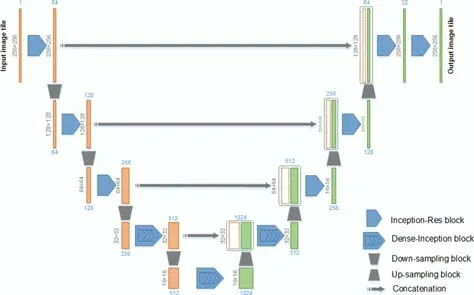
Fig.15 DENSE-INception U-net structure diagram[20]圖15 DENSE-INception U-net 結構圖[20]
2.3.6 其他方法
Li 等人提出了PBR-Unet[21],主要包括提取像素級概率圖的功能提取模塊和用于精細分割的雙向遞歸模塊,如圖16 所示.用2D Unet 提取概率圖,用于指導精細分割;雙向遞歸模塊將上下文信息集成到整個網絡中,避免了傳播過程中空間信息的丟失,從而節省內存.徐等人提出了基于級聯Vnet-S[22]的單一器官分割法,在V-net 的基礎上減少V-net 的編解碼器的卷積單元,減小卷積核的大小,在跳連中加入Dropout 緩解過擬合,以減少3D 卷積帶來內存占用問題,提升運算速度.
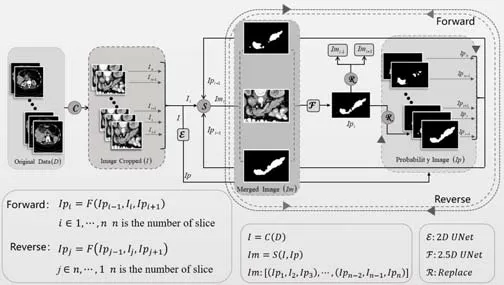
Fig.16 PBR-Unet structure diagram[21]圖16 PBR-Unet 結構圖[21]
特征融合其實更多意義上講的是網絡的上下文特征的融合、不同模態特征的融合.上下文特征的融合可以從編解碼器中加入新的模塊DAC 和RMP 幫助融合信息,如CE-Net[73];也可以在跳連階段增加編解碼器信息的流動,如MultiResUNet[19]、Unet++[23]或者去掉跳連、增加信息聚合的DFA-Net[24];或者外接特征金字塔從不同分辨率角度保證分割的準確性,如MFP-Unet[25].對于不同模態的融合,可將編碼器分別提取各模態之間的信息再進行融合,如深度級聯腦腫瘤分割方法[26]、Dense Multi-path U-Net[27]、IVD-Net[28].
2.4.1 上下文特征的融合
(1) 編解碼器加入新的模塊
為了獲取更高層次的信息,并保留2D 醫學影像分割中的醫學信息,Gu 等人在編解碼器的基礎上加入上下文提取模塊,從而構成新的網絡CE-Net[73],整體框架如圖17 所示.
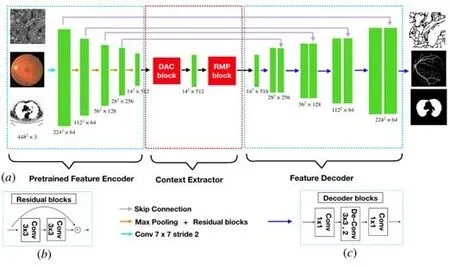
Fig.17 CE-Unet network structure diagram[73]圖17 CE-Unet 網絡結構圖[73]
2.4 針對特征融合的改進方法
上下文提取模塊主要包括DAC(dense atrous convolution module)模塊和RMP 模塊(residual multi-kernel pooling).作者受inception-ResNet-V2[74]模塊和擴張卷積啟發提出了DAC 模塊,以編碼高層級的語義特征圖.RMP 模塊采用殘差多核池化方法,主要依靠多核有效視場來檢測不同大小的目標,解決醫學影像中物體尺寸的巨大變化.
(2) 在跳連處改進
U-Net 的跳連結構主要是融合上下文的語義特征,以更好地分割病灶。但是簡單的級聯使得高層級和低層級的語義信息融合容易造成重要語意丟失,因而針對這一問題,相關工作提出了多種改進特征融合的方法.Nabil等人在MultiResUNet[19]中提出:由一系列帶有殘差連接的卷積層構成的Res path 取代U-Net 的級聯,使低級特征經過進一步處理再與高級特征級聯,以消除編碼器的低級特征和解碼器的高級特征融合時造成的語義差異(如圖18 所示).Zhou 等人從另一方面對跳連進行改進,提出帶有深度監控的嵌套的密集跳連路徑的Unet++[23],結構如圖19 所示.
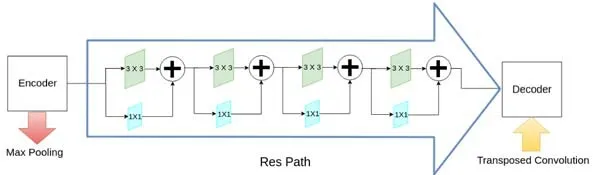
Fig.18 Skip connection of MultiResUnet[19]圖18 MultiResUnet 的跳連[19]
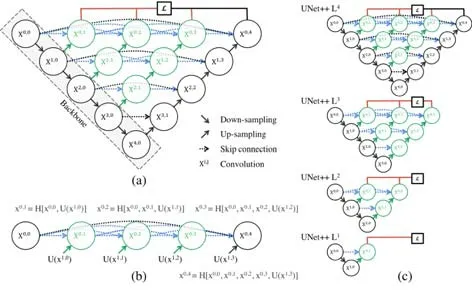
Fig.19 UNet++network structure diagram[23]圖19 UNet++的網絡結構圖[23]
Jin 等人在跳連處加入attention 機制,提出了三維混合殘差注意感知分割網絡RA-UNet[29],用于精確提取肝臟興趣體積(VOI),并從肝臟VOI 中分割腫瘤.該網絡在3D U-net 的基礎上,除了第1 層和最后一層外,其他都由殘差結構堆疊,以實現增加深度而不會產生梯度爆炸,并在跳連處加入Wang 等人提出的殘差注意力模型[75],分為用于處理原始特征的主干分支、用于增強特征抑制噪聲的軟掩膜分支.
楊兵等人所提出的深度特征聚合網絡DFA-Net[24](如圖20 所示)直接去掉U-Net 跳連并稱其為基礎層,加入中間層、聚合層以及特征聚合模塊FAM,幫助更好地融合上下文信息.Nikhil 等人提出的U-Det[30]將U-Net的跳連替換為Bi-FPN[76],如圖21 所示.其擁有自頂向下和自底向上的路徑的同時,每個節點為不同的輸入加入不同權重,以強調不同輸入的重要性.而Li 所提出的DPSN[77]在跳連處采用特征金子塔,高度提取抽象編碼器的特征之后,再通過跳連和解碼器進行級聯,將高層語義特征和低層語義特征更好的融合.
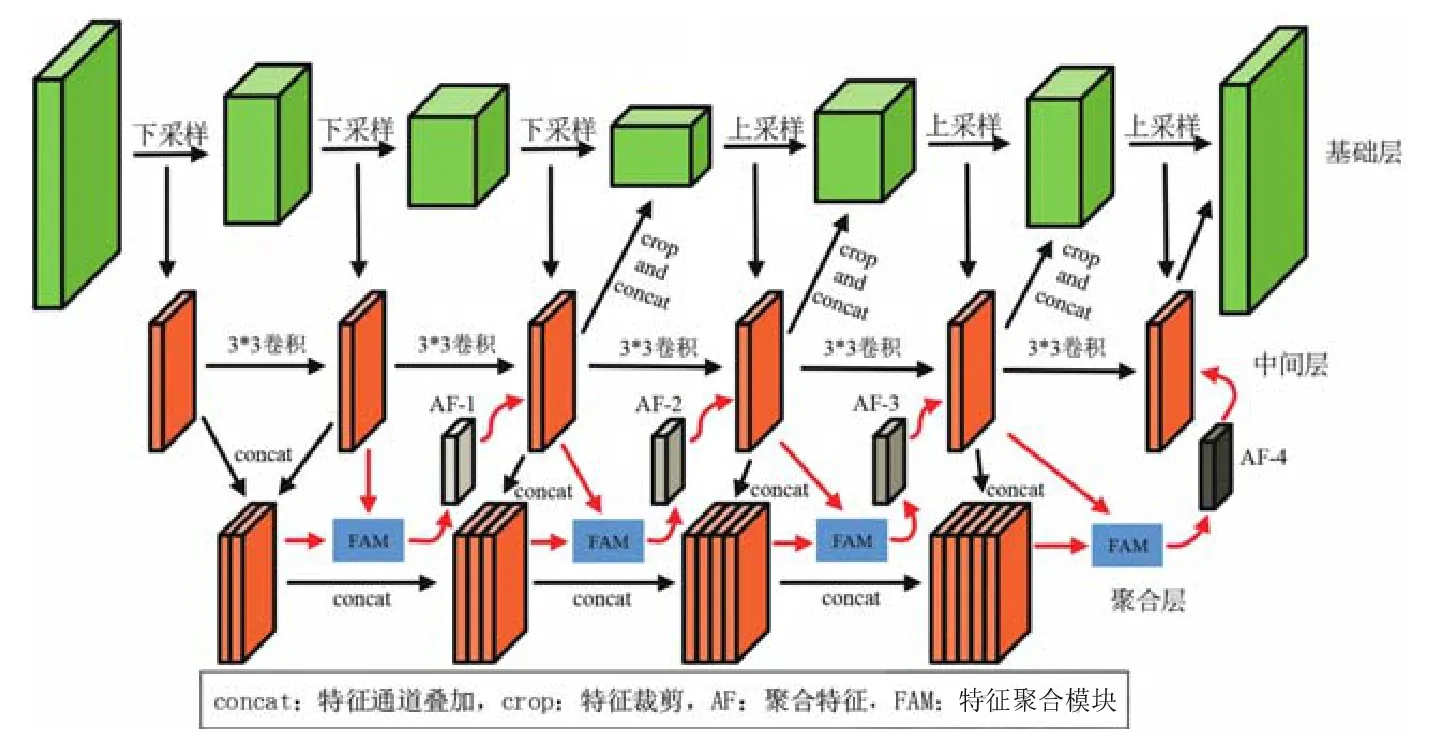
Fig.20 DFA-Net network structure diagram[24]圖20 DFA-Net 網絡結構圖[24]
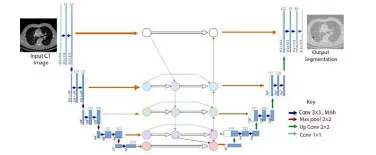
Fig.21 U-Det network structure diagram[30]圖21 U-Det 網絡結構圖[30]
(3) 外接特征金字塔
Moradi 等人提出了MFP-Unet[25],該網絡在U-Net 基礎上外接特征金字塔網絡FPN[78],從擴展路徑的各個層次提取特征,最后將提取的特征串聯,形成64 通道的最終特征映射,并傳給用于特征分類濾波器中,以提升語義對分割的貢獻.
2.4.2 不同模態的特征融合
傳統的U-Net 網絡對于多模態圖像輸入,采用先混合處理再輸入的方式,這樣操作容易丟失不同模態的部分信息.Lachinov 等人[26]為解決這一問題,提出一種深度級聯腦腫瘤分割方法,主要是將編碼器并行分出幾個路徑分別學習不同模態的特征表示,在跳連和bottleneck 處采用像素最大化操作再與解碼器級聯,網絡結構如圖22 所示.
而Dolz 等人提出的Dense Multi-path U-Net[27]在編碼器多路徑的基礎上加入Dense Net 的思想,以解決缺血性中風病灶的位置和形狀的高度變異性.此方法首先將輸入端圖像混合的方式,變成在不同路徑中對每個模式進行處理,以更好地利用其獨特的信息,如圖23 所示;然后在不同模態之間建立稠密連接,改善數據流,減輕梯度消失;并且擴展了非對稱inception 卷積塊,代替最大池化操作,其多擴張率的卷積操作,從不同尺度上提取特征,更好的捕獲上下文信息.同年,Jose Dolz 等人在Dense Multi-path U-Net[27]的基礎上提升編碼器的多路徑稠密性,提出了IVD-Unet[28],主要對椎間盤(IVD)圖像進行分割.
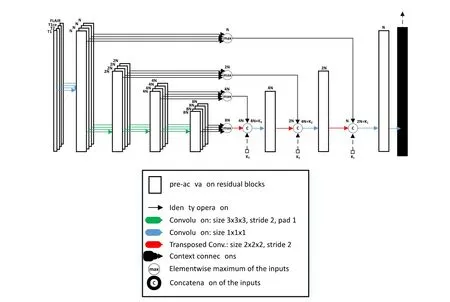
Fig.22 Gliomas segmentation and cascaded U-Net network structure diagram[26]圖22 Glioma 分割與級聯U-Net 網絡結構圖[26]
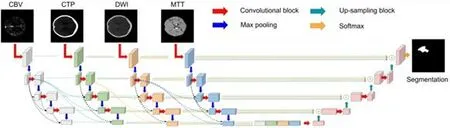
Fig.23 Dense Multi-path U-Net network structure diagram[27]圖23 Dense Multi-path U-Net 網絡結構圖[27]
2.5 針對提高泛化能力的改進方法
在臨床實踐中,醫學影像是從不同的供應商處獲取,從特定的源域訓練的U-Net 再傳輸到不同的目標域時,性能會急劇下降.泛化能力是指網絡可以混合訓練來自不同提供商的圖像,具體方法有兩種:從內部結構提出適應不同提供商圖像的域適配器,如3D U2-net[35]采用在編解碼器單元內采用Adapter 找到合適網絡訓練的卷積,從而適應不同提供商提供的圖像;從外部接入Cycle-GAN 網絡,如Yan 等人提出的Unet-GAN[36],包括一個用于適應供應商的非配對生成對抗網絡(CycleGAN)[79],一個用于對象分割的LV-Unet.在圖24 中,LV-Unet 是由數據集S訓練的滿足LV(左心房)分割的分割網絡;CycleGAN 是一個為未配對的圖像到圖像轉換而設計的既定架構,包括兩個生成器GS和GT,代表源域和目標域;兩個辨別器DS和DT,辨別是原始圖像還是轉換圖像.
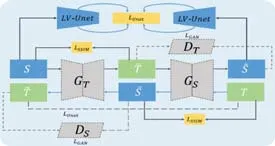
Fig.24 U-netGAN network structure diagram[36]圖24 U-netGAN 網絡結構圖[36]
2.6 針對小樣本訓練數據集的改進
醫學影像由于涉及隱私問題和標注成本高的問題,其數據集數量極少.針對小樣本訓練數據集的問題,一般從重復的網絡結構和數據集標簽兩個方面進行.
· 重復網絡結構可以在bottleneck 重復使用SRU 門控單元[31],也可以重復使用整個U-Net 如Bridged U-net[32].
· 從數據本身標簽入手,可以結合貝葉斯訓練給定數據標簽再進行網絡訓練,提升分割準確性;或者將一幅圖像僅使用一個單一全局標簽,以降低對數據量的要求.
2.6.1 重復網絡結構
Wang 等人[31]提出在U-Net 的瓶頸處加入重復單元結構:雙門控遞歸單元(DRU)或單門控遞歸單元(SRU),可以在數據集和計算能力有限的情況下進行訓練.DRU 在GRU[80]上進行改進,能有效地細化迭代分割,但浪費內存,因而提出簡化成單門控的SRU 代替DRU,其精度并未變化.
Chen 等人提出了Bridged U-net[32],采用U-Net 橋連接的方法,在多個層次上充分利用不同的特征,加速神經網絡的收斂.網絡結構如圖25 所示.兩個U-Net 之間的橋連接采用級聯,U-Net 的跳連采用加法,可以達到網絡的最好表現形式.激活函數采用ELU 和ReLU 相結合,解決了單純使用ELU 的隨著網絡不斷深入的飽和問題.
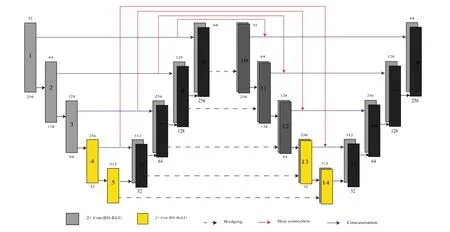
Fig.25 Bridged U-net network structure diagram[32]圖25 Bridged U-net 的網絡結構圖[32]
2.6.2 計算數據標簽
U2-NET[33]提出一個具有認知不確定性反饋的BAYESIAN U-NET 模型,用于病理OCT 掃描中光感受器層的分割.通過貝葉斯對于給定數據和標簽進行后驗概率計算,再通過U-Net 進行訓練.
Florian Dubost 提出了GP-Unet[34],用弱標簽來檢測病灶的卷積神經網絡,也就是每幅圖像只需要一個單一的全局標簽“病變計數”就可以訓練,網絡結構如圖26 所示.GP-Unet 是一個具有完全卷積結構的回歸網絡,結合一個全局池層,將3D 輸出聚合成一個指示病變數量的標量.在測試時,GP-Unet 首先運行網絡來估計病變的數量,再移除全局池層來計算輸入圖像大小的定位圖.
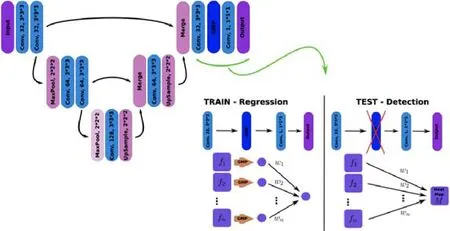
Fig.26 GP-Unet network structure diagram[34]圖26 GP-Unet 網絡結構圖[34]
3 基于U-Net 面向結構模塊的改進
本節對于U-Net 面向結構模塊的改進作出總結,現有工作主要在編解碼器、bottleneck 和損失函數改進、數據流增強以及自動搜索結構幾方面對U-Net 提出各種改進型研究.這些工作對網絡結構進行了不同的變體,或是針對不同的問題加入了不同的結構.
3.1 針對編碼器解碼器結構的改進方法
編、解碼器的改進可分為3 部分:一是卷積操作的改進,如加入協調引導卷積、長短殘差結構;二是編解碼器單元的改進,如可以可形變卷積塊、循環殘差卷積和概率模塊;三是上、下采樣的改進,如可以采用長短殘差結構和最近鄰插值的方法.
3.1.1 卷積操作改進
肺葉的鑒別和診斷對疾病的診斷和治療具有重要意義,少數肺病在肺葉有區域性的病變,準確分割肺葉極為重要,Wang 等人[37]提出一種基于利用協調引導卷積的深度神經網絡,從胸部CT 圖像中自動分割肺葉的方法.其首先采用自動肺分割方法提取CT 圖像中的肺面積,然后利用V-net 對肺葉進行分割.協調卷積部分結構圖如圖27 所示.
Fig.27 Coordination-guided convolution proposed by Wang,et al.[37]圖27 Wang 等人提出的協調卷積[37]
為了減少不同肺葉的錯誤分類,文中采用協調引導卷積(CoordConvs)[81]來生成肺葉位置信息的附加特征圖.CoordConv 是對經典卷積層的簡單擴展,通過添加額外的坐標通道來集成位置信息.
對于模態的急性亞急性腦中風病灶MRI 圖像分割,Albert 等人[38]提出在采樣過程中平衡患者和健康的人的MRI 圖像采樣,并且在U-Net 的網絡結構中加入長短殘差結構代替卷積操作和下采樣操作在保證精度的同時減少參數,改進結構如圖28 所示.
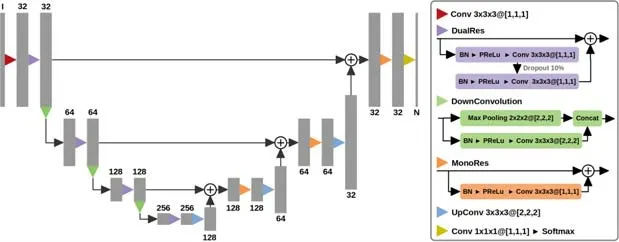
Fig.28 Network structure diagram proposed by Albert,et al.[38]圖28 Albert 等人提出的網絡結構圖[38]
3.1.2 編、解碼器單元改進
Jin 等人提出DUNet[39],其是在U-Net 的框架的基礎上,用可變形卷積塊[82]作為編碼器、解碼器的每一個單元.可變形卷積塊通過學習局部、密集和自適應的感受野來模擬不同形狀和尺度的視網膜血管,以達到準確分割.具體是在標準卷積使用的網格采樣位置上添加偏移量,而偏移量是從附加卷積層生成的先前特征映射中學習的.因此,變形能夠適應不同的尺度、形狀、方向等.圖29 給出可變形卷積與普通卷積方法差異的示意圖.
Fig.29 Comparison of deformable convolution and normal convolution in DUNet[39]圖29 DUNet 中可變形卷積和正常卷積對比[39]
蔣等人提出的I-Unet[40]在U-Net 的基礎上改進編解碼器單元,編碼器采用由擴張卷積、inception 和RCL層組成的Conv-Block,解碼器采用反卷積、RCL 層組成的Deconv-Block,通過擴大感受野進行多尺度特征融合.
何承恩等人基于3D-Unet 提出了3D-HDC-Unet[41],在編碼器的每個單元中加入混合膨脹卷積殘差塊,以不斷變化的膨脹率改變棋盤效應[83]給分割帶來的負面影響.
Alom 等人提出了R2U-Net[42],該方法將殘差連接和循環卷積結合起來,用于替換U-Net 中原來的子模塊,其改進結構如圖30 所示,圖中環形箭頭表示循環連接.圖31 展示了幾種不同的子模塊內部結構圖.該方法保證網絡深度的同時,減輕梯度消失的影響,在提取低級特征有顯著效果,多應用于視網膜血管分割.
Kohl 等人提出HPU-net[43],一個結合U-Net 和條件變分自動編碼器(cVAE)的能夠考慮多尺度變化的層次概率分割網絡,網絡結構如圖32 所示.該網絡分為采樣過程和訓練過程,在采樣過程中,解碼器額外對延遲的空間網格采樣.在訓練過程中,采用條件概率分布對網絡進行訓練.
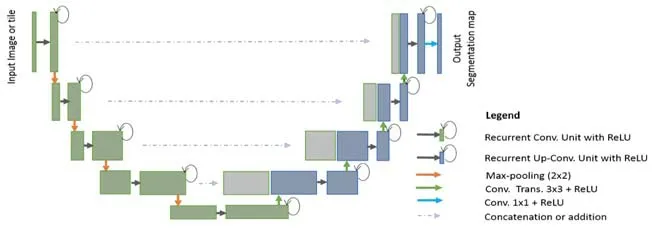
Fig.30 R2U-Net network structure diagram[68]圖30 R2U-Net 網絡結構圖[68]
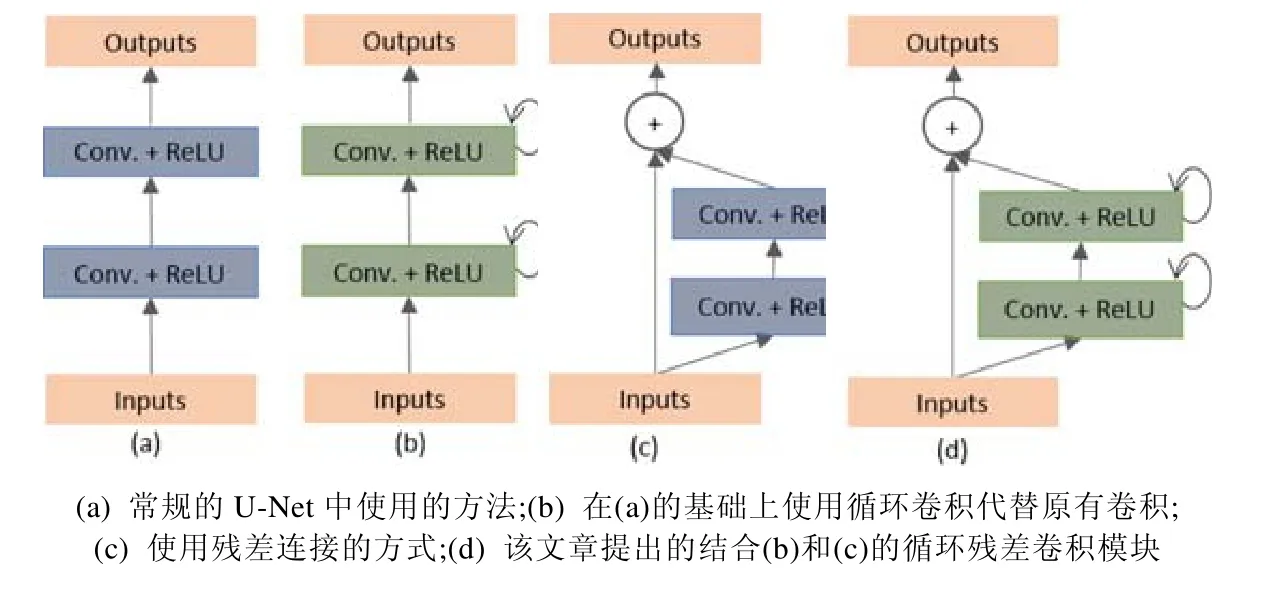
Fig.31 Structure diagram of Recurrent convolution in R2U-Net[42]圖31 R2U-Net 中循環卷積結構圖[42]
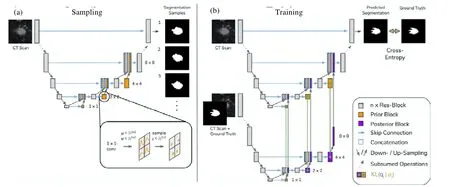
Fig.32 HPU-net network structure diagram[43]圖32 HPU-net 網絡結構圖[43]
3.1.3 上、下采樣改進
在微創手術中,準確地追蹤到手術器械的位置是十分重要的.針對內窺鏡圖像中的分割和識別外科器械問題,Hasan 等人[44]為緩解轉置卷積導致“不均勻重疊”也就是棋盤格形狀的偽影問題,提出了U-NetPlus 網絡結構,將VGG-11 和VGG-16[84]作為編碼器這種預先訓練的編碼器[85],通過規避與目標數據相關聯的優化挑戰,加快了收斂速度[86].
Wang 等人提出了Non-local U-Nets[45],在U-Net 的基礎上,對于輸入輸出模塊采用殘差結構,對于上下采樣采用外部嵌套殘差結構的全局聚合模塊,從而減弱單一卷積操作所帶來的信息丟失問題.
3.2 基于損失函數的改進方法
神經網絡訓練過程中,使用損失函數計算每次迭代的結果與真實值之間的差距,從而指導下一步訓練向正確的方向進行.損失函數改進主要解決的是類不平衡的問題,主要是從函數自身和兩個損失函數相結合兩個方面進行改進.
3.2.1 函數自身改進
Dice loss 函數的一個局限性在于FP與FN的檢測權重相等,這將導致分割圖有較高的準確率和較低的召回率.像在皮膚病變者眾數據極不平衡,感興趣區域極小,FN需要比FP高很多才能提高召回率.V-net[2]中提出了一個基于dice coefficient 的損失函數,也就是對分割求偏導數,從而不需要為不同類別分配權重,就可以建立前景、背景平衡.
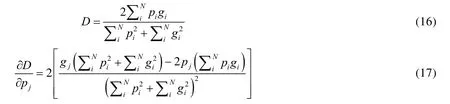
對于Dice loss 的預測接近真實情況時效果不佳引起震蕩的問題,Chen WL 等人提出一個新的損失函數Cos-Dice[32]損失函數,來加速學習進程.

3.2.2 兩個函數的混合
針對醫學數據類不平衡的問題,Abraham等人基于Tversky index 提出了一個廣義的損失函數Focal Tversky Loss(FTL)[47].與Dice loss 函數相比,這個函數在訓練較小結構可以更好地權衡準確率與召回率之間的關系(其中,c為類別,TIc為Tversky index).

而AnatomyNet[46]和3D-HDC-Unet[41]采用Dice 系數和Focal loss 相結合的方式解決這一問題.

實驗結果表明,λ=0.5 時效果最好.
RAUNet[7]提出的Cross Entropy Log Dice(CEL-Dice)結合了交叉熵的穩定性和類不平衡不影響Dice loss的特性,因此,它有比Dice loss 更好的穩定性,比交叉熵更好地解決類不平衡的問題(H為交叉熵,D為Dice loss).

Zhong 等人[48]提出了交叉熵和Dice loss 損失組合新的形式:

3.3 針對增加數據流路徑的改進方法
針對于數據流的改進主要是從兩個方面:一是采用DenseNet 的思想,增加網絡中不同模塊之間的連接;二是將U-Net 網絡串行使用兩次,也就是橋連接,從而達到信息成倍數流通的目的.
U-Net 的各種變體都包含編碼器和解碼器,但是對于數據流路徑數量是有限的,Zhang 等人提出的MDUNet[51]將DenseNet 的思想應用于編、解碼器、跳連中,直接融合高層和低層相鄰的不同比例尺的特征映射,增強當前層的特征傳播.這在很大程度上提高了信息流的編解碼能力(如圖33 所示).
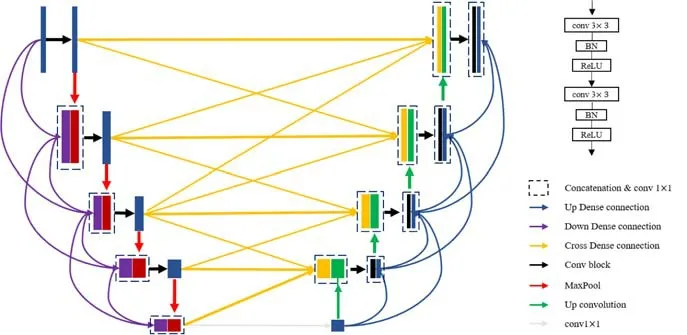
Fig.33 MDU-Net network structure diagram[51]圖33 MDU-Net 的網絡結構圖[51]
Zhuang 等人提出的LadderNet[49],其結構類似于橋連接,與之最大區別在于兩點:其一,LadderNet 用加法取代U-Net 中跳連采用的級聯,兩個并行U-Net 對應層也采用加法;其二,LadderNet 采用了一個新的共享權重殘差塊(如圖34 所示),解決了多編碼器解碼器分支來的參數增多、訓練難度增加的問題.這個共享權重殘差塊由3個部分組成:跳連、遞歸卷積以及dropout 正則化.其在同一塊中的兩個卷積層共享參數可以看作一個遞歸層,兩個卷積層之間加入dropout 避免過擬合.
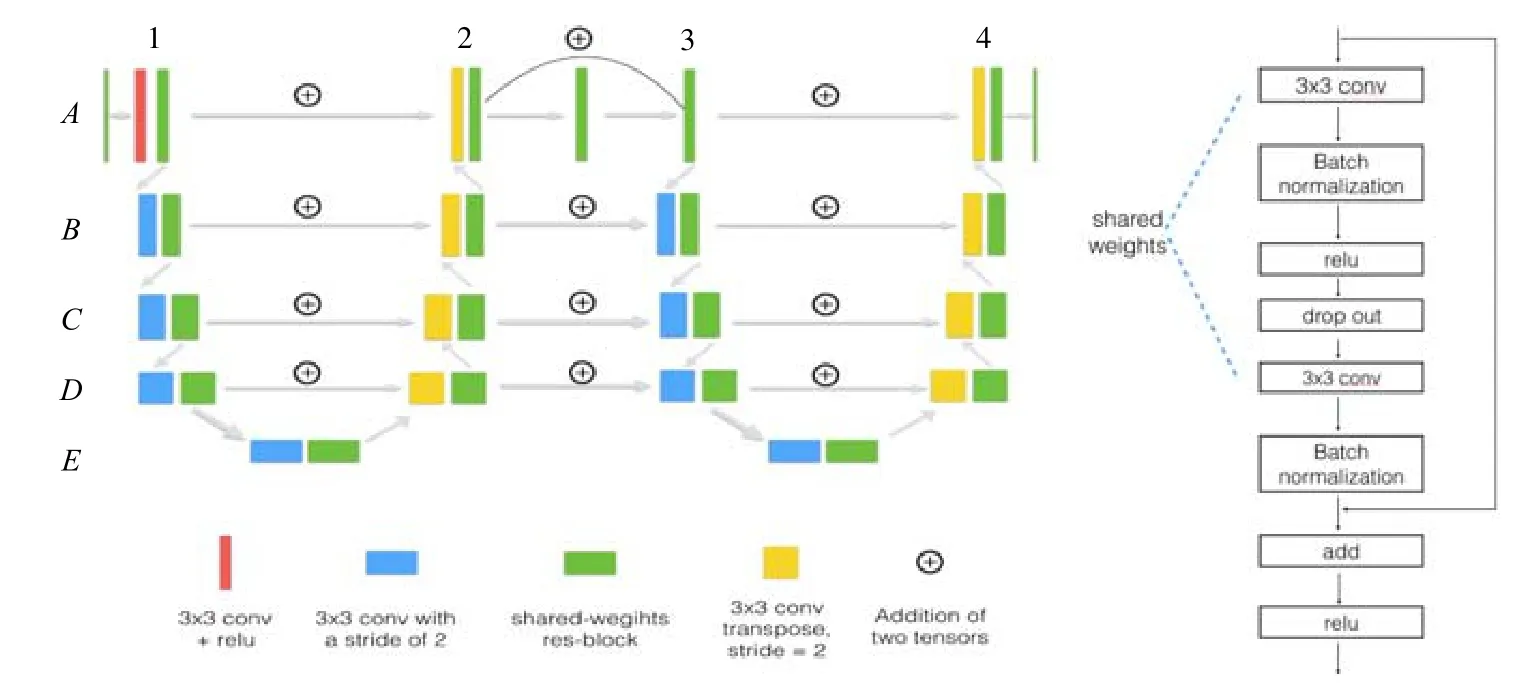
Fig.34 LadderNet network structure diagram[49]圖34 LadderNet 網絡結構圖[49]
3.4 基于自動搜索最優網絡結構的改進方法
Ken 等人借鑒了網絡結構搜索(NAS),提出了SegNAS3D[52]三維圖像分割網絡結構搜索,以解決三維圖像分割中大量手動調參和網絡體系結構優化的問題,如圖 35 所示.文中提出了在每一層加入一個新的塊結構Mg-Blk,該塊結構是由可學習塊Block[87]、空間dropout 和可選擇殘差連接組成.文中最重要的是這個可學習塊block 的學習訓練,文中將一個塊結構表示成一個有向無環圖,如圖36 所示,每一個節點代表一個特征圖,每一條邊代表一次操作.矩陣的行和列為輸入節點和輸出節點,矩陣中的數值為擴張卷積的擴張率,通過學習節點數以及擴張率來訓練整個網絡的準確性.
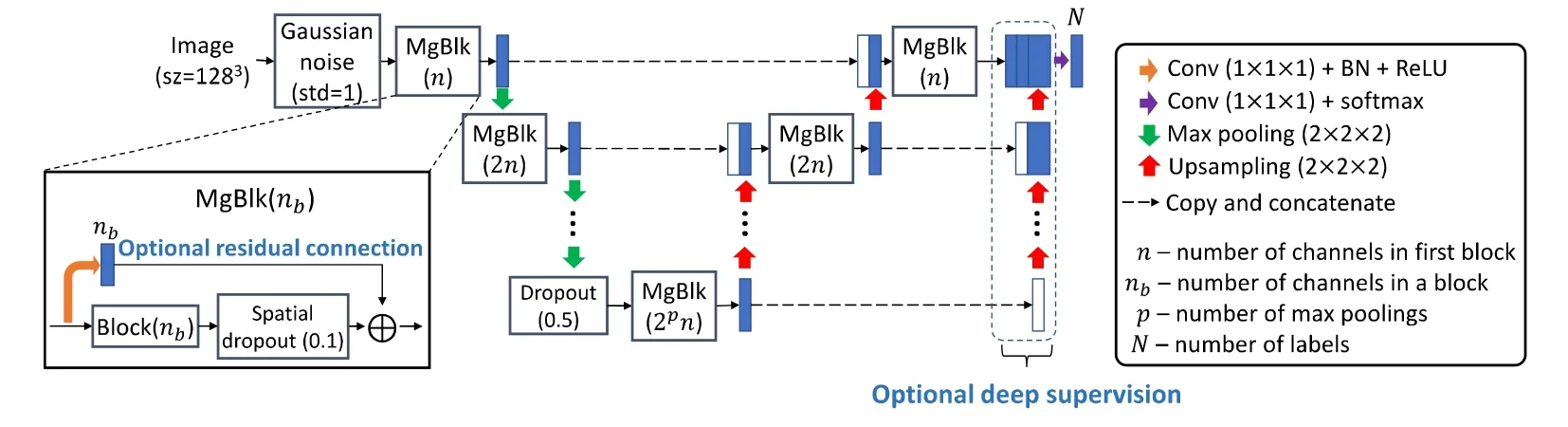
Fig.35 SegNAS3D network structure diagram[52]圖35 SegNAS3D 網絡結構圖[52]
3.5 基于瓶頸(bottleneck)的改進方法
Bottleneck 是U 型網絡收縮路徑和擴張路徑中間的部分,其主要接受了所有來自編碼器提取的特征信息,并將分割好的的圖像通過解碼器恢復到原有分辨率,因而其重要性可想而知.一般對于bottleneck 的改進,多采用attention 機制,以更好地關注分割細節.Wang 等人提出的鞏膜分割模型ScleraSegNet[9]在bottleneck 中采用4種attention 機制,將通道注意力和空間注意力相結合,以更好地分割.而Wang 等人[31]受GRU 的啟發,在bottleneck 處重復使用SRU 模型,在保證分割精度的同時,又減輕參數過多帶來的影響.
而Li 等人提出了新的改進方法BSU-Net[50],其先將U-Net 的編解碼器以及bottleneck 進行改進,加入了Inception、Dense 模塊和擴張卷積,并稱該網絡為Base U-Net.然后將Base U-Net 按照是否去掉跳連分為Encoding U-Net 和Segmentation U-Net,再將兩者的bottleneck 部分連接.大多數的網絡金隊輸入輸出有監督,而BSU-Net 通過將U-Net 改進,稱自動編碼器,彌補了bottleneck 的監督空白,并且可以進一步提取bottleneck 處的信息,對于圖像進行更好的分割.網絡結構如圖37 所示.
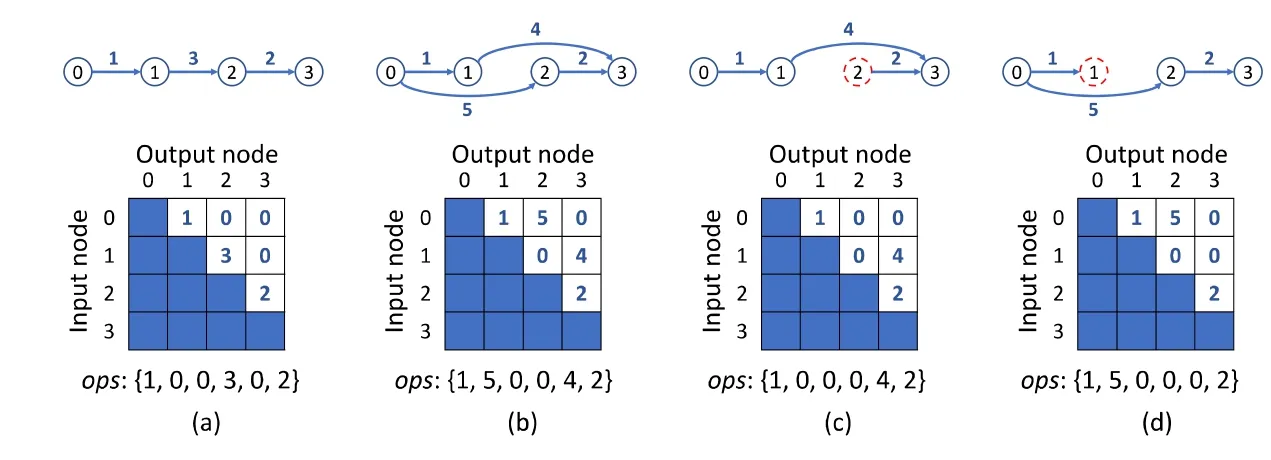
Fig.36 SegNAS3D expansion coefficient selection[52]圖36 SegNAS3D 擴張系數選擇[52]
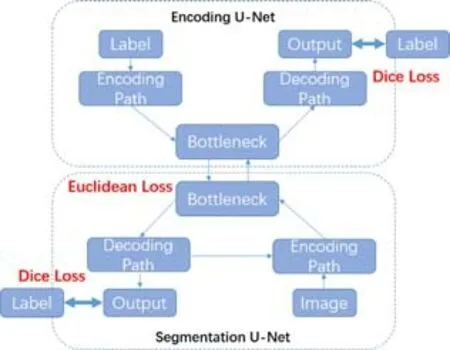
Fig.37 BS U-Net network structure diagram[50]圖37 BS U-Net 網絡結構圖[50]
4 U-Net 結構改進中常用結構模塊
由于圖像分割任務的目標不同,其網絡結構也不盡相同.通過對解決問題的分類,我們總結歸納出如下適用于不同問題的網絡結構模塊,從而幫助大家針對不同問題,快速找到適用的模塊以組成網絡結構.
4.1 殘差結構
一般來說,增加神經網絡的寬度和深度可以提高網絡的表達性能.但如果簡單地增加網絡的層數,就會面對梯度消失或是梯度爆炸的問題.何凱明等人為此提出了殘差網絡[88],將每兩層網絡中增加一個跳連,以保證增加層數后不會削弱網絡的表達性能.殘差結構如圖38 所示.在V-net[2]、MultiResUNet[19]、RDA-Unet[12]等結構中都有采用,可以放置于編碼解碼器單元,也可在下采樣中使用.
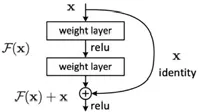
Fig.38 Residual structure[88]圖38 殘差結構[88]
4.2 Attention模塊
Attention 的主要思想是強化特征,在醫學影像里常用于分割細節較多的血管、肺葉,其內部結構不固定,可根據強調的內容自行設計,例如強調特征圖稱為Spatial Attention、強調通道為Channel Attention.Attention U-net[5]、CASU[6]、RAUNet[7]、CIA-Net[8]都是在解碼器中加入attention 模塊,Attention U-net 的AGs 是加入門控信號以消除噪聲,CASU 的AGs 采用Up-link 以聚焦特征,IAM 是將核、輪廓兩個解碼器分支的信息聚合.這三者都是空間信息方面的特征聚焦,而AAM 主要是通過強調目標通道從而聚焦特征;ScleraSegNet[9]是在瓶頸處加入CAM 和SAM 塊,從空間和通道兩個方面進行特征的聚焦.表1 給出了不同的Attention 模塊的總結.

Table 1 Network model with attention mechanism表1 加入attention 機制的網絡模型
4.3 SE模塊
通道的壓縮和激勵,通過找到特征較好的通道,強調這一通道,壓縮不相關的通道,以減少參數,強化分割精度.無論AnatomyNet[46],還是Roy 等人[4]提出的通道和空間擠壓激勵,都是運用了這一思想.SKNet[89]在SENet的基礎上結合了Merge-and-RunMappings 以及attention on inception block,用多尺度特征匯總信息,來按照通道指導側重使用哪個核的表征,從而減少了參數增加路徑和動態選擇.因而在之后的圖像分割中,可以考慮采用SKNet 所提出的方法代替SE 結構.
4.4 DenseNet模塊
DenseNet 主要是將每一層的網絡復制到下一層的全連接結構,增強數據流動的同時減少計算量.醫學影像分割中,常將Dense 的應用于編碼器與解碼器的全連接、編解碼器的單元,從而達到減少參數提升計算精度.H-DenseUNet[14]和FD-UNet[16]都是在編解碼器的單元中引用Dense 模塊,不同在于:前者是將2D 和3D Dense的模塊相結合,用2D 網絡指導3D 網絡分割;而后者僅僅在編解碼器每個單元中使用Dense 模塊以減少參數.Dense Multi-path U-Net[27]和IVD-Unet[28]的網路結構大部分相同,后者在前者的基礎上將編碼器的稠密性提升到了一個新的高度,將不同模態之間的信息更好地交互.MDU-Net[51]將稠密的思想應用在編碼器的每個單元之間、解碼器的每個單元之間,并且跳連也不再單單是編解碼器對應層的連接,采用全連接的方式將高級信息和低級信息充分融合利用,表2 給出了稠密模塊的總結.

Table 2 Application of DenseNet thought in network表2 應用DenseNet 思想的網絡
4.5 Inception模塊
在醫學影像中,病灶所占區域在不同的圖像中變化極大,因而卷積核的選擇非常重要.然而較小的卷積核適合局部信息,較大的內核更適合捕獲全局分布的信息.Inception 將擴張率不同、大小不同的卷積都囊括在內,通過不同尺度提取特征,從而達到精確提取特征的目的,例如CE-Net[73]中的DAC 模塊就是為了更好地提取特征而設計.但由于 Inception 中包含不同大小的卷積核,大卷積核相比于小卷積核計算量要多很多,因而MultiResUNet[19]選擇用3×3 代替5×5,7×7 的卷積核,而Dense Multi-path U-Net[27]和IVD-Unet[28]采用非對稱inception 模塊,也就是將n×n的卷積拆解成n×1,1×n的卷積,從而降低計算量.
4.6 CycleGAN模塊
生成對抗性網絡(GAN)將圖像從一個領域轉換成另外一領域,例如將斑馬轉換成馬.在醫學影像中,由于不同源域的圖像放在一起訓練將導致極大的問題,通過將圖像先經過CycleGAN 再進行訓練,從而達到更好的訓練效果,例如Unet-GAN(如圖39 所示)[36].
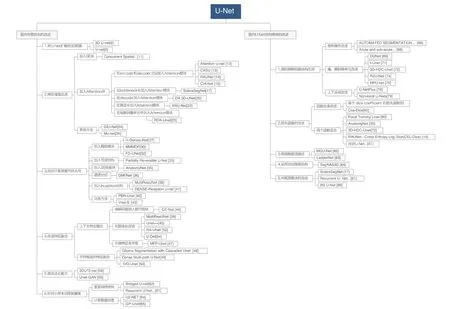
Fig.39 U-net extended structure technology development flow chart圖39 U-Net 擴展結構技術發展流程圖
5 總結與建議
對于上文介紹的基于U-Net 擴展結構的技術脈絡總結如圖39 所示,按照面向性能優化和面向結構改進總結成表3 和表4.主要從網絡維度、改進結構、亮點、數據集、評價參數這5 個方面進行總結.
1)網絡的維度主要是2D、3D、2D 和3D 的混合:2D 網絡為基本網絡;3D 網絡因為其具有2D 網絡沒有的上下文信息;2D 和3D 網絡的融合以2D 網絡的快速分割結果來指導3D 模型的學習并實施分割,主要在減少內存、提升計算速度中使用.
2)對于改進的結構,包括編解碼器、bottleneck、跳連、卷積操作、上下采樣、損失函數、外接其他結構以及數據標簽.編解碼器的改進包括編解碼器單元的改進、上下采樣、卷積操作的改進,在大部分問題中都有應用,而像跳連、數據標簽這類改進主要是為解決特征融合、小樣本數據集問題.
3)在數據集方面,相關方法采用了幾乎各不相同的數據集,主要包括腦腫瘤(BraTS)、視網膜血管、肝臟、胰臟、腰間盤、乳腺癌、前列腺等.由于各種方法采用的數據集不盡相同,本文列舉數據集以提供一個數據集名稱索引.由于不同方法評價所采用的數據集不盡相同,所以不同方法難以進行橫向比較.
4)從指標函數方面,可見主要評價指標是Dice scores,IOU 次之.表中總結了各個方法采取的評價指標以及指標數值,幫助大家在選擇網絡模型時有一個參考和比較.
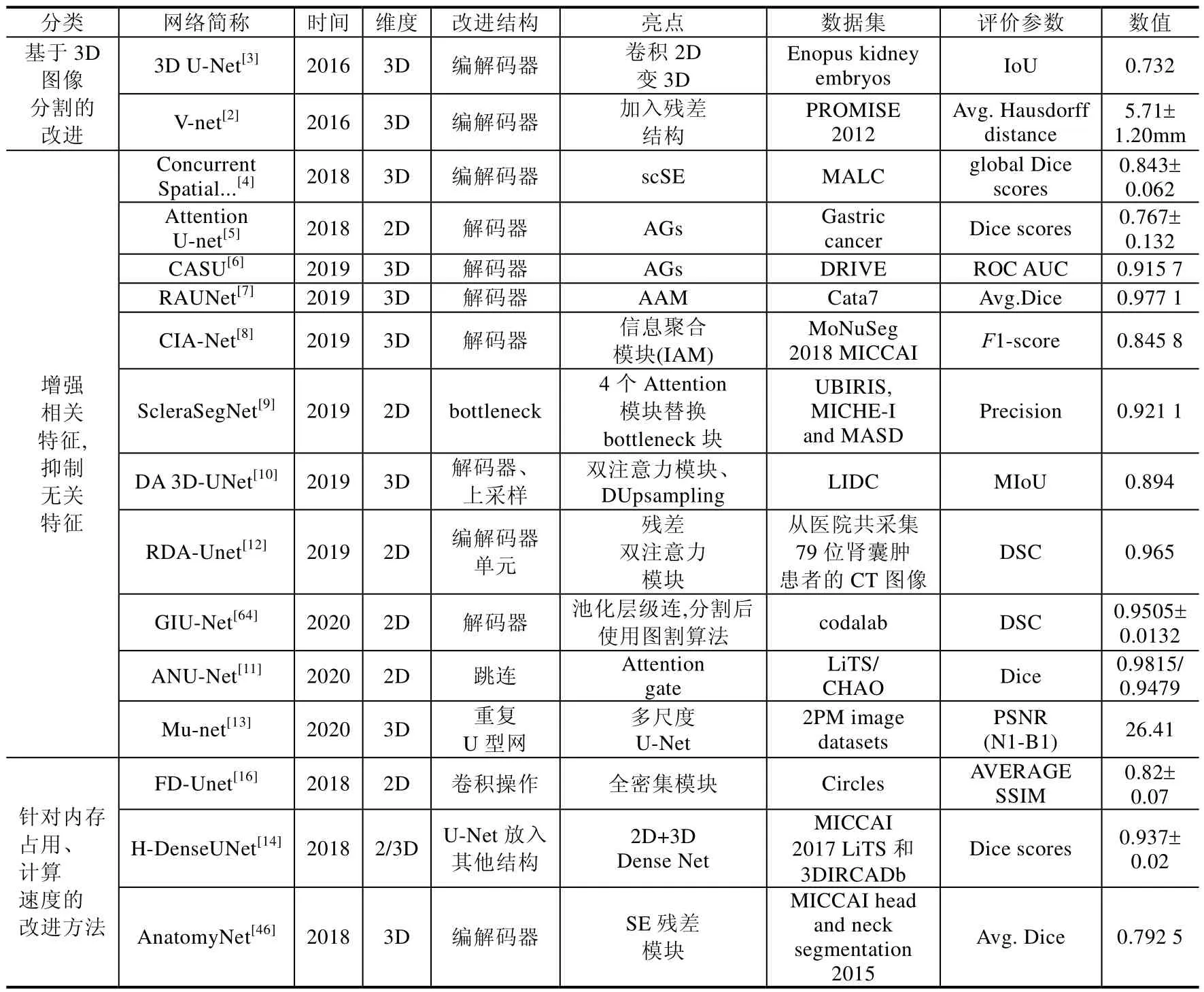
Table 3 Based on U-Net,it classifies the performance optimization and compared from the aspects of improved structure and highlights表3 基于U-Net 面向性能優化進行分類,并從改進結構、亮點等方向進行對比
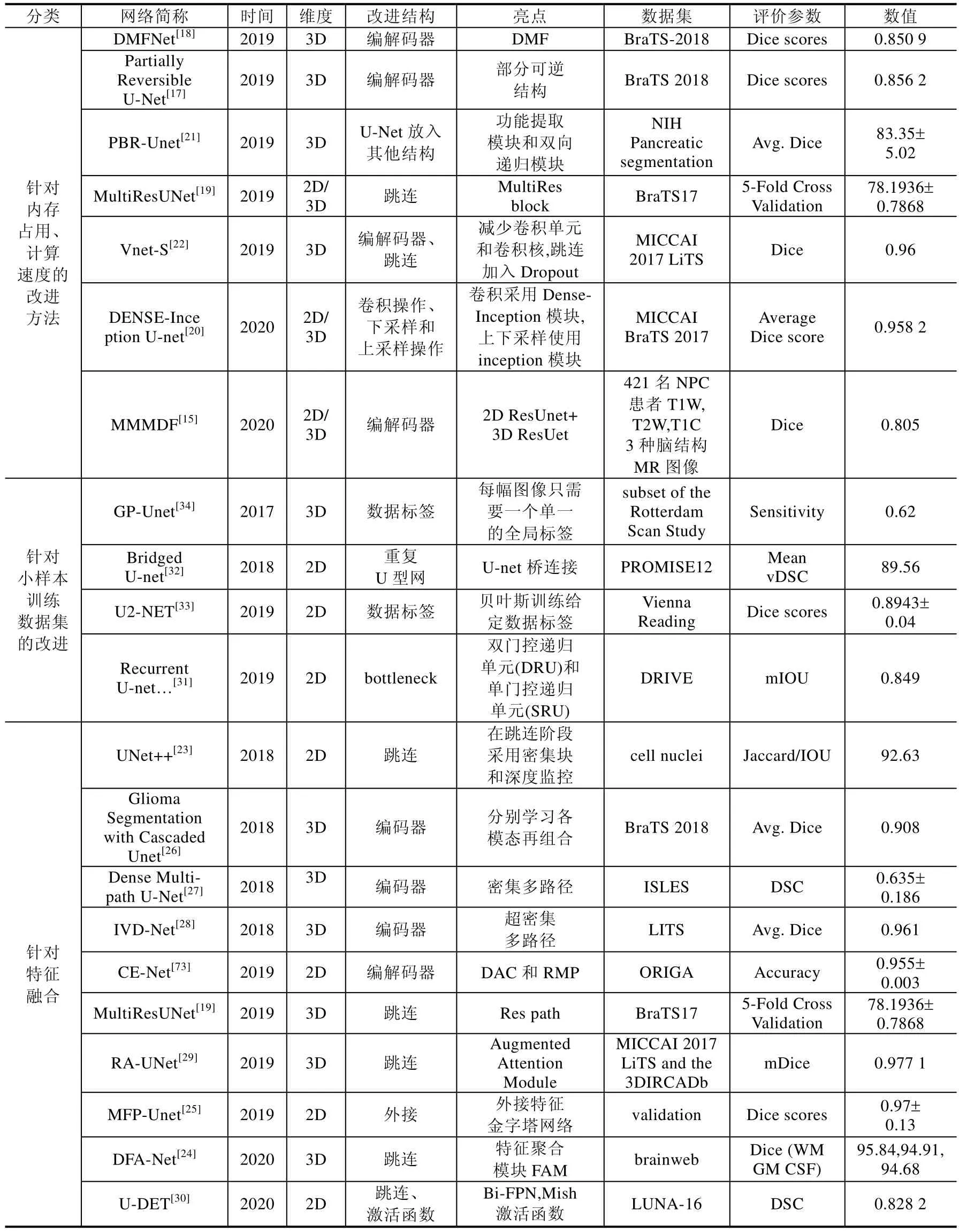
Table 3 Based on U-Net,it classifies the performance optimization and compared from the aspects of improved structure and highlights (Continued 1)表3 基于U-Net 面向性能優化進行分類,并從改進結構、亮點等方向進行對比(續1)

Table 3 Based on U-Net,it classifies the performance optimization and compared from the aspects of improved structure and highlights (Continued 2)表3 基于U-Net 面向性能優化進行分類,并從改進結構、亮點等方向進行對比(續2)
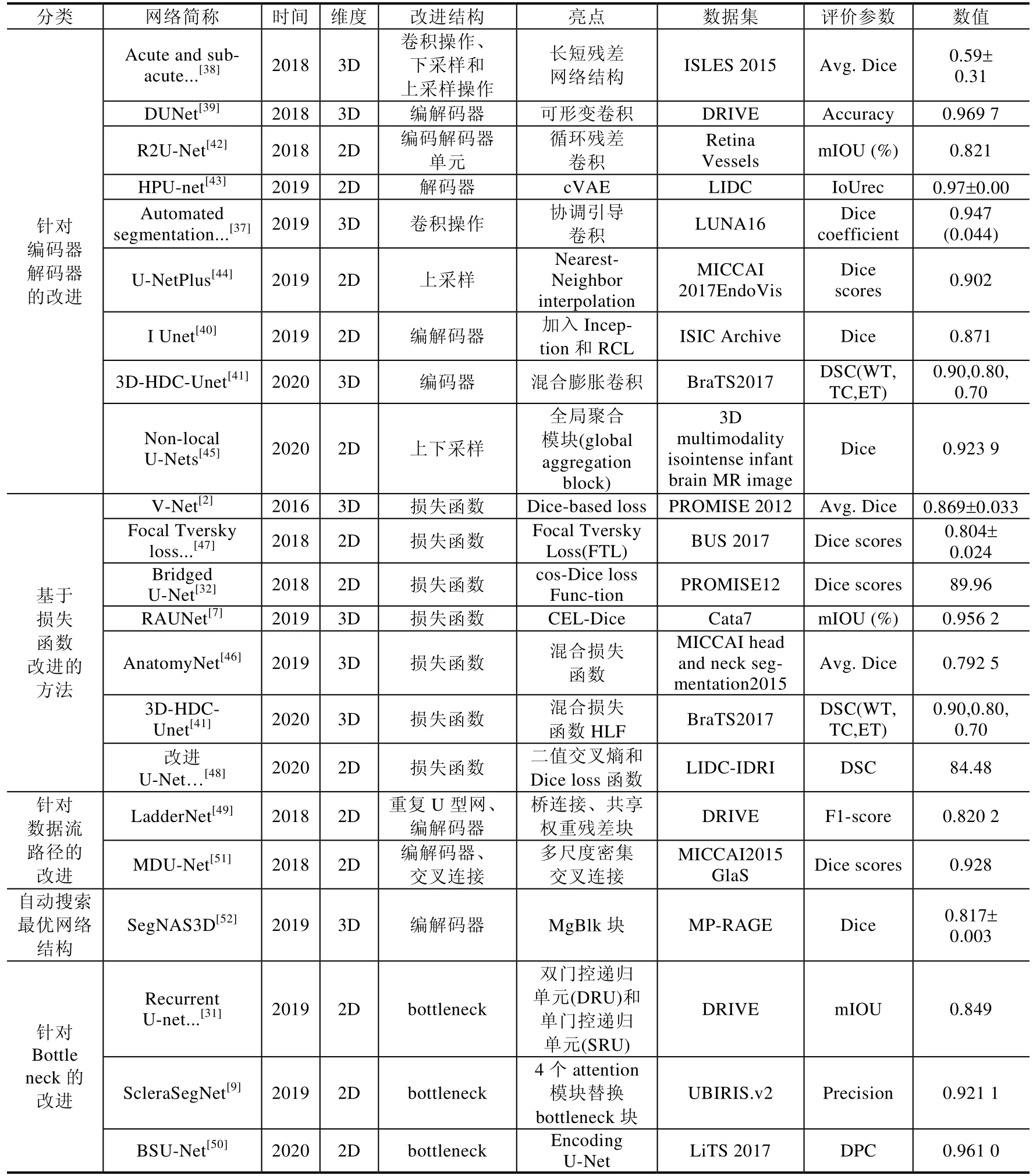
Table 4 Based on U-Net,it classifies the structural module improvement,and compares the improved structure and highlights表4 基于U-Net 面向結構模塊改進進行分類,并從改進結構、亮點等方向進行對比
隨著器官結構差異化、病灶形狀多樣化,U-Net 已經無法滿足所有病灶高精準性的分割.隨著attention 機制、Dense 模塊、Inception 模塊以及殘差結構、圖割等模塊的發展和完善,近期一些工作在U-Net 的基礎上加入不同的模塊,以實現對于不同病灶的精準分割.基于U-Net 擴展結構多種多樣,因而我們進一步總結了針對不同的目的的網絡結構改進方法,總結出幾個方案供參考,見表5.
1)對于分割微小細節,例如視網膜血管、肺葉等,可在殘差的基礎上使用可變形卷積或者擴張卷積,根據空間、通道激勵,在解碼器或bottleneck 中選擇加入attention 模塊或者SE 模塊.
2)針對提升計算速度的問題,可以采用的基本結構包括擴張卷積、殘差結構、SE 殘差塊等;主要改進的特殊結構包括從編解碼器單元加入稠密模塊或者可逆結構,對于損失函數可選擇Dice-based loss.
3)對于特征融合問題,可以將網絡編碼器按照不同模態分別提取特征再進行總體融合,不同模態之間加入稠密卷積,增加信息流減少參數,或者解碼器外接特征金子塔輔助特征融合.
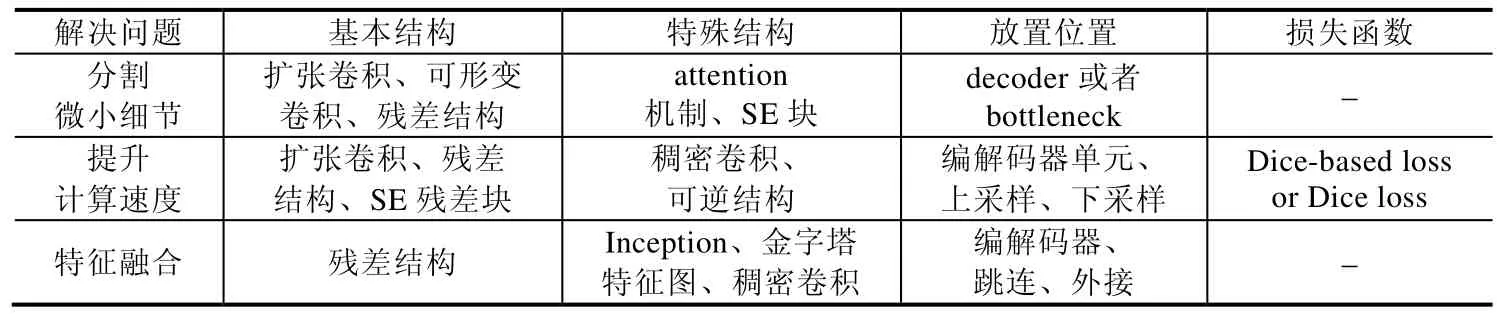
Table 5 Suggestions on using structure for different problems表5 針對不同問題的使用結構建議
綜上所述,本文分類總結和分析了基于U-Net 結構改進的醫學圖像分割方法,從改進的性能指標目的和改進的主要結構特點,對主要的相關工作進行了總結和介紹.基于對現有工作的綜述,提煉出基于U-Net 進行結構改進的一些常用改進模塊和常用改進方法,可以作為未來這個領域研究工作的參考.對于U-Net 的未來應用,UNet 不僅應用于醫學影像分割,在其他領域也有較好的應用效果,例如應用于人群識別的W-net[90],應用于航空圖像的ResUNet-a[91]、TernausNet[85]、FlowS-Unet[92]、ST-Unet[93]等多種改進方法.將U-Net 擴展到更多的應用領域,并進一步提升U-Net 的特征提取和識別準確性,提高計算效率,是未來可行的研究方向.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
哲學評論(2021年2期)2021-08-22 01:53:34
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
