引入Transformer 和尺度融合的動物骨骼關鍵點檢測模型構建
2021-03-11 01:11:50張飛宇王美麗王正超
農業工程學報 2021年23期
張飛宇,王美麗,2,3※,王正超
(1. 西北農林科技大學信息工程學院,楊凌 712100; 2. 農業農村部農業物聯網重點實驗室,楊凌 712100;3. 陜西省農業信息感知與智能服務重點實驗室,楊凌 712100)
0 引 言
目前畜牧業存在養殖成本高、效率低等問題,規模化、智能化圈養成為畜牧業發展的必然趨勢[1]。但隨著養殖密度增大,牲畜患病的概率也隨之加大。因此,有效的疾病預防是規模化養殖的重要環節。研究表明,牲畜行為與疾病之間存在一定的聯系[2],因此加強對牲畜行為的研究與分析,可以為其疾病預測提供研究思路和解決途徑。其中,骨骼關鍵點檢測作為動作識別、行為分析的前置任務,是實現動物體況信息的無接觸判別和異常信息預警的關鍵步驟。同時,骨骼關鍵點檢測還可以實現對動物的跟蹤保護和身份識別[3]。
傳統方法研究動物的行為或姿態時,常常需要將物理標記物或傳感器附著到動物的關鍵部位以達到收集數據的目的[4-5],但是這種方法會帶來一定的創傷,且動物本身的活動會造成傳感器的丟失或位移,存在較大的局限性。
近年來,深度學習技術在畜禽養殖領域的應用快速發展,大量學者研究畜禽行為識別[6-7]、個體檢測[8]等任務。研究人員發現動物骨骼關鍵點檢測與人體姿態估計任務目標相同。人體姿態估計的成功來源于大規模數據集[9],但手動標記數據需要耗費大量的人力和成本。相比人體姿態數據集,動物關鍵點數據集不僅更少,而且更難收集[10]。動物由于毛發、姿態等原因更容易形成自身遮擋,而且其四肢比人體更對稱,導致識別難度更大[11]。Li 等[12]提出基于無監督的動物姿態估計方法,從CAD 圖像生成的偽標簽在線更新到真實結果。該方法為解決動物數據集不足問題提供思路,但是結果不夠準確,無法應對復雜情況。
目前,基于卷積神經網絡(Convolutional Neural Networks, CNN)的姿態估計方法可以很好地學習特征檢測關鍵點[13]。Xiao 等[14]提出的SimpleBaseline 方法先檢測出圖片中每個人的區域框,然后獨立地去檢測單人區域的姿勢。Bao 等[15]基于神經網絡搜索技術為姿勢估計任務設計特征提取器PoseNAS,該方法的搜索策略可以端到端地設計姿勢編碼器和解碼器。然而這些卷積神經網絡結構復雜且參數量大,訓練及推理會占用大量計算資源和時間,在實際應用場景中受限。因此需要研究更實用高效的網絡結構。Transformer 采用基于自注意力和多層感知器的編碼器-解碼器架構[16],在各種視覺任務中顯示出巨大的潛力[17-19]。TokenPose 使用基于Token 的Transformer 結構解決人體姿態估計問題,通過自注意力交互捕獲外觀線索和約束線索[20]。但是該方法需要大量的數據訓練,并且對于動物骨骼關鍵點的檢測性能不佳,無法直接應用于本文任務。Sun 等[21]提出高分辨率姿態估計網絡(HRNet),該方法在特征提取過程中并行連接多個子網,從而獲得更多的語義信息,使準確率提升。
綜上所述,基于 HRNet 的特征提取優勢與Transformer 結構的全局建模特點,本文提出了一種高效的動物骨骼關鍵點檢測模型(HRNet-Transformer,HRTF)。使用改進的Transformer 編碼器取代常規卷積網絡高維特征提取部分;加入多尺度融合,提升模型不同維度特征融合能力;使用Hardswish 激活函數[22]作為網絡的主激活函數,進一步提升網絡的檢測精度。為了更好的驗證該方法的魯棒性和泛化能力,本文創建了一個包含養殖場與野外場景中多品種的羊關鍵點數據集,應用該數據集和已有的動物關鍵點數據集ATRW[23]進行試驗,將本文算法和其他算法進行對比分析。試驗結果表明該網絡比主流卷積神經網絡更高效,在動物數據集上表現優秀,且具有可解釋性。
1 材料與方法
1.1 數據采集及數據集制作
使用單目相機拍攝陜西省楊凌區曹新莊試驗站山羊圖像共1 600 張,并進行預處理。為增加數據集魯棒性,從Cao 等[11]制作的開源動物數據集中增選多場景羊的圖像,最終共收集1 800 張羊只圖像作為數據集。包含不同姿態、不同品種的羊圖像,如圖1 所示。體現了數據集的多樣性,充分考慮實際檢測時的復雜場景。該數據集按7∶3 的比例分為訓練集和測試集。由于該數據集規模較小,為防止模型過擬合,對訓練集采用五折交叉驗證法進行驗證[24]。
本文采用輕量級的圖像標注工具VIA[25]進行人工標注,17 個骨骼關鍵點標注樣例如圖1e 所示。以羊骨骼關鍵點為例,1~3 號為面部關鍵點,4~9 號為前腿關鍵點,10~15 號為后腿關鍵點,16 號為尾巴關鍵點,17 號為身體中心關鍵點。每張圖片需要框選出羊只主體并標注該羊只對應的17 個關鍵點。在標注關鍵點時,嚴格按照1號至17 號關鍵點順序進行標注,相應的關鍵點標簽會被自動對齊。
1.2 公開數據集
除了本文制作的羊數據集,為了進一步驗證模型的泛化性和遷移能力,試驗訓練集還加入與圖1e 定義一致的東北虎公開骨骼關鍵點數據集ATRW[23]。該數據集的圖像選自動物園監控視頻,包含92 頭東北虎個體,共4 124張圖像數據。每張圖片中包含一個東北虎主體及15 個關鍵點,相比羊數據集缺少2 個前膝蓋關鍵點,1~2 號關鍵點為耳朵。此外,在測試集中增加了VOC 數據集[26]的牛、馬等動物圖像做跨域測試。為統一標準,圖像數據均采用JPEG 格式,標注格式采用COCO 格式[27]。
2 動物骨骼關鍵點檢測模型
本文在 HRNet 模型的基礎上,引入優化的Transformer 編碼器和多尺度融合模塊,提出了一種動物骨骼關鍵點檢測模型HRTF,該模型由3 部分組成:1)以卷積神經網絡作為主干用于提取圖像低級特征的特征提取器;2)用于捕捉全局跨位置信息,對高級語義特征進行建模的Transformer 編碼器;3)用于輸出最終預測結果的回歸關鍵點熱圖模塊。HRTF模型結構如圖2所示。本文模型可以從更高的分辨率直接獲得全局約束關系,并保留細粒度的局部特征信息。除此之外針對基于Transformer 結構的TokenPose 模型計算效率低、在小數據集上訓練效果不佳的問題,HRTF 模型不僅可以獲得更好性能,而且參數量較小。不同規模的模型適用于不同精度和運行速度的需求。
2.1 特征提取器設計
HRNet 的并聯設計有助于進行特征融合[21]。該網絡由多個子網絡并行連接而成,通常設置4 級子網,當前子網的分辨率是前一級的1/2。該網絡將高分辨率子網用作網絡的第一階段,通過添加較低分辨率子網來形成更多的階段。其中第一階段子網使用Bottleneck 模塊,其余子網使用BasicBlock 模塊[28]。下采樣時,使用步長為2的3×3 卷積;上采樣時,先使用1×1 卷積進行通道數的匹配,再使用最近鄰差值;相同分辨率使用恒等映射。重復多次對不同尺度的特征進行融合。然而,HRNet 需要堆疊多層才能得到全局信息,也很難捕捉關鍵點之間的約束關系,其復雜的并行結構和較少的下采樣次數導致推理速度較慢,尤其是最后一級子網由于需要融合前3級子網的關鍵點特征信息,參數量占比超過整個網絡的70%。
為了提升網絡性能,本研究將HRNet 前3 級子網設計成并聯形式,增強模型對動物圖像低維特征的獲取能力。優化Transformer 編碼器使其替換最后一級子網,在減少參數規模的同時有效的提取高維特征。然后通過特征融合模塊將高分辨率和低分辨率的特征信息進行多尺度融合,提升對動物骨骼關鍵點的定位準確率。
2.2 Transformer 編碼器設計
引入Transformer 編碼器可以有效的解決HRNet 參數量大、高維特征提取能力差的問題,有助于遮擋、趴臥等復雜場景下對關鍵點的定位。但是,常規Transformer編碼器需要大量的訓練集數據,并且訓練時收斂慢。因此,本文對Transformer 模塊進行了改進,降低模型對數據量的要求,加快收斂速度。
優化后的Transformer 編碼器由3 部分組成:正弦位置嵌入編碼(Sine Position Embedding, SPE)[16]、多頭注意力模塊(Multi-head Self-Attention, MSA)[18]和多層感知器模塊(Multi-layer Perceptron, MLP)[16],整體設計如圖3 所示。
假設特征提取器的輸出F∈Rf×H×W,H,W表示最后一個子網的輸出分辨率,f表示通道數。不同于ViT 將輸入圖像分割為相同大小的網格小塊,再將網格塊編碼為Token[18]。本文通過1×1 卷積和降維操作將特征圖F降維到序列F∈RL×d,式中分辨率L=H×W,d為通道數,該操作復雜度低且可以保留特征信息。同時,根據位置嵌入編碼模塊獲取位置信息SPE∈RL×d,使特征圖帶有必要的位置關系。最后F與SPE 一起進入由多頭注意力模塊和多層感知器模塊串聯組成的編碼器中。Transformer 模塊整體過程可表示為
式中E是當前Transformer 編碼器層的輸出序列,作為下一編碼器層或熱圖回歸模塊的輸入序列。
2.2.1 位置嵌入編碼
關鍵點檢測是對位置信息高度敏感的任務,動物骨骼相對于人體的對稱性更強,點之間相似度高,檢測時易出現混淆。由于沒有引入循環結構和卷積結構,Transformer 模塊本身是缺失位置信息的。SPE 給Transformer 編碼器的輸入加上位置編碼,讓特征向量保持空間位置關系[16]。但是SPE 是對降維后的向量序列直接編碼,而降維后再編碼會損失2D 空間上的信息。不同于SPE,針對關鍵點檢測這一任務,位置信息在圖像的水平x和垂直y方向上是獨立的。本文對2D 圖像特征圖先進行x和y方向的位置嵌入編碼再降維,以減少空間信息的損失,使網絡可以更為準確的獲取骨骼點的位置信息。
本文改進的位置編碼過程表示為
2.2.2 多頭注意力模塊
自注意力機制可以加強關鍵特征的表達能力,提取稀疏數據的重要特征。為了使網絡可以更好的捕捉骨骼關鍵點之間的內部相關性,本文將帶有位置信息的特征圖輸入到帶有3 個權重參數矩陣W q,W k,W v?Rd×d的MSA 模塊中,Q,K,V?RL×d分別表示對應的查詢量(query)、鍵(key)和值(value)。MSA 是帶有h個頭的自注意力操作,能以有限的層數進行依賴內容的全局交互,而不是僅關注圖像局部區域。通過將值矩陣Q中的每個值與W中的相應權重進行線性組合,實現對特征向量F的更新。因此,注意力圖可以被看作是動態權重。然后,將得到的注意力圖與低維特征圖再次融合,以進行不同尺度特征信息的交換。這種機制在捕捉最終關鍵點預測熱圖與上下文關系方面起著關鍵作用。
2.2.3 多層感知器模塊
多層感知器模塊MLP 可以更好的構建出動物骨骼關鍵點之間的空間位置聯系,提升模型的定位效率。為了節約計算成本并提高模型的健壯性,本文對MLP 模塊進行了改進。該模塊通常由2 個全連接層、一層ReLU 激活函數以及LayerNorm 組成。本文設計的MLP 先將維度din降維到dout再升維回din,采用Hardswish 激活函數,數學表達為
與ReLU 激活函數相比,Hardswish 是非單調的,有助于緩解反向傳播期間的梯度消失問題,保證訓練初期的穩定性[22]。全連接層會使用大量參數,本文的MLP 相比較于常規先升維再降維的操作可以節約計算成本而不會損失模型精度。
2.3 熱圖回歸模塊設計
本文選擇回歸熱圖的方法預測關鍵點坐標,并設計輕量級熱圖回歸模塊。相比較于直接回歸點坐標,該方法結果更準確更容易訓練。首先將Transformer 模塊的輸出升維到E∈RC×d×d,通過 1×1 卷積生成預測熱圖M∈Rk×H’×W’,k為關鍵點個數,H’和W’為輸入圖像尺寸的1/4。在坐標與熱圖的轉換過程中,采用DARK 策略[29],以減少從小尺度熱圖進行編解碼時的量化誤差,保證生成結果的準確性。使用均方誤差(Mean Square Error)計算預測熱圖和目標熱圖之間的損失。
3 結果與分析
3.1 試驗參數設置
本試驗均在配置為Intel Xeon 8160T @ 2.1GHz 和NVIDIA TITAN RTX 的PC 上進行,使用 PyTorch 深度學習框架構建模型。試驗選用Adam 優化器,batch 大小設置為16,訓練次數設置為200 次迭代,學習率從10-4下逐漸降到10-5。圖像主體的長寬比設為1:1,從原始圖像中剪裁出標注主體然后輸入到模型中,輸入大小為256×256。熱圖大小設置為輸入大小的1/4。每張圖像都要經過一系列的數據增強操作,包括翻轉、旋轉(±40°)和縮放(±30%)。對于數據規模較小的羊數據,在訓練時采用五折交叉驗證法[24],將訓練集隨機分為5 份,其中4 份進行訓練,余下的一份做驗證,重復該過程5 次從中挑選最優模型。在測試中,通過計算原始圖像和翻轉圖像的熱圖平均值計算最終得分。
試驗采用基于OKS(Object Keypoint Similarity)[27]的平均準確率(Average Precision, AP)、平均召回率(Average Recall, AR)[30]分數作為評估指標。采用十億次浮點運算數(Giga Floating-point Operations Per Second,GFLOPs)描述模型的計算量,評估模型對硬件算力要求。
為了與特征提取器HRNet 的參數量相對應,本文設計3 個規模不同的網絡HRTF-S、HRTF-M 和HRTF-L,兼容更多的應用場景。當數據集規模較小時,如本研究中的小規模羊數據集,可使用小規模網絡HRTF-S,不容易出現過擬合,且可以保證實時性;大規模網絡HRTF-L精度最佳,但是對硬件要求較高,檢測速度相比其它兩個規模的網絡較慢;中等規模網絡HRTF-M 介于HRTF-S和HRTF-L 之間,能在精度和速度之間達到一定的平衡。在實際應用時,可根據不同數據規模、硬件條件、實時性需求等選擇合適的網絡模型。參數設置如表1 所示。
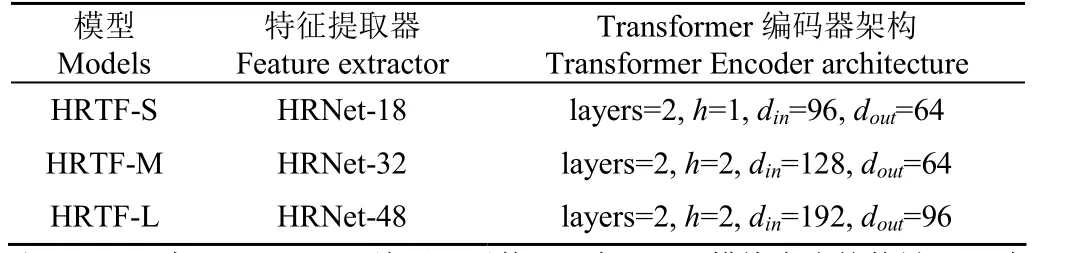
表1 HRTF 不同規模網絡的參數設置Table 1 Parameter setting table of HRTF network
3.2 模型性能對比及分析
為了評價本文方法對動物骨骼關鍵點的檢測性能,對比了姿態估計領域的方法SimpleBaseline[14]、HRNet[21]、PoseNAS[15]和TokenPose[20]。所有模型通過ImageNet 進行預訓練[31]。使用羊數據集作為訓練集和測試集,本文算法HRTF 和其他算法的對比結果如表2 所示。
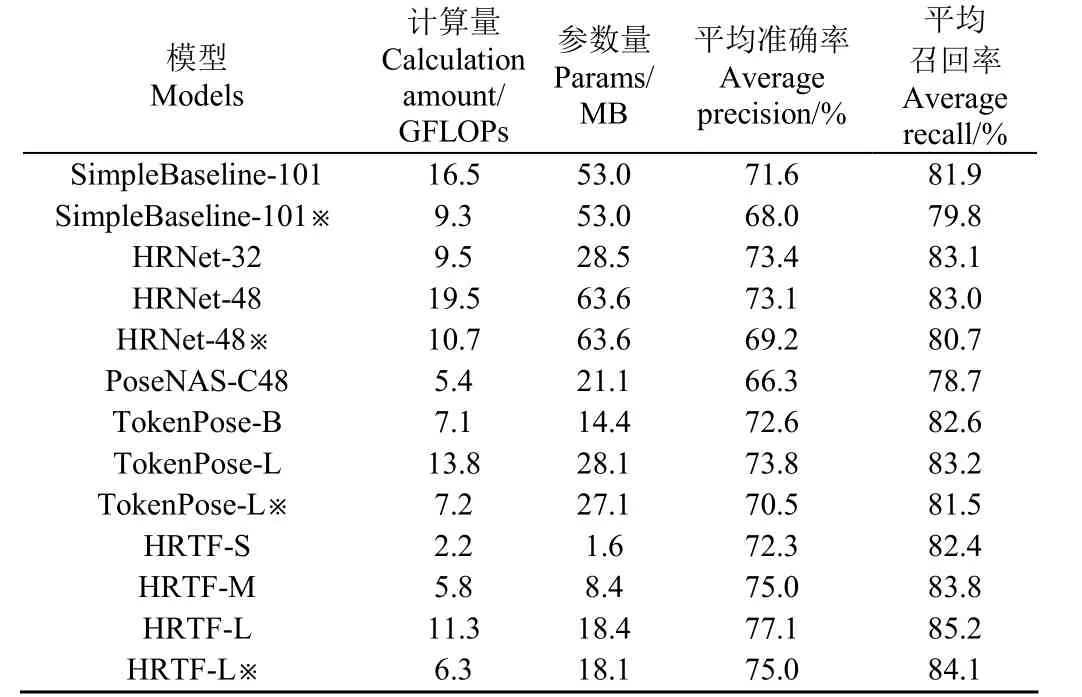
表2 羊數據集下各模型性能對比Table 2 The performance comparison of sheep dataset
從表2 中可以看出,與HRNet-48 相比,HRTF-L 參數量和計算量分別減少71%和42%,并獲得目前對比算法中的最優結果,AP 達到77.1%,試驗預測效果如圖4a 所示。改善了HRNet-48 在小數據集上容易出現過擬合的問題。HRTF-S與TokenPose-B 的性能接近而計算量要低的多,單張圖像的檢測時間為14 ms,實現了實時檢測,說明本文提出的混合結構模型以更少的計算量和復雜度獲得了更好的檢測效果。
TokenPose-L 由于其Transformer 結構設計復雜,收斂速度慢,在第200 次迭代時準確率僅能到71.5%,在300次迭代時才趨于收斂。而HRTF有效改善了這一缺點,在更少的訓練次數下收斂就能趨于穩定。
實際應用中動物圖像常來源于監控攝像頭,大部分的分辨率較低,特征提取難度增大,而且更大的輸入尺寸需要更大的計算量。如表2 所示,使用192×192 作為圖像輸入大小時,SimpleBaseline 和HRNet 準確率分別下降3.6 個百分點和3.9 個百分點,說明它們對羊圖像輸入尺寸敏感,在小尺寸圖像上表現不佳。HRTF-L 仍能達到75%的結果,證明其檢測不同尺度的圖像時魯棒性更好,因此HRTF 在實際的養殖場中的適用性更強。
基于東北虎數據集的試驗對比結果如表3 所示。當數據集規模增大后,模型間差距縮小;關鍵點數量減少,整體結果上升,但HRTF-L 仍然獲得了最好的結果,準確率達到89.7%,試驗預測效果如圖4b 所示。對比HRNet-32和HRTF-S 結果可以發現,盡管HRNet-32 有結構更復雜的特征提取主干,但是結果比HRTF-S 低。這說明Transformer 編碼器對羊圖像中的高級語義信息的建模能力至關重要,相比較于卷積網絡可以從低維特征提取器中獲取更多有效信息。
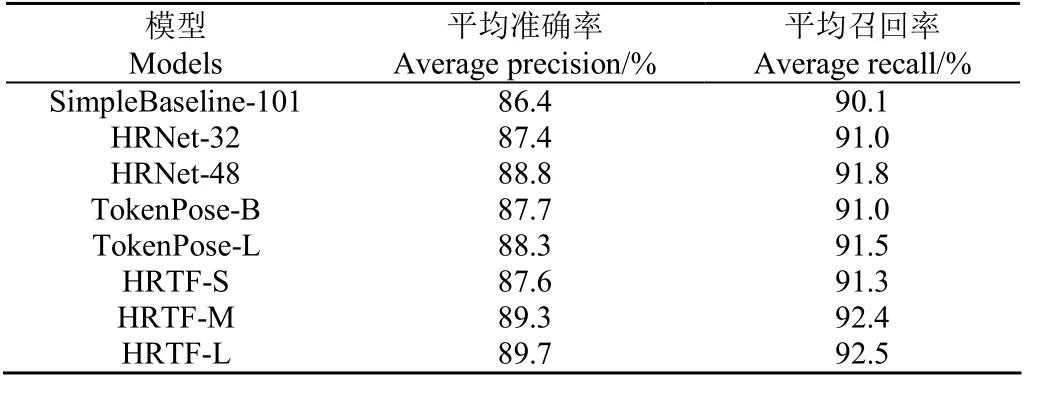
表3 東北虎數據集下各模型性能對比Table 3 The performance comparison of Amur tiger dataset
3.3 模型消融試驗
以HRTF-M 為基準模型在羊數據集上進行消融試驗,與HRNet-32 對比,驗證位置嵌入編碼模塊和多層感知器模塊的有效性,結果如表4 所示。
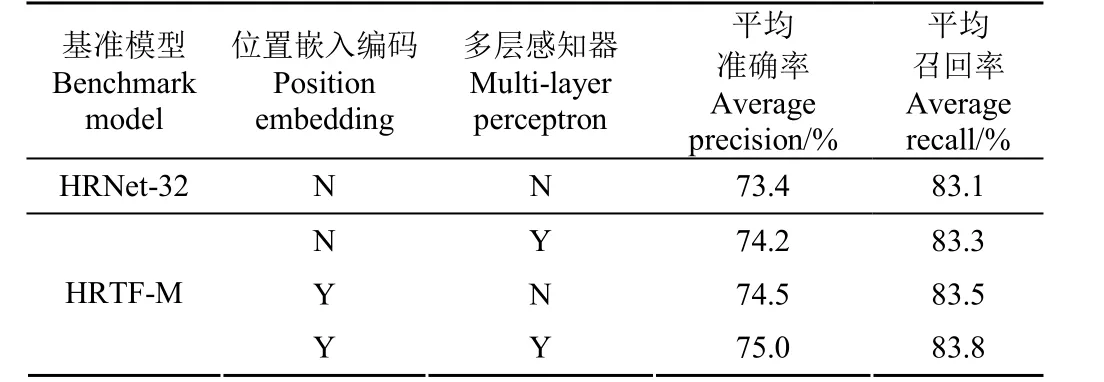
表4 消融試驗結果Table 4 The results of ablation test
相比較于完整HRTF-M 模型,去掉位置嵌入編碼后準確率下降了0.8 個百分點,去掉多層感知器后準確率下降了0.5 個百分點。說明SPE 提供的位置信息和MLP 提供的信息融合均對整個模型起到正向反饋,可以有效提升模型性能,證明了本文中各組成模塊的有效性。
3.4 模型可解釋性與跨域性
動物骨骼存在一定的對稱性和領域關聯性,比如腿部的骨骼關鍵點之間存在聯系。優化后的Transformer 編碼器的能夠更精準的建立關鍵點位置之間的依賴關系。將HRTF-L 的中間輸出層可視化,如圖5 所示,注意力模塊中的可視化熱圖明顯的反映出了關鍵點之間的聚集和聯系。而隨后的熱圖回歸模塊會進一步細化關鍵點位置,輸出最終的預測位置。這說明注意力模塊可以有效的發現這些動態特征,而不需要依賴圖像特征,證明了模型具有可解釋性,能夠用于解決遮擋、趴臥等復雜場景下對關鍵點定位困難的問題。
為進一步說明模型的泛化性,本文選用VOC 數據集中的牛、馬和狗3 種動物做測試集,使用以羊數據集為訓練集的HRTF-L 模型進行跨域試驗。圖6 展示了這些試驗的預測結果。不同動物之間存在一定的骨骼空間關系相似性,但是外觀、體型存在很大差異。而結果顯示,使用羊骨骼模型在牛、馬和狗這些動物身上均能較好地檢測出骨骼關鍵點,證明了HRTF 模型具有良好的跨域性和泛化能力。
4 結 論
檢測動物骨骼關鍵點是進行動物姿態識別和行為分析的前置任務。為實現準確、高效的動物骨骼關鍵點檢測,本文在HRNet 結構基礎上引入了改進的Transformer編碼器,增強了模型對動物骨骼關鍵點的檢測性能,通過在自建的羊數據集和多種動物數據集上試驗,證明了該方法的有效性和泛化性。主要結論如下:
1)通過改進HRNet 的子網結構并引入Transformer編碼器,使新模型可以從更高的分辨率直接獲得全局約束關系防止骨骼關鍵點錯位,并保留細粒度的局部圖像特征信息。
2)改進Transformer 編碼器結構,通過使用優化的Transformer 編碼器替換模型中的最后一級子網,模型獲得了更好檢測效果,同時參數量和計算量分別減少71%和42%。在小規模羊數據集和輸入小分辨率圖像的情況下準確率達75%,適合實際場景應用。
該模型可以提高動物骨骼關鍵點檢測的準確率,幫助更高效的完成動物姿態識別和行為分析。在多種動物數據集上進行跨域測試,試驗結果表明該模型具有較強的泛化能力和魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
