基于動態損失函數的遠程監督關系抽取
2021-03-13 06:00:44彭正陽于碧輝
小型微型計算機系統 2021年2期
關鍵詞:模型
彭正陽,呂 立,于碧輝
1(中國科學院大學,北京 100049)
2(中國科學院 沈陽計算技術研究所,沈陽 110168)
1 引 言
關系抽取是信息抽取中的一項重要工作,其目的是抽取句子中標記實體對之間的關系.關系抽取屬于構建知識圖譜的關鍵步驟,且已經廣泛應用于自動摘要、問答系統及檢索系統中.
傳統的監督方法需要大量的人工勞動來標記原始數據,價格昂貴且耗費時間.因此,Mintz等人[1]在2009年提出了遠程監督.遠程監督的描述如下:如果知識庫中兩個實體表達了一個關系,那么任何包含這兩個實體的句子都可以表達這種關系.遠程監督是一種快速、有效的對大量數據進行自動標注的方法.然而,這種假設太過強烈,容易導致錯誤標注.因為某句中提到的兩個實體,它們之間的關系可能并不是知識庫中對應的關系.
為了解決錯誤標注問題,2015年,Zeng等人[2]對于每個實體對,選擇數據集中最有可能表達該實體對對應關系的一個句子作為代表來進行訓練,這必然會遺漏一些有價值的信息.2016年,Lin等人[3]對一個實體對對應的所有句子進行基于注意力機制的權值計算,通過對錯誤的句子進行降權處理來減少錯誤標注帶來的不良影響.2017年,Ji等人[4]通過將更多有用的實體信息引入到注意力權重的計算中,來提高注意力機制的效果.然而,仍然存在一些噪音句子被賦予很大的權重,并且大量簡單句子累計的權重也影響到模型的效果.
本文提出了一種動態損失函數,根據訓練過程中交叉熵損失分布情況,動態改變損失函數中每個樣本的權值,使得錯誤標注的樣本和大量簡單的樣本權重降低.如圖1中左圖所示,本文對每個mini-batch中樣本的交叉熵損失分布進行了統計.如圖1中右圖所示,為了便于計算且更加清晰,本文通過雙曲正切函數(tanh)對損失值進行了歸一化,并把橫軸從0到1均勻分割成了M個區間,縱軸為每個區間內樣本的數量.其中左側損失非常小的樣本數量較多,它們屬于大量的簡單樣本,而最右側交叉熵損失過大且數量突然增加的,屬于錯誤標注或難以學習的樣本.本文根據每個區間的樣本密度,在損失函數中對不同樣本賦予不同的權重,再根據增加了權重的損失函數進行訓練.某些情況下,異常樣本的數量非常小或損失值非常大,會導致簡單樣本的權值減少很多,而異常值的權重卻減少的很少.因此,本文將交叉熵損失值最高的N個樣本的權重系數置為0,其中N要取相對較小的值,如果設置的過大,困難樣本將不被學習,而且保留少量的噪聲作為干擾有利于提升模型的效果.
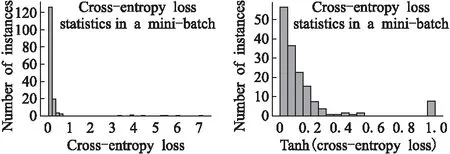
圖1 交叉熵損失在mini-batch中的分布Fig. 1 Distribution of cross-entropy loss in a mini-batch
本文的主要貢獻如下:
1)本文提出了一種根據每個mini-batch中訓練樣本的交叉熵損失分布而動態改變樣本權重的新的損失函數.
2)本文將動態損失函數應用于遠程監督關系提取任務,并在NYT-Freebase公共數據集上取得了優于基線的結果.
3)本文的方法是與模型無關的,可以應用于其他任務的模型中.
2 相關工作
在關系抽取任務中,有監督關系抽取是最常用的方法.Zelenko等人[5]及zhou等人[6],利用全監督模型進行關系提取.但人工標注語料嚴重缺乏,為了解決這一問題,Mintz等人[1]在2009年提出使用遠程監督來自動標記數據.然而,遠程監督必然伴隨著貼錯標簽的問題.為了緩解這一不足,Riedel等人[7]在2010年提出多實例單標簽方法.隨后,Hoffmann等人[8]和Surdeanu等人[9]提出了多實例多標簽的方法.
近年來,隨著神經網絡的廣泛應用,越來越多的研究在遠程監督關系抽取任務中使用神經網絡,莊傳志等人[10]的綜述概括了神經網絡在關系抽取上的發展歷程.2014年,Zeng等人[11]首次應用了基于CNN的方法,自動的獲取了相關的詞匯和句子級特征.2015年,Zeng等人[2]提出了具有多實例學習的分段最大池化卷積神經網絡(PCNN).Lin等人[3]在PCNN的基礎上引入了句子層注意力機制,并充分利用語料中所有包含兩個實體對的句子.為了提高注意力機制的表現,一些論文使用了知識庫的信息,如:Zeng等人[12];Ji等人[4];Han等人[13].在模型創新上,宋睿等人[14]采用了卷積循環神經網絡.此外,強化學習和對抗學習也開始被應用于遠程監督關系抽取任務中,如:Feng等人[15]以及Qin等人[16]的研究.對于噪聲標簽,Liu等人[17]提出了軟標簽方法,葉育鑫等人[18]采用噪聲觀測模型和神經網絡結合的方式來降低錯誤標簽影響.
關于損失函數,Lin等人[19]在2017年提出了Focal Loss,通過將交叉熵損失函數矯正到設計的形式來解決大量簡單樣本的問題.然而,Focal Loss有兩個難以調整的參數.并且它不能動態地改變參數.此外,2019年,Wang等人[20]提出了對稱交叉熵損失函數.
3 關系抽取模型
本文提出的基于動態損失函數的遠程監督關系抽取模型結構如圖2所示.首先在embedding層,采用詞向量模型將文本轉化成向量形式,并與位置向量拼接作為模型的輸入,對應圖2中的Vector Presentation部分;然后在卷積層通過卷積運算抽取出文本的特征并通過分段最大池化層來保留顯著特征;接下來是Attention層,將卷積并池化后的句子向量與關系向量進行相關性計算,來構建注意力機制,降低錯誤標注的權重;最后通過采用動態損失函數的分類層輸出關系的類別.該模型與其他神經網絡模型的不同之處在于使用了動態損失函數,在模型訓練時,先計算當前批次的訓練數據的損失分布來確定每個樣本的權重系數β,然后使用增加了動態權重系數的損失函數來進行模型訓練,降低錯誤標注和簡單樣本的影響.
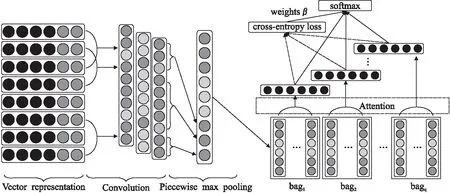
圖2 基于動態損失函數的遠程監督關系抽取模型Fig. 2 Distant supervision relation extraction model of dynamic loss function
3.1 Embedding層
Embedding層將句子文本中的每個詞轉換為對應的向量形式.
3.1.1 詞向量
詞向量其目的是將單詞轉換成分布式表示,以表達單詞的語法和語義信息.本文使用了Mikolov等人[21]提出的Skip-gram模型來訓練詞向量.
3.1.2 位置向量
位置向量由Zeng等人[11]在2014年提出.它被定義為當前詞到兩個實體的相對距離,并用兩個向量來表示這兩個距離.關系抽取任務中,越靠近實體對的詞對關系類別的影響越大,因此,添加位置向量的表示,比單純詞向量包含更多有價值的信息.
最后,將詞向量和位置向量拼接起來作為模型的輸入.假設詞向量的維度是k_w,位置向量的維度是k_d,則每個詞最終的向量化表示的維度為k=k_w+2×k_d.
3.2 卷積層
卷積是一種矩陣間的運算.假設矩陣A=(aij)m×n,矩陣B=(bij)m×n,卷積計算公式如下.
(1)
通過Embedding層,對于長度為n的句子,可以獲得由詞向量組成的矩陣X=[x1,x2,…,xn].選定一組卷積核W={w1,w2,…,wm},w∈Rl×d,其中l是卷積核的大小,d是詞向量的維度.然后,經過m個卷積核的滑動卷積操作,得到卷積后的特征矩陣C=[c1,c2,…,cm].
3.3 分段最大池化層
分段最大池化操作是由Zeng等人[2]在2015年提出的,根據兩個實體將一個句子劃分為3個片段,并分別在3個片段中分別執行max pooling.
根據實體的位置將卷積后的向量分割成3部分ci=[ci1,ci2,ci3],最大池化分別在每段句子上取最大值:pi1=max(ci1),pi2=max(ci2),pi3=max(ci3).每個卷積核得到的結果通過分段最大池化操作得到pi=[pi1,pi2,pi3],最后,把所有的分段最大池化的結果進行拼接得到句子低維向量編碼p∈R3m.
3.4 Attention層
在獲得句子表征后,本文采用Lin等人[3]在2016年提出的句子層面的注意力機制.同一實體對的所有句子的集合稱為一個包,注意力機制通過計算包中每個句子最大池化后得到的向量與預測關系的向量的相關程度得到權重系數,通過權重系數來降低噪聲的影響.設S是一個包含n個句子的包,S={p1,p2,…,pn}.具體計算公式如下.
(2)
(3)
其中,A為隨機初始化的權重對角矩陣,r為關系的向量表示,α為每個句子的權重系數,S為Attention層的輸出結果.
3.5 動態損失函數
目前采用的多實例學習的目的是區分包而不是句子,本文的模型結果的預測概率公式定義為.
(4)
其中nr為關系的總數,W為關系的矩陣表示,S為一個包,b為偏置向量.
在訓練過程中,目標是最小化交叉熵損失函數.本文使用交叉熵定義動態損失函數公式如下.
(5)
其中q是mini-batch的大小,θ是模型中所有的參數,βi是的Si權重,權重是動態的變化,在不同輪次,不同的mini-batch中的β是不同的.
本文采用mini-batch梯度下降來最小化目標函數.它通過從訓練集中隨機選擇一個小批數據來進行迭代訓練,直到模型收斂為止.動態損失權重β的計算過程如下:
1.計算mini-batch中每個訓練樣本的交叉熵損失值.
2.通過雙曲正切函數(tanh)將所有樣本的損失值進行歸一化.
3.將0-1的區間劃分成M個相等的區間,計算每個區間的長度e=1/M.
4.統計歸一化后的損失值落在每個區間內的樣本的個數Ri.
5.計算每個區間的樣本密度Di=(Ri+1)/e,采用加1來平滑數據,避免密度為0.
6.根據每個樣本的所處區間,得到其對應的權重系數βi=1/Di.
根據上述步驟可以得出如下計算公式.
(6)
(7)
由于對所有的樣本都增加個一個小于1的權重,這會導致模型收斂速度變慢,因此需要乘以一個系數γ,γ的值取為mini-batch的大小q.當M取值為1或M把每個樣本劃分為一個區間時,若不采用平滑,則動態損失函數等價于原始損失函數.動態損失函數的最終形式如下.
(8)
特殊情況下,交叉熵損失值較大的樣本數量非常少或者某個樣本的交叉熵損失值非常大,會導致簡單樣本的權值減少的很多,而異常樣本的權重減少的很少.本文采用將交叉熵損失值最高的N個樣本的權重系數置為0的方式,來避免這個問題.
對于每個mini-batch,經過計算后各區間的權重系數βi的分布情況如圖3所示.

圖3 各個區間的權重分布Fig.3 Weight of each region
此外,為了增加模型的泛化能力,并降低過擬合的影響,本文使用Dropout[22]作為正則化方法,優化遠程監督關系抽取模型.
4 實 驗
4.1 數據集與評價指標
本文采用Riedel[7]于2010年生成的一個廣泛應用于遠程監督關系抽取任務的數據集對模型進行評估.它將Freebase知識庫中的實體對與紐約時報(NYT)語料庫對齊.以2005-2006年新聞中的句子作為訓練數據,2007年新聞中的句子作為測試數據.訓練集有522,611個句子,281,270個實體對,18,252個關系事實.測試集有172,448個句子,96,678個實體對和1,950個有關系事實.數據集包含53個關系,包括一個特殊的關系NA,它表示實體對之間的關系是不可用的.
本文采用與Lin等人[3]一致的評估方法,采用held-out來評估本文的模型.本實驗結果的評價指標采用準確率-召回率(PR)曲線和平均準確率(P@N),通過對比平均準確率以及PR曲線來評估模型的性能.
4.2 參數設置
為了將本文實驗結果與其他基線結果更好進行比較,本文使用與Lin等人[3]相同的參數進行實驗驗證.表1列出了本文模型在實驗中使用的超參數.對于區間個數M和權重置零個數N,本文設置M的取值集合為{5,10,20,30},N的取值集合為{1,3,5,7},當M值設為20,N值設為3時獲得最優解.

表1 超參數設置Table 1 Parameter settings
4.3 實驗結果及分析
4.3.1 本文方法與現有方法比較
為評估本文提出模型的效果,本文選擇了以下有代表性的模型進行比較:
Mintz:Mintz等人[1]首次提出的遠程監督模型.
MultiR:Hoffmann等人[8]提出的一個多實例學習方法的關系抽取模型.
MIML:Surdeanu等人[9]提出的一個多實例多標簽的關系抽取模型.
PCNN+ONE:Zeng等人[2]提出一種分段最大池化的卷積神經網絡(PCNN).在卷積神經網絡的基礎上按實體位置將特征分成三段進行池化并結合多實例學習的關系抽取模型.
PCNN+ATT:Lin等人[3]提出的關系抽取模型.在PCNN基礎上增加了注意力機制,減少噪聲標簽的影響.
以上5種模型與本文提出模型的準確率-召回率(PR)曲線對比情況如圖4所示.
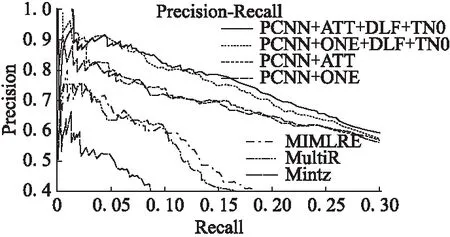
圖4 不同模型的PR曲線Fig.4 PR curves of different methods
從圖4的PR曲線可以看出,PCNN模型的結果顯著優于傳統的基于特征的方法,因為神經網絡模型可以自動的抽取出句子特征,可以避免人工特征選擇及NLP工具導致的錯誤傳播問題.分段最大池化的卷積神經網絡模型(PCNN)可以通過神經網絡結構自動抽取特征,并選擇出不同部分重要的特征,因此取得了較大提高.增加了注意力機制的模型(PCNN+ATT)比傳統的每個包中選擇一個句子的模型(PCNN+ONE)稍好一些,表明注意力機制可以削弱噪聲標簽的影響,對于關系抽取結果的提升有一定的促進作用.
相較于PCNN+ONE及PCNN+ATT模型,本文提出的模型增加了動態損失函數(DLF)并將前N大損失的樣本權值設置為0(TN0),結果明顯優于先前的模型.雖然PCNN+ATT在關系抽取方面功能強大,但是要處理所有的數據噪聲仍然很困難.本文提出的方法在原有模型的基礎上,進一步削弱了噪聲數據的影響,并且降低了大量簡單樣本的影響,從而有效提高了模型的抽取效果.
4.3.2 本文方法的效果分析
本文將動態損失函數分別添加到PCNN+ONE模型和PCNN+ATT模型.并對增加了DLF和TN0的模型分別進行了實驗.
從圖5和圖6可得出如下結論:
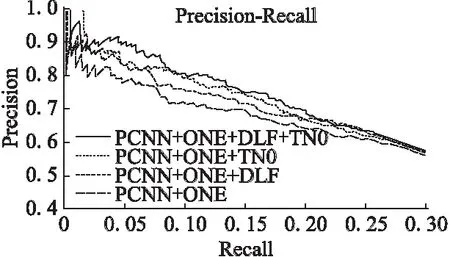
圖5 PCNN+ONE模型的PR曲線Fig.5 PR curves of PCNN+ONE
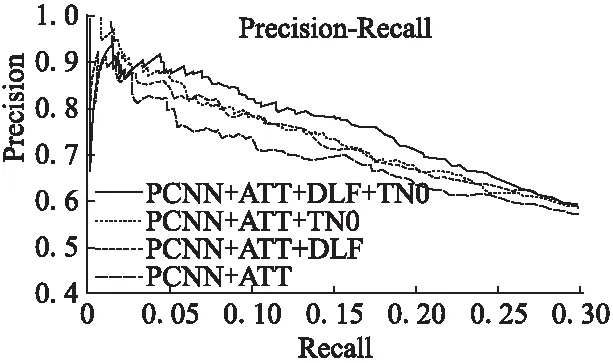
圖6 PCNN+ATT模型的PR曲線Fig.6 PR curves of PCNN+ATT
1)對于PCNN+ATT和PCNN+ONE,增加DLF方法的結果都優于原模型.DLF減少了過于簡單的大量樣本和某些噪聲樣本的權值.
2)對于PCNN+ATT和PCNN+ONE,增加TN0的結果均優于原模型.這表明,具有較大交叉熵損失的樣本可能是噪聲或難以學習的樣本,TN0降低了它們的權重.
3)對于PCNN+ONE,增加TN0的結果明顯優于增加DLF的結果.而對于PCNN+ATT,兩種方法的性能接近.這意味著PCNN+ONE中的噪聲樣本比PCNN+ATT中的噪聲樣本影響更大,因為注意力機制在一定程度上降低了噪聲樣本的影響.
4)對于PCNN+ATT和PCNN+ONE,同時增加DLF和TN0的模型均優于其他模型,說明兩種方法可以疊加使用.因為在增加了DFL之后,一些有噪聲的樣本仍然有較大的權值,而增加TN0方法可以消除它們的影響.
4.3.3 P@N準確率比較
根據之前的工作,本文采用了P@N來比較本文提出的模型和基線模型.從表2中可以看出:對于PCNN+ONE和PCNN+ATT模型,本文的方法較先前方法可以提高了10%以上的精度.結果表明,本文提出的基于動態損失函數的模型是有效的,不管是否已經使用了注意力機制,平均準確率均優于對比模型.
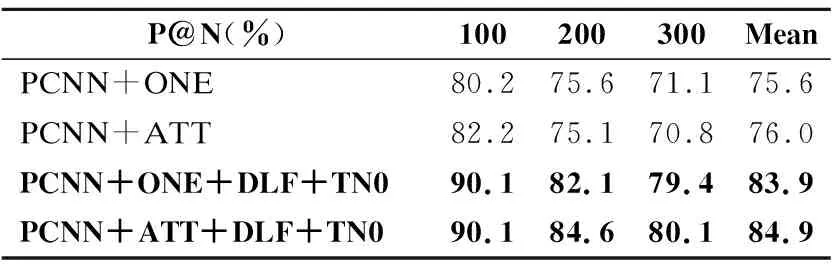
表2 平均準確率P@NTable 2 P@N for relation extraction
5 結 語
本文以遠程監督關系抽取為研究對象,通過對損失分布情況的分析,提出了一個用于遠程監控關系提取的動態損失函數,來解決遠程監督造成的錯誤標注問題.該方法根據交叉熵損失的分布來動態改變樣本的權重,降低了簡單樣本和噪聲樣本的權重.實驗結果表明,本文提出的方法適用于遠程監督關系抽取任務,能夠有效提升遠程監督關系抽取模型的效果.在未來的工作中,考慮解決模型訓練前期不穩定的問題,并嘗試將本文提出的方法應用于其他自然語言處理任務中.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
