結合Attention-ConvLSTM的雙流卷積行為識別
2021-03-13 06:00:42揭志浩曾明如周鑫恒
小型微型計算機系統 2021年2期
揭志浩,曾明如,周鑫恒,何 強
(南昌大學 信息工程學院,南昌 330031)
1 引 言
相比于諸如物體檢測,人臉識別等領域,在利用視頻數據進行人體行為識別方面,神經網絡的表現依然欠佳.究其原因,是視頻數據相比于圖像信息還具有時間屬性,傳統的神經網絡主要依靠靜態的圖像RGB信息,而不能充分利用人體的運動信息[1,2].近年來卷積神經網絡在機器視覺方面得到了很好的發展,它也逐漸被運用到人體行為識別.雙流(Spatial-Temporal Stream)卷積神經網絡是目前運用最廣泛的方法之一[3],相比于傳統的方法主要依靠靜態圖像的RGB信息進行視頻數據分析,雙流卷積還可以利用視頻數據中被檢測目標隨時間變化的運動信息.在雙流卷積的基礎上,Du Tran[4]等人提出了3D卷積,將2D的卷積核替換成3D,對連續幀視頻數據進行卷積處理.Feichenhofer[5]等人探究了多種對雙流信息進行融合的方法,并且發現相比于softmax層,在卷積層對雙流信息進行融合效果更好.Zhu[6]等人提出的卷積結構可以自動提取視頻數據的時間流信息,而不需要對視頻數據進行預處理.這些方法雖然綜合分析了連續多幀視頻數據中的人體運動信息與RGB信息,但是這些方法在視頻級的分析和識別上基于平均預測,對于長時間范圍的運動信息分析往往并不準確.長短時記憶循環(LSTM)神經網絡在處理序列模型的數據時表現出色,被廣泛運用于諸如機器翻譯,語音識別等領域.由于視頻數據具有天然的序列屬性,Donahue[7]等人提出將LSTM用于視頻的描述與識別,取得很好的效果.但是傳統的長短時記憶循環神經網絡有其結構性的缺陷,這是因為LSTM把所有的輸入都當成向量.在文獻[7]中,雖然所有的數據都進行了卷積處理,但是在輸入到LSTM之前都要進行向量化,這種操作無疑破壞了視頻數據的空間特征.
綜上可知,對視頻數據的時間和空間屬性同時進行很好地分析仍然是艱難的工作,且而在視頻背景復雜的情況下,現有的方法普遍缺乏有效的機制對一些顯著特征實現有效的抓取和利用.
針對上述問題,本文提出將基于注意力機制的卷積長短時記憶循環神經網絡與雙流卷積中的時間流進行結合,一方面實現了較長時間跨度的時間流數據的輸入輸出,另一方面將LSTM直接作用于神經網絡的卷積層,更好地保留了光流信息的空間特征.注意力機制使得神經網絡對視頻數據中的顯著特征和關鍵幀進行了更好的利用.本文優化了擴展之后網絡的正則交叉熵損失函數,使得神經網絡能夠實現更快的收斂.
2 雙流卷積網絡
最早用于人體行為識別的雙流卷積神經網絡由Simonyan[8]等人提出,如圖1所示他們提出將視頻數據分為兩個數據流,即空間流(Spatial stream)和時間流(Temporal stream)/光流(Optical stream),并將其分別輸入到不同的卷積神經網絡,空間流負責處理靜態圖像的RGB信息,時間流處理被檢測目標的運動信息(即連續幀視頻數據中特征點隨時間的位移信息),最后在softmax層對雙流數據流進行融合.
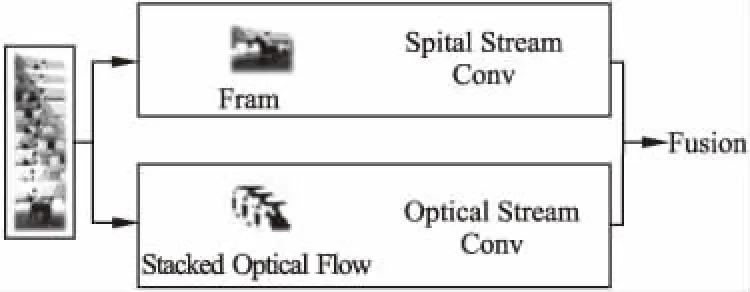
圖1 雙流卷積神經網絡Fig.1 Two-stream CNN
3 LSTM
1997年Sepp等人在文獻[9]中提出了一種長短時記憶(Long Short-Term Memorry)循環神經網絡,如圖2所示,把傳統循環神經網絡的隱藏層自連接單元用LSTM單元替換,解決傳統循環神經網絡在反相傳播時存在的梯度消失和梯度爆炸的問題,LSTM網絡更新遞歸公式如下:

圖2 長短時記憶單元Fig.2 LSTM unit
(1)
其中W是權重矩陣,σ是激活函數.ct為記憶單元,每次的輸入輸出都對其進行一定程度的更新,it代表輸入門,它決定新的輸入對新的記憶單元的影響程度,ft代表遺忘門,它決定舊的記憶單元對新的記憶單元的影響程度,ot為輸出門,由它得出的輸出作為一個隱藏狀態輸入到下一個LSTM單元,各門值與記憶單元均為同維的列向量.由式可知在t時刻的各門值由t-1時刻的記憶單元,隱藏狀態,新的輸入,及偏置值共同影響,合理地設置遺忘門和更新門,可以較為容易地把記憶細胞中的信息傳遞到更遠,既克服了傳統循環神經網絡存在的梯度消失和梯度爆炸的問題,又使得神經網絡可以更好地學習長時間范圍內輸入輸出之間的依賴關系。但是式(1)中的it和ht均為列向量,這種網絡結構處理具有明顯空間特征的圖像和視頻數據顯然是不合理的,因為列向量并不能反映數據中各局部特征的之間的空間關系.
4 ConvLSTM
Xingjian[10]等人第一次提出了卷積的長短時記憶循環神經網絡(ConvLSTM),這種LSTM在保留傳統LSTM的優點的同時,還可以保留諸如圖像,視頻等信息的空間特征.Seo[11]等人首次將ConvLSTM用于序列圖像的識別,得到了很好的實驗效果.ConvLSTM的更新遞歸公式如下:
It=σ(Wxi*Xt+Whi*Ht-1+Wci*Ct-1+bi)
Ft=σ(Wxf*Xt+Whf*ht-1+Wcf*Ct-1+bf)
Ct=Ft⊙Ct-1+It⊙tanh(Wxc*Xt+Whc*Ht-1+bc)
Ot=σ(Wxo*Xt+Who*Ht-1+Wco*Ct+bo)
Ht=Ot⊙tanh(Ct)
(2)
與式(1)相比,式(2)中的W表示卷積核,*表示卷積,⊙表示Hadamard乘,卷積結構相比于向量更加能夠保留數據的局部特征及其之間的空間關系.
在利用視頻數據進行行為識別方面,傳統方法通常在神經網絡的全連接層使用LSTM,雖然保留了幀數據的全局特征,但是幀數據的局部特征和空間關系卻遭到破壞.行為識別的過程中,局部運動特征及其之間的空間關系至關重要,本文提出在神經網絡的卷積層使用LSTM,將輸入xt擴展成N×N×D的輸入Xt,其中N×N即為在當前卷積層feature map的大小,D為該卷積層的通道數.
5 Attention-ConvLSTM
注意力機制最早由Bahdanau等人在文獻[12]中提出,應用于機器翻譯.這種機制通過自動地分析數據的局部特征據與預測結果之間的相關性,使得神經網絡可以選擇性地關注輸入數據的重要特征[13],從而賦予一些關鍵特征更大的權重,其在自然語言處理,機器翻譯等方面表現出色[14,15].Kelvin Xu等人在文獻[16]中首次將注意力機制應用于機器視覺并且取得了很好的效果.由于注意力機制可以實時動態地關注數據中顯著特征,賦予它們不同的權重,這使得當數據中存在多種特征,并且當數據中存在強干擾時這種機制的作用更加明顯.
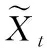
St=Ws*tanh(Wxa*Xt+Wha*Ht-1+ba)
(3)
(4)
(5)
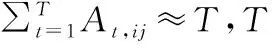
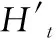
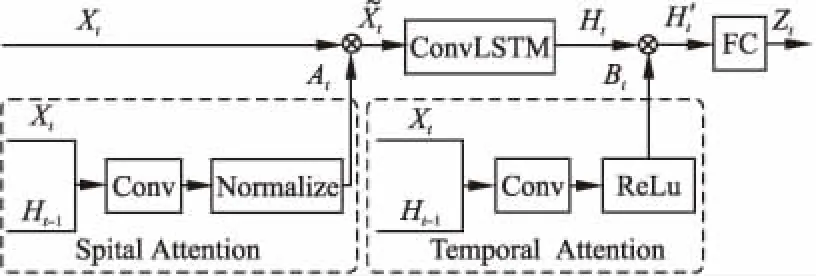
圖3 基于注意力機制的卷積長短時記憶網絡Fig.3 ConvLSTM based on attention mechanism
(6)
(7)
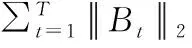
式中C為所有可能的分類數目,y=(y1,…,yC)T是數據集真實的標簽,當前視頻行為屬于第i類行為時yi=1,yj=0(j≠i).θ表示所有的模型參數,為了防止神經網絡的過度擬合也對其作了限制.
6 實驗與結果分析
本文的實驗基于UFC101[17]和HMDB51[18]兩個通用人體行為數據集,UFC101中包含了101類的13320個視頻片段,在視頻長短,行為類別,視頻背景,相機運動,攝像角度等方面有很好的多樣性.HMDB51包含51類的6766個視頻片段,其視頻片段有更大的類內差別和更小的類間差別,所以更具有挑戰性.對于這兩個數據集,都將其中80%的視頻片段作為訓練集,剩下的20%作為測試集.本文參考文獻[2]中的方法對數據集中視頻數據進行了預處理,不同之處在于將抽取的光流數據的幀數從10擴大到20.
本文選取VGG-16[19]作為時間流和空間流的卷積網絡框架,它包含13個卷積層,3個全連接層,使用在ImageNet上預訓練的模型參數對卷積神經網絡進行初始化.本文將VGG-16最后一個卷積層的數據作為Attention-ConvLSTM的輸入數據,所有的W~a和W~b均為1×1大小的卷積核,所有的Wx~和Wh~均為3×3大小的卷積核,本文在softmax層對視頻的雙流數據進行了融合.
為了更好地將本文所提出的方法與傳統方法進行比較,本文將簡單的雙流卷積,結合傳統LSTM和結合Attention-ConvLSTM的雙流卷積神經網絡在相同的數據集上進行了訓練和測試,圖4-圖6分別是以上3種網絡在UFC101和HMDB51兩個數據集上隨著迭代次數從0到300時在訓練集和測試集上的準確率曲線.
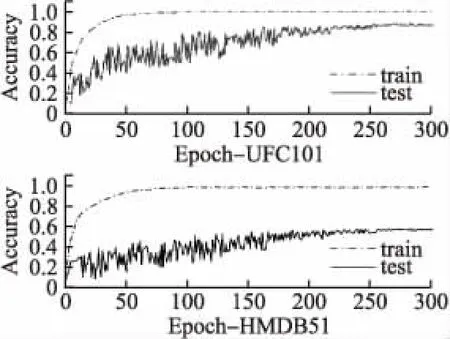
圖4 雙流卷積神經網絡的訓練準確率Fig.4 Accuracy curve of two stream ConvNet
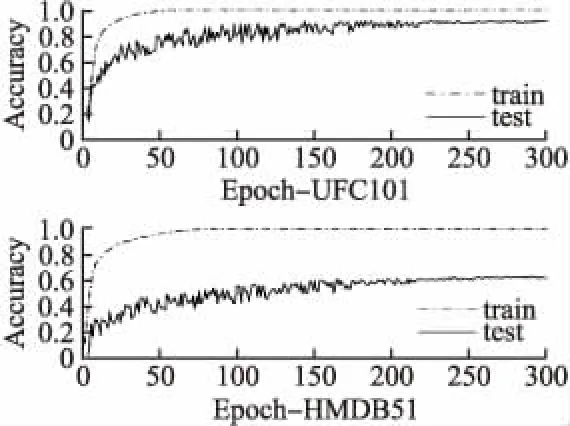
圖5 結合傳統LSTM雙流卷積神經網絡的訓練準確率Fig.5 Accuracy curve of two stream ConvNet with traditional LSTM
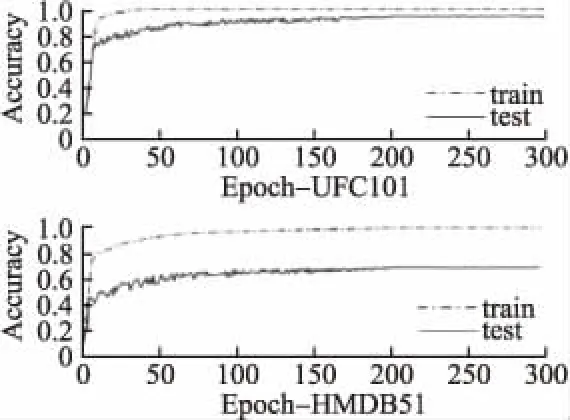
圖6 結合Attention-ConvLSTM雙流卷積神經網絡的訓練準確率Fig.6 Accuracy curve of two stream ConvNet with Attention-ConvLSTM
從圖4-圖6中可以看出,在UFC101和HMDB51上雙流卷積神經網絡的識別準確率分別為88.0%和59.4%,其結合了傳統LSTM的神經網絡識別準確率為90.3%和63.2%,結合了Attention-ConvLSTM的神經網絡識別準確率為94.6%和69.8%.改進之后的網絡也表現出了更好的收斂性,簡單的雙流卷積和結合了傳統LSTM的神經網絡在訓練集上分別經過280,250次左右的迭代才達到收斂,而結合了Attention-ConvLSTM的神經網絡經過200次左右的迭代就達到收斂.且如表1所示,本文提出的方法較其他傳統方法在識別準確率上也有較大提升.分析可知,簡單的雙流卷積網絡對于長時間范圍和具有復雜運動背景的視頻數據識別率是較低的.結合了傳統LSTM的雙流卷可以更好的利用序列幀數據之間的依賴關系積使得神經網絡的性能得到了一部分提高,結合Attention-ConvLSTM的雙流卷積可以更好地分析局部特征的空間關系,對顯著特征和關鍵幀實現更有效的利用,這使得神經網絡的性能得到進一步提高.
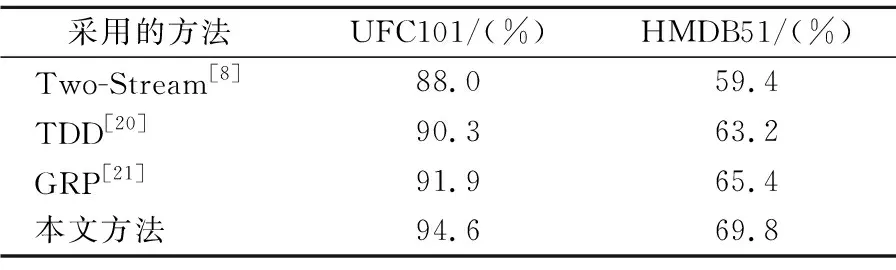
表1 不同算法在UCF101和HMDB51準確率對比Table 1 Comparison of the accuracy of the different algorithms on the UFC101 and HMDB51
7 結 論
在行為識別方面,傳統雙流卷積神經網絡在對長時間范圍及包含了復雜運動背景的視頻數據進行處理時,抽樣幀標簽分配常常出錯,識別結果基于平均預測,這導致傳統方法的識別成功率并不是很高.為了更好地利用了序列幀運動信息之間的依賴關系,本文提出將ConvLSTM和雙流卷積中的時間流結合,ConvLSTM相比傳統LSTM更能夠保留視頻數據中的空間信息.為了可以更加準確分析具有復雜運動背景的視頻數據,本文還引入了注意力機制,注意力機制使得神經網絡可以將運動信息的顯著特征和關鍵幀利用得更加充分.本文提出的新的正則交叉熵損失函數對擴展之后的網絡參數進行更好地約束.在UFC101和HMDB51數據集上的實驗結果表明本文提出的方法相比于傳統方法具有更高的識別準確率,神經網絡所需要的訓練時間也有所縮短,從而驗證了本文提出的方法的有效性.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
