基于情感增強的微博謠言檢測
2021-03-14 00:50:38奚金霞
現代計算機 2021年36期
奚金霞
(四川大學網絡空間安全學院,成都 610065)
0 引言
中國社會科學院2020年發布的《中國新媒體發展報告》指出[1]:我國網民在接收新聞信息時,傾向于通過移動端從微博、微信等社交媒體獲取信息,電視、紙媒等傳統媒體在信息傳播方面占有率大大下降。社交媒體的公開性、快捷性使人們可以隨時隨地分享自己感興趣的內容,極大地方便了信息交流,但由于消息發布的便利以及社交媒體自身審核環節的薄弱,用戶的無節制傳播促進了謠言的泛濫,在線社交網絡成為謠言傳播的重災區。謠言在傳播過程中通常會被放大和扭曲,引起受眾恐慌,嚴重時甚至會威脅社會的和諧穩定。因此,不論是對于網絡環境的凈化,還是社會穩定的維護,都迫切需要技術手段自動化檢測信息內容的真實性,從而促進在線社交媒體上謠言的快速有效識別。
為了及時鑒別謠言,遏制其傳播,業界做了大量的努力與嘗試。早期基于淺度機器學習的謠言檢測采用特征手動提取結合機器學習算法的方法,主要圍繞如何選擇和提取有效的特征來區分謠言和非謠言而展開[3],所提取的特征通常分為四種類型:基于內容的特征,如句子長度、情感詞數等[2];基于用戶的特征,如是否認證、用戶類型等[16];基于主題的特征(即前兩個特征集的聚合),如集合中積極和消極情緒的比例等[5];基于傳播的特征,如傳播樹的深度、廣度等[8]。之后,一部分研究探索了上述特征隨時間變化的動態特性[3,6],提出了基于時間序列的謠言檢測方法。然而,基于淺度機器學習的謠言檢測方法嚴重依賴于初期的人工特征工程,難以獲取高維、復雜的數據特征[11],模型性能提升受限。為了解決這個問題,研究者們將深度學習引入謠言檢測領域。循環神經網絡RNN 最先被用來學習文本的時間序列特征[4],但RNN 在訓練過程中存在梯度消失的問題,因而只能適應短文本中上下文依賴關系的學習。于是研究者們提出了用長短期記憶網絡LSTM 和門限遞歸單元GRU[4,11]來解決梯度消失問題,實現了文本長距離依賴關系的捕捉。之后,在圖像領域表現較好的卷積神經網絡CNN 又被引入用于提取謠言全局特征[10,12-13],實驗證明該方法能有效地識別謠言且有助于實現謠言早期檢測。上述基于深度學習的謠言檢測方法傾向于使用神經網絡自動學習文本的上下文語義特征來判定待檢測信息的可信度。然而,根據Vosoughi等人[14]的研究,人們對于謠言事件和真實事件的情感反應是不同的,謠言事件中群體反應多為恐懼、厭惡和驚訝等消極情緒,而真實事件多引發期待、喜悅和信任等積極情緒。相對于語義特征,文本中所攜帶的情感特征是區分謠言和非謠言更有效的特征[15]。因此,如何充分提取文本中的情感特征以提高謠言檢測效率是本文研究的重點。除此之外,對于不同類型的信息,使用不同的特征進行模型訓練將得到不同的結果。如Ro?sas 等人[9]發現對于教育、政治等嚴肅話題,需要重點關注信息中的語言特征,而對于明星類話題,則應該給予用戶情感觀點更多的關注。然而現有工作大多通過獲取一套通用的特征集合來表征所有的網絡數據,對數據集中的微博信息類型缺少必要的分析,忽略了不同類型數據的個性化特征,導致難以挖掘隱藏在異質數據中的高價值信息。因此,如何有效提取不同類型信息中的細粒度數據特征,也是本文研究的重點。
針對上述問題,本文選取新浪微博作為重點研究對象,將謠言檢測任務拆分為微博類型檢測、情感增強、謠言分類三個子任務,充分考慮情感特征對于謠言檢測的重要性,區分待檢測信息的類型。本文的主要貢獻概括如下:
(1)將情感融入預訓練模型來幫助識別不實信息。該方法在文本向量化過程中側重于提取文本內容中的情感極性特征,能有效增強文本建模中情感特征的表現能力。
(2)針對不同類型的微博信息,基于情感文本編碼結果,分類別構建分類器,挖掘更細粒度、更有效的特征來區分謠言和非謠言,進一步提高整個模型的檢測準確率。
1 基于情感增強的謠言檢測模型
本節主要介紹我們提出的基于情感增強的謠言檢測模型。如圖1所示,本文提出的基于情感增強的謠言檢測模型由三部分構成:微博類型分類器、情感增強編碼器、謠言分類器。在檢測過程中,首先根據微博原帖文本對待檢測微博進行類型分類,然后通過情感編碼器獲得微博文本(原帖、轉發、評論)的情感增強向量,最后輸入到對應類型的謠言分類器中得到謠言與否的分類結果。

圖1 基于情感增強的謠言檢測模型
1.1 微博類型分類器
考慮到多數微博原帖文本長度短、包含信息少等特點,本文選取Google 提出的預訓練語言模型BERT對原帖文本進行建模。因為BERT利用多層的Transformer 作為基本的編碼器,通過selfattention 機制在大量無監督數據上進行自監督訓練,其內部已充分學習到常用語料的語法和句法知識,具有強大的語義表征能力。文本的編碼過程如圖2 所示,其中e1,…,en為輸入向量,T1,…,Tn為輸出向量。

圖2 BERT模型結構
具體地,對于給定的微博原帖文本序列:
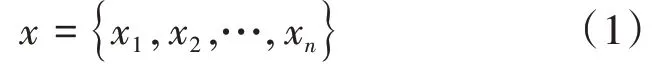
其中xi表示文本序列的第i個字符。考慮到微博類型分類器實現的是對單個微博原帖文本的分類,所以我們將句子分割向量EA置為0,并獲取每個字位置嵌入符xi Pi和詞嵌入Ei形成字符的表示,位置嵌入Pi的計算具體如下:

其中i表示字符在句子中的位置,2j和2j+ 1 分別表示詞向量的偶數和奇數維度,d表示詞向量的維度。我們分別對每個字符的三個向量求和,作為最終的輸入向量。之后我們將輸入到堆疊的Transformer 編碼器和解碼器中,取最后的輸出成為最終的語義上下文編碼,最后連接Softmax層產生微博類型概率分布:

其中,wc和bc表示參數向量和偏置,xe為微博原帖的向量表示。得到類型概率分布后,取概率值最大的為預測結果,后續依此結果將數據輸入到對應的謠言分類器中。
1.2 情感增強編碼器
在情感編碼器構建階段,我們對數據集中的文本進行了情感標注,然后選出相近數量的積極情感文本和消極情感文本,基于BERT 進行情感分類,并固定模型參數形成情感編碼增強編碼器EBERT,它以情感學習為目標,所以對于文本情感特征的捕捉更加敏銳。情感分類模型的設計與微博類型分類器相同。在句向量表示階段,具體地,對于待檢測微博m中的所有文本:


再輸入到多層帶有多頭注意力機制的Trans?former 中,將xei分別與矩陣WQ、WK、WV相乘,得到查詢矩陣Q、鍵矩陣K、值矩陣V,以此計算自注意力:

其中dK為向量維度。接著計算多頭注意力結果:

多頭注意力輸出結果經殘差計算和標準化后,輸入全連接層。經過n層編碼器訓練后,我們提取倒數第二層Transformer 的輸出作為最終句向量的表示。整個句向量的表示過程可公式化為:

最后,將微博中所有句向量縱向拼接形成待檢測微博m的整體表示:

1.3 謠言分類器
TextCNN[29]是Yoon Kim 提出的一種用于處理文本分類問題的卷積神經網絡,與CNN 從上到下、從左到右滑動進行特征提取不同的是,TextCNN 僅存在豎直方向的滑動,其核心思想是捕捉文本局部特征。對于單條文本來說,局部特征是由若干詞組成的滑動窗口,通過學習可以得到文本上下文聯系,而對于本文所要檢測的微博來說,局部特征是若干評論/轉發組成的滑動窗口,通過學習可以得到微博中評論/轉發文本之間的聯系。綜上所述,在構建本文的謠言分類器時,TextCNN 是一個合適的選擇。該模塊的模型結構如圖3所示。
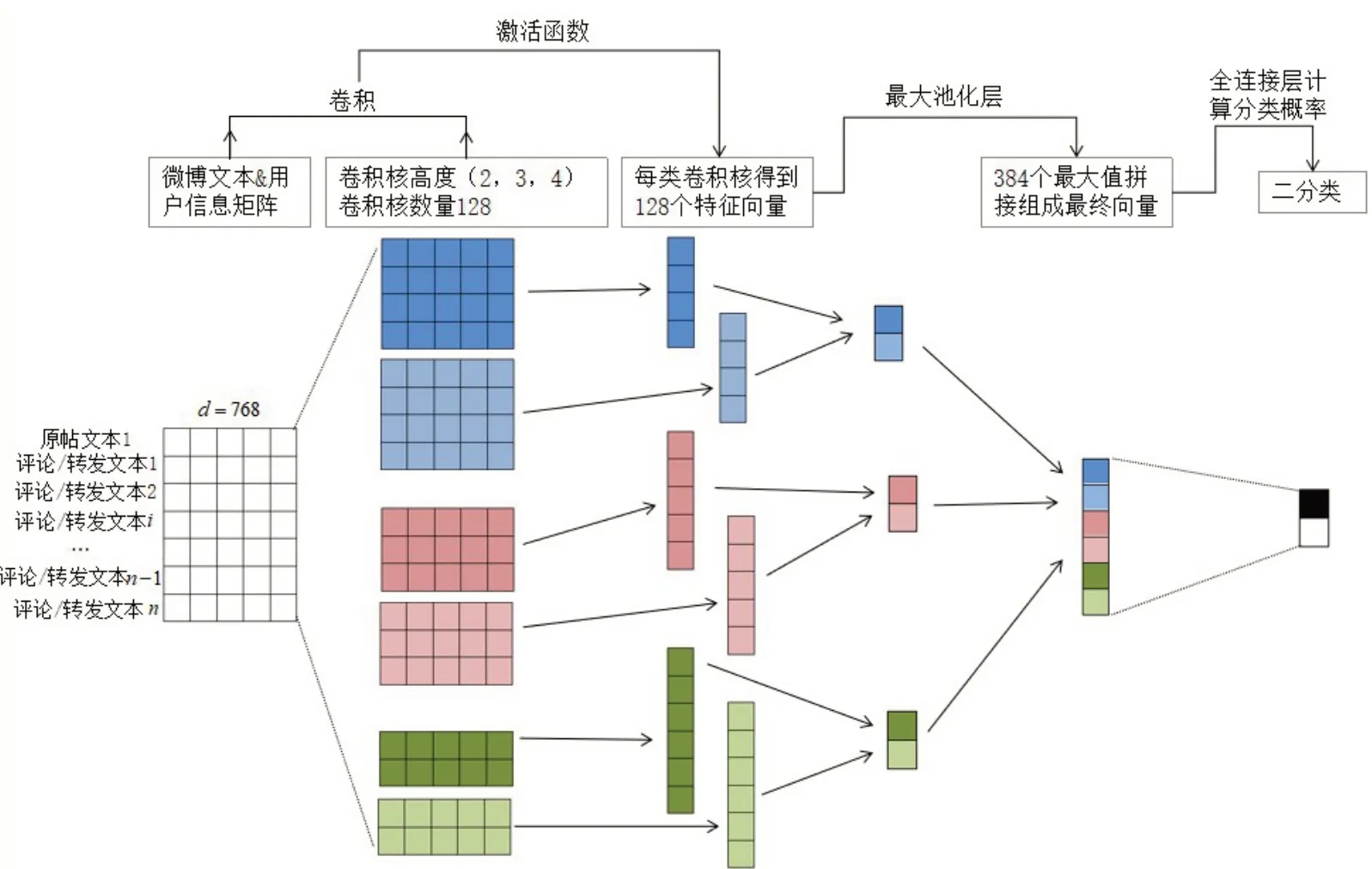
圖3 謠言分類模塊架構
2 實驗與分析
2.1 數據集
在目前的謠言檢測研究中,很少有工作考慮到微博信息類型對謠言檢測的影響,現存公開數據集不能滿足本文實驗的需求。因此,我們選擇在新浪微博平臺上構建自己的數據集。新浪微博平臺將微博信息分為社會、科技、財經、歷史等49 類,我們對新浪微博管理平臺上的謠言進行了類別統計,發現謠言多產生于社會、國際、明星、健康類。因此,我們僅收集這四類微博數據驗證本文方法的有效性,微博類型分類模塊所使用的數據集如表1 所示。之后我們在Ma①https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0和Liu②https://github.com/thunlp/Chinese_Rumor_Dataset/的新浪微博公開數據集上進行了驗證,數據集的具體情況如表2所示。

表1 微博類型分類所使用數據集概述

表2 數據集中謠言與非謠言分布情況
2.2 實驗設置
本文使用準確率、精確率、召回率和F1值作為評估指標。在模型的實現上,微博類型分類器、情感增強編碼器及其他對比實驗所使用的預訓練模型均基于BERT 中文預訓練模型BERTBase-Chinese,模型結構為:12-layer, 768-hid?den, 12-heads, 110M parameter,超參數設置為:batch size 為24,學習率為3e-5、最大句子長度128。謠言分類器使用TextCNN,其中卷積核高度為[2,3,4],卷積核數量為128,Dropout 為0.5,batch size 為20,學習率為1e-3,使用ReLU 作為激活函數,使用交叉熵作為模型的損失函數。
2.2.1 對比方法
(1)無情感增強和分類。移除微博類型分類器,用BERT-Base-Chinese 代替EBERT 獲得文本編碼,再將所有類型數據不加區分地輸入到TextCNN謠言分類器中。
(2)僅分類。在對文本進行建模時,用BERT-Base-Chinese 代替EBERT 獲得文本編碼,再輸入到對應類型的TextCNN謠言分類器中。
(3)僅情感增強。移除微博類型分類器,使用EBERT 獲得情感增強文本編碼,再將所有類型數據不加區分地輸入到TextCNN謠言分類器中。
(4)本文方法。使用微博類型分類器對微博進行分類,使用EBERT 獲得情感增強文本編碼,再輸入到對應類型的TextCNN謠言分類器中。
2.2.2 實驗結果及分析
表3、表4列出了實驗結果,觀察分析后可得出如下結論:

表3 rumdect數據集實驗結果

表4 CED_Dataset數據集實驗結果
(1)在我們的實驗中,分類或情感增強任一模塊的加入都使得模型四個指標有不同程度的提高,證明各類別信息特征的細粒度提取和情感特征充分提取能有效提升模型的性能。
(2)同時引入分類和情感增強模塊的模型在兩個數據集上均達到最高性能,召回率均提升5%以上,說明所提出模型能有效識別虛假信息,減少謠言漏報率。
3 結語
針對現有方法忽略謠言文本情感特征和特征提取粗粒度的問題,本文提出了基于情感增強的謠言檢測方法。借助預訓練模型強大的文本語義表征能力,以情感檢測為導向構建情感增強編碼器,充分提取文本中的語義和情感信息。并分類別構建謠言分類器,更深層次捕捉各類別信息的細粒度特征,實現全方位多層次的數據特征提取。在公開數據集上的實驗結果表明,引入情感增強和微博類型分類后的謠言檢測模型性能大幅提升,充分證明了本文方法的有效性。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
