基于低秩行為信息和多尺度卷積神經(jīng)網(wǎng)絡(luò)的人體行為識別方法
2021-03-18 13:45:14
計(jì)算機(jī)應(yīng)用 2021年3期
(長江師范學(xué)院電子信息工程學(xué)院,重慶 408100)
0 引言
人體行為識別是利用計(jì)算機(jī)視覺技術(shù)處理視頻內(nèi)容的一個(gè)重要研究方向[1],是讓機(jī)器學(xué)會(huì)“察言觀色”的第一步,在安防、人機(jī)交互和視頻檢索等領(lǐng)域具有重要的研究和應(yīng)用價(jià)值。近年來,越來越多的學(xué)者和機(jī)構(gòu)投入到這項(xiàng)工作的研究當(dāng)中,他們嘗試使用各種方法來實(shí)現(xiàn)基于計(jì)算機(jī)視覺的行為識別技術(shù),并取得了不錯(cuò)的效果,具體的方法和文獻(xiàn)將在第1 章相關(guān)工作里詳細(xì)分析。這些行為識別方法可大致分為兩類:一是基于傳統(tǒng)分類方法的行為識別技術(shù);二是基于深度學(xué)習(xí)的行為識別技術(shù)。結(jié)合這兩類方法的優(yōu)點(diǎn),當(dāng)前行為識別技術(shù)主流的研究方向是使用人工提取特征結(jié)合深度學(xué)習(xí)的方法[2-3],然而由于人體行為本身的復(fù)雜性,且人體行為容易受到復(fù)雜背景、遮擋、光線等環(huán)境因素的干擾,目前的特征提取方法大多步驟繁瑣,容易產(chǎn)生誤差傳遞,且對動(dòng)作相對緩慢或靜止的行為很難有效建模,此外單一尺度的卷積神經(jīng)網(wǎng)絡(luò)不能從多角度充分描述人體行為特征,不利于最終的行為識別。
針對這些問題,本文提出了一種基于低秩行為信息(Lowrank Action Information,LAI)和多尺度卷積神經(jīng)網(wǎng)絡(luò)(Multiscale Convolutional Neural Network,MCNN)的人體行為識別方法。本文以包含人體行為的視頻序列為研究對象,首先提取行為視頻中的低秩行為信息(LAI),相較光流特征,LAI 不需要相鄰幀之間位移要比較小和人體目標(biāo)在不同幀間運(yùn)動(dòng)時(shí)其亮度不發(fā)生改變等假設(shè),且能很好地捕獲視頻中人體行為的時(shí)空信息。然后,針對LAI的特點(diǎn),設(shè)計(jì)了多尺度卷積神經(jīng)網(wǎng)絡(luò)(MCNN)以進(jìn)一步提取LAI中的行為特征,最終實(shí)現(xiàn)了該模型下的人體行為識別,為行為識別技術(shù)提供了一種新的解決方案,進(jìn)一步提高了行為識別準(zhǔn)確率,促進(jìn)了該技術(shù)的實(shí)用化進(jìn)程。
1 相關(guān)工作
基于傳統(tǒng)分類方法的行為識別技術(shù)是將行為識別看作是一個(gè)行為分類問題,主要分為行為特征提取和行為分類兩個(gè)步驟。這類方法的特點(diǎn)是人工從視頻序列中提取人體行為特征,然后利用分類器對特征進(jìn)行分類。通過多年的研究,研究者們提出了許多優(yōu)秀的特征提取方法。Han 等[4]利用稀疏幾何特征來提取人體輪廓及內(nèi)部信息。Hoshino 等[5]采用光流法提取視頻序列中的運(yùn)動(dòng)信息,首先計(jì)算連續(xù)幀間的光流場,然后采用非重疊的時(shí)空網(wǎng)格對光流場進(jìn)行細(xì)分,并累計(jì)每個(gè)網(wǎng)格內(nèi)的光流幅度作為網(wǎng)格的特征表示。Tripathi等[6]利用基于梯度信息的方向梯度直方圖特征描述子進(jìn)行人體行為識別。Wang 等[7]提出了稠密軌跡方法,其思路是利用光流場來獲得視頻序列中的一些軌跡,再沿著軌跡提取光流直方圖(Histogram Of Flow,HOF)、方向梯度直方圖(Histogram of Oriented Gradient,HOG)、運(yùn)動(dòng)邊界直方圖(Motion Boundary Histogram,MBH)和trajectory 4 種特征。在提取到行為特征后,這類方法通常將特征輸入到K近鄰分類器、相關(guān)向量機(jī)(Relevance Vector Machine,RVM)和支持向量機(jī)(Support Vector Machine,SVM)等分類器進(jìn)行行為分類。
近年來,深度學(xué)習(xí)方法逐漸被應(yīng)用到人體行為識別中,并取得了更好的效果,具有代表性的方法有:1)Simonyan 等[8]提出的雙流卷積神經(jīng)網(wǎng)絡(luò)方法,該網(wǎng)絡(luò)分為兩條支路,一條支路處理RGB 圖像,另一條支路處理光流圖像,然后再聯(lián)合訓(xùn)練,最后將兩條支路識別結(jié)果按權(quán)重融合。2)TSN(Temporal Segment Network)[9],該方法是雙流卷積神經(jīng)網(wǎng)絡(luò)的改進(jìn)網(wǎng)絡(luò),用以解決雙流卷積神經(jīng)網(wǎng)絡(luò)不能對長時(shí)間的視頻進(jìn)行建模的問題。Du 等[10]提出的RPAN(Recurrent Pose-Attention Network),首先用Two-Stream 的方法生成特征,然后引入姿態(tài)注意機(jī)制,最后用長短期記憶(Long Short-Term Memory,LSTM)網(wǎng)絡(luò)完成行為識別。3)C3D(3-Dimensional Convolution)[11],利用三維卷積核對行為視頻進(jìn)行處理。這些模型被提出之后,又有很多學(xué)者在其基礎(chǔ)上進(jìn)行了改進(jìn)并取得了較好的效果[12]。深度學(xué)習(xí)的引入在一定程度上降低了對人工提取行為特征的依賴,其識別效果特別是復(fù)雜背景下的識別效果有了不錯(cuò)的提升。
傳統(tǒng)方法在基于深度學(xué)習(xí)的方法出現(xiàn)之前是行為識別的主要方法,也取得了不錯(cuò)的識別性能,但在一些復(fù)雜場景的數(shù)據(jù)庫上很難取得令人滿意的效果。基于深度學(xué)習(xí)的方法中多是基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)發(fā)展而來。CNN在圖像處理應(yīng)用中取得了巨大成功,為視頻處理提供了很好的參考;但相較圖像處理,視頻處理多了一個(gè)時(shí)間維度,存在視頻幀數(shù)多、場景復(fù)雜等困難。針對這些問題,上述方法通常將傳統(tǒng)行為特征與深度學(xué)習(xí)網(wǎng)絡(luò)相結(jié)合進(jìn)行人體行為識別,其中比較有效的方法是提取行為視頻的光流信息作為深度學(xué)習(xí)網(wǎng)絡(luò)的輸入,進(jìn)而實(shí)現(xiàn)人體行為識別。然而,在提取光流特征的過程中,當(dāng)視頻中人體行為相對緩慢或暫時(shí)靜止時(shí),將無法提取到運(yùn)動(dòng)信息;而且光流特征通常只是具有運(yùn)動(dòng)的那部分人體而非整個(gè)人體,因此難有人體形態(tài)的整體輪廓,這樣的網(wǎng)絡(luò)輸入極大地影響了復(fù)雜場景中的行為識別效果;此外,單一尺度的卷積神經(jīng)網(wǎng)絡(luò)不能提取不同感受野下的人體行為特征,影響了人體行為的識別率。
2 基于LAI和MCNN的行為識別框架
本文通過學(xué)習(xí)視頻幀間的數(shù)據(jù)分布來提取視頻中人體行為的LAI。首先,將原始行為視頻分割為N段,分別對每小段視頻進(jìn)行低秩學(xué)習(xí)得到每小段視頻的LAI;然后,在時(shí)間軸上進(jìn)行串聯(lián)成整個(gè)行為視頻的LAI。針對視頻中LAI的特點(diǎn),設(shè)計(jì)MCNN 模型,通過多尺度卷積核提取不同感受野下的行為信息,再結(jié)合各卷積層、池化層和全連接層進(jìn)一步提取LAI中的行為特征,進(jìn)而實(shí)現(xiàn)視頻中人體行為的識別。完整的行為識別框架如圖1所示。

圖1 行為識別框架Fig.1 Framework of action recognition
3 低秩行為信息
通過深入挖掘視頻幀間的數(shù)據(jù)分布,利用魯棒主成分分析(Robust Principal Component Analysis,RPCA)方法進(jìn)行非嚴(yán)格意義下的低秩稀疏分解,實(shí)現(xiàn)視頻序列中的人體低秩行為信息提取。
RPCA 方法其本質(zhì)是尋找高維數(shù)據(jù)在低維空間上的最佳映射。假設(shè)存在一個(gè)數(shù)據(jù)矩陣X∈Rp×q可以分解為一個(gè)低秩矩陣T與一個(gè)稀疏誤差矩陣S之和。RPCA 方法可以描述為如下的最優(yōu)化問題[13]:

其中:rank(?)表示求秩運(yùn)算,‖ ? ‖1表示l1范數(shù)計(jì)算的是數(shù)據(jù)中各元素絕對值之和,規(guī)則化參數(shù)λ通常為:

假設(shè)視頻序列的一幀圖像的尺寸是h×u,幀數(shù)為q。如圖2 所示,首先將每幀圖像拉成一個(gè)長度為h×u的列向量,并依次堆疊成數(shù)據(jù)矩陣X∈Rp×q,其中p=h×u,q為視頻的幀數(shù)。然后采用式(1)和式(2)對X進(jìn)行低秩學(xué)習(xí),從得到的低秩矩陣中抽取一個(gè)列向量進(jìn)行圖像還原即得到低秩信息圖像。圖2 以一段奔跑視頻為例,其低秩學(xué)習(xí)結(jié)果如圖2(b)所示,遺憾的是該結(jié)果沒有成功提取出視頻中的行為信息。通過研究發(fā)現(xiàn)問題在于式(2)的λ取值,經(jīng)過反復(fù)實(shí)驗(yàn),得出有效的λ值為式(3)所示:

其中K的具體取值將依據(jù)具體的數(shù)據(jù)集而定。運(yùn)用式(3)學(xué)習(xí)到的結(jié)果如圖2(c)所示。圖3為幾個(gè)自然場景中人體行為的低秩學(xué)習(xí)結(jié)果示例。

圖2 視頻序列低秩學(xué)習(xí)過程Fig.2 Low-rank learning process of video sequence

圖3 其他低秩學(xué)習(xí)結(jié)果示例Fig.3 Examples of other low-rank learning results
為了捕獲人體運(yùn)動(dòng)的時(shí)間信息,將各視頻段的低秩學(xué)習(xí)結(jié)果在時(shí)間方向上進(jìn)行堆疊,其示意圖如圖4 所示,以最終實(shí)現(xiàn)捕獲視頻中人體行為的時(shí)空信息,即LAI,并將此作為多尺度跨通道卷積神經(jīng)網(wǎng)絡(luò)的輸入數(shù)據(jù)。

圖4 低秩行為信息生成Fig.4 Generation of low-rank action information
對比圖2(c)和圖4(c)可以發(fā)現(xiàn),圖2(c)捕獲了整個(gè)視頻序列中的人體行為信息,并整合到了一張圖像上,圖像呈現(xiàn)了人體來回運(yùn)動(dòng)軌跡和運(yùn)動(dòng)分布信息,圖4(c)由于捕獲的是分段視頻序列中的行為信息,其中人體行為比較集中,干擾小,因而每個(gè)低秩行為信息更加明顯,同時(shí)在時(shí)間上進(jìn)行堆疊后也捕獲了圖2(c)沒有的時(shí)間信息,更適合作為后續(xù)MCNN 的輸入。
4 MCNN模型
4.1 MCNN模型結(jié)構(gòu)
針對人體行為LAI的特點(diǎn)設(shè)計(jì)了MCNN 模型,以提取LAI中的行為特征并完成人體行為的識別。人們在觀察事物時(shí)通常會(huì)略看不重要的部分,視線移動(dòng)較快,重要的部分會(huì)仔細(xì)觀察,視線移動(dòng)較慢。為了模擬這一現(xiàn)象,以獲取不同感受野下的運(yùn)動(dòng)信息。模型對低秩行為信息采取1×1、3×3 和5×5 三個(gè)尺寸的卷積核進(jìn)行特征提取,相同尺寸下采用4個(gè)不同的卷積核進(jìn)行運(yùn)算,以獲取4個(gè)不同方向上的特征信息。經(jīng)過三個(gè)尺寸卷積核運(yùn)算后,尺寸為1×1 的卷積核提取的特征圖尺寸最大,3×3卷積核的特征圖次之,5×5卷積核的特征圖最小。為了便于后續(xù)層處理,將3×3和5×5卷積核的特征圖通過邊緣補(bǔ)零至與1×1卷積核的特征圖的相同尺寸。將補(bǔ)零后的特征圖與1×1 卷積核的特征圖一起經(jīng)過2×2 的最大池化層以壓縮特征圖,然后用兩個(gè)3×3的卷積核進(jìn)行卷積后再通過2×2的池化層進(jìn)一步提取特征,網(wǎng)絡(luò)模型中在每個(gè)卷積層結(jié)束后均使用線性整流單元(Rectified Linear Unit,ReLU)進(jìn)行激活,最后連接兩個(gè)全連接層并通過sigmoid函數(shù)輸出行為類別。具體網(wǎng)絡(luò)模型結(jié)構(gòu)如圖5 所示,為了使圖像簡潔,只給出了第一幀特征圖的操作示意圖,同一層的其他特征圖做類似操作。
4.2 網(wǎng)絡(luò)模型的訓(xùn)練
將低秩行為信息與多尺度跨通道卷積神經(jīng)網(wǎng)絡(luò)模型融合,行為視頻的分割段數(shù)N對整個(gè)模型的訓(xùn)練非常重要,將極大地影響網(wǎng)絡(luò)模型的計(jì)算速度和識別效果。此外,在N一定的情況下,多尺度跨通道卷積神經(jīng)網(wǎng)絡(luò)模型中各層的最佳權(quán)重參數(shù)還與具體的行為數(shù)據(jù)集有關(guān),不同的數(shù)據(jù)集,其視頻幀的尺寸和數(shù)量都不一致,這些參數(shù)將針對具體的數(shù)據(jù)集在訓(xùn)練得到。在訓(xùn)練模型時(shí),首先設(shè)定整個(gè)模型的損失函數(shù),假設(shè)有L個(gè)帶標(biāo)簽樣本{z1,y1},{z2,y2},…,{zL,yL},此標(biāo)簽為oneof-c標(biāo)簽,其中:

對于樣本zl,設(shè)網(wǎng)絡(luò)模型的輸出為ol,定義其誤差為:

則網(wǎng)絡(luò)模型的整體損失函數(shù)定義為:

設(shè)W為所有網(wǎng)絡(luò)模型參數(shù)組成的向量,則最優(yōu)的一組參數(shù)W*定義為:

在具體參數(shù)優(yōu)化時(shí),若用EL對所有參數(shù)直接求解時(shí)仍然非常復(fù)雜,因此考慮先用EL對輸入的加權(quán)和求導(dǎo),再用輸入加權(quán)和對參數(shù)求導(dǎo)。
定義好網(wǎng)絡(luò)模型的損失函數(shù)后,擬采用交替訓(xùn)練方法對整個(gè)模型進(jìn)行訓(xùn)練,即在固定視頻分割段數(shù)N的情況下,采用上述方式訓(xùn)練MCNN模型,之后再固定網(wǎng)絡(luò)模型參數(shù),改變分割段數(shù)N的取值,最小化模型損失函數(shù),計(jì)算此時(shí)最佳N的取值,以此方法反復(fù)多次交替訓(xùn)練模型,得出特定數(shù)據(jù)集下整個(gè)模型的最優(yōu)參數(shù)組合。
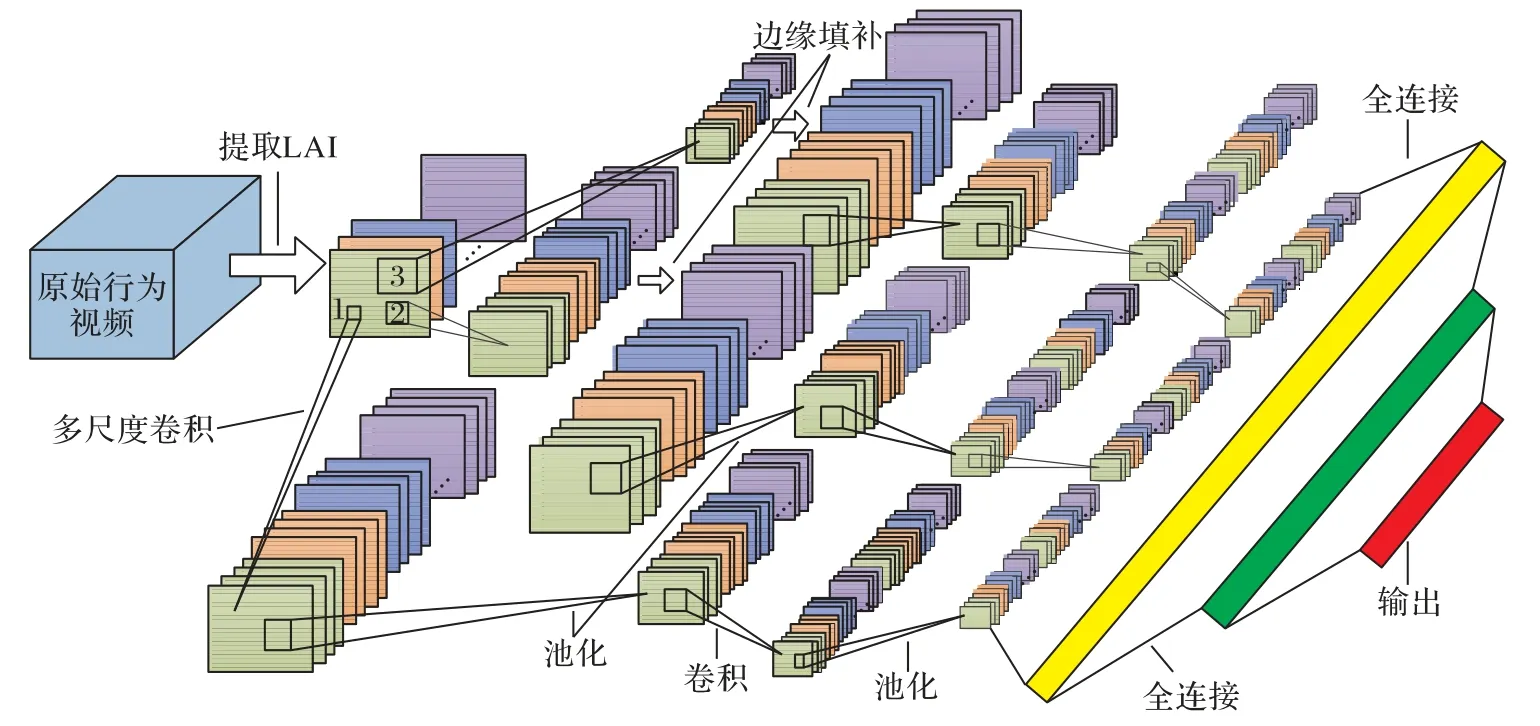
圖5 MCNN結(jié)構(gòu)Fig.5 Structure of MCNN
5 實(shí)驗(yàn)結(jié)果與分析
為了驗(yàn)證所提出方法的行為識別性能,在兩個(gè)具有代表性的基準(zhǔn)數(shù)據(jù)庫KTH和HMDB51上進(jìn)行行為識別實(shí)驗(yàn)。
KTH 數(shù)據(jù)庫[14]是行為識別技術(shù)中流行的數(shù)據(jù)庫之一。該數(shù)據(jù)庫共記錄了四種不同的場景下完成6 種行為,分別由25 位志愿者完成,共計(jì)599 個(gè)行為視頻。HMDB51 數(shù)據(jù)庫是由Kuehne 等[15]提供。該數(shù)據(jù)庫共記錄了51 種人體行為,每類行為又收集了不少于101 個(gè)的視頻序列。該數(shù)據(jù)庫中的行為視頻行為類別多、行為樣本數(shù)多、挑戰(zhàn)性大。
首先,在上述兩個(gè)數(shù)據(jù)庫上對每個(gè)行為視頻提取其LAI,之后將提取到的LAI輸入到MCNN中,采用3.2節(jié)所述的交替訓(xùn)練方法對整個(gè)模型進(jìn)行訓(xùn)練。在訓(xùn)練過程中,通過計(jì)算每個(gè)數(shù)據(jù)庫上不同參數(shù)組合的識別性能,以確定最優(yōu)性能下的參數(shù)組合。圖6 和圖7 分別展示了兩個(gè)數(shù)據(jù)庫上不同參數(shù)組合得出的識別性能。從圖6、7 中可以看到,KTH 數(shù)據(jù)庫上的最優(yōu)參數(shù)組合為K=1.25,N=10;HMDB51 數(shù)據(jù)庫上的最優(yōu)參數(shù)組合為K=1.30,N=15。以上參數(shù)組合可為其他數(shù)據(jù)庫和實(shí)際應(yīng)用中的參數(shù)取值提供參考,根據(jù)反復(fù)實(shí)驗(yàn)可知,實(shí)際應(yīng)用中由于行為數(shù)據(jù)差異,參數(shù)組合會(huì)存在一定差別,但參數(shù)的大致取值范圍應(yīng)為:K為[1.0,1.5],N為[5,20],可根據(jù)具體情況計(jì)算不同參數(shù)組合的識別性能,以最終確定最優(yōu)的參數(shù)組合。
最后將訓(xùn)練好的網(wǎng)絡(luò)模型進(jìn)行測試,測試過程中采用了留一法交叉驗(yàn)證測試方法,確保了訓(xùn)練集與測試集的獨(dú)立性。經(jīng)過統(tǒng)計(jì),所提方法在KTH 數(shù)據(jù)庫上達(dá)到了97.33%的行為識別率,在HMDB51 數(shù)據(jù)庫上達(dá)到了72.05%的行為識別率,圖8 和圖9 分別為KTH 和HMDB51 數(shù)據(jù)庫上得到的混淆矩陣。圖9 中,由于行為類別有51 類,用數(shù)字1 至51 分別代表51 類行為,具體行為名稱分別為:brush-hair,cartwheel,catch,chew,clap,climb,climb-stairs,dive,draw-sword,dribble,drink,eat,fall-floor,fencing,flic-flac,golf,handstand,hit,hug,jump,kick-ball,kick,kiss,laugh,pick,pour,pull-up,punch,push,pushup,ride-bike,ride-horse,run,shake-hands,shoot-ball,shootbow,shoot-gun,sit,sit up,smile,smoke,somersault,stand,wingbaseball,sword-exercise,sword,talk,throw,turn,walk,wave.
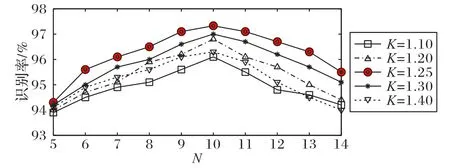
圖6 KTH數(shù)據(jù)庫上不同參數(shù)組合的識別性能Fig.6 Recognition performance of different parameter combinations on KTH database
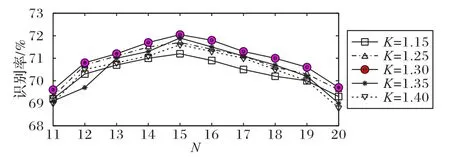
圖7 HMDB51數(shù)據(jù)庫上不同參數(shù)組合的識別性能Fig.7 Recognition performance of different parameter combinations on HMDB51 database

圖8 KTH數(shù)據(jù)庫上的混淆矩陣Fig.8 Confusion matrix on KTH database
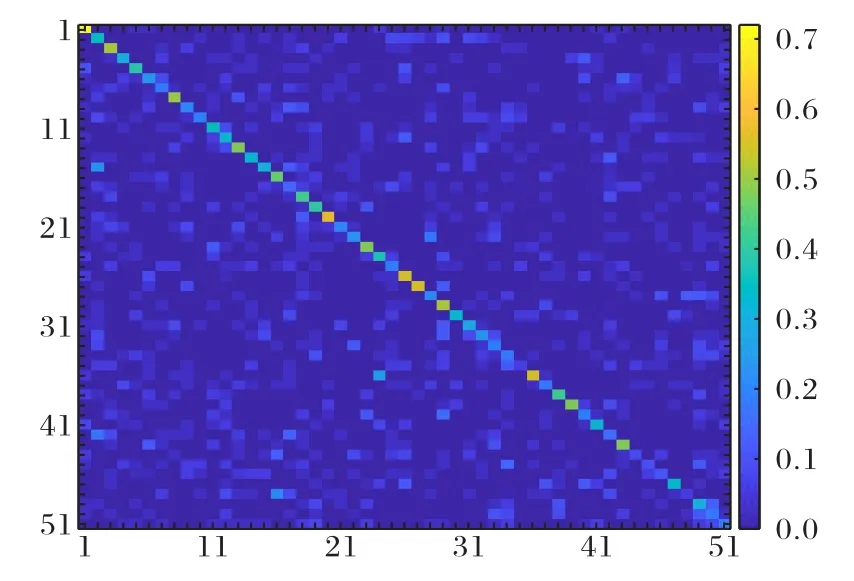
圖9 HMDB51數(shù)據(jù)庫上的混淆矩陣Fig.9 Confusion matrix on HMDB51 database
從圖8 和圖9 可以看出,在KTH 數(shù)據(jù)庫上“慢跑”和“快跑”之間最容易發(fā)生混淆,這主要是由于跑步的快、慢界限很難把握。HMDB51數(shù)據(jù)庫較為復(fù)雜,其中行為種類多,場景復(fù)雜多樣,相近行為之間容易混淆,這也是該數(shù)據(jù)庫挑戰(zhàn)性大的原因,但就總體而言,本文所提方法取得了較好的識別性能。
為了全面評價(jià)所提出方法的行為識別性能,進(jìn)行了三組對比實(shí)驗(yàn)。第一組是首先對行為視頻提取光流信息,然后將光流信息輸入MCNN 計(jì)算在KTH 和HMDB51 數(shù)據(jù)庫上的識別性能,并與本文方法進(jìn)行對比。第二組是對比MCNN 與傳統(tǒng)CNN 及支持向量機(jī)(SVM)的性能,將行為視頻的LAI 分布輸入CNN 和把LAI 直接拉成向量后輸入SVM,其中CNN 為LeNet5網(wǎng)絡(luò),分別計(jì)算兩種方法在兩個(gè)數(shù)據(jù)庫上的識別性能,并與本文方法的識別結(jié)果進(jìn)行對比。第三組是比較其他行為識別方法與本文所提方法的識別性能。
表1展示了光流+MCNN、LAI+SVM 和LAI+CNN 與本文提出方法在兩個(gè)數(shù)據(jù)庫上的對比結(jié)果,結(jié)果表明本文提出的LAI+MCNN 的方法在兩個(gè)數(shù)據(jù)庫上均取得了更好的識別效果。表2 和表3 分別列舉了本文方法與相近方法[16-27]在KTH和HMDB51 上的識別性能對比,這些相近方法均采用了人工提取特征與深度學(xué)習(xí)網(wǎng)絡(luò)相結(jié)合的方式進(jìn)行人體行為識別。從結(jié)果可以看出,本文方法在兩個(gè)數(shù)據(jù)庫上均取得了最優(yōu)的識別性能,同時(shí)較文獻(xiàn)[21]方法和文獻(xiàn)[27]方法分別提高了0.67 和1.15 個(gè)百分點(diǎn)。上述三組對比實(shí)驗(yàn)驗(yàn)證了本文所提方法的有效性。

表1 兩個(gè)數(shù)據(jù)庫上不同方法組合的識別率對比 單位:%Tab.1 Recognition rate comparison of different combinations of methods on two databases unit:%
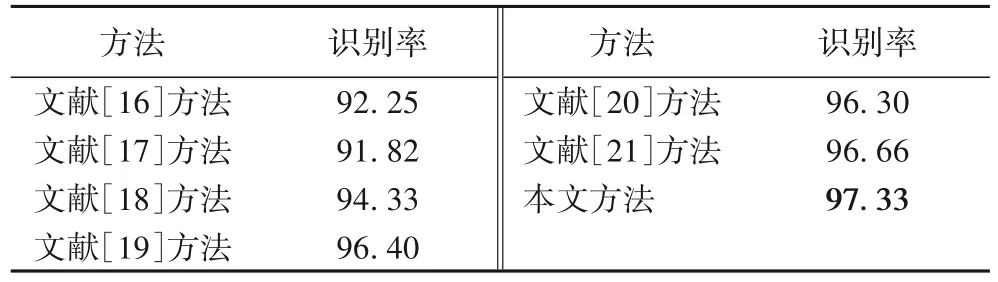
表2 KTH數(shù)據(jù)庫上不同方法的識別率對比 單位:%Tab.2 Recognition rate comparison of different methods on KTH database unit:%

表3 HMDB51數(shù)據(jù)庫上不同方法的識別率對比 單位:%Tab.3 Recognition rate comparison of different methods on HMDB51 database unit:%
6 結(jié)語
本文充分利用行為數(shù)據(jù)間的關(guān)聯(lián)性,從數(shù)據(jù)學(xué)習(xí)的角度挖掘行為視頻中的人體行為信息,通過對視頻幀進(jìn)行分段低秩學(xué)習(xí),并在時(shí)間軸上進(jìn)行連接進(jìn)而提取到行為視頻的LAI,LAI 能夠有效地捕獲視頻中的行為信息,且提取步驟簡潔,避免了因繁瑣步驟產(chǎn)生的誤差傳遞,相較光流法,無需視頻幀間的運(yùn)動(dòng)假設(shè)便可捕獲行為信息。針對LAI 的特點(diǎn),本文設(shè)計(jì)了MCNN 模型,將LAI 輸入MCNN 模型,通過多尺度卷積核獲取不同感受野下的行為特征,并合理設(shè)計(jì)各卷積層、池化層及全連接層進(jìn)一步提煉特征,最終輸出行為類別。實(shí)驗(yàn)結(jié)果表明本文所提方法在兩個(gè)基準(zhǔn)數(shù)據(jù)庫上取得了更好的識別效果,通過設(shè)計(jì)三組對比實(shí)驗(yàn),驗(yàn)證了本文所提方法的有效性。雖然HMDB51 數(shù)據(jù)庫是自然場景的數(shù)據(jù)庫,但還是不能等同于現(xiàn)實(shí)場景,將本文提出的方法應(yīng)用于現(xiàn)實(shí)場景的人體行為識別中,并不斷進(jìn)行改進(jìn)和完善以提高現(xiàn)實(shí)場景中的行為識別效果是需要進(jìn)一步完成的工作。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
中外會(huì)展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
