
基于注意力機制的圖像超分辨率重建
2021-03-18 13:45:46,*
計算機應用 2021年3期
,*
(1.貴州大學計算機科學與技術學院,貴陽 550025;2.貴州師范學院數學與大數據學院,貴陽 550018)
0 引言
圖像在攜帶信息方面扮演著越來越重要的角色,高分辨率(High Resolution,HR)的圖像越清晰,所蘊含的信息也越多。然而,由于成像設備以及天氣、光線等環境因素和噪聲的干擾,會獲取到許多低分辨率(Low Resolution,LR)模糊的圖像,如何提高圖像的分辨率是非常有研究意義的。最直接有效的方法是改善圖像捕捉設備,但是在實際應用中,改良硬件成本昂貴,對于小型企業或者個人研究者是不友好的,因此,超分辨率(Super Resolution,SR)重建技術由此而生,它通過改良算法來提高圖像分辨率,成本極低,適用于任何研究者。圖像超分辨率重建技術在軍事、遙感、醫療影像[1-2]等領域都有著廣泛的應用。
廣為熟知的超分辨率重建方法大體分為三類:基于插值、基于重建的和基于學習[3-4]的方法。插值法通過某個像素點與其周圍像素點對應的空間位置關系,利用數學公式來推導估計縮小和放大后的對應點的像素值。常見的插值法有雙立方插值[5]、最近鄰插值[6]和雙線性插值[7],插值法的速度快,但是重建的圖像細節紋理部分比較模糊。基于重建的方法利用圖像的整體信息結合數學方法求解高分辨率圖像的特征表達,然后重建出高分辨率圖像,常見的重建方法有最大后驗概率法[8]、迭代反向投影法[9]、凸集投影法[10]等。基于學習的方法利用大量的外部圖像樣本,結合數學公式的推導,學習LR與HR圖像之間的映射關系,獲取復雜的先驗知識;然后在重建高分辨率圖像時,能更好地放大圖像細節部分,提高圖像質量。早期的學習方法主要是機器學習,通過矩陣變換來求解高、低分辨率圖像之間的映射關系。圖像的稀疏編碼(Sparse Coding,SC)就是其中的經典學習方法,它將LR 和HR 對應的特征圖部分一一編碼成字典,形成對應的映射關系,然后學習編碼字典中元素的映射關系,重建高分辨率圖像。Yang 等[11]提出的基于稀疏表達算法,通過訓練高、低分辨率圖像的塊字典,使得其他的圖像塊都能夠適用于這一字典稀疏表達,且同一個圖像塊對應的高、低分辨率圖像字典的線性表達一致。
近年來,隨著圖形處理器(Graphic Processing Unit,GPU)的發展,基于深度學習的方法被廣泛用于圖像超分辨率重建領域,尤其是卷積神經網絡(Convolutional Neural Network,CNN)能自動提取豐富的特征,學習LR和HR之間的復雜映射關系。2014年,Dong等[12]首次利用卷積神經網絡來進行超分辨率重建任務,提出了超分辨率卷積神經網絡(Super-Resolution Convolutional Neural Network,SRCNN)模型,采用端到端的訓練方式,在當時大大提高了重建效果,開啟了卷積神經網絡處理超分辨率問題的時代。隨后許多研究者在其基礎上進行研究,致力于構建更好的模型。2016年,Kim等[13]將殘差思想應用于超分辨率重建任務,提出了使用非常深的卷積網絡超分辨率(Super-Resolution using Very Deep convolution network,VDSR)模型,同時將網絡的深度增加到了20 層,證明了深層網絡能提取出更多的特征,取得更好的重建效果。為了更注重視覺效果,Ledig等[14]提出了使用生成對抗網絡的超分辨率(Super-Resolution using a Generative Adversarial Network,SRGAN)模型,利用感知損失和對抗損失來提升和恢復出圖像的真實感,在當時取得了最逼真的視覺效果。Lim等[15]通過對殘差網絡的改進,提出了增強深度超分辨率網絡(Enhanced Deep Super-Resolution network,EDSR)模型,通過移除批規范化處理(Batch Normalization,BN)操作,堆疊更多的網絡層,提取更多的特征,從而得到更好的性能表現,并在同年的圖像恢復與增強新趨勢(New Trends in Image Restoration and Enhancement,NTIRE)大賽中取得了第一名的成績。
盡管上述基于深度學習的SR 方法都取得了很好的重建效果,但是仍然存在一些問題:1)它們都沒有對網絡提取的特征加以區別。平等對待每個通道,限制了網絡的表達能力,可能讓網絡在冗余的低頻特征上浪費計算資源。2)深層網絡所需要訓練的參數更多,等待的時間更久,如何減少參數運算量、提高模型性能也是一個重要的問題。針對上述存在的問題,本文提出了一種基于通道注意力機制(Channel Attention mechanism,CA)和深度可分離卷積(Depthwise Separable Convolution,DSC)的網絡結構,由淺層特征提取塊,基于通道注意力機制的深層特征提取塊和重建模塊組成。首先,將低分辨率圖像送入淺層特征提取塊,提取原始特征;然后,在深層特征提取塊中,在局部殘差模塊中加入通道注意力機制來提取深層的殘差信息,由于使用通道注意力機制會增加計算開銷,使得訓練的參數增加,所以在局部殘差模塊中還采用深度可分離卷積技術來減少參數運算量;最后,在重建模塊,將提取的深層殘差信息和LR 的信息融合,重建HR 輸出。本文的主要工作有以下三點:
1)提出了一種局部和全局的殘差網絡結構,有效緩解了梯度消失的問題,并且局部殘差塊能將圖像原始的豐富細節傳遞到后面的特征層中,提取更豐富的細節特征。
2)在局部殘差模塊中融入了通道注意力機制,并將通道注意力網絡模塊的全連接層換成了卷積層,通過挖掘特征圖通道之間的關聯性,側重提取關鍵特征信息。
3)在局部殘差模塊中融入了深度可分離卷積技術,能有效減少網絡的參數。
1 注意力機制
注意力機制通過模仿人類對事物觀察的方式來決定對輸入的哪部分數據進行重點關注,然后從重點數據部分提取關鍵特征。注意力機制最早應用于機器翻譯和自然語言處理方向,此后在各領域都有廣泛的應用。
注意力機制一般分為硬注意力(Hard Attention)機制和軟注意力(Soft Attention)機制。硬注意力機制是在所有特征中選擇部分關鍵的特征,其余特征則忽略不計。例如,在Wang等[16]的數字識別任務中,在提取原始圖像的特征時,只有含有數字的像素點是有用的,所以只需要對含有數字的像素點進行重點關注即可。因此,硬注意力機制能有效減少計算量,但也會丟棄圖像的部分信息,而在超分辨率重建任務中,圖像的每一個像素點的信息都是有用的,顯然硬注意力機制不適用超分辨率重建任務。
軟注意力機制不像硬注意力機制那樣忽略某些特征,它對所有的特征設置一個權重,進行特征加權,通過自適應調整凸顯重要特征。這樣的方式適用于超分辨率重建任務,本文引入的通道注意力機制就屬于軟注意力機制的一種。圖像經過每層網絡時,都會產生多個不同的特征圖,通道注意力機制通過對每張特征圖賦予不同的權重,讓網絡從特征的通道維度來提取重要的特征。最早將通道注意力機制用于圖像超分辨率重建任務的是Zhang 等[17]提出的殘差通道注意力網絡(Residual Channel Attention Network,RCAN),該模型證明了通過考慮通道之間相互依賴的特性,調整通道注意力機制,能重建出高分辨率的圖像。隨后Lu 等[18]提出多特征通道網絡(Channel Attention and Multi-level Features Fusion Network,CAMFFN),將通道注意力機制和遞歸卷積網絡結合,在每個遞歸單元的開始部分采用通道注意力機制,自適應地調整輸入特征的重要通道特征,取得了良好的效果。Liu等[19]提出一種單一圖像的注意力網絡,該網絡分為特征重建網絡和注意力產生網絡,特征重建網絡采用稠密卷積網絡(Dense Convolutional Network,DenseNet)結構,而注意力網絡采用U-Net結構,最后將兩個分支的結果融合,獲得高分辨率的重建圖像。
2 本文方法
通常認為網絡層數越深,提取的特征越豐富;并且,越深的網絡提取的特征越抽象,越具有語義信息。然而在實際應用中,簡單地增加深度會出現退化問題,原因可能是經過多層特征提取之后,許多圖像的邊緣紋理等細節丟失了,因此,本文提出了一種基于注意力機制和深度可分離卷積的網絡結構,通過引入全局和局部殘差學習能有效解決網絡退化問題。局部殘差網絡能將豐富的圖像細節傳到后面的特征層中,在局部殘差模塊中采用通道注意力機制和深度可分離卷積,前者通過調整各通道的特征圖權重,讓網絡從特征的通道維度來提取比較重要的特征,后者則能極大降低模型的訓練參數。同時,采用自適應矩估計(Adaptive moment estimation,Adam)優化器來加快整個模型快速收斂,縮短訓練的時間。本文設計的網絡模型如圖1所示。
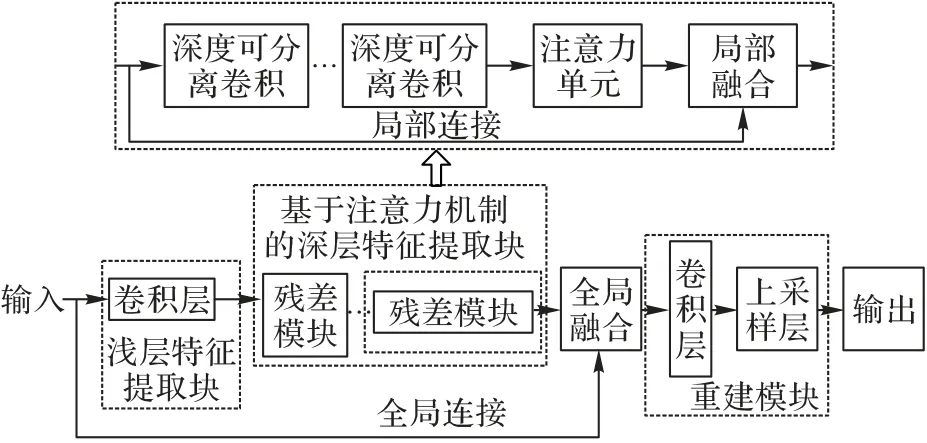
圖1 本文提出的網絡模型Fig.1 The proposed network model
整個網絡模型大體分為三部分:第一層為淺層特征提取塊,用于提取低水平特征;中間層為基于通道注意力機制的深層特征提取塊,由若干個局部殘差模塊組成,用于學習高水特征;最后一層為重建模塊,用于融合低水平特征和學習到的殘差特征,重建高分辨率圖像。
2.1 淺層特征提取塊
淺層特征提取塊由一個卷積層和激活層組成,用于從輸入的低分辨率圖像中提取特征,用Y和F0表示網絡的輸入與輸出,該特征提取可用式(1)表示:

其中:*為卷積操作;W0為卷積核;b0為偏置;F0為從低分辨率Y中提取的特征;σ為激活函數,這里采用ReLU 作為激活函數。在進行卷積操作前,為防止卷積之后的特征圖越來越小,此處在每次卷積之前都進行補零操作,這樣能夠確保每次卷積之后的圖像依然是原來的大小。
2.2 基于通道注意力機制的深層特征提取塊
在這一部分,經過淺層特征提取塊后,獲取了低分辨率圖像的特征圖,需要把這些特征映射到高維上繼續提取有效的信息。這一模塊由多個相同結構的殘差模塊組成,每個殘差模塊由若干個深度可分離卷積單元和一個通道注意力機制單元組成,接下來分別介紹這兩個單元。
2.2.1 通道注意力機制
一般來說,注意力機制可以看作是一種信號導向,它將更多可用的資源分配給輸入圖像中信息最豐富的部分。每一張圖像都能用RGB(Red-Green-Blue)三個通道表示出來,在卷積神經網絡中,通過不同的卷積核對每個通道進行卷積,每個通道就會產生新的特征信息,每個通道的特征信息就表示該圖像在每個卷積核上的分量,通常采用64 個卷積核對圖像進行卷積,其中卷積核的卷積操作將每個通道的特征信息分解成64 個通道上的分量,由于圖像中的高頻信息是聚集的,那么在64 個通道上的關鍵信息其實是分布不均的,普通的卷積神經網絡并沒有把關鍵信息明顯區別出來,如何對每個通道特征產生不同的注意是關鍵步驟。通常LR 圖像具有豐富的低頻信息和有價值的高頻信息成分,低頻信息一般比較平坦,而高頻成分通常是在某一區域充滿了邊緣、紋理和細節。卷積核在對圖像進行卷積時,有一個感受野的限制,只能對感受野內的信息提取特征,無法輸出感受野之外的信息。因此,可以使用全局平均池化操作對全局空間內的信息轉化為通道描述符,然后通道注意力機制通過給每個通道設置一個權重來表示通道與關鍵信息的相關性,權重越大,則該通道的信息越關鍵,輸出的特征就越多,最后重建出來的圖像分辨率就更高。通常通道注意力機制單元由一個池化層、兩個全連接層組成,全連接層用于降低維度,控制模型的復雜性。這里將兩個全連接層換成卷積層用以增加網絡非線性,更好擬合通道復雜的相關性,并且還能減少一定的參數。改進的通道注意力機制單元如圖2所示。
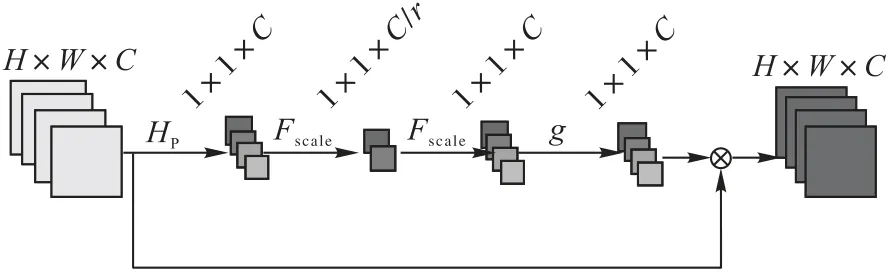
圖2 通道注意力機制Fig.2 Channel attention mechanism
首先,池化層將大小為H×W的C個特征圖轉化為1×1大小的C個特征圖,其計算方式如式(2)所示:
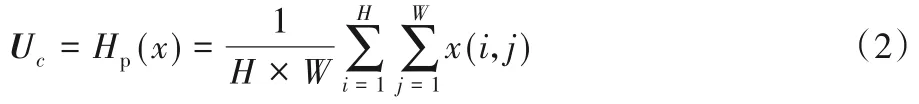
其中:x(i,j)表示C個特征x在位置(i,j)處的值;Hp(x)為全局池化函數,把每個通道內所有的特征值相加再平均;Uc為經過池化后的全局信息。
經過池化層之后,得到全局信息Uc,為了獲取全局信息Uc和各通道的相關性,引入一個門控機制,來學習各通道之間的非線性交互作用。門控單元Sc的計算方式如式(3)所示:

其中:σ是ReLU 激活函數,而g是一個sigmoid 函數;W1和W2分別是兩個卷積層的權重,通過每個局部殘差塊的兩個卷積層訓練學習,不斷調整其對應的兩個權重,得到一個一維的激勵權重來激活每一層通道。最后將通過sigmoid 函數得到的特征值Sc重新調整輸入Uc。

式(4)表示放縮過程,經過門控單元得到特征圖后,需要將1×1 大小的C個特征圖還原成H×W大小的特征圖,每個通道和其對應的權重相乘,從而可以增強對關鍵通道域的注意力,其中Sc和Uc是第c個通道中的縮放因子和特征映射。這樣通過通道注意力機制就可以自適應地調整通道特征來增強網絡的表達能力。
2.2.2 深度可分離卷積
深度可分離卷積最早是用于語義分割方向,在實際應用中使用效果良好,后被廣泛用于各領域。文獻[20]將深度可分離卷積代替傳統卷積提出了小巧而高效的移動端卷積神經網絡(efficient convolution neural Networks for Mobile vision applications,MobileNets)模型,在沒有降低準確率的情況下,大大減少了模型的參數,使得MobileNet 模型廣泛應用于移動端。深度可分離卷積將標準卷積進行拆分,將輸入數據的通道單獨卷積,再使用點卷積整合輸出,其計算式如下:

其中:*表示卷積操作;Hm為輸出的特征圖;F為輸入特征圖;K為卷積核;i,j為特征圖中每個像素值的坐標;m為通道數。深度可分離卷積是一種可分解的卷積,是在標準卷積基礎上改進的,它可以分解為兩個更小的操作:深度卷積(Depthwise Convolution,DC)和逐點卷積(Pointwise Convolution,PC)兩個階段。DC是深度可分離卷積的濾波階段,針對每個輸入通道采用其對應的卷積核進行卷積操作。PC 是深度可分離卷積的組合階段,整合DC 階段的所有特征圖信息,串聯輸出。標準卷積和深度可分離卷積的區別如圖3、4所示。
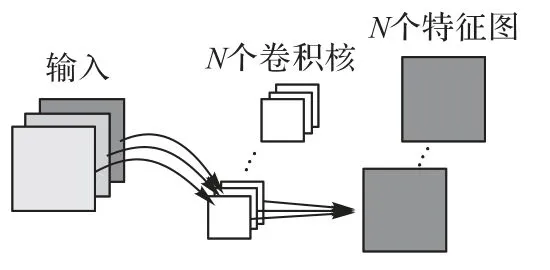
圖3 標準卷積Fig.3 Standard convolution
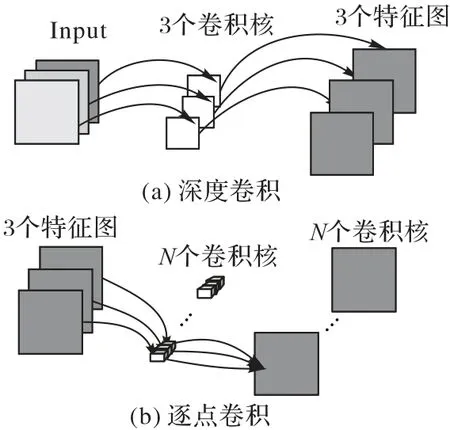
圖4 深度可分離卷積Fig.4 Depthwise separable convolution
為了比較普通卷積和深度可分離卷積的參數運算量,假設輸入M通道大小為H×W的特征圖,經過D×D大小的卷積核進行卷積操作后,輸出大小為H×W的N通道特征圖。
則標準卷積參數運算量如式(6)所示:
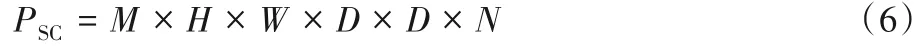
深度可分離卷積的參數運算量如式(7)所示:
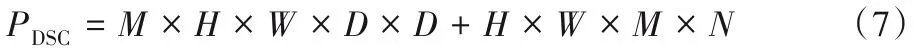
因此,兩種結構對應參數運算量之比如式(8)所示:

從式(8)可以得出,與標準卷積參數運算量相比,使用深度可分離卷積能極大降低模型參數運算量,當兩個網絡模型的層數相同時,若深度可分離卷積全部使用3×3的卷積核,即D=3,則參數運算量能減少為原來的1/9左右。
2.3 重建模塊
將前面深層特征提取塊獲取的輸出降維到與初始低分辨率輸入相同的維度,自適應地融合和保留之前學習到的特征,進行全局特征融合并輸出,重建出高分辨率的圖像。

其中:Y為圖像初始輸入;R為非線性映射學習到的高頻特征信息;Fd表示局部特征融合層的計算操作;Gup表示上采樣操作;Hhigh則為重建的高分辨率圖像。
2.4 損失函數
超分辨率重建的任務是通過卷積神經網絡一系列操作獲取重建圖像Hhigh,讓Hhigh和原高分辨率圖像Fhigh越相似越好。因此,需要一個函數來評價Hhigh和Fhigh之間的相似性,均方誤差(Mean Square Error,MSE)函數可以通過計算Hhigh和Fhigh兩幅圖像的每個像素點的誤差來評價Hhigh和Fhigh之間的相似性。誤差越小,即表示兩幅圖像越相似。所以本文采用均方誤差來作為損失函數(Loss Function),損失函數計算如式(10)所示:
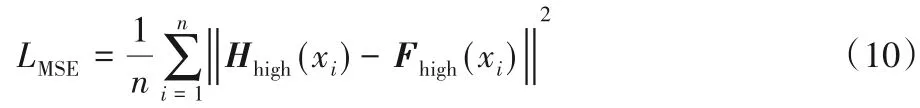
其中:i表示每個像素點;Hhigh為重建的高分辨率圖像;Fhigh為原始高分辨率圖像。通常在評價重建圖像質量時,峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)是一個重要的評價指標,而在計算PSNR 時,MSE 越小,則PSNR 越大,表示重建的圖像質量越好,與原始高分辨率圖像越相似。因此,使用MSE作為損失函數可以獲得比較大的PSNR。
3 實驗與結果分析
3.1 數據集和評價指標
實驗采用的數據集是圖像超分辨率標準數據集BSD300[21],含有300 張圖像,包含了自然界的各種景象,其中200 張用于訓練,100 張用于驗證。測試集采用Set5[22]、Set14[23]數據集,Set5 數據集包含5 張動植物的圖像,Set14 數據集包含14 張自然景象的圖像,比Set5 包含更多的細節信息。這些圖像通常用于圖像的重建。
本次實驗采用兩種國際通用的評判標準峰值信噪比和結構相似度(Structural SIMilarity index,SSIM)作為重建圖像的質量評價指標。PSNR 通過計算重建的高分辨率圖像與原始的高分辨率圖像之間像素點的差值來衡量圖像的質量,PSNR的單位是dB,數值越大,表示重建的圖像越好,失真越小,與原始圖像越相似,其計算如式(11)所示:
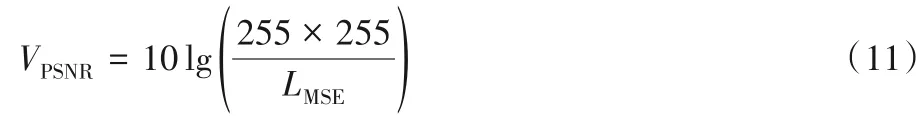
結構相似性以兩幅圖像的結構相似度為標準,從圖像的亮度、對比度和結構三個方面進行評價,計算式如下所示:
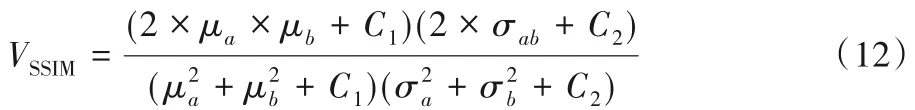
其中:μa和μb分別為圖像A和B的均值,表示亮度;分別為圖像A和B的方差,表示對比度;σab為圖像A和B的協方差,表示結構;C1、C2為常數,C1=(k1×L)2,C2=(k2×L)2,通常取k1=0.01,k2=0.03,L=255。結構相似性的取值范圍在0~1,結果越接近1,表示兩幅圖越相似。
3.2 實驗設置
本實驗使用4塊GPU來訓練各模型,型號都為Tesla-P40。由于目前許多研究的重構倍數都是2、3、4倍,因此本文實驗的重構倍數也采取相同的倍數,方便比較。針對輸入的彩色圖像,通過下采樣生成低分辨率的圖像,然后將RGB圖像轉換至YCbCr顏色空間,將Y通道的信息送入本網絡進行重建。網絡優化器使用Adam優化器,初始動量設為0.9,Batchsize設置為32,基礎學習率為0.001,之后每訓練25個Epoch,學習率減小一半。濾波器的個數為64 個。整個模型中,在局部和全局的特征融合部分采用1×1的卷積核,其他卷積層則采用3×3的卷積核,并且進行卷積操作之前都采用0 填充邊界,從而保證卷積之后的特征圖尺寸不變。激活函數都采用ReLU激活函數。
3.3 實驗結果
將本文提出的方法在Set5 和Set14 數據集上與Bicubic、SRCNN[12]、VDSR[13]、EDSR[15]、RCAN[17]等方法進行對比,表1為Set5 和Set14 數據集在不同模型中所取得的PSNR 均值和SSIM均值,表中加粗部分為本文模型的結果。

表1 不同模型的PSNR和SSIM均值Tab.1 PSNR and SSIM average values of different models
從表1 的實驗結果來看,本文提出的模型和SRCNN、VDSR、EDSR、RCAN 相比,在Set5、Set14 數據集上的PSNR 和SSIM 均值都有所提升。在放大倍數較低時,本文的模型重建效果和RCAN 相比沒有明顯的提升,但在放大倍數較高時,本文的模型重建效果良好,PSNR均值也有較大的提升,表明本文的模型提取圖像細節的能力比較強。從圖5 中的睫毛圖像也可以看出,本文的模型重建出來的圖像更清晰,與原高分辨率圖像更相似。一般而言,隨著放大倍數的增大,圖像重建的難度也會隨之增大,在放大倍數為4 時,本文的模型相較RCAN模型在Set14 上的PSNR 均值提升了0.39 dB。在RCAN 的啟發下,本文模型將特征圖通道注意力機制應用于殘差網絡,帶來了良好的重建效果,但是特征圖通道注意力機制會帶來巨大的參數量,增加計算開銷。為了減少通道注意力機制帶來的大量參數影響,本文還引入了深度可分離卷積來減少參數運算量,表2是各模型的參數運算量以及運算時間對比。
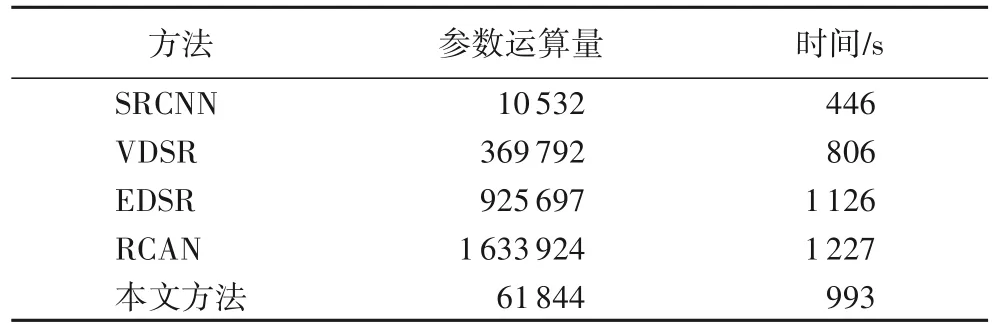
表2 不同模型的參數運算量和運算時間Tab.2 Parameter computing amount and computing time of different models
表2 給出了各模型產生的參數運算量和模型所用的時間對比,由于Bicubic 屬于傳統模型,所以這里沒有把它與各模型比較。由于實驗設備的限制,VDSR、EDSR、RCAN 和本文模型的每個殘差塊都只設置了10 層網絡。從實驗結果來看:本文的模型相較VDSR 模型,參數運算量是其1/6 左右;相較EDSR模型,參數運算量是其1/15左右;相較RCAN 模型,參數運算量是其1/26 左右。從各模型所運行的時間來看,SRCNN所運行的時間最短,因為SRCNN 模型的網絡結構只有三層,參數少,所以訓練的時間也越短;反觀RCAN 模型,由于使用了通道注意力機制,使得參數增加,耗時也長;而本文的模型耗時比RCAN 模型的運行時間短,雖然也使用了通道注意力機制,但是在局部殘差模塊中使用了深度可分離卷積技術,減少了參數。這進一步證明使用深度可分離卷積技術能大大減少參數運算量,從而減少訓練的時間,提高算法的性能。圖5~8 都是在重構倍數為2 時,在Set5 和Set14 上重建的圖像。為了方便看出效果,文中選取了各圖像中容易辨別的細節特征,例如圖5 中的眼睫毛部分,從圖中可以明顯看出本文的方法重建出來的圖像更清晰,與原HR 圖像幾乎一致;圖6 中的蝴蝶翅膀部分,從放大的圖像來看,其他方法重建出來的圖像在細節紋理部分都有一定程度的模糊,特別是傳統的Bicubic方法,更是模糊不清,而本文方法重建出來的紋理部分比較清晰;圖7 中胡須部分,從放大的圖像來看,本文方法相較其他方法重建出來的圖像,胡須根根分明,清晰可見;圖8 從少女的頭飾也可以看出本文方法在圖像細節方面,處理得更好。
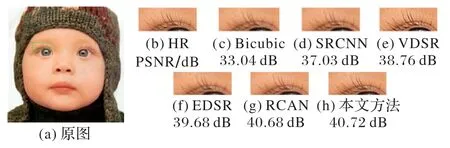
圖5 baby圖像主觀對比結果Fig.5 Subjective comparison results of baby image

圖6 butterfly圖像主觀對比結果Fig.6 Subjective comparison results of butterfly image

圖7 baboon圖像主觀對比結果Fig.7 Subjective comparison results of baboon image

圖8 comic圖像主觀對比結果Fig.8 Subjective comparison results of comic image
4 結語
本文設計了一種基于通道注意力機制和深度可分離卷積的網絡結構,對單幅圖像進行超分辨率重建。該方法通過在局部殘差塊中采用通道注意力機制來發掘特征圖通道之間的相關性,提高網絡提取關鍵特征的能力,使得重建的圖像更清晰,并且在局部殘差塊中引入深度可分離卷積技術,減少訓練的參數。實驗結果表明本文的方法重建效果良好,而且也大大減少了訓練的參數,提高了模型性能。本文研究的不足之處是每次訓練的模型只能適用于一種重構倍數,因此下一步的工作是將多尺度重構倍數應用于網絡模型中。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年21期)2018-11-09 01:23:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
