基于人體脈搏信號的疲勞檢測方法研究
2021-03-19 01:17:38中國礦業大學北京機電學院何澳來韓雪倩王春滿金昭明李成昱胡小紅
電子世界 2021年3期
中國礦業大學(北京)機電學院 何澳來 韓雪倩 王春滿 金昭明 李成昱 胡小紅
針對生理電信號分析是實現人體疲勞狀態監測最客觀有效的途徑。為此,本文通過對多名志愿者在不同疲勞狀態下脈搏信號的檢測,提取了時域和頻域的多種特征值,并利用隨機森林算法來檢測和判斷志愿者的疲勞狀態。結果顯示,脈搏可以較好的反映人體的疲勞狀態,該研究的目的在于為基于生理電信號分析的疲勞檢測提供新的研究思路和分析途徑。
人們在經歷長時間的勞動后會產生疲勞感。不同于身體機能運動導致的疲勞,只因過度用腦而產生的疲勞,定義為“精神性疲勞”。“精神性疲勞”會引發工作效率低,長期處于此狀態還會導致內心焦慮、抑郁等一系列嚴重心理問題,而目前針對精神性疲勞的量化檢測方法并不完善,需要有效的疲勞檢測方法來判斷人們的疲勞狀態。
近些年,已有研究者證實過脈搏,心電,腦電等生理信號與疲勞程度息息相關并建立了相關數學模型。本文基于前人研究,結合脈搏信號受外界環境干擾小、易檢測、與疲勞程度相關性較高等特點,選擇使用脈搏信號來進行疲勞量化。量化方法使用生理參數測量法,對人體脈搏特征進行多層次時頻域特征提取,并利用特征值通過隨機森林算法進行疲勞分類。
1 數據的采集與處理
1.1 所用設備及檢測對象
選擇健康的檢測對象20名,男10名,女10名。所選志愿者均為壯年,且無心腦血管等疾病,脈波平穩。平均年齡為23.85歲。志愿者均為考研學習者、碩士和單位文事人員,平時工作主要為腦力勞動,并保證所測數據當日未進行過劇烈的體力活動。實驗所用的儀器為光電式脈搏采樣儀,掃描周期為200Hz,脈搏高度單位為mm汞柱。
1.2 數據采集
采集前,志愿者先通過表格自測,通過志愿者主觀的感受初步分類疲勞狀態,以確定數據的可信性,表格使用11個形容詞對身體狀態進行描述,分別為“愉快—痛苦”、“欲睡—清醒”、“走神—精力集中”等。形容詞對交叉分布。并將這些形容詞對都分為 7 檔,定義為“非常—比較—有點—無影響—有點—比較—非常”,并予以相應的分值。數據采集方法為志愿者安靜地坐在椅子上,使用儀器的架夾子夾住食指或中指前端,測量實時脈搏,持續一分鐘。
2 特征值及其提取
2.1 時域信號的提取
脈搏波信號在時域下的峰值,周期等特征與疲勞有較強的相關性。本項目主要通過MATLAB對脈波信號進行時域分析,可得到峰谷值、第二個脈搏峰值比例、周期等多組特征值進行研究。大體經過平滑濾波、取反取極值、提取等步驟。
2.1.1 脈搏波信號預處理
由于波形提取過程中的環境以及設備的自身干擾,原始波形存在較多的尖刺波導致圖像不單調,影響了后續的波峰特征值提取,如圖1所示。所以調用MATLAB的smoothdata函數中的高斯濾波進行平滑濾波處理,如圖2所示。
即:smoothdata(d,'gaussian',10);其中d為數據,'gaussian'為高斯濾波器。10為數據窗口。
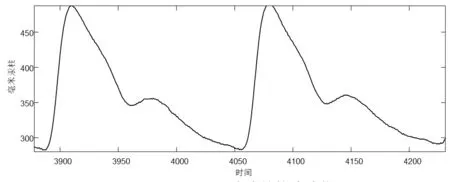
圖1 濾波前的脈波信號

圖2 濾波后的脈波信號
2.1.2 提取第二個波峰值及周期
洋桔梗適合的土壤EC值為1.0~1.3[1]。栽苗后第10 d可施第1次肥,以濃度約為0.1%~0.2%的高磷肥為主,以促進植株根系的生長;生長前期主要施用高N肥,如N∶P∶K=30∶10∶10的水溶肥促進葉片、莖稈生長;在中期每隔10 d左右施用1次平衡肥,如N∶P∶K=20∶20∶20的水溶肥或N∶P∶K=17∶17∶17的復合肥;大約定植后50 d生長到第7節位時,進入花蕾期要施高鉀肥,如K2SO4;中后期土壤施肥的同時要結合葉面肥,如KH2PO4噴施,每隔7 d噴1次。在花芽形成前隨著苗正常生長而慢慢上調肥料EC值。
本文在峰值提取過程中主要利用的是MATLAB里面的findpeaks函數組成的特征值提取算法,該特征提取算法有較高的準確性,可以快速有效的提取相關時域特征。
即:[maxv,maxl]=findpeaks(d,'minpeakdistance',60)
其中d為所要處理的波形,60為兩個峰值之間間隔的最小距離,提取后的峰值點坐標保存在[maxv,maxl]中。
將保存到輸出矩陣里的波峰特征值導出,分別提取出第一個波峰(高)和第二個波峰(低),并通過波谷與第二個波峰的橫坐標之差乘以采樣周期,即可獲得第二個波的周期。
2.2 頻域下的第二峰值
此特征值是用matlab的快速傅里葉變換得到頻域下的圖像,通過程序找到第二個峰值對應的頻率并讀出。因為在不同疲勞程度下頻域下的第二峰值有所不同,故取其為特征值。快速傅里葉變換及作圖,如圖3所示。
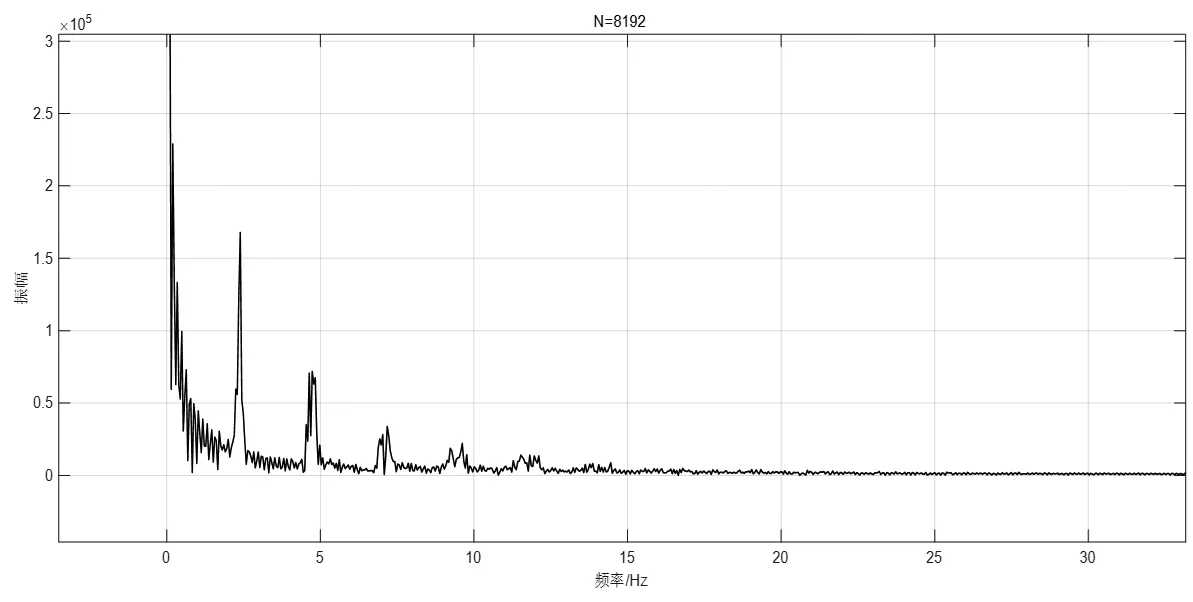
圖3 頻域下的第二峰值傅里葉變換圖
2.3 圖像的裕度和峭度
峭度是反映隨機變量分布特性的數值統計量,是4階累積量。有正常峰度(即零峭度)、正峭度和負峭度之分。
裕度是統計學術語,指留有一定余地的程度,允許有一定的誤差。公差裕度是根據統計的對象和范圍來規定的。如:噪音裕度、相位裕度、安全裕度等。
3 隨機森林分類器設計
3.1 分類器的選用
對比于其它算法,支持向量機的樣本大規模訓練難以實施;神經網絡有黑盒子性質,數據量大,開發時間長。而隨機森林算法具有很好的準確率,能夠處理多維特征的樣本而不需要降維,能夠評估各個特征在分類問題上的重要性,對于缺省值問題也能夠獲得很好得結果。綜上,選用隨機森林算法進行機器學習較為適宜。
3.2 實驗過程
首先對得到的數據進行預處理,將存在明顯數量級錯誤的數據視為噪聲,統一置為0。然后使用sklearn庫建立隨機森林對象,訓練模型。最后用十折交叉驗證的方式評估模型的置信度,并顯示出每個特征值訓練出的權重,其中權重值高的為與疲勞度最相關的特征值。
3.3 隨機森林參數優化
(1)由于樹的個數不宜太多,也不宜太少。經過多次實驗分析結果,認為選擇31棵最合適。
(2)在實驗中,我們采用了固定的random_state(隨機種子),可以保證程序每次運行都分割一樣的訓練集和測試集。否則,同樣的算法模型在不同的訓練集和測試集上的效果不一樣。
(3)由于隨機森林中的樹個數過多時會浪費掉約37%的訓練數據(袋外數據,oob),它們不參與建模。于是我們就使用這些數據作為測試集,這樣大大提高了數據的利用率。
在對參數進行優化之后,相同樣本下的置信度從87%提高至90.63%。
實驗首先測量了100余組數據進行10折交叉驗證測試,在交叉驗證時我們測量出它的置信度超過90%,并分析出與結果關系最密切的特征值為頻域第二個波峰特征值,幾乎是其他特征值相關度的2倍。我們又測量了38組數據,對這100組數據訓練出的模型進行測試,正確率高達100%。綜上,實驗結果置信度較高,驗證本文的疲勞檢測結果有效整個實驗程序的流程圖如圖4所示:

圖4 算法流程圖
結論:本文通過采集20個腦力勞動者的200余組脈搏波信號,利用數據處理軟件進行信號濾波去噪處理,并提取出可用的特征值,基于這些特征值訓練出隨機森林模型進行疲勞評估,在十折交叉驗證下置信度高達90%,這個結果表明了在上述參數下訓練出的模型可以有效地實現疲勞檢測,不過在本文的研究中僅僅使用了20名志愿者的數據作為疲勞檢測的原始數據,數據量來源比較單一。由于不同人的生理特征可能影響脈搏,脈搏波形的個體差異會不會影響疲勞檢測系統的訓練效果,這個問題值得探討。在未來的研究中,可以增加數據來源,同時針對更多的場景進行研究,避免此類影響。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
海峽科技與產業(2016年3期)2016-05-17 04:32:12
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25