融合指針網絡的新聞文本摘要模型
2021-03-21 05:11:52蔡中祥孫建偉
小型微型計算機系統 2021年3期
蔡中祥,孫建偉
1(中國科學院大學,北京100049) 2(中國科學院 沈陽計算技術研究所,沈陽 110168)
1 引 言
隨著互聯網技術的快速發展,越來越多的機構更傾向于使用網絡平臺發布信息,人們在日常生活和工作生活中常常被豐富的平臺信息所包圍.因此,人們迫切需要尋找一條能夠快速、準確獲得所需信息的途徑.自動文本摘要技術能夠快速地精簡源文本,并根據其主要內容來生成短文本摘要,有效地為人們快速獲取信息提供了很大的便利.
根據文本摘要的實現方式可分為抽取式摘要和生成式摘要.抽取式摘要通過對源文本句子根據重要度重新排序組合,抽取能夠表示源文本主要信息的短語、句子以生成摘要.該方法簡單實用,生成的摘要全部來源于源文本.但是通常會有句子間不連貫的問題,同時還會產生一些冗余詞.生成式摘要通常使用編碼器獲取源文本的上下文特征信息,利用自然語言生成技術生成摘要.雖然該方法比抽取式方法生成的摘要更具有語義性,但是會存在生成摘要重復和生成未登錄詞等問題.近年來,隨著在seq2seq框架中使用注意力機制,源文本和摘要之間加強了相關性聯系,生成摘要的通順性也相繼得到改善,文本摘要技術也愈發成熟.
本論文首次將文本摘要技術應用在黨建新聞領域中,提出Tri-PCN模型為長文本的黨建新聞生成合適的新聞標題.本論文的創新之處在于:1)使用Transformer模型作為編碼器和解碼器,利用多端注意力機制從新聞長文本序列中提取多層次文本特征,使模型更加適合黨建新聞長文本序列的特點.2)從指針生成網絡中引入指針復制功能,使生成的新聞標題保留新聞文本中關鍵的黨建信息.在本論文構建的黨建新聞數據上,通過3個模型的實驗對比,表明本文提出的Tri-PCN模型更適合黨建新聞領域的文本摘要任務.
2 相關工作
自動文本摘要作為自然語言處理的主要任務之一,人們早已開展大量的研究.早期的研究主要是抽取式文本摘要技術,根據關鍵詞、句子位置等特征,計算關鍵詞、關鍵句的重要度,選擇最得分最高的詞和句子組成摘要.2004年,Mihalcea等[1]將源文本中的句子作為圖的節點,圖中邊的權重通過計算節點之間的相似度獲得.然后使用基于圖算法的TextRank算法計算句子的重要度,將句子重新排序重組,組成新的摘要.
隨著深度學習的發展,利用神經網絡模型的生成式方法也得到廣泛應用.2015年,Rush等[2]首次提出在seq2seq框架中應用注意力機制的文本摘要模型.該模型以卷積神經網絡(CNN)為編碼器,神經網絡語言模型(NNLM)為解碼器,結合注意力機制生成摘要,是生成式文本摘要技術的一項突破性工作.2016年,Chopra等[3]在Rush等[2]的工作成果上使用循環神經網絡(RNN)替代卷積神經網絡(CNN)作為編碼器,利用循環神經網絡的時序性提高了摘要的質量.同年,Nallapati等[4]將seq2seq框架中的編碼器和解碼器全部替換為循環神經網絡,同時在編碼器中加入了額外的詞性和實體信息特征,進一步提高了摘要的質量.雖然基于seq2seq框架的生成式文本摘要技術逐漸成為主流,然而仍然存在一些問題,比如生成未登錄詞(OOV)、生成詞重復等問題.2015年,Vinyals等[5]提出了在seq2seq框架中添加指針網絡的Ptr-Net模型,指針結構[6-8]逐漸成為主流.2016年,Gu等[9]提出了添加拷貝機制的CopyNet模型.兩種模型在生成摘要時不僅可以從詞表中選擇詞,還可以從源文本中直接拷貝詞,有效緩解了未登錄詞問題.2017年,See等[10]提出的指針生成網絡(Pointer-generator network)將指針機制和拷貝機制同時添加到seq2seq框架中,緩解了未登錄詞和生成詞重復問題.2018年,Gehrmann等[11]等提出基于一種注意力機制自上而下選擇內容的摘要生成模型,Lin等[12]重新使用卷積神經網絡作為編碼器對源文本進行全局編碼,在文本摘要任務上取得了很大的提高.Shen等[13]根據語言結構提取句子特征向量,并構建AM-BRNN模型生成摘要.同年,越來越多的研究者開始將強化學習應用在文本摘要任務中.Paulus等[14]首次在文本摘要任務上引入了強化學習,通過對生成摘要的評估指標進行聯合優化,緩解了曝光偏差問題.Xu等[15]提出一種基于卷積自注意力編碼并結合強化學習策略的強化自動摘要模型.
經過實驗研究表明,基于seq2seq框架的生成式文本摘要模型更適合短文本標題的生成,對于過長的文本生成標題效果比較差.原因在于,編碼器無法充分的從過長的文本序列提取上下文信息特征,產生長期依賴問題.而以RNN為代表的編碼器因為時序性特點,無法并行計算;在模型訓練時需要花費大量的時間,同時還需要大量的計算資源.因此,本文針對上面兩種缺點加以改善,并成功應用在黨建新聞領域中.
3 本文的方法與模型
本文提出的融合指針網絡的黨建新聞領域文本摘要模型結構如圖1所示.該模型是基于編碼器-解碼器結構提出的,由3部分組成,第1部分是新聞文本編碼器,輸入分好詞的新聞文本,經過詞嵌入后得到文本的詞向量(Embedding)表示,使用Transformer模型[16]的多端注意力機制(Multi-Head Attention)提取新聞文本特征,得到K特征矩陣和V特征矩陣;第2部分是指針復制網絡,通過編碼器提取的兩個特征矩陣與解碼器提取的Q特征矩陣計算,得到復制指針pgen,使用復制指針選擇新聞標題詞是從詞表中生成還是從新聞文本中復制;第3部分是新聞標題解碼器,同編碼器相似,輸入分好詞的新聞標題,詞嵌入后得到標題的詞向量表示,使用Transformer模型提取新聞標題特征,得到Q特征矩陣,利用復制指針選擇的標題詞生成新聞標題.
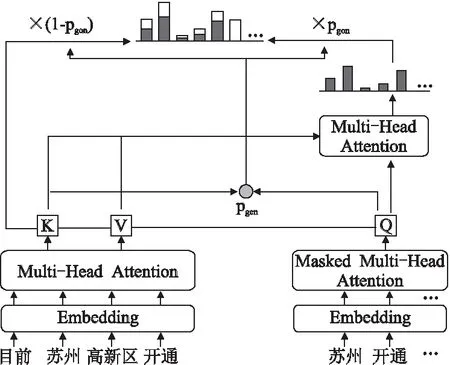
圖1 模型總體結構Fig.1 Modestructure
3.1 新聞文本特征提取編碼器
為了將新聞文本輸入到模型中進行處理,需要使用編碼器對文本進行特征提取.目前流行的編碼器結構為雙向長短時記憶網絡(Bidirectional Long Short-Term Memory,BiLSTM[17]),但是在黨建領域中,新聞文本的長度普遍比普通文本摘要任務長3-5倍.因此,本文采用Transformer模型作為編碼器.Transformer編碼器的輸入與其他編碼器不同,是新聞文本分詞后的詞向量(Embedding)與詞位置向量(PositionalEncoding)的累加組成.然后使用多端注意力機制(Multi-HeadAttention)對輸入詞向量進行特征提取;使用殘差連接和層歸一化(Add&Norm)用來緩解梯度消失、加速模型訓練時收斂.相比于雙向長短時記憶網絡的優點是:1)處理更長的文本序列;2)可以高效的并行化計算.Transformer模型結構如圖2所示.
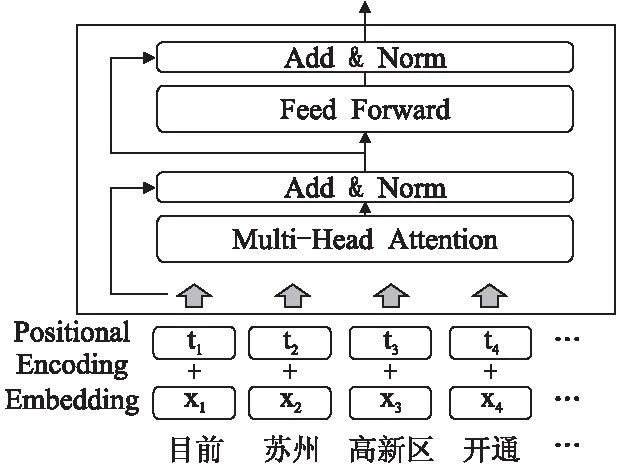
圖2 Transformer編碼器Fig.2 Transformer encoder
3.1.1 詞嵌入
給定一個新聞文本序列S=(w1,w2,…,wn),對文本進行分詞.在輸入到編碼器前,使用word2vec詞向量訓練工具把每個詞轉換成向量表示X=(x1,x2,…,xn).由于Transformer編碼器并不像雙向長短時記憶網絡編碼器具有時序性,因此使用正余弦函數為每個詞添加一個位置編碼T=(t1,t2,…,tn),計算方式如式(1)、式(2)所示:
PE(pos,2i)=sin(pos/1000002i/dmodel)
(1)
PE(pos,2+1)=cos(pos/1000002i/dmodel)
(2)
其中,pos為詞在句子中的位置,i為向量的某個維度,dmodel為詞向量的維度.最終的詞嵌入向量由詞向量與位置編碼向量通過相加得到.
3.1.2 多端注意力特征提取模型
將新聞文本序列的詞嵌入向量分別乘以3個不同的參數矩陣WQ、WK、WV進行線性映射,得到Transformer模型的輸入 Q矩陣、K矩陣和V矩陣.為了更好的捕獲不同層次文本序列的特征信息,該模型使用了由多個縮放點積自注意力(Scaled Dot-Product Attention)構成的多端注意力模型,多端注意力模型模型結構如圖3所示.
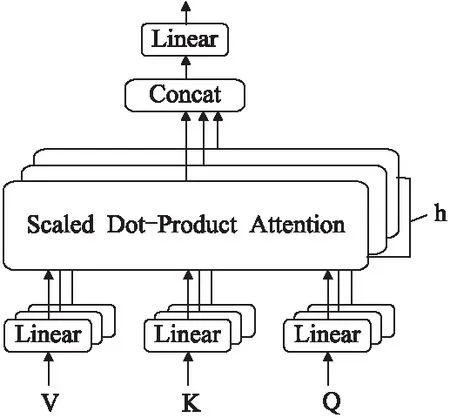
圖3 多端注意力模型結構圖Fig.3 Multi-head attention model structure
其中,縮放點積自注意力的計算方式如式(3)所示:
(3)
其中,dk=64為縮放因子,通過縮放因子的歸一化保證訓練時梯度的穩定.不同縮放點積自注意力模型得到不同的輸出向量Z,將8個輸出向量進行拼接并通過一個全連接層后得到多端注意力模型的輸出,計算方式如式(4)所示:
MultiHead(Q,K,V)=Concat(head1,…,head8)WO
(4)
接著加入殘差連接以緩解梯度消失問題,同時對輸出進行層歸一化,加快訓練時模型收斂.之后,將輸出向量輸入到一個全連接前饋神經網絡層,該全連接層由兩次變換構成.第1次通過ReLU激活函數做非線性映射,第2次是使用線性激活函數恢復到原始維度,計算方式如式(5)所示:
FFN(x)=max(0,xW1+b1)W2+b2
(5)
為了獲取多層次的新聞文本信息,得到更加充分的新聞本文表征,在編碼階段總共堆疊6個相同的模塊進行計算,得到兩個特征矩陣K矩陣和V矩陣.
3.2 融合指針網絡的新聞標題生成解碼器
在解碼階段,同樣使用一個Transformer模型作為解碼器用來生成新聞標題.為了能夠從輸入的新聞文本中抽取更多的重要信息,模型中添加了指針生成網絡.模型自動生成標題詞的功能,同指針生成網絡從輸入文本中復制詞的功能相結合,有效提高了生成的新聞標題的豐富度.
與編碼階段不同的是,解碼階段是一個順序輸入過程.在生成新聞標題的每一個時刻t,使用一個掩碼多端注意力模型進行特征提取(訓練階段輸入的是參考新聞標題t時刻的詞,測試階段是解碼器t-1時刻生成的詞).掩碼多端注意力模型將t時刻之后的詞進行掩碼操作,只允許使用t時刻之前的特征向量計算t時刻的特征向量.除了增加掩碼操作,其他的計算方式都與解碼階段相同.最終,得到一個特征矩陣Q,Q矩陣表示從開始時刻到當前時刻的新聞標題特征向量.
接著使用多端注意力模型對Q矩陣和來自解碼器的K矩陣、V矩陣進行計算,同樣在多端注意力模型后加入殘差連接和全連接前饋神經網絡層,最后經過 層的歸一化,得到詞表中所有詞的分布概率Pvacab.
在黨建領域中,新聞文本在分詞后通常包含比較多的低頻詞,經過數據預處理操作,統一被歸檔為未登錄詞(OOV),在詞表中使用“
在解碼階段,每一個時刻t通過復制指針pgen控制預測詞是從詞表中生成還是從新聞文本中復制.指針pgen計算方式如式(6)所示:
(6)
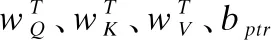
最終,融合了指針網絡模型的解碼器,可以通過指針pgen選擇從新聞文本中直接復制黨建關鍵信息詞.計算詞表的分布概率前,先將新聞文本中的未登錄詞提取出來擴充到詞表中構建新的詞表,然后再計算t時刻預測詞w的分布概率.計算方式如式(7)所示:
(7)
可以看出,若預測詞w是未登錄詞,那么pvocab(w)等于零.這樣,預測詞w就可以只從新聞文本中生成.其中,αt是新聞文本序列對解碼器t時刻預測詞的注意力分布權重,通過解碼器提取新聞標題得到的Q特征矩陣與編碼器提取新聞本文得到的K特征矩陣、V特征矩陣計算而得.具體計算方式如式(8)、式(9)所示:
et=vTtanh(WQQt+WKKt+WVVt+battn)
(8)
αt=softmax(et)
(9)
因為新聞文本中可能存在多個位置i的詞wi都是預測詞w,因此計算詞表概率時需要將所有預測詞w的注意力權重進行累加,如公式(7)所示.
4 實驗與分析
4.1 數據集描述
目前國內還沒有黨建領域的新聞文本摘要數據集,公開的高質量中文文本摘要數據集只有哈工大的LCSTS數據集[18],但是該數據集包含了科技、娛樂等多個領域,句子的平均長度在10-30之間,和黨建領域的新聞數據相差較大.
實驗所用數據集均為使用Python爬蟲抓取的人民日報上近20年的新聞,包括新聞標題和新聞文章兩部分.因為原始數據紛亂復雜,所有數據都經過了預先處理,包括刪除特殊
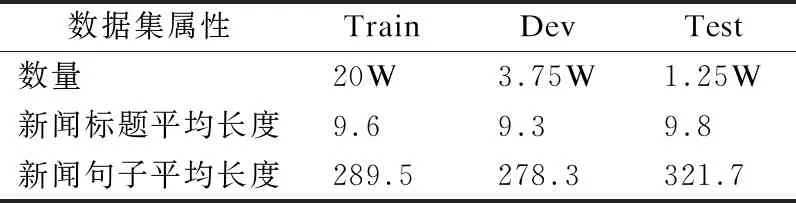
表1 數據集的統計信息Table 1 Statistics of dataset
符號、去除停用詞等,并使用jieba分詞工具進行分詞,過濾詞頻小于3的詞和長度大于100小于380的新聞.通過整理實際獲取到的新聞數據為25W條,分為訓練集(80%,20W條數據)、驗證集(15%,37500條數據)和測試集(5%,12500條數據).數據集信息如表1、表2所示.

表2 數據集樣例Table 2 Sample dataset
4.2 實驗設置
4.2.1 實驗環境
實驗環境如表3所示.

表3 實驗環境Table 3 Lab environment
4.2.2 實驗參數設置
本實驗的詞向量訓練使用Google開源的word2vec工具,詞向量的維度設置為512.批次大小設置為64.Transformer模型中所有的全連接前饋神經網絡層隱狀態維度都設置為2048.優化算法使用Adam算法,初始學習率設置為為0.002,超參數設置為β1=0.9,β2=0.98,ε=10-9.解碼時,使用集束搜索方法,束寬度設置為4.
4.2.3 實驗評價指標
實驗采用ROUGE[19]作為黨建新聞標題生成模型的評測方法.ROUGE-N通過比較生成摘要和參考摘要的重疊詞以衡量兩者之間的相似度,計算方法如式(10)所示:
(10)
其中,Ref Summaries為參考摘要,即人工爬取的新聞標題.n-gram為n元詞(n個連續的詞).Countmatch(-ngram)為同時出現在模型生成的摘要和參考摘要中的n元詞個數.實驗中采用了ROUGE-1(1-gram)和ROUGE-2(2-gram),有效的衡量生成新聞標題包含的關鍵信息量.
實驗中還采用了ROUGE-L,通過計算生成摘要和參考摘要的最長公共子序列,衡量生成新聞標題的流暢度和可讀性.
4.3 實驗對比方法
為了驗證模型的有效性,本文實現了3個對比實驗模型與本文提出的模型進行比較.
TextRank:該模型是基于圖算法的一種抽取式文本摘要方法,通過計算句子間的重要度,進行排序重組生成新的摘要.該模型經常作為抽取式自動文本摘要的基準模型.
ABS:Rush等[2]等首次提出在seq2seq框架的基礎上使用注意力模型,作為生成式文本摘要方法并應用到自動文本摘要任務中.該模型經常作為生成式自動文本摘要的基準模型.
Pointer Generator:在ABS的基礎上,通過指針結構選擇摘要詞,并且添加覆蓋機制,有效緩解了未登錄詞和生成摘要重復問題.
對比模型和本文提出的模型在黨建新聞數據集上的實驗評測結果如表4所示.
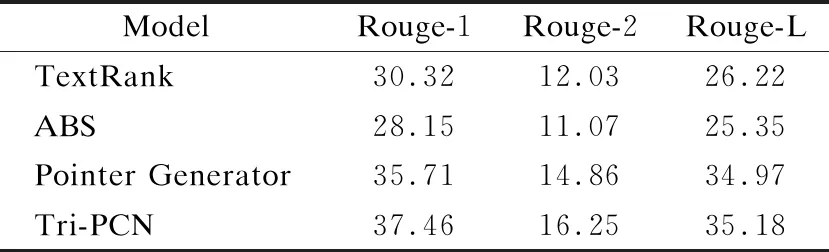
表4 模型評測對照表Table 4 ComparisonTable of models
由表4可以看出:
1)基于TextRank算法的抽取式文本摘要模型作為一種簡單的非監督學習方法,在3項ROUGE評測指標上都略高于生成式自動文本摘要的基準模型ABS.雖然ABS基準模型使用了注意力機制,有效的從長文本序列中提取到豐富的文本特征信息,但是抽取式方法仍然能獲得不錯的成績,證明新聞標題中的關鍵詞大部分來自于新聞文本中的詞.
2)與生成式文本摘要基準模型ABS相比,Pointer Generator模型有了進一步的提高.因為Pointer Generator模型使用指針結構和覆蓋機制緩解了未登錄詞問題以及重復生成問題.說明指針網絡可以明顯提高新聞標題的質量.
3)與3個對比模型相比,本文提出的Tri-PCN模型在3項ROUGE評測指標上均取得最好成績.表明該模型在黨建新聞領域的數據集上,可以從長文本的新聞序列中提取更多的文本特征,同時通過指針復制網絡保留新聞的關鍵信息,使生成的摘要更滿足黨建新聞的要求.
5 結 語
針對于黨建新聞領域的自動文本摘要任務,本文提出了一種融合指針網絡的生成式模型Tri-PCN.在從黨建新聞文本中提取特征時使用由多端注意力機制為單位的Transformer模型作為編碼器和解碼器,使得模型能更好的處理長文本序列,同時Transformer模型的并行化計算也加速了訓練過程.融合了指針網絡使得模型更大程度上保留新聞文本中的重要黨建信息.通過在爬取的真實黨建新聞數據集上進行實驗對比,本文的模型比其他方法生成的新聞標題有更好的準確性和可讀性.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
