交叉連接的少層殘差卷積神經網絡
2021-03-21 05:11:52李國強陳文華
小型微型計算機系統 2021年3期
關鍵詞:模型
李國強,陳文華,高 欣
(燕山大學 智能控制系統與智能裝備教育部工程研究中心,河北 秦皇島 066004) (燕山大學 河北省工業計算機控制工程重點實驗室,河北 秦皇島 066004)
1 引 言
近年來,隨著眾多學者對人工智能(AI)的不斷研究,基于深度學習[1]的人工智能技術已成功地應用于語音識別[2],自然語言處理[3],計算機視覺等領域.在許多視覺識別任務中,深度卷積神經網絡都具有良好的效果,如圖像分類[4],圖像檢索[5]、目標檢測[6]和語義分割[7]等.經典的卷積神經網絡從VGG[8],Inception[9-11],ResNet[12]發展到DenseNet[13],其間也涌現出很多其他卷積神經網絡.
2012年的ImageNet競賽中,AlexNet[14]網絡獲得冠軍,也是卷積神經網絡第一次被嘗試應用在圖像處理上并獲得廣泛關注.2014年的ImageNet競賽中,VGG網絡作為定位任務中的基礎框架獲得冠軍,當時網絡深度(卷積層層數)被認為是VGG網絡取得良好效果的重要因素.Network-In-Network(NIN)利用多層感知機(Multilayer Perceptron)來提高圖像分類的準確率,多層感知機由全連接層和非線性函數組成.上述表明卷積神經網絡的深度和寬度是改善網絡性能的兩個關鍵因素,但是隨著網絡越來越深,訓練會變得困難并且會出現過擬合問題.為了解決這個問題,Srivastava等人提出了Highway Networks,它使用一種學習門機制(a learned gating mechanism)讓信息在幾個卷積層之間有效傳遞.隨后,He等人提出ResNet,應用恒等映射來實現殘差學習,它使不同卷積層間有規律連接起來.不久后,密集網絡(DenseNet)的作者將這種方法的作用發揮到極致,使每一層都和之前的層相連接.
隨著ResNet變得越來越受歡迎,許多改進版逐漸出現.Wide Residual Network(WRN)[15]網絡通過增加通道數來加寬網絡.ResNeXt[16]提出的基數(cardinality)超參數為調整模型容量提供了一種新方法.Huang等人提出了Stochastic Depth residual networks(SD ResNets)[17],極大降低了模型訓練時間,SD ResNets在訓練過程中隨機去掉(drop)一些卷積層,但是在測試的時候不會這樣做,同時說明一些卷積層可能是冗余的.
當卷積神經網絡應用跨層連接時,它的性能可以得到很大的提升,變得更加準確和高效,訓練也會變得容易.在殘差網絡(ResNet)的啟發下,文章設計了兩種新型卷積神經網絡框架(C-FnetO和C-FnetT),它們采用了全新的交叉跨層連接布局方式并具有較少的卷積層層數.C-FnetO網絡和C-FnetT網絡中不僅相鄰模塊間具有連接線,在模塊內部還設有跨層連接線,有利于充分保留圖像特征信息.不同分支處的特征融合采用DenseNet網絡中通道拼接方式(concatenation).同時,對兩種新型網絡模塊中采用的跨層連接布局方式的有效性進行理論上的證明.C-FnetO和C-FnetT兩種網絡分別在4個公開的權威數據集(MNIST,CIFAR-10,CIFAR-100和SVHN)上進行訓練和測試,并與最先進的殘差和密集網絡模型(ResNet和DenseNet)等進行對比實驗.實驗結果表明,文章設計的網絡模型在4種數據集上都取得了相對更好的效果,其中C-FnetT網絡的效果最佳,在4種數據集上均取得了最高的圖像識別準確率.所以,在后面的文章中,以C-FnetT卷積神經網絡為主要對象進行介紹.
2 C-FnetO和C-FnetT網絡模塊化設計
2.1 網絡布局
在C-FnetO和C-FnetT兩個網絡中,分別有n個模塊,每個模塊主要由3層卷積層組成,最后一個模塊由2層卷積層組成.鑒于兩種網絡框架區別很小,以相對復雜的C-FnetT網絡為例進行展示,如圖1所示,除了相鄰模塊間具有連接線外,在每個模塊內部也具有連接線,兩條連接線成交叉狀態,也是與殘差模型的不同之處.而C-FnetO只是減少了每個模塊的內部連接線(即圖1中的虛線線條),其他均與C-FnetT一致.
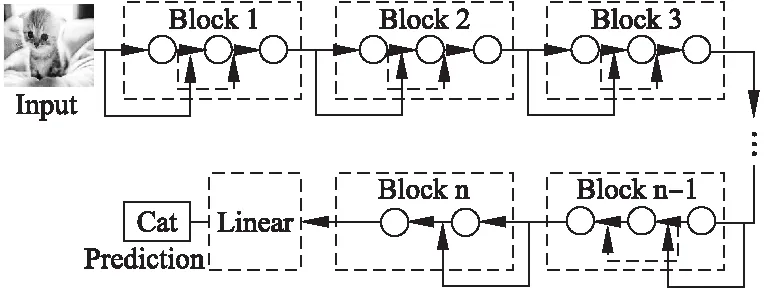
圖1 C-FnetT的布局圖Fig.1 C-FnetT with n blocks
2.2 網絡模塊
對于C-FnetO網絡的模塊,如圖2左圖所示,x0表示輸入圖像信息,x1,x2和x3分別表示第1層,第2層和第3層的輸出.fL(*)表示非線性變換,可以為批正則化(Batch Normalization)[18],激活線性單元(Rectified linear units)[19],或卷積(Convolution),其中下標L表示卷積層,取值為0,1,2,3.則C-FnetO模塊可以建模如公式:
x1=[f1(x0),x0]
(1)
x2=f2([f1(x0),x0])=f2(x1)
(2)
x3=f3(f2([f1(x0),x0]))=f3(x2)
(3)
其中[*,*]表示通道拼接操作(concatenation),如:[f1(x0),x0]代表f1(x0)與x0在第三維度,即通道上的拼接.
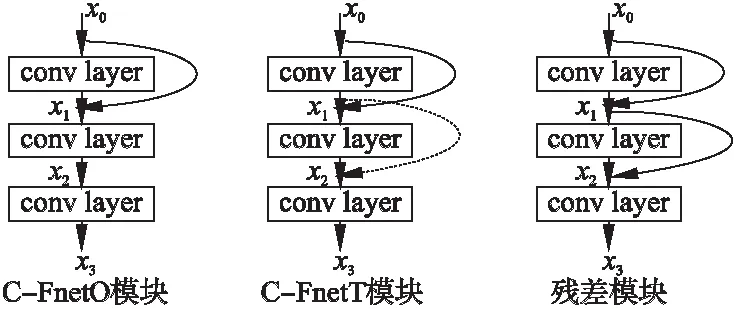
圖2 3種網絡的模塊Fig.2 Model of three networks
假設δ為模塊中最后一層輸出的loss值,可以根據反向傳播理論得到梯度值,如公式(4)所示:
(4)
對于C-FnetT網絡的模塊,如圖2中間所示,它比C-FnetO模塊多了一條跨層連接線,建模公式如式(5)、式(6)和式(7):
x1=[f1(x0),x0]
(5)
x2=[f1(x0),f2([f1(x0),x0])]=[f1(x0),f2(x1)]
(6)
x3=f3([f1(x0),f2([f1(x0),x0])])=f3(x2)
(7)
依然假設δ為模塊中最后一層輸出的loss值,可以根據反向傳播理論得到梯度值,如公式(8)所示:
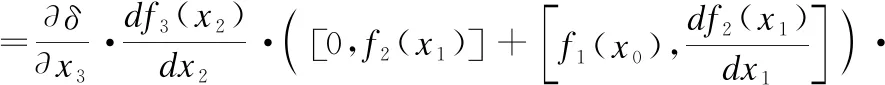
(8)
由于網絡采用模塊化設計方法,整體網絡框架由每一個模塊組成,以C-FnetT為例,下標b表示網絡的模塊數,則C-FnetT網絡的整體建模公式如式(9)(近似復合函數)所示:
(9)
整個網絡的梯度計算類似單個模塊的計算方法,文章不再贅述.
2.3 殘差模塊
應用殘差連接方式時,如圖2右圖所示,建模公式為式(10)、式(11)和式(12):
x1=[f1(x0),x0]
(10)
x2=[[f1(x0),x0],f2(x1)]=[f2(x1),x1]
(11)
x3=f3([[f1(x0),x0],f2(x1)])=f3([f2(x1),x1])=f3(x2)
(12)
同樣設δ為模塊中最后一層輸出的loss值,可以根據反向傳播理論得到梯度值,如公式(13)所示:
(13)
2.4 理論分析
文章設計的網絡模塊采用了交叉連接方式,為了證明它的有效性,圖3直觀地展示了3種模塊的示意圖,可以觀察到,C-FnetO比C-FnetT少一個②通路,比殘差模塊少②和③通路,而C-FnetT比殘差模塊少一個③通路,通路①是它們共有的,C-FnetO和C-FnetT均在殘差模塊的基礎上進行了優化.在2.2和2.3節中,給出了每種網絡的單個模塊的梯度傳播公式,由公式(4)、公式(8)和公式(13)可知,C-FnetO相比C-FnetT和殘差連接模塊,在梯度公式中包含更少的信息,而C-FnetT與殘差連接模塊擁有同等的信息量,但是C-FnetT的梯度值更偏小一些,可以獲得更加豐富和細膩的圖片特征信息,提高圖像識別準確率.
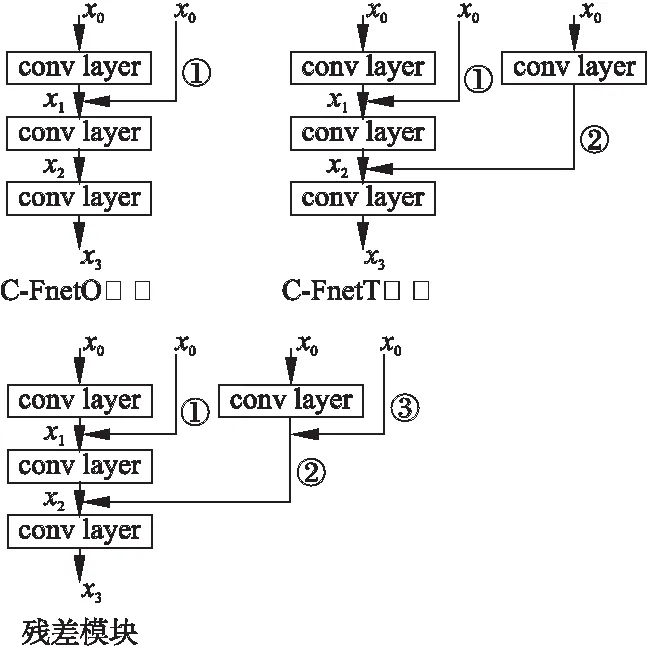
圖3 3種網絡的模塊拆解圖Fig.3 Model of three networks
在卷積神經網絡中,無論淺層網絡還是深層網絡,對圖像識別任務都具有重要作用.淺層的網絡可以提取低水平的圖像特征信息,而深層網絡可以提供高水平的圖像特征信息,為了更好融合兩者的信息,C-FnetT網絡采用了交叉連接方式.一方面,C-FnetT網絡可以實現端到端的訓練模式,實現梯度的反向傳播.另一方面,C-FnetT可以避免過擬合和梯度消失問題,縮短學習周期并避免網絡飽和問題.
3 實 驗
將C-FnetO和C-FnetT兩個網絡在4種公開數據集(MNIST,CIFAR-10,CIFAR-100和SVHN)上進行訓練和測試,為了對比模型效果,還增設了無連接網絡(Plain-net),經過一系列實驗,取n=5(此時效果最好)的3種網絡模型與其它典型網絡進行對比,它們的框架結構如圖4所示.
為了保證實驗的公平性,在每個實驗中,對4種數據集采取相同的圖像處理方法,超參數的設置也遵循公平對比原則.
3.1 數據集
MNIST:手寫數字數據庫[20]來自NIST的專用數據庫3(SD-3)和專用數據庫1(SD-1)[21],其中包含從0-9的二進制手寫數字圖像.它們由高等學校學生和美國人口普查局工作人員收集.訓練集共有60000個樣本,SD-3和SD-1分別提供30000個.測試集共有10000個樣本,SD-3和SD-1分別提供5000個.MNIST數據集由28×28的灰度圖像組成.
CIFAR-10:該數據集[22]由32×32像素的彩色自然圖像組成,共10個類別,訓練集有50000張圖片,測試集有10000張圖片.我們還采用了廣泛用于該數據集的標準數據增強方案[12](鏡像/移位).
CIFAR-100:該數據集[22]的尺寸和格式與CIFAR-10數據集一樣,不同的是CIFAR-100數據集包含100種類別.
Street View House Numbers:SVHN[23]數據集由Google Street View收集的32×32像素的彩色房屋編號圖像組成.數據集中有兩種格式,我們考慮第2種格式,73257張圖像作為訓練集,26032張圖像作為測試集,531131張圖像作為額外的一組數據集.這個數據集的任務是對位于圖像中心的數字進行分類,其他出現在背景中的數字不作為檢測目標.
3.2 訓 練
實驗平臺是單個GPU,參數是Nvidia TITAN Xp,采用的深度學習框架是Tensorflow,目前它非常受歡迎.
在CIFAR-10數據集上,模型在訓練時采用帶有動量的隨機梯度優化算法,借鑒文獻[24]中的方法,設置權重衰減(weight decay)大小為10-4,Nesterov momentum大小為0.99,權重初始化引用文獻[16]中的方法.每次訓練處理的圖片(batch size)為64張,迭代批次為200.初始學習率設為0.001,當訓練批次達到總批次數的50%和75%時,學習率除以10.
在CIFAR-100數據集上,每次訓練處理的圖片為128張,迭代批次為160.初始學習率設為0.1,當訓練批次達到總批次數的50%和75%時,學習率除以10.其它設置與CIFAR-10相同.
在手寫數字數據集(MNIST)上,每次訓練處理的圖片為128張,迭代批次為50.初始學習率設為10-4,當訓練批次達到總批次數的50%和75%時,學習率除以10.權重衰減和Nesterov momentum參數及優化算法設置和數據集CIFAR-10相同.
對于SVHN數據集,訓練網絡時采用Adam優化
算法,每次訓練處理的圖片為40張,迭代批次為25.初始學習率設為10-4,此外,還將局部對比歸一化[25](local contrast normalization)方法應用于該數據集的預處理.
然而,文章的目標不是實現最優的圖像識別效果,其中需要利用其他技術,如集成(ensemble),隨機化輸入順序(randomized input order)和抽樣方法(sampling methodologies)等.因此,并沒有采用這些輔助技術,而是僅僅使用一個簡單的模型框架進行對比實驗,驗證提出網絡的有效性.
3.3 C-FnetO,C-FnetT和Plain-net
C-FNetO,C-FnetT和Plain-net共3種網絡的具體參數和框架細節在表1和圖4中展示,由于采用n=5,所以網絡的卷積層層數共15層,圖4中從左至右依次是Plain-net,C-FnetO和C-FnetT,它們的基礎框架相同,只是在跨層連接線的設置上存在區別,并呈現由簡單到復雜的趨勢.
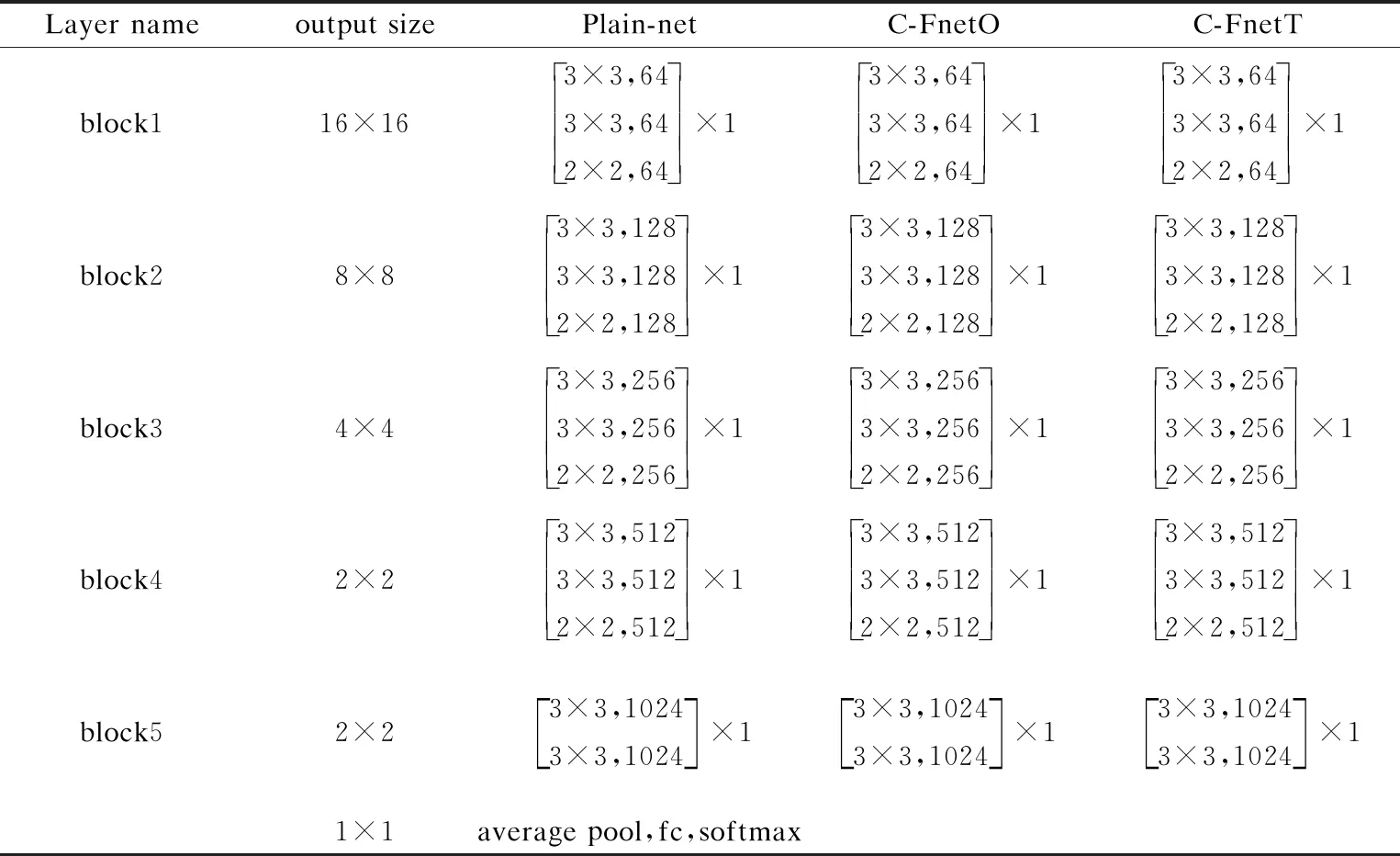
表1 3種網絡模型框架Table 1 Architecture for three networks
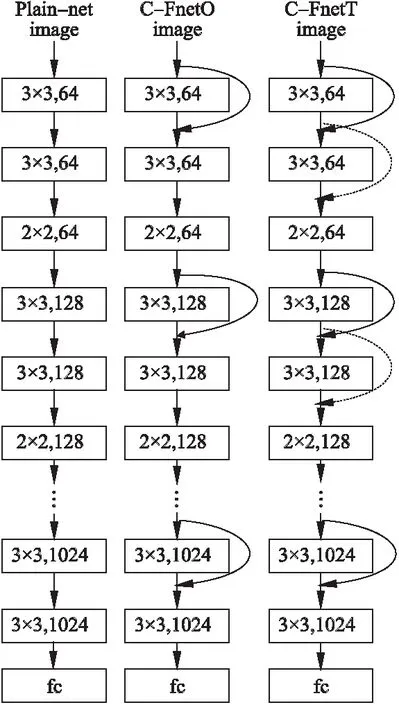
圖4 3種網絡模型結構Fig.4 Architecture for three networks
圖5記錄了3種網絡在不同數據集上的準確率,可以觀察到,C-FnetO比Plain-net的測試準確率高一些,而C-FnetT的測試準確率比C-FnetO高一些,即C-FnetT表現最佳,同時證明引入交叉跨層連接可以提高網絡性能.
3.4 實驗結果與分析
文章分別在4個公開數據集上對各種網絡模型進行測試,其中,MNIST數據集比較簡單,采用很淺的網絡就可以實
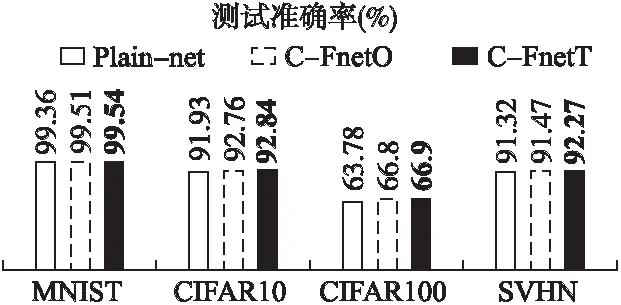
圖5 3種網絡的測試準確率Fig.5 Test accuracy of three networks
現不錯的圖像識別準確率,當采用復雜網絡時,很容易出現過擬合現象,但是在實驗中,通過dropout方法避免了過擬合的出現.在MNIST數據集上的測試準確率如表2所示,最好的測試結果以加粗黑體標注,可以觀察到C-FnetT網絡的準確率為99.54%,在所有的模型中表現最好,雖然結果和ResNet接近,但是C-FnetT的卷積層層數卻很少.
在CIFAR-10數據集上的實驗結果如表3所示,C-FnetT的層數最少,但是取得了相對最高的識別準確率,比ResNet,DenseNet,Inception-ResNet-v2和Xception分別提高了0.41%,9.63%,6.66%和7.24%.這是相當不錯的測試結果,較少的層數獲得了更高的準確率,證明了交叉連接方式的有效性和殘差模塊中跨層連接的部分冗余性.
在CIFAR-100數據集上的測試準確率如表4所示,C-FnetT依然是表現最好的網絡,比ResNet和DenseNet分別提高3%和34%.為了更充分證明C-FnetT優化方法的正確性,圖6展示了C-FnetT和ResNet訓練誤差對比圖,由于C-FnetT是在殘差模塊的基礎上進行改進,所以主要和殘差網絡對比.由圖6可以明顯發現在104次迭代訓練后,C-FnetT的訓練誤差遠遠低于ResNet,并保持下去,大大提高了模型收斂速度.

表2 MNIST上的圖像識別測試準確率(%)Table 2 Test accuracy(%)on MNIST dataset

表3 CIFAR-10上的圖像識別測試準確率(%)Table 3 Test accuracy(%)on CIFAR-10 dataset
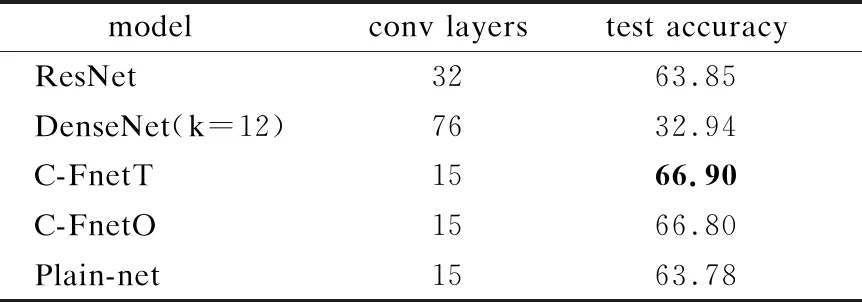
表4 CIFAR-100上圖像識別測試準確率(%)Table 4 Test accuracy(%)on CIFAR-100 dataset
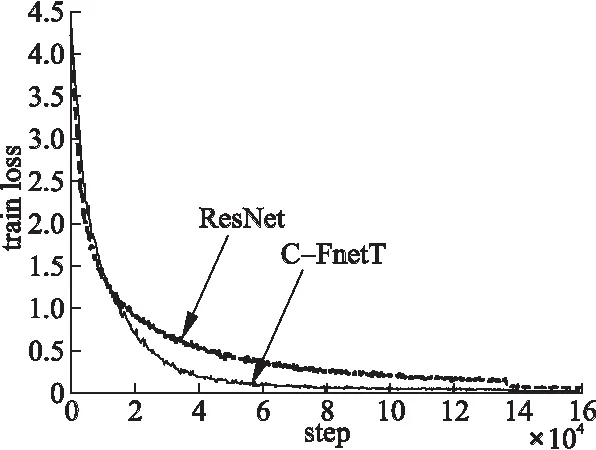
圖6 兩種網絡在CIFAR-100上的訓練誤差 (其中ResNet有32層,C-FnetT為15層)Fig.6 Train loss of two networks on CIFAR-100
表5記錄了模型在SVHN數據集上的準確率,C-FnetT的結果為92.27%,相比其它網絡獲得了最好的圖像識別效果.同時圖7繪制了C-FnetT和ResNet訓練誤差對比圖,在3×104次迭代訓練后,C-FnetT的訓練誤差開始明顯低于ResNet網絡,這樣的狀態一直保持到訓練結束,極大證明了C-FnetT模型的有效性.

表5 SVHN上的圖像識別測試準確率(%)Table 5 Test accuracy(%)on SVHN dataset
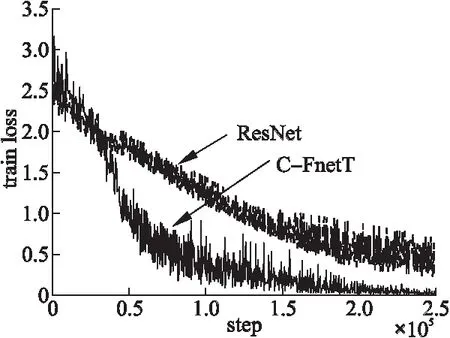
圖7 兩種網絡在SVHN上的訓練誤差 (其中ResNet有32層,C-FnetT為15層)Fig.7 Train loss of two networks on SVHN
4 總 結
文章提出兩種新型的網絡結構(C-FnetO和C-FnetT),它們在四種公開數據集(MNIST,CIFAR-10,CIFAR-100和 SVHN)上顯著提高了圖像分類準確率,尤其C-FnetT.首先,C-FnetT在殘差模塊基礎上進行優化,采用交叉連接方式,并以較少的層數獲得了比很多先進模型更高的準確率.此外,實驗結果表明,與其它方法相比,C-FnetT不僅具有更好的測試精度和泛化能力,而且加快了模型收斂速度.在未來的工作中,將文章提出的模型在ImageNet數據集上進行檢驗將成為主要任務.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
