基于改進ReliefF與k-means算法的良惡性肺結節分類模型
2021-03-21 05:11:56朱英亮仇旭陽
小型微型計算機系統 2021年3期
朱英亮,仇旭陽,徐 磊
(上海理工大學 光電信息與計算機工程學院, 上海 200093)
1 引 言
如今,肺癌已嚴重威脅人類的身體健康,在中國,肺癌在發病率和死亡率方面在城市人群里居于第一位.由于肺癌早期癥狀不明顯,容易發生誤診.在診斷不明而進行手術切除的結節中約有一半是良性.因此,進行早期地準確診斷并給出合理的治療方案具有非常重大的意義.CT作為無創輔助診斷的一種重要手段,由于其非介入性、高分辨率等特點,在臨床上被廣泛使用.
肺癌在初期表現為結節癥狀,利用計算機輔助技術協助專家對肺部CT圖像進行分析成為臨床上的主要應用.
目前利用圖像分析技術來輔助醫生進行良惡性肺結節的診斷已在臨床上得到了廣泛的應用,也是當前醫學圖像分析領域的熱門研究課題之一,很多學者提出了不同的算法模型進行良惡性肺結節的分類.Sangamithraa等人[1]利用灰度共生矩陣提取肺部結節的紋理特征,然后利用反向傳播網絡(BPN)完成良惡性肺結節的分類.Hien等人[2]提出了一種基于圖像小細胞集的灰度密度分布特征提取算法,利用該算法提取肺部的灰度密度特征,最后用隨機森林進行結節的分類. Akram Sheeraz等人[3]提出了一種基于混合特征的支持向量機(SVM)肺結節檢測和良惡性分類系統.但是該方法易受閾值的影響.Duan[4]提出用高斯混合模型(GMM)將提取的結節特征分組,再利用Relief和前向選擇算法找局部最優特征,最后用最優路徑森林進行結節分類,達到平均89.8%的識別率.Yang[5]提出了一種新型的多判別生成對抗網絡模型,該模型與編碼器相結合,用于肺結節的良性和惡性分類,識別率達到了95.32%,但是運行時間過長以及網絡復雜.Xie[6]等人一種基于多視角知識的協同(MV-KBC)深度學習模型,基于ResNet-50網絡進行訓練,惡性結節的識別率達到了95.7%,但是網絡足夠復雜,需求的數據集大,訓練極為耗時,要求的硬件性能過高.
近些年來,在傳統算法中灰度共生矩陣(GLCM)被各種研究表明是模式識別的有力基礎,利用GLCM計算出的紋理屬性有助于理解圖像內容的細節,GLCM的使用比主成分分析法(PCA)具有更高的準確率[7].Raju[8]等人使用了一種高效的與GLCM屬性相關的模糊C均值(FCM)分割算法,用于在超聲腎圖像中對腎囊腫和腫瘤進行分類.IUW Mulyono[9]等人利用灰度共生矩陣(GLCM)從parijoto水果中提取紋理特征,然后使用K最近鄰(KNN)方法對它們進行分類.Swati Jayade[10]等人提出利用GLCM提取皮膚癌變區域的圖像特征,將這些特征作為SVM分類器的輸入來進行分類.Huang[11]等人利用灰度共生矩陣提取海洋渦旋的紋理特征進行海洋渦旋識別.Zhou[12]利用灰度共生矩陣提取肺部CT圖像的9種紋理特征.但是良惡性肺小結節紋理區別主要在邊緣[13].因此本文利用灰度-梯度共生矩陣(GGCM)提取肺部CT圖像的14種紋理特征,并改進了灰度-梯度共生矩陣中提取邊緣的算子.在此基礎上,本文重點提出了一種基于新的距離度量的ReliefF算法使得重要特征能夠讓同類樣本聚合,不同類樣本分離,并且消除了樣本差異化及數量的影響,進而計算出對應的紋理特征的權重值,最后將權值應用到改進的k-means算法中構建結節分類模型.本文所選數據集為LIDC,其中共有1018個研究實例.本文從中選取128個實例,這些實例統計共有452個肺結節(包括247個惡性結節,205個良性結節,根據XML文件獲取結節良惡性信息).LIDC數據庫中都有一個XML注釋文件用來保存肺結節的主要特征信息,包含結節的惡性程度(良惡性結節),大結節(直徑≥3mm)的輪廓坐標,小結節(直徑<3mm)的中心點坐標等.從247個惡性結節中隨機選取180個,205個良性結節中隨機選取150個作為訓練集,剩下的良惡性結節作為測試集.本文采用準確率和平均準確率兩種指標來衡量提出算法對良惡性肺結節分類的準確性和有效性.
2 方 法
本文提出的方法主要包括以下4個步驟,并且算法流程圖如圖1所示.
1)運用中值濾波去除噪聲和直方圖均衡化對CT圖像進行增強;
2)提取CT圖像中肺結節區域;
3)運用改進的灰度-梯度共生矩陣提取肺結節ROI區域的紋理特征;

圖1 本文算法流程圖Fig.1 Algorithm flow chart
4)用改進的ReliefF和改進的k-means算法對紋理特征權重聚類,構建結節分類模型.
2.1 預處理
本文運用中值濾波和直方圖均衡算法對CT圖像進行濾波和增強.并對CT圖像進行256級灰度轉換,而后進行16級灰度壓縮,圖2為處理后的CT圖像及其直方圖.
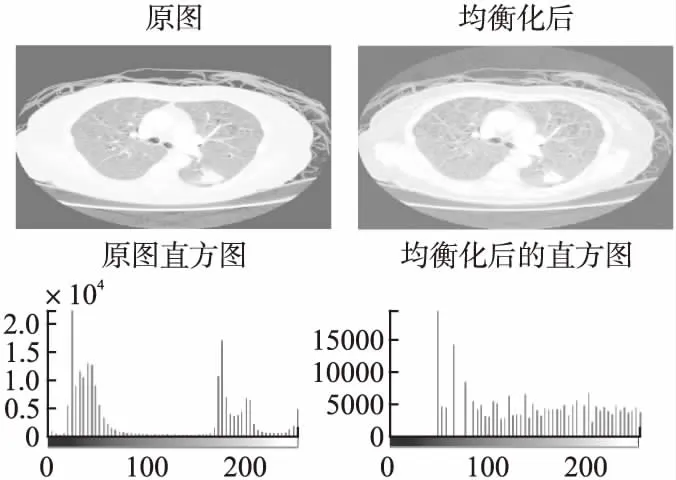
圖2 預處理后的CT圖像及其直方圖Fig.2 Preprocessed CT images and their histograms
2.2 提取肺結節區域
本文所選用的肺結節CT圖像數據的ROI(region of interest)區域是LIDC/IDRI數據庫中已經劃分好的,由4個放射學專家進行手動劃分,并將ROI區域位置信息保存在XML文件中,XML文件包含了切片CT原始數據的所有信息,將XML中ROI區域信息讀出后對肺結節進行分割,為后面的灰度-梯度共生矩陣提取肺結節特征做準備.如圖3所示,白色的線所示區域即肺結節區域.
2.3 灰度-梯度共生矩陣的改進及紋理特征提取
對圖像進行分類和識別最重要的就是對圖像特征進行提取,然后選取相關性強的特征進行分類.圖像的特征形式包括顏色、形狀、紋理及空間關系等,利用紋理特征進行疾病的分析已在臨床上得到了廣泛的應用,是用于疾病診斷的重要輔助手段.其中利用灰度共生矩陣(GLCM)提取圖像的紋理特征在特征分類中得到了較為廣泛的應用,但是僅僅利用灰度共生矩陣來提取肺結節的紋理特性是不夠的.因為良惡性小結節的紋理特性主要區別是邊緣,因此灰度-梯度共生矩陣(GGCM)成為了一種更好的選擇,但是其一般的做法是利用邊緣算子例如Sobel和Canny等進行提取邊緣來獲取梯度信息,但是Sobel和Canny等算子容易造成邊緣信息缺失.本文針對這一缺陷,提出了一種邊緣檢測算子,可以有效避免結節邊緣信息的泄露,更好地提取紋理特性來進行良惡性結節的識別.假設圖像為f,邊緣檢測算子(式(1))為:
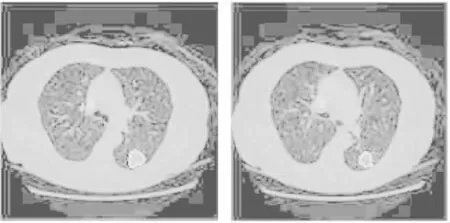
圖3 CT圖像中肺結節的ROI區域Fig.3 ROI of pulmonary nodules in CT images
(1)
其中Gσ是高斯核,σ為標準差,本文實驗中φ=2.如圖4所示為本文改進邊緣檢測算法應用在肺部CT圖像上的效果.圖4左側為Sobel算子的檢測結果,肺結節邊緣發生泄漏;右側為本文提出算法的檢測結果,結節邊緣信息完整.這能夠讓灰度-梯度共生矩陣提取更完整的結節邊緣信息,得到更全面的紋理特征.本文利用改進的灰度-梯度共生矩陣提取肺結節區域的小梯度優勢、大梯度優勢、灰度分布不均勻性、梯度分布不均勻性、能量、灰度平均和梯度平均等14個相關的紋理特征,并且按照測試樣本與訓練樣本3:1的比例,隨機選擇部分數據作為測試樣本,分別用灰度-梯度共生矩陣提取

圖4 CT圖像邊緣檢測算法對比Fig.4 CT image edge detection algorithm comparison
14個相應的特征紋理數據,然后將這些進行平均化處理得到相應的良性和惡性結節的14個紋理特征數據的對比圖,如圖5所示.從圖中可以看到,灰度-梯度共生矩陣提取的紋理特征中有些特征例如灰度差、小梯度優勢、相關性等特征就能很好區分良惡性肺結節(由于改進了邊緣檢測算子,因此梯度信息可以很好區分良惡性結節),而有些例如灰度平均、梯度平均等紋理特征就不能很好區分良惡性結節,因此需要在這14個紋理特征空間中剔除無關(區分效果不明顯)的特征量,縮小特征空間.
2.4 特征選擇算法及其改進
利用圖像的特征進行分類或者檢測時,需要將提取出來的特征進行一定程度上的冗余特征的去除.因為無關特征不僅會加大運算量和時間,而且會干擾分類的正確性.因此,如何從提取的眾多特征中找出相關性最大的特征成為利用紋理特征進行結節分類的關鍵性的一步.由于Relief系列算法簡單高效,使其得到了廣泛的應用.并且沒有數據類型的限制,

圖5 良惡性結節紋理特征對比Fig.5 Comparison of texture characteristics of benign and malignant nodules Average feature weight curve
根據特征和類別之間的相關性的大小來給相應的特征分配不同大小的權重,并且將權重小于某個閾值的特征剔除,達到選取特征的目的,但是它只能處理兩類別的數據.Kononenko[14]將Relief算法做了改進,使得能夠處理多類別問題,即ReliefF算法.每次從訓練集中隨機選擇一個樣本R,從該樣本的同類和不同類中各選擇k個最近鄰樣本,然后根據式(2)計算特征I的特征權重:
(2)
式中,diff(I,Ri,Hj) 和diff(I,Ri,Mj(C)) 為兩樣本在特征I上的歐式距離,用來表征兩樣本的相似程度,因此ReliefF算法的核心思想主要是讓重要的特征(分配的權重系數盡可能大)使得同類樣本盡可能靠近,不同類的樣本盡可能遠離,達到更好地分類效果.
Huang[15]提出特征選擇的準確度與訓練集樣本的數量是呈正相關的.在實際情況中,不同特征所對應的樣本數量是不一樣的,并不是均勻分布的.并且每次算法運行時選中的樣本點都不相同,因此屬性權值必會波動,也就是需要考慮樣本間的差異.因此本文提出改進的ReliefF算法.
假設一個訓練樣本集含有N個類別,則特征I的特征權重計算式為:


(3)
式(3)為本文改進的算法.其中Ldist的計算公式為:
(4)
在式(4)中,uc為與樣本R同類別樣本的中心,uj為與R不同類別的樣本中心,實驗中δs=0.5,δd=1.5.本文用新的距離計算方法取代歐式距離的計算方法,式(4)中第1項能使同一類別的樣本盡可能靠近,第2項能使不同樣本盡可能相離,這樣使得相關性強的特征能有效地進行分類.與此同時為了消除ReliefF算法中樣本數量對特征權值的影響,在計算特征權重時,考慮類別數N和樣本數Aj以及不同類的最近鄰樣本M,使得特征權重評價更加均衡.
為了消除其他特征分量的噪聲干擾,對樣本Ri在更新特征I的權值時,近鄰樣本的選擇以該維特征分量上的距離為準則,那么樣本間的距離可表示為式(5):
(5)
通過以上分析可知,本文改進的ReliefF算法使得特征權重分配更加均衡,新的距離計算公式使得重要特征能讓同類樣本更加聚合,不同類樣本相互分離,達到了更好的分類效果.另外本文綜合考慮樣本數量不均勻所帶來的權重值計算的缺陷,同時也減小了不相關特征的噪聲影響,使近鄰樣本的選擇更準確.
本文實驗數據來自UCI機器學習數據庫,選取數據類型為威斯康星州乳腺癌數據集(Breast Cancer Wisconsin (Original) Data Set),此數據集有699個樣本,每條數據有11個屬性,但是可以用于提取的只有9個特征.在訓練集上用ReliefF、Zhou[12]提出的W-ReliefF和本文算法進行特征選擇的對比實驗.根據式(4)隨機選取k個近鄰樣本,由于隨機k值的不同將導致不同的特征權重,因此本文采取平均值的方法,將3個算法各運行10次,最后取10次權重結果的平均值作為最后的特征權重系數.各個屬性權重的大小分布如圖6所示.由圖6所示,ReliefF算法的平均特征權值從大到小為1>6>3>8>7>5>2>9>4,W-ReliefF算法的平均特征權值從大到小為1>7>5>8>3>9>6>2>4,本文改進算法的平均特征權值從大到小為1>8>5>7>9>3>6>2>4.從圖6可以明顯看出屬性9的平均權值在3種方法當中變化小.因此選定屬性9作為權重閾值的邊界,因此可以明顯得到W-ReliefF在ReliefF的基礎上將屬性6剔除了,而本文算法在W-ReliefF的基礎上將屬性3剔除了,因此本文提出的算法進一步壓縮了屬性空間,而且剔除了傾向于占大多數的良性樣本的屬性3和6,保留了重要的屬性特征.

圖6 平均特征權值曲線圖Fig.6 Average feature weight curve
為了進一步驗證本文提出的改進的ReliefF算法的有效性,從UCI數據庫中隨機選取8個用于分類并且類別數不少于2的樣本作為訓練集進行實驗.表1為所選的訓練集的信息.
由于訓練集樣本中各類別的樣本數量分布不一樣,可以用表1的不平衡度來進行描述,可表示為式(6):

(6)
其中分子表明各個類別最大樣本數與最小樣本數之差(Nc為每個類別包含的樣本數),分母表明每個類別的平均樣本數(n為樣本總數,N為類別總數).式(6)表明各個類別最大與最小樣本數占每個類別具有的樣本數的比例之差,可以反應類別數據的分布情況.在數據集上分別運行ReliefF、W-ReliefF和本文改進的算法各20次,然后求出每個屬性平均權重系數,進行比較后,選出有效的屬性.最后運用k-means算法對特征選擇后的有效屬性進行分類,求出分類準確率,結果如表2所示,圖7為特征選擇結果.

表1 所選訓練集概況Table 1 Overview of the selected training set

表2 特征選擇前后的分類準確率比較Table 2 Comparison of classification accuracy before and after feature selection
由圖7可知,本文算法會使得數據集特征空間減小,去除相關性小的特征,并且效果比W-ReliefF和ReliefF算法好.表2中給出經過兩種算法進行特選擇后再利用k-means分類的準確率對比,帶有“↑”符號的,表示準確率上升明顯,“↓”符號的表示準確率有所降低.數據表明利用本文算法進行特征選擇后,識別準確率明顯提高的有6組數據,比其他算法的識別準確率都要高.本文改進的ReliefF算法比W-ReliefF算法效果更好,原因是本算法不僅考慮了樣本中各類別數的不均衡度,平衡了各特征權重系數的分配.而且在此基礎上利用重要的特征能使得同類樣本聚集,不同樣本盡可能分開的特性,重新設計了距離選擇公式.并且改進了近鄰樣本選擇的標準,更好地去除了冗余特征,使得識別的準確率更高.

圖7 特征選擇結果圖Fig.7 Feature selection result graph
2.5 聚類算法k-means及其改進
聚類算法是將一堆數據按照它們各自的特性分為幾個類別,它是一種無監督學習,使得同一類別中的數據相似性盡可能大,不同類別中的數據差異性盡可能大.k-means算法因其效率高、原理簡單,實現容易等得到了廣泛的應用.由于聚類算法是根據特征間的相似度來劃分的,因此,一般將內部特征間差異的相似度作為一個很重要的衡量指標,一般定義樣本點到數據中心點之間的距離的方法來描述數據之間的差異性[16].
k-means算法是基于歐式距離,該算法的核心公式為:
(7)

k-means算法的優點是效率高并且易于實現,但是也有一些的不足之處:
1)k-means算法以k為參數,需要事先人為設定好k值,也就是類別的個數,而k值的選定是難以估計的.然而本文研究的主要是良惡性結節的二分類問題,k值可以預先設定為k=2,因此可以忽略k值設定的影響.
2)k-means算法在聚類過程中,采用歐式距離來描述樣本之間的相似度,這種描述方式是假設樣本數據各個維度對于相似度的衡量作用是相同的,即沒有考慮樣本數據屬性之間的差異.重新計算每個類的質心(即為聚類中心),重復這樣的過程,直到質心不再改變,最后確定了每個樣本的所屬類別.因此算法的缺點是對類別規模差異太大的數據效果不好,并且對噪聲和離群點十分敏感,對于不同權重系數的特征屬性不能有效區分.因此本文對k-means算法做出對應的改進策略,使其更準確地進行良惡性結節的分類.
針對k-means算法的缺點,本文利用改進的ReliefF算法縮減樣本數據的特征空間,并賦予特征相應的不同權重值.并將不同大小的特征權重引入k-means算法中,此時的k-means算法改變了數據各個維度對于相似度的衡量作用,可以很好的消除噪點和離群點的影響.另外本文引入改進ReliefF算法中的距離法則,同類樣本盡可能靠近,不同樣本盡可能分開的思想,因此本文改進的k-means算法(式(8))為:
(8)
權重在聚類過程中實現等值聚類起著至關重要的作用,且改進的k-means算法中的wi是一個非負數,是由本文改進的ReliefF算法得到的各紋理特征對應的權值wi.
在模式識別的過程中,分類就是將具有相同特性的樣本歸為一類,而具有另外共性的歸為另一類.在醫學圖像的輔助診斷系統中,分類器可以用于病人病情決策.本文利用改進的ReliefF算法與改進k-means算法結合起來構建良惡性結節的分類器.
3 實驗結果與討論
對于提取的紋理特征利用改進的ReliefF算法計算特征權重,將權重大小進行比較分析,運行程序20次,統計結果如圖8所示.由圖8可知,灰度差、相關性、小梯度優勢等特征的權重最大,權重大的特征是最主要的影響因素,從多次計算規律來看,不同的特征有不同的重要程度,因此有著不同大小的特征權重,選取多個特征的組合進行實驗分析,本文將特征按照1-14進行編號.
本文利用改進的ReliefF算法對特征賦予權重的高低進行從大到小排序,并且選擇相應的權重數據,再利用改進的 k-means算法進行聚類分析,實驗結果如表3所示.

表3 應用不同屬性組合分類成功率Table 3 Success rate of classification by applying different combinations of attributes
從表3的實驗結果可以看出,選擇特征權重最大的8個屬性(灰度差、梯度差、能量、小梯度優勢、相關性、灰度熵、混合熵、逆差矩)用于結節分類,分類的正確率是最高的,同時實驗結果表明特征權重小的屬性會增加特征空間的維度,影響分類的精度.因此利用灰度-梯度共生矩陣提取出的紋理特征可作為良惡性結節分類的選擇特征.在此基礎上,本文將最大的8個紋理特征權重加入到改進的k-means算法中去,構建一個結合了改進ReliefF以及改進的k-means算法的良惡性結節分類器.本文提出的良惡性結節分類器是基于紋理特征進行識別的,實驗結果如表4所示.

表4 肺結節分類準確率Table 4 Classification accuracy of pulmonary noclules
由表4可以看出,根據紋理特征可以進行良惡性肺結節的識別,實驗結果表明:本文提出的算法對于惡性結節識別率高,良性結節識別率良好,并且改進的ReliefF和k-means算法均有效,準確率都有一定提升.如表5所示,本文將提出的算法與其他算法的識別率進行了比較,從比較結果中發現本文提出的算法相比其他傳統算法較優,使得良性結節的識別率有了一定的提升.但相對于文獻[6]提出的多視角知識的協同(Multi-View Knowledge-Based Collaborative)深度學習模型存在差距,原因是此方法ResNet-50網絡來提取結節的外觀、體素和形狀特性,然后再利用基于知識的協作(Knowledge-Based Collaborative)子模型進行分類.網絡深度深,模型復雜度高. 文獻[5]提出多將判別生成對抗網絡模型與編碼器相結合,用于肺結節的良性和惡性分類的算法也比本文識別率優,但是網絡復雜,訓練耗時.這些對于本文有進一步啟發,下一步工作可以利用深度學習的網絡提取肺結節不同視角的特征,再與編碼器相結合,最后利用本文改進的方法進行分類.

表5 幾種算法的比較Table 5 Comparison of several algorithms

圖8 改進ReliefF算法計算20次屬性的權重分布誤差棒圖Fig.8 Improved ReliefF algorithm calculates the error bar graph of weight distribution of 20 attributes
4 結 論
本文對肺部CT圖像首先利用改進了邊緣檢測算子的灰度-梯度共生矩陣提取了14種紋理特征參數,然后通過改進的ReliefF算法使得分類作用大的特征將同類樣本聚合,不同類樣本分開,并且降低特征空間的維度.最后本文對k-means算法的距離度量進行改進,引入同類樣本聚合、不同類樣本分開的距離度量準則,將重要特征的權重引入到此算法中進行良惡性肺結節的分類.本文構建了從提取紋理特征到冗余特征去除再到分類的算法模型.并且在實驗測試集上通過大量實驗以及識別率對比得出不同紋理特征對于分類的貢獻效果各不相同,紋理特征空間存在冗余特征,需要通過一定手段進行特征空間的壓縮,本文實驗發現灰度梯度共生矩陣提取的紋理特征中灰度差、梯度差、能量、小梯度優勢、相關性等8個重要特征的組合可以得到最好的分類結果,本文算法可以達到良性結節83.46%,惡性結節95.02%的識別率.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
