學貫中西:讓機器學習華夏智慧
2021-03-22 09:10:20高煥堂
電子產品世界 2021年11期
關鍵詞:特征
高煥堂
0 前言
機器學習(ML)除了能夠學習大數據(big data)中的規律和法則之外,也能夠學習人類的智慧。華夏文化淵源長久、博大精深,處處充滿智慧。因此,我們可以讓機器來學習華夏的文化底蘊和智能,還能更上層樓而學貫中西。
1 復習:什么是特征(feature)
機器學習之路,首先從觀察特征出發。回憶一下,人們對于周圍的問題或事件常從不同的角度來觀察或看出不同的特征。所謂特征(feature),就是一件事物或一群事物,其具有與眾不同的特色或表征。例如,人們在辨別其他人的長相時,常常會觀察對方的臉形、眼神、嘴巴、發型等特征來區分和判斷,只要記住對方獨特的長相特征就可以,而不必記憶其他細節。這是人們天賦的觀察和提取特征的能力。再如,當您一大早從家里出門時,常常會先觀察天氣的特征:溫度23℃、“陽光普照”等。
在前面各期曾經說明了ML(機器學習)的目的并不一定是拿數據來運算,而是在于〈觀察〉在此X空間里數據的大小、分布及重復出現頻率(次數)等。每一條數據成為空間里的一個點(point),而每一項特征則成為空間的一個維度(dimension)。于是,各條數據的特征值成為該點的坐標值。
2 特征的種類
在ML(機器學習)領域,特征常分為兩種:數值型(Numerical)特征與分類型(Categorical)特征。“數值型特征”是大家很熟悉的,可以用整數或浮點數表示,是能拿來進行加減乘除等數學計算的特征(值)。例如剛才提到的氣溫是23℃。這就是一個數值特征。再如,人的身高、貓尾巴長度等也都是數值特征。至于分類型特征,又可細分為兩種:次序型(ordinal)特征和名目型(nominal)特征。
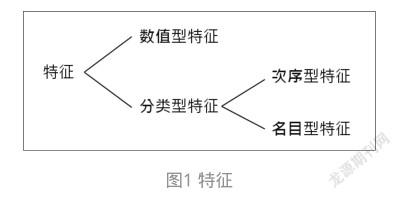
其中,“次序型特征”是具有順序、可分等級的特征。例如,衣服的大小常常分為:小(S)、中(M)、大(L)、特大(XL)4個等級。再如,牛排的熟度可分為:Blue、Rare、Medium Rare、Medium、Medium Well和Well Done 6個級別。
再如,《孫子兵法》有言:“不戰而屈人之兵,善之善者也。故上兵伐謀,其次伐交,其次伐兵,其下攻城。”其中分為4個等級:伐謀、伐交、伐兵和攻城。《孫子兵法》又言:“知彼知己,百戰不殆。不知彼而知己,一勝一負。不知彼不知己,每戰必殆。”其中分為三個等級:知彼知己、不知彼而知己和不知彼不知己。
“名目型(nominal)特征”只是對事物分門別類之后各類別的名稱或標簽而已。例如,性別:男、女。兩儀:陰、陽。五行:金、木、水、火、土。它們之間沒有級別之分。
3 如何對“分類型特征”進行編碼
在ML領域,必須將分類型特征轉換成數字,又稱為對這些特征進行編碼(encoding)。對于次序型與名目型特征,各有不同的方法將它們轉換成數字。
例如,對于次序型(ordinal)特征常使用卷標編碼(label-encoding)方式進行轉換。例如,衣服的小(S)、中(M)、大(L)、特大(XL)4個等級對應1、2、3、4,這樣特征(值)之間的大小順序也就呈現出。再如,牛排熟度的Blue、Rare、Medium Rare、Medium、Medium Well和Well Done 6個等級對應1、2、3、4、5、6,這樣就可以了。
另外,對于名目型(nominal)特征則常使用唯1編碼(one-hot-encoding)方式進行轉換,在中文里又稱為“獨熱編碼”。例如上述的兩儀。
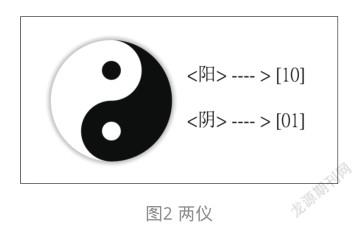
由于它們之間不具有順序性,所以也可把“陽”對應成[01],而“陰”對應成[10]。

由于每一個編碼中都含有一個1,其他都為0,所以稱為One-Hot-Encoding編碼;簡稱OHE編碼。
4 “分類型特征”的范例
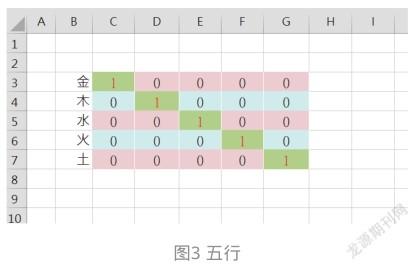
剛才已經提到了華夏文化中的五行觀念,就是金、木、水、火、土。使用OHE編碼如下:
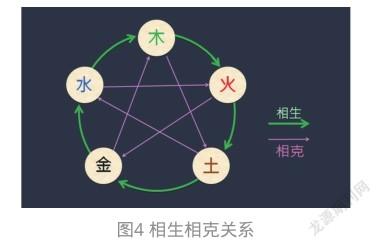
大家知道,五行之間有“相生”關系,也有“相克”關系。
現在,來建立一個兩層神經網絡(NN)模型,如圖5所示。

以NN模型表示如圖6所示。
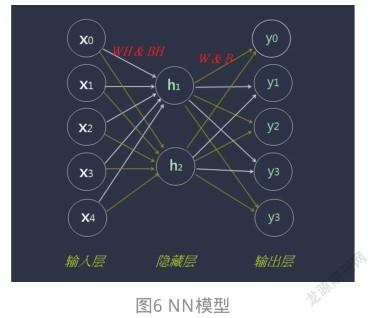
在Z空間中設定了5個目標值,如圖7所示。
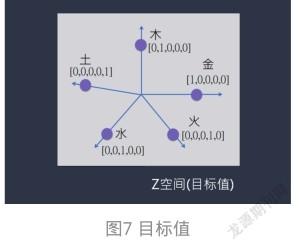
只要按下“學習”按鈕,ML就會尋找出隱藏層的權重WH和BH,同時尋找出輸出層的權重W和B。如圖8所示。
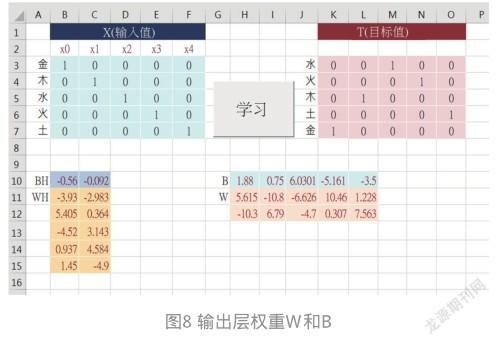
有了隱藏層的權重WH和BH,以及輸出層的權重W和B之后,就可以隨時輸入層X空間,對應隱藏層H空間,再對應輸出層的Z空間,就得到預測值了。例如,把剛才訓練好的權重拿過來,就可以隨時輸入X值,然后通過兩層權重的計算得到Z預測值。這個過程,就是所謂的:預測(Predict)。如圖9所示。
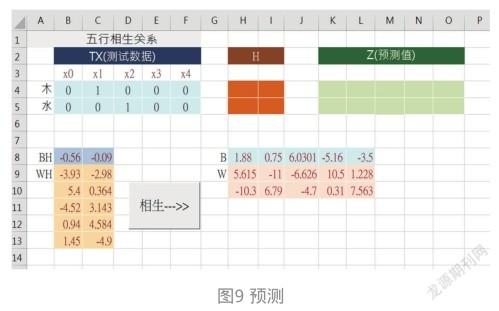
請按下“相生”,輸入木和水的OHE編碼,然后通過兩層權重的計算得到Z預測值。如圖10所示。
例如,輸入測試數據:木=[0,1,0,0,0],通過NN模型的兩層權重計算得到預測值。此時,ML計算出預測值:Z=[0.02、0、0、0.95、0.03]。那么,ML如何得知這個預測值就是“火”呢?非常簡單,只要看看Z空間中這個預測值代表的點靠近哪一個目標值(點)就知道了。例如,預測值Z=[0.02、0、0、0.95、0.03],非常靠近[0、0、0、1、0],所以歸于“火”類。如圖 11所示。
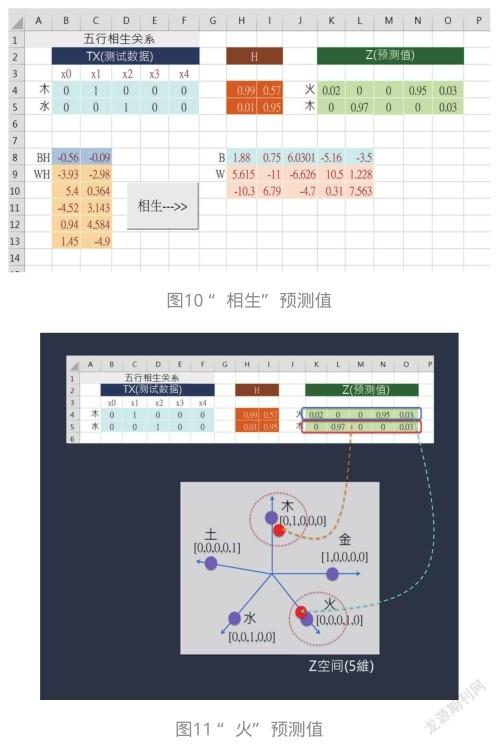
同樣,另一測試資料:水=[0、0、1、0、0],通過NN模型的兩層權重計算得到預測值:Z=[0、0.97、0、0、0.03]。那么,ML如何得知這個預測值就是“木”呢?非常簡單,只要看看Z空間中這個預測值代表的點靠近哪一個目標值(點)就知道了。例如,這預測值Z=[0、0.97、0、0、0.03],非常靠近[0、1、0、0、0],所以歸于“木”類。
5 結語
善于使用OHE編碼將非常方便表達華夏文化中的概念(Concept)和術語。然而,您可能會問:如果數千或數萬個術語,其OHE編碼將變得很冗長,實際上可行嗎?答案是沒問題的。因為ML有很好的機制可以進行“降維”,能有效化解上述問題。下一期,將會繼續說明。
3175501908239
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
