CGGA:一種CNN與并行門控機制混合的文本分類模型
2021-03-22 01:37:22馬建紅劉亞培劉言東陶永才
小型微型計算機系統 2021年3期
馬建紅,劉亞培,劉言東,陶永才,石 磊,衛 琳
1(鄭州大學 軟件學院,鄭州 450002) 2(鄭州大學 信息工程學院,鄭州 450001) 3(河南省國土資源電子政務中心,鄭州 450002)
1 引 言
新聞通過公開媒體傳播,隨著網絡的快速發展,紙質新聞時代迅速轉變為網絡媒體時代,隨之新聞文本數量呈指數級增長.如何在海量信息中對文本正確、高效地分類,是自然語言處理發展中一個重要的問題.相比國外文本分類技術的發展,國內文本分類技術起步較晚,且中英文表述方式不同,因此兩者在文本分類技術研究中會面臨不同的問題[1].
傳統的文本分類方法是將特征工程與分類方法結合進行文本分類[2].特征工程中,文本通過詞袋模型、n-grams詞袋模型、向量空間模型等,將文本轉化為計算機可理解的方式.之后,利用布爾權重計算、TF-IDF權重計算、基于熵概念的權重計算等方法,進行特征選擇.最后利用樸素貝葉斯算法(Naive Bayesian algorithm)、K近鄰算法(k-Nearest Neighbor,KNN)、決策樹方法、支持向量機分類等分類方法,對文本進行分類.這些分類方法特征表達能力差,序列捕捉能力弱,很難深層次的表征文本信息.而對于文本數據,最重要的是如何更好的選取特征,以及快速捕捉到上下文等信息.
隨著深度學習的發展,利用神經網絡來處理文本分文本類問題成為研究熱點.基于卷積神經網絡(Convolutional Neural Networks,CNN)、循環神經網絡(Recurrent Neural Network,RNN)的方法可以有效的緩解詞語特征表征能力弱,序列捕捉能力差等問題.卷積神經網絡[3]通過稀疏交互和權值共享,來進行特征提取,并能有效的減少學習參數的參數量,從而提高運算效率.循環神經網絡通過上一時刻的信息和當前時刻的輸入,來確定當前時刻的信息,保持了數據中的依賴關系,有效的解決了序列數據的處理問題.但是隨著卷積神經網絡、循環神經網絡在文本處理上的研究越來越深入,關于以上兩種網絡處理序列型數據的缺點也隨之暴露.CNN會出現忽略局部與整體之間的關聯性的問題,RNN則存在隨著遞歸,權重指數級爆炸或消失、難以捕捉長期時間關聯等問題.并且,對于中文文本分類研究中,存在文本分類準確率不高、容易出現忽視上下文信息特征問題.
現有的神經網絡文本分類模型大多是幾個模型的簡單堆疊,沒有很好的對模型的缺點針對性的優化,并且對于中文的文本分類研究較少,且中文文本分類仍存在分類準確率低、缺少多方面特征提取等問題.為了解決以上問題,本文在卷積神經網絡(CNN)的基礎上引入雙向門控循環單元(Bidirectional Gated Recurrent Unit,BiGRU)來學習上下文信息,增強局部與整體之間關聯性,彌補卷積網絡提取特征多樣性的不足;利用門控Tanh-ReLU單元(Gated Tanh-ReLU Units,GTRU)控制信息流動,并緩解梯度彌散的問題;使用多頭注意力機制(Multi-Head Attention)來優化模型,提高模型文本分類準確率.
2 相關工作
Kim Y等人[4]使用CNN進行句子級文本分類任務,其融合多個不同大小的卷積核進行卷積操作來進行特征提取,并利用Max-over-time pooling來選出每個特征映射中的最大值,之后傳遞給一個完全連接的softmax層,其輸出是標簽上的概率分布,該模型在多個基準上取得了很好的效果.Lai等人[5]提出了循環卷積神經網絡(RCNN)分類方法,將左側上下文向量、詞嵌入、右側上下文向量進行拼接,來得到上下文信息,利用線性變換和tanh激活函數得到最大池化層的輸入,然后自動判斷哪些單詞在文本分類中扮演關鍵角色,從而進行文本分類任務.Johnson 等人[6]提出了一種低復雜度的詞級深度卷積神經網絡文本分類體系結構,將卷積層與步長為2 的池化構成疊加模塊,可以有效地表示文本中的長距離關系,并加入殘差模塊來進行深層網絡的訓練.
隨著網絡的加深,會出現梯度彌散的現象,以至于難以訓練深層次的網絡.Dauphin等人[7]第一次將門限控制引入到CNN中,介紹了門控線性單元(Gated Linear Units,GLU)和門控雙曲正切單元(Gated Tanh Units,GTU),并在其論文中構建了門控卷積網絡的語言建模體系結構,利用門控線性單元(GLU),來控制層次結構中信息的傳遞,該模型在WikiText-103上實現了一個新的技術狀態,并在谷歌億字基準上實現了一個新的最佳單gpu結果.Gehring等人[8]提出完全基于卷積神經網絡的序列到序列(ConvS2S)的翻譯模型,分別在編碼與解碼的卷積操作之后,引入GLU激活單元作為非線性運算以優化梯度傳播,證明了其有效性.Xue等人[9]建立了方面嵌入的門控卷積網絡(GCAE),將詞嵌入經過卷積操作之后經門控Tanh-ReLU單元(Gated Tanh-ReLU Units,GTRU)來控制情感特征和方面特征的傳播,從而進行方面級情感分類.這里我們將門控Tanh-ReLU單元進行簡化并應用到中文新聞文本分類處理的問題中,來進行文本特征選取,優化文本分類模型.
由于RNN的迭代性會造成梯度消失問題和梯度爆炸問題[10],Hochreiter等人[11]提出長短期記憶(Long Short-Term Memory,LSTM)解決了梯度反向傳播過程中梯度消失問題,并能夠保持數據中的長期依賴關系,其表現優于RNN,之后經改良和推廣到廣泛應用.Cho等人[12]提出門控循環單元(Gated Recurrent Unit,GRU),GRU是LSTM的一種簡化結構,與LSTM性能相當,但參數更少,收斂速度更快,不容易過擬合[13],Cho等將其應用到機器翻譯領域,并取得不錯的效果.鄭誠等人[14]提出了一種基于密集連接循環門控單元卷積網絡的混合模型(DC-BiGRU_CNN)用于處理短文本分類,在多個公開數據集上,該模型的文本分類準確率有顯著提升.
注意力機制(Attention Mechanism)來源于人類的視覺,人類可以將有限的視覺資源進行有效的分配,從而來關注比較重要的信息.Vaswani等人[15]利用多個相同的放縮點積注意力(Scaled Dot-Product Attention)構成多頭注意力(Multi-Head Attention),并提出一種完全基于注意力機制的翻譯模型,在兩個機器翻譯任務上取得了更優的效果,證明了注意力機制的有效性.Zehui等人[16]提出了多任務多頭部注意記憶網絡(MMAM),用多頭文檔注意機制作為內存對共享文檔特征進行編碼,用多任務注意機制來提取特定類別的特征,在餐廳領域和汽車領域的兩個中文細粒度情感分析數據集上的結果優于其他細粒度情感分析模型.王吉俐等人[17]利用循環神經捕捉文本的上下文信息,通過引入注意力機制得到文本類別的特征向量矩陣后,運用卷積神經網絡模型完成文本的分類.
在學習與探索了前人在中文文本分類方面的研究上,本文構建了一種基于卷積神經網絡的混合門控文本分類模型(CGGA).將預先處理好的字符級詞向量作為卷積層的輸入,利用卷積進行局部特征提取,從而得到特征向量;與雙向門控循環單元(BiGRU)結合,來獲取數據內部聯系以進行上下文建模,來提取數據間的關系特征;利用門控Tanh-ReLU單元(GTRU)進一步篩選上層的輸出特征,并減輕模型的梯度彌散問題;之后利用多頭注意力機制來關注不同子空間信息,對權重進行更新計算;最后用softmax多分類器進行文本類別分類.本文構建的CGGA中文文本分類模型在 THUCNews數據集、搜狐數據集(SogouCS)上取得了較好的效果,證明該模型在結構和提高分類準確率等方面具有一定的實用性與創新性.
3 模型實現
本文結合卷積神經網絡(CNN)、門控Tanh-ReLU單元(GTRU)、雙向門控循環單元(BiGRU)和多頭注意力機制(Multi-Head Attention),構建一個中文文本分類模型,具體工作如下.
3.1 門控Tanh-ReLU單元(Gated Tanh-ReLU Units,GTRU)
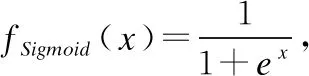
門控線性單元(Gated Linear Units,GLU)表示為fl-GLU(X)=(X*W+b)?σ(X*V+c),即將卷積后的結果分別經過線性映射和S形門控,并將兩者的輸出相乘,作為下一層的輸入.門控雙曲正切單元(Gated Tanh Units,GTU)表示為fl-GTU(X)=tanh(X*W+b)?σ(X*V+c),即將卷積后的結果分別經過tanh門控和S形門控,并將兩者的輸出相乘,作為下一層的輸入.其中σ是sigmoid函數,?是矩陣間的元素相乘.
在本文中,我們引入門控Tanh-ReLU單元(Gated Tanh-ReLU Units,GTRU)[9],并去掉式子relu(X*W+Vv+b)中方面類別的嵌入向量v,將GTRU簡化表示,如公式(1)所示:
fl-GTRU(X)=relu(X*W+b)?tanh(X*V+c)
(1)
其中,X∈RN×m是l層的輸入,其是單詞嵌入或是前一層的輸出,N為詞序列的長度,m為詞向量的維度,W∈Rk×m×n、V∈Rk×m×n表示不同的卷積核,k為卷積核的大小,n表示輸出維度,b∈RN、c∈RN表示偏置參數.
GTRU將卷積后的輸出分別經過一次線性映射relu(X*W+b)和門tanh(X*W+c)控制,將兩者的輸出相乘作為下一層的輸入,從而控制信息向下層流動的力度.Sigmoid函數與tanh函數線性相關,Sigmoid在輸入處于[-1,1]時,其函數值變化比tanh函數更敏感,一旦接近或超出區間就失去敏感性,使處于飽和狀態,影響神經網絡預測的精度值;而tanh函數的輸出和輸入能夠保持非線性單調上升和下降關系,其收斂速度快、容錯性好、有界,且其飽和期晚于Sigmoid函數[20].GTRU和GLU只有一個衰減項,相比GTU可以較好地減輕梯度彌散,且GTRU和GLU都擁有線性的通道,可以使梯度很容易通過激活的單元,反向傳播且不會減小,但在相同的訓練時間下,GTRU比GLU、GTU獲得更高的精度.因此,采用GTRU來構建文本分類模型,以提高文本分類性能.
3.2 雙向門控循環單元(BiGRU)
LSTM 解決了傳統RNN中反向傳播過程中出現的梯度消失等問題,而GRU 保持了 LSTM 效果,具有更加簡單的結構,更少的參數,更好的收斂性.門控循環單元(GRU)由兩個門組成,分別為重置門r(reset gate)與更新門z(update gate),這兩個門控機制能夠保存長期序列中的信息,且不會隨時間而清除或因為與預測不相關而移除.其結構如圖 1所示.
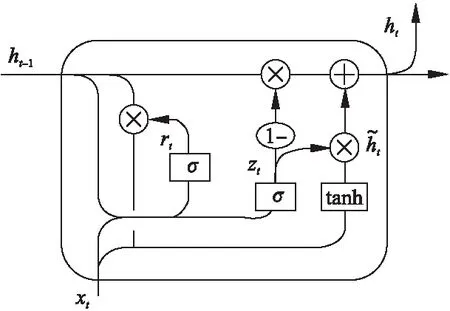
圖1 GRU模型Fig.1 Gated Recurrent Unit model
GRU模型的計算過程如公式(2)~公式(5)所示:
rt=σ(Wr·[ht-1,xt])
(2)
zt=σ(Wi·[ht-1,xt])
(3)
(4)
(5)
雙向門控循環單元(BiGRU)在文本序列建模時,在每一時刻,輸入會同時提供兩個方向相反的GRU,而輸出則由這兩個單向GRU共同決定.BiGRU的具體結構如圖2所示.
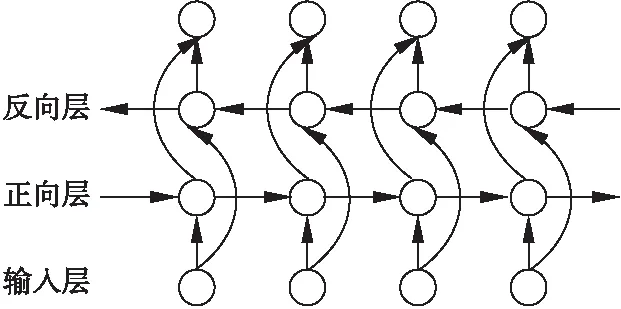
圖2 雙向門控循環單元模型結構(BiGRU)Fig.2 Bidirectional Gated Recurrent Unit model structure
其具體計算過程如公式(6)~公式(8)所示:
(6)
(7)
(8)
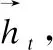
3.3 多頭注意力機制(Multi-Head Attention)
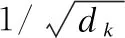
(9)
在多頭注意力操作之前,先將Q、K、V進行線性變換,之后將其映射到h個不同的子空間,在每個子空間中進行放縮點積注意力計算,以關注不同子空間的重要信息.之后將以上子空間上的注意力的輸出進行拼接.多頭注意力總體架構如圖3所示.
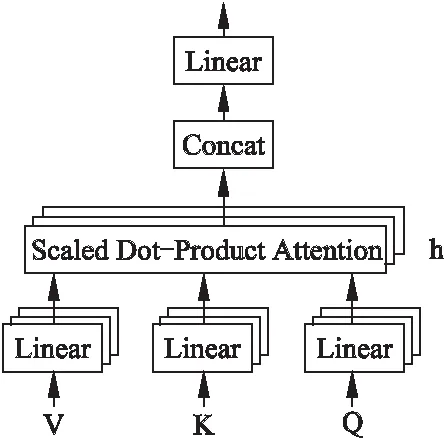
圖3 多頭注意力Fig.3 Multi-Head Attention
多頭注意力機制的計算如公式(10)所示.
(10)
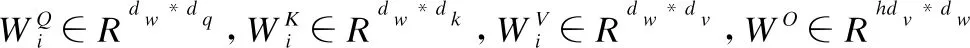
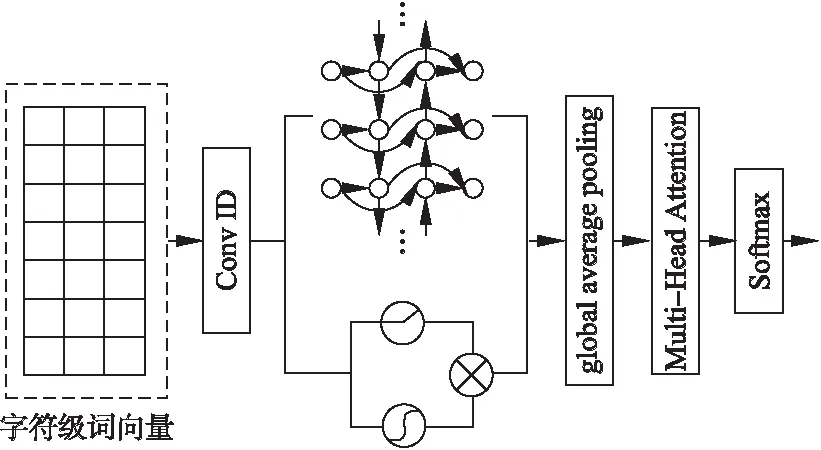
圖4 CGGA模型Fig.4 CGGA model
3.4 CGGA中文文本分類模型
本文的所構建的CGGA中文文本分類模型結構如圖4所示.已有研究表明,字符嵌入可以最大程度的保持原文本信息,故實驗中將字符級詞向量作為卷積層的輸入.在數據預處理階段,將原始中文序列文本按字符劃分為單個漢字與符號,再構建大小為5000的詞匯表,使用one-hot編碼對每個字符進行量化,之后將輸入的中文序列轉化為相應的向量序列.這里字符向量序列最大長度設置為700,輸入序列長度不足700或字符不在詞匯表中的用零向量表示,超過設置長度的字符都忽略.
模型中,首先將字符級詞向量輸入到卷積層進行卷積操作,得到局部特征矩陣;然后將特征矩陣分別輸入到GTRU和BiGRU,對整個輸入特征進行上下文建模,學習數據上下文之間的聯系;之后將兩者的輸出結果進行拼接,作為全局平均池化(Global Average Pooling,GAP)的輸入,這里使用全局平均池化替代全連接層,以進行特征壓縮并防止過擬合;然后利用多頭注意力機制進行特征權重更新計算,使模型在相應文本類別上有著更高的輸出;最后利用softmax進行中文文本分類.
4 實 驗
4.1 實驗環境
本文的實驗環境及其配置如表1所示.

表1 實驗環境配置Table 1 Experimental environment configuration
4.2 實驗數據集
1)THUCNews數據集,是由清華大學自然語言處理實驗室推出的中文新聞文本分類數據集,包含74萬篇新聞文檔,分為14個新聞類別.本文選取其中的10個類別,每個類別包含6500篇新聞文檔,其中5000為訓練集、500驗證集、1000為測試集.
2)搜狐新聞數據集(SogouCS),是搜狐實驗室推出的中文新聞文本數據集,本文選取其中的12個類別,每個類別大約包含3000篇新聞文檔,其中2000左右為訓練集、500驗證集、500為測試集.
4.3 實驗評價指標
本文使用宏平均精確率(Macro average precision,MAP)、宏平均召回率(Macro average recall,MAR)、宏平均F1-Score(Macro average F1-Score,MAF1)來作為文本分類評測指標,它們分別是指每個類別的精確率、召回率、F1-Score的算術平均.各評價指標的計算公式如式(11)~式(13)所示:
(11)
(12)
(13)
其中,n為總分類數,Pk為第k類的精確率,Rk為第k類的召回率,F1k為第k類的F1-Score.
4.4 實驗參數設置
在實驗中,模型的參數值的設置會影響到實驗的最終結果,這里列出本文實驗中的部分參數,以此為基準進行實驗.本實驗的模型參數設置如表2所示.
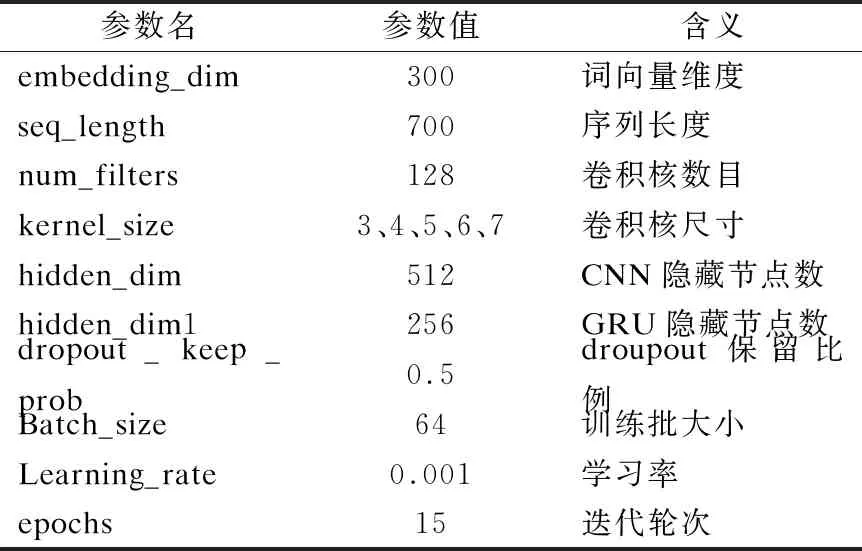
表2 模型參數設置Table 2 Model parameter setting
4.5 實驗結果對比與分析
使用單一的字符級卷積神經網絡(CCNN)作為基線文本分類模型.這里字符級卷積神經網絡的基本結構包括:輸入層、卷積層、激勵層、全局平均池化層、輸出層.
4.5.1 不同優化操作對比
在CCNN模型中,分別使用ReLU激活函數、門控線性單元(GLU)、門控雙曲正切單元(GTU)和門控Tanh-ReLU單元(GTRU)來對比不同激活操作對文本分類性能的影響.其中,以最常用的ReLU激活函數作為基礎,進行測試對比.
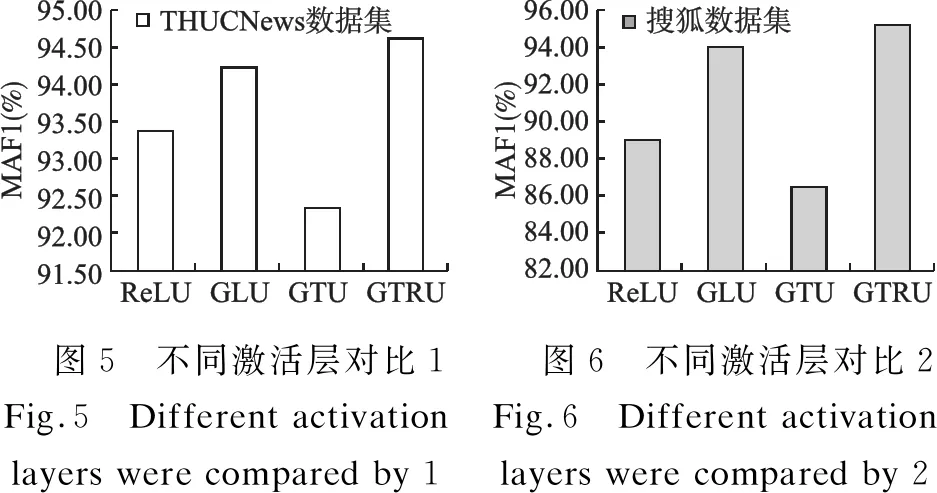
圖5 不同激活層對比1Fig.5 Different activationlayers were compared by 1圖6 不同激活層對比2Fig.6 Different activationlayers were compared by 2
圖5和圖6是分別在THUCNews數據集和在搜狐數據集(SogouCS)上,具有不同激活操作的CCNN模型的宏平均F1-Score(MAF1).從兩個圖中可以看出,使用GLU和GTRU的CCNN模型文本分類結果的MAF1值均高于使用ReLU激活函數,且使用GTRU的結果更好.使用GTU的文本分類結果MAF1值低于使用ReLU激活函數.其中,使用門控Tanh-ReLU單元(GTRU)的模型MAF1值比使用ReLU激活函數在THUCNews數據集和在搜狐數據集(SogouCS)上分別高1.24%、6.28%.由此證明了門控Tanh-ReLU單元(GTRU)在卷積網絡中的優化效果更好.
4.5.2 不同并行結構模型對比
CCNN-BiGRU模型:將字符級向量分別作為單一的CCNN模型和BiGRU模型的輸入,之后將兩者的輸出拼接,然后進行分類實驗;CCNN(GTRU)-BiGRU模型:將字符級向量分別作為使用GTRU的CCNN模型和BiGRU模型的輸入,之后將兩者的輸出拼接,然后進行分類實驗;CGG模型.將本文所構建的CGGA模型(如圖4所示)去掉注意力機制,這里簡寫為CGG模型.將這3個具有并行結構的模型進行實驗對比.
表3為3個不同的并行結構在兩個數據集上的宏平均召回率(MAR).在THUCNews數據集上和搜狐數據集(SogouCS)上,模型CNN(GTRU)-BiGRU比模型CNN-BiGRU的宏平均召回率(MAR)分別高0.08%、0.20%,說明使用GTRU優化的CCNN模型與BiGRU并行的分類結果更好,且證明了GTRU的有效性.模型CGG比模型CNN(GTRU)-BiGRU的MAR分別高0.32%、0.05%,比模型CNN-BiGRU的MAR分別高0.40%、0.25%,證明本文的并行結構分類效果更好.
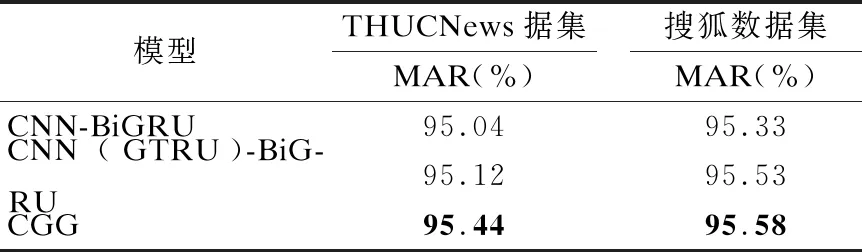
表3 并行結構模型對比Table 3 Parallel structure model comparison
4.5.3 不同分類模型對比
表4為5個模型分別在THUCNews數據集和搜狐數據集(SogouCS)上分類的宏平均精確率(MAP),這5個模型分別為:字符級卷積神經網絡(CCNN)、雙向門控循環單元(BiGRU)、增加了多頭注意力的字符級卷積神經網絡(CCNN-A)、CGG模型、本文構建的分類模型CGGA.由CCNN模型和CCNN-A模型、CGG模型和CGGA模型兩組對比模型的宏平均精確率(MAP)值可以看出,增加了多頭注意力機制后的模型在兩個數據集上的MAP更高,這證明了多頭注意力機制可以優化模型,使模型的分類精確率更高.在THUCNews數據集上CGGA模型分類的宏平均精確率比單一的CCNN模型和BiGRU模型的分別高2.24%、0.76%;在搜狐數據集上CGGA模型分類的宏平均精確率比單一的CCNN模型和BiGRU模型的分別高6.78%、0.92%.從實驗結果可以看出,本文構建的CGGA模型可以有效的提高文本分類的精確率.

表4 模型分類精確率對比Table 4 Model classification precision rate comparison
4.5.4 不同卷積核尺寸大小對比
這里本文將分別測試尺寸大小分別為3、4、5、6、7的卷積核對CGGA模型文本分類的影響.
由圖7可以看出,在兩個數據集上的宏平均精確率(MAP)的折線走向,先下降后上升再下降,在卷積核尺寸為6時取得最高的宏平均精確率.由此說明了在CGGA模型上,卷積核尺寸的不同會影響模型的分類效果.
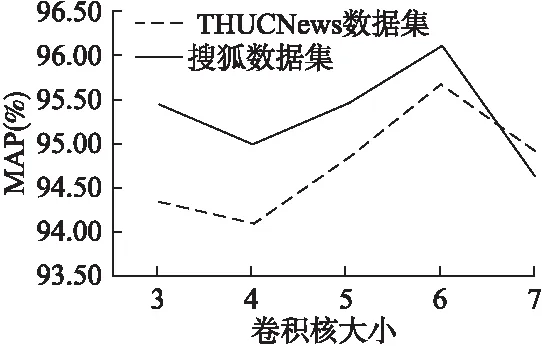
圖7 CGGA模型不同卷積核大小對比Fig.7 CGGA model is compared with different convolution kernel sizes
5 結 論
本文提出了一種基于卷積神經網絡的并行門控混合文本分類模型,即CGGA模型.在字符級卷積網絡的基礎上引入了雙向門控單元(BiGRU)和門控Tanh-ReLU單元,學習數據間的依賴關系,有效的彌補了卷積神經網絡忽略局部與整體之間的關聯性的缺陷,提高卷積網絡的性能;并引入多頭注意力機制(Multi-Head Attention)來關注不同子空間的重要信息,以提高模型文本分類的準確率.CGGA模型在THUCNews數據集和搜狐數據集(SogouCS)上分別進行訓練和測試,其實驗結果證明,中文文本分類任務中,在卷積神經網絡中使用并行的門控機制和注意力機制有利于文本分類任務的研究.由于本文中模型使用的卷積神經網絡較簡單,在接下來的學習與研究中,來探索如何使用深層的卷積神經網絡來進一步提高分類準確率.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
