一種半監督學習的代碼自動生成性能評估方法
2021-03-22 01:39:08張曉江
小型微型計算機系統 2021年3期
關鍵詞:特征
張曉江,姜 瑛
(昆明理工大學 云南計算機技術應用重點實驗室, 昆明 650500) (昆明理工大學 信息工程與自動化學院, 昆明 650500)
1 引 言
如何有效地提高軟件開發的效率和質量,是軟件工程領域關心的核心問題.一直以來,許多研究者都通過改善軟件開發方法和運用技術手段來提高軟件開發的自動化水平.其中,代碼自動生成技術指利用某些技術自動地生成軟件源代碼,達到根據程序員的需求自動編程的目的.代碼自動生成技術被認為是提高軟件開發自動化程度和質量的重要方法,受到學術界和工業界的廣泛關注.
以 GitHub 和 Stack Overflow 為代表的開源網站和開源社區的發展,給研究人員提供了大量高質量的源代碼.這些代碼中隱含著許多知識,將這些知識用于軟件開發中,使得大規模代碼的學習成為可能.通過使計算機理解源代碼中的語義信息和結構信息,并借助計算能力的增長和深度神經網絡,代碼補全、基于功能描述的代碼自動生成、基于輸入輸出的代碼自動生成等成為當前的研究熱點[1].
目前,代碼自動生成技術的部分研究已應用到實際開發中,依據某種代碼生成方法實現的代碼自動生成工具通常以插件的形式嵌入到集成開發環境中.例如,IntelliJ IDEA、Eclipse、PyCharm等集成開發環境都支持嵌入的代碼自動生成插件,以幫助程序員提高開發效率.在應用代碼自動生成工具編程的過程中,需要程序員和代碼自動生成工具相互配合來完成編碼工作.代碼自動生成工具根據程序員的輸入及當前代碼語義環境生成代碼,生成的代碼出現在IDE(Integrated Development Environment)的代碼推薦框中,程序員根據需要在代碼推薦框中進行代碼選擇.此外,程序員也可能對選擇的生成代碼進行修改、刪除等操作.
代碼自動生成技術的目的是為了提高軟件的開發效率.而在代碼自動生成過程中,程序員的開發效率很大程度上是由代碼自動生成的性能來決定的.代碼自動生成的性能指代碼自動生成過程中所占用的時間空間以及代碼自動生成的規模和效率.通過對代碼自動生成的性能評估,可以對比不同模型生成代碼的質量,分析影響生成代碼性能的因素.目前代碼自動生成的相關研究越來越多,但是很多研究者只是針對代碼生成模型進行不斷改進,忽略了代碼自動生成過程中由程序員和代碼自動生成工具相互作用而產生的性能問題.實際上,代碼自動生成的性能取決于代碼自動生成工具以及程序員的行為.
本文通過分析程序員行為與代碼自動生成工具行為的交互特征,結合半監督學習方法與深度神經網絡提出了一種代碼自動生成性能評估方法,并且分析了代碼自動生成過程中性能類別與程序員行為以及代碼自動生成工具行為之間的關系.
2 相關工作
在現有研究中,用來評估代碼自動生成性能的指標主要包括Precision(精確率)、Recall(召回率)、MRR(Mean Reciprocal Rank)、F-Measure[2].如果代碼自動生成工具推薦的是排序后的K個結果,可以使用Top-K的Precision、Recall、MRR、F-Measure對代碼自動生成性能進行評估.
1)Precision:又稱查準率,指代碼自動生成工具正確推薦的代碼數目占代碼自動生成工具推薦代碼總數的比例,計算如公式(1)所示:
(1)
式(1)中,Actual_code(i)代表第i次程序員真實需要的推薦代碼,Recom_code(i)代表第i次代碼自動生成工具推薦的代碼.
2)Recall:又稱查全率,定義為代碼自動生成工具正確推薦代碼數目與程序員真實需要的推薦代碼總數之間的比例.
(2)
式(2)中的各變量含義同式(1).
3)MRR:體現代碼自動生成工具推薦代碼結果的優劣情況,靠前的結果較優,評分越高.第1個推薦代碼成功推薦,則分數為1;第2個推薦代碼成功推薦則分數為0.5;第n個推薦成功分數為1/n;若沒有推薦成功分數為0.計算如公式(3)所示:
(3)
式(3)中,K為代碼自動生成次數,rank(i)為第i次正確推薦代碼所在推薦列表中的位置.
4)F-Measure:是Precision和Recall的加權調和平均.
(4)
在代碼自動生成性能評估中,通常將Precision和Recall視為同等重要,所以將式(4)中的β設為1,就是最常見的F1-Measure.
在基于機器學習的代碼自動生成的研究過程中,Hindle A等人[3]將傳統的N-Gram模型應用到代碼自動生成的研究中,使用語言模型N-Gram進行代碼預測,實驗通過MRR評估代碼自動生成的性能,MRR評估指標為51.88%.Hellendoorn VJ等人[4]在語言模型的基礎上加入“緩存”機制來維護程序的局部信息,通過對比循環神經網絡與帶有“緩存”機制的N-Gram,發現代碼的局部性特征對于token的預測有極大的幫助,使用循環神經網絡進行代碼預測時MRR評估指標為67.5%,而帶有“緩存”機制的N-Gram模型MRR評估指標為69.3%.
Nguyen TT等人[5]引入了一種統計語言模型SLAMC(A Novel Statistical Semantic Language Model For Source Code),在語言模型的基礎上加入“緩存”機制來維護程序的局部信息.實驗結果表明,加入“緩存”機制的模型捕獲了源代碼中的局部規律,實驗使用Top-K的Precision對模型生成代碼準確性進行評估,Precision在Top-1中達到64.00%、Top-5達到78.20%.Raychev V等人[6]使用N-gram模型與循環神經網絡結合,在JavaAPI調用級別進行代碼補全,利用N-Gram模型對程序中的API 調用序列建模,從而對API的調用序列進行預測.該研究通過分析Top-K個推薦代碼的Precision來評估模型的效果.Tu Z等人[7]同樣針對N-Gram模型忽略的程序局部特征,在語言模型中加入了緩存機制,其附加的緩存組件通過捕獲軟件的局部性,從而改進了N-Gram方法,其中MRR評估指標為54.44%,Top-1中Precision為52.04%,Top-5中Precision為57.45%.Raychev V 等人[8]基于循環神經網絡,將程序代碼的抽象語法樹的序列化結果作為訓練數據集,并將網絡輸出結果區分為終結符的預測和非終結符的預測,該方法在一定程度上運用了存在于抽象語法樹中的結構化信息,進一步提升了與生成代碼相關的非終結符預測的準確性,該研究使用Top-K個推薦代碼的Precision來對模型生成代碼性能進行評估.
Allamanis M等人[9]提出了專門為方法命名問題設計的神經概率語言模型的源代碼,該模型通過在一個高維連續空間中將名稱分配到稱為嵌入的位置,以一種具有相似嵌入的名稱傾向于在相似的上下文中使用的方式來了解哪些名稱在語義上是相似的,并通過F1-Measure評估模型的性能.之后,Allamanis M等人[10]基于圖網絡學習代碼中的結構以及語義特征,利用圖模型中的不同邊表示代碼token之間的結構和語法關系,實驗中F1-Measure評估指標為44.0%.
在當前代碼自動生成的相關研究中,缺乏針對代碼自動生成性能的統一評估方法.部分研究用Precision、Recall、MRR、F-Measure作為評估代碼自動生成性能的指標,但這些指標僅基于代碼自動生成個數以及生成代碼的正確性來進行計算.在實際開發中,代碼自動生成的效果不僅僅由代碼自動生成工具決定,程序員的行為在其中也起到了較大的作用.現有評估方法忽略了程序員行為在代碼自動生成過程中的重要性,只是針對代碼自動生成結果進行了評估.此外,由于大部分研究采用不同的評估指標,且各指標之間無法直接轉化,難以對各種代碼自動生成模型和方法進行對比.因此,針對代碼自動生成過程進行性能評估是亟待解決的問題.
本文綜合程序員以及代碼自動生成工具在代碼自動生成過程中的作用,提出了一種基于半監督學習的代碼自動生成性能評估方法.通過采集程序員行為與代碼自動生成工具行為的相關數據來抽取代碼自動生成過程中影響性能的特征,利用半監督學習對代碼自動生成過程中的相關特征數據進行聚類分析從而確定性能類別;根據與性能相關的特征數據以及對應的性能類別來訓練代碼自動生成性能評估模型,從而分析代碼自動生成性能、程序員行為與代碼自動生成工具行為在代碼自動生成過程中對性能的影響程度.
3 針對程序員行為與代碼自動生成工具行為相關數據的重要特征提取
代碼自動生成的性能包括程序員編程的性能和代碼自動生成工具的性能,因此影響代碼自動生成過程性能的數據主要包括程序員行為數據和代碼自動生成工具行為數據.
3.1 與性能相關的基本特征
在代碼自動生成過程中,有時代碼自動生成工具生成了符合邏輯的代碼,但并不符合程序員的預期,那么這段代碼在實際使用中也是性能較差的.因此,與性能相關的基本特征由程序員行為和代碼自動生成工具行為共同決定.若能抽取所有與性能相關的特征,則可以分析出代碼自動生成過程中的所有性能問題.但是,考慮到性能數據收集過程中產生的程序擾動以及軟硬件開銷,本文主要關注與性能相關的基本特征.
代碼自動生成工具會根據程序員的輸入代碼自動生成代碼,而程序員的輸入代碼決定著代碼自動生成工具生成代碼的內容.程序員輸入代碼的長短可能會導致生成不同的代碼,而程序員錯誤的輸入甚至會導致代碼自動生成工具生成不相關的代碼.所以程序員的輸入在很大程度上影響著代碼自動生成工具的性能.
代碼自動生成工具為程序員更高效的完成編碼工作提供了輔助,程序員選中的生成代碼代表著實際開發中需要的代碼,同時也反映了代碼自動生成工具生成代碼的正確性.此外,程序員選擇生成代碼過程中的按鍵次數可以反映出程序員需要的代碼在代碼推薦列表中的位置以及代碼自動生成工具生成代碼的準確率.程序員在選擇生成代碼之后發生的刪除或糾正代碼行為表示程序員雖然選擇了生成代碼,但生成代碼需要經過修改才能達到程序員的期望.
程序員當前已經編寫好的代碼可視為代碼上下文,代碼自動生成工具會根據代碼上下文進行代碼自動生成.因此,代碼上下文的復雜度以及代碼上下文的語義環境決定了代碼自動生成的內容,清晰的代碼上下文結構更有助于生成高質量的代碼.在代碼自動生成工具每次向程序員推薦的代碼中,程序員是否選擇生成代碼決定了生成代碼是否成功推薦.現有工具在提供代碼生成功能時,通常將生成的代碼添加到IDE的代碼推薦框中,然后程序員根據自己的實際需要選擇相應的生成代碼.因此,自動生成的代碼在代碼推薦列表中的位置及生成時間尤為重要,它將直接影響程序員的按鍵次數以及等待時間,從而進一步影響開發效率.由于編寫代碼具有很大的靈活性,因而代碼自動生成工具生成代碼的數量可以為程序員提供多種解決方案.

表1 代碼自動生成性能基本特征Table 1 Basic characteristics of automatic code generation performance
綜上所述,本文定義了程序員行為、代碼自動生成工具行為與代碼自動生成性能相關的基本特征,如表1所示.
3.2 與性能相關的復雜特征分析及處理
除了3.1中提出的與性能相關的基本特征,由于代碼中存在大量程序員自定義的修飾符,導致代碼自動生成工具推薦的代碼在語義上符合程序員的需要,但是實際代碼并不一定完全與程序員需要的代碼相同.所以,程序員的刪除行為或生成代碼是否被程序員選擇等信息并不能完全衡量代碼自動生成過程的性能.因此,將程序員選擇代碼與生成代碼之間的語義相似度作為一個與性能相關的重要特征.
為了得到選擇代碼與生成代碼之間的語義相似度,本文用Word2Vec[11]對代碼token進行向量化表示.Word2Vec在一個連續空間中為每個詞語產生一個對應的分布式向量,可計算詞語之間的相似度.本文應用Word2Vec的這一特性來評估代碼自動生成工具生成的代碼與程序員所需代碼之間的相似性.Word2Vec主要包括CBOW(Continuous Bag-of-Words Model)[12]和Skip-Gram[13]兩種模式,其中CBOW是從原始語句推測目標詞,Skip-Gram是從目標詞推測出原始語句,實踐表明CBOW對小型語料效果較好,而Skip-Gram在大型語料庫中表現更加出色.因此本文使用Skip-Gram模型為代碼訓練一種分布式的向量表示.
訓練詞向量之前需要大量分詞后的優質代碼語料.在構建代碼語料的過程中,由于代碼文件通常包含大量的自然語言注釋,將影響詞向量以及代碼分詞的效果.本文使用抽象語法樹(Abstract Syntax Tree,AST)對代碼進行解析并進行數據清洗,校驗代碼語料語法是否規范,并利用AST構建代碼詞典.
3.2.1 數據清洗
為了避免代碼語料中存在的自然語言注釋以及語法不規范等問題對詞向量的構建產生影響,我們使用AST對代碼語料進行解析,通過AST結構的完整性來檢查代碼語法是否規范.首先將待解析代碼初始化為code,將code通過AST解析為T,通過檢查T來判斷code語法是否規范,若不規范對code進行刪除,否則通過遍歷T中節點,刪除T中注釋節點,對T進行AST反向解析,將T輸出為Tcode,Tcode即為干凈數據.
3.2.2 建立代碼詞典/分詞
在建立代碼詞典過程中,首先初始化代碼詞典為L,將Tcode通過AST解析為T,遍歷T中所有節點,將所有葉子節點內容添加到L,通過集合對L進行去重.去重后的L即為代碼詞典,通過L使用正向最大長度匹配對Tcode進行分詞.建立代碼詞典/分詞算法如表2所示.

表2 建立代碼詞典/分詞算法Table 2 Building code dictionary/word segmentation algorithm
3.2.3 計算生成代碼相似度
使用分詞后的代碼語料通過Skip-Gram模型訓練詞向量.由于相似代碼具有相似的向量表示,本文通過計算生成代碼與程序員預期代碼之間的余弦相似度得到選擇代碼與生成代碼之間的語義相似度,使用公式(5)計算生成代碼相似度.
(5)
其中A表示程序員預期代碼token,Ak表示tokenA的第k維向量;B表示代碼自動生成工具生成代碼token,Bi為生成的第i個代碼,Bik表示tokenBi的第k維向量.通過計算B中生成代碼Bi與程序員期望代碼A的相似度,可以得到選擇代碼與生成代碼之間的語義相似度,即生成代碼相似度.
4 確定性能類別
抽取性能特征有助于確定性能類別.基于3.1中的代碼自動生成性能基本特征及3.2中生成代碼與選擇代碼的語義相似度,可以綜合考慮程序員行為和代碼自動生成工具行為后對性能類別進行劃分.如果可以對性能數據進行分類,就能進一步分析性能特征對性能的影響程度.K-means是一種常用的對數據進行無監督聚類的方法[14],但K-means算法在對性能數據進行分類時,可能將一些性能數據明顯較差的數據混合到其余類別中.
我們在觀察采集到的性能數據時,發現偶爾出現部分特征項為0的數據,而這部分數據大多分布在代碼自動生成工具推薦代碼個數、程序員選擇的生成代碼、程序員選擇生成代碼的按鍵次數、生成代碼語義相似度等特征中.這些數據明顯屬于性能較差的類別.為了避免在分類過程中將性能特征數據中的程序員行為和代碼自動生成工具行為混淆,或將某一種特征弱化,借鑒文獻[15]中基于背景知識分類的方法,本文將半監督算法與代碼自動生成過程中程序員和代碼自動生成工具間的關系相結合,定義相應的約束條件對性能數據進行分類.
4.1 約束
在K-means的背景下,實例約束可以表示哪些實例應該組合或不應該組合在一起的背景知識.因此,本文考慮兩種成對的約束關系,即正關聯約束和負關聯約束.
1)正關聯(Must-link)約束指定兩個實例必須位于同一個類別中.
2)負關聯(Cannot-link)約束指定兩個實例不可能位于同一個類別中.
針對性能體現明顯較差的數據,通過定義正關聯約束,指定該類數據在聚類過程中強制分配到低性能類別中.反之針對性能體現明顯較高的數據,則定義為負關聯約束,指定該類數據不與低性能數據劃分到同一類別中.
4.2 帶約束的K-means聚類算法
為了確定性能數據的類別,本文通過一組正負關聯約束結合K-means的聚類原則對性能數據進行半監督聚類.首先將性能數據初始化為D,定義一對正關聯約束(Con=)和負關聯約束(Con≠),根據K-means的聚類原則,首先隨機初始化類別中心C,針對D中的性能數據di在滿足約束關系的前提下將其就近分配到Cj.以di到Cj的平均距離對Cj進行更新,并對D中的性能數據di在不違反約束關系的前提下就近分配類別,直到Cj不再發生變化,通過評估聚類效果來確定最佳k值.帶約束的K-means聚類算法如表3所示.

表3 帶約束的K-means聚類算法Table 3 Constrained K-means clustering algorithm
4.3 評 估
雖然帶約束的性能聚類一定程度上可以避免錯誤的分類,但直接決定聚類效果好壞的類別個數是人為定義的.為了使聚類效果達到最佳,我們在確定性能類別數k時,根據帶約束的聚類方法分別計算不同k值時性能類別中數據D的誤差平方和,如式(6)所示.
(6)
其中,SSE代表所有樣本的聚類誤差,Ci代表第i個類別,p為Ci中的樣本點,mi為Ci的質心(Ci中所有樣本的均值).依據SSE的思想[16],可以對k值進行搜索,當SSE下降幅度變小時確定k值.通過以上過程,可以劃分性能類別個數,并對每個類別中數據的特征賦予類別實際意義,如果不能很好地解釋每個類別,就再考慮次優的劃分方法,直至找到能被賦予實際意義的性能類別.性能類別可作為評估代碼自動生成性能的一項指標.
5 基于DNN的代碼自動生成性能評估
通過第4節的方法可以得到合理的性能類別,有助于對性能特征數據進行標記.為了分析代碼自動生成過程中性能類別與程序員行為及代碼自動生成工具行為之間的關系,本文設計了一種基于深度神經網絡(Deep Neural Networks,DNN)的代碼自動生成性能評估模型.該模型根據程序員行為與代碼自動生成工具行為特征數據進行性能分類,同時針對每種性能類別分析程序員行為與代碼自動生成工具行為的影響程度,以此評估代碼自動生成的性能.基于DNN的代碼自動生成性能評估模型如圖1所示.
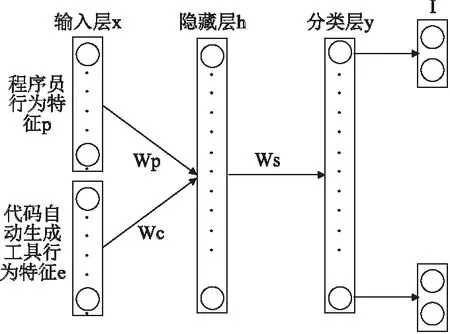
圖1 基于DNN的代碼自動生成性能評估模型Fig. 1 Performance evaluation model of automatic code generation based on DNN
從程序員行為特征輸入層p到隱藏層h的過程記為函數fp,從代碼自動生成工具行為特征輸入層c到隱藏層h的過程記為函數fc,從隱藏層h到性能分類層y的過程記為函數g,如式(7)、式(8)所示:
h=fp(xp)+fc(xc)=S(Wp+b)+S(Wc+b)
(7)
y=g(h)=S(WTh+d)
(8)
其中S一般取為sigmod函數;Wp為程序員行為特征輸入層p與隱藏層之間的權重矩陣,Wc為代碼自動生成工具行為特征輸入層c與隱藏層之間的權重矩陣;b表示隱藏層的偏置向量,d表示輸出層的偏置向量.依據式(7)、式(8)可以得到x所屬性能類別y.為方便表示,記θ=(Wp,Wc,WT,b,d).
假設程序員行為特征輸入層的樣本數據為p={p1,p2,…,pn},代碼自動生成工具行為特征輸入層的樣本數據為c={c1,c2,…,cn},D為包含N個p和c的訓練集以及數據對應的性能類別標簽,則訓練基于DNN的代碼自動生成性能評估模型的過程就是利用D對參數θ的訓練過程,訓練目標是使y和性能類別標簽盡可能接近,性能數據分類準確度使用均方誤差來描述,其定義為式(9):
(9)
通過以上方法可以得到參數θ.針對未知性能類別的代碼生成特征數據x,可以將特征數據分為程序員行為數據xp以及代碼自動生成工具行為數據xc兩部分輸入模型,由于程序員與代碼自動生成工具在代碼生成過程中有著不同的重要程度,我們在圖1中的I層計算了xp與xc對分類結果y的影響程度,即Impact_P和Impact_C.計算方法如式(10)、式(11)所示:
Impact_P=(WTfp(xp)+b)/y
(10)
Impact_C=(WTfc(xc)+d)/y
(11)
其中Impact_P為程序員行為特征p對性能類別y的影響程度,Impact_C為代碼自動生成工具行為特征c對性能類別y的影響程度.
通過基于DNN的代碼自動生成性能評估模型,可以針對代碼自動生成過程中產生的程序員行為數據以及代碼自動生成工具行為數據對代碼生成性能進行分類,同時分析程序員和代碼自動生成工在性能類別中的影響程度.
6 實 驗
本文在前期研究中實現了原型工具API4ACGT[17],并利用IntelliJ IDEA的開源插件機制將API4ACGT無縫集成到IntelliJ IDEA中.API4ACGT可以在程序員使用代碼自動生成工具進行編碼時動態記錄程序員的行為信息以及代碼生成工具行為信息.
6.1 性能數據及復雜特征提取
我們將API4ACGT(1)https://github.com/xiaojiangzhang安裝到多個程序員的IDE中,同時安裝了代碼生成工具IDEA和AiXCoder.對不同時刻、熟練程度不同的程序員在代碼自動生成工具輔助下的編程過程的性能數據進行了采集,數據規模為15000條.部分數據如表4所示.
通過API4ACGT得到性能數據后,首先需對數據進行特征提取,并計算代碼自動生成工具生成的代碼與程序員需要代碼之間的語義相似度.應用3.2中的方法,我們在GitHub開源社區中爬取了40余萬個Start大于20的Java代碼文件(約11GB),并建立了Java代碼語料庫,代碼詞庫中的token為77272個.

表5 詞向量聚類結果Table 5 Word2Vec clustering results
利用代碼詞庫對Java代碼進行分詞后,使用Skip-Gram模型訓練代碼詞向量,并在Python3.7環境中使用Gensim提供的Word2Vec模塊對分詞后的代碼語料進行詞向量的訓練.正如前文所述,AST中的相似節點應該具有相似的表示,為了評估訓練的詞向量是否達到這個標準,通過K-Means聚類來評估我們訓練的詞向量.實驗中我們將聚類個數設置為48,截取了3個類別中的部分token,結果如表5所示.在類別1中幾乎所有符號都與String類型相關,類別2中大多數符號都與循環控制有關,類別3中主要是List的子類或相關方法.這個結果證實了我們的訓練是有效的,相似的符號具有相似的向量表示.
根據式(5),對代碼自動生成工具所生成的推薦代碼與程序員選擇的生成代碼進行了語義相似度的計算,并將其合并為生成代碼語義相似度指標.同時對表4中部分原始數據進行了數值化,代碼自動生成工具推薦代碼索引按照式(12)進行計算.
(12)
其中n為代碼索引位置.生成代碼位置越靠后,s值就越小。與代碼自動生成過程相關的所有性能特征數值化后如表6所示.

表6 性能特征數值Table 6 Performance feature value
表6中有少量數據存在空值,主要集中在代碼自動生成工具生成推薦代碼個數、代碼自動生成工具是否成功推薦代碼、代碼自動生成工具推薦代碼索引、生成代碼語義相似度等特征中.通過分析,出現這種情況的原因主要是由于代碼自動生成工具未能為程序員生成代碼,所以在程序員選擇代碼行為或代碼自動生成工具相關行為的數據上為空值,可以通過人工判定這種情況屬于性能較差的體現.
6.2 性能分類
在應用第4節中的方法標注性能類別時,可以基于人工判定的結果定義相關約束.如果代碼自動生成工具推薦代碼個數、代碼自動生成工具是否成功推薦代碼、代碼自動生成工具推薦代碼索引、生成代碼語義相似度的特征值為空或0,則將這類數據強制連接到性能較差的數據類別中;不滿足該約束時,該類數據不允許連接到性能較差的類別中.基于這種約束,我們對數據集進行了聚類,通過計算不同k值與SSE值確定最優的性能類別個數,結果如圖2所示.
在性能類別數等于3時SSE下降幅度為1413.9,性能類別數等于4時SSE下降幅度為642.47,下降幅度明顯變緩慢.可見,將性能數據劃分為高、中、低3個類別是合理的.因此,本文設定類別數為3.通過對數據集進行聚類及標注,聚類結果如圖3所示.

圖2 SSE 計算結果Fig.2 SSE statistics
在圖3中,負值表示數據相對較小.如圖3所示,在性能較低的類別中,代碼上下文復雜度較高,而代碼自動生成工具生成代碼時間較長,成功推薦代碼次數較少,同時生成代碼與程序員期望代碼之間的代碼語義相似度較低.程序員行為中刪除行為較突出,說明生成代碼并不符合程序員的期望.此外,在代碼復雜度較高的情況下,代碼自動生成工具生成代碼數量較少,時間較長,在代碼自動生成過程中性能表現較低.

圖3 聚類結果Fig.3 Clustering results
6.3 代碼自動生成性能評估
應用第5節的性能評估模型,本文在分類后的數據中隨機抽取13000條作為訓練集,2000條作為測試集,使用隱藏層數為3、隱層節點數為20的網絡參數對模型進行訓練.在訓練階段為了防止深度學習中常見的擬合性問題,本文在模型訓練過程中加入了Dropout正則化處理,最終模型針對測試集性能分類準確率達到98.17%.
為了評估程序員行為與代碼自動生成工具行為在代碼自動生成過程中各自的影響程度,選擇了一批經過復雜特征提取后的數據進行分類,并計算了程序員行為特征與代碼自動生成工具行為特征在不同性能類別中的影響程度,用一個三元組
表7中Class為性能類別.可以看出,低性能類別中Impact_P指標明顯高于Impact_C.從序號為3、9、10、11、14、16的數據中可以看出,代碼自動生成工具推薦代碼個數接近0,代碼自動生成工具是否成功推薦代碼為0,生成代碼語義相似度幾乎為0,Impact_P均值為0.8352,而Impact_C均值為0.1648,可以看出程序員行為對低性能類別影響程度較高.低性能數據的各項特征可以反映出代碼生成工具沒有為程序員生成符合期望的代碼.在中性能數據中,Impact_P與Impact_C較為接近,程序員行為數據與代碼自動生成工具行為數據分布比較均勻.例如序號為1、5、7、12、15的中性能數據,Impact_P與Impact_C均值為0.4849和0.5151.在高性能數據中,Impact_C指標比較突出,Impact_C幾乎接近1.此時,代碼自動生成工具生成代碼的語義相似度最高達到0.8542,生成代碼數量也達到最高,同時程序員按鍵次數依舊保持在1左右,即代碼自動生成工具為程序員生成了優質的代碼,從而提高了程序員的開發效率.

表7 程序員行為特征與代碼自動生成工具行為特征在不同性能類別中的影響程度實驗數據Table 7 Experimental data on the influence of behavior characteristics of programmers and automatic code generation tools on different performance categories
上述實驗表明,本文的方法可以有效分析代碼自動生成過程的性能,并判斷程序員行為與代碼自動生成工具行為對代碼自動生成過程性能的影響程度.
6.4 評估結果分析
為了進一步驗證本文所提出的方法,代碼自動生成過程中采集的性能數據使用Precision、Recall、MRR、F1-Measure及本文評估方法中的
從表8中可以看出,不同評估指標顯示表7中16條代碼自動生成記錄的性能評估結果為中等.與Precision、Recall相比,F1-Measure、MRR、
在代碼自動生成過程中,涉及較多可能影響代碼自動生成性能的因素.例如,程序員輸入代碼會直接影響代碼自動生成工具推薦代碼內容;程序員選擇生成代碼之后,可能出現刪除代碼的行為等.從公式(1)、(2)、(4)可知,Precision、Recall以及F1-Measure只計算了代碼自動生成工具推薦代碼個數以及正確推薦代碼次數,MRR計算了代碼自動生成工具正確推薦代碼排序結果.本文提出的方法綜合考慮了影響代碼自動生成性能問題的相關因素,從程序員行為以及代碼自動生成工具行為兩個方面進行評估.通過選擇深度神經網絡作為性能評估的基礎模型,在代碼自動生成性能評估過程中,不僅對性能數據類別進行計算,而且使用深度神經網絡中不同神經元之間的權重參數來估計程序員與代碼自動生成工具行為數據對性能評估的影響程度,同時也可以利用兩種行為對性能的影響程度分析性能問題的瓶頸.

表8 代碼自動生成性能評估結果Table 8 Results of code automatic generation based on different performance metrics
7 結束語
本文針對代碼自動生成提出了一種性能評估方法,綜合考慮了程序員與代碼自動生成工具的作用,通過抽取程序員行為與代碼自動生成工具行為特征,使用帶約束的半監督聚類方法對性能數據進行分類;根據程序員行為特征數據以及代碼自動生成數據建立了一種基于DNN的性能評估模型,評估了程序員和代碼自動生成工具對代碼自動生成性能的影響程度.實驗表明,代碼自動生成性能表現較高時,代碼自動生成工具行為特征權重較大,幾乎直接決定了性能類別,同時也說明高性能的代碼自動生成在較大程度上簡化了程序員的開發行為;而在低性能類別中,程序員的行為特征權重較大,說明低性能的代碼自動生成會導致程序員的開發行為在編程中占據較大比重;在中性能類別中,程序員行為特征與代碼自動生成工具行為特征的權重較為平衡.
本文所提出的代碼自動生成性能評估方法通過分析程序員行為與代碼自動生成工具行為的交互特征,可以有效的對生成代碼性能進行評估,并可應用于實際軟件項目中.但是,目前僅針對程序員行為與代碼自動生成工具行為對性能分類影響程度進行了研究,下一步將針對程序員與代碼自動生成工具行為中的不同特征對于性能影響程度進行研究,為提高代碼自動生成性能提供更多參考.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
