基于雙排序原理的先進(jìn)先出數(shù)據(jù)核銷高速通用算法
2021-03-24 09:56:14王國(guó)忠
軟件工程 2021年3期
摘? 要:本文按照軟件中臺(tái)的思想,設(shè)計(jì)了一個(gè)針對(duì)先進(jìn)先出(First-In First-Out, FIFO)[1]數(shù)據(jù)核銷的通用實(shí)現(xiàn)框架及其對(duì)應(yīng)的入庫(kù)數(shù)據(jù)模型、消費(fèi)數(shù)據(jù)模型和匹配核銷模型。同時(shí),設(shè)計(jì)了基于雙排序原理的先進(jìn)先出數(shù)據(jù)核銷高速實(shí)現(xiàn)方法。該方法按照匹配規(guī)則先對(duì)數(shù)據(jù)進(jìn)行排序,然后對(duì)兩個(gè)有序隊(duì)列進(jìn)行單循環(huán)匹配查找,避免了傳統(tǒng)先進(jìn)先出實(shí)現(xiàn)中的雙循環(huán)操作,可以大幅度提高運(yùn)算性能,大幅度節(jié)省CPU開銷和存儲(chǔ)開銷,實(shí)現(xiàn)超大數(shù)據(jù)量的快速匹配,可以支持兩個(gè)億級(jí)數(shù)據(jù)庫(kù)的快速先進(jìn)先出匹配。
關(guān)鍵詞:先進(jìn)先出;存儲(chǔ)過程;雙排序;面向?qū)ο?/p>
中圖分類號(hào):TP31? ? ?文獻(xiàn)標(biāo)識(shí)碼:A
Abstract: This paper proposed to design a general implementation framework for FIFO (First-In First-Out) data verification and its corresponding inbound data model, consumption data model and matching verification model based on idea of middle platform. At the same time, a high-speed realization method of FIFO data verification is designed based on the double sorting principle. This method first sorts data according to matching rules, and then performs a single-loop matching search on the two ordered queues, avoiding double-loop operation in traditional FIFO implementation. The proposed method significantly improves computing performance, and greatly saves CPU and storage overheads. As a result, it is capable of processing super large data volume, and can support fast FIFO matching of two databases with large data volume.
Keywords: First-In First-Out (FIFO); storage procedure; double sort; object-oriented
1? ?引言(Introduction)
先進(jìn)先出是傳統(tǒng)庫(kù)存商品成本核算的一個(gè)通用方法,商品銷售先選擇最早采購(gòu)的商品價(jià)格作為銷售商品的庫(kù)存成本。目前,國(guó)內(nèi)很多企業(yè)對(duì)于各類消費(fèi)數(shù)據(jù)都需要用先進(jìn)先出的方法進(jìn)行核算。隨著互聯(lián)網(wǎng)新零售大幅度崛起,消費(fèi)數(shù)據(jù)從傳統(tǒng)的商品批發(fā)零售擴(kuò)大到很多場(chǎng)景,例如CRM[2](Customer Relationship Management)的積分核銷[3]就是十分典型的一個(gè)應(yīng)用,不同商家的積分產(chǎn)生和使用,需要相互結(jié)算。隨著全渠道零售的興起,各個(gè)結(jié)算主體之間也存在先進(jìn)先出的結(jié)算需求。從軟件實(shí)現(xiàn)上來看,數(shù)據(jù)庫(kù)先進(jìn)先出核銷需要解決模塊化和運(yùn)算高效的技術(shù)難點(diǎn)。先進(jìn)先出算法的缺陷會(huì)使系統(tǒng)運(yùn)行性能變差,甚至導(dǎo)致系統(tǒng)癱瘓。
為了節(jié)省服務(wù)器的計(jì)算時(shí)間,需要設(shè)計(jì)一個(gè)通用的高速核銷引擎,方便應(yīng)用程序直接調(diào)用,大幅度降低普通程序員對(duì)出入數(shù)據(jù)核銷實(shí)現(xiàn)的門檻。目前數(shù)據(jù)基本上都存儲(chǔ)在數(shù)據(jù)庫(kù)中,而程序開發(fā)工具大部分是Java或C語言等,通過JDBC/ODBC和數(shù)據(jù)庫(kù)連接讀取和寫入數(shù)據(jù)。由于數(shù)據(jù)庫(kù)和開發(fā)工具都具備運(yùn)算能力,因此先進(jìn)先出引擎可以利用開發(fā)工具能力,也可以利用數(shù)據(jù)庫(kù)能力,以及兩者混合能力來實(shí)現(xiàn)。
本文按照軟件中臺(tái)的思想,設(shè)計(jì)了一個(gè)針對(duì)先進(jìn)先出數(shù)據(jù)核銷的通用實(shí)現(xiàn)框架及其對(duì)應(yīng)的入庫(kù)數(shù)據(jù)模型、消費(fèi)數(shù)據(jù)模型和匹配核銷模型。同時(shí),為了克服傳統(tǒng)先進(jìn)先出數(shù)據(jù)核銷中的雙循環(huán)操作瓶頸,設(shè)計(jì)了基于雙排序原理的先進(jìn)先出數(shù)據(jù)核銷高速實(shí)現(xiàn)方法,通過先排序后先進(jìn)先出,把先進(jìn)先出算法從乘法變成加法,實(shí)現(xiàn)超高速的計(jì)算引擎[4],可以滿足超大數(shù)據(jù)的先進(jìn)先出需求。
2? ?先進(jìn)先出通用模型設(shè)計(jì)(Design of FIFO general model)
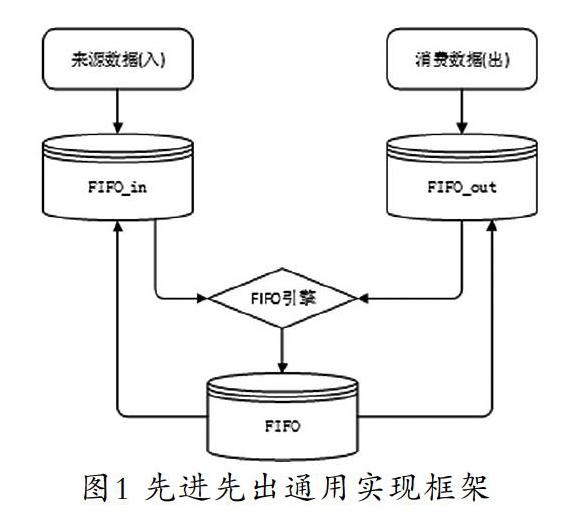
為了實(shí)現(xiàn)通用的先進(jìn)先出引擎,本文設(shè)計(jì)了一個(gè)先進(jìn)先出通用實(shí)現(xiàn)框架[5]。如圖1所示,該框架包含來源數(shù)據(jù)模型FIFO_in、消費(fèi)數(shù)據(jù)模型FIFO_out和匹配核銷模型FIFO三個(gè)模塊。任何需要使用先進(jìn)先出算法的系統(tǒng),只要將數(shù)據(jù)按照要求存入兩個(gè)出入表,然后調(diào)用先進(jìn)先出引擎運(yùn)行,即可得到結(jié)果。
入庫(kù)數(shù)據(jù)模型FIFO_in,存儲(chǔ)來源數(shù)據(jù)。例如對(duì)于商品,就是采購(gòu)入庫(kù)數(shù)據(jù);對(duì)于顧客積分,就是顧客消費(fèi)產(chǎn)生的積分。為了標(biāo)識(shí)來源數(shù)據(jù)唯一性,該表需要加入來源數(shù)據(jù)的唯一主鍵信息,主要字段為:先進(jìn)先出種類(用于區(qū)分應(yīng)用場(chǎng)景,例如商品出入庫(kù)、顧客積分等)、來源數(shù)據(jù)關(guān)鍵詞(一般是入庫(kù)單號(hào)+商品+日期或產(chǎn)生積分的銷售小票單號(hào)+顧客信息+日期)、來源數(shù)據(jù)的數(shù)值(數(shù)量、金額、成本、積分等)、來源數(shù)據(jù)的優(yōu)先級(jí)(解決FI的不同場(chǎng)景,例如后進(jìn)先出,只需要調(diào)整優(yōu)先級(jí)即可)、已核銷的數(shù)值(被FO匹配到的數(shù)值)、未被核銷的數(shù)值等。
消費(fèi)數(shù)據(jù)模型FIFO_out,存儲(chǔ)使用數(shù)據(jù)。對(duì)于商品,就是銷售或批發(fā)數(shù)據(jù);對(duì)于顧客積分,就是使用積分(包括積分抵現(xiàn)、退貨、積分換券等用掉的積分)。為了標(biāo)識(shí)目標(biāo)數(shù)據(jù)唯一性,該表需要加入消費(fèi)數(shù)據(jù)的唯一主鍵信息,主要字段為:先進(jìn)先出種類(商品出入庫(kù)或積分核銷等場(chǎng)景)、消費(fèi)數(shù)據(jù)關(guān)鍵詞(一般是銷售單號(hào)或積分使用單號(hào),加上產(chǎn)品或顧客信息)、消費(fèi)數(shù)據(jù)的數(shù)值(數(shù)量、金額、成本、積分等)、消費(fèi)數(shù)據(jù)的優(yōu)先級(jí)(解決哪些數(shù)據(jù)優(yōu)先處理的問題)、已匹配數(shù)據(jù)(已經(jīng)匹配到的數(shù)值)等。
匹配核銷模型FIFO,存儲(chǔ)匹配記錄,即消費(fèi)數(shù)據(jù)和來源數(shù)據(jù)核銷關(guān)系。這需要通過運(yùn)行先進(jìn)先出引擎從FIFO_out循環(huán),逐行從FIFO_in表尋找。FIFO匹配核銷模型主要信息為:先進(jìn)先出種類、出方關(guān)鍵詞、入方關(guān)鍵詞及核銷數(shù)據(jù)。
3? ?五種先進(jìn)先出算法(Five FIFO algorithms)
傳統(tǒng)數(shù)據(jù)核銷大部分是單個(gè)數(shù)據(jù)發(fā)生后,通過某些條件去尋找來源,這樣實(shí)現(xiàn)比較簡(jiǎn)單。例如,顧客使用積分抵現(xiàn),由于積分可能是其他商家產(chǎn)生的,這樣就需要針對(duì)使用積分找到提供積分的商家銷售單進(jìn)行結(jié)算。實(shí)現(xiàn)單個(gè)數(shù)據(jù)尋找算法很簡(jiǎn)單,就是找到這個(gè)顧客以前的積分記錄,把未核銷的積分按照先進(jìn)先出原則排序,逐個(gè)匹配,將匹配到的記錄存在數(shù)據(jù)庫(kù)中,并標(biāo)記已經(jīng)核銷的記錄,防止重復(fù)核銷。然而當(dāng)數(shù)據(jù)數(shù)量非常龐大時(shí),先進(jìn)先出引擎算法的效率直接決定了整個(gè)系統(tǒng)的運(yùn)算性能,一個(gè)有缺陷的先進(jìn)先出算法會(huì)使系統(tǒng)運(yùn)行性能變差甚至導(dǎo)致系統(tǒng)癱瘓。
傳統(tǒng)的先進(jìn)先出數(shù)據(jù)核銷采用雙循環(huán)機(jī)制,運(yùn)算量大,不適用于處理大規(guī)模的數(shù)據(jù)。為了解決這個(gè)問題,本文設(shè)計(jì)了基于雙排序原理的先進(jìn)先出數(shù)據(jù)核銷高速實(shí)現(xiàn)方法。該方法按照匹配規(guī)則先對(duì)數(shù)據(jù)進(jìn)行排序,然后對(duì)兩個(gè)有序隊(duì)列進(jìn)行單循環(huán)匹配查找,避免了傳統(tǒng)先進(jìn)先出實(shí)現(xiàn)中的雙循環(huán)操作,可以大幅度提高運(yùn)算性能,節(jié)省CPU開銷和存儲(chǔ)開銷,實(shí)現(xiàn)超大數(shù)據(jù)量的快速匹配,可以支持兩個(gè)億級(jí)數(shù)據(jù)庫(kù)的快速先進(jìn)先出匹配。本節(jié)從先進(jìn)先出數(shù)據(jù)核銷算法演進(jìn)的角度,對(duì)以下五種算法的原理和優(yōu)缺點(diǎn)進(jìn)行說明。
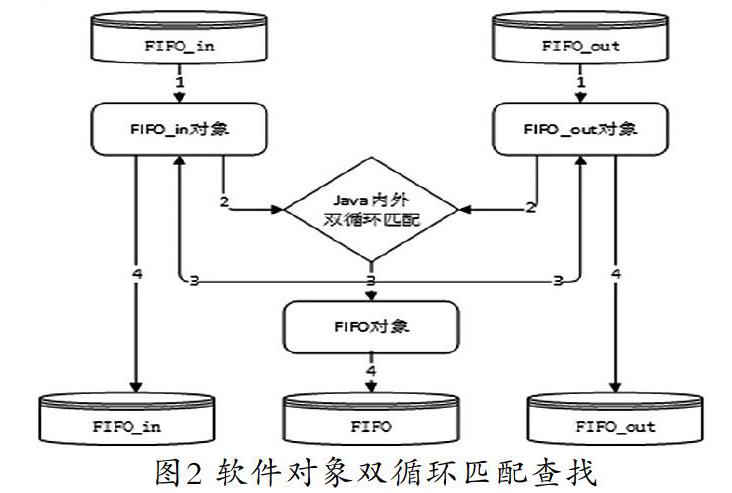
(1)軟件對(duì)象雙循環(huán)匹配查找:基于面向?qū)ο蟮能浖_發(fā)思想,先將來源數(shù)據(jù)和消費(fèi)數(shù)據(jù)分別映射成開發(fā)工具環(huán)境的兩個(gè)對(duì)象,通過應(yīng)用軟件(Java/C#)雙循環(huán)進(jìn)行匹配查找,然后把結(jié)果寫到數(shù)據(jù)庫(kù)中。
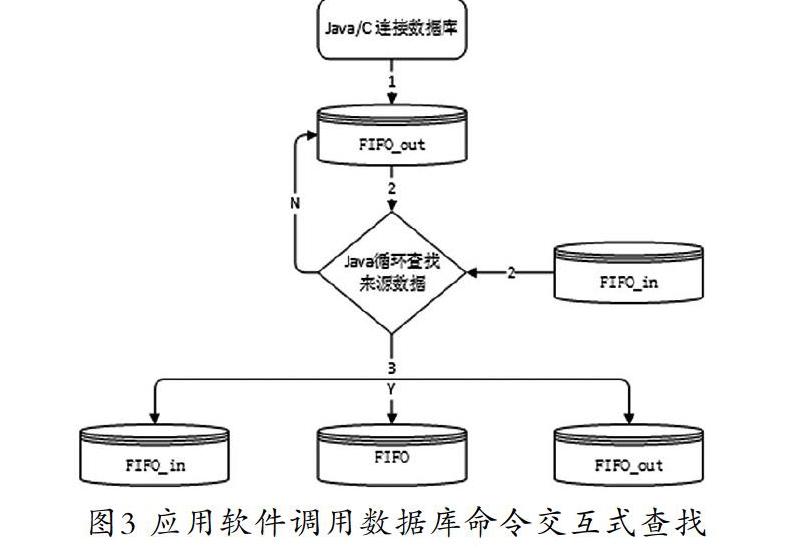
(2)軟件調(diào)用數(shù)據(jù)庫(kù)命令交互查找匹配:應(yīng)用軟件負(fù)責(zé)寫SQL查找和修改語句,交互式調(diào)用數(shù)據(jù)庫(kù)進(jìn)行查找運(yùn)算。這個(gè)方法中開發(fā)工具不存儲(chǔ)大量數(shù)據(jù),全部利用數(shù)據(jù)庫(kù)的存儲(chǔ)和SQL能力,進(jìn)行循環(huán)調(diào)用。
(3)數(shù)據(jù)庫(kù)內(nèi)部雙循環(huán)匹配查找:利用數(shù)據(jù)庫(kù)的PL/SQL[6]能力,實(shí)現(xiàn)雙循環(huán)匹配查找,不需要非數(shù)據(jù)庫(kù)的開發(fā)語言代碼。
(4)開發(fā)語言雙排序單循環(huán)匹配查找:首先通過面向?qū)ο蟮拈_發(fā)語言排序,然后進(jìn)行排序匹配查找,最后批量寫到數(shù)據(jù)庫(kù)中。
(5)數(shù)據(jù)庫(kù)排序單循環(huán)匹配查找:通過PL/SQL,利用數(shù)據(jù)庫(kù)的排序能力,直接在數(shù)據(jù)中排序快速匹配,不需要應(yīng)用開發(fā)工具反復(fù)調(diào)用數(shù)據(jù)庫(kù)計(jì)算能力。
3.1? ?方法1:軟件對(duì)象雙循環(huán)匹配查找
這是最傳統(tǒng)的面向?qū)ο蟮姆椒ǎ脩?yīng)用開發(fā)工具,例如Java、C++[7]或.net,將來源數(shù)據(jù)和消費(fèi)數(shù)據(jù)分別映射成開發(fā)工具環(huán)境的兩個(gè)對(duì)象,然后采用雙循環(huán)方法,對(duì)兩個(gè)對(duì)象進(jìn)行匹配,最后將匹配結(jié)果存在FIFO對(duì)象并刷新FIFO_in和FIFO_out對(duì)象的已匹配數(shù)量,把對(duì)象保存到數(shù)據(jù)庫(kù)的表中,如圖2所示。
上述方法利用開發(fā)工具能力雙循環(huán),總體的計(jì)算次數(shù)為:出數(shù)據(jù)記錄×進(jìn)數(shù)據(jù)記錄,所以,總體運(yùn)算量比較大,效率很低。其優(yōu)點(diǎn)是方便理解,調(diào)試運(yùn)維效率高。
3.2? ?方法2:軟件調(diào)用數(shù)據(jù)庫(kù)命令交互查找匹配
本方法也是傳統(tǒng)的算法,消費(fèi)數(shù)據(jù)和來源數(shù)據(jù)不需要映射到對(duì)象,通過逐條把數(shù)據(jù)庫(kù)消費(fèi)數(shù)據(jù)讀取到內(nèi)存,然后根據(jù)條件從來源數(shù)據(jù)匹配,匹配到的直接寫入數(shù)據(jù)庫(kù),如圖3所示。這個(gè)方法的特點(diǎn)是開發(fā)工具部署的應(yīng)用環(huán)境內(nèi)存消耗很低,存儲(chǔ)全部運(yùn)用數(shù)據(jù)庫(kù)的能力,指示命令都是應(yīng)用程序下達(dá)給數(shù)據(jù)庫(kù)的。這個(gè)方法類似傳統(tǒng)的C/S架構(gòu),客戶端發(fā)命令,數(shù)據(jù)庫(kù)運(yùn)算,并且一次命令對(duì)應(yīng)一個(gè)匹配運(yùn)算。
這個(gè)方法的優(yōu)點(diǎn)是調(diào)試方便,容易運(yùn)維;缺點(diǎn)是運(yùn)行效率很低,應(yīng)用軟件和數(shù)據(jù)庫(kù)反復(fù)交互,每次SQL運(yùn)行都需要編譯,代價(jià)比較大。這個(gè)算法一般是系統(tǒng)開發(fā)初期使用,成熟后需要升級(jí)到方法3。
3.3? ?方法3:數(shù)據(jù)庫(kù)內(nèi)部雙循環(huán)匹配查找
本方法是方法2的改進(jìn),將開發(fā)工具的循環(huán)代碼通過
PL/SQL[8]翻譯成數(shù)據(jù)庫(kù)的存儲(chǔ)過程,在數(shù)據(jù)庫(kù)內(nèi)部實(shí)現(xiàn)雙循環(huán)匹配查找,如圖4所示。這樣客戶端和數(shù)據(jù)庫(kù)只需要交互一次,具體循環(huán)全部在存儲(chǔ)過程中,大幅度減少了網(wǎng)絡(luò)交互的開銷和SQL反復(fù)編譯的代價(jià)。
該方法存儲(chǔ)過程的優(yōu)點(diǎn)是運(yùn)行效率很高,SQL代碼都是預(yù)編譯好的,大幅度節(jié)省了數(shù)據(jù)庫(kù)編譯SQL的時(shí)間,同時(shí)節(jié)省了開發(fā)語言和數(shù)據(jù)庫(kù)交互的網(wǎng)絡(luò)時(shí)延代價(jià);缺點(diǎn)是出現(xiàn)問題時(shí)調(diào)試運(yùn)維不方便,所以需要等方法2成熟后,再翻譯成存儲(chǔ)過程比較好。
3.4? ?方法4:開發(fā)語言雙排序單循環(huán)匹配查找
前面三個(gè)方法的特點(diǎn)是運(yùn)用內(nèi)外雙循環(huán)的傳統(tǒng)算法,運(yùn)算量都是消費(fèi)記錄和來源記錄的乘積,對(duì)于數(shù)據(jù)量很大的場(chǎng)景運(yùn)算非常慢。特別是匹配出現(xiàn)異常,需要重新匹配的時(shí)間很長(zhǎng),無法快速高效支撐大型企業(yè)的應(yīng)用,所以理論上只能停留在實(shí)驗(yàn)室,不能投入生產(chǎn)系統(tǒng)。
先進(jìn)先出本質(zhì)上是兩個(gè)大表的匹配,雖然不是Join,實(shí)際上可以利用排序Join的思想,將運(yùn)算量從乘法變成加法,極大提高運(yùn)算的效率,有力支撐企業(yè)先進(jìn)先出各種場(chǎng)景的應(yīng)用,包括BI(Business Intelligence)分析需要的先進(jìn)先出應(yīng)用。
方法4通過開發(fā)語言將數(shù)據(jù)進(jìn)行排序,然后基于排序后的隊(duì)列進(jìn)行匹配查找,最后將結(jié)果批量寫到數(shù)據(jù)庫(kù)。圖5首先將來源和消費(fèi)兩個(gè)大表數(shù)據(jù)映射成開發(fā)工具環(huán)境的兩個(gè)對(duì)象(類似方法1),然后分別按照匹配規(guī)則排序,變成兩個(gè)隊(duì)列。后續(xù)匹配算法變成了兩個(gè)隊(duì)列從頭開始同時(shí)向下循環(huán),把雙循環(huán)變成單循環(huán),運(yùn)算量最大就是兩個(gè)隊(duì)列記錄數(shù)的總和。
排序是本方法的主要代價(jià),需要利用已有的優(yōu)秀排序算法進(jìn)行快速排序,這樣才可以將兩個(gè)對(duì)象按照各自的排序進(jìn)行單循環(huán)匹配。匹配過程是消費(fèi)數(shù)據(jù)對(duì)象外循環(huán),來源數(shù)據(jù)(進(jìn)數(shù)據(jù))為內(nèi)循環(huán)。和雙循環(huán)的主要區(qū)別是,這兩個(gè)循環(huán)是同步進(jìn)行的,誰匹配完一個(gè)就移到下一個(gè),所以總的循環(huán)次數(shù)是兩個(gè)相加。匹配完成后,需要將匹配結(jié)果的對(duì)象寫回?cái)?shù)據(jù)庫(kù)。
3.5? ?方法5:數(shù)據(jù)庫(kù)排序單循環(huán)匹配查找
方法4的缺點(diǎn)是需要將大量的數(shù)據(jù)讀到應(yīng)用服務(wù)器的內(nèi)存,匹配完還需要將大量的匹配數(shù)據(jù)寫回?cái)?shù)據(jù)庫(kù),代價(jià)比較大。所以方法5通過PL/SQL將方法4的代碼轉(zhuǎn)換成數(shù)據(jù)庫(kù)的存儲(chǔ)過程,利用數(shù)據(jù)庫(kù)的排序能力,可以大幅度提高運(yùn)算性能,實(shí)現(xiàn)超大數(shù)據(jù)量的快速匹配,大幅度節(jié)省CPU開銷和存儲(chǔ)開銷。
圖6是數(shù)據(jù)庫(kù)排序匹配方法的流程圖,排序只需要數(shù)據(jù)庫(kù)建一個(gè)索引,每秒可以處理十萬條記錄。然后定義兩個(gè)Cursor,分別對(duì)應(yīng)消費(fèi)數(shù)據(jù)和來源數(shù)據(jù),兩個(gè)循環(huán)組成單循環(huán),第一個(gè)循環(huán)和第二個(gè)循環(huán)同時(shí)進(jìn)行匹配,整個(gè)計(jì)算量最多是兩個(gè)表的記錄數(shù)相加,所以可以支持兩個(gè)億級(jí)數(shù)據(jù)量的快速先進(jìn)先出匹配。
4? ?結(jié)論(Conclusion)
本文按照軟件中臺(tái)的思想,設(shè)計(jì)了一個(gè)針對(duì)先進(jìn)先出數(shù)據(jù)核銷的通用實(shí)現(xiàn)框架及其對(duì)應(yīng)的入庫(kù)數(shù)據(jù)模型、消費(fèi)數(shù)據(jù)模型和匹配核銷模型,并對(duì)五種先進(jìn)先出數(shù)據(jù)核銷的實(shí)現(xiàn)方法進(jìn)行了闡述。對(duì)于企業(yè)應(yīng)用,大部分采用方法5。先進(jìn)先出作為企業(yè)級(jí)應(yīng)用,模塊化價(jià)值比較高,可防止不同應(yīng)用場(chǎng)景重復(fù)開發(fā),造成額外開發(fā)量以及性能潛在的風(fēng)險(xiǎn)。不同算法對(duì)系統(tǒng)的要求不一樣,效果差異很大。普通程序員很容易使用前面運(yùn)行效率低的算法,在系統(tǒng)開始運(yùn)行幾個(gè)月后,造成系統(tǒng)癱瘓。對(duì)于有一定規(guī)模的企業(yè)應(yīng)用數(shù)據(jù),數(shù)據(jù)庫(kù)使用效率是十分重要的。先進(jìn)先出只是數(shù)據(jù)庫(kù)應(yīng)用中比較常用的一種方法,其他人工智能的算法也需要充分利用數(shù)據(jù)庫(kù)能力,合理設(shè)計(jì)算法。如果超過一個(gè)數(shù)據(jù)庫(kù)能力,就需要用多個(gè)數(shù)據(jù)庫(kù)以及大數(shù)據(jù)的方法解決。
參考文獻(xiàn)(References)
[1] 闞運(yùn)奇.營(yíng)銷零售行業(yè)先進(jìn)先出算法設(shè)計(jì)[J].無線互聯(lián)科技,2012(12):98.
[2] 李靜.基于數(shù)據(jù)挖掘技術(shù)的電子商務(wù)CRM研究[J].現(xiàn)代電子技術(shù),2015(11):126.
[3] 蔣文書.運(yùn)用數(shù)據(jù)挖掘技術(shù),精準(zhǔn)把握客戶需求[J].軟件和集成電路,2018(Z1):20.
[4] 侯寧.大數(shù)據(jù)環(huán)境下并行化先進(jìn)先出成本算法研究[J].軟件導(dǎo)刊,2019,18(06):85.
[5] 許桂平.基于數(shù)據(jù)庫(kù)的通用驅(qū)動(dòng)程序自動(dòng)編寫算法研究[J].電子設(shè)計(jì)工程,2019(15):166-169;174.
[6] CJ Fernandez Candel, J Garcia Molina, FJ Bermudez Ruiz, et al. Developing a model-driven reengineering approach for migrating PL/SQL triggers to Java: A practical experience[J].The Journal of Systems and Software,2019(151):38-64.
[7] 鐘玲玲,劉冬雪,黃小平,等.基于C語言的學(xué)生信息管理系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)[J].河南科技學(xué)院學(xué)報(bào)(自然科學(xué)版),2019(04): 62-67;78.
[8] 周嵐.Oracle中基于Java的存儲(chǔ)過程[D].合肥:安徽大學(xué),2006.
作者簡(jiǎn)介:
王國(guó)忠(1971-),男,碩士,講師.研究領(lǐng)域:大型分布式數(shù)據(jù)庫(kù)應(yīng)用,企業(yè)級(jí)應(yīng)用.

- 軟件工程的其它文章
- 軟件實(shí)訓(xùn)教學(xué)系統(tǒng)設(shè)計(jì)
- 基于神經(jīng)網(wǎng)絡(luò)的高校科研項(xiàng)目前景預(yù)測(cè)系統(tǒng)研究與設(shè)計(jì)
- 智慧公路工程中信息資源規(guī)劃
- 體育競(jìng)賽實(shí)時(shí)數(shù)據(jù)分享系統(tǒng)儲(chǔ)存方案設(shè)計(jì)與優(yōu)化
- 基于主動(dòng)探測(cè)的非關(guān)系型數(shù)據(jù)庫(kù)風(fēng)險(xiǎn)感知系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
- 基于改進(jìn)多層感知機(jī)模型的港口吞吐量預(yù)測(cè)研究