基于密度估計(jì)和VGG-Two的大豆籽粒快速計(jì)數(shù)方法
2021-03-29 02:14:04王瑩李越武婷婷孫石王敏娟
智慧農(nóng)業(yè)(中英文)
2021年4期
王瑩 李越 武婷婷 孫石 王敏娟

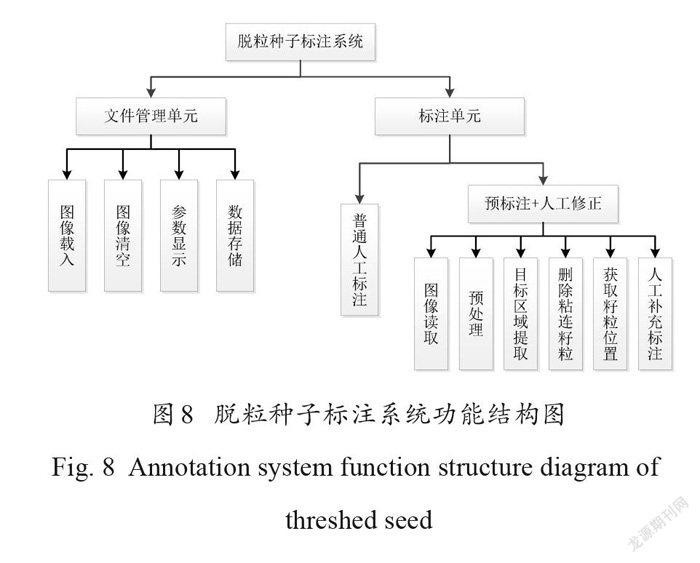

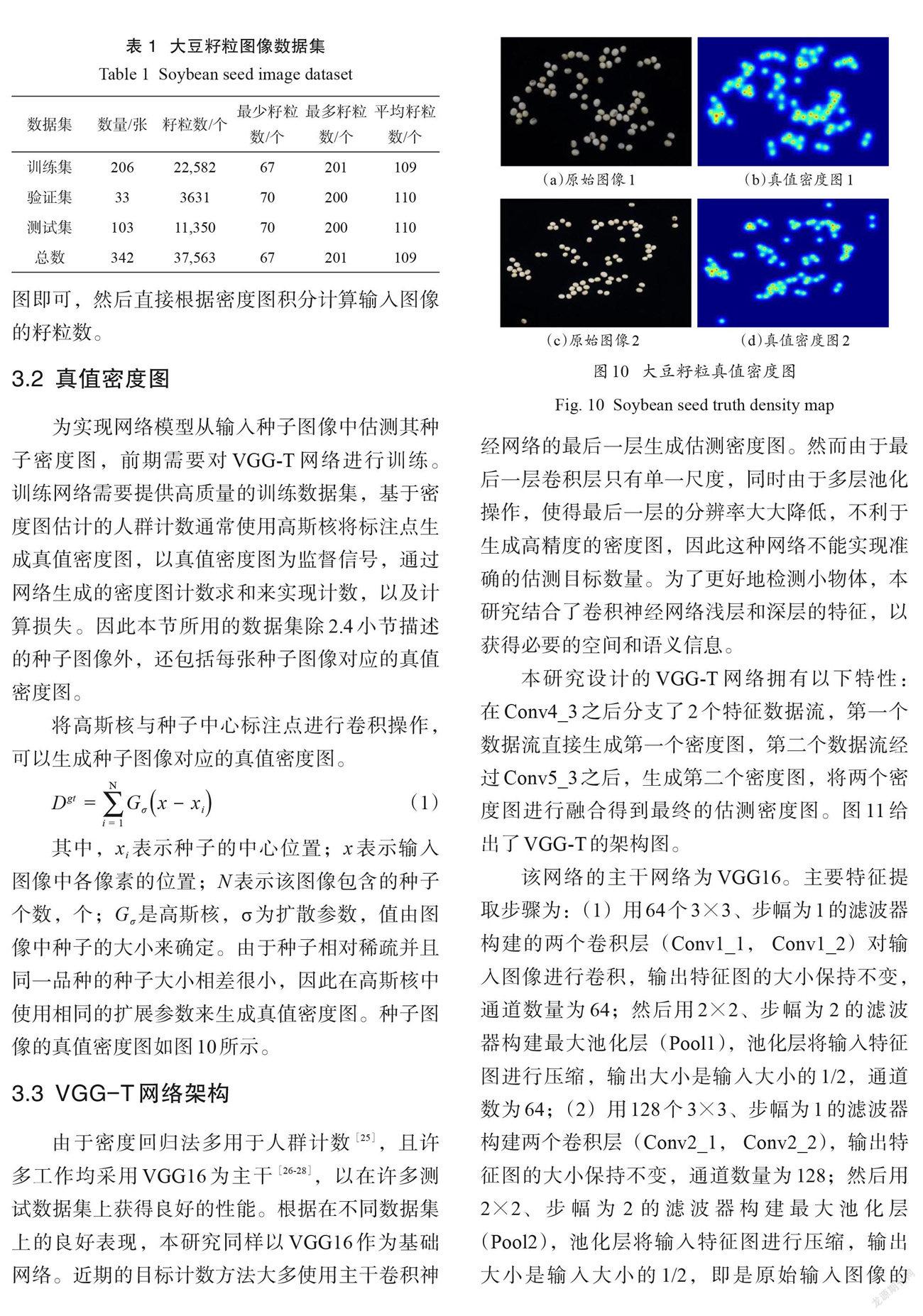


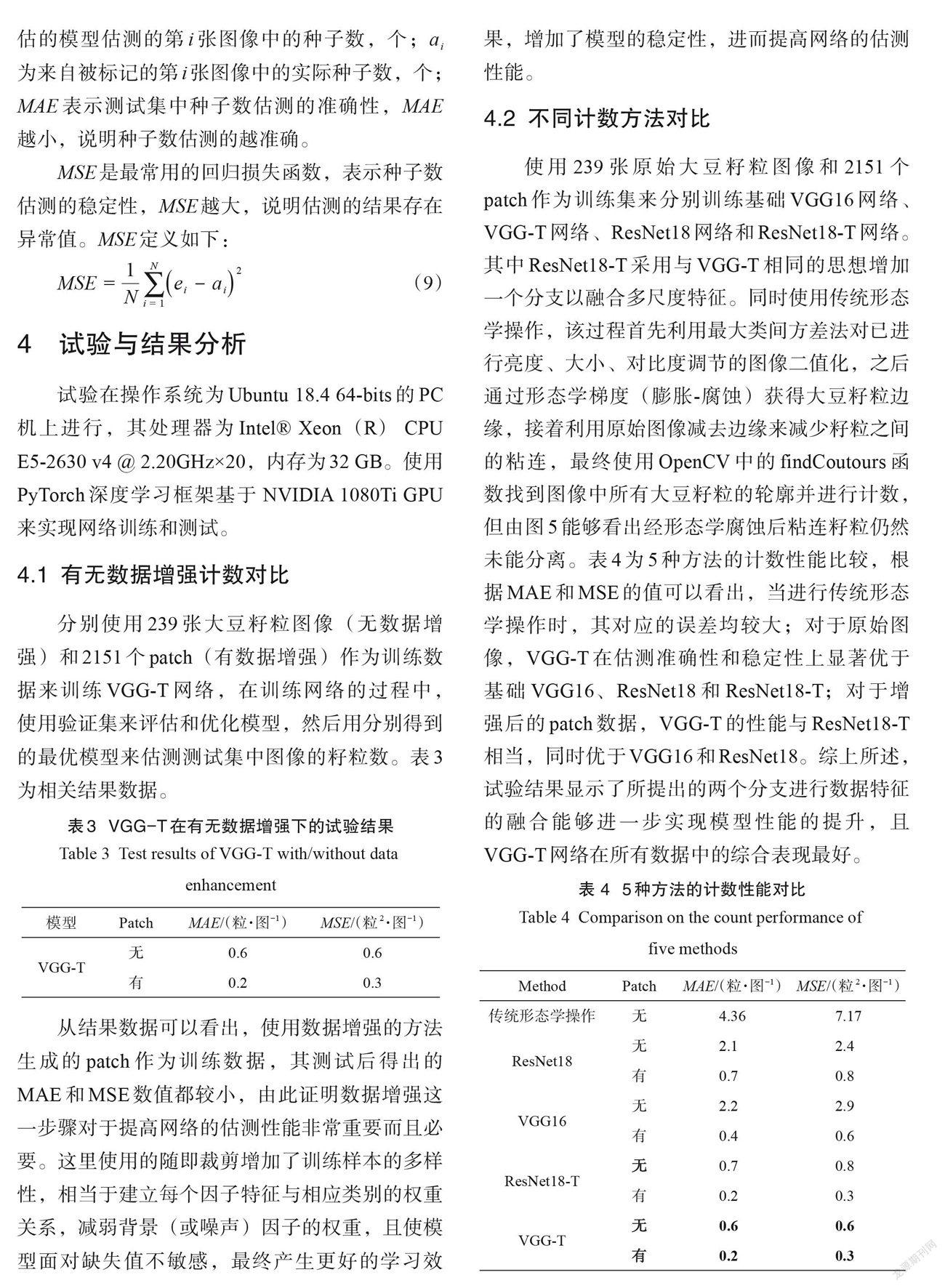

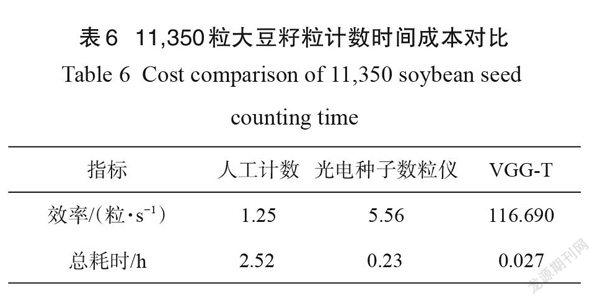

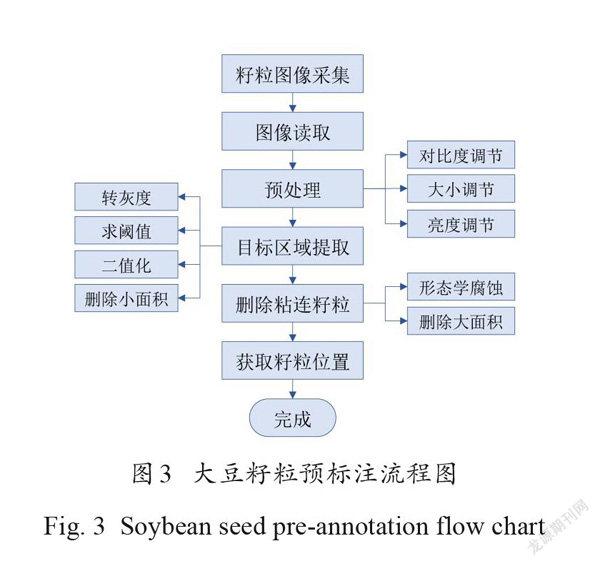
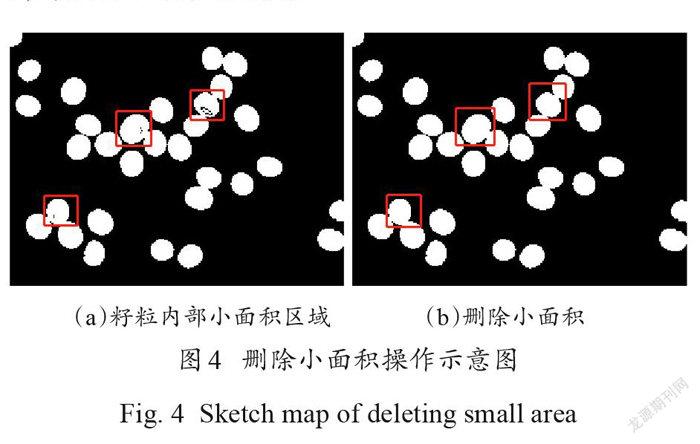

摘要:為快速準(zhǔn)確計(jì)數(shù)大豆籽粒,提高大豆考種速度和育種水平,本研究提出了一種基于密度估計(jì)和 VGG-Two (VGG-T)的大豆籽粒計(jì)數(shù)方法。首先針對大豆籽粒計(jì)數(shù)領(lǐng)域可用圖像數(shù)據(jù)集缺乏的問題,提出了基于數(shù)字圖像處理技術(shù)的預(yù)標(biāo)注和人工修正標(biāo)注相結(jié)合的快速目標(biāo)點(diǎn)標(biāo)注方法,加快建立帶標(biāo)注的公開可用大豆籽粒圖像數(shù)據(jù)集。其次構(gòu)建了適用于籽粒圖像數(shù)據(jù)集的VGG-T 網(wǎng)絡(luò)計(jì)數(shù)模型,該模型基于VGG16,結(jié)合密度估計(jì)方法,實(shí)現(xiàn)從單一視角大豆籽粒圖像中準(zhǔn)確計(jì)數(shù)籽粒。最后采用自制的大豆籽粒數(shù)據(jù)集對 VGG-T 模型進(jìn)行測試,分別對有無數(shù)據(jù)增強(qiáng)的計(jì)數(shù)準(zhǔn)確性、不同網(wǎng)絡(luò)的計(jì)數(shù)性能以及不同測試集的計(jì)數(shù)準(zhǔn)確性進(jìn)行了對比試驗(yàn)。試驗(yàn)結(jié)果表明,快速目標(biāo)點(diǎn)標(biāo)注方法標(biāo)注37,563個大豆籽粒只需花費(fèi)197 min ,比普通人工標(biāo)注節(jié)約了1592 min ,減少約96%的人工工作量,大幅降低時間成本和人工成本;采用VGG-T 模型計(jì)數(shù),其評估指標(biāo)在原圖和補(bǔ)丁(patch)情況下的平均絕對誤差分別為0.6和0.2,均方誤差為0.6和0.3,準(zhǔn)確性高于傳統(tǒng)圖像形態(tài)學(xué)操作以及ResNet18、ResNet18-T 和VGG16網(wǎng)絡(luò)。在包含不同密度大豆籽粒的測試集中,誤差波動較小,仍具有優(yōu)良的計(jì)數(shù)性能,同時與人工計(jì)數(shù)和數(shù)粒儀相比,計(jì)數(shù)11,350個大豆籽粒分別節(jié)省大約2.493h和0.203h ,實(shí)現(xiàn)大豆籽粒的快速計(jì)數(shù)任務(wù)。
關(guān)鍵詞:卷積神經(jīng)網(wǎng)絡(luò);籽粒計(jì)數(shù);籽粒圖像;點(diǎn)標(biāo)注;密度圖; VGG-Two;育種
中圖分類號: TP391.4;TP183文獻(xiàn)標(biāo)志碼: A文章編號:202101-SA002
引用格式:王瑩, 李越, 武婷婷……
登錄APP查看全文
猜你喜歡
今日農(nóng)業(yè)(2022年16期)2022-11-09 23:18:44
中國化肥信息(2022年7期)2022-08-31 01:29:28
中國化肥信息(2022年5期)2022-08-30 01:58:26
今日農(nóng)業(yè)(2021年20期)2021-11-26 01:23:56
今日農(nóng)業(yè)(2021年14期)2021-10-14 08:35:34
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
下一代英才(酷炫少年)(2018年6期)2018-07-09 03:17:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
