參數化模型數據庫在早期碰撞性能預研中的應用及優勢
2021-03-30 03:34:58鄧文字吳健余馮明松羅慧娟黃炎
汽車零部件 2021年3期
鄧文字,吳健余,馮明松,羅慧娟,黃炎
(上汽通用五菱汽車股份有限公司,廣西柳州 545007)
0 引言
隨著社會經濟的高速發展,汽車的需求量逐年增加,交通事故頻發使汽車安全受到廣泛關注,考慮汽車的安全性能在人們選購汽車時越發重視。汽車發生碰撞時,白車身作為主要吸能部分,對其研究具有重要意義。在傳統汽車的早期概念車身開發設計流程中,提升車身綜合性能和縮短整體開發周期一直是很難兼顧的矛盾。
在早期車身結果優化設計時,參數化模型可實現尺寸、材料、料厚、等多變量的一體式優化,在車型早期概念開發階段得到廣泛應用[1-2]。
本文作者針對早期碰撞性能開發提出先使用SFE車身數據庫搭建車身碰撞仿真模型,再利用SFE模型的隱式參數特性結合Isight DOE實驗方法驗證大量方案。這種方法旨在車身早期概念開發階段就積極參與白車身的相關性能驗證,改變傳統CAE分析落后于早期開發設計的流程,在縮短早期研發周期的同時提升車身碰撞性能。
在某新車型預研項目中首先利用SFE車身數據庫和初始輸入概念參考數據搭建了車身碰撞模型,根據項目需求和研究重點分別選取材料牌號變量9個、厚度參數變量29個、截面參數變量26個作為碰撞性能的設計變量,以侵入量、回彈時刻、吸能比、加速度作為優化目標。選取230個樣本點搭建Isight DOE,實現車身系統結構優化設計的自動循環運算。
這套白車身碰撞安全性能正向開發流程在白車身概念開發階段就進行大量CAE碰撞性能仿真分析,可以使工程師在車身概念設計階段有較大的設計空間尋求多種設計方案,從中篩選出性價比最好的綜合方案,在較短開發周期內提升碰撞性能以達到目標要求,為后續車身設計提供優化指導性建議和方案。從而極大程度地提高研發質量和效率,保證后期研發順利,有效降低研發成本。
1 基于參數化數據庫搭建碰撞仿真模型
1.1 隱式參數化技術
參數化數據庫搭建的模型是基于隱式參數化建模技術建立的數據集合。
在隱式參數化技術描述中,單個模型的幾何形狀由3種類型參數控制:基點坐標位置、基線曲率、基礎截面形狀。系統級模型可以通過控制上敘述參數和描述單個模型之間拓撲關系來自動生成。因為所有系統級模型是拓撲關系相連接,一旦上述任一參數修改,與其相關聯的所有幾何體都會產生相應變化[3-4]。這種模型具有兩個功能:(1)模型結構具有全參數化功能,幾何結構的位置、尺寸和形狀等可以任意改變,能記錄改變的過程并保存為設計變量;(2)幾何結構發生改變的參數化模型可以自動生成幾何結構相同并滿足網格質量要求的有限元模型。基于上述功能,隱式參數化技術成為車身結構設計優化的有利工具[5]。
1.2 SFE參數化數據庫
不同于傳統SFE建模,建立SFE參數化模型數據庫時,前期需要花費一定時間,對SFE參數化模型數據庫建模,進行相應的規劃。通過對國內外多款車型的主要截面和接頭的拓撲結構進行分析,可以發現其拓撲結構都是“大同小異”,主要差異就是尺寸大小的不同。就是說,主要截面和接頭在各個車型之間通過尺寸調整可以做到有效互換以斷面和接頭的通用性為基準,靈活地處理各種拓撲連接的數據庫。利用SFE模塊化技術,將整車分解到截面與接頭層面,這是實現數據庫的技術基礎。以截面和接頭拓撲結構為主導的數據庫適用于每一個企業。不在整車宏觀層面上考慮模塊的通用性問題(如前艙、側圍、前/后地板總成是否通用等等),而將著眼點放在截面和接頭拓撲結構的通用性上面,在這個微觀層面上,各種迥異的車型都能體現出通用性。
數據庫的最大特點是充分發揮模塊化的優勢,可以高效地衍生不同拓撲結構的各種車型。數據庫對一個企業的平臺規劃要求不高,不局限于特定的車身架構,可以在“局部模塊”的層面上快速完成各種整車結構的拼接和組合。
為保證通用性和靈活性,該數據庫搭建的整體思路可概括為:化繁為簡,有效拆分,干凈靈活。
綜上所述,數據庫的兩大特點是:
(1)不局限于工程平臺且兼容工程平臺,不受零件結構朿縛,可通過核心車型及局部拓撲模塊完成大批量車型衍生,即以最少的數據量覆蓋企業的全部車型。
(2)無重復建模工作,即所有新建模型均以數據庫原則建立并存儲到數據庫中,后續開發中遇到類似的拓撲結構可以直接調用數據庫模型。
1.3 利用SFE數據庫搭建碰撞模型
1.3.1 白車身拼裝
根據項目開發需求和車型定義,在已建立的SFE數據庫中挑選各個模塊拓撲形式一致或能快速修改符合需求的結構進行拼裝。如果數據庫中沒有相似或能快速修改的模塊選擇,則需要少部分重建(重建的部分可以歸納進數據庫中以擴展數據庫模塊類型)。
初步拼裝完成的白車身模型需要利用SFE模型隱式參數化的特性,根據CAS數據、門洞線以及截面數據、車身尺寸信息以及總布置數據等概念參考數據以及相關約束條件進行調整。
1.3.2 SFE碰撞網格的輸出
SEF碰撞仿真模型不同于剛度模態仿真模型,輸出的車身網格需要與車身之外的其他總成組合成整車進行碰撞仿真實驗。SFE輸出的白車身碰撞模型通過PATCH與整車其他總成連接。在對應連接位置建立相關PATCH,并且PATCH ID與整車其他總成保持一致。以防SFE輸出白車身碰撞網格節點號與其他總成網格節點號相同。相關設置完成以后SFE可以快速自動劃分碰撞模型。
SFE白車身模型搭建完成,劃分出網格數據后,替換原白車身數據,與其他總成數據拼接,即可完成碰撞數據的搭建,如圖1所示。

圖1 白車身模型搭建
1.4 基于SFE數據庫搭建碰撞仿真模型的優勢
1.4.1 時間效益
不同于傳統參數化建模方式,數據庫模塊有直接替換和快速修改的特點,這直接改變了在早期開發中傳統參數化模型修改方案的方式。利用SFE數據庫搭建車身模型平均為20個工作日,相比SFE逆向建模平均40個工作日(圖2),提高了一倍工作效率,同時提前了CAE分析時間節點。

圖2 建模時間統計
1.4.2 性能效益
與常規CAE分析對比,利用SFE數據庫搭建車身碰撞仿真模型能在早期CAD數據不足的情況下將有限元分析提前介入到概念開發階段,及時了解整車性能表現,早發現問題早解決,有效把控進度,采用SFE數據庫介入早期車身碰撞性能開發會使得早期模型具有較高的性能,可以為后續的詳細開發提供指向性的優化建議及方案。
SFE車身數據庫可以永久性更新,重復性使用。少量新建的模型可以擴充進數據庫,豐富數據庫模塊類型,數據庫越豐富建模效率越高,開發車型選擇更廣。
2 多學科多目標參數優化
通過SFE參數化模型進行Isight DOE實驗方法找到白車身幾何尺寸、材料牌號、零件厚度等各參數之間的最佳組合,以滿足碰撞安全性能驗證。確定完參數變量后,生成網格數據開始運算并提取結果。運用結果搭建近似模型,并進行誤差分析,滿足要求后,基于近似模型,進行仿真和優化。具體流程圖如圖3所示。
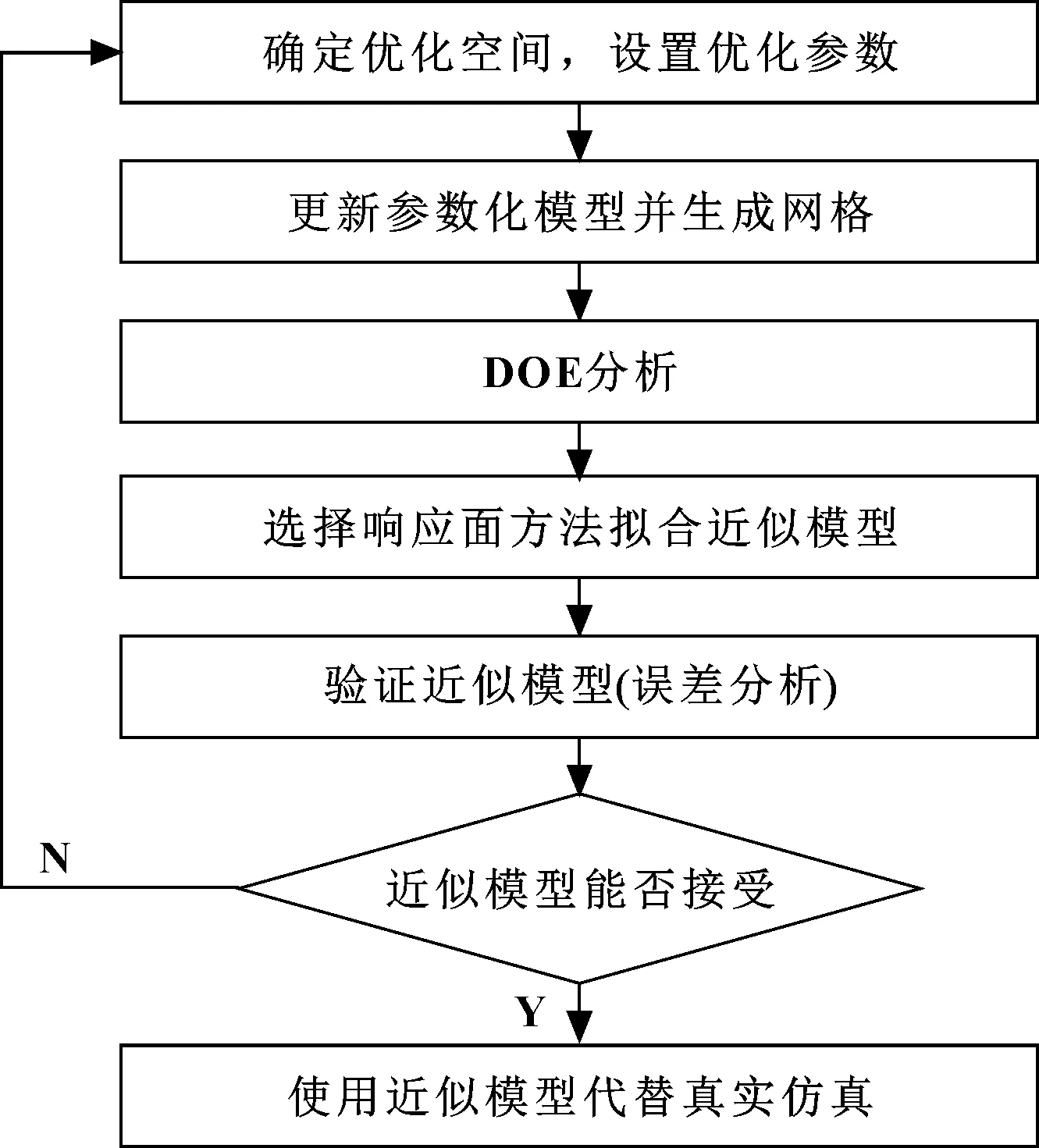
圖3 參數優化流程圖
2.1 優化參數
在優化前與設計部門確認相關參數優化空間,避免優化計算后發現參數不可調整,優化無效、反復。定義碰撞仿真需要驗證的相關參數變量空間:幾何尺寸、材料牌號、零件厚度等。
將白車身前端結構尺寸以及一些零部件的材料和料厚作為設計變量。涉及防撞梁、吸能盒、前大梁、SHOTGUN、前大梁加強板、前地板縱梁、前圍板加強板、前圍板橫梁、中通道、前地板、上邊梁和門檻梁。共材料牌號變量9個、厚度參數變量29個、截面參數變量26個。圖4為錄制厚度參數的部分板件;圖5為部分錄制的截面參數。

圖4 錄制厚度參數的部分板件
圖5 部分錄制的截面參數
2.2 試驗設計方法
以概率論和數理統計原理為基礎,在設計空間上選取合理有效的有限個樣本點,使之能最好地反映設計空間的特性,這種方法就叫做試驗設計(Design of Experiment,DOE)[6]。運行DOE共分3個步驟:試驗計劃、執行試驗、結構分析。
試驗計劃需確定變量的水平和類型,研究因素的主效應、交互效應,挑選合理的試驗設計方法,生成樣本點,確定所需響應。
試驗設計方法決定了樣本點的數量與空間分布,若選取的樣本點的分布并不合理或者數量不足,會導致再多的樣本點也得不到精度更高的近似模型。因此在眾多設計試驗方法中,挑選出最合理最高效的設計試驗方法尤為重要。常見的設計試驗方法包括:Box-Behnken試驗設計、中心組合試驗設計(Central Composite Design,CCD)、拉丁超立方試驗設計(Latin Hypercube)、正交矩陣試驗方法(Orthogonal Arrays)、Parameter Study試驗方法等。
DOE樣本點選取主旨為相關參數進行相關性能優化,以節約計算量,提高優化效率。優化拉丁超立方試驗設計(Optimal Latin Hypercube,OLHD)具有均衡分散性和整齊可比性的特點,能夠快速生成樣本點并能均勻地填充設計空間[7-8]。與中心組合相比,大大減少了試驗次數,與正交矩陣相比,樣本點分布更加均衡。此方法生成的樣本點能更好反映出試驗指標與試驗范圍內各因素的關系。適用于車身結構優化樣本點的選取。
故選取拉丁超立方生成樣本點,通過ISIGHT軟件調用SFE Concept軟件,根據預先設定的參數變量,自動生成240個ODB有限元模型后,提交到服務器上計算。
運用基于Hyperworks二次開發的腳本,自動讀取240版碰撞模型的各種性能指標。
2.3 近似模型方法
近似模型方法通過數學模型的方法,模擬眾多輸入參數與輸出參數之間的響應關系。用近似模型替代實際工程問題,能夠避免高強度仿真計算,減少迭代時間,并預測最優解[9]。
與傳統對比如圖6所示。預估輸入輸出參數間的響應關系,有效地避免局部優化解,找到全局最優解,可與DOE組成更好的優化策略。

圖6 優化策略
近似模型原理:基于試驗設計方法,抽樣獲得大量樣本數據,用回歸、擬合、插值等方法創建安全仿真的近似模型。
擬合近似模型的常用方法有:多項式響應面方法(Response Surface Methodology,RSM)、克里格方法(Kriging)和徑向基神經網絡方法(Radial Basis Functions,RBF)等。
多項式響應面方法(Response Surface Methodology,RSM)是響應面方法中最為常用的方法,在結構分析與優化中用于近似分析,其基本原理是根據已知設計點信息,構建多項式擬合模型,一般常用的為二階多項式[10]。二階多項式響應面近似模型具有相當高的近似精度,在多學科優化中,可替代耗時的有限元計算。
文中為了在較短時間內得到較為準確的結構,選用二階多項式響應面方法擬合近似模型,并基于近似模型得到了各參數變量對于各性能指標的相關性以及貢獻量。同時對近似模型的精度進行誤差分析,前圍板侵入量的誤差結果如圖7所示,大部分介于-3~3之間。
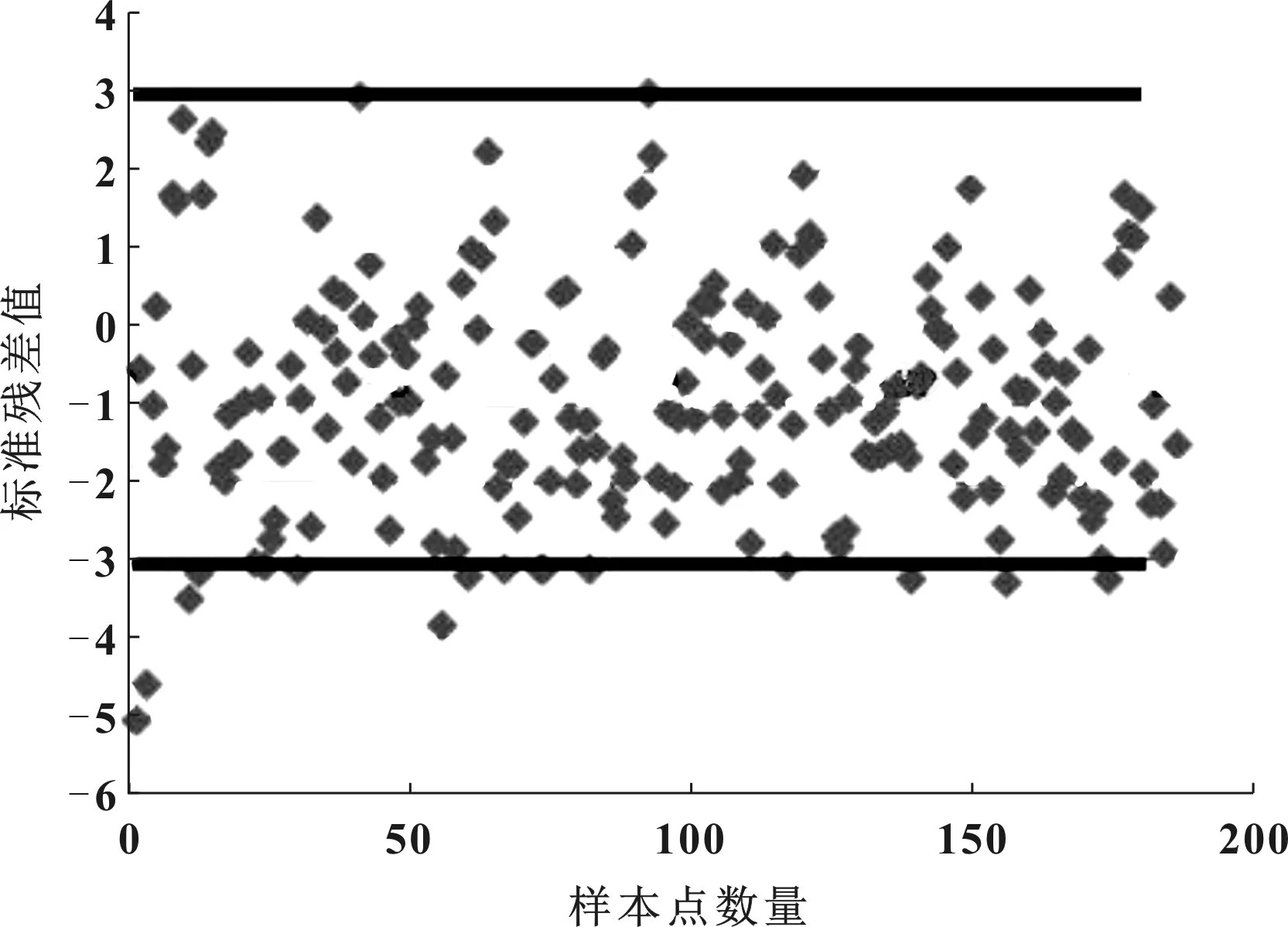
圖7 誤差結果
2.4 多目標優化算法
實際項目中,約束函數和目標設計變量可能是線性的連續單峰的函數或是非線性的離散多峰的函數;設計變量可能是連續的或是離散的,問題較復雜。需根據不同的情況,選擇不同的優化算法。
根據優化算法的適用范圍,優化算法可分為局部優化算法和全局優化算法。局部算法包括直接搜索算法和梯度優化算法,這種算法運算求解效率很高,但存在尋找不到全局解的可能性。
全局優化算法中有一種由進化理論和遺傳變異理論為基礎理論的遺傳算法(Genetic Algorithm,GA),此種算法與局部優化算法相比,能夠在全局空間內搜索優化解,但是這種算法運算求解效率相對較低。
實際項目中的優化目標較多,而且往往優化目標之間是互相矛盾、制約關系。針對此問題,在遺傳算法基礎上發展的多目標遺傳算法給出了解決方案。多目標遺傳算法共分為兩代。第一代多目標遺傳算法主要包括:多目標遺傳算法(MOGA)、非支持排序遺傳算法(NSGA)、Niched-Pareto遺傳算法(NPGA)。
第二代多目標遺傳算法包括:Strength Pareto遺傳算法(SPEA)、Pareto Archived遺傳算法(PAES)、非支配排序遺傳算法II(NSGAII)和序列二次方遺傳算法(NLPQL)等。
序列二次方遺傳算法(NLPQL)特點是算法效率高、對求解非線性性能目標具有高穩定性、能快速收斂到高質量的優化解。
通過尋求車身質量最小的同時滿足其他相關性能要求,或者在滿足質量要求尋求更優其他性能指標。以此分析質量以及性能指標的帶寬。
根據多種約束與目標的設置,進行多輪優化,最終得到最優結果。部分具體設計變量優化后的前后對比見表1。
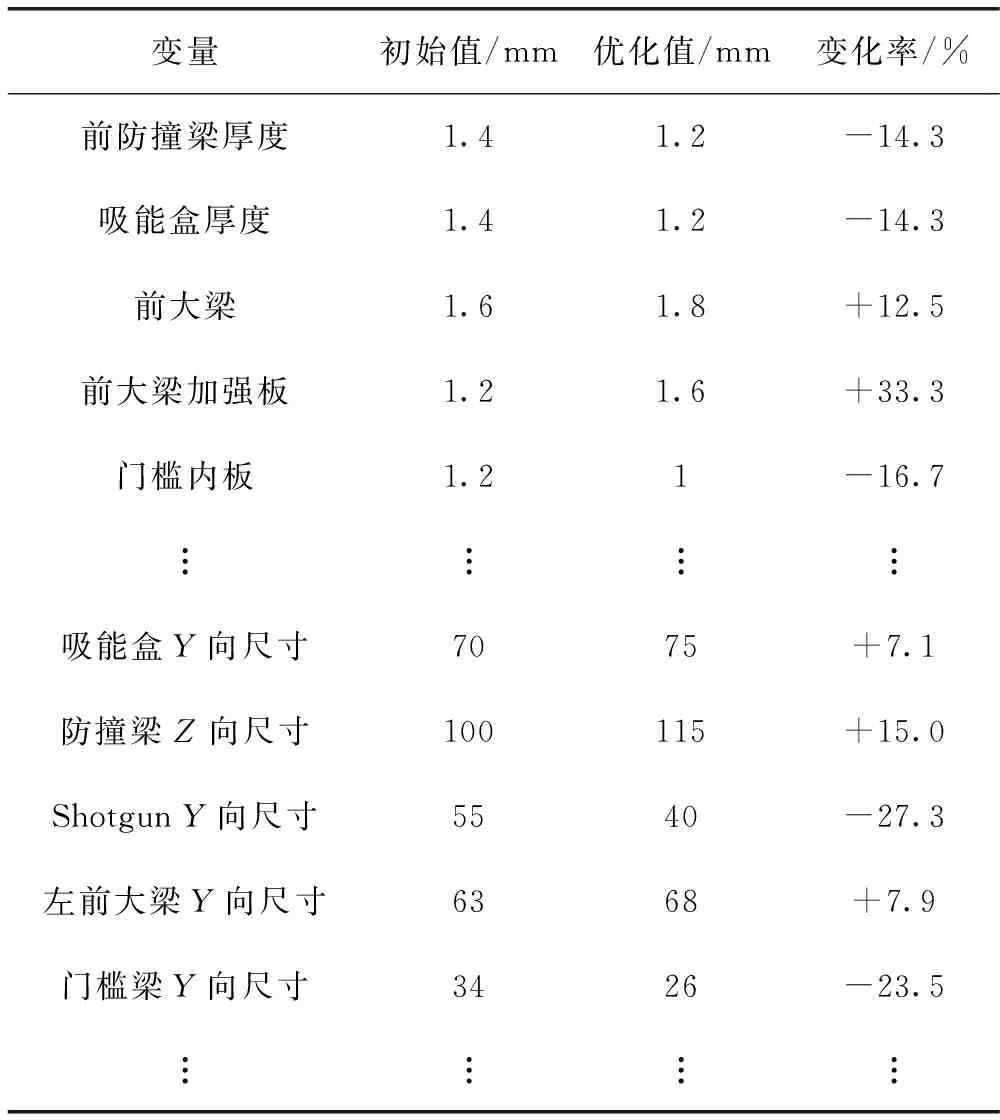
表1 設計變量優化結果
2.5 詳細設計與結果驗證
將優化算法得出的最優優化結果的參數(幾何尺寸、材料牌號、零件厚度等)代入SFE模型自動劃分有限元網格,并分別進行碰撞性能驗證。對比實際仿真結果與IsightDOE實驗輸出結果誤差。包括加速度曲線、最大侵入量、質量等。
經實際碰撞模型仿真分析得到結果,部分數值見表2。
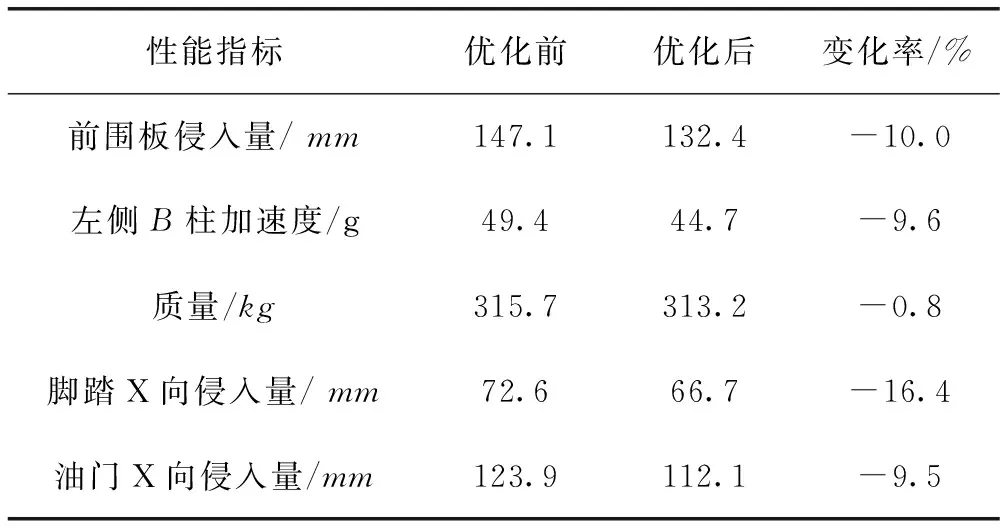
表2 碰撞性能優化結果
圖8為優化前后左側B柱加速度曲線對比,加速度峰值優化前為49.4g,優化后為44.7g,降低了9.6%。

圖8 優化前后左側加速度曲線對比
圖9為優化前后前圍板侵入量曲線對比,侵入量峰值優化前為147.1mm,優化后為132.4mm,降低了10%。
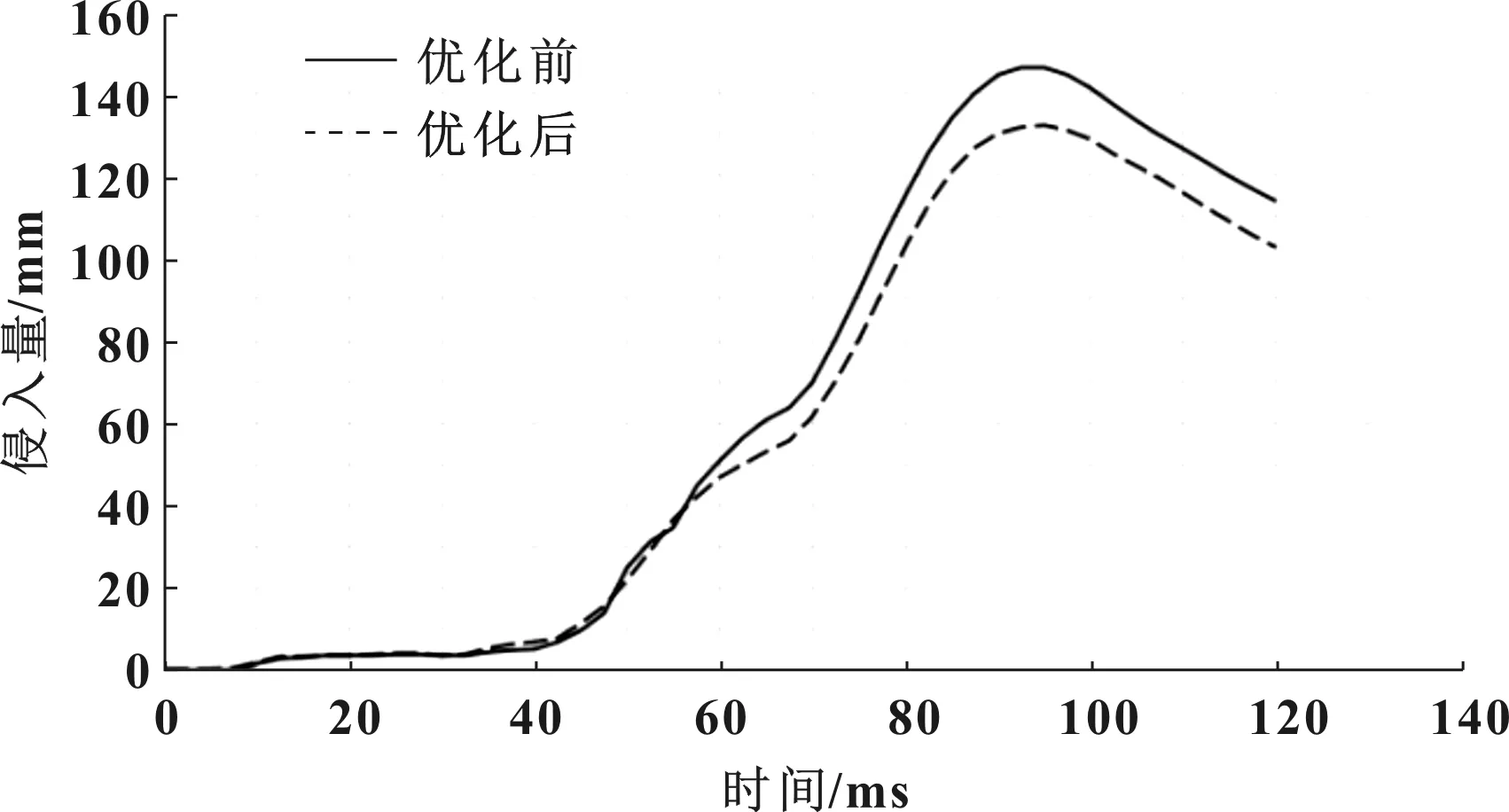
圖9 優化前后前圍板侵入量曲線對比
在ODB工況下,白車身優化后降低了前圍板、三踏板侵入量和左側B柱加速度,全面提升性能的情況下,又減少2.54kg。輕量化的同時,又達到了提升性能的要求。
最后,結合制造工藝和車身結果工程經驗,對優化得到的結果,進行進一步判斷與詳細設計,實現參數化模型數據庫在早期碰撞性能的預研。
3 結論
(1)基于參數化模型數據庫可以快速地搭建早期車身碰撞性能仿真模型,利用SFE模型的參數化特性能快速有效地驗證截面參數、材料牌號、零件厚度變更等方案。
(2)運用DOE實現了車身系統結構優化設計的自動循環運算。克服了提升車身綜合性能和縮短整體開發周期難以兼顧的矛盾。在車身早期概念開發階段實現CAE分析驅動CAD設計,為設計部門提供重要的整車性能信息和車身設計方向,達到參數化模型數據庫在早期碰撞性能的預研的目的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
