基于卷積神經網絡的玉米病害識別方法研究*
2021-03-31 01:24:52王國偉劉嘉欣
中國農機化學報 2021年2期
關鍵詞:模型
王國偉,劉嘉欣
(吉林農業大學信息技術學院,長春市,130000)
0 引言
我國三大農作物之一的玉米是重要的糧食作物及產業原料,玉米產業的穩定健康發展,在糧食安全、農民收入增加及國家經濟中起著重要作用[1]。伴隨著玉米產量的增加,玉米病害種類的繁雜,怎樣迅速正確的判斷出玉米病害,并且選取對應的控制措施,對玉米生產至關重要。根據肉眼觀察和經驗判斷很容易導致誤診,容易花費很多時間,并且無法在一定時間內診斷和治療玉米病害,從而使玉米生產效率降低。隨著計算機技術的發展,利用圖像識別技術診斷和檢測病害已成為診斷研究的一個重要領域[2]。在植物病害識別中,機器學習技術與圖像處理相結合的應用越來越廣泛。針對玉米常見的病害,毛彥棟等[3]提出一種SVM和DS證據理論融合方法、陳麗等采用遺傳算法、張開興等[4]采用圖像處理技術和BP神經網絡算法、張善文等[5]基于局部判別映射(LDP)算法和朱景福等[6]應用局部線性嵌入(LLE)算法對提取的病害特征進行約簡,識別率依次為93.3% 、90.0%、93.4%、94.4%、99.5%。這些研究盡管已經獲得了良好的效果,但是很難提取特征,也存在適應性低和魯棒性差等問題。
近幾年,深度學習在圖像分割和圖像識別方面取得了良好的效果,并且在特征提取中起著重要作用,它能夠自動提取圖像特征,所以在各個領域都有廣泛的應用 (如人臉識別[7-8]、語音識別[9]和行人檢測[10]等)。顧博等[11]利用GrabCut自動分割算法并融合基于顯著性的SLIC算法對玉米3種病害進行識別和分割、許景輝等[12]利用遷移學習方法對玉米大斑病和銹病進行識別。在對其他植物病蟲害的識別中也有很多研究學者將深度學習技術運用其中,并且獲得了較好的效果。馬浚誠等[13]將卷積神經網絡應用在溫室黃瓜病害識別方法研究中,對黃瓜病害進行識別。王艷玲等[14]將遷移學習應用到AlexNet卷積神經網絡中對10類番茄葉片病害圖像識別。蔣豐千等[15]提出了一種基于caffe框架下的卷積神經網絡識別方法來識別生姜病害。楊晉丹等[16]選取一種基于混合池化的CNN-9模型對草莓葉部白粉病病害進行識別以及蒲秀夫等[17]建立了一種二值化卷積神經網絡模型對多種植物病蟲害進行識別。
因此,本文基于經典CNN的深度學習網絡模型-LeNet,根據玉米病害圖像數據本身的特點,進行改進和完善,構建了一個多層 CNN 網絡結構玉米病害圖像識別模型,以期提高模型的魯棒性和泛化能力,實現對玉米病害準確、快速的識別。
1 材料與方法
1.1 玉米圖像數據集
本研究所用到的數據集,是由 5 種不同玉米圖像組成,包括玉米花葉病、灰斑病、銹病、葉斑病4種病害圖像和玉米健康圖像。5類玉米試驗樣本圖像共采集1 967張,均在自然環境下。其中玉米花葉病600張,灰斑病265張,銹病350張,葉斑病400張,玉米健康352張。本文試驗將玉米圖像分為2組:訓練數據1 574張,測試數據393張。將樣本集進行編號分類并制作標簽,分別用 0、1、2、3、4 表示對應的類別標簽,標簽0為玉米花葉病、1為灰斑病、2為銹病、3為葉斑病、4為玉米健康。圖片大小尺寸統一修改為256像素×256像素,表1列出了具體的數據集數量。4類玉米病害示例及玉米健康圖像見圖1。

表1 5種玉米圖像數據集Tab. 1 5 kinds of corn image data sets


(a) 花葉病(b) 灰斑病(c) 銹病


(d) 葉斑病(e) 玉米健康
1.2 試驗方法
1.2.1 程序運行環境
本試驗所有代碼均是在框架:PaddlePaddle 1.6.0(python 3.7)框架下完成的。框架環境:GPU:Tesla V100.Video Mem:16GB;硬件環境:Intel(R) Core(TM)i3-4005U CPU @1.70G。Windows 7 64bit 操作系統。
1.2.2 卷積神經網絡
卷積神經網絡(Convolutional Neural Network,簡稱 CNN)[18-19]作為深度學習技術的一個代表,近年來取得了飛速的發展。該結構包括輸入層、卷積層、池化層、全連接層和輸出層。其中卷積層和池化層是用于提取圖像特征的模型核心部分,全連接層可以在高層次特征域中以圖像分類為主實現圖像映射。
其中,卷積層包括大量卷積核, 經過計算卷積可獲得輸入圖像的特征圖,其公式[20]如式(1)所示。
(1)
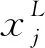
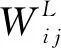
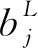
池化層(也稱為下采樣層), 它實質上是通過圖像處理來提取原始特征信息, 并且減小數據的空間大小和特征維數,其公式如式(2)所示。
(2)
式中:down(·)——下采樣函數;
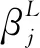
1.3 玉米病害識別模型結構與訓練
1.3.1 模型結構
本文模型是在經典的LeNet模型基礎上進行改進。LeNet這個網絡雖然很小,但它的整體結構模型非常完整,傳統的卷積、池化等操作都有涉及[21]。LeNet[22]網絡原有3 層卷積、2 層池化、1 層全連接層。改進之后,本文CNN玉米病害識別模型網絡結構見圖 2,共有10個網絡層,包含輸入層、3個卷積層、3個池化層、2個全連接層和輸出層。
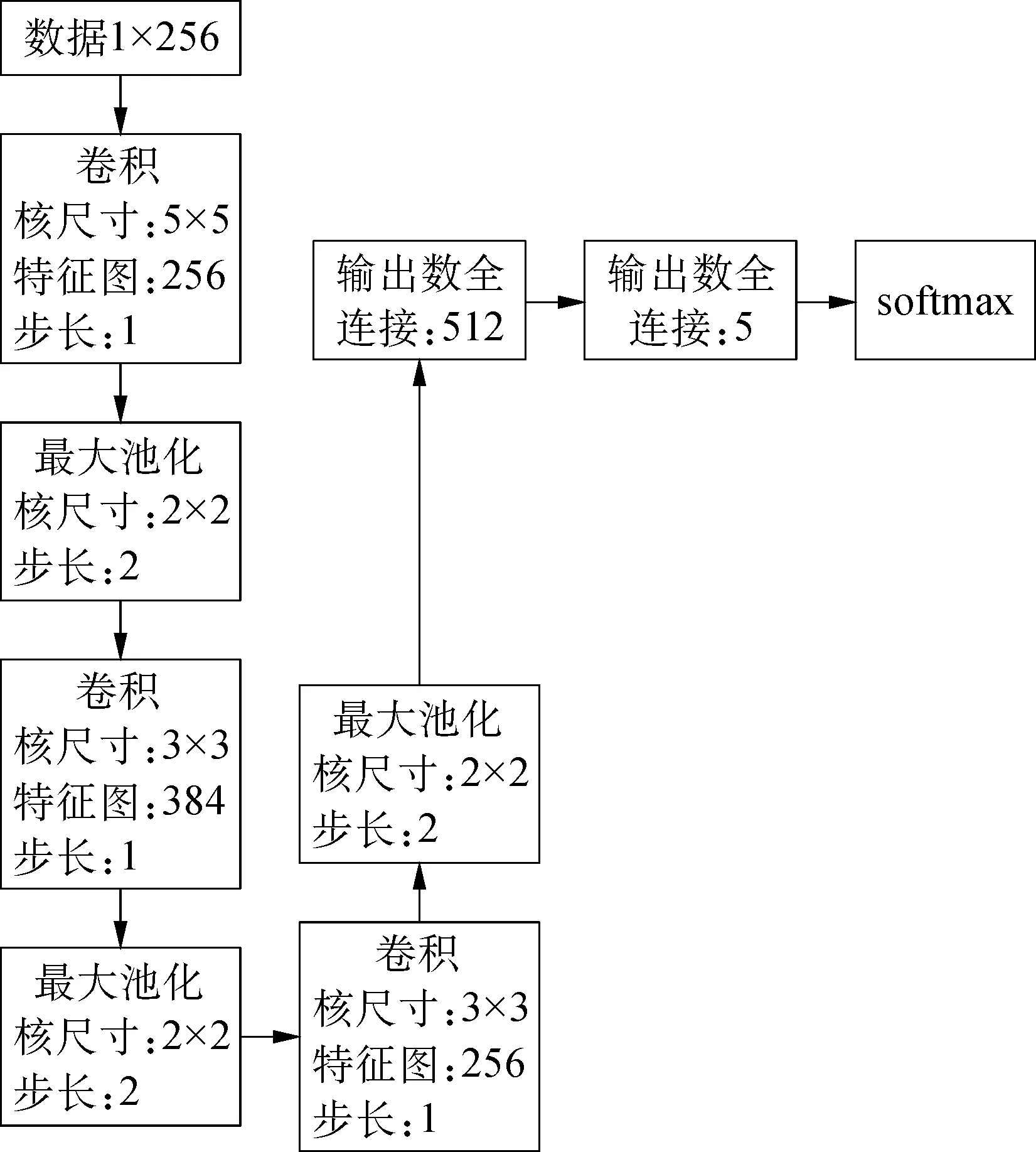
圖2 CNN玉米病害識別模型網絡結構圖Fig. 2 CNN corn disease identification model network structure diagram
另外,在第一層卷積和第二層卷積當中,加入局部響應歸一化層(Local Response Normalization,LRN),能夠提高模型結構的準確性和泛化能力,全連接模塊都包含了dropout 層,并且在訓練期間一些連接會被隨機丟棄,丟棄概率設置為0.5。另外本文采用修正線性單元(ReLU)[23]作為激勵函數,添加在卷積層之后,進行數據的訓練。本文池化方式采用的是最大池化法(Max pooling),最后采用Softmax分類器,作為最后的分類輸出層,輸出類別為5。
因此,按照試驗的具體要求,在本研究中提出的玉米病害識別模型的網絡結構參數設置如表2所示。

表2 本研究模型參數設置Tab. 2 Parameter settings of this research model
1.3.2 模型優化
模型結構優化的實質是最大程度地減少損失函數的迭代次數。通過將自適應矩估計(Adam)(Adaptive moment estimation)替換傳統的隨機梯度下降(SGD)(Stochastic Gradient Descent)方法來進行模型的優化。Adam算法的實質是按照損失函數動態調整每個參數梯度的一階矩估計和二階矩估計。其特點是計算效率高,占用內存小,適用于解決大樣本量和優化參數問題。
選擇指數衰減法作為學習率更新方法。首先將網絡訓練的初始學習率設定為較大的值,使訓練達到最優解的鄰域,然后學習率逐漸降低。指數衰減法學習率的更新見公式(3)。
lr=lro·dr∧(?gs/ds」)
(3)
式中:lr——衰減后的學習率;
lro——最初學習率;
dr——衰減系數;
gs——目前的迭代次數;
ds——衰減步長(也就是說,學習率在每次指定的迭代次數后都會更新)。
采用交叉熵損失函數計算分類損失,添加L2正則化懲罰模型內部加權參數,避免模型的過擬合。函數如公式(4)所示。
(4)
式中:J——訓練損失率;
θ——模型加權系數;
λ——正則項系數;
x——批量訓練樣本數;
p——預期分類概率;
q——預測分類概率。
此外,本文中的第一和第二全連接層添加了Dropout策略層,以防止過度擬合。Softmax函數用作最后一個全連接層中的最終輸出。Softmax函數通常用作神經網絡模型的分類器。通過函數運算,計算出輸入樣本被識別為特定類別的概率。經過一系列參數調整后,將獲得對應于正確類別的最大概率值。
1.3.3 模型訓練過程
本研究模型訓練過程主要分為如下3個階段: (1)創建數據集,建立與此研究訓練相適應的玉米病害圖像數據庫,使用玉米病害圖像作為模型訓練下一階段的數據源。(2)根據圖2所示的模型思路,進行編譯和模型參數設定。最大訓練數設置為200輪,batch_size=50。(3)訓練并且保存模型,執行器接收傳入的程序。最后,采用反向傳播算法逐層求導,在連續迭代訓練過程中調整模型參數,得到最小收斂值當作最終輸出。
2 結果與分析
2.1 不同激勵函數對模型性能的影響
在神經網絡結構中,這里的激勵函數是為了保障網絡輸出是非線性函數而添加的。這里一般使用的幾種激勵函數是Tanh函數、Sigmoid函數和ReLU函數。與前兩個函數相比,ReLU函數具有計算簡單,收斂速度快的特點,函數如式(5)所示。
ReLU(x)=max(0,x)
(5)
圖3顯示了不同激活函數對識別準確率影響的試驗結果。可以看出,當使用ReLU函數時,識別準確率最高。ReLU激勵函數[24]由于采用了分段形式,所以它的前、后、導數形式都是分段的,使得優化學習和求解模型收斂問題更加容易。
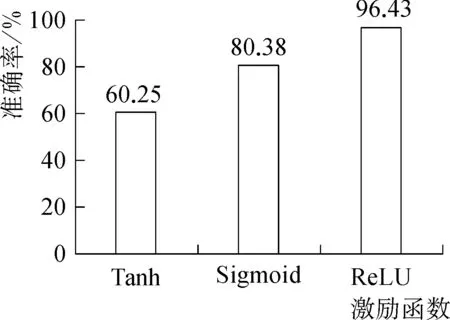
圖3 不同激活函數對試驗產生的結果Fig. 3 Results of different activation functions on the experiment
2.2 有無Dropout層對模型性能的影響
訓練模型的過程中,通常會發生過擬合現象。所謂的過擬合,具體顯示為模型準確率在訓練集上的表現良好,在測試集上的表現不佳,這意味著模型的泛化能力較弱,進而影響準確率。為避免訓練過擬合,除了在數據處理過程中添加數據集之外,本研究還將Dropout層添加到模型中。在網絡的每個訓練期間,Dropout層會依據一定的概率將有些神經元權重臨時置為0,減少神經元之間的依存關系,避免網絡的過度擬合。在測試中,該程序共執行3次。測試結果如表3所示。
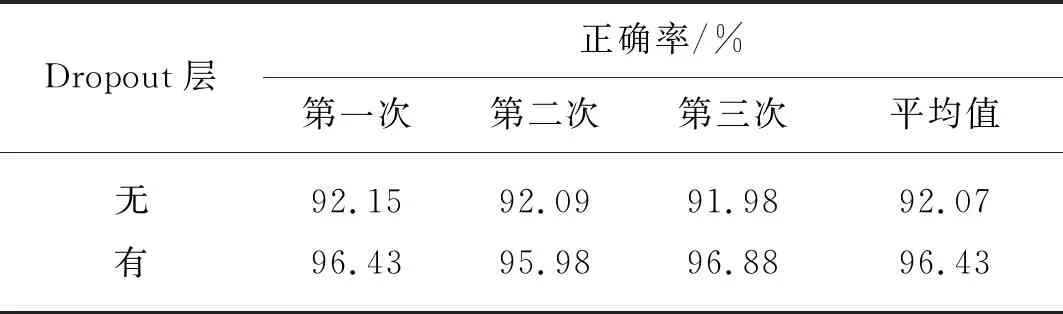
表3 Dropout層對試驗的影響Tab. 3 Influence of Dropout layer on the experiment
2.3 網絡層數,正則項系數及學習率對準確率的影響
為了確定最佳參數,得到最佳模型,對試驗結果進行比較,包括網絡層數的設置(卷積層、全連接層)、初始學習率的設置、正則項系數的設置等。其中,3 種全連接層設置(1 層、2 層、3 層),3 種卷積層設置(2層、3 層、4 層),3 組正則項系數設置(0、0.000 1、0.001),3 組初始化學習率設置(0.000 1、0.001、0.01)。試驗測試結果見表4。根據表4中內容可以看出,在B2組實驗中,當設置 2 個全連接層、3 個卷積層,正則項系數為0.000 1,學習率為0.001時最小訓練損失率和最大訓練準確率分為達到0.103 77和0.964 3,模型性能最優。
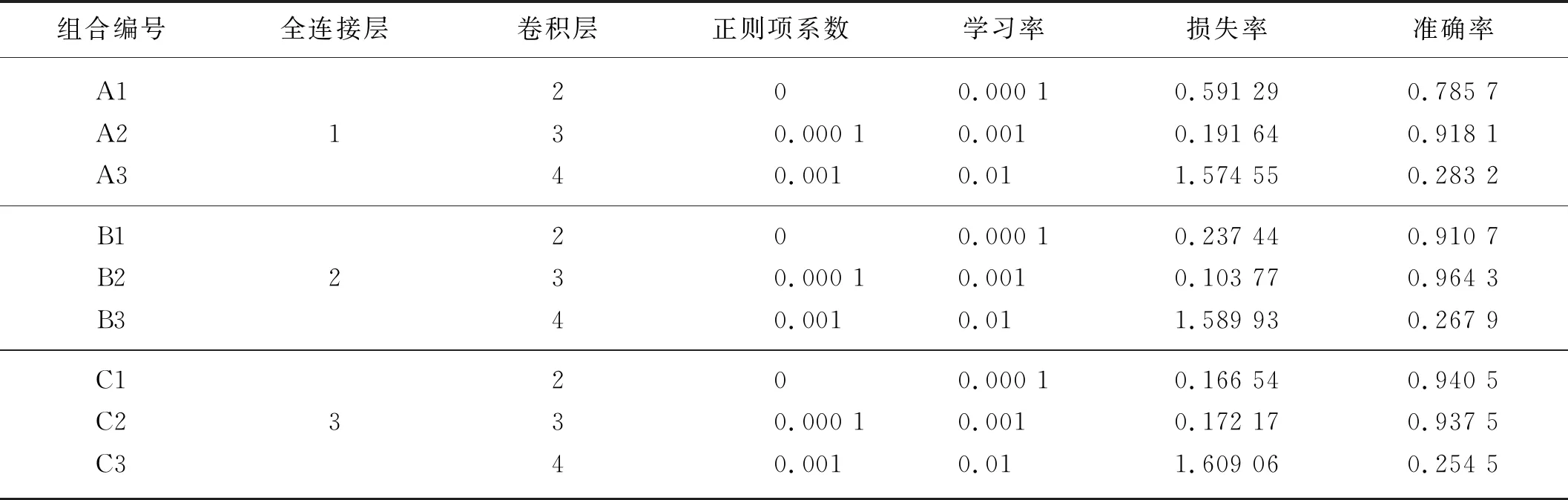
表4 參數設置與訓練結果Tab. 4 Parameter settings and training results
2.4 Adam算法SGD算法比較
本文運用Adam算法代替傳統的SGD算法。SGD算法通過保持單一的學習率(即alpha)來更新所有的權值,并且學習率在訓練過程期間不會發生改變。而Adam算法通過計算梯度的一階矩估計和二階矩估計來設計針對不同參數的獨立自適應學習率。在3個卷積層、2個全連接層、正則項系數為0.000 1、初始化學習率為0.001的總條件下,通過試驗,來對比兩種方法的差別。圖4顯示了在相同條件下Adam算法和SGD算法試驗的訓練準確率變化趨勢。結果表明,當采用Adam算法時,模型的準確率更高。
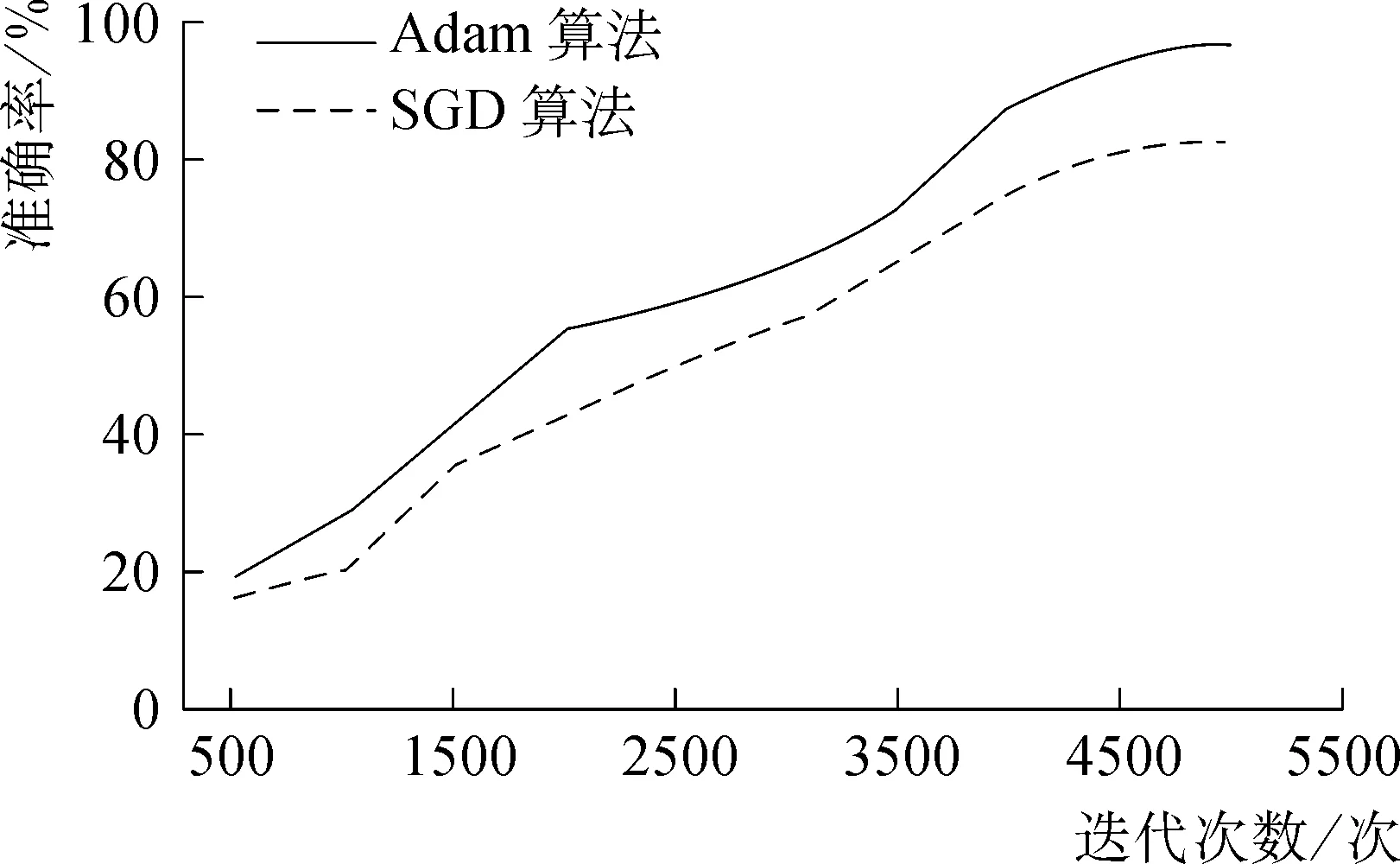
圖4 Adam算法和SGD算法訓練準確率Fig. 4 Training accuracy of Adam algorithm and SGD algorithm
圖5顯示了在相同條件下Adam算法和SGD算法試驗的訓練損失率變化趨勢。損失率越小代表著曲線越收斂,模型學習效果越好。根據圖5能夠看出,當使用Adam算法時,曲線收斂效果比使用SGD算法時更好,并且損失率更小。試驗表明,當使用Adam算法優化模型時,模型效果更好,更為理想。
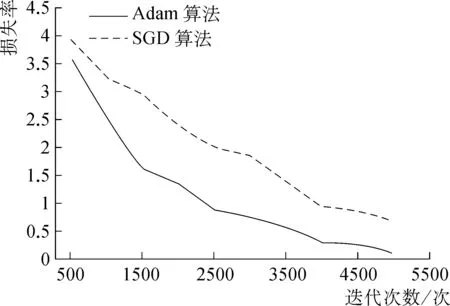
圖5 Adam算法和SGD算法訓練損失率Fig. 5 Adam algorithm and SGD algorithm training loss rate
2.5 驗證結果分析
如上所述,在玉米圖像中選取了120幅玉米花葉病圖像、53幅灰斑病圖像、70幅銹病圖像、80幅葉斑病圖像和70幅玉米健康圖像作為固定的檢測數據集。數據集中的所有圖像均未參與模型的訓練和識別。因此,通過識別準確性來檢驗本文模型的泛化能力,即模型對未參與訓練的新圖像是否同樣具有高的識別準確率。試驗結果表明,用未參與模型訓練的新圖像來檢驗模型的識別能力,仍然取得了理想的識別率。其中,由于銹病和玉米健康圖像與其他玉米病害具有明顯不同的特征,因此識別率達到了100%;葉斑病玉米病害圖像在某些細節特征上與灰斑病有相似的細節特征,出現誤判現象,識別準確率為93.75%。花葉病的玉米病害圖像識別準確率為95.83%;灰斑病的玉米病害圖像識別準確率略低,但也達到了90.57%。由于測試集圖像與訓練集圖像具有相同的背景等因素,因此5類玉米圖像識別的平均準確率達到96%,接近于訓練準確率。
表6為測試集玉米圖像識別后統計的混淆矩陣。其中,葉斑病和灰斑病在形狀、顏色、紋理及局部細節上有相似之處,因此2類玉米病害均存在誤判現象;花葉病和玉米健康雖不屬于同一種,但也存在相似之處,因此花葉病圖像有 5張被誤判為玉米健康。
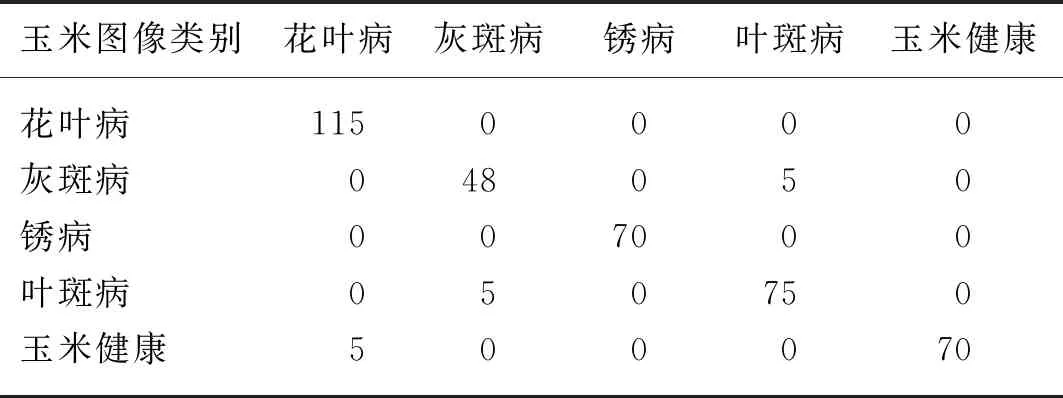
表6 測試集玉米圖像識別后統計的混淆矩陣Tab. 6 Confusion matrix of the statistics of the corn image recognition in the test set
3 不同方法比較
為驗證本文研究方法的可行性,將其與傳統的CNN模型和基于CNN的VGG網絡模型進行4種玉米病害和玉米健康圖像識別的對比試驗。試驗主要從識別率、損失率和單幅玉米病害圖像識別時間三個方面對模型性能進行評估,對比結果如表7所示。從中可看出,VGG模型的平均識別率為49.75%,平均識別時間為6.20 s,在對比的三種模型中識別率最低且識別時間最長;傳統CNN模型的平均識別率為80.66%,平均識別時間為3.10 s,識別效果相對較好;本文提出的方法平均識別率為96.43%,平均識別時間為0.15 s,識別率最高,識別時間最短,識別效果最好。
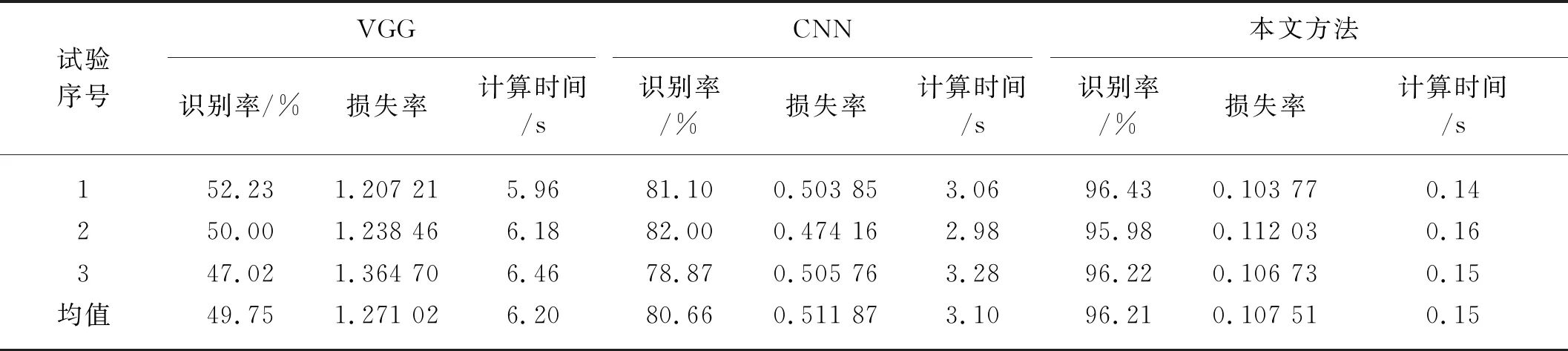
表7 提取方法比較Tab. 7 Comparison of extraction methods
4 結論
本文基于經典CNN模型LeNet的基礎上,構建了一個10層的玉米病害識別模型,完成對玉米花葉病,灰斑病,銹病,葉斑病,4類不同玉米病害圖像和玉米健康圖像的識別分類。在訓練集和測試集上達到了一定的識別效果。
1) 基于深度學習的玉米病害圖像識別模型可以自動提取出玉米病害特征,可以較好的對玉米病害圖像進行分類,對玉米花葉病、灰斑病、葉斑病識別準確率分別為95.83%、90.57%、93.75%,對銹病和玉米健康識別準確率均為100%,平均識別準確率在96%以上,平均識別時間為0.15 s,無需人工的對輸入圖像進行特征提取,只需簡單地標記類別即可,節省了大量人力和時間,提高了識別效率和精度。
2) 在模型優化方面,提出了用Adam算法代替傳統的SGD算法,提高了識別率。 除此之外,使用指數衰減法調整學習率,并且將L2正則項添加到交叉熵函數中。為了防止訓練過程中過擬合情況的發生,在網絡層中使用Dropout策略和ReLU激勵函數。
3) 與其他模型的圖像識別率相比,該模型具有更強的識別性能和較好的實用性。可鑒別4種玉米病害和玉米健康圖像。該模型提高了模型的泛化能力和魯棒性,為接下來的植物病害研究提供了基礎和理論依據。
因為本研究只是研究和分析了4種常見的玉米病害,所以必然存在一些限定性,為了進一步推廣模型,并提高玉米病害圖像識別的準確性和實用性,下一階段將收集更多高質量的玉米病害圖像,調整和優化模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
