基于Spark的醫療設備運維信息挖掘分析研究?
2021-04-04 07:49:00饒季勇錢雪忠
計算機與數字工程 2021年3期
關鍵詞:設備
饒季勇 李 聰 錢雪忠,2
(1.江南大學物聯網工程學院 無錫 214122)
(2.江南大學物聯網技術應用教育部工程研究中心 無錫 214122)
1 引言
隨著各醫院醫療設備數量和種類的不斷增長,設備的運維問題也日益凸顯,做好醫療設備運維的質量保證,對于臨床診斷和治療工作有著重大的意義[1],數字化時代的到來,更激發了對制造業及其運營的全新思考,工業4.0運用IOT技術動態響應設備需求,機械傳感器與控制系統互聯互通,可實現醫療信息化系統用于醫療設備的預測性維護、統計評估等[2]。根據大數據的定義,醫院所生成的醫療設備運行數據可以被認為是大數據[3]。這些海量數據蘊含著大量對設備運行有應用價值的信息。數據挖掘能從這些歷史數據中提取出故障相關信息,進行設備故障的診斷。
傳統的數據挖掘面對海量醫療設備大數據時,難以滿足性能需求。越來越多的學者開始向大數據預測性維護方向進行研究[5~6],但針對醫療設備運維大數據研究卻不多,通過對Spark的研究發現,Spark是一個基于內存的并行計算框架,避免了Ha?doop將中間結果存入磁盤,再從磁盤中重讀的繁瑣問題,因此Spark相比于Hadoop MapReduce在迭代計算方面更加高效。在面對設備異常數據時,通常采用聚類算法進行數據分析,例如孟建良、劉德超[12]就電力系統不良數據采用并行K-means算法進行實驗,實現電力系統負荷信息的檢測;宋鳴程等[15]提出一種基于Spark的K-means算法和FP-Growth算法結合的新方法對火電大數據進行處理,挖掘到目標的強關聯規則,從而得到各工況下的參數達到過的最優值,并對機組運行進行優化指導。聚類算法眾多,最為常用的是K-means算法,為了提高算法的聚類效果,學者們針對K-means算法提出了很多優化算法,比如Bahmani B和Moseley B等[7]提出的Scalable K-Means++算法,優化了K-means對隨機生成初始質心的問題,使K-means算法的效率得到很大提升;張玉芳等[10],使用基于取樣的劃分的思想改進了K-means算法,在算法的穩定性上獲得了提升。
針對以上問題,提出了基于Spark的醫療設備運維信息挖掘分析方法,該方法通過K-means算法在Spark平臺上并行計算,根據數據的挖掘結果對設備運行參數進行故障歸類,有效地解決了傳統數據處理面對海量數據時的迭代計算問題,提高了醫療設備運維信息的處理能力。同時,該方法根據真實的醫療設備運行狀態,對其運行參數進行了型號、閾值的劃分,保證了數據挖掘的可靠性和高效性。
2 Spark平臺架構
2.1 Hadoop
Hadoop是Apache軟件基金會旗下的一個開源分布式計算平臺,為用戶提供了系統底層細節透明的分布式基礎架構。它是基于Java語言開發的,具有很好的跨平臺特性,并且可以部署在廉價的計算機集群中。
Hadoop的核心部分包括HDFS、MapReduce和YARN。HDFS是分布式文件存儲系統,用于管理同一網絡下跨多臺計算機的文件,包含名稱節點(NameNode)和數據節點(DataNode)。MapReduce是一種分布式并行編程框架,主要用來處理和產生大規模數據集,“Map”和“Reduce”是其中的兩大基本操作,Map函數對數據進行分塊處理并產生中間結果,Reduce函數則對Map函數產生的中間結果進行歸約產生最終結果。YARN是統一的資源調度器,完成對任務資源的管理、調度等功能。
2.2 Spark
Apache Spark是一個開源集群運算框架,最初是由加州大學伯克利分校AMPLab所開發,它是一個類Hadoop MapReduce的通用并行計算框架,使用了存儲器內部運算技術,在原有的Hadoop Ma?pReduce優點上,彌補了其在迭代計算方面的不足,提高了運算速度。
Spark由Scala語言編寫,Spark的核心是彈性分布式數據RDD,Spark其他功能都是基于RDD和Spark Core之上的,RDD抽象化是經由一個以Sca?la、Java、Python的語言集成API所呈現。Spark包含用于在內存上提供數據查詢功能的Spark SQL、機器學習庫MLlib、流式計算Spark Streaming、用于圖分析的算法合集Graph X等模塊。
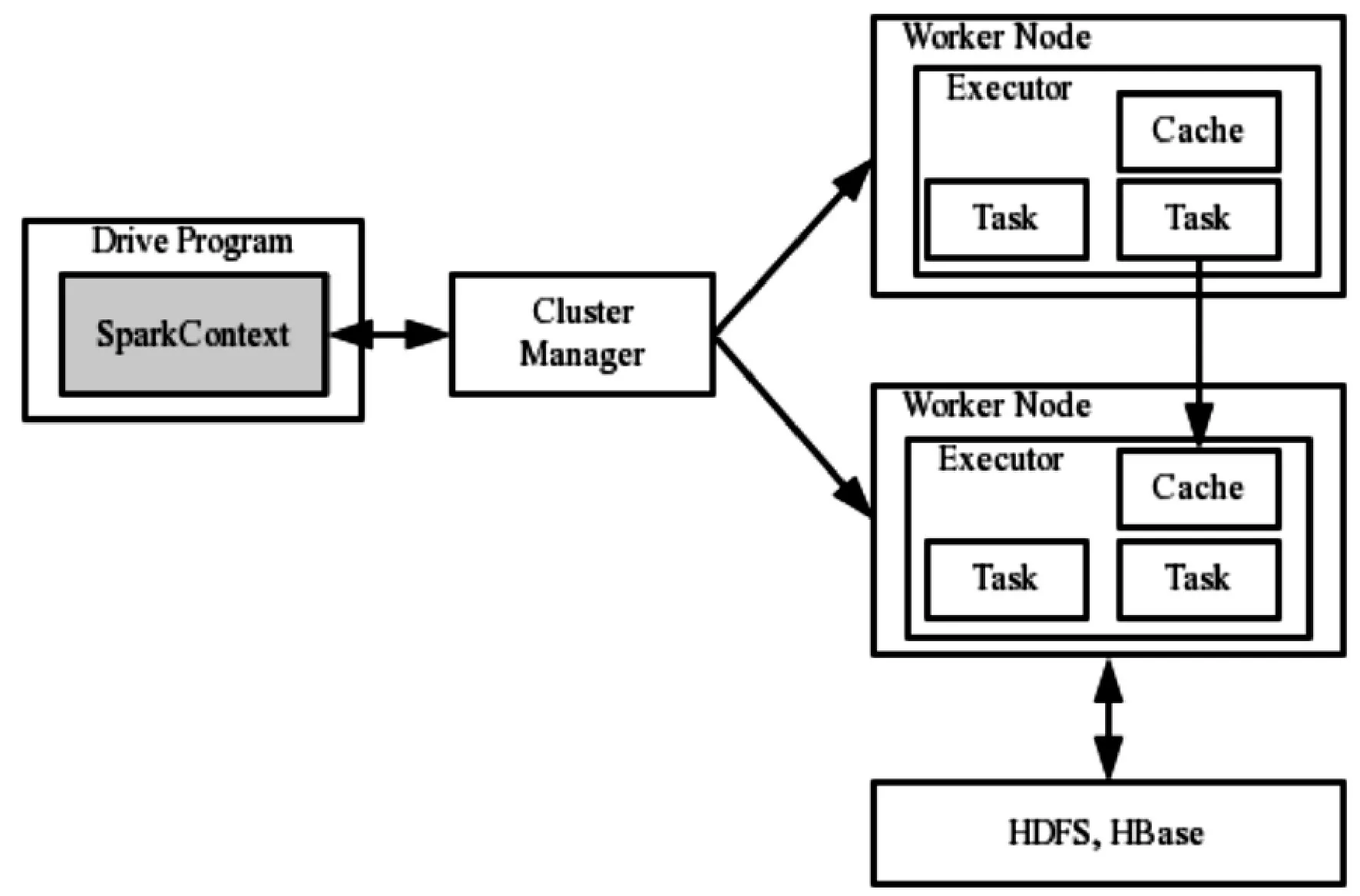
圖1 Spark系統架構
如圖1所示,Spark運行架構包括集群資源管理器(Cluster Manager)、工作節點(Worker Node)、每個應用的任務控制節點(Driver)和每個工作節點上負責具體進程的執行進程(Executor)。其中,Cluster Manager可以是Spark自帶的Standalone資源管理器,也可以是YARN或Mesos等資源管理框架。
3 算法分析
3.1 K-means算法
K-means是一個數據挖掘算法,屬于無監督學習,可以根據對象的屬性或特性將N個對象聚類到K個簇,同一簇中的對象相似度較高;而不同簇中的對象相似度較小。讓數據與相應簇質心間的距離的平方和最小,這樣就可完成這個分組。其算法表達式為
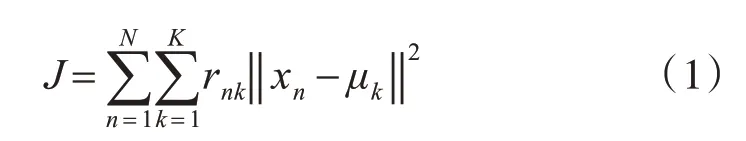
其中xn表示n個d維數據,μi表示簇中心的平均值,rnk表示數據被歸類到簇的時候為1,否則為0。
K-means算法的第一步是根據給定的k值,取k個樣本點作為初始劃分中心。第二步將數據點分配到最近的簇質心。對于一個給定的d維數據點,可以使用距離函數來確定最近的簇質心,采用歐式距離函數來計算這個質心生成該數據點的可能性有多大。若要得出兩個d維數據點x=(x1,x2,…xd)和y=(y1,y2,…,yd)之間的歐式距離,歐式距離公式為
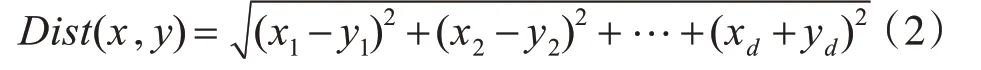
第三步,計算每個劃分中樣本點的平均值,將其作為新的中心。循環2、3步直至達到最大迭代次數,或劃分中心的變化小于某一個預定義閾值。
3.2 基于Spark的K-means算法
K-means算法需要重復迭代計算每一個數據與質心的歐式距離,所以K-means算法的時間復雜度會隨著數據量的不斷增大而不斷增大,處理大數據時會出現計算瓶頸。其次,在單機平臺上由于無法完全將數據加載到內存進行計算,所以需要重復讀寫內存和磁盤,浪費大量資源。本系統采用基于Spark平臺的K-means算法處理醫療設備運維大數據,將醫療設備運行時產生的大數據分發到各個計算節點,同時進行計算,解決了單機狀態下處理大數據的計算瓶頸,又由于Spark是基于內存計算的框架,還可以優化諸如K-means等迭代算法的計算。其算法流程如下所示。

4 系統設計與實現
實驗在ecs服務器單機偽分布式配置上進行,偽分布式Spark集群環境如表1所示。按照安陽市人民醫院型號為3.0T HDXT的儀器運行參數,模擬高斯分布數據進行實驗。Hadoop進程以分離的Ja?va進程來運行,節點既作為NameNode也作為DataNode,同時讀取的是HDFS中的文件。軟件開發環境采用IntelliJIDEA 2018.2.4。單機上所有軟件在安裝并配置完成后即可啟動Spark偽分布式集群進行測試。基于Spark的醫療設備運維系統架構如圖2所示。
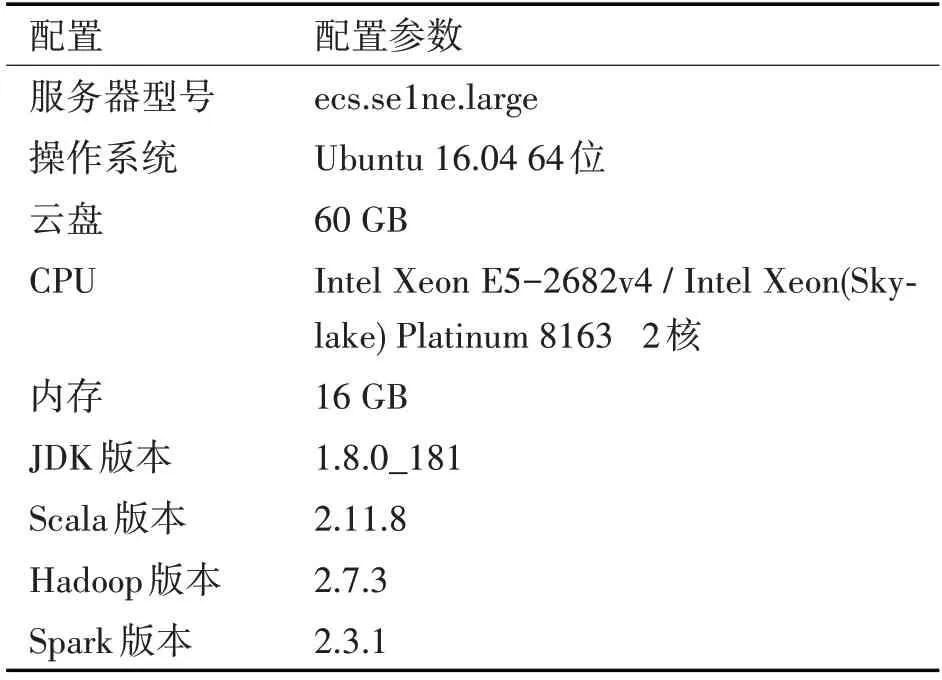
表1 計算節點配置
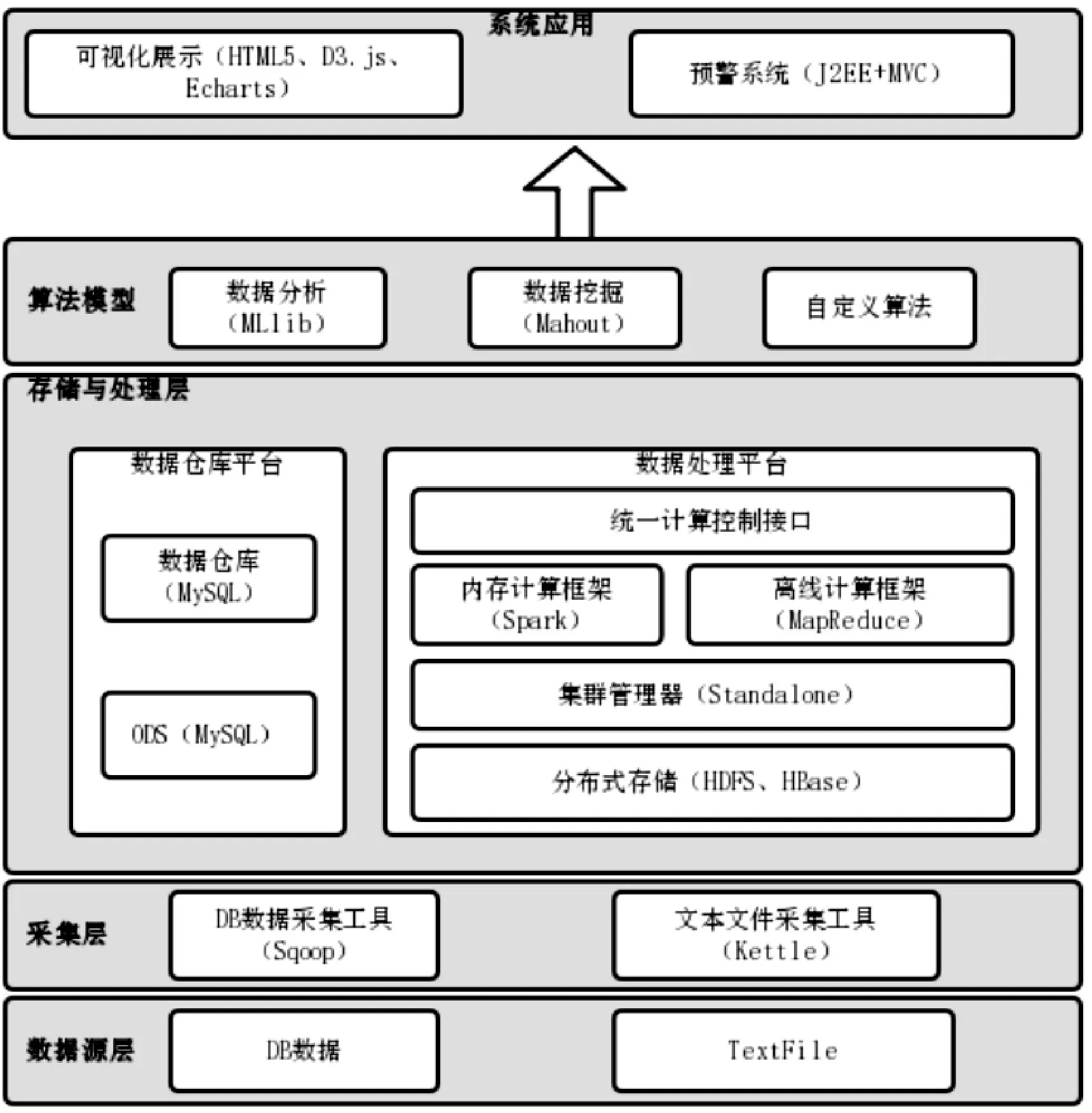
圖2 系統架構
數據采集方面,對于DataBase數據采用Sqoop工具將儲存于MySQL的數據抽取到HDFS中,對于文本文件采集我們使用傳統的Kettle導入HDFS或MySQL中。采用HDFS作為分布式文件存儲,MySQL作為傳統數據庫,Standalone資源管理器,采取偽分布式部署,使用基于Spark的K-means聚類模型進行數據處理,構建離線醫療設備運維分析模型,表明Spark平臺的高可靠性和運算速度快的特點。數據可視化方面,采用Java編寫MySQL數據庫連接模塊,結合JavaScript技術,利用Json作為數據傳輸類型。可視化的結果以靜態圖像和動態圖像結合的方式呈現,使得用戶能夠從不同的角度去觀察數據視圖。Echart提供了豐富的數據交互能力及各種各樣的圖表結構,本系統選擇了Echart中多種圖表與百度地圖API結合的方式將結構呈現給用戶。可視化界面主要分為設備基本信息和數據運維信息兩個部分。設備基本信息部分主要針對設備的基礎信息,健康狀況,分布情況及整個系統的錯誤日志進行展示,并實時更新。數據運維信息部分主要針對算法中分析出來的數據利用Echart圖表動靜結合的呈現出來。
5 系統測試與分析
運用安陽市人民醫院3.0T HDXT型號設備在2018-06-27~2018-11-16這段時期運行產生的數據歸結出的運行參數閾值進行預測的標準。型號3.0T HDXT設備運行參數閾值如表2所示。
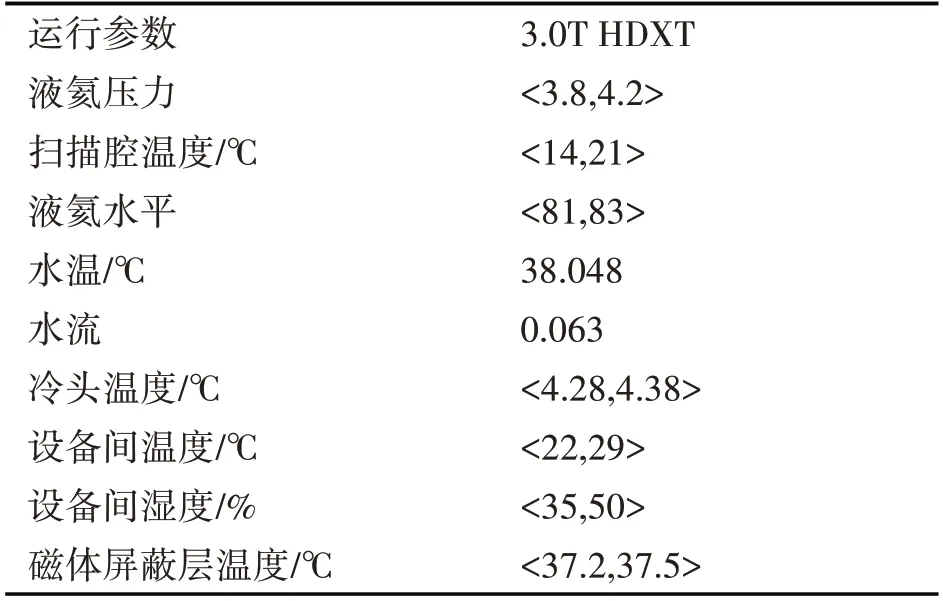
表2 型號3.0T HDXT設備運行參數閾值
K-means算法使用Scala語言,在IntelliJ IDEA 2018.2.4內進行編譯。類比型號3.0T HDXT設備運行數據,采用高斯分布的模擬數據進行實驗,共有3萬組9維數據,選取液氦壓力、掃描腔溫度、液氦水平、水溫、水流等9項參數,運用基于Spark的K-means算法進行聚類計算,產生的3個聚類中心如表3所示。與表2設定的閾值相對照可以看出,位于第一、二類的數據點的液氦水平較高,磁體屏蔽層溫度較低;第三類的數據點的液氦壓力很低,掃描腔溫度較高,水溫較高,冷頭溫度較高,由此可以將這3萬條數據簡單分為3類做初步的預測。
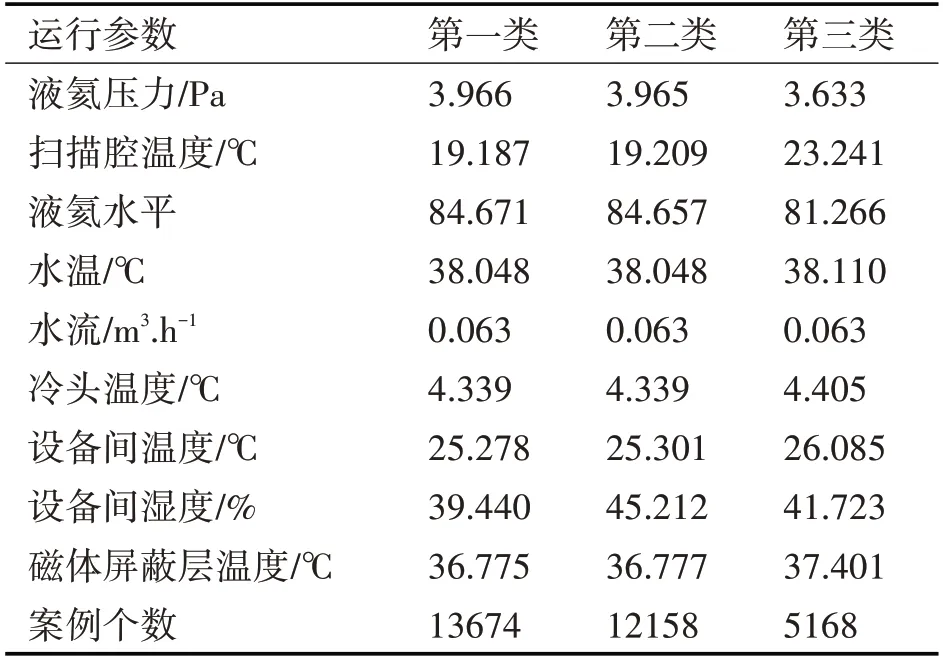
表3 K-means聚類中心
為了驗證基于Spark的K-means算法相對于一般的K-means算法,對大數據的挖掘效率更高。該方法使用單機并行K-means算法與基于Spark平臺的并行K-means算法進行比較,對3百、3千、3萬、30萬、300萬組9維數據進行測試,聚類個數都設為3,最終比較兩算法的運行時間,結果如圖3所示。
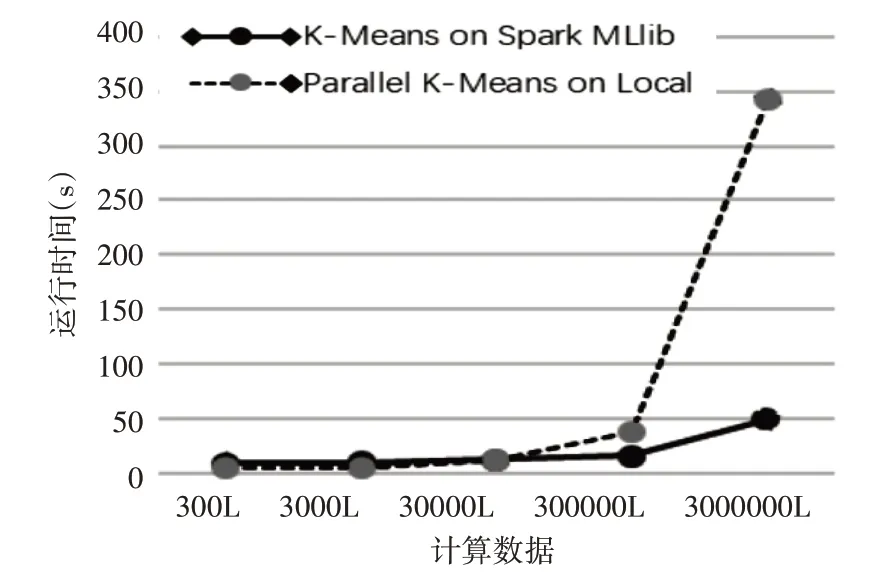
圖3 K-means運行時間對比結果
由圖3可以看出,最大迭代次數相同的情況下,在數據量不大的情況下,兩種算法的運行時間相差不大。當數據量小于3萬組9維數據時,由于Spark集群需要啟動和調用MLlib庫,消耗了一些時間,單機并行的K-means算法要比基于Spark平臺的K-means算法更快。但數據量上升到十萬以上,基于Spark的K-means算法運行速度明顯要優于單機并行的K-means算法,當數據量為300萬組9維數據時,基于Spark的K-means算法運行時間僅為單機的七分之一。由以上分析可知,基于Spark的K-means算法能夠高效地處理醫療設備運行大數據問題。
6 結語
本文提出了一種處理醫療設備運維信息的新方法,基于Spark的K-means聚類模型進行醫療設備運維信息預測分析。該方法結合Spark內存計算模型,解決了大數據的迭代計算問題。通過Spark平臺上并行K-means算法與單機狀態下的K-Means算法的比較,以及對醫療設備運維信息數據的算例分析和實驗,選擇K-means算法模型,并引入分布式存儲系統HDFS,解決了傳統方法難以有效處理醫療設備大數據的問題,滿足了預測系統處理大量數據的需求,在醫療運維方面具有十分重要的應用價值。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
當代工人(2020年13期)2020-09-27 23:04:20
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
電子制作(2018年10期)2018-08-04 03:24:48
家庭影院技術(2017年11期)2017-12-20 08:10:57
工業設計(2016年12期)2016-04-16 02:52:00
IT時代周刊(2015年8期)2015-11-11 05:50:37
汽車維修與保養(2015年1期)2015-04-17 03:25:28
設備管理與維修(2015年12期)2015-04-09 06:57:00
