面向復(fù)雜場(chǎng)景的精準(zhǔn)高效車輛重識(shí)別算法研究
2021-04-05 07:25:24金曉峰黃彥杰徐天適黃宇恒黃躍珍
現(xiàn)代信息科技 2021年17期
金曉峰 黃彥杰 徐天適 黃宇恒 黃躍珍
摘? 要:在視頻監(jiān)控場(chǎng)景中,由于車輛外觀的多樣性、車輛間的相似性以及應(yīng)用場(chǎng)景的復(fù)雜性,導(dǎo)致算法難以區(qū)分不同的車輛目標(biāo);同時(shí),實(shí)際應(yīng)用對(duì)車輛重識(shí)別算法的實(shí)時(shí)性也提出了要求。為兼顧精度和速度,進(jìn)行了以下工作:首先,構(gòu)建了一個(gè)場(chǎng)景復(fù)雜、含有近百萬張車輛圖片的數(shù)據(jù)集;其次,對(duì)車輛重識(shí)別算法的數(shù)據(jù)預(yù)處理、網(wǎng)絡(luò)結(jié)構(gòu)、后處理三個(gè)方面進(jìn)行詳細(xì)實(shí)驗(yàn);最后,對(duì)模型進(jìn)行蒸餾與量化,在保證模型精度的情況下提高模型速度。最終在自研測(cè)試集上的重識(shí)別精度達(dá)到了93.35% Rank1和76.30% mAP,推理速度達(dá)到了400.6 FPS,滿足了實(shí)際應(yīng)用需求。
關(guān)鍵詞:視頻監(jiān)控;車輛重識(shí)別;模型設(shè)計(jì)
中圖分類號(hào):TP391.4? ? 文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):2096-4706(2021)17-0095-05
Abstract: In the video surveillance scene, due to the diversity of vehicle appearance, the similarity between vehicles and the complexity of application scene, it is difficult for the algorithm to distinguish different vehicle targets; at the same time, the real-time performance of vehicle re-recognition algorithm is also required in practical application. In order to give consideration to accuracy and speed, the following work is carried out: firstly, a data set with complex scenes and nearly one million vehicle images is constructed; secondly, detailed experiments on data preprocessing, network structure and post-processing of vehicle re-recognition algorithm are carried out; finally, the model is distilled and quantified to improve the model speed while ensuring the accuracy of the model. Eventually, the re-recognition accuracy on the self-developed test set reaches 93.35% Rank1 and 76.30% mAP, and the reasoning speed reaches 400.6 FPS, which meets the needs of practical application.
Keywords: video surveillance; vehicle re-recognition; model design
0? 引? 言
車輛重識(shí)別技術(shù)是一種基于圖像的車輛檢索技術(shù),其旨在搜索到不同視頻監(jiān)控場(chǎng)景下的相同車輛。在交通監(jiān)管、刑偵追查等場(chǎng)景下,由于違法人員對(duì)車輛進(jìn)行篡改和遮擋,從而導(dǎo)致基于車牌信息的車輛識(shí)別方式失效;而基于車輛特征的車輛重識(shí)別技術(shù)能通過目標(biāo)車輛的整體和局部特征信息,有效地識(shí)別、檢索和追蹤目標(biāo)車輛。
傳統(tǒng)的車輛重識(shí)別方法基于手工構(gòu)建的特征,利用特征算子提取車輛外觀特征,而后進(jìn)行編碼來獲取用于描述該車輛的特征向量,如Liu等人[1]采用的SIFT-BOW法,在提取了車輛外觀的SIFT特征后,采用詞袋法(Bag of Words,BoW)[2]對(duì)SIFT[3]特征進(jìn)行編碼。此類方法的性能依賴于手工設(shè)計(jì)特征的可靠性及參數(shù)選擇的合理性,泛化能力差。
目前普遍采用深度卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network, CNN)[4,5]提取車輛特征用于車輛重識(shí)別[6]。Liu等人[1]將CNN提取的特征與傳統(tǒng)描述子的特征相融合;He等人[7]通過提取車輛局部特征,如車窗、車燈、年檢標(biāo)等,作為輔助判斷,獲取較基于全局特征方法更高的精度。但是,車輛局部區(qū)域特征的獲取一方面需要對(duì)數(shù)據(jù)集進(jìn)行額外標(biāo)注,增加訓(xùn)練成本;另一方面網(wǎng)絡(luò)需要包含檢測(cè)部件,導(dǎo)致推理時(shí)間變長(zhǎng)、算法的實(shí)時(shí)性能降低,無法滿足實(shí)際應(yīng)用需求。
為有效地訓(xùn)練和評(píng)估車輛重識(shí)別算法的性能,研究人員構(gòu)建了多個(gè)包含大量車輛圖像、身份及攝像頭信息的公開數(shù)據(jù)集,如VeRi[1,8]、VehicleID[9]、Veri-Wild[10]等;但由于采集地點(diǎn)、視頻錄制時(shí)長(zhǎng)等限制導(dǎo)致數(shù)據(jù)集欠缺豐富性,對(duì)現(xiàn)實(shí)場(chǎng)景擬合不佳。
后處理方法作為車輛重識(shí)別任務(wù)中重要的一環(huán),研究人員也進(jìn)行了大量的研究。如Zhong等[11]提出的K倒序重排方法被廣泛運(yùn)用,但其計(jì)算量較大。部分工作[12,13]使用車輛軌跡、車牌信息、攝像頭位置等信息進(jìn)行后處理,但是這類方法的局限性在于需要額外的輔助信息。平均查詢擴(kuò)展(Average Query Expansion, AQE)[14,15]也是圖像檢索領(lǐng)域常用的后處理手段之一。
針對(duì)上述問題,本文分別從車輛重識(shí)別的數(shù)據(jù)集構(gòu)建及處理、網(wǎng)絡(luò)結(jié)構(gòu)的構(gòu)建、網(wǎng)絡(luò)加速方法及后處理方法進(jìn)行了探索和改進(jìn):
數(shù)據(jù)集:對(duì)公開數(shù)據(jù)集和私有數(shù)據(jù)集進(jìn)行整合處理,構(gòu)建一個(gè)包含多種復(fù)雜場(chǎng)景,具有近百萬數(shù)據(jù)的大型數(shù)據(jù)集;
網(wǎng)絡(luò)結(jié)構(gòu):對(duì)多個(gè)主干網(wǎng)絡(luò)以及組件進(jìn)行對(duì)比實(shí)驗(yàn),最終采用ResNet-101-IBN-NL作為網(wǎng)絡(luò)結(jié)構(gòu);
加速方法:對(duì)模型蒸餾和模型量化方案進(jìn)行實(shí)驗(yàn),最終采用蒸餾后的ResNet 34-IBN作為網(wǎng)絡(luò)結(jié)構(gòu),并對(duì)其進(jìn)行FP16量化;
后處理方法:對(duì)多種后處理方案進(jìn)行對(duì)比實(shí)驗(yàn),最終采用AQE作為后處理方法。
實(shí)驗(yàn)結(jié)果表明,該車輛重識(shí)別方案在自研測(cè)試集上Rank1達(dá)到93.35%,mAP達(dá)到76.30%,推理速度達(dá)到400.6 FPS,滿足了實(shí)際應(yīng)用需求。
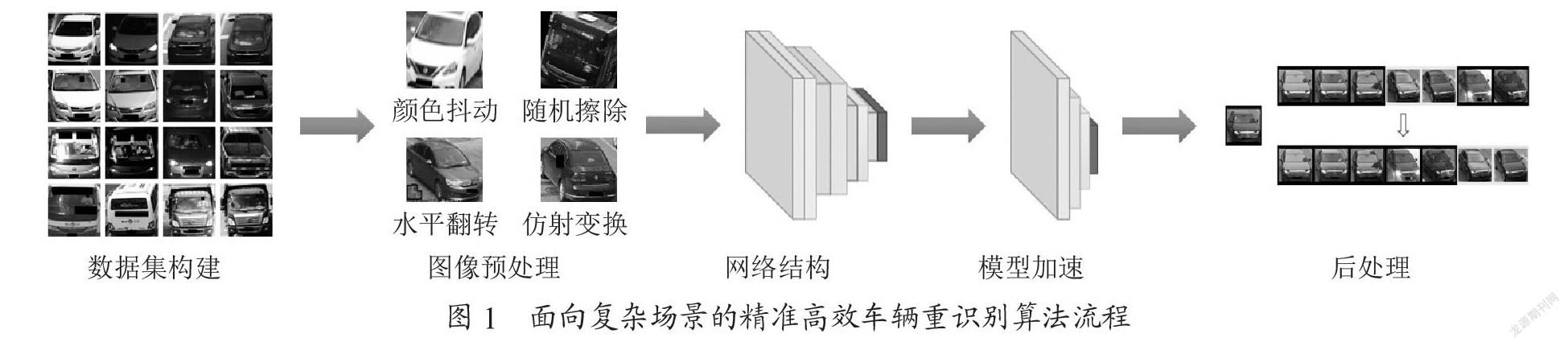
1? 算法流程
整體算法流程如圖1所示,包括五個(gè)模塊:數(shù)據(jù)集構(gòu)建、圖像預(yù)處理、網(wǎng)絡(luò)結(jié)構(gòu)、模型加速和后處理。
1.1? 數(shù)據(jù)集構(gòu)建
目前,車輛重識(shí)別領(lǐng)域的公開數(shù)據(jù)集[1,8-10]有的具有上萬ID、幾十萬的數(shù)據(jù)量,但由于采集環(huán)境通常是某一城市的固定區(qū)域,且時(shí)間跨度有限,導(dǎo)致天氣、光照、車型等方面的數(shù)據(jù)多樣性受到了限制。此外,在單一數(shù)據(jù)集上進(jìn)行訓(xùn)練易使網(wǎng)絡(luò)過擬合,在面對(duì)復(fù)雜的現(xiàn)實(shí)場(chǎng)景時(shí)表現(xiàn)不佳。
因此,為保證車輛重識(shí)別模型對(duì)現(xiàn)實(shí)場(chǎng)景的魯棒性,本文將部分車輛重識(shí)別數(shù)據(jù)集進(jìn)行抽取組合,并加入部分私有數(shù)據(jù)形成新數(shù)據(jù)集;為減輕長(zhǎng)尾效應(yīng)對(duì)網(wǎng)絡(luò)造成的影響,新數(shù)據(jù)集中剔除了含5張以下樣本的類別,對(duì)含100張樣本以上的頭部類別進(jìn)行隨機(jī)抽取,使得這些類別最終樣本數(shù)在50到100之間,最終的數(shù)據(jù)集包含44 390個(gè)類別,994 463張樣本。
1.2? 網(wǎng)絡(luò)結(jié)構(gòu)
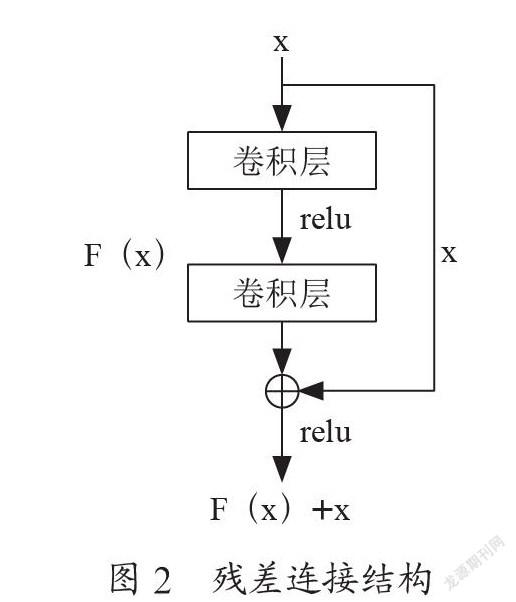
1.2.1? ResNet網(wǎng)絡(luò)
ResNet網(wǎng)絡(luò)是一種由He等人[16]提出的網(wǎng)絡(luò)結(jié)構(gòu),其創(chuàng)新性地提出殘差連接結(jié)構(gòu)(如圖2所示),使網(wǎng)絡(luò)淺層的信息得以更完整地傳送到深層,從而解決了先前的網(wǎng)絡(luò)結(jié)構(gòu)在深層時(shí)易發(fā)生梯度消失或梯度爆炸的缺陷。通過殘差連接結(jié)構(gòu),網(wǎng)絡(luò)可以達(dá)到較大的規(guī)模,從而能更好地?cái)M合復(fù)雜的現(xiàn)實(shí)場(chǎng)景。
1.2.2? 組件
IBN組件[17]在網(wǎng)絡(luò)中將實(shí)例歸一化(Instance Normalization, IN)和批歸一化(Batch Normalization, BN)結(jié)合,以提升網(wǎng)絡(luò)的跨域性能,降低識(shí)別的錯(cuò)誤率;SE(Squeeze Excitation)[18]組件采用可訓(xùn)練的權(quán)重系數(shù)以學(xué)習(xí)不同特征通道相對(duì)于任務(wù)的重要程度,增強(qiáng)有用特征并削弱對(duì)當(dāng)前任務(wù)用處不大的特征;Non-local[19]組件通過建立卷積核與圖像其他位置的關(guān)聯(lián)信息,從而達(dá)到擴(kuò)大卷積核感受野的效果。
本文采用ResNet網(wǎng)絡(luò)作為主干網(wǎng)絡(luò),并將其原有的BN層替換為IBN組件,同時(shí)加入注意力機(jī)制組件以提升網(wǎng)絡(luò)的識(shí)別性能。
1.3? 模型加速
在實(shí)際的應(yīng)用場(chǎng)景中,速度是一項(xiàng)重要的指標(biāo)。大模型的精度較小模型高,但是小模型在速度上更有優(yōu)勢(shì);知識(shí)蒸餾是一種讓小模型獲得接近大模型精度效果,同時(shí)保持其本身推理速度優(yōu)勢(shì)的方法。本文采用Hinton等[20]提出的方法,用大模型指導(dǎo)小模型,從而使小模型的預(yù)測(cè)方式向大模型靠攏。
模型的參數(shù)量化[21]是加速的另一種途徑。為了保證模型精度,訓(xùn)練通常采用32位浮點(diǎn)數(shù)(FP32)存儲(chǔ)模型參數(shù);在推理時(shí),為兼顧精度與速度,采用16位浮點(diǎn)數(shù)(FP16)或8位整型(INT8)存儲(chǔ)模型參數(shù),以求盡可能保留FP32的推理精度的同時(shí),達(dá)到減少計(jì)算量、提高運(yùn)算速度、節(jié)約運(yùn)算數(shù)據(jù)存儲(chǔ)空間的效果。
1.4? 后處理
在檢索階段,提取待查詢圖像目標(biāo)(query)和數(shù)據(jù)庫圖像(gallery)特征,將待查詢圖像目標(biāo)特征與所有數(shù)據(jù)庫圖像特征進(jìn)行比對(duì),確定查詢樣本的檢索結(jié)果,但此時(shí)并不是最優(yōu)排序,可通過后處理進(jìn)一步優(yōu)化特征檢索結(jié)果,目前常用的后處理方法有翻轉(zhuǎn)、K倒序重排[10]、平均查詢擴(kuò)展(Average Query Expansion, AQE)[16,17]等。翻轉(zhuǎn)指的是將原始query圖像特征及其翻轉(zhuǎn)圖像特征進(jìn)行加權(quán)作為最終的查詢特征進(jìn)行檢索;K倒序重排的方法通過求取query與其對(duì)應(yīng)的檢索結(jié)果的近鄰關(guān)系以優(yōu)化排序結(jié)果;AQE是一種在初次檢索排序后,取前K個(gè)檢索結(jié)果的特征與query特征進(jìn)行融合、再作檢索的方法。
2? 實(shí)驗(yàn)
實(shí)驗(yàn)采用上文中提到的自建數(shù)據(jù)集進(jìn)行訓(xùn)練和測(cè)試,抽取該數(shù)據(jù)集其中70%作為訓(xùn)練集,30%作為測(cè)試集,以探索該網(wǎng)絡(luò)對(duì)多域車輛圖像的重識(shí)別能力。
2.1? 配置說明
數(shù)據(jù)方面:圖片的尺寸被統(tǒng)一為256×256;數(shù)據(jù)增廣方面,Baseline默認(rèn)開啟隨機(jī)水平翻轉(zhuǎn)、隨機(jī)擦除[22]。圖像將采用ImageNet數(shù)據(jù)集[23]的均值和標(biāo)準(zhǔn)差進(jìn)行歸一化。
訓(xùn)練策略:采用4張V100-16 GB顯卡進(jìn)行訓(xùn)練,圖像大小為256×256,batch size設(shè)置為512。數(shù)據(jù)載入時(shí)用PK采樣器,設(shè)定每個(gè)ID抽取4張圖片。為加快模型收斂速度,優(yōu)化器選擇帶預(yù)熱的ADAM優(yōu)化器,初始學(xué)習(xí)率為2.5e-5,經(jīng)過5 000次迭代后達(dá)到基礎(chǔ)學(xué)習(xí)率2.5e-4;采用階梯下降的策略在第30、70、90個(gè)epoch將學(xué)習(xí)率衰減至前一個(gè)epoch的1/10,整個(gè)訓(xùn)練過程為120個(gè)epoch。損失函數(shù)選擇交叉熵和三元組損失。此外,所有的模型均采用ImageNet預(yù)訓(xùn)練權(quán)值。
測(cè)試環(huán)境:1×V100-16 GB顯卡,160 GB RAM。圖像大小為256×256,batch size為128。
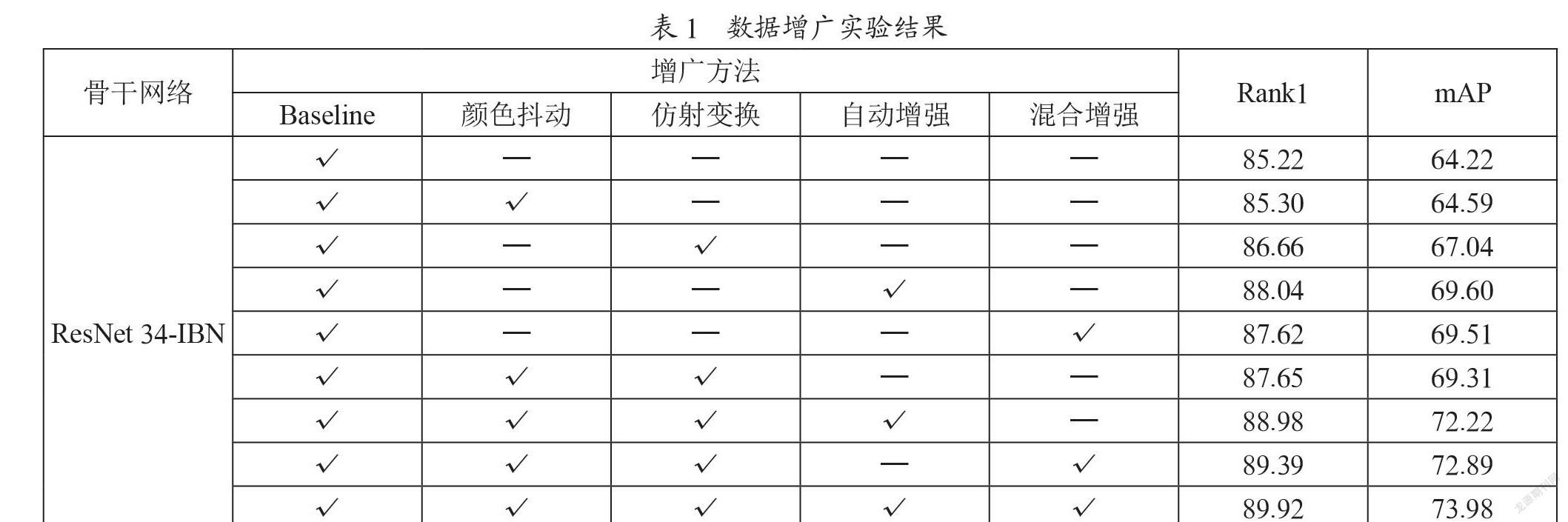
2.2? 數(shù)據(jù)增廣實(shí)驗(yàn)
在機(jī)器學(xué)習(xí)領(lǐng)域,有效的數(shù)據(jù)增廣可以提高模型對(duì)新數(shù)據(jù)的判別能力;而過度的數(shù)據(jù)增廣則可能使模型關(guān)注錯(cuò)誤的特征,損害模型的魯棒性,使輸出結(jié)果不可靠。為了加快實(shí)驗(yàn)速度,我們采用ResNet 34-IBN作為該實(shí)驗(yàn)的骨干網(wǎng)絡(luò)。在Baseline的基礎(chǔ)上,測(cè)試了隨機(jī)顏色抖動(dòng)、隨機(jī)仿射變換、自動(dòng)增強(qiáng)[24]、混合增強(qiáng)(Augmix)[25]四種增廣手段,實(shí)驗(yàn)結(jié)果如表1所示。實(shí)驗(yàn)表明,這四種方法均可提高模型在測(cè)試集上的準(zhǔn)確率。當(dāng)它們?nèi)勘皇褂脮r(shí),Rank1提升了4.7%,mAP提升了9.76%。
2.3? 網(wǎng)絡(luò)結(jié)構(gòu)實(shí)驗(yàn)
本文對(duì)主干網(wǎng)絡(luò)及增強(qiáng)組件的選取進(jìn)行實(shí)驗(yàn)。在主干網(wǎng)絡(luò)方面,采用ResNet 34-IBN、ResNet 50-IBN及ResNet 101-IBN進(jìn)行對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表2,ResNet101-IBN在兩項(xiàng)精度指標(biāo)上均優(yōu)于其他兩種網(wǎng)絡(luò)。在組件方面,對(duì)注意力組件SE[18]和Non-local(NL)[19]進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表3所示,Non-local組件在精度與速度兩項(xiàng)指標(biāo)上的綜合效果最優(yōu)。因此,本文采用ResNet101-IBN作為主干網(wǎng)絡(luò),并加入Non-local組件。
2.4? 后處理方法實(shí)驗(yàn)
本文對(duì)重排序(Rerank)[10]、翻轉(zhuǎn)(Flip)及平均查詢擴(kuò)展(Average Query Expansion, AQE)[16,17]三種方法進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表4所示。單獨(dú)使用重排序使Rank1下降1.55%,mAP提升5.04%;單獨(dú)使用AQE的Rank1提升0.42%,mAP提升5.69%;單獨(dú)使用翻轉(zhuǎn)的Rank1與mAP均有明顯下降;此外,實(shí)際應(yīng)用中,還需考慮后處理所需的時(shí)間。從表4也可看出,AQE所需時(shí)間遠(yuǎn)遠(yuǎn)低于重排序所用時(shí)間。因此,綜合考慮精度與速度,本文采用AQE作為后處理方法。
2.5? 模型加速
本文采用模型蒸餾與量化進(jìn)行模型加速。模型蒸餾方面,采用3.3小節(jié)的ResNet 101-IBN-NL作為教師網(wǎng)絡(luò),并選取ResNet 34-IBN作為學(xué)生網(wǎng)絡(luò),實(shí)驗(yàn)結(jié)果如表5所示。相較于直接訓(xùn)練的ResNet34-IBN模型,蒸餾后的學(xué)生網(wǎng)絡(luò)保持推理速度的同時(shí),Rank1與mAP分別提高3.54%與2.43%。量化方面,采用3.2小節(jié)中的ResNet 34-IBN進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果見表6。相較于FP32精度方案,F(xiàn)P16精度模型大小減少67%,顯存占用減少20%,推理速度提高1.49倍,且精度相當(dāng)。而INT8模型雖然在模型大小、顯存占用及推理速度上領(lǐng)先,但精度損失較多。因此,本文采用FP16量化方案。
2.6? 實(shí)驗(yàn)總結(jié)
綜上所述,本文采取的車輛重識(shí)別方案為:(1)數(shù)據(jù)預(yù)處理采用隨機(jī)翻轉(zhuǎn)、隨機(jī)擦除、隨機(jī)顏色抖動(dòng)、隨機(jī)仿射變換、自動(dòng)增強(qiáng)、混合增強(qiáng)的增廣組合;(2)模型采用經(jīng)ResNet 101-IBN-NL蒸餾后的ResNet 34-IBN網(wǎng)絡(luò),并對(duì)網(wǎng)絡(luò)進(jìn)行FP16模型量化;(3)后處理階段采用AQE方法進(jìn)一步改善排序結(jié)果。最終,該方案在自研測(cè)試集上的Rank1和mAP分別為93.35%和76.30%,推理速度為400.6 FPS。
3? 結(jié)? 論
針對(duì)車輛重識(shí)別算法在復(fù)雜現(xiàn)實(shí)場(chǎng)景中的精度與速度需求,本文首先通過構(gòu)建豐富的多域數(shù)據(jù)集,以盡可能涵蓋現(xiàn)實(shí)場(chǎng)景的情況;其次,本文通過詳盡的實(shí)驗(yàn)對(duì)數(shù)據(jù)的增廣方式、網(wǎng)絡(luò)結(jié)構(gòu)與組件、訓(xùn)練策略、后處理方法進(jìn)行了優(yōu)化選擇,提高模型在復(fù)雜數(shù)據(jù)上的表現(xiàn);最后,采用模型蒸餾和模型量化,使模型的速度得到了很大的提升,從而滿足了現(xiàn)實(shí)應(yīng)用的要求。在未來的研究中,我們會(huì)對(duì)數(shù)據(jù)集和模型結(jié)構(gòu)等方面進(jìn)行進(jìn)一步的探索,以期達(dá)到更好的效果。
參考文獻(xiàn):
[1] LIU X C,LIU W,MA H D,et al. Large-scale vehicle re-identification in urban surveillance videos [C]//2016 IEEE International Conference on Multimedia and Expo (ICME).Seattle:IEEE,2016:1-6.
[2] CSURKA G,DANCE C,F(xiàn)AN L,et al. Visual Categorization with Bags of Keypoints [C]//Workshop on statistical learning in computer vision,ECCV.2004:1-2.
[3] LOWE D G. Distinctive Image Features from Scale-Invariant Keypoints [J].International journal of computer vision,2004,60(2):91-110.
[4] LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-based learning applied to document recognition [J].Proceedings of the IEEE,1998,86(11):2278-2324.
[5] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. Imagenet Classification with Deep Convolutional Neural Networks [J].Communications of the ACM,2017,60(6):84-90.
[6] ZHENG Z D,RUAN T,WEI Y C,et al. VehicleNet:Learning Robust Visual Representation for Vehicle Re-Identification [J].IEEE Transactions on Multimedia,2020,23:2683-2693.
[7] HE B,LI J,ZHAO Y,et al. Part-Regularized Near-Duplicate Vehicle Re-Identification [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:3997-4005.
[8] LIU X,LIU W,MEI T,et al. Provid:Progressive and Multimodal Vehicle Reidentification for Large-scale Urban Surveillance [J].IEEE Transactions on Multimedia,2017,20(3):645-658.
[9] LIU H,TIAN Y,YANG Y,et al. Deep Relative Distance Learning:Tell the Difference Between Similar Vehicles [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Las Vegas:IEEE,2016:2167-2175.
[10] LOU Y,BAI Y,LIU J,et al. Veri-wild:A Large Dataset and a New Method for Vehicle Re-Identification in the Wild [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:3235-3243.
[11] ZHONG Z,ZHENG L,CAO D,et al. Re-Ranking Person Re-Identification With K-Reciprocal Encoding [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Honolulu:IEEE,2017:1318-1327.
[12] LUO H,CHEN W,XU X,et al. An Empirical Study of Vehicle Re-Identification on the AI City Challenge [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Nashville:IEEE,2021:4095-4102.
[13] ZHENG Z,JIANG M,WANG Z,et al. Going Beyond Real Data:A Robust Visual Representation for Vehicle Re-Identification [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.Seattle:IEEE,2020:598-599.
[14] BABENKO A,LEMPITSKY V. Aggregating Local Deep Features for Image Retrieval [C]//Proceedings of the IEEE international conference on computer vision. Santiago:IEEE,2015:1269-1277.
[15] KALANTIDIS Y,MELLINA C,OSINDERO S. Cross-Dimensional Weighting for Aggregated Deep Convolutional Features [C]//European conference on computer vision. Cham:Springer,2016:685-701.
[16] HE K,ZHANG X,REN S,et al. Deep Residual Learning for Image Recognition [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Las Vegas:IEEE,2016:770-778.
[17] PAN X,LUO P,SHI J,et al. Two at once:Enhancing Learning and Generalization Capacities via IBN-Net [C]//Proceedings of the European Conference on Computer Vision (ECCV).2018:464-479.
[18] HU J,SHEN L,SUN G. Squeeze-and-Excitation Networks [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Salt Lake City:IEEE,2018:7132-7141.
[19] WANG X,GIRSHICK R,GUPTA A,et al. Non-Local Neural Networks [C]//Proceedings of the IEEE conference on computer vision and pattern recognition. Salt Lake City,IEEE:2018:7794-7803.
[20] HINTON G,VINYALS O,DEAN J. Distilling the Knowledge in a Neural Network [J/OL].arXiv:1503.02531 [stat.ML].(2015-05-09).https://arxiv.org/abs/1503.02531.
[21] NVIDIA. NVIDIA TensorRT [EB/OL].[2021-07-25].https://developer.nvidia.com/zh-cn/tensorrt.
[22] ZHONG Z,ZHENG L,KANG G,et al. Random Erasing Data Augmentation [J/OL].arXiv:1708.04896 [cs.CV].(2017-08-16).https://arxiv.org/abs/1708.04896v2.
[23] DENG J,DONG W,SOCHER R,et al. Imagenet:A Large-Scale Hierarchical Image Database [C]//2009 IEEE Conference on Computer Vision and Pattern Recognition.Miami:IEEE,2009:248-255.
[24] CUBUK E D,ZOPH B,MANE D,et al. Autoaugment:Learning Augmentation Strategies from Data [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:113-123.
[25] HENDRYCKS D,MU N,CUBUK E D,et al. Augmix:A Simple Data Processing Method to Improve Robustness and Uncertainty [J].arXiv:1912.02781 [stat.ML].(2019-12-05).https://arxiv.org/abs/1912.02781.
作者簡(jiǎn)介:金曉峰(1985—),男,漢族,山東濰坊人,廣電運(yùn)通智能安全研究院副院長(zhǎng),高級(jí)工程師,博士研究生,研究方向:計(jì)算機(jī)視覺、視頻大數(shù)據(jù)。
