一種基于視頻的多目標追蹤與分割算法
2021-04-06 10:13:46蘇松源杜長青諸雅琴
計算機技術與發展 2021年3期
黃 濤,蘇松源,杜長青,諸雅琴,陳 勇
(1.國網江蘇省電力工程咨詢有限公司,江蘇 南京 210024;2.教育部網絡與信息集成重點實驗室(東南大學),江蘇 南京 210096;3.東南大學 網絡空間安全學院,江蘇 南京 210000)
0 引 言
在計算機視覺領域中多目標檢測和追蹤發展很快,在很大程度上,這些進步是由強大的深度學習驅動的,比如Fast/Faster RCNN[1]和MDNet[2]算法等用于目標檢測和目標追蹤,這些方法在概念上很直觀,并且具有靈活性以及快速的檢測時間。
實例分割在目前來說具有很大的挑戰性,因為它需要將圖像中的所有對象正確地檢測出來,對每個對象也需要精準的分割。因此需要結合計算機視覺中的對象檢測、目標分類、邊界框定位以及語義分割。基于以上要求,人們可能會認為需要復雜的方法才能獲得良好的結果。目前現有的目標追蹤算法只是將目標框起來進行追蹤。因此,該文介紹一種檢測精度更高的、靈活快速的模型,可以將視頻中的目標輪廓識別出來并進行追蹤。
該文介紹的為基于改進的Mask-RCNN[3]目標追蹤算法,是在Mask-RCNN[3]的基礎上進行了改進。由于Mask-RCNN[3]在每個感興趣的區域(RoI)上添加一個用于預測分割掩碼[4]的分支,與現有的用于分類和邊界盒回歸的分支并行,并且RoIAlign[5]在候選區域的每個單元中計算出四個坐標位置,然后用雙線性內插的方法[6]計算出這四個位置的值,最后進行最大池化操作。雖然提高了精度,但對一張圖片分割需要耗費很長時間,無法對視頻目標進行實時追蹤。
該文針對現有問題提出了如下兩點改進:
(1)在原有的Mask-RCNN[3]模型中加入光流分析法來加快對圖片中目標的識別,減少對圖片的分割運行時間。
(2)先加入直方圖差值的方法提取視頻中的關鍵幀,再將此放進改進后的Mask-RCNN模型進行目標追蹤,可以有效減少普通幀的干擾。
1 相關工作
目標追蹤領域自身的特性如下:復雜的實際應用環境,相似的背景環境,各種各樣的遮擋等外界因素以及追蹤的目標形態變化,大小變化各式各樣的旋轉以及運動速度變化等等。而且當目標跟蹤算法投入到實際應用時,會出現一個很重要的問題—實時性問題。過去幾十年以來,目標跟蹤的研究取得了長足的進展。從Meanshift[7]、Particle Filter[8]和Kalman Filter[9]等經典跟蹤方法,到基于統計學和積分的方法,再到近幾年出現的深度學習相關方法,使得目標追蹤領域越來越熱門。
目標跟蹤算法主要分為兩類:
生成式模型[10]:通過在線學習方式建立生成目標模型,然后根據目標模型來尋找對應的圖像區域,但這一類方法沒有考慮目標所在的背景區域信息,從而丟失了一部分信息,導致了此類算法的跟蹤效果不夠理想。。
判別式模型:將目標追蹤的問題分兩部分完成,首先將目標和背景信息提取出來放入到訓練器中進行訓練,從而將目標從圖像序列背景中分離出來,然后得到該目標所在當前幀的位置。
該文提出的基于改進的Mask-RCNN目標追蹤算法屬于判別式模型,在原有基礎上通過引入光流分析和直方圖提取關鍵幀的策略來達到實時追蹤的效果。
2 Mask-RCNN算法原理
Mask-RCNN[3]是由Faster-RCNN[2]改進而來的,在Faster-RCNN[2]對RoI Pooling做了改進并提出了RoI Align,這樣改進后不再進行取整操作,而是用雙線性插值來更精確地找到每個塊對應的特征。使得為每個RoI取得的特征能夠更好地對齊原圖上的RoI區域。與此同時,增添mask branch預測K個種類的mm二值掩膜輸出,引入預測K個輸出的機制,允許每個類都生成獨立的掩膜,避免類間競爭。這樣做解耦了掩膜和種類預測,提高了分割效果。
如圖1所示,Mask-RCNN[3]算法流程如下:

圖1 Mask-RCNN網絡結構
(1)輸入圖像;
(2)將整張圖片輸入CNN進行特征提取;
(3)用RPN生成推薦窗口(proposals),每張圖片對應N個窗口,然后在卷積神經網絡的最后一層卷積特征圖上對這N個窗口進行映射;
(4)特征提取完畢后,通過RoI Align池化層使得每個RoI生成的特征圖的尺寸大小一致;
(5)最后通過分類預測、邊界框預測和mask掩膜預測進行回歸生成對應的分割圖片。
2.1 ROI Align模型
ROI Align[5]很好地解決了之前算法池化操作中兩次量化造成的區域不匹配的問題。
由于預選框的位置通常是由模型回歸得到的,一般來講是浮點數,而池化后的特征圖要求尺寸固定。所以ROI Align進行了重新設計:
(1)遍歷每一個候選區域,保持浮點數邊界不做量化。
(2)將候選區域分割成mm個單元,每個單元的邊界也不做量化。
(3)先在每個單元中固定四個坐標位置,然后用雙線性內插的方法[6]計算出這四個位置的值,最后進行最大池化操作。
2.2 基于FCN網絡的mask特征
如圖2所示,ROI Align操作生成的ROI區域固定大小的特征圖,經過4個卷積操作后,生成14×14大小的特征圖;然后經過上采樣生成28×28大小的特征圖;最后通過卷積操作生成大小為28×28,深度為80的特征圖。上述過程為全卷積網絡,這樣可以保證mask分支的每一層都有mm大小的空間布局,不會缺少空間維度的向量。并且與全連接層預測mask相比,FCN需要更少的參數,可以得到更好的效果。

圖2 Mask網絡分支
3 算法改進
Mask-RCNN[3]算法雖然能識別目標輪廓,但對一張圖片分割需要耗費很長時間,無法對視頻目標進行實時追蹤。該文引入光流分析法對視頻中關鍵幀進行提取,可以有效減少分割時間,達到對目標的實時跟蹤。
3.1 光流分析法
光流分析法是利用時域中圖像序列里像素的變化以及相鄰幀之間的相關性來找到前一幀與當前幀之間的對應關系,從而計算出相鄰幀之間目標的運動信息的一種方法。
該文在Mask-RCNN[3]模型在相鄰幀提取出候選區域后加入LK光流法,在相應的區域中先進行特征點提取,有效減少背景特征,使后面的mask提取和邊界框預測時間大幅度縮短。
模型結構如圖3所示。

圖3 改進網絡結構
3.2 視頻關鍵幀提取
視頻幀[11]是視頻進行顯示的基本結構單元,關鍵幀是從視頻幀中提取出來的,是表述鏡頭的關鍵性圖像幀,又叫代表幀,其可減少視頻索引的工作量和數據量。由于視頻中有很多幀和需求無關,所以進行關鍵幀提取,將有用的幀篩選出來與分割模型相結合來提高檢測精度。
該文基于圖像信息[12]進行特征提取,采用直方圖差值算法來提取關鍵幀。通過把顏色特征作為主要特征,先將GRB顏色空間轉換為HSV,然后通過對H色調和S飽和度進行顏色識別來進行關鍵幀的提取。
常用的顏色特征表征有直方圖、顏色聚合量、顏色相關圖等,由于直方圖可以很直觀地得到每個像素的顏色比例分布,可以方便幀之間的對比,所以該文采用顏色直方圖進行描述,提取流程如圖4所示。
3.3 視頻多目標追蹤設計
該文采用視頻關鍵幀提取技術和改進后的Mask-RCNN算法進行實驗,通過對MOT16視頻集[13]輸入訓練,進行關鍵幀提取,根據每一幀圖片的大小及目標個數來學習對該圖片分割需要花費多長時間,訓練出分割模型后,對第一幀開始分割并同時預測出分割時間,緊接著跳到該時間之后的那一幀繼續進行分割并預測,來達到自適應多目標檢測與追蹤。
分割模型中時間損失率函數L計算為:

其中,T0表示對圖片的預測時間,T1表示圖片分割的實際時間,λ表示損失系數。

圖4 視頻幀提取流程
通過測試,使用多目標視頻幀分割可以在0.05 s左右分割一次,基本達到實時分割的效果。性能如表1所示。
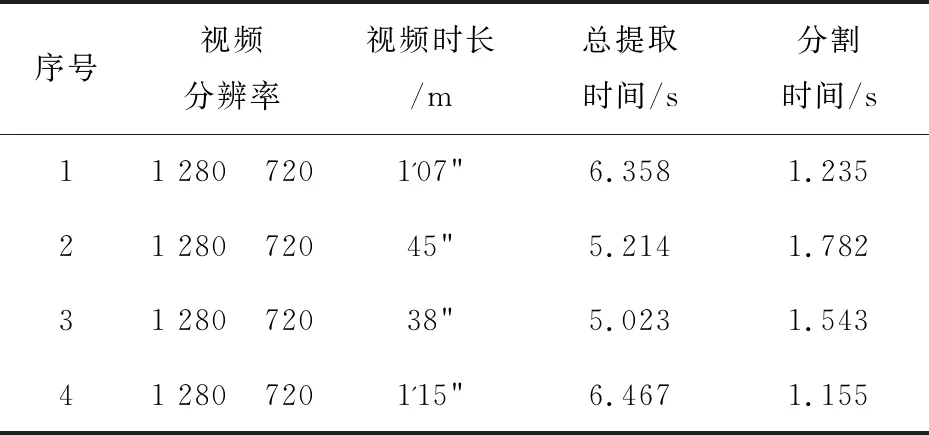
表1 算法性能測試
該表格中總提取時間為對整個視頻提取關鍵幀所用的時間,分割時間為一次實例分割所用的時間。
4 實 驗
文中使用的數據為MOT16視頻集[13]。通過MOT基準測試集[14]的測試序列來評估多目標跟蹤算法實現的性能。為了驗證改進的算法在多目標跟蹤上的精確性和實用性,選用了MOT16視頻集[13]進行實驗,并和普通Mask-RCNN[3]算法在目標跟蹤上的效果進行了對比,結果如表2所示。

表2 各算法性能對比
由表2可以看出,改進后的算法比普通的Mask-RCNN算法在時間上快了3倍左右,基本可以對實時目標進行追蹤。
同時文中還對現已存在的視頻多目標跟蹤算法進行對比,具體如表3所示。

表3 多目標跟蹤算法對比
由表3可知,改進的Mask-RCNN算法在MOTA[18]和MOTP上均高于其他已知的經典算法,FAF[19]和ML也有所下降,實現了在短時間的情況下對輪廓進行精準切割,這是Deep SORT[16]等追蹤算法所達不到的。圖5為截取的一段視頻,其中幾幀作為實例展示出來,是用M8手機拍攝的1 280×720像素的1'15"視頻,1 s提取關鍵幀為20,圖6顯示的是對該視頻中間15 s的預測時間和實際時間的差值。

圖5 目標追蹤與分割
由圖6可知,改進Mask-RCNN算法在15 s內對300幀進行了目標跟蹤,由于引進了光流分析和視頻關鍵幀提取,使得對每一幀的預測時間和實際處理時間為0.05 s左右,相差不超過0.01 s,相比普通Mask-RCNN[3]算法在實時性上有了大幅度提高。并由圖5可以看出,該算法在實時目標追蹤的同時,也對目標輪廓進行了精準分割,保證了目標檢測精度。

圖6 預測時間與實際時間對比
5 結束語
該文采用了一種簡單、靈活的對象實例分割框架,可以有效地檢測出圖像中的對象類別,并且在該模型的基礎上進行改進,通過引入光流分析法與視頻幀分割方法達到多目標追蹤的目的,并且與其他經典目標追蹤算法相比在保證實時性的同時多了精準的輪廓分割。通過輸入視頻流,來實時追蹤目標并且對其進行實例分割,基本可以用于實踐需要,且對于在實際應用中的多目標檢測具有一定的參考價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
