邊緣計(jì)算驅(qū)動(dòng)的對(duì)話機(jī)器人終端部署
2021-04-06 04:04:19馬壯楊威
軟件工程 2021年2期
馬壯 楊威
摘? 要:目前,大部分內(nèi)置對(duì)話功能的終端只是用戶文字語音傳輸?shù)摹爸修D(zhuǎn)站”,并不承擔(dān)計(jì)算功能。這導(dǎo)致用于計(jì)算的云服務(wù)需要承擔(dān)較高的網(wǎng)絡(luò)負(fù)載和計(jì)算負(fù)載。隨著硬件性能的不斷提升,終端設(shè)備也能運(yùn)行部分自然語言處理算法,分擔(dān)云服務(wù)的壓力。本文討論了使用邊緣計(jì)算技術(shù)實(shí)現(xiàn)對(duì)話機(jī)器人終端部署的可行性,并設(shè)計(jì)了基于云+邊緣協(xié)同計(jì)算的對(duì)話系統(tǒng)架構(gòu)。通過將部分對(duì)話機(jī)器人部署在終端,可以降低云服務(wù)的訪問頻率,從而降低網(wǎng)絡(luò)和計(jì)算負(fù)載。
關(guān)鍵詞:對(duì)話機(jī)器人;邊緣計(jì)算;深度學(xué)習(xí)模型部署
Abstract: At present, most information terminals with built-in dialogue function are only transit stations for users' text and voice transmission, and they do not undertake calculation functions. As a result, cloud services for computing have to carry high network load and computing load. With hardware improvement, terminal devices can also locally run some natural language processing algorithms to share pressure of cloud services. This paper discusses feasibility of using edge computing technology to realize deployment of chatbot terminals, and designs a dialogue system architecture based on cloud + edge collaborative computing. By deploying some chatbots on terminals, access to cloud services can be reduced, thereby lowering network and computing load.
Keywords: chatbot; edge computing; deep learning model deployment
1? ?引言(Introduction)
基于自然語言處理技術(shù)的對(duì)話機(jī)器人正在深刻地改變?nèi)藱C(jī)交互的模式。依托于文本相似度匹配、命名實(shí)體識(shí)別等自然語言處理算法,對(duì)話機(jī)器人能夠在一定的封閉域內(nèi)理解人類的語言,并給出符合常識(shí)的響應(yīng)。但受制于這些算法的高計(jì)算復(fù)雜度,對(duì)話機(jī)器人的算法部署大多采用云部署的方式,使用云端的高性能計(jì)算集群完成算法任務(wù)[1]。隨著用戶數(shù)量的增加,云端需要更大規(guī)模的計(jì)算集群來完成高并發(fā)的對(duì)話服務(wù)響應(yīng),這樣一來系統(tǒng)部署的成本就會(huì)顯著提升。
在硬件設(shè)備計(jì)算能力不斷高速提升的今天,許多終端設(shè)備(例如中高端手機(jī)和平板電腦)都配有高主頻多核心的中央處理器。如果使用邊緣計(jì)算技術(shù)充分調(diào)動(dòng)這些計(jì)算資源,終端設(shè)備便具備了實(shí)時(shí)語音視頻信號(hào)處理、深度學(xué)習(xí)算法前向推理的能力。在邊緣計(jì)算技術(shù)的支撐下,經(jīng)過優(yōu)化的終端設(shè)備就能夠獨(dú)立完成自然語言處理任務(wù),初步實(shí)現(xiàn)語義理解和高頻問題的應(yīng)答,分擔(dān)云服務(wù)器的部分計(jì)算壓力。云服務(wù)器可以將計(jì)算資源集中在低頻、高精度、依賴海量常識(shí)信息的用戶問題的應(yīng)答中。將對(duì)話機(jī)器人的云端部署與邊緣設(shè)備部署相結(jié)合,能夠充分發(fā)揮二者的優(yōu)勢(shì),在保證對(duì)話機(jī)器人能夠準(zhǔn)確回答用戶問題的前提下,盡可能地降低部署難度和部署成本。
本文將先介紹對(duì)話機(jī)器人部署和邊緣計(jì)算的研究基礎(chǔ);然后總結(jié)邊緣計(jì)算驅(qū)動(dòng)的對(duì)話機(jī)器人部署技術(shù),論證其可行性;最后提出基于云+邊緣協(xié)同計(jì)算的對(duì)話機(jī)器人部署架構(gòu)。
2? ?相關(guān)研究(Related study)
2.1? ?對(duì)話機(jī)器人部署相關(guān)研究
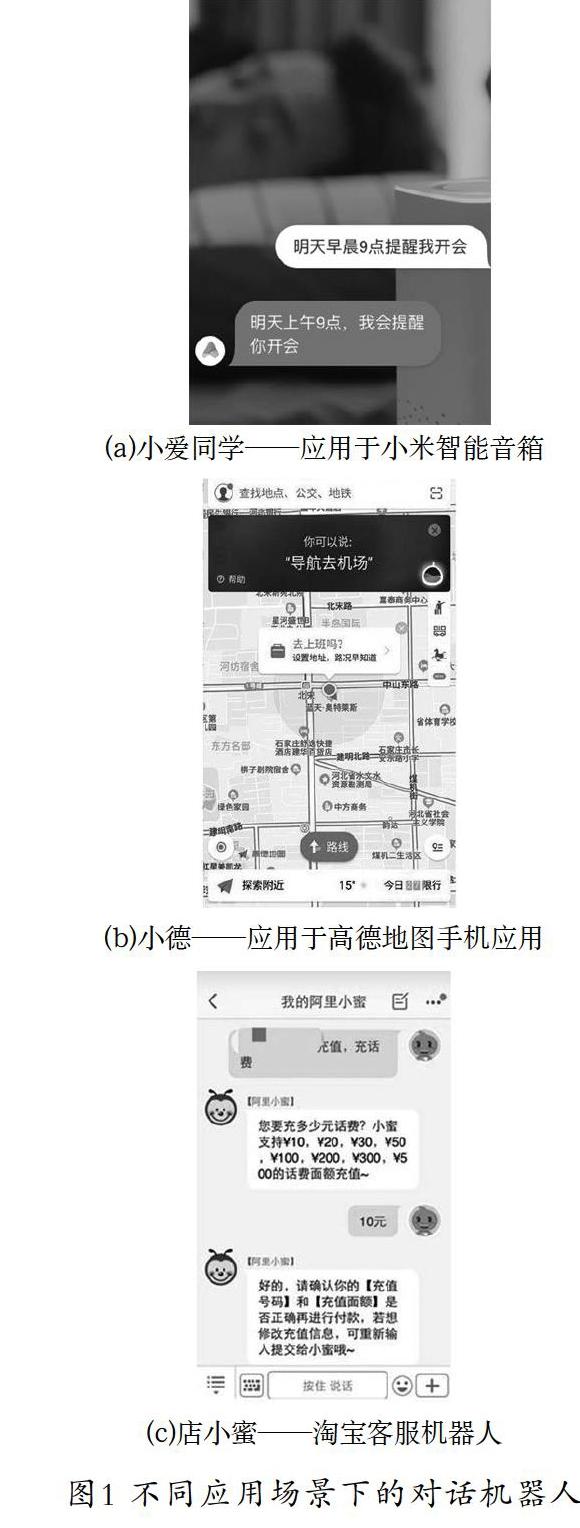
目前,已經(jīng)有很多對(duì)話機(jī)器人完成了部署并產(chǎn)品化,如圖1所示。小米的對(duì)話機(jī)器人小愛同學(xué)已經(jīng)融入小米產(chǎn)品生態(tài)體系中。用戶可以與搭載了小愛同學(xué)的小米智能音箱對(duì)話,從而控制35大品類的智能家居設(shè)備,例如電視、掃地機(jī)器人、智能插座等[2]。高德地圖的對(duì)話機(jī)器人小德主要面向?qū)Ш綀鼍埃ㄟ^語音交互,向用戶提供路徑導(dǎo)航、附近公共設(shè)施搜索等服務(wù)。阿里的店小蜜在簡單的配置之后就能夠智能回答用戶的高頻問題,大大降低了人工客服的工作量。
上述三款對(duì)話機(jī)器人分別以智能音箱、手機(jī)、網(wǎng)頁為載體,與用戶產(chǎn)生交互。當(dāng)用戶通過語音或鍵盤輸入與對(duì)話機(jī)器人溝通時(shí),終端會(huì)將用戶的語音、文本等原始數(shù)據(jù)上傳到云端,由云服務(wù)器完成語義分析并將回復(fù)返回終端,最后終端將回復(fù)結(jié)果呈現(xiàn)給用戶。在這個(gè)流程中,終端主要承擔(dān)著數(shù)據(jù)收發(fā)和用戶交互的任務(wù),而核心算法都在云端的服務(wù)器上進(jìn)行計(jì)算。
雖然算法的云服務(wù)部署具有擴(kuò)展性高、通用性強(qiáng)等優(yōu)點(diǎn),但是隨著用戶與對(duì)話機(jī)器人的交流頻率越來越高,云服務(wù)器的網(wǎng)絡(luò)負(fù)載和計(jì)算負(fù)載也會(huì)越來越高,這樣一來會(huì)顯著提高云服務(wù)的部署成本。
2.2? ?邊緣計(jì)算相關(guān)研究
邊緣計(jì)算指在靠近數(shù)據(jù)源頭的一側(cè)就近提供服務(wù)的技術(shù),已經(jīng)被廣泛應(yīng)用于自動(dòng)駕駛、工業(yè)物聯(lián)網(wǎng)、智慧城市等領(lǐng)域[3]。基于智能終端的邊緣計(jì)算設(shè)備能夠?qū)崟r(shí)分析傳感器采集的數(shù)據(jù),并產(chǎn)生快速響應(yīng),在滿足實(shí)時(shí)業(yè)務(wù)的同時(shí)還能夠保護(hù)用戶的隱私。
為了保證一系列復(fù)雜算法(例如深度學(xué)習(xí)算法)能夠順利地在邊緣設(shè)備上運(yùn)行,開發(fā)者通常會(huì)從硬件和軟件兩個(gè)層面進(jìn)行優(yōu)化。硬件加速是指使用專用的高性能計(jì)算單元代替中央處理器執(zhí)行復(fù)雜算法的技術(shù)。數(shù)字信號(hào)處理器(Digital Signal Processor,DSP)專用于數(shù)字信號(hào)處理任務(wù),圖形處理單元(Graphic Processing Unit,GPU)更擅長圖形渲染,神經(jīng)網(wǎng)絡(luò)推理計(jì)算可以使用神經(jīng)網(wǎng)絡(luò)處理單元(Neural Processing Unit,NPU)進(jìn)行加速。軟件加速是指在軟件層面上充分調(diào)動(dòng)已有的硬件資源提升計(jì)算效率的技術(shù),常見的軟件加速技術(shù)有異構(gòu)計(jì)算、內(nèi)存分配優(yōu)化、指令集優(yōu)化等。在固定的硬件條件下,使用最適合的軟件加速方案進(jìn)行調(diào)優(yōu),能夠最大程度地利用不同計(jì)算單元的特性,在邊緣設(shè)備上實(shí)現(xiàn)實(shí)時(shí)的數(shù)據(jù)采集、處理與分析。
但是,畢竟終端設(shè)備的計(jì)算能力無法與云服務(wù)器相比,而且目前最新的高精度的自然語言處理算法復(fù)雜度較高,因此使用邊緣計(jì)算技術(shù)部署對(duì)話機(jī)器人仍有諸多挑戰(zhàn)。
3? 邊緣計(jì)算驅(qū)動(dòng)的對(duì)話機(jī)器人部署技術(shù)研究現(xiàn)狀(Research status of edge computing-driven chatbot terminal deployment technology)
在對(duì)話機(jī)器人和用戶交互的過程中,算法需要解決諸如自然語言理解、文本相似度匹配等問題。目前,基于深度學(xué)習(xí)的預(yù)訓(xùn)練模型(BERT、GPT等)在這類問題上展現(xiàn)出很大的優(yōu)勢(shì)。但是因?yàn)檫@類模型需要先從海量文本中學(xué)習(xí)自然語言的多樣化表示,所以參數(shù)普遍很多(超過300M個(gè)浮點(diǎn)數(shù))[4]。針對(duì)這一任務(wù),我們需要解決硬件加速、軟件加速和模型輕量化三個(gè)問題。下面本文將從這三個(gè)角度介紹邊緣計(jì)算技術(shù)應(yīng)用于對(duì)話機(jī)器人部署場景的可行性。
3.1? ?硬件加速
由于目前驅(qū)動(dòng)對(duì)話機(jī)器人的自然語言處理算法大多基于深度學(xué)習(xí)方法,因此如果在智能終端的硬件選型過程中考慮集成能夠提升深度學(xué)習(xí)算法推理速度的計(jì)算單元,就能使智能終端具備對(duì)話機(jī)器人部署的可能性。常見的應(yīng)用于深度學(xué)習(xí)算法邊緣計(jì)算的高性能計(jì)算單元包括圖形處理單元(GPU)、神經(jīng)網(wǎng)絡(luò)處理單元(NPU)、可編程邏輯門陣列(FPGA)等。
GPU最早應(yīng)用于解決圖形渲染問題,它能夠調(diào)用計(jì)算能力不高但數(shù)量眾多的計(jì)算核心,并行地完成諸如3D坐標(biāo)變換等簡單計(jì)算操作,從而實(shí)現(xiàn)復(fù)雜三維物體的實(shí)時(shí)渲染。自2012年Alex提出了AlexNet并使用GPU加速了神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程之后,GPU被廣泛應(yīng)用于深度學(xué)習(xí)模型的訓(xùn)練和云端部署任務(wù)中。在邊緣計(jì)算場景下,手機(jī)等智能終端的系統(tǒng)級(jí)芯片(SoC)中都包含負(fù)責(zé)畫面渲染的GPU,這些GPU能夠輔助加速神經(jīng)網(wǎng)絡(luò)的前向推理。同時(shí),NVIDIA嘗試將高性能的GPU嵌入開發(fā)板中,推出了Jetson系列開發(fā)板。該系列產(chǎn)品在神經(jīng)網(wǎng)絡(luò)計(jì)算任務(wù)上的表現(xiàn)遠(yuǎn)超同價(jià)位的樹莓派開發(fā)板,為開發(fā)者硬件選型提供了新的選項(xiàng)。
NPU是專用于神經(jīng)網(wǎng)絡(luò)計(jì)算的計(jì)算單元,架構(gòu)設(shè)計(jì)上模仿了生物神經(jīng)網(wǎng)絡(luò),以“神經(jīng)元”為基本單位。在計(jì)算過程中,模型中每層神經(jīng)元的結(jié)果無須輸出到主內(nèi)存,直接按照網(wǎng)絡(luò)結(jié)構(gòu)傳遞給下層神經(jīng)元。這使NPU無須像CPU和GPU一樣頻繁訪問內(nèi)存,這樣不僅提升了整體計(jì)算速度,還能夠大大降低功耗。目前,高端手機(jī)的SoC芯片(華為麒麟990、三星Exynos980等)中都集成了專用于執(zhí)行深度學(xué)習(xí)算法的NPU。
FPGA是一種半定制電路,開發(fā)者可以使用硬件描述語言(Verilog、VHDL等)修改芯片中門電路和存儲(chǔ)器之間的連線,從而實(shí)現(xiàn)算法的部署。依托于硬件電路天然的并行特性,F(xiàn)PGA能夠擁有更快的計(jì)算速度、更高的帶寬,同時(shí)保持較低的功耗。但是,受制于硬件開發(fā)的復(fù)雜性,將算法部署在FPGA上需要更多的時(shí)間。2020年,百度推出了基于FPGA的開發(fā)板EdgeBoard,同時(shí)提供了Paddle-Mobile到FPGA的模型轉(zhuǎn)換工具。這一產(chǎn)品大大簡化了深度學(xué)習(xí)算法在FPGA上的部署過程,使在FPGA上快速迭代算法成為可能。
綜上,在對(duì)話機(jī)器人載體終端的硬件設(shè)計(jì)過程中,如果采用系統(tǒng)級(jí)芯片(SoC)解決方案,可以在芯片設(shè)計(jì)過程中為GPU和NPU模塊分配相應(yīng)的空間。如果采用板級(jí)解決方案,可以選用配有GPU模塊或FPGA模塊的開發(fā)板,然后基于開發(fā)板中的Linux/Android系統(tǒng)進(jìn)行軟件開發(fā)。兩種方案都能夠在硬件層面提升終端執(zhí)行深度學(xué)習(xí)算法的能力,從而輔助實(shí)現(xiàn)對(duì)話機(jī)器人的邊緣部署。
3.2? ?軟件加速
與云服務(wù)器不同,邊緣計(jì)算設(shè)備受功率和成本的限制,往往無法通過單純累加硬件的方式實(shí)現(xiàn)深度學(xué)習(xí)算法加速。因此,為了讓有限的硬件資源最大程度發(fā)揮出最高的性能,小米、阿里、騰訊等公司都研發(fā)了針對(duì)邊緣計(jì)算設(shè)備的深度學(xué)習(xí)算法前向推理框架。這些框架都包含以下軟件加速技術(shù):
異構(gòu)計(jì)算:當(dāng)智能終端在硬件層面集成了高性能計(jì)算單元之后,為了更好地調(diào)度不同的計(jì)算單元協(xié)同完成復(fù)雜的計(jì)算任務(wù),需要有一個(gè)跨平臺(tái)的通用軟件編程標(biāo)準(zhǔn)。2008年,蘋果公司提出了一個(gè)這樣的標(biāo)準(zhǔn),命名為OpenCL。此后,Intel、NVIDIA、AMD等公司硬件產(chǎn)品的驅(qū)動(dòng)程序中都陸續(xù)提供了OpenCL的API支持。前向推理框架可以使用OpenCL調(diào)度GPU等計(jì)算單元實(shí)現(xiàn)加速[5]。但在智能終端,尤其是Android平臺(tái)上,硬件設(shè)計(jì)沒有統(tǒng)一的標(biāo)準(zhǔn)。僅GPU一項(xiàng)就有高通的Adreno系列、ARM的Mali系列、Imagination的PowerVR系列、NVIDIA的Tegra系列,每個(gè)系列的硬件架構(gòu)和紋理壓縮格式不盡相同,這導(dǎo)致前向推理框架想要兼容所有設(shè)備是非常困難的。目前,騰訊TNN和阿里MNN都做到了Android平臺(tái)和iOS平臺(tái)的深度調(diào)優(yōu);小米mace僅支持高通、聯(lián)發(fā)科、松果等系列芯片的異構(gòu)計(jì)算,尚不支持iOS平臺(tái)。
算符級(jí)優(yōu)化:在深度學(xué)習(xí)模型訓(xùn)練過程中,為了提升神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搭建的靈活性,網(wǎng)絡(luò)都被劃分成粒度較小的基礎(chǔ)算符(例如,卷積、激活函數(shù)、矩陣乘法等)。由于每個(gè)算符計(jì)算完成之后都要將計(jì)算結(jié)果從低層內(nèi)存搬運(yùn)到高層內(nèi)存,因此會(huì)反復(fù)讀取內(nèi)存造成不必要的數(shù)據(jù)傳輸開銷。因此,前向推理框架往往會(huì)采用算符融合的方式,把一些常見的同時(shí)出現(xiàn)的算符(Conv+bn+ReLU)合并為一個(gè)粒度較大的算符,這樣能夠顯著提升推理速度。另外,對(duì)一些常用算符的實(shí)現(xiàn)方式進(jìn)行單獨(dú)優(yōu)化也是有效地加速方案。TNN等框架中都使用了Winograd等快速卷積方法替換傳統(tǒng)的卷積實(shí)現(xiàn)方式,雖然損失了一定的精度,但是計(jì)算速度能夠至少提升四倍[6]。此外,基于Strassen算法的矩陣乘法加速算法還能夠顯著提升全連接層運(yùn)算速度。
低精度優(yōu)化:目前絕大部分深度學(xué)習(xí)算法的權(quán)重?cái)?shù)據(jù)類型都是32-bit浮點(diǎn)數(shù)。但是大量研究表明,在模型計(jì)算尤其是模型前向推理的過程中,如此高的數(shù)據(jù)精度是不必要的[7]。如果將權(quán)重?cái)?shù)據(jù)量化到FP16(16-bit浮點(diǎn)數(shù))或INT8(8-bit整數(shù))形式,在一定調(diào)優(yōu)的前提下不僅能保證模型推理的準(zhǔn)確性,還能顯著提升計(jì)算效率并降低內(nèi)存帶寬。為了在硬件層面上加速低精度計(jì)算,ARM的GPU從Mali-G76起全面支持INT8計(jì)算指令,寒武紀(jì)等NPU廠商也都在芯片中集成了INT8壓縮方案。
此外,軟件加速還包括Neon向量化優(yōu)化、內(nèi)存優(yōu)化等方法,通過對(duì)處理器底層資源調(diào)度的優(yōu)化,能夠減少不必要的計(jì)算開銷。目前,深度學(xué)習(xí)前向推理框架仍處于快速發(fā)展階段,常規(guī)的框架并不能完美兼容所有硬件設(shè)備和計(jì)算算符。因此在對(duì)話機(jī)器人的邊緣部署過程中,需要綜合考慮目標(biāo)設(shè)備的硬件條件和待使用的網(wǎng)絡(luò)模型,選用兼容性最好的框架。
3.3? ?模型輕量化
目前,基于語言模型預(yù)訓(xùn)練的自然語言處理算法在諸多任務(wù)上表現(xiàn)出出色的準(zhǔn)確度,最具代表性的模型有BERT和GPT等。這些模型為了從海量文本中學(xué)習(xí)多樣化的自然語言表示,往往在設(shè)計(jì)過程中沒有考慮計(jì)算復(fù)雜度,模型參數(shù)數(shù)量往往是上億級(jí)別,這導(dǎo)致了此類模型幾乎無法直接部署到任何終端設(shè)備上。因此,如果想實(shí)現(xiàn)對(duì)話機(jī)器人的終端部署,在自然語言處理模型的設(shè)計(jì)上就要關(guān)注輕量化的問題。
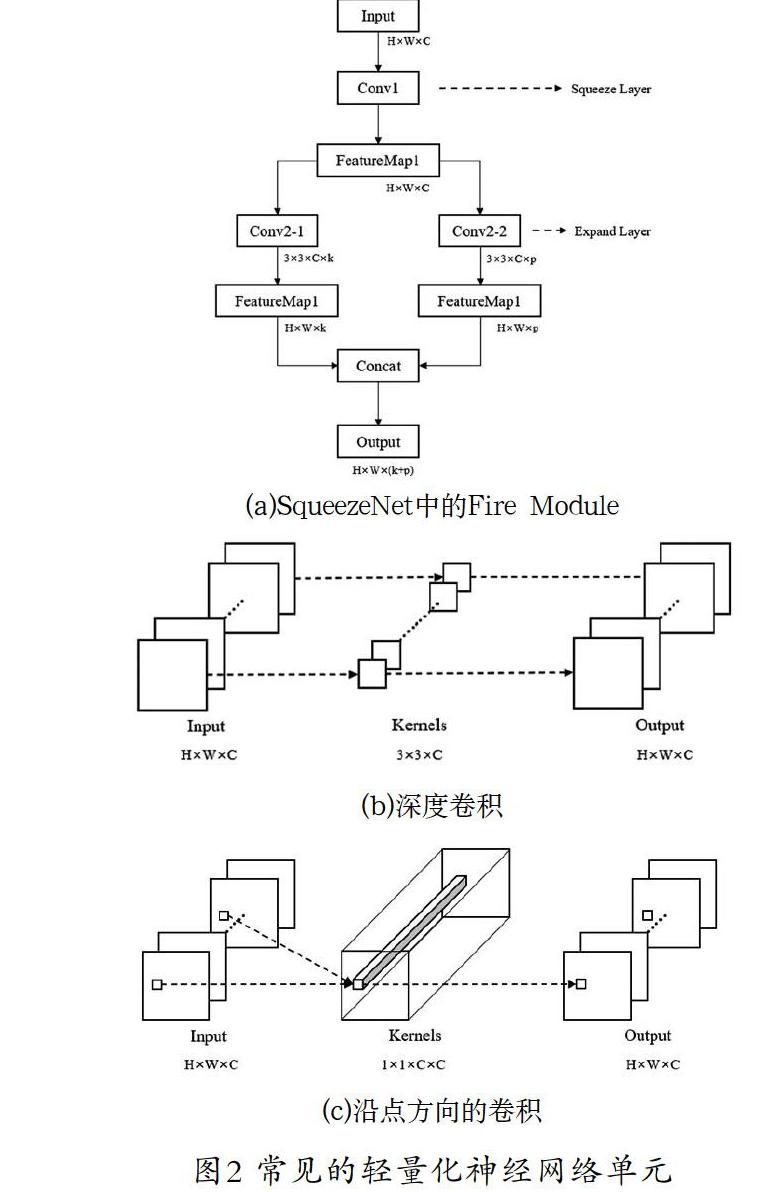
在神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)(Network Architecture Design,NAD)域,在保證模型特征提取能力的前提下減少模型的計(jì)算量是重要的研究方向之一。常見的輕量化神經(jīng)網(wǎng)絡(luò)單元如圖2所示。SqueezeNet[8]中設(shè)計(jì)了一種Fire Module結(jié)構(gòu),先使用1×1卷積將通道數(shù)降為輸入的一半,然后再分別用一個(gè)1×1和3×3的卷積核對(duì)得到的特征圖進(jìn)行卷積操作,最后將這兩層的結(jié)果整合之后輸出。用該結(jié)構(gòu)代替普通的3×3卷積核,不僅能夠提升網(wǎng)絡(luò)的特征提取能力,還能將參數(shù)量減少為原來的1/4。MobileNet[9]中使用Depth-wise Convolution和Point-wise Convolution替代普通的卷積核,前者對(duì)每個(gè)通道的特征圖僅采用一個(gè)3×3的卷積核進(jìn)行操作,整合單個(gè)通道特征圖的空間信息;后者使用1×1的卷積核,整合單個(gè)位置多個(gè)通道之間的信息,從而在實(shí)現(xiàn)傳統(tǒng)卷積功能的基礎(chǔ)上,減少參數(shù)量的效果。
當(dāng)模型設(shè)計(jì)和訓(xùn)練完成之后,通過分析每一層的參數(shù),研究者們發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)模型中有些層的參數(shù)對(duì)最終輸出結(jié)果的貢獻(xiàn)不大,所以可以使用剪枝算法刪除這些貢獻(xiàn)不大的參數(shù)或?qū)樱瑥亩@著減小模型的體積,提升模型計(jì)算速度。剪枝算法中首先會(huì)利用L1、L2正則化等方式評(píng)價(jià)神經(jīng)網(wǎng)絡(luò)權(quán)重參數(shù)的貢獻(xiàn)度,然后刪除貢獻(xiàn)度低的參數(shù)或?qū)印_@個(gè)過程會(huì)不可避免地帶來模型精度的損失,因此剪枝后的模型需要重新訓(xùn)練。在上述過程中,如果單次剪枝掉過多的參數(shù),會(huì)導(dǎo)致模型參數(shù)崩潰,需要通過重新訓(xùn)練恢復(fù)精度。因此通常情況下的剪枝操作是迭代進(jìn)行的,即單次剪枝掉少量參數(shù),重新訓(xùn)練之后再次評(píng)估參數(shù)貢獻(xiàn)度,而后繼續(xù)進(jìn)行剪枝,直至模型參數(shù)減少到目標(biāo)值。針對(duì)自然語言處理中常用的BERT模型,Michel等人[10]提出可以將模型中的多頭注意力模塊剪枝為單頭注意力模塊,McCarley等人[11]進(jìn)一步通過剪枝操作將BERT前饋?zhàn)訉拥膶挾葴p小。以上方法都能實(shí)現(xiàn)模型的輕量化。
不同于剪枝算法迭代地降低模型參數(shù),知識(shí)蒸餾方法先直接設(shè)計(jì)一個(gè)目標(biāo)小模型,以該小模型為“學(xué)生”,以預(yù)訓(xùn)練的大模型為“教師”,構(gòu)建Teacher-Student架構(gòu)。通過使用數(shù)據(jù)真實(shí)標(biāo)簽(Hard Target)和教師模型的輸出(Soft Target)構(gòu)建損失函數(shù)以訓(xùn)練學(xué)生模型,能夠使學(xué)生模型獲得教師模型所學(xué)習(xí)到的“知識(shí)”,由此訓(xùn)練出的輕量化模型的性能顯著優(yōu)于直接使用數(shù)據(jù)真實(shí)標(biāo)簽訓(xùn)練得到的模型。在Tiny BERT[12]模型的訓(xùn)練過程中,研究者將預(yù)訓(xùn)練BERT模型的Embedding層、隱藏層和輸出層分別蒸餾到小模型中,在保證模型在多項(xiàng)自然語言處理任務(wù)中表現(xiàn)穩(wěn)定的前提下,推理速度提升了9.4倍。
在實(shí)際應(yīng)用中,神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)、剪枝和知識(shí)蒸餾三種方法通常被聯(lián)合應(yīng)用于模型輕量化任務(wù)。為了構(gòu)建ALBERT[13]模型,研究者首先應(yīng)用神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)技巧搭建了輕量化的ALBERT模型,然后使用知識(shí)蒸餾方法將預(yù)訓(xùn)練的IB-BERT中的知識(shí)遷移到輕量化模型中,最后使用參數(shù)剪枝操作降低模型參數(shù)數(shù)量。輕量化的自然語言處理模型能夠從根本上降低邊緣計(jì)算設(shè)備的計(jì)算壓力,從而保證對(duì)話機(jī)器人能夠成功部署在智能終端上。
4? 基于云+邊緣協(xié)同計(jì)算的對(duì)話系統(tǒng)架構(gòu)(Chatbot system architecture based on cloud + edge collaborative computing)
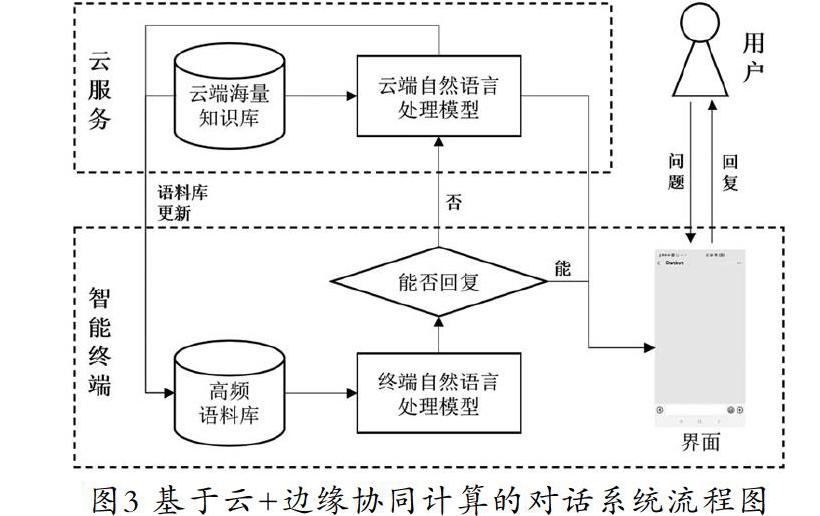
雖然邊緣計(jì)算驅(qū)動(dòng)的對(duì)話機(jī)器人部署技術(shù)已經(jīng)較為成熟,但邊緣設(shè)備的計(jì)算和存儲(chǔ)能力依然無法和云端的服務(wù)器相比。在面對(duì)海量知識(shí)庫檢索等復(fù)雜對(duì)話任務(wù)時(shí),云計(jì)算仍然有著無可替代的地位。因此本文結(jié)合邊緣設(shè)備和云端設(shè)備的性能特點(diǎn)及對(duì)話機(jī)器人系統(tǒng)的業(yè)務(wù)特殊性,提出了一種云+邊緣協(xié)同計(jì)算的對(duì)話系統(tǒng)架構(gòu)。
在對(duì)話機(jī)器人的業(yè)務(wù)層面,可以將其業(yè)務(wù)分成封閉域問答和開放域問答兩部分。封閉域問答是指對(duì)話機(jī)器人回復(fù)產(chǎn)品相關(guān)問題的功能,比如小愛同學(xué)會(huì)介紹小米相關(guān)產(chǎn)品的常見問題和進(jìn)行新品推薦,淘寶客服機(jī)器人可以回答關(guān)于產(chǎn)品規(guī)格、發(fā)貨時(shí)間和特價(jià)信息等問題。因?yàn)榉忾]域問答面向的應(yīng)用場景較為單一,場景中涉及的高頻對(duì)話語料是有限,所以語義解析和信息檢索的難度相對(duì)較低,可以由智能終端直接生成回復(fù)。開放域問答的范圍相對(duì)寬泛,與業(yè)務(wù)內(nèi)容沒有強(qiáng)關(guān)聯(lián)的部分都可以定義為開放域問答。由于用戶與對(duì)話機(jī)器人討論的話題可能橫跨多個(gè)領(lǐng)域,因此這意味著支持開放域問答的對(duì)話機(jī)器人背后需要有龐大的知識(shí)庫作為支撐。如果想實(shí)現(xiàn)海量知識(shí)庫中的知識(shí)檢索和事實(shí)檢索,就必然要使用云服務(wù)器的計(jì)算資源。因此在解決開放域問題時(shí),智能終端只負(fù)責(zé)完成最開始部分的語義解析和文本分類任務(wù),后續(xù)的回復(fù)生成交由云服務(wù)器完成。
綜上,在云+邊緣協(xié)同計(jì)算的對(duì)話系統(tǒng)架構(gòu)(圖3)下,用戶輸入問題后,智能終端會(huì)使用文本分類算法確認(rèn)問題的類型(封閉域、開放域),然后使用語義解析算法提取問題中的關(guān)鍵信息。如果問題為封閉域問題,則由終端在本地知識(shí)庫中檢索答案并回復(fù)給用戶;若問題無法解答或?yàn)殚_放域問題,則由終端上傳到云服務(wù)器,由云服務(wù)器在大規(guī)模知識(shí)庫下進(jìn)行答案的檢索。
此外,云端可以統(tǒng)計(jì)不同問題的交互頻次,基于此動(dòng)態(tài)更新保存在終端的高頻對(duì)話語料庫,保證終端能夠盡可能地解答用戶的高頻問題,分擔(dān)云端的計(jì)算壓力。同時(shí),終端可以利用空閑時(shí)間使用本地?cái)?shù)據(jù)訓(xùn)練模型并發(fā)送給云服務(wù)器,云服務(wù)器借由安全多方學(xué)習(xí)等方法聚合來自多個(gè)終端的更新參數(shù),獲得新的精度更高的語義解析模型,并返回每個(gè)終端。數(shù)據(jù)和模型的更新提供了對(duì)話機(jī)器人持續(xù)成長的可能性。
5? ?結(jié)論(Conclusion)
本文從硬件、軟件和算法三個(gè)層面論述了邊緣計(jì)算技術(shù)應(yīng)用于對(duì)話機(jī)器人部署任務(wù)的可行性。使用專用于深度學(xué)習(xí)模型推理的框架,驅(qū)動(dòng)硬件架構(gòu)中的GPU、NPU等高性能計(jì)算單元,執(zhí)行經(jīng)過輕量化設(shè)計(jì)的自然語言處理模型,使智能終端也能夠完成自然語言處理任務(wù),從而實(shí)現(xiàn)對(duì)話機(jī)器人的終端部署。
基于現(xiàn)有邊緣計(jì)算技術(shù)和對(duì)話業(yè)務(wù),本文提出了一個(gè)云+邊緣協(xié)同計(jì)算的對(duì)話系統(tǒng)架構(gòu)。在該框架下,部署在邊緣設(shè)備上的對(duì)話機(jī)器人能夠自主回答一定封閉域下的高頻問題,部署在云端的對(duì)話機(jī)器人則負(fù)責(zé)回答終端無法回復(fù)的復(fù)雜問題。通過這種方式,邊緣設(shè)備的計(jì)算資源能夠得到充分的利用,云計(jì)算平臺(tái)的網(wǎng)絡(luò)負(fù)載和計(jì)算負(fù)載也會(huì)顯著降低。
參考文獻(xiàn)(References)
[1] 姚永剛.基于云計(jì)算的人機(jī)對(duì)話系統(tǒng)研究與實(shí)現(xiàn)[D].廣州:華南理工大學(xué),2013.
[2] 王浩暢,李斌.聊天機(jī)器人系統(tǒng)研究進(jìn)展[J].計(jì)算機(jī)應(yīng)用與軟件,2018,35(12):1-6;89.
[3] 丁春濤,曹建農(nóng),楊磊,等.邊緣計(jì)算綜述:應(yīng)用、現(xiàn)狀及挑戰(zhàn)[J].中興通訊技術(shù),2019,25(03):1-7.
[4] 李舟軍,范宇,吳賢杰.面向自然語言處理的預(yù)訓(xùn)練技術(shù)研究綜述[J].計(jì)算機(jī)科學(xué),2020,47(03):170-181.
[5] 王湘新,時(shí)洋,文梅.CNN卷積計(jì)算在移動(dòng)GPU上的加速研究[J].計(jì)算機(jī)工程與科學(xué),2018,40(01):34-39.
[6] Lavin A, Gray S. Fast algorithms for convolutional neural networks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016:4013-4021.
[7] 尹文楓,梁玲燕,彭慧民,等.卷積神經(jīng)網(wǎng)絡(luò)壓縮與加速技術(shù)研究進(jìn)展[J].計(jì)算機(jī)系統(tǒng)應(yīng)用,2020,29(09):16-25.
[8] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size[DB/OL]. [2016-12-04]. https://arxiv.org/pdf/1602.07360.pdf.
[9] Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition,2018: 4510-4520.
[10] Michel P, Levy O, Neubig G. Are sixteen heads really better than one?[C]. Advances in Neural Information Processing Systems, 2019:14014-14024.
[11] McCarley J S. Pruning a bert-based question answering model[DB/OL]. [2019-10-14]. https://arxiv.org/pdf/1910.06360.pdf.
[12] Jiao X, Yin Y, Shang L, et al. Tinybert: Distilling bert for natural language understanding[DB/OL]. [2019-09-24]. https://arxiv.org/pdf/1909.10351.pdf.
[13] Lan Z, Chen M, Goodman S, et al. Albert: A lite bert for self-supervised learning of language representations[DB/OL]. [2019-09-30]. https://arxiv.org/pdf/1909.11942.pdf.
作者簡介:
馬? ?壯(1994-),男,碩士,初級(jí)研究員.研究領(lǐng)域:深度學(xué)習(xí),神經(jīng)網(wǎng)絡(luò)部署.
楊? ? 威(1968-),男,本科,工程師.研究領(lǐng)域:云計(jì)算,軟件架構(gòu)設(shè)計(jì).
