基于機器視覺的路面裂縫病害多目標識別研究
2021-04-07 07:58:30章世祥張漢成李西芝
公路交通科技 2021年3期
章世祥,張漢成,李西芝,胡 靖
(1. 華設設計集團,江蘇 南京 210014;2. 東南大學 土木工程學院,江蘇 南京 211189;3. 東南大學 計算機科學與工程學院,江蘇 南京 211189;4. 東南大學 智能運輸系統研究中心,江蘇 南京 211189)
0 引言
裂縫是路面結構的主要病害類型,尤其是半剛性基層結構引起的反射裂縫對道路設施的正常運營造成極大隱患,裂縫若得不到及時維養將發展為坑槽病害,對行車安全性極其不利。有效的裂縫檢測技術對維持路面服役水平、保障車輛行駛安全至關重要,傳統的路面病害檢測主要依靠人工巡檢方式,其存在效率低、主觀性強且成本較高等缺陷,隨著圖像處理技術的不斷發展,基于病害圖像的識別與分析為路面裂縫檢測提供了高效方法,但其識別精度依賴于病害圖像質量。因此,研究提出了一種基于機器視覺的路面裂縫識別技術,為路面結構的病害評估提供基礎。
傳統的圖像識別技術主要通過圖像灰度值等特征定義病害區域,如大津法OTSU、邊緣檢測與區域生長算法等[1-3],對于具有簡單背景且灰度差異較大的病害圖像具有較好的識別效果,但復雜背景下識別錯誤率較高。對于路面裂縫病害的識別,分割算法相對而言具有較好的正確率,但其處理速度較慢[4]。利用圖像紋理并考慮亮度和連通性來識別裂縫,或采用動態閾值方法均只能獲得較為粗糙的裂縫形態[5]。此外,基于Canny邊緣檢測的裂縫識別也較易出現誤識別情況,可見傳統圖像識別技術普遍問題在于準確度低,誤報率高,無法對病害進行像素級的識別,需要手動提取特征,且預處理的方法直接影響到識別效果等[6-7]。對于深度學習框架而言,卷積神經網絡(CNN)被認為對復雜背景下病害的識別具有極大的優勢。AlexNet模型證明了CNN 網絡能夠提升圖像分類的效果,隨后GoogleNet、 VGG與ResNet等均表明了CNN網絡在圖像識別中的有效性[8-9]。近年來,基于深度學習的圖像識別技術逐漸用于工程結構的病害檢測,Zhang等提出了基于深度卷積神經網絡的道路裂縫檢測系統,使用了整流線性單元(ReLU)作為激活函數,提高模型在訓練時收斂的速度[10]。Xu等在全卷積神經網絡(FCN)的基礎上建立了FCNN模型,其語義分割效果較好但訓練時間相對較長[11]。Jiang等采用無人機實時獲取裂縫圖像并進行識別,同時可以獲取裂縫的寬度值[12]。Maeda等建立了一個大型路面病害數據庫,并基于MobileNet等輕量級模型對裂縫進行識別,實現了對病害的快速推理,但是犧牲了部分的準確度[13]。Ni等將GoogLeNet和ResNet20組合用于識別裂縫,取得了良好的效果。但是對于尺寸較小的裂縫識別效果不佳,并且識別速度較慢[14]。Cha等使用滑動窗口基于CNN辨識裂縫,但無法確定最佳滑動窗口大小,且處理速度較慢[15],而采用Fast R-CNN模型識別裂縫有效提高了速度,但是無法輸出裂縫的掩碼,同時也無法統計出裂縫的大小[16]。綜上所述,基于深度學習模型對于病害的檢測問題主要還是集中在圖像分類,或者按圖像塊進行分類,最終為圖像產生塊檢測結果,而不是針對病害像素產生檢測結果,更進一步的研究也只停留在語義分割的層次上。部分研究實現了對于像素級的分類,然而并不能實現實例分割,當在一個圖像中出現多個同種病害時,無法將其區分識別[17]。此外,部分基于深度學習的模型推理速度過慢,難以在工程中實現高效應用。
本研究提出一種基于深度卷積神經網絡的自動化道路病害的檢測模型,基于Mask R-CNN框架[18],用以實現對路面的裂縫進行實例分割的目的。相對于以往的自動化病害檢測模型相比,該模型實現對裂縫的實例分割,可對裂縫病害開展有效的識別、檢測、定位與多裂縫目標分割。同時,擴展的主干網絡有效提高了模型的識別性能與精度,具備像素級別的識別效應,減少模型對于路面切割縫的誤識別,增強模型的魯棒性。
1 多語義機器視覺識別模型
1.1 基于Mask R-CNN的識別模型框架
卷積神經網絡(CNN)常用于實現目標物檢測、語義分割與定位[19],由于其具備較好的識別精度,因此在隧道等工程結構的病害研究中得到了一定應用,而在CNN基礎上發展得到的R-CNN與Faster R-CNN顯著地提升了檢測效率[20]。研究引入Mask R-CNN開展路面裂縫病害的識別,并且實現病害體的實例分割。Mask R-CNN在Faster R-CNN的基礎上,增加了第3個支路以輸出每個目標物的Mask。同時,為了建立深層卷積神經網絡以解決訓練時梯度消失的問題,采用ResNet-50和ResNet-101兩個模型作為主干網絡提取圖片的特征[21],其網絡結構如表1所示。
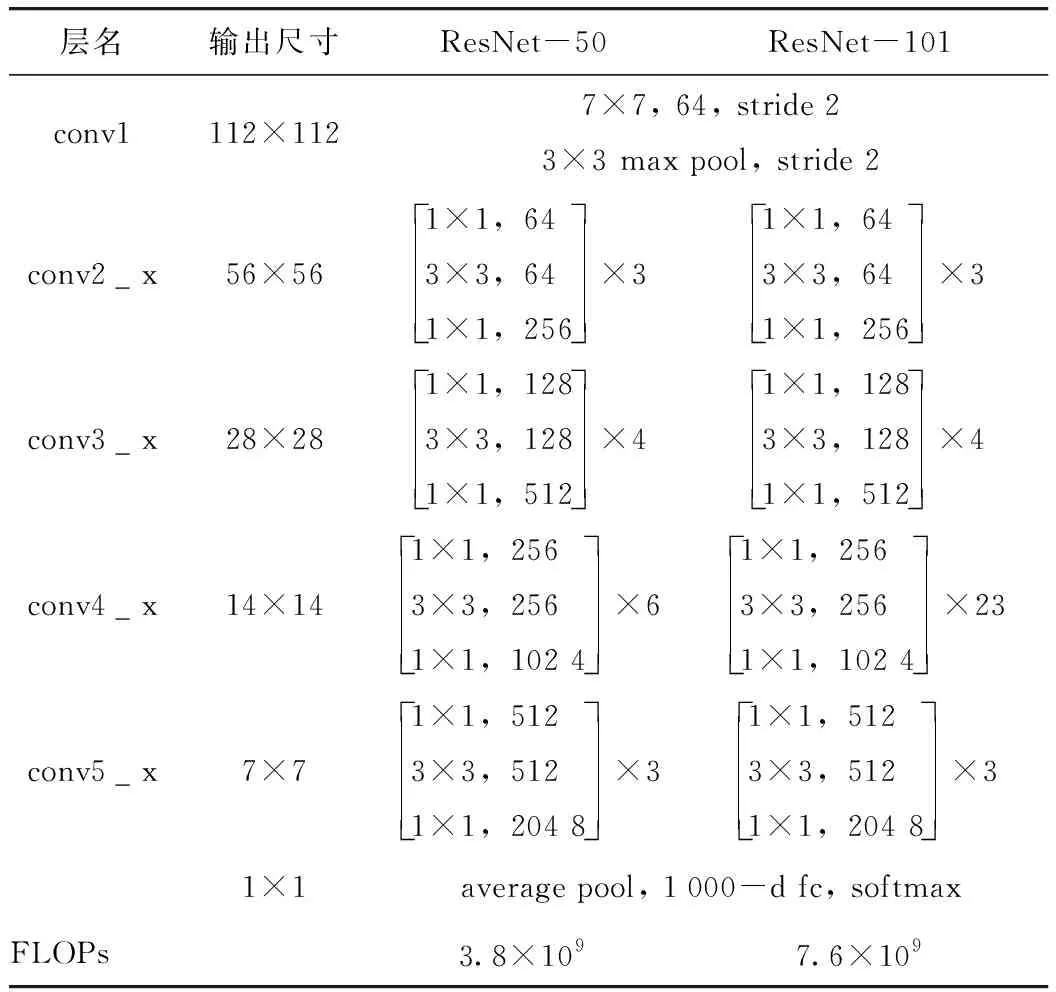
表1 ResNet-50與ResNet-101模型結構Tab.1 Structure of ResNet-50 and ResNet-101 models
裂縫病害具有較大的長寬比,其像素面積相對背景而言較小且不同裂縫尺寸存在差異。因此,需要在卷積神經網絡中盡可能地利用深層網絡與淺層網絡數據信息,分別提取用于裂縫病害檢測與分類的語義、幾何特征。研究選用Feature Pyramid Networks(FPN)提取各層次維度的裂縫特征,為了提高模型的性能,構建了多尺度的特征圖,如圖1所示。采用多尺度特征融合的方式,將主干網絡每個stage的特征圖輸出,深層特征通過上采樣和低層特征融合,且每層特征均為獨立預測。
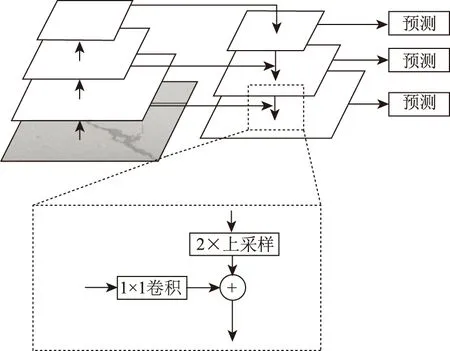
圖1 特征金字塔網絡模型Fig.1 Feature pyramid network (FPN)
本研究所建立的識別模型框架如圖2所示。模型結構分為兩部分,第1部分的主干網絡由ResNet-50、ResNet-101的FPN層組合而成,主干網絡的主要作用是提取圖片的特征。第2部分的網絡處理輸入的特征圖并生成候選區域,即有可能包含一個目標的區域,再分類候選區域并生成邊界框和掩碼,從而實現采用相同的識別模型對不同路面裂縫的像素級識別與實例分割。
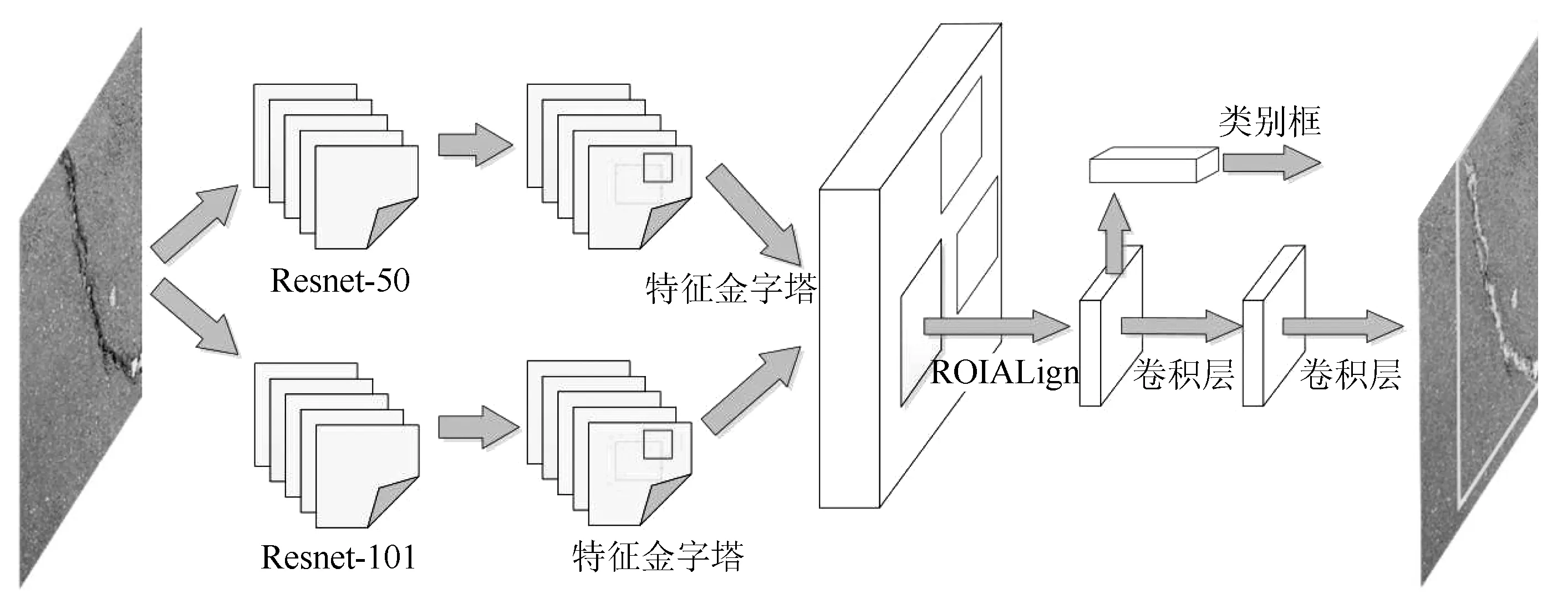
圖2 提出的識別模型結構Fig.2 Proposed structure of identification model
已有研究成果表明,增加網絡的深度或寬度不會降低網絡性能,因為可以在當前網絡上增加卷積層而不改變特征圖的尺寸,得到的新模型應具有更強的特征提取能力[21]。這表明較深的模型所產生的誤差不應該比較淺的模型高[22]。為了進一步提高模型的性能,將ResNet-50、ResNet-101兩個主干網絡的FPN層按層次分別疊加在一起,通過將輸出的特征圖直接相加以此來增加FPN層每一層的語義信息和幾何信息。如表2所示,ResNet-50和ResNet-101輸出的特征圖大小的尺寸是一致的,因此不需要進行額外的升采樣或降采樣等處理。

表2 性能評價指標Tab.2 Performance indicators
1.2 模型損失函數優化
裂縫病害的長寬比值較大,其在圖像中的像素數遠小于背景像素。因此,若采用Mask R-CNN框架的經典損傷函數將導致裂縫像素誤識別為背景像素。本研究構建新的損傷函數以提高裂縫的識別正確率,病害圖像通過識別模型后計算出預測值,該預測值與真實值間的差距可采用函數進行量化:
Loss=LossCls+LossBox+LossMask,
(1)
式中,LossCls為病害類型分類誤差;LossBox為病害位置誤差;LossMask為掩模真實值誤差。
其中LossMask可由以下公式進行計算:
LossMask=-∑[λ·W·yi·lnσ(xi)+(1-yi)·
lnσ(1-xi)],
(2)
式中,λ為權重系數,其值越大表明對分類錯誤的裂縫像素懲罰值越大;W為背景像素數與裂縫像素數的比值;yi為第i個像素的真實值;xi為第i個像素的預測值;σ為Sigmoid函數。
研究所建立的模型采用隨機梯度下降算法(SGD)進行訓練[23],每次從訓練集中隨機選取一個樣本進行學習以加快訓練效率,同時采用沖量算法Momentum加速損失函數的收斂性[24]。對于隨機采的m組數據,可計算其平均損失梯度為:
(3)
式中,f(x;w)為學習器;wi-1為第i-1次訓練時的參數,模型訓練更新速度與計算參數更新值分別為:
vi=βvi-1-αΔw,
(4)
wi=wi-1-vi,
(5)
式中,β為動量參數;vi-1為第i-1次訓練時的更新速度;α為學習率。
1.3 識別模型訓練
為了解決數據集的缺乏導致的模型泛化能力不強、模型訓練時間過長、函數無法收斂等問題,研究采用了基于遷移學習的模型訓練方案[25],采用在ImageNet數據庫中預先訓練的ResNet-50,ResNet-101模型,將基礎網格模型與特征圖金字塔網絡FPN層凍結,只訓練剩余的部分以確保模型具備較好的訓練速度與準確率。此外,為避免與裂縫類似的干擾影響,將明顯的干裂圖像作為困難樣本(Hard Example)加入到訓練集中對模型進行訓練,這樣可以提高模型對于裂縫識別的準確度,減少對于切割縫等干擾物的誤識別。
本研究對裂縫病害的識別可劃分為如圖3所示的4項內容,圖3(a)為病害分類,即判斷圖像中是否存在裂縫病害,屬于二分類問題;圖3(b)為位置檢測,判斷裂縫在圖像中的位置并用Box選中;圖3(c)為語義分割,將圖像中裂縫病害進行像素級分割;圖3(d)為實例分割,將同一張圖片中的多個裂縫進行像素級的分割。

圖3 裂縫識別步驟Fig.3 Steps of crack identification
訓練集輸入的圖像數據分辨率為768×1 024,batchsize設置為2,學習率為0.001。為了使損失函數更好收斂,使用學習率指數衰減讓學習率隨著學習進度降低以達到更好的訓練目的。識別模型的構建使用pytorch 1.3.1版本在ubuntu18.04上部署了建模環境,并使用i9-9900k和RTX2080ti來進行模型的訓練和測試。
2 路面裂縫病害訓練數據標注與參數學習
為了訓練與測試識別模型,收集了不同分辨率的路面裂縫圖像1 290張,其中橫向與縱向裂縫1 128 張、網狀裂縫162張。隨機選取1 144張圖像作為訓練集,選取146張圖像作為測試集,訓練集中水泥路面與瀝青路面裂縫病害圖像分別為778張與366張。為便于計算,壓縮不同路面裂縫圖像至統一分辨率768×1 024。為了獲取圖片像素級的標注,先對原圖進行灰度化和二值化預處理,并且調整灰度閾值及去除多余的噪點,典型病害標記如圖4所示。

圖4 識別模型訓練集標注Fig.4 Labeling training set of identification model

圖5 不同損失函數的對比Fig.5 Comparison different loss functions
將病害圖像按照9∶1分為訓練集與測試集,并采用翻轉、對稱與隨機調整亮度、對比度實現訓練集數據增強并擴充4倍,以實現訓練模型具備更好的泛化能力與魯棒性[26]。
識別模型的性能采用PIXACC,PIXAP,PIXREC,IOU開展像素級別評估,并使用COCO數據集中的評價指標AP50,AP75對模型實例分割的能力進行詳細的性能評估[27]。此外,識別模型在輸出裂縫Mask的同時還會輸出包含裂縫Box,因此使用AP和REC來評價模型的裂縫檢測能力。
如前所述,裂縫像素和背景像素的數量存在顯著的不平衡,如果使用Mask R-CNN框架的傳統損失函數計算方法,在訓練中為了降低Loss值,模型會更傾向于將更多的裂縫像素分類為背景像素。為緩解正負樣本數量上的失衡問題,研究在訓練LossMask時使用平衡二值化交叉熵(Balanced binary cross entropy)計算mask分支上的Loss數值。
圖5對比了平衡二值化交叉熵與傳統方法在裂縫識別中的區別,可見前者具有較為顯著的識別優勢,不會影響模型對于裂縫的目標檢測。平衡二值化交叉熵方法的應用效果受權重參數λ的影響較為顯著,有必要對最優權重參數的取值開展對比分析。
圖6說明了權重參數λ變化對性能評價指標的影響,由圖6(a)可知,隨著權重參數λ的增加,不同性能評價指標變化趨勢有所區別:PIXACC,PIXAP與IOU均隨著權重參數λ的增加而逐漸減少,其中PIXACC對權重參數λ的變化并不敏感;PIXREC的變化呈現相反趨勢,即隨著權重參數λ的增加而逐漸增大。通過試算可知,一定范圍內權重參數λ越大,識別模型中對于裂縫像素的錯誤分類懲罰值越大,則識別模型更偏向于將像素分類為裂縫像素,此時PIXREC越大且PIXAP越小。識別模型需要達到有效識別裂縫的目的,因此PIXREC與PIXAP需要取得平衡,即在確保較高PIXREC的前提下盡可能提高PIXAP數值。圖6(b)為不同權重參數λ下PIXAP與PIXREC的變化情況,可見當權重參數λ取得0.3時符合要求。
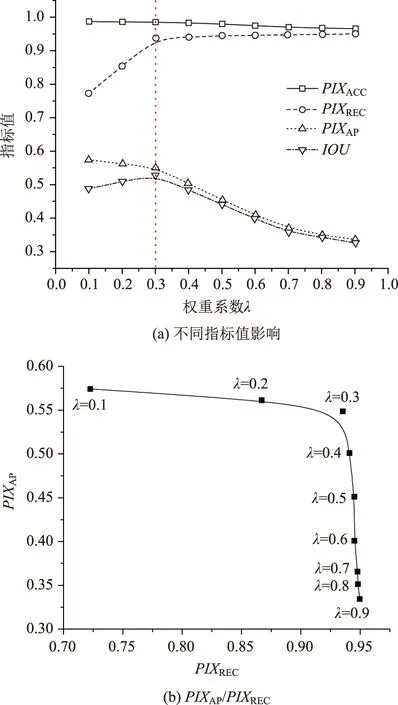
圖6 權重參數λ取值影響Fig.6 Influence of weight parameter λ value
3 研究成果討論
3.1 識別效果分析
本研究所建立的識別模型共迭代30 000次,迭代次數每滿1 000次將會評估識別模型對于驗證集的驗證效果,識別模型的損失函數隨迭代次數的變化如圖7(a)所示,為進一步對比不同主干網絡的損失函數變化規律,將不同的主干網絡訓練結果進行對比,如圖7(b)所示。
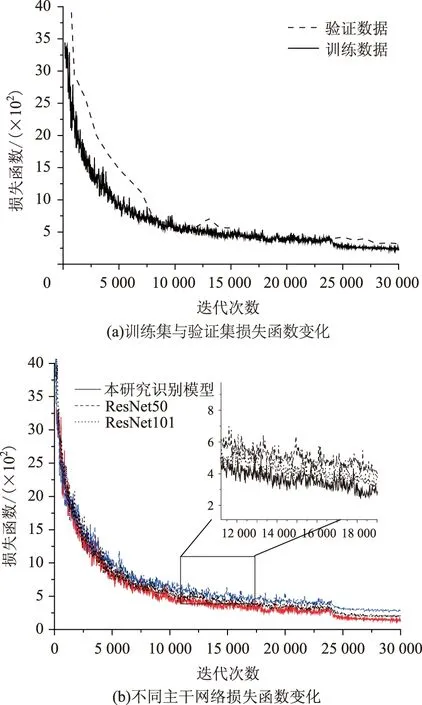
圖7 識別模型損失函數變化規律Fig.7 Change rule of loss function of identification model
訓練與驗證結果均表明了所建立識別模型具備有效的泛化性能,訓練過程中未發生過擬合現象,訓練后的模型能夠精確地識別路面裂縫病害。由圖7(a)可知,損失函數隨著迭代次數的增加在逐漸減小,表明其識別精度逐漸提高。在迭代次數小于10 000 時,其減小速率較大,隨后趨于平緩。圖7(b)顯示了不同主干網絡中損失函數的變化規律,可見其變化趨勢相似,在相同迭代次數下,所建立的識別模型的損失函數更小,具備更好的識別精度。本研究所用測試集共146張圖片,包含162條裂縫,識別模型成功識別160條裂縫,成功識別出93.6%的裂縫像素,同時正確分類了98.9%的裂縫病害。裂縫數據集區別于其他傳統的實例分割的數據集,標注時難以精確區分裂縫的界限,因此數據集中存在因標注產生的誤差像素。
如圖8所示,所建立的模型實際上可以較好地實現裂縫識別,然而裂縫輪廓細節相對難以精確描述,存在著大量的孔隙且人工標注會漏掉部分裂縫的細節。所以,PIXAP,IOU,AP50,AP75在裂縫識別中會因為訓練集圖像本身難以精準標注的問題受到影響。

圖8 典型病害圖像識別效果Fig.8 Result of typical diseases image recognition
以測試集數據為基礎,表3列出了本研究識別模型與主干網絡為ResNet-50、ResNet-101的Mask R-CNN模型以及全卷積神經網絡FCN模型的性能指標對比,可見優化后模型框架與損失函數具備相對較好的綜合指標,滿足復雜背景下路面裂縫病害的識別與提取。
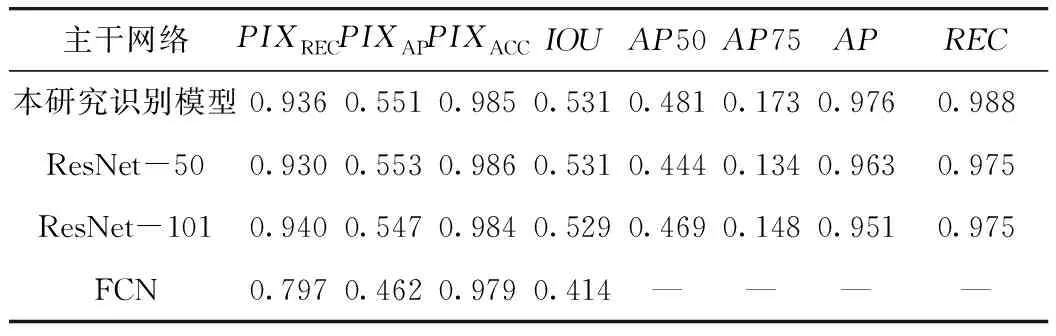
表3 識別模型的性能指標Tab.3 Performance indicators of recognition model
3.2 識別效果對比
由前述分析可知,識別模型由于擴充了主干網絡,其在裂縫識別的性能指標得到了優化,針對裂縫檢測與識別的指標AP與REC有所提高。為了與常用的語義分割模型開展對比,本研究選用以VGG-Net為主干網絡的FCN模型以相同的病害數據開展訓練,并在測試集中進行驗證[28],同時也列出了常見的自適應閾值與Canny邊緣檢測算法識別效果,如圖9所示。
由圖9可以看出,識別模型在裂縫識別的問題中表現相對較好,通過合并ResNet-50和ResNet-101增加主干網絡寬度可以在一定程度上進一步提高模型的性能。如圖9(a)與圖9(b)所示,所建立的識別模型能較好地識別裂縫形貌,并且對于同一張圖片中的多條裂縫與細微裂縫均可實現有效識別與實例分割,針對非裂縫病害的路面接縫等結構也能達到有效過濾的目的。此外,對于復雜的網狀裂縫也具備一定的識別能力。作為對比,全卷積神經網絡FCN的識別效果如圖9(c)所示,其對微小裂縫的細節描述能力較弱,且由于模型結構設計的不同導致其只有語義分割的功能,在識別網狀裂縫方面效果較差。圖像閾值化是從灰度圖像中分離目標區域和背景區域的基本方法,然而僅僅通過設定固定閾值很難達到理想的分割效果。自適應閾值通過計算像素的局部平均強度確定其應該具有的閾值,進而保證圖像中各個像素的閾值會隨著周圍鄰域塊的變化而變化。自適應閾值在識別瀝青路面的裂縫時效果不佳,主要是由于瀝青路面顏色、紋理、光影的變化過于劇烈,易將其他低灰度值物體識別為裂縫,如圖9(d)所示。Canny邊緣檢測是基于估計高斯平滑圖像每個像素的梯度作為邊緣強度的指標,可見其識別效果也無法滿足要求,且與自適應閾值類似,均不能實現非裂縫構造的辨識,如圖9(e)所示。
本研究所建立的識別模型通過組合ResNet-50與ResNet-101的FPN層來獲得更好的特征提取能力。對于傳統的卷積神經網絡,網絡層次越深,特征圖的尺寸越小,其在輸入圖的映射范圍越大,因此針對圖像中細小裂縫所處位置的描述能力會下降。

圖9 裂縫病害識別效果對比Fig.9 Comparison of crack disease identification results

圖10 FPN層的特征圖Fig.10 Feature images of FPN layers
圖10所示為識別模型中不同FPN層的病害圖像特征狀況,可見低層的病害特征圖主要表現為背景、裂縫的紋理、輪廓等細節信息,如圖10(a)所示;隨著分析層次的逐漸增加,特征圖的響應逐漸變得抽象,輪廓等細節信息逐漸缺失,如圖10(b)~圖10(d)所示。然而,高層特征圖通過與低層特征圖進行疊加,依然保留了裂縫的幾何信息,提升了識別模型檢測尺寸不同裂縫的能力。本研究所建立的識別算法對橫向、縱向與網狀裂縫均具有較好的識別效果,并且達到每秒處理20張病害圖像數據,有效實現對病害圖像或視頻數據的高效處理。
4 結論
本研究針對路面結構常見的裂縫類病害,基于Mask R-CNN框架擴展并優化了識別模型,實現了裂縫病害的圖像分類、位置檢測、語義分割與實例分割,通過與其他傳統與深度學習識別算法的成果對比,得到如下結論:
(1)基于深度學習的識別模型能夠開展病害圖像的語義分割,并對同一張圖像中的不同裂縫進行了實例分割,提高了識別模型的可擴展性。
(2)通過合并ResNet-50與ResNet-101的FPN層可以顯著提高主干網絡提取病害圖像特征的性能,本研究模型對裂縫病害類型的辨識正確率達到98.9%,并可精確識別93.6%的裂縫類像素。
(3)利用平衡二值化交叉熵計算函數數值,并對裂縫像素的錯誤分類設置更高的懲罰值,可有效緩解裂縫像素和背景像素數量上失衡導致的召回率下降。
(4)識別模型訓練過程中引入遷移學習框架,提高了模型訓練的收斂性,極大減少了訓練時間成本,實現用較少的數據集訓練得到較為精確的識別模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
