電力大數據關鍵技術在電力傳輸預測與規劃中的應用
2021-04-08 05:01:48王鵬飛何麗娟宋鴻雁
東北電力技術 2021年2期
王鵬飛,何麗娟 ,宋鴻雁
(國網銀川供電公司,寧夏 銀川 750000)
對大數據及其相關技術的研究最早可追溯至Apache軟件基金會的一個開源項目,該項目中大數據技術被用于處理一個互聯網搜索引擎中產生的巨大數據集。大數據技術有三個“大”特性:大數據量,大數據種類和大傳輸速率[1-2]。自21世紀以來,大數據逐漸被應用于電力系統,智能電網也應運而生,在近十幾年的發展中,逐漸凸顯出了以下趨勢:分布式發電的普及、可再生能源的高度普及、終端用戶的積極參與和雙向通信技術[3]。在大數據的參與下,現代智能電網正在演變成一個復雜的物理網絡系統,電力公司部署的大量計量/傳感設備也提供了足夠多的數據來支撐大數據算法的運行。
常用于電氣系統的數據采集系統有SCADA、WAMS、Smart meter、Power quality recorder等。這些數據采集系統各有優劣,種類繁多,包括溫度、濕度、電壓、載荷、風速、日照等多種數據,幾乎涵蓋了電力系統的方方面面。除了表現出多數據種類外,這些系統也體現了大數據多數據量的特點,以一區域型電網為例,SCADA系統1年內最高可記錄7億個包括總線電壓、輸入輸出功率、頻率、斷路狀態等在內的數據[4]。
目前大數據技術在電力系統中的應用仍處于早期的階段,現有的一些工作大多聚焦于大數據分析系統的結構設計以及大數據驅動的應用,采集的數據量雖然很大,但使用的整體方法與結構較為宏觀,特別針對電力大數據在預測規劃方面的研究并不多見。基于此,本文先對電力大數據技術的意義與關鍵技術展開了論述,特別是其在電力系統中的組織結構。此外針對預測規劃這一目標,結合現有的一些研究方法與理論,提出了可行的方式并分析了效果[5-6]。
1 電力大數據系統的架構
目前對大數據系統的定義較為寬泛,本文中以Pei Zhang等人的定義為基礎進行下一步分析與論證,即認為電力大數據是海量的、相互關聯的業務數據,包括通過各種信息化手段采集的結構化數據、半結構化數據以及非結構化數據,這些信息化手段包括智能設施、傳感器、音頻和視頻監控設備、移動終端等[7]。
雖然電力大數據技術從大數據中繼承了3個“大”特性,但其仍有一些自身獨特的特點。①電力系統是一個動態的高度非線性時變系統,本質上是一系列連續動態過程與獨立事件的相互作用,不同的數據在不同時間、不同地點被采集,時間間隔小到毫秒,大到小時,地點跨度甚至能達到上千公里。②電力系統中的數據類型還會根據測量目標的種類發生一定變化。③電力系統的狀態既是暫時的,又在空間上與外部獨立變量相結合。④電力系統存在的本質目標是保持時刻變化的發電與載荷的平衡,這意味著發電一側要對負載的變化做出實時響應。但是在實際生產中,負載是一個高度隨機的變化量,用電負載受天氣、用戶活動等多方面的影響。⑤現代電力系統中存在許多可再生能源發電器,這類輸入的發電量同樣具有隨機性和間歇性的特點,給大規模可再生能源為電力系統的控制帶來了更多麻煩,甚至導致電涌等現象的發生,增加了無用損耗。⑥現代電力系統已經演變成深度信息物理融合系統,在這樣的應用背景下,數據的完整性、安全性、準確性深刻影響著系統的應用,而這3個特性本質上取決于底層通信網絡的效率和拓撲結構。由傳感器測量誤差帶來的影響也不可忽略,包括傳輸錯誤、噪聲、通信延遲等。此外,安全性也會帶來許多人為問題,2015年,烏克蘭首次發生因人為攻擊而導致的停電,因此可以預見到,虛假數據注入也是一種不可忽視的破壞電力系統方式[8]。
基于上述這些電力大數據系統的特點,G.Zhao等人提出一較為完備的電力大數據系統結構,如圖1所示。整個系統中最關鍵的部分之一是基于數據存儲框架的HDFS分布式文件系統,其二是基于數據處理框架的Map-Reduce計算技術。不論是分布式文件系統還是Map-Reducing計算技術都可以處理PB、ZB量級的數據,整個框架中還包含一些其他的模塊,例如智能商業應用、傳統數據庫、大數據連接框架、大數據描述框架、網絡層、操作系統、服務器、備份、恢復以及數據管理器等[9]。
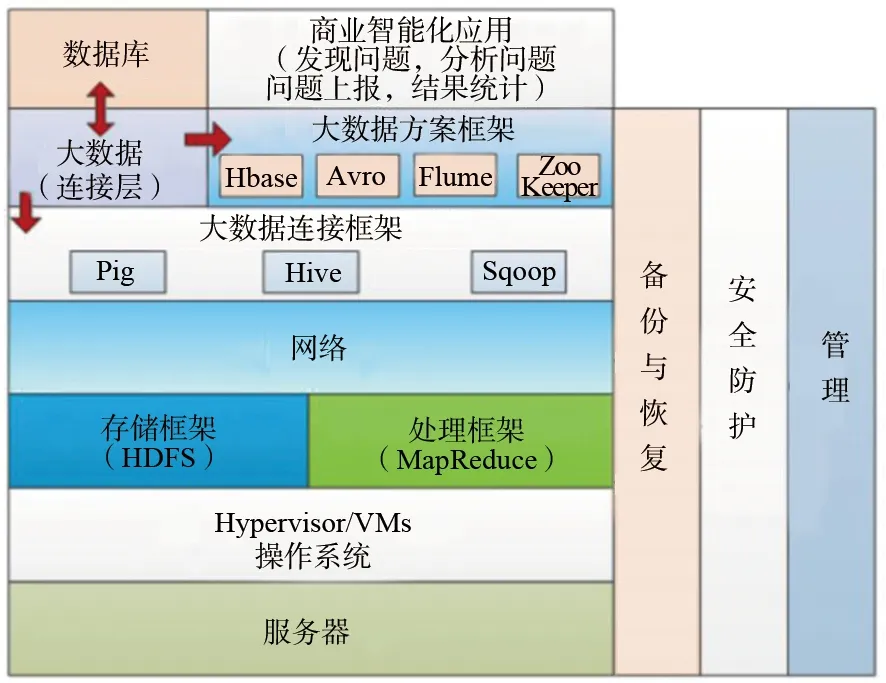
圖1 電力大數據系統結構
大數據存儲框架和大數據處理框架是基于傳統的計算機服務器、操作系統以及虛擬主機運行的,這意味著整套系統的造價更低,擴展空間更大。大數據連接框架與大數據處理、存儲框架通過網絡層相連。其由許多的子模塊組成,包括平行計算機編程語言Pig,數據庫管理工具Hive,開源數據傳輸工具Sqoop。基于上述工具,操作者可以方便地通過大數據連接器訪問任何一個分布式文件存儲系統和傳統數據庫[10]。
電力大數據處理的流程與傳統大數據系統并非完全不同,最大的一個區別是傳統大數據處理中會考慮大量的非結構化數據,這種情況下采用并行處理技術,例如Map-Reduce是至關重要的。因此需要對電力大數據系統中包含的關鍵技術進行進一步分析。
2 電力大數據系統關鍵技術
2.1 云計算
云計算是基礎技術,是大數據的重要補充,云計算技術可以集成計算處理資源和存儲資源,改善數據處理和信息交互能力,是技術中最強大的組成部分,為處理大數據“多數據量”的主要問題提供了有效的技術手段,云計算與大數據技術之間的關系可以用圖2簡潔的描述[11]。

圖2 大數據與云計算之間的關系
2.2 數據存儲
數據存儲涉及的方面較多,其主要研究工作在于如何協調大量存儲設備協同工作,以此為外部的用戶以及商業存儲提供一個方便統一的調用、存儲接口。在電力大數據系統中,根據數據的結構(同時考慮結構化與非結構化數據)和時間尺度(非實時數據、半實時數據、實時數據)對數據進行分類,因此協調數據庫的不同功能需求來滿足海量電網數據的協同處理需求,數據存儲部分的數據來源既可以是電力公司所有的網絡設備,也可以是第三方數據存儲商提供的服務設備。
2.3 數據集成
數據存儲之上需要考慮的是數據的集成相關技術。數據集成模塊扮演了一個中繼角色,其目的在于收集、校核、清理以及統一不同來源的數據便于后續處理。這一類數據管理系統被稱為中央管理、外部訪問的統一管理系統。數據集成與管理技術包括數據融合與集成、數據提取、數據清洗、數據濾波等,對應于電力大數據技術中的數據提取、轉換、加載以及電力系統的統一建模等技術。但電力大數據系統可能仍存在許多問題,如數據質量差、準確度低、實時性不足等,這就需要高性能的數據管理系統相配合。
2.4 數據計算
近年來,電力數據使用場景大量增加,電力公司越來越趨向于使用新的數據處理技術,來更有效利用軟件和硬件資源,以減少投資,維護成本,降低能耗,同時提供更穩定和更強的數據處理能力。在提出的電力大數據架構中,數據計算層通過數據集成層訪問數據,進行各種分析和處理工作。各種數據分析技術可以位于這一層,例如并行分布式計算、內存計算和流處理。此外,還可以在此層中應用虛擬化技術,為上層應用程序和用戶提供硬件和軟件的可視化。從這個意義上講,數據分析層提供的服務也稱為電力云服務。
2.5 數據應用
數據應用是在數據存儲、數據集成、數據計算基礎上建立起來的上層應用,它根據底層提供的數據和服務類型建立面向不同電力場景的應用程序。數據應用的背景下,可以用到許多人工智能、大數據相關的上層技術,如數據挖掘、深度學習、機器學習、圖像識別等。典型的電力數據應用有電網安全在線分析、間歇發電預測、動態線路評估、設備健康監測與診斷、負荷管理等。要保證電力系統可靠、穩定、高效率地運行,電力行業對數據精準度的要求會更高。每種技術都有其各自適合的應用場景,也有各自的局限性,使用時應注意識別,選擇合適的技術處理合適的問題。
3 電力大數據關鍵技術在輸電預測規劃中的應用
電力大數據在基礎的數據方面已經得到了大量的技術積累,給輸電預測規劃、能源管理方面的發展帶來了前所未有的機遇。預測是電力系統運行和規劃的一項基本而重要的任務。經典的預測問題包括負載預測和電價預測[12-13]。
隨著可再生能源的日益普及,可再生發電(如風能、太陽能光伏)預測成為電力大數據的又一重要應用。與負荷需求等其他變量相比,可再生能源發電涉及環境、天氣、氣候、可再生能源發電機自身發電曲線等多種因素,因而具有更大的隨機性和預測難度。因此,與傳統的點預測不同,對區間預測技術的進一步研究成為越來越熱的研究趨勢,以更好地反映可再生發電的不確定性。圖3給出了點和區間預測的效果圖示,區間預測不僅提供了不確定變量的平均值,而且提供了該變量可以隨機變化的范圍。預測區間可作為魯棒優化技術的輸入,為高水平可再生能源電力系統的更加穩健運行和規劃提供技術支持。此外,除了預測風電、太陽能光伏發電機組的發電量外,風電、太陽能光伏發電機組的升壓功率預測也是至關重要的,因為這類間歇可再生能源的升壓速率對系統的電力調度、電量儲備、頻率控制等都有重要影響。最近的一些研究開發了可再生的斜坡預測方法。與此同時,由于智能電能表的廣泛應用,人們對預測家庭層面的負載需求數據也越來越感興趣。預測結果可用于支持更好的負荷管理和需求響應計劃。但與總負荷需求相比,家庭負荷具有更大的隨機性和波動性。為了獲取其負荷模式,必須考慮居民的行為[14-15]。此外,考慮到這些住宅計量數據,可對用戶的用電模式進行分析。

圖3 點與區間預測圖例
4 結束語
電力大數據技術對電網的升級建設以及未來發展都有至關重要的意義,本文介紹了應用于電力大數據技術的基本框架,提取了其中的5個關鍵技術一一進行了介紹。在此基礎上介紹了電力大數據技術在輸電預測規劃方面的典型應用案例。可以看到電力大數據技術進一步應用的難點不在于技術,而是在于針對不同的技術找到其合適的應用場景與應用條件,本文的分析對電力大數據技術的進一步應用提供參考。
