Attention-CNN 在惡意代碼檢測中的應用研究
2021-04-11 12:49:02程琪芩孫志強
計算機與生活 2021年4期
馬 丹,萬 良+,程琪芩,孫志強
1.貴州大學計算機科學與技術學院,貴陽 550025
2.貴州大學計算機軟件與理論研究所,貴陽 550025
瑞星2019 年上半年中國網絡安全報告[1]指出,2019 年上半年共截獲病毒樣本為1.03 億個,病毒累計感染次數4.38 億次,病毒總體數量比2018 年同期上漲32.69%。所有惡意代碼攻擊中,針對Windows系統的攻擊已經超過了67%。此外,病毒種類隨著各種技術的進步而大幅度增長。
為了檢測各種層出不窮的惡意代碼,反病毒研究者需要不斷獲取并了解惡意代碼的相關行為,主要通過人工分析揭示惡意代碼的具體函數以達到解除該病毒的目的[2-3],但是這種不經過前期處理直接分析惡意代碼是一個比較耗時的工程。傳統方法是從惡意代碼的反匯編指令中生成特征向量、控制流圖并比較[4-6],但是這種比較對象僅是惡意代碼的代碼部分,對打包樣本或重要的攻擊行為隱藏在數據部分的惡意代碼是無效的。
為了同時檢測到惡意代碼數據部分和代碼部分的攻擊行為,Nataraj 等人[7]將有標簽的惡意代碼轉化為灰度圖,并利用k近鄰算法對未標記的惡意代碼樣本進行分類,這種方法即使在惡意代碼是混淆的情況下也能夠得到較高的準確率,但是該方法最終通過GIST(generalized search trees)算法提取圖片紋理特征,而該算法復雜度高,導致提取特征的效率不高。Ahmadi 等人[8]在Nataraj 等人[7]的基礎上提出多特征梯度增強算法對惡意代碼進行分類,該方法有效地提高了包括壓縮樣本在內的惡意代碼分類精度,但是用傳統機器學習方法難以提取高維度的特征,導致檢測效果不明顯。
卷積神經網絡在圖像[9]、自然語言處理[10]、文本處理[11]等領域得到迅速發展,由于它能自動學習輸入數據特征而無需人工參與,于是網絡安全研究者們將神經網絡引入到網絡安全的各個領域。龍廷艷等人[12]利用自編碼網絡對惡意代碼進行檢測,這種方法能夠比傳統機器學習方法(隨機森林、支持向量機(support vector machine,SVM))得到較好的檢測效果,但是也存在無法檢測混淆惡意代碼的問題。Cui等人[13]采用了蝙蝠算法(bat algorithm,BA)解決了惡意代碼家族樣本數量不均勻導致的過擬合問題,并結合卷積神經網絡對Nataraj 等人[7]提出的方案進行了改進,這種方法一定程度上檢測出混淆惡意代碼并得到較高的準確率。事實證明將惡意代碼轉化為灰度圖后用深度學習的方法提取特征比使用機器學習方法得到更高的準確率[14-15]。
雖然將惡意代碼轉化為灰度圖后,用深度學習的方法對惡意代碼進行檢測或分類都能得到很好的檢測效果,同時還能在一定程度上檢測到混淆代碼,但是這樣的方法也存在一定的缺陷,將惡意代碼轉化為灰度圖已失去原有的可解釋性,不能解釋惡意代碼存在哪些惡意行為。而注意力機制能夠將網絡中間層的特征賦予相應的權重并可視化[16],本文提出Attention-CNN 模型,在將惡意代碼分類的同時得到注意力圖,該注意力圖能夠對惡意代碼的特殊區域進行強調,以便利用得到的注意力圖進行下一步分析,找到惡意代碼存在的惡意行為,保證在良好的檢測效率下得到惡意代碼中的行為。
本文的工作如下:
(1)將注意力機制結合卷積神經網絡應用于惡意代碼檢測方向,構建網絡模型Attention-CNN,對惡意代碼進行分類并對惡意代碼灰度圖的重要區域進行可視化。
(2)通過從注意力層得到的注意力圖(對惡意代碼灰度圖的強調部分)與原始惡意代碼二進制文件的映射關系,找到具有重要特征的位置,再利用反匯編工具分析該位置存在的惡意行為。
1 卷積神經網絡
卷積神經網絡是一類包含卷積計算且具有深度結構的前饋神經網絡,是深度學習的代表算法之一[17-18],能進行有監督學習和無監督學習,其隱含層內卷積核的參數共享使得卷積神經網絡能夠以較小的計算量提取特征。給定一幅圖,卷積神經網絡能提取其特征并通過全連接層進行輸出,達到分類目的。
(1)卷積層
在卷積神經網絡中,卷積層是通過卷積過濾器實現對輸入圖片的特征提取,如xi,j(0 ≤i<W,0 ≤j<H)表示大小為W×H的輸入圖片,其處理公式為:

式中,wp,q(0 ≤p,q<M)表示大小為M×M的卷積過濾器的權值。
通常情況下,在卷積處理過程中,卷積過濾器往往如圖1 所示有多個通道,并且多個通道的過濾器同時進行特征提取,例如,當輸入圖片是xi,j,k(0 ≤i≤W,0 ≤j≤H,0 ≤k≤K),即圖片大小為W×H,通道為K,其卷積處理公式為:
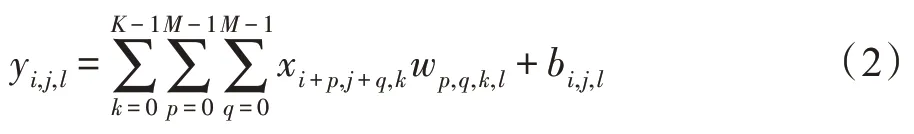
式中,bi,j,l表示神經網絡的偏置,wp,q,k,l表示神經網絡的權重。
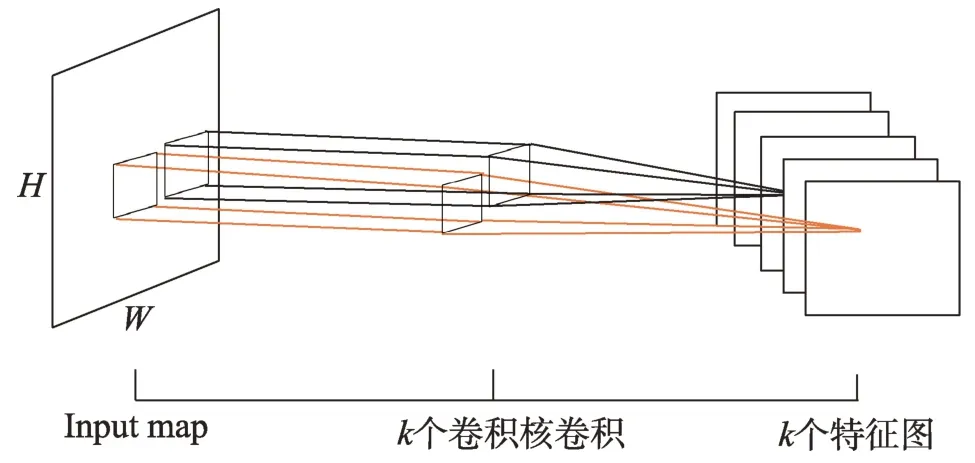
Fig.1 Multichannel convolution processing圖1 多通道卷積處理
(2)全連接層
經過多個卷積層和池化層后,模型往往會連接著1 個或1 個以上的全連接層。全連接層中的每個神經元與其前一層的所有神經元進行全連接,可以整合卷積層或者池化層中具有類別區分性的局部信息。
(3)激活函數
輸入圖片在經過卷積處理后,會將其結果經過激活函數處理,使模型有更強大的表達能力,本文的卷積層以及全連接層的激活函數使用線性整流函數(rectified linear unit,ReLU),在x<0 時,硬飽和,x>0 時,導數為1,保持梯度不衰減,從而緩解梯度消失問題,能更快收斂,表達式為:

(4)輸出層
模型最后是輸出層,將全連接層的輸出結果傳遞給一個函數,即Softmax 邏輯回歸(Softmax regression),該層也可稱為Softmax 層(Softmax layer),它將多個神經元的輸出映射到(0,1)區間內,其輸出值可作為模型檢測為某類的概率,從而達到多分類的效果,其表達式為:

式中,wi為輸出層的權重,b為輸出層的偏置,σi(z)是Softmax 函數,作為輸出層的激活函數。
2 注意力機制
注意力機制是一種常用于深度學習中對特征進行強調的技術,為了提高翻譯任務的性能,首先應用于自然語言處理領域[19]。隨著技術的進步,注意力機制也能應用于卷積神經網絡中,對圖片的重要部分進行可視化[16]。
本文所采用的注意力機制的原理如圖2 所示,首先從模型的第3 個卷積層中得到zi,j(0 ≤i≤W,0 ≤j≤H),和普通卷積層一樣,將得到的zi,j傳輸到注意力層,從而計算出圖像的注意力權重,并傳送到下一層。為了得到?,注意力機制計算zi,j的每個區域的注意力權重即ai,j,注意力機制公式為:
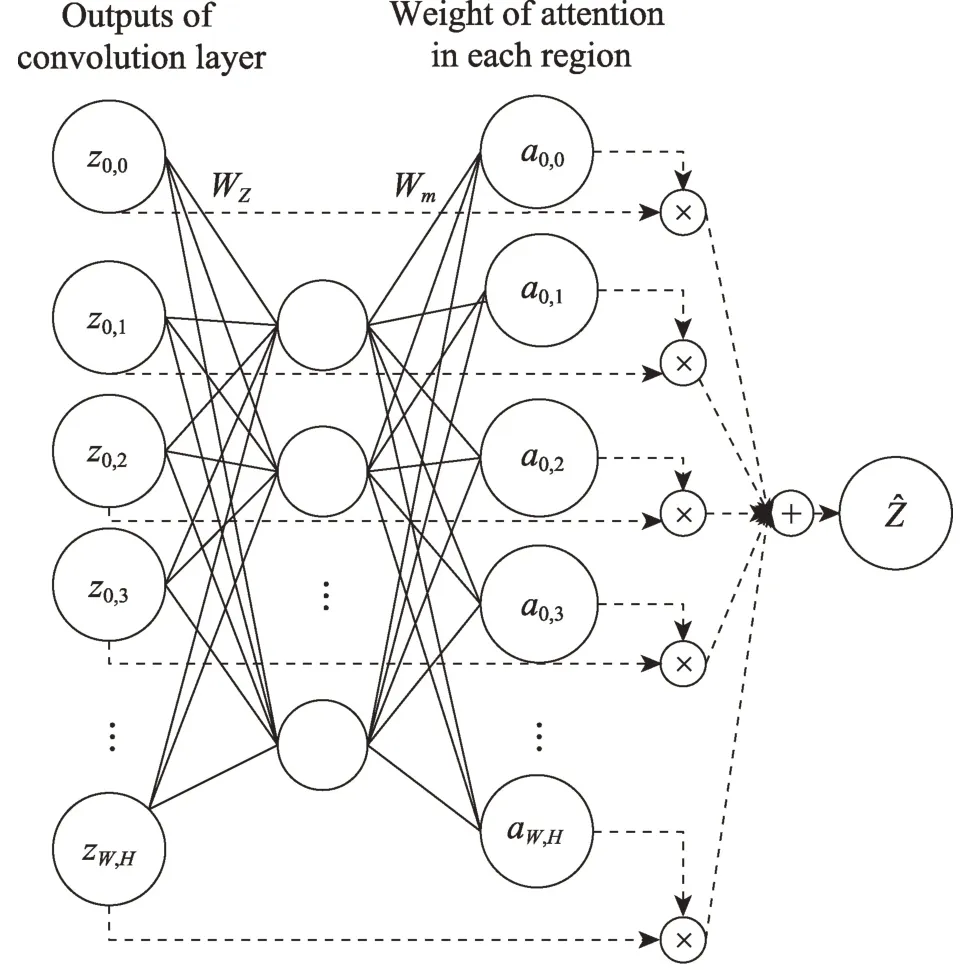
Fig.2 Attention mechanism圖2 注意力機制

式中,Z=(zi,j) 表示從卷積層中得到的特征圖,A=(ai,j)表示對每個輸入特征強調的總和。

式中,zi,j表示從上一個卷積層中得到的特征圖的某個區域,ai,j表示特征圖中某個區域的注意力權值。
總的來說,本文所使用的注意力機制算法如算法1 所示,輸入是從第3 個卷積層得到的特征圖,輸出是特征圖的注意力權重。
算法1注意力機制算法
輸入:第3 個卷積層輸出的特征圖zi,j。
輸出:注意力權重。

3 Attention-CNN 檢測模型
Attention-CNN 惡意代碼檢測模型框架如圖3 所示,本章將從惡意代碼可視化、模型構建、模型訓練幾個方面介紹該檢測框架的具體過程。首先是處理數據,即將惡意代碼轉化為灰度圖,具體過程將在3.1節介紹,其次是構建帶有注意力機制的網絡模型并結合灰度圖對網絡模型進行訓練。接著用待檢測樣本對網絡模型進行檢測,最后是結果分析,結果分析將在第5 章進行詳細闡述。
3.1 惡意代碼可視化
惡意代碼的惡意行為不僅僅存在于代碼部分,還可能隱藏在惡意代碼的數據部分。為了更有效地檢測惡意代碼,本文將惡意代碼二進制文件轉化為灰度圖,這樣可以以統一的方式處理樣本的代碼部分和數據部分。具體方法如圖4,首先將給定的惡意代碼二進制文件的每8 位組合,其次遍歷整個二進制文件,將組合后的8 位二進制排列為無符向量。而8位二進制轉化為十進制數后,其范圍是0 到255,剛好是灰度圖像素值(0:黑色,255:白色),最后將向量轉換為一個二維數組,即灰度圖。圖像的寬度是固定的,高度可以根據文件大小而變化。
轉化后的灰度圖中,同一個家族的灰度圖其紋理是相似的,而不同家族的圖像紋理又有一定的區別。圖5(a)、圖5(b)分別是Hoax.Win32.Renos 家族以及Trojan.Win32.BHO 家族的灰度圖,可以觀察到同一個家族內的惡意代碼紋理是相似的,而兩個不同的家族其紋理又是有一定的區別。
3.2 模型構建
Attention-CNN 由多個卷積層堆疊而成,本文的檢測模型由3 個卷積層、1 個注意力層以及2 個全連接層組成。
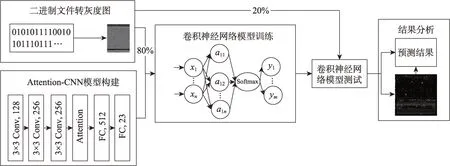
Fig.3 Workflow of this paper圖3 本文的工作流程

Fig.4 Binary to grayscale圖4 二進制轉灰度圖

Fig.5 Texture of malware family圖5 惡意代碼家族圖片紋理
卷積操作存在兩個問題:
(1)隨著網絡層數的加深,輸出的特征圖越來越小;
(2)圖像邊界信息丟失,即有些圖像角落和邊界的信息發揮作用較少。
因此需要在卷積層加入padding 填充,常用的padding 填充有“valid”和“same”,當輸入圖片大小為W×H,卷積核大小為M×M,strides=[1,1,1,1],padding=valid,則卷積層輸出的圖片大小為(W-(M-1))×(H-(M-1)),即相應圖片的長和寬都減少了M-1 個單位。若要圖片大小保持不變,則需要在卷積處理前對圖片的邊緣用0 填充,即“same”填充,在與valid 填充有相同的輸入圖片大小、卷積核大小以及strides下,經過卷積后得到的特征圖的大小為((W+2P)-(M-1))×((H+2P)-(M-1)),其中P=(M-1)/2。
本文最后會通過得到的注意力圖回溯到原來的灰度圖以及原始惡意代碼,以分析該重要位置存在的惡意行為,為了使注意力圖與輸入圖片能有位置上的對應關系,本文在卷積層“same”填充,同時省去池化層,以保持圖片大小不變,詳細參數如表1 所示。
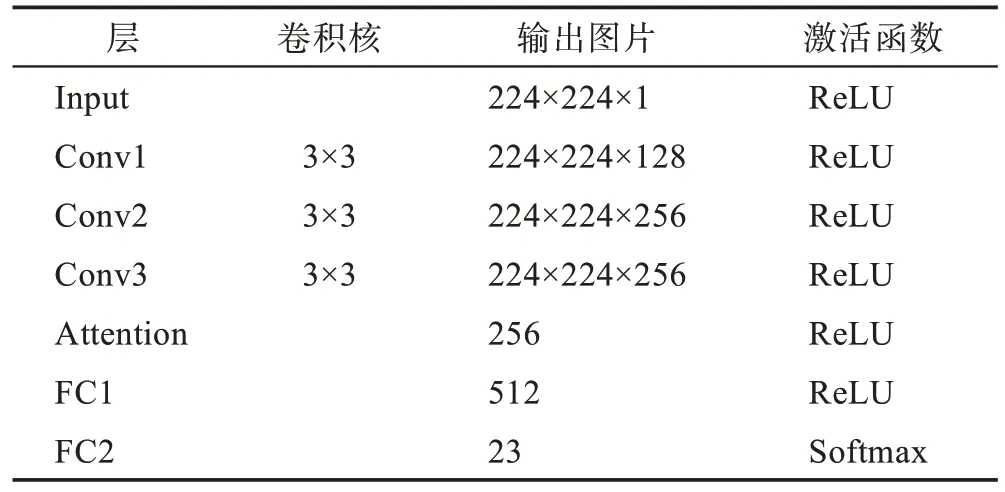
Table 1 Model parameters of convolutional neural network表1 卷積神經網絡模型參數
3.3 模型訓練
卷積神經網絡的訓練過程分為兩個階段:第一個階段是數據由低層次向高層次傳播的階段,即前向傳播階段;另外一個階段是當前向傳播得出的結果與預期不相符時,將誤差從高層向低層進行傳播訓練的階段,即反向傳播階段,訓練過程如圖6 所示。訓練過程為:
(1)網絡模型權值的初始化。
(2)輸入數據經過卷積層、全連接層的向前傳播得到輸出值。
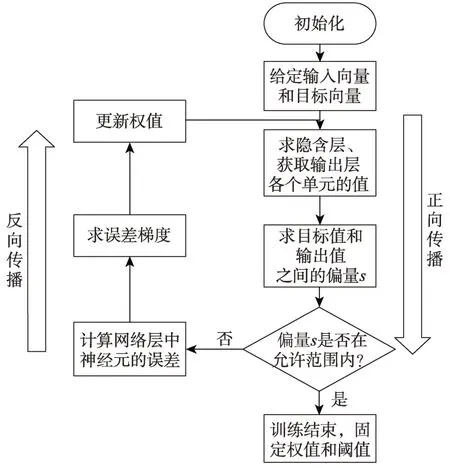
Fig.6 Model training process圖6 模型訓練流程
(3)求出網絡的輸出值與目標值之間的誤差。
(4)當誤差大于期望值時,將誤差傳回網絡中,依次求得全連接層、卷積層的誤差,通過梯度更新權重和偏置;當誤差等于或小于期望值時,結束訓練。
本文的惡意代碼檢測模型訓練與檢測過程如算法2所示,具體分為兩步:首先是構建帶有注意力機制的卷積神經網絡模型;其次用3.1 節中可視化的惡意代碼灰度圖輸入到檢測模型中訓練并檢測。
算法2Attention-CNN 檢測模型訓練與檢測過程
輸入:G={Mi},i={1,2,…,n},i表示輸入的序號,Mi表示經惡意代碼轉化的灰度圖,G表示灰度圖集合。
輸出:R={ri}和A={ai},R表示檢測結果集合,ri表示第i個惡意代碼的檢測結果。A表示注意力圖,ai表示第i個惡意代碼對應的注意力圖。
1.構建Attention-CNN 檢測模型
1.1 增加一個包含128 個神經元、卷積核大小為3×3 的卷積層,填充為Same;
1.2 增加一個包含256 個神經元、卷積核大小為3×3 的卷積層,填充為Same;
1.3 增加一個包含256 個神經元、卷積核大小為3×3 的卷積層,填充為Same;
1.4 增加注意力層
1.5 注意力層得到的權重與上一個卷積層得到的特征相乘;
1.6 增加包含512 個神經單元的全連接層,激活函數為ReLU;
1.7 增加包含23 個神經單元的全連接層,激活函數為Softmax;
2.Attention-CNN 模型訓練與測試
2.1 參數初始化;
2.2 while 不滿足提前終止訓練條件do:
2.3 while 訓練集剩余數據不為空do:
2.4 模型訓練輸入一組小批量數據樣本;
2.5 使用Softmax 函數進行數據樣本分類;
2.6 使用Adam 梯度下降優化算法更新權重值;
2.7 end while
2.8 使用測試集數據驗證模型;
2.9 end while
4 實驗過程與結果分析
4.1 數據集
(1)Data1:本文的模型最終目的是得到分類結果以及注意力圖,實現用注意力圖與輸入圖片以及原始惡意代碼進行對比分析,因此所需的數據集是原始惡意代碼并非現成的灰度圖。考慮到這個因素,采用VX Heaven[20]上公開的數據集作為本實驗的數據集。該數據集曾用于2017 年Vyas 等人[21]、2018 年Dam 和Touili[22]以及2019 年Dovom 等人[23]的論文中,包含了48.88 GB 的惡意代碼原始惡意代碼,本文選用其中的9 644 個樣本進行處理。樣本類別以及數量如圖7 所示,為了便于顯示,圖中將惡意代碼家族的名稱每節用兩個字符顯示,如“Backdoor.Win32.Cecknogtihuan”改為“Ba.Wi.Ce”。
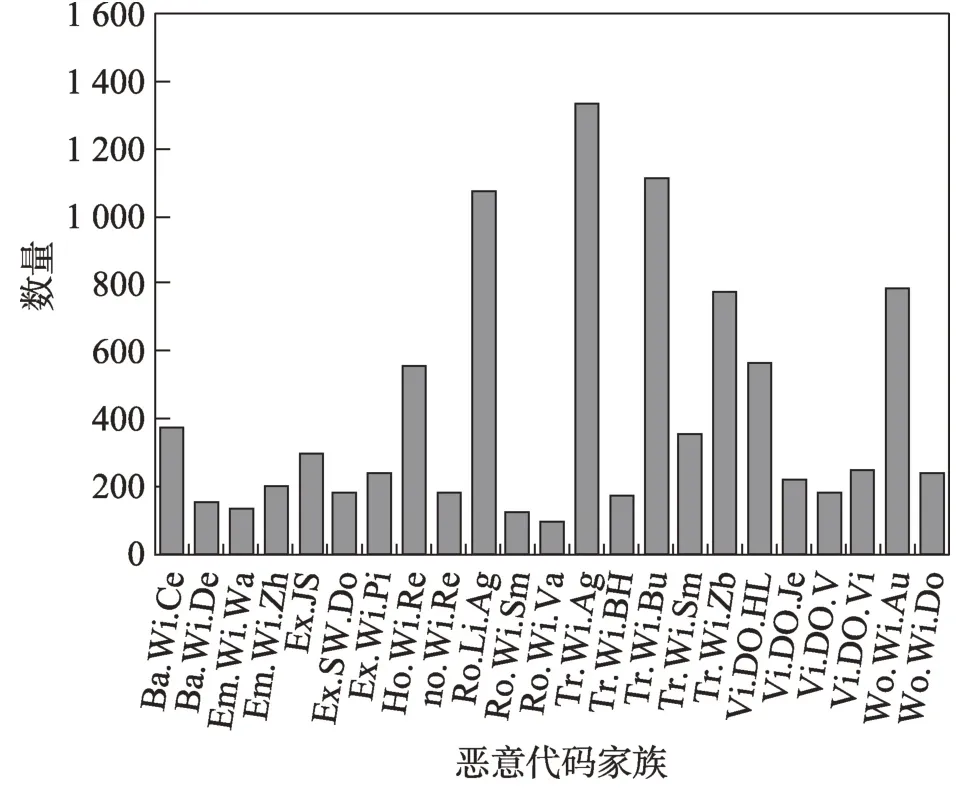
Fig.7 VX Heaven dataset圖7 VX Heaven 數據集
(2)Data2:目前用灰度圖對惡意代碼進行分類的方法中,有一部分研究者使用的數據集是Nataraj 等人公開的Malimg 數據集[7],該數據集有25 類共9 339個樣本。為了和現存的惡意代碼分類模型對比,本文在Malimg 數據集上與其他方法進行訓練并對比實驗結果。樣本類別及數量如圖8 所示。
4.2 優化模型
4.2.1 優化函數對模型的影響
VX Heaven 數據集中的二進制惡意代碼轉化成灰度圖后,將得到的灰度圖按照2∶2∶6 的比例分別得到驗證集、測試集和訓練集,并輸入到本文的Attention-CNN 深度學習模型中訓練。在訓練階段,不同的優化函數會得到不同的訓練效果,為了得到更好的訓練效果,本文對比了多個優化函數對函數收斂的影響。圖9 顯示Adam、Momentum、Adadelta、SGD 幾個優化函數在模型中的收斂情況,其中Adam和Momentum 都能快速收斂,但Adam 收斂效果較好,而Adadelta 和SGD 效果比較差,故本文使用的優化函數是Adam。其他參數設置如表2 所示。
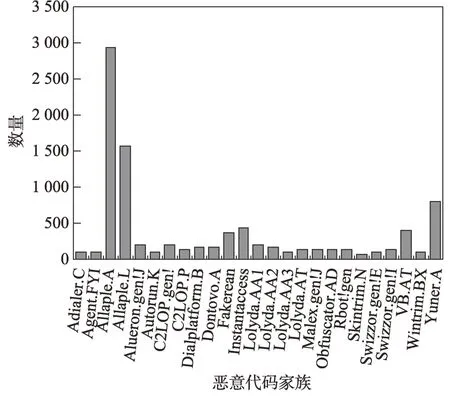
Fig.8 Malimg dataset圖8 Malimg 數據集
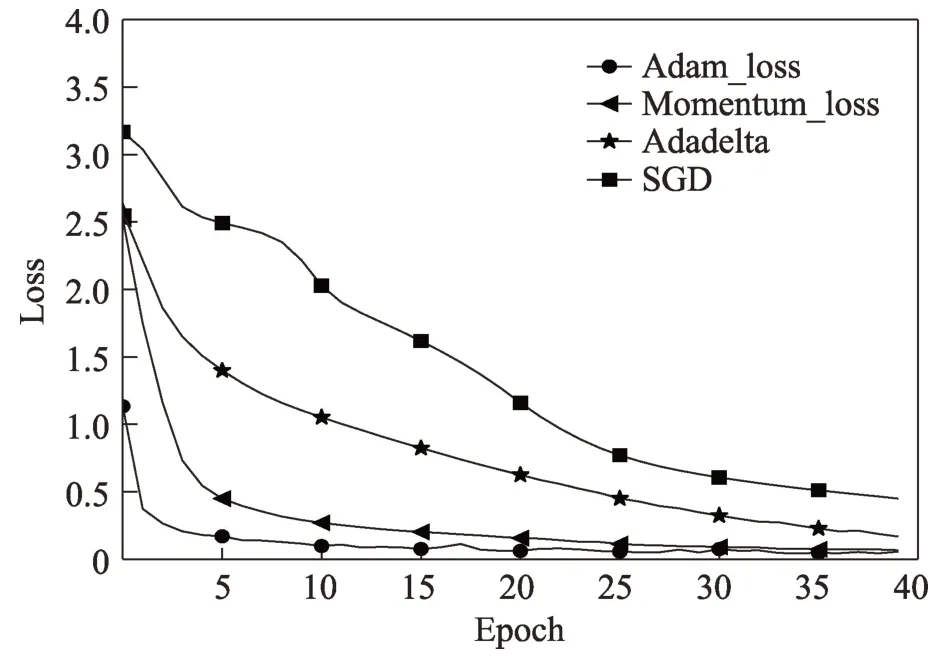
Fig.9 Influence of optimization function on loss function圖9 優化函數對損失函數的影響

Table 2 Model parameter setting表2 模型參數設置
4.2.2 不同大小的輸入圖片對模型的影響
CNN 模型輸入圖片的尺寸是固定的,但是不同的輸入圖片大小會使CNN 得到不一樣的效果,為了得到更適合的輸入圖片的尺寸,本文以64×64、96×96、192×192、224×224 的輸入尺寸來訓練模型。表3記錄了各個尺寸的圖片的相應評價指標,可以看出,圖片尺寸越大,其相應的準確率(Accuracy)、精度(Precision)、召回率(Recall)以及F1-score越高。
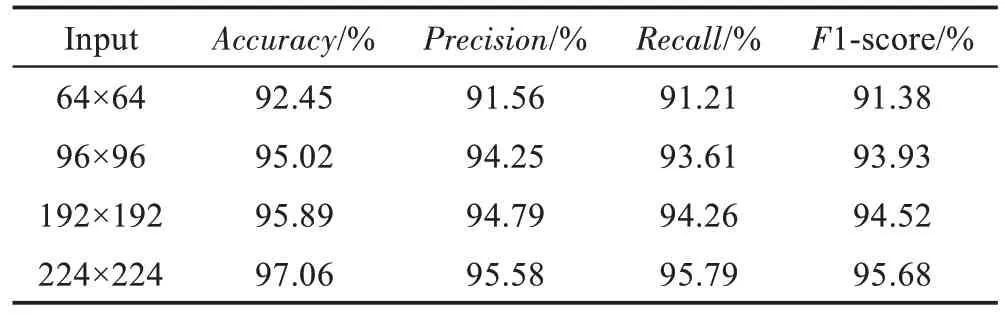
Table 3 Comparison of input pictures of different sizes on each indicator表3 不同大小的輸入圖片在各個指標上的對比
此外,圖10 是用不同大小的圖片作為模型輸入而得到的混淆矩陣。該圖顯示,輸入尺寸越大,其混淆矩陣得到預測標簽和真正標簽更匹配(大部分值都對應在正角平分線處)。為了得到更好的分類效果,本文設定模型的輸入圖片大小為224×224,盡可能保留惡意代碼中的有用信息。
4.3 評價指標
訓練及測試的過程中,將使用不同的評價指標評估本文模型,本文的評價指標主要有4 個,分別為Accuracy、Precision、Recall以及F1-score。
Accuracy表示分類的準確率,即對給定的數據,分類正確的樣本數占總樣本數的比例,其計算公式為:
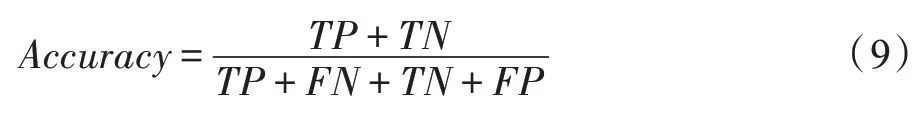
Precision是指在預測為正確樣本中真正正確樣本所占的比例,其計算公式為:

Recall指的是預測正確的某類樣本占該類總樣本的比例,其計算公式為:

F1-score 是精確率和召回率的調和平均。因為精確和召回率兩個指標是相互矛盾的,當檢測結果的精確率高時,其召回率往往會相應降低,反之亦然。為了調和這樣的矛盾,本文引入了F1-score,其計算公式為:
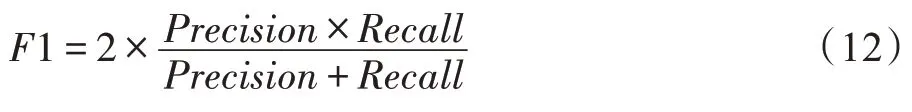
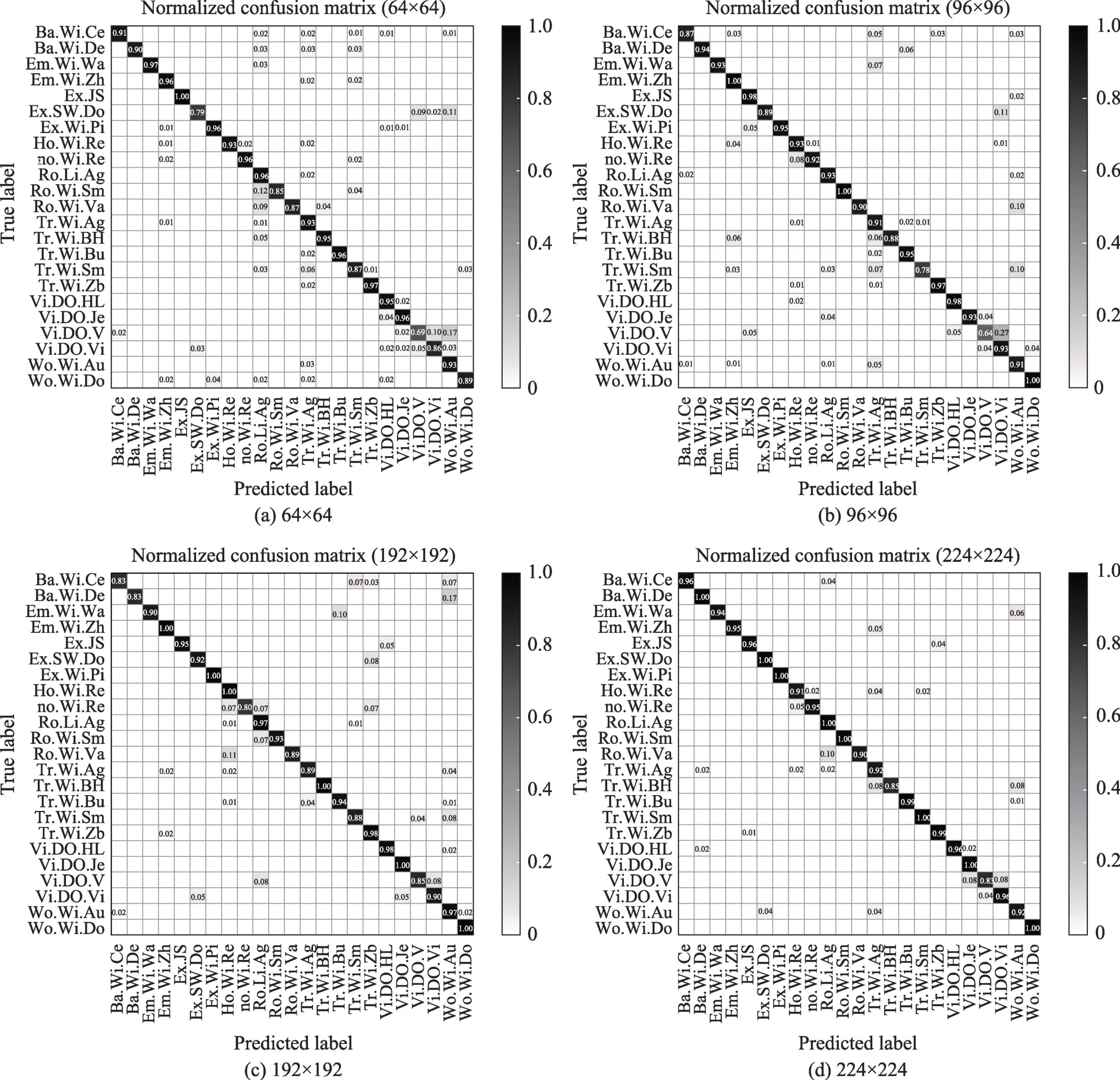
Fig.10 Confusion matrix obtained from different input images in training models圖10 不同輸入圖片訓練模型得到的混淆矩陣
其中,TP表示樣本預測為某個家族,實際上也是該家族;FP表示樣本預測為某個家族,實際上不是該家族;TN表示樣本預測不是某家族,實際上是該家族;FN表示樣本預測不是某家族,實際上也不是該家族。
4.4 對比分析
4.4.1 在數據集VX Heaven 下的對比實驗
為了證明本文方法的檢測效果,將傳統的機器學習方法和沒有注意力機制的CNN 與本文方法進行對比實驗,并統計檢測結果的Accuracy、Precision、Recall以及F1-score 4 個指標。
其中機器學習方法的參數設置如下:
(1)用網格搜索算法對RF(random forest)尋優,最優的參數如表4 所示,表中n是樹的棵數,m是最大特征數,d是最大樹的深度,k是最小樣本數。

Table 4 Random forest parameter setting表4 隨機森林參數設置
(2)SVM 分類的影響因素主要是C(錯分懲罰因子)、g(RBF 核函數的控制因子值),網格尋優(Gridsearch)確定最優值為C=128,g=0.12。
(3)J48.trees參數設置主要有C=0.25,M=2。
表5 記錄了傳統機器學習方法、不帶注意力機制的CNN(參數與表2 相同)以及本文的Attention-CNN的各個指標的情況。RF、SVM、J48.trees 都是機器學習方法中常用的分類算法,但是相比本文方法其準確率、精確度、召回率以及F1 值都不高。同樣不帶注意力機制的CNN其相應的評價指標略低于本文方法。
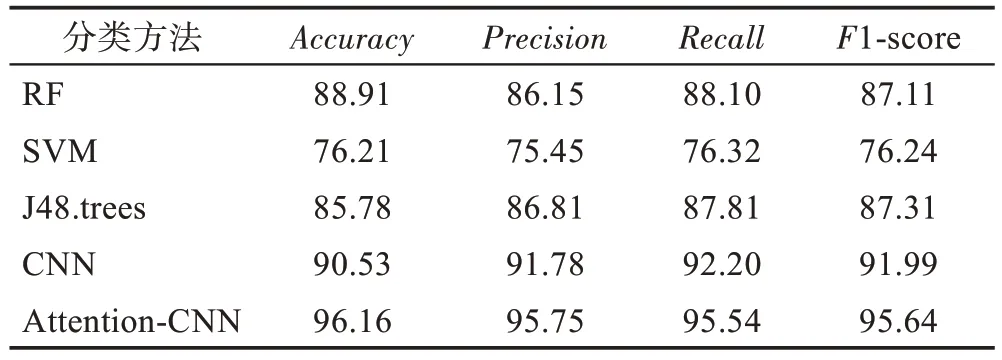
Table 5 Comparison of Attention-CNN with other methods表5 Attention-CNN 與其他方法的對比結果 %
4.4.2 在Malimg 數據集下的對比實驗
本文構建的模型能夠在得到注意力圖的同時對樣本進行分類,為了驗證本文提出的模型的分類效果,用相同Malimg 數據集與文獻[13]模型進行訓練并與本文方法進行對比。為了便于說明,將文獻[13]中使用的模型稱為vsNet,將本文使用的模型稱作Attention-CNN,對比結果如圖11。在Malimg 數據集下的實驗證明,vsNet 模型檢測的準確率是94.50%,而本文的Attention-CNN 模型能夠達到98.80%的準確率,相比于vsNet的方法提高了4.3個百分點。同時從圖11 中可以看出,Attention-CNN 在25 個epoch 附近,函數已經收斂,損失函數基本達到穩定,精確度基本達到最大值。而vsNet 模型在100 個epoch 的時候還未達到穩定,精度緩慢增加,經過后續的訓練,最終在200 個epoch 的時候達到穩定。因此本文提出的分類模型能夠得到較好的分類效果,訓練時間相對較短。
5 利用注意力圖對樣本進行額外分析
5.1 通過注意力圖獲取惡意代碼行為信息
本文的Attention-CNN 模型,最終會輸出分類結果以及注意力圖。本節對得到的注意力圖進行分析。
圖12 展示本文的惡意代碼分析流程,完成模型訓練階段后,模型對樣本進行檢測,最終會得到相應的分類結果和注意力圖。接下來將模型輸出的注意力圖用于人工分析。當重要區域在代碼部分,則用IDApro 將二進制文件反匯編,將注意力圖的重要區域位置對應到二進制文件的相應位置,并提取該位置的函數從而得到惡意代碼的行為信息,當重要區域落在數據部分則提取相應的資源文件。
得到的注意力圖如圖13 所示,注意力圖中標注了該樣本特有的特征位置,圖中標有顏色的點就是含有該樣本的重要字節序列位置,當灰度圖中的位置是確定的時候,則可將該位置對應到二進制文件的相應部分,后續可通過IDApro 找到該部分對應的函數,以分析該惡意代碼的行為。
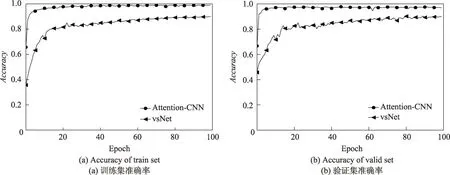
Fig.11 Accuracy of Attention-CNN and vsNet圖11 Attention-CNN 和vsNet的準確率

Fig.12 Workflow of manual analysis圖12 人工分析工作流程
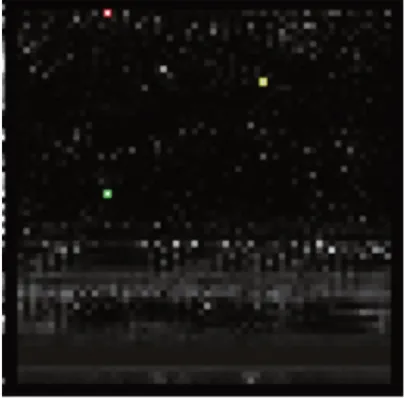
Fig.13 Attention map圖13 注意力圖
Nataraj 等人[7]指出,通過二進制轉換而來的灰度圖,其各個部分都對應著二進制文件的相應部分,如圖14 是Trojan.Donto.vo.A 變種的相應部分在灰度圖中的顯示情況,其中.text 表示二進制文件的代碼部分,.rdata 和.data 都表示二進制文件的數據部分,最后一部分是.rsrc 部分,它包含模塊的所有資源以及應用程序所使用的圖標。因此當注意力圖的重要位置在代碼部分,則提取惡意代碼的函數,當注意力圖的重要位置在數據部分以及資源部分時,則提取惡意代碼的資源文件。

Fig.14 Section division of grayscale image圖14 灰度圖的節劃分
5.2 對Backdoor.Win32.Agobot.lt的分析
圖15左圖是Backdoor.Win32.Agobot.lt灰度圖,屬于Worm:Win32/Gaobot 家族,它能夠通過IRC(Internet relay chat)執行來自遠程服務器的命令。除此之外,該家族能夠通過攔截HTTP/FTP 通信來竊取登錄信息[24]。圖15 右圖是本文模型得到的Backdoor.Win32.Agobot.lt的注意力圖,本文將該惡意樣本的二進制文件用IDApro 來反匯編,通過注意力圖中的標有重要信息的位置找到原文件中的相應位置。圖15右中標有紅色的點對應到源文件的sub_401356函數,通過分析得到,該位置是一個能夠連接到IRC 服務器并進入聊天室接收來自遠程服務器的指令。標有綠色點對應到源文件的sub_410F80 函數,這是一個用于接收截獲的HTTP 通信的內容的函數,并檢查內容是否包含字符串,例如“PAYPAL”或“paypal.com”。
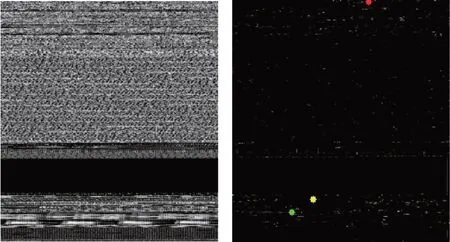
Fig.15 Grayscale and attention map of Backdoor.Win32.Agobot.lt圖15 Backdoor.Win32.Agobot.lt灰度圖和注意力圖
5.3 對Trojan-Banker.Win32.Banbra.r的分析
圖16 左圖展示的是Trojan-Banker.Win32.Banbra.r灰度圖,這是一種TrojanSpy:Win32/Banker 家族的惡意樣本,其設計目的是通過輸入鍵盤和鼠標來竊取銀行賬戶信息[25],圖16 右圖是其通過本文方法得到的注意力圖,其中紅色的地方表示權重最高的位置,通過該位置找到了源文件中的sub_480A84,這是一個通過電子郵件發送操作系統版本、鍵盤記錄、截圖等信息的函數。此外黃色地方表示權重第二大的位置,該位置映射到源文件的“√”和“×”,這是存在于可執行文件中,并由以Delphi為按鈕圖標生成的資源文件,位圖數據被認為具有很高的重要性,因為Delphi經常被用于TrojanSpy:Win32/Banker,具有標識作用。

Fig.16 Grayscale and attention map of Trojan-Banker.Win32.Banbra.r圖16 Trojan-Banker.Win32.Banbra.r灰度圖和注意力圖
分析結果表明,所提出的方法所得到的注意力圖中的區域所對應的字節序列在人工分析惡意代碼樣本行為時提供了有用的信息。此外,即使每個樣本的位置發生變化,該方法也可以有效提取相應的特征。
6 結束語
針對目前網絡中存在大量的惡意代碼的攻擊問題,本文提出了基于注意力機制的卷積神經網絡模型,對惡意樣本進行檢測和分析,模型最終輸出待檢測惡意代碼樣本屬于哪個家族,同時得到相應的注意力圖。通過與傳統的機器學習以及不帶注意力機制的CNN 進行比較,本文方法在準確率、召回率、以及F1 值都有較高的值。在Malimg 數據集下與文獻[13]的方法進行比較,其準確率提高了4.3 個百分點,取得較好的檢測效果。通過模型輸出的注意力圖,本文獲取到惡意代碼的重要特征區域并通過與惡意代碼二進制文件的映射關系進行人工分析,實驗證明,本文方法能夠獲取惡意代碼存在的行為,彌補傳統灰度圖形式的惡意代碼檢測方法中的惡意代碼不可解釋性。
本文提出的檢測方法可能面臨以下挑戰:
(1)本文通過將VX Heaven 數據集中的惡意代碼轉換為灰度圖,其相應家族之間的圖片紋理區別不大,導致分類的準確度并沒有使用Malimg 數據集高,但Malimg 數據集中只有現成的圖片,沒有原始惡意代碼,導致無法做進一步分析。
(2)本文在VX Heaven 數據集以及Malimg 數據集上都得到較好的檢測效果。但是現如今的惡意代碼與VX Heaven 或Malimg 數據集存在一定的差異,因此下一步工作將收集比較新的惡意代碼樣本,使模型在現代惡意代碼中有更好的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
