Bert在微博短文本情感分類中的應用與優化
2021-04-12 09:50:46劉彥隆
小型微型計算機系統 2021年4期
宋 明,劉彥隆
(太原理工大學 信息與計算機學院,山西 晉中030600)
1 引 言
近年來,隨著互聯網技術的迅猛發展,微博、推特等社交媒體的出現使用戶從信息的接收者轉變為主動發起者,海量數據的迸發,給文本處理任務帶來了挑戰,單單依靠人工方法來挖掘信息不切實際,因此,通過某種技術手段自動化、智能化地處理任務成為迫切需求.與此同時,深度學習,機器學習等人工智能技術正滲透到各行各業,為中文短文本情感分析技術革新帶來了參考意義.
文本情感分析是自然語言處理研究的一個熱點,是對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程[1].其中一個重要問題就是情感分類,也就是情感傾向性判斷,即判斷文本的觀點是積極褒義的,消極貶義的還是客觀中性的.自然語言處理技術快速發展,越來越多的研究者關注于網絡用戶的情感分析.Yang 等[2]改進 Kim的模型,基于卷積神經網絡理論,對 Twitter 推文進行了分類研究,并驗證了卷積神經網絡對 Twitter 信息情感分類的優越性能,這種方法只考慮到了文本局部特征,未能捕獲較長文本前后的信息相關性;周瑛等[3]引入深度學習理論,提出了基于注意力機制的LSTM(Long-Short Term Memory)模型,模型解決了長文本微博信息的情感特征分析.但LSTM仍具有計算費時,梯度消失等局限,同時標注成本高,同一詞匯在不同領域的多種含義仍限制了性能的提升;對于小數據集的自然語言處理任務,ULMFiT[4](Universal language model fine-tuning for text classification)提出了一種高效的遷移學習方法,緩解了數據集不足的問題;為平衡簡單樣本和困難樣本的貢獻,OHEM[5]算法選取高損失值的樣本作為訓練樣本,加強了對困難樣本的學習程度,但完全忽略了高概率的簡單樣本對模型的貢獻.
現有微博數據內容涵蓋范圍較廣,同時關注敏感話題、相關領域等.從頭訓練的機器學習方法訓練費時,對數據量也有一定要求,成本較高.因此本文提出Bert[6](Bidirectional Encoder Representations from Transformers)預訓練模型作為網絡結構,初始化網絡參數進行遷移學習,以獲取深層語義信息,提升泛化能力.首先將此算法與經典情感分類算法卷積神經網絡TextCNN[7](Convolutional neural networks for sentence classification)、長短期記憶網絡LSTM[8]、通用語言模型微調Ulmfit等模型進行性能對比.并針對困難樣本容易分錯的問題,將Focal Loss[9]引入到中文文本情感分類任務中,結合對比實驗,本文提出的方法在多分類任務中優于同類算法,Focal Loss一定程度提升對困難樣本的分類能力.
2 相關工作
2.1 Bert語言模型預訓練
通過預訓練得到語言的表征工作已經進行了數十個年頭,從傳統密集分布的非神經詞嵌入模型[10]到基于神經網絡的 Word2Vec[11]和 GloVe[12],這些工作提供了一種初始化權值的方法,在多項自然語言處理任務中,不僅使訓練方式便捷很多,模型的效果同時有明顯的提升作用.Bert把語言模型作為訓練任務,通過無監督預訓練的方式抽取大量語言信息,并遷移到其他下游任務.
采用Transformer[13]網絡結構進行預訓練,受完型填空任務的啟發,采用“masked language model”(MLM),并在所有網絡層中把上下文信息同時考慮在內,此方法突破了單向語言模型的局限.進而可以得到深層雙向的語言表示.
Bert采用雙向 Transformer 結構,通過放縮點積注意力與多頭注意力直接獲取語言單位的雙向語義關系.通過 Transformer 結構獲取到的信息優于傳統的RNNs 模型以及對正反向 RNNs 網絡直接拼接的雙向 RNNs 模型.
2.2 輸入表示
Bert的輸入是由兩個句子相連的序列,每個句子前面添加一個標識符[CLS]表示句子開始,尾部添加一個標識符[SEP]作為結束,兩個句子通過分隔符[SEP]隔開.對于每個單詞,Bert進行了3種不同的嵌入操作,分別是對單詞位置信息進行編 碼position embeddings、對單詞進行Word2vec 編碼token embeddings、對句子整體進行編碼segmentation embeddings.將這3種嵌入結果進行向量拼接,可以得到Bert輸入,如圖1所示.
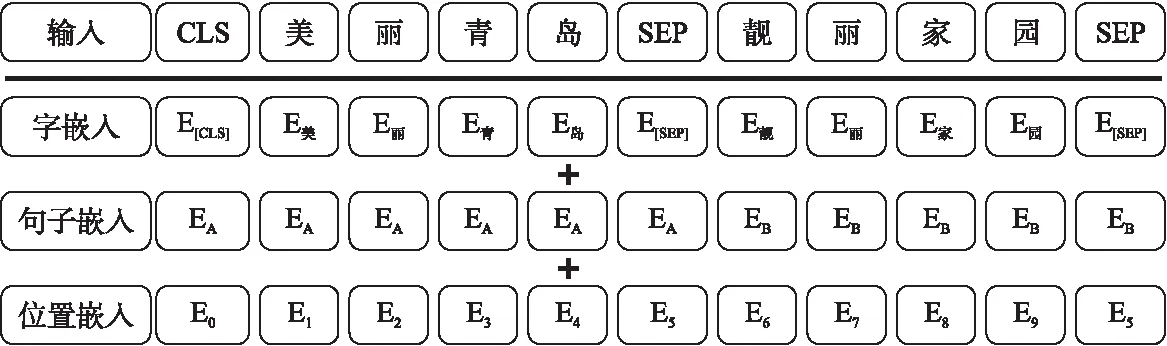
圖1 Bert的輸入表示Fig.1 Input representation of Bert
2.3 Masked LM
ELMo[14]使用經過獨立訓練的從左到右和從右到左LSTM的串聯來生成用于下游任務的功能.OpenAI GPT則是使用從左向右的單向Transformer作為網絡結構.事實上,深層雙向模型比從左向右模型或從左向右和從右向左模型的淺層連接更強大.不幸的是,因為雙向條件將允許每個單詞在多層上下文中間接“看到自己”.故標準條件語言模型只能從左到右或從右到左進行訓練.
為了解決語義單向問題,Bert將輸入詞的15%隨機進行掩蔽(Mask),其中被掩蔽掉的詞80%幾率被[MASK]替代,10%幾率是正確的詞匯,10%幾率替換成詞匯表中隨機詞匯,通過訓練語言模型預測這些詞來抵消“鏡像問題”的影響.但是語言模型無法學習到句子間的關系,于是 Bert引入下句話預測(NSP)任務來解決這個問題.預訓練后 Bert無需引入復雜的模型結構,只需要對不同的自然語言處理任務進行微調、學習少量的新參數,即可通過歸納式遷移學習將模型用在源域與目標域不相同的新任務中.Mask LM流程如圖2所示.
2.4 Transformer編碼器
Bert模型采用Transformer作為特征提取器,模型由多個Transformer層疊加構成.Transformer 編碼器有兩個子層,分別是基于自注意力機制的自注意力層和全連接前饋網絡層.同時,在每個子層內都加入了殘差結構(residual)和歸一化層(layer nomalization),結構圖如圖3所示.
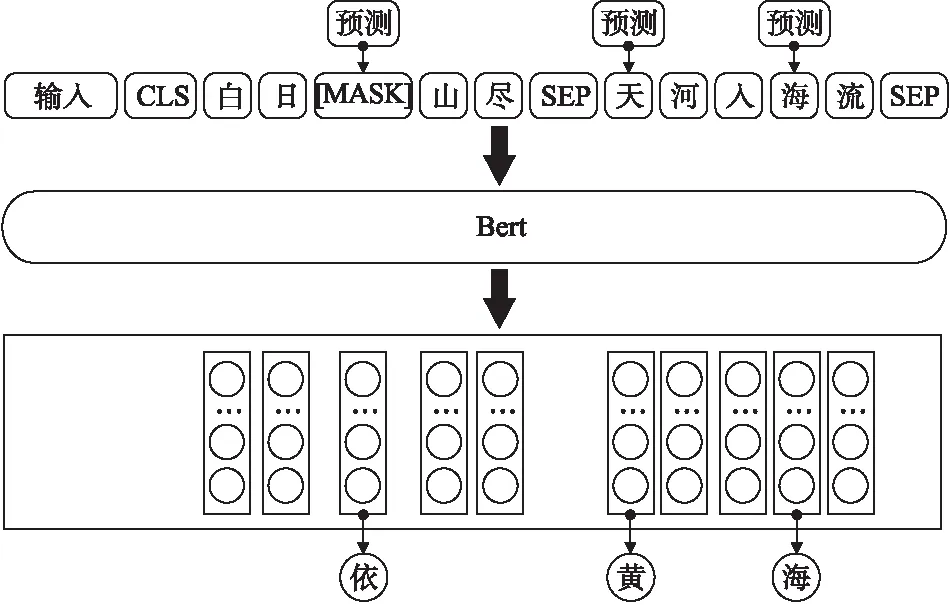
圖2 Masked LM流程Fig.2 Process of Masked LM
其中h個縮放點積注意(Scaled Dot-Product Attention)組成多頭自注意力模型(Multi-Head Attention).作為基本單元,縮放注意力計算公式為:
(1)
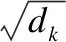
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(2)
(3)
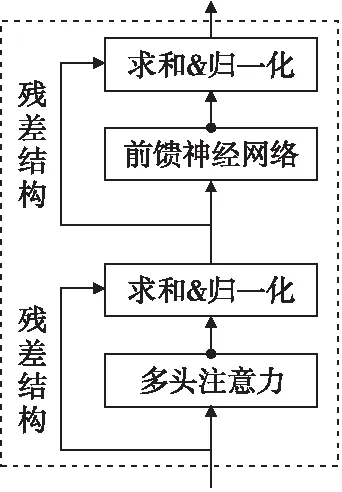
圖3 Transformer編碼器Fig.3 Transformer encoder
如果對矩陣Q、K和V進項線性計算,轉換成不同的矩陣,然后使用 h 個縮放點積單元進行計算,把h個縮放點積單元計算的結果組合起來,就能夠獲得更多的語義特征.由于每個縮放點積單元的輸入 K、Q 和 V 在進行計算時的權重不同,就能夠獲取來自文本不同空間的語義特征.以捕捉句子中的每個詞關于上下文的信息.
前饋網絡層由兩個大小為 1的卷積核組成,使用 ReLu 激活函數做兩次線性轉換
FFN(x)=max(0,xW1+b1)W2+b2
(4)
其中W1和W2是權重,b1和b2為偏置項.最后經過殘差網絡和層歸一化得到最終輸出.
Transformer 編碼器網絡總共使用n個編碼器抽取文本的特征,后將學習到的分布式特征使用全連接層將特征整合映射到樣本標記空間,以便進行文本情感傾向性分類.
3 基于Focal Loss優化Bert微調模型
3.1 交叉熵損失函數
對于大多數文本分類任務,通常采用交叉熵(Cross Entropy,CE)作為損失函數,其計算公式為公式(5):
CE(pt)=-log(pt)
(5)
其中:
(6)
pt是某事件發生的概率,pt屬于[0,1].對于多分類情況,實際為二分類擴展,如公式(7)所示:
(7)
其中M為類別數量,yc指示變量,如果樣本預測類別和該類別相同則為1,否則為0,pc為預測樣本屬于類別c的概率.
3.2 引入權重的Focal Loss 算法
傳統交叉熵作為損失函數時,未考慮到簡單樣本和困難樣本對模型優化的貢獻程度差異,數量多且簡單的樣本占loss優化的絕大部分,此類樣本容易分類loss值較低,相對而言,數量少的困難樣本對loss的優化貢獻下降,導致模型的優化方向并不理想.故本文提出了基于Bert遷移學習模型fine tuning時,采用重塑交叉熵損失的方法Focal Loss,降低被良好分類樣本的損失權重,并把重點放在稀疏的困難樣本上,即情感傾向較難劃分,預測概率較低的一類樣本.以優化損失函數,進一步提升情感多分類模型效果.
首先在傳統交叉熵基礎上,添加了調制因子(1-pt)γ,計算公式為式(8):
FL(pt)=-(1-pt)γlog(pt)
(8)
其中(1-pt)γ為調制因子,γ∈[0,5]為聚焦參數,γ取不同值對結果影響不同,當γ=0時,FL=CE,等于傳統的交叉熵函數;當γ>0時,降低了簡單樣本的相對損失值,進而將注意力放在困難樣本和分錯的樣本上.例如當pt=0.9且γ=2時,FL=0.01CE,即得分越高pt越接近1,損失權重越小,簡單樣本對損失函數的影響越小;相反,當pt=0.2且γ=2時,FL=0.64CE,這樣得分值越低pt越接近0,損失權重越大,而不是將CE同比降低,困難樣本對損失函數的影響越大.因此,在訓練過程中加強了困難樣本的訓練,對簡單樣本減少訓練.
FL(pt)=-α(1-pt)γlog(pt)
(9)
進一步α作為平衡權重,如式(9)所示,α∈[0,1],控制正負樣本對總的loss的共享權重,調節縮放比例.FocalLoss同時在一定程度上能緩解數據不均衡問題,無論哪種類別數據較少,由于樣本少導致在實際訓練過程中更容易判錯,種類特征學習不夠,置信度也變低,損失也隨之增大.同時在學習過程中逐漸拋棄簡單樣本,因此,剩下了各類別的困難樣本,可以達到同樣的訓練優化目的.
3.3 情感分類模型訓練流程
具體基于Bert與Focal Loss的情感分類模型微調流程如圖4所示,首先對標注的微博語料進行數據預處理,包括去除無關字符,特殊符號等;然后進行分詞,根據position embeddings、token embeddings、segmentation embeddings得到Bert的輸入向量表示;輸入到經過初始化的預訓練Bert模型中,利用分類器預測值與真實標簽值對比并通過Focal Loss算法得到損失值;最后優化器進行優化調整權重參數,重復fine tuning過程直至迭代結束.
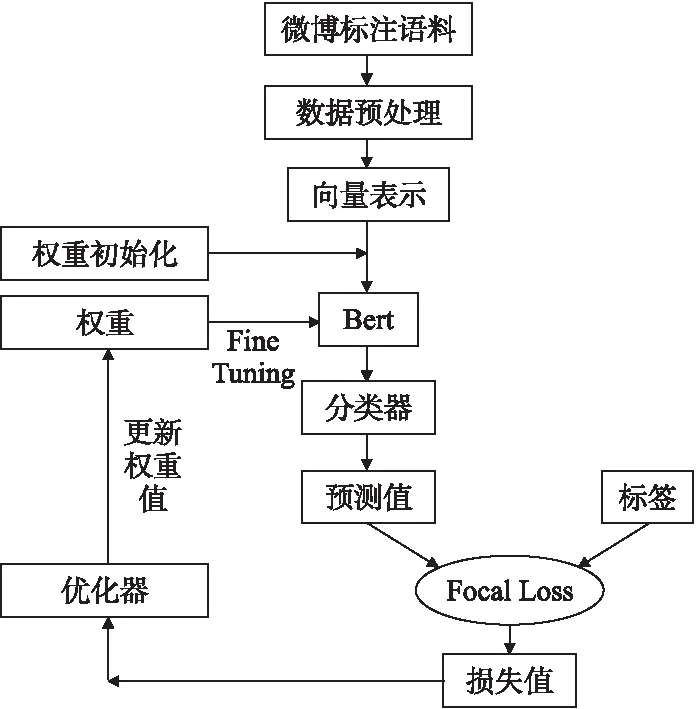
圖4 Bert-FL模型訓練流程Fig.4 Training process of Bert-FL model
4 實驗與分析
4.1 實驗數據
本文數據是針對廣播電視領域,通過網絡爬蟲爬取新浪微博某時間段熱點話題評論數據,通過人工對微博評論數據的情感傾向進行標注整理,得出積極正面語料5027條,消極負面語料5058條,中性語料9939條,共計20208條數據集.
微博數據內容不規范,通常包含一些與情感分類無關的符號,例如網址鏈接url,話題內容“#話題#”,“@用戶”,類似的這些字符并不是人們想要表達的信息,這些無用的信息可能對接下來的情感分類效果造成一些影響.所以首先要刪除過濾掉這類無關字符,一般通過正則表達的方法來處理,去除特定字符進而保留文本的主要內容.在運行各算法之前,通常要對文本分詞,本實驗統一采用jieba來分詞.另外,根據個別算法的要求,有時也需要對停用詞進行處理,對照停用表將其去除.將預處理后的數據存放在本地數據庫中,進行下一步語料庫的劃分,其中每個類別隨機抽取439條,共計1317條用作測試集.剩下每個類別隨機抽取90%用于訓練構建模型,10%用于驗證調整模型參數.詳見表1.
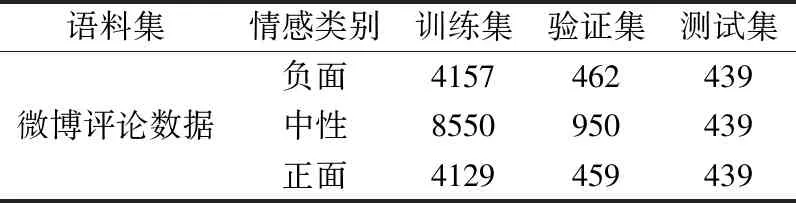
表1 數據集劃分Table 1 Date set partition
4.2 評價指標
準確率(Accuracy)是在衡量文本分類結果時常用的直觀的評價指標.它是在測試文本中,預測標簽與實際標簽吻合的文本所占的比率.計算公式為:
(10)
預測時長是指在同等文本數量情況下,各模型完成預測所占用的時間.
4.3 結果及分析
為驗證雙向語義編碼表示Bert的有效性,實驗首先構建Bert網絡結構,并用同樣的數據集在一些經典情感分類方法上進行訓練預測,多次訓練得出各自最優模型對比.
由于實驗數據是中文微博短文本,且微博規定評論內容不超過140個詞,結合實驗所用服務器的內存大小,故處理文本的最大長度設置為150,同時對過短為句子也不做處理.Bert模型訓練的具體參數如表2所示.實驗在Linux CentOS 7.3.1611下進行,采用Anaconda虛擬環境編程,實驗基于Tensorflow 1.11.0和Pytorch 1.3.0深度學習框架來搭建模型,并使用兩塊TITAN X(Pascal)GPU來運行模型.

表2 Bert超參數設置Table 2 Bert hyperparameter setting
實驗結果如表3所示,從實驗結果可以看出,在整體準確率方面,基于預訓練的遷移學習模型都在90%以上,均優于從頭訓練的網絡模型,其中Bert的分類準確率最高,達到91.56%.由于Transformer編碼器在處理文本序列時,序列中單詞之間不受距離的限制,任意單詞之間的關系都可以捕獲.一定程度證明Transformer編碼器效果優于LSTM.TextCNN準確率最低,因為其提取的局部特征在任務中會缺失部分前后相關語義信息.LSTM準確率相較于TextCNN提升不明顯原因可能是大部分句子長度較短,簡單的單向LSTM并沒有發揮提取長期特征的優勢.但在分類速度上,TextCNN的分類速度遠遠超過遷移學習類模型,僅需1s,原因是CNN其權重共享特征,參數大大減少,Bert模型速度最慢.另外無論LSTM與Transformer網絡結構都相對復雜一些.對比試驗表明,Bert模型在短文本情感分類任務中準確率最高,但分類速度表現略差.
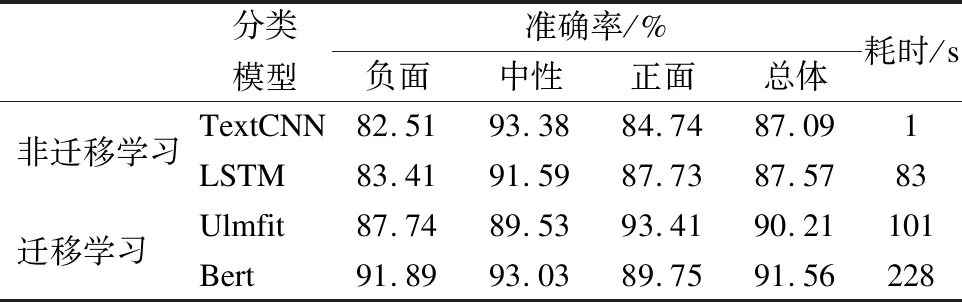
表3 各模型分類結果對比表Table 3 Comparison table of classification results of each model
雖然Bert網絡模型整體預測準確率略有提升,但由于數據中存在情感傾向較難區分的句子,這些因素都不同程度對分類準確率造成了影響.為解決此問題,進一步構建基于Focal Loss的Bert模型,進行多組實驗,選出最優權重因子α參數,如表4所示.

表4 Bert-FL不同參數在測試集的表現Table 4 Performance of different Bert-FLparameters in the test set
由表4可以看出,當γ= 2且α= 0.75時,能達到最高準確率92.39%,證明了此參數更適合本次情感分類任務.同時與Bert的最高準確率91.56%相比,提升0.83%,可以得出,此方法在整體準確率上略有提升.各類別預測結果如表5所示,對比實驗結果表明,改進后的Bert-FL模型在數據相對較少的負面和正面的分類準確率均有一定提升,整體準確率分布更加均衡.
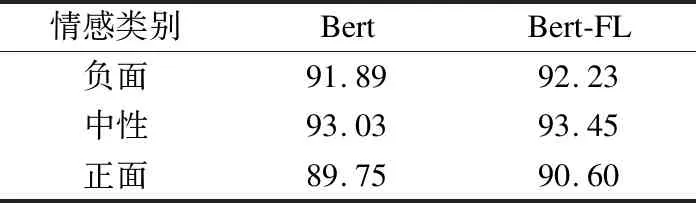
表5 各情感類別準確率對比Table 5 Comparison of accuracy rates of various emotion categories
為進一步驗證Focal Loss對困難樣本的學習能力,實驗從439條測試集中人工篩選出408條簡單樣本,31條困難樣本進行測試.Bert和Bert-FL 在簡單/困難樣本中的表現如表6所示.

表6 Bert-FL在簡單/困難樣本中的表現Table 6 Performance of Bert-FL in easy / hard samples
由表6可以看出,將Bert的損失函數替換成Focal Loss后,簡單樣本的準確率變化不明顯,而對于31條困難樣本預測準確率,模型有一定程度的提升.這是因為簡單樣本置信度高,損失小,權重因子α與γ參數的作用使得損失變化更小,參數更新越微小;與之相比,困難樣本置信度低,損失較大,優

表7 各類別例句Table 7 Example sentences for various category
化器著重學習此類樣本.實驗結果一定程度驗證了改進后的算法在不影響簡單樣本分類效果的情況下,提升了困難樣本的分類準確率.證明了該算法的可行性與有效性.表7展示了數據集中正面、中性、負面3類別例句以及困難樣本例句.
5 結束語
本文在面向廣播電視微博領域的中文短文本情感多分類任務中,提出了Bert作為預訓練模型初始化網絡參數,在模型微調時刻采用Focal Loss替代交叉熵,一定程度緩解訓練數據稀疏的困難樣本和較多的簡單樣本對分類器學習貢獻度不同的問題.該方法仍然有不足之處,訓練模型大及參數過多,預測時間長等.在今后的研究工作中將繼續優化算法模型,改進模型缺點.提升模型在工程中的應用效果.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
