基于深度前編碼卷積網絡的漢越語音翻譯方法
2021-04-12 09:50:48許樹理余正濤王振晗梁仁鳳
小型微型計算機系統 2021年4期
王 劍,許樹理,余正濤,王振晗,梁仁鳳
(昆明理工大學 信息工程與自動化學院,昆明 650500) (昆明理工大學 云南省人工智能重點實驗室,昆明 650500)
1 引 言
隨著中國和“一帶一路”沿線國家的交流日益密切,在會議演講、視頻直播等應用場景現有文本到文本的機器翻譯技術[1,2]已不能滿足實際需求.因此出現了語音翻譯技術,通過語音翻譯能夠將源語言的語音轉化為目標語言的文本,緩解不同語言之間存在的交流障礙.
目前語音翻譯主要有兩種實現形式,一種是通過語音識別[3,4]和機器翻譯構建級聯系統,先將源語言語音轉錄為源語言文本再進行翻譯,另一種是通過端到端的語音翻譯技術,直接將源語言的語音轉化為目標語言的文本,實現語音到文本的翻譯.在漢越語音翻譯中,語料的稀缺性加劇了不同系統間的錯誤傳遞,訓練可用的級聯系統十分困難[5],因此使用端到端系統進行語音翻譯,更能滿足實際應用需求,也是當前研究的熱點.
端到端語音翻譯系統一般由序列到序列模型實現[6-8],與基于純粹文本的機器翻譯不同,源語言語音會以頻譜圖的形式作為模型輸入,頻譜圖由時域和頻域兩個維度的信息組成,有效地提取頻譜圖中的時頻特征,成為提升模型質量的重要手段.另外,由于模型輸入輸出跨越模態,在表征相同語義時,音頻序列遠長于文本序列,往往多個音頻幀對應一個文本標識.音頻序列的這個特點,在基于多頭注意力機制的Transformer的編碼的過程中[9],會由于注意力計算的全局性,導致注意力被稀釋在過長的序列中,分散模型對音頻序列中重要的短距離依賴應有的注意,產生局部依賴建模能力不足的問題[10].同時,音頻序列較長的特性還會造成模型參數規模過大,占用資源過多影響模型的訓練速度.針對這些問題,本文提出基于深度前編碼卷積網絡的Transformer(Deep Residual Convolutional Transformer),利用卷積神經網絡在音頻下采樣及局部特征提取的優勢,增強模型對音頻頻譜時域和頻域的綜合表征能力及效率,輔助Transformer對于局部依賴的建模,同時引入距離懲罰機制強迫Transformer偏袒局部依賴等方式,提高了語音翻譯的質量.
2 相關工作
近年來,國內外許多學者針對語音翻譯相關技術開展了深入的研究,并取得了一定進展.其中,語音到文本的語料庫是語音翻譯的基礎,在語音語料庫構建方面,Bérard等人[8,11]利用語音合成技術生成語音語料的方式,使用法英雙語語料庫BTEC構建了法語語音到英語文本的語音語料庫[8],并于2018年通過將英文有聲書和其法語譯文對齊的方式,構建了增強的LibriSpeech英法語音翻譯語料庫[11],這為語音翻譯研究提供了支持,也為構建漢越語料庫提供了一種思路.語音識別是級聯語音翻譯的基礎,并且由于語音識別與語音翻譯任務相似,同樣是將音頻序列并轉化為文本的過程,語音識別的相關方法在端到端語音翻譯有很多可以借鑒的地方,在語音識別方法研究方面,Chorowski等人[12]提出基于注意力機制的語音識別方法,使用基于注意力的循環序列生成器對音頻序列進行編碼解碼,并通過卷積注意力機制進行注意力權重計算,使模型在解碼時避免重復注意到相同特征,進而取得了良好的效果.Zhang等[13]提出基于深度卷積神經網絡的語音識別方法,通過堆疊多層卷積神經網絡、卷積長短時記憶網絡及膠囊網絡,增強編碼器的表達能力,降低了語音識別的詞錯率.基于以上研究工作的支撐,在語音翻譯模型研究方面,2016年Bérard等人[8]在Chorowski等人[12]提出的語音識別模型的基礎上,使用層級LSTM編碼器與帶有卷積注意力機制的解碼器,實現了端到端的語音到文本翻譯,在與Google語音識別和統計機器翻譯構成的級聯翻譯系統對比后,證明端到端的語音翻譯系統能夠獲得相近的性能.2017年Weiss等人[14]提出一種基于深度循環神經網絡的語音翻譯方法,通過加深解碼器神經網絡層數,并采用多任務學習方法訓練語音翻譯模型,使端到端的語音翻譯性能超過以往級聯方式構建的語音翻譯系統.2018年Bansal等人[5],在Weiss等人[14]的基礎上,通過降低輸入頻譜的維度,縮減模型參數規模,使用詞級文本解碼器等方式,使模型在單張顯卡的計算資源以及小規模數據集的條件下,表現出良好的性能.2019年Gangi等人[10]將Transformer模型引入語音翻譯,通過使用對數距離懲罰機制,使模型偏袒編碼序列中的局部依賴關系,取得了很好的效果.
3 模 型
端到端語音翻譯技術取得了快速的進展,但在相關工作中,模型在編碼階段前,僅對音頻進行下采樣緩解編碼器的計算壓力[15],忽略了在編碼階段前對頻譜圖進行深層次的時頻信息處理.另外,在使用Transformer構建語音翻譯模型時,其全局注意力機制的計算方式會對局部依賴建模造成阻礙[10].卷積神經網絡利用較小的卷積核,在二維的頻譜圖上進行卷積操作的方式,在頻譜圖中的時頻信息提取以及局部依賴建模方面具有獨特的優勢[13].因此,本文基于深度卷積網絡,增加音頻深度前編碼過程,在音頻下采樣及局部特征提取時,增強模型對音頻頻譜時域和頻域的綜合表征能力,同時引入距離懲罰機制強迫Transformer偏袒局部依賴等方式,解決局部依賴建模能力不足的問題,構建基于深度前編碼卷積網絡的漢越語音翻譯模型結構如圖1所示.
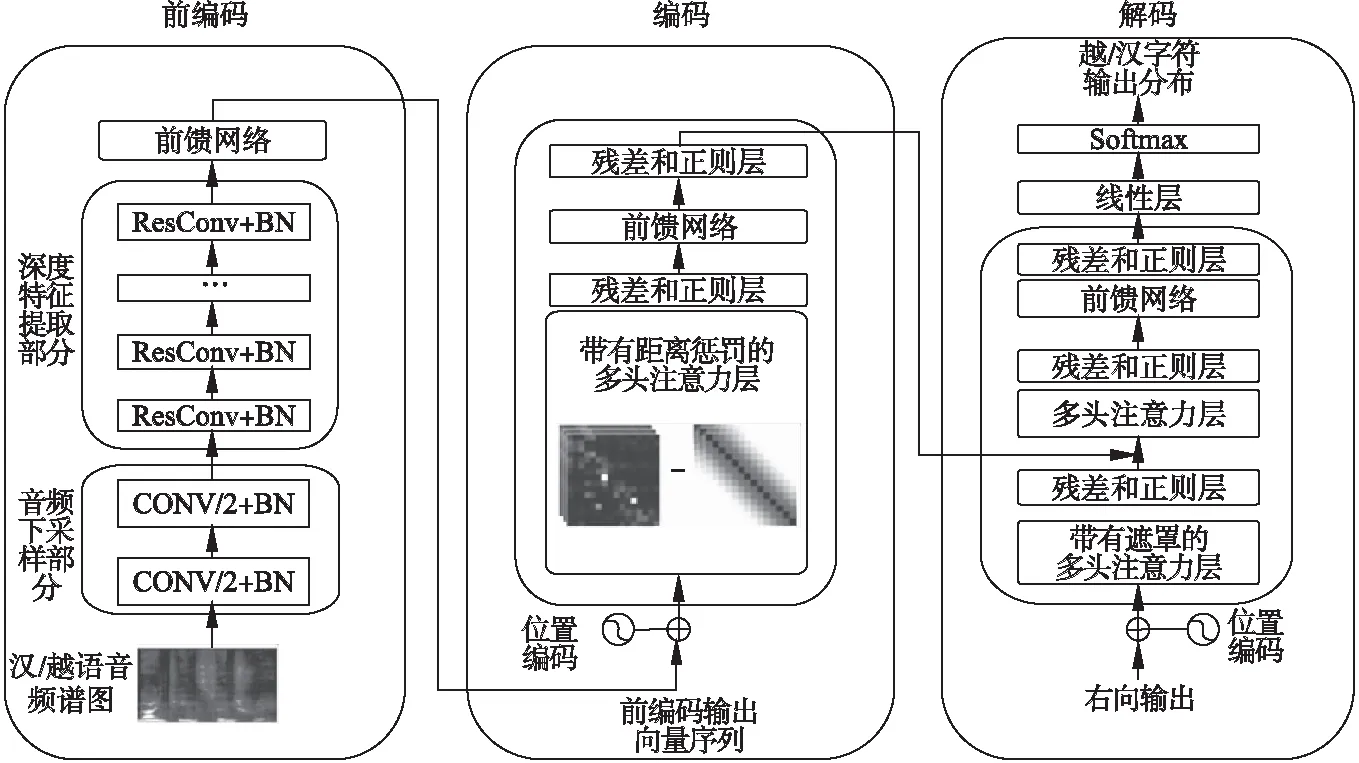
圖1 模型結構圖Fig.1 Architecture of the model
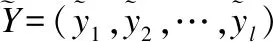
(1)
3.1 前編碼
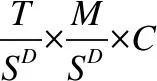
X′=BatchNorm(W*X)+X
(2)
3.2 編碼與解碼
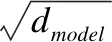
(3)
Transformer通過多頭注意力機制MHA(Q,K,V),將輸入映射到h個不同子空間進行注意力計算.通過堆疊Nc層多頭注意力子層,并在每個子層間引入殘差和層規范化提升模型的泛化能力,對輸入序列內部的依賴關系Hn=MHA(Hn-1,Hn-1,Hn-1)進行建模,其中H0為經過Position Embedding處理的前編碼輸出向量,HNc為編碼器輸出.
本文在編碼器中使用對數距離懲罰機制對注意力函數中的相似性得分進行重新計算,使得編碼器偏袒針對局部依賴的特征提取,將公式(3)改寫為:
(4)
其中,D是以di,j為元素的距離矩陣,其中di,j=|i-j|,πlog是距離懲罰函數,如公式(5)所示:
(5)
在解碼端,通過兩組多頭注意力,將目標序列內部的依賴關系Fn=MHA(Sn-1,Sn-1,Sn-1)和目標語言端與編碼端的依賴關系Gn=MHA(F,HNc,HNc)進行建模,經全連接網絡變換得到Sn=FFN(Gn)其中S0為初始目標端字符向量.將解碼器頂層隱狀態SNc映射到目標端詞表空間,經SoftMax得到目標端詞表上的概率分布作為模型輸出分布,其中當音頻輸入為漢語時解碼器生成字母級的越南語輸出分布,當音頻輸入為越南語時解碼器生成字符級的漢語輸出分布.
4 實驗與結果分析
4.1 數據準備
為了進行漢越語音翻譯的對比試驗,構建了13萬漢越雙語語音到文本語料庫,具體設置見表1.
如表1所示,其中訓練集包含12萬對,驗證集和測試集各包含5000對.由于語音翻譯語料獲取的難度,本文通過Google語音合成服務,將13萬漢越文本轉化為約220小時的漢越語音,包含男聲和女聲各兩種音色,通過與音頻文本對齊構建了漢越語音翻譯語料庫.在以上語料庫中,語音語料均通過預處理,轉化為步長為10毫秒,窗口大小為25毫秒,維度為40的梅爾倒頻譜filter-banks頻譜圖.
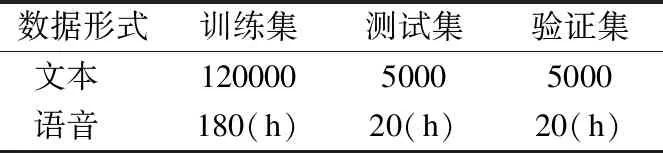
表1 實驗數據規模Table 1 Scaleofexperimentdata
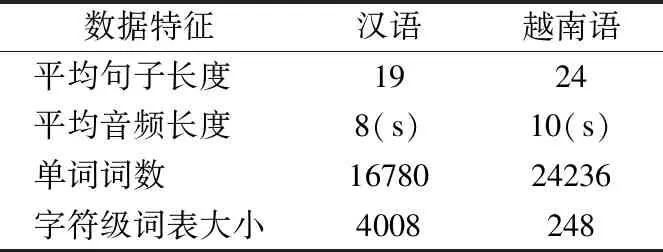
表2 實驗數據特征Table 2 Featureofexperimentdata
為說明本文構建語料庫的一般性,現對漢越雙語構建的文本及合成音頻進行分析,具體數據特征見表2.
漢越雙語的在本語料庫中的平均句子長度分別為19個詞和24個詞,生成的音頻平均長度分別為8秒和10秒,文本中分別包含16780個詞和24236個詞.另外,由于本文采用了字符級的文本解碼器,所以構建了以字符為單元的詞表,其中漢語為字符文字而越南語字母文字,因此由漢語語料及越南語語料生成的詞表大小相差很大,其中越南語的詞表大小為248,漢語詞表大小為4008.
4.2 實驗環境及參數設置
本文使用PyTorch1.2搭建模型,使用標簽平滑交叉熵損失作為目標函數,標簽平滑率為0.1,梯度裁剪為20,編解碼隱藏層向量為768維.訓練時,通過Adam優化器進行優化,通過inverse sqrt動態調整學習率.
4.3 基線模型
為了證明提出方法的效果,選取以下幾種最新方法進行對比實驗:
1)級聯系統,通過語音識別系統將源語言語音識別為源語言文本,然后再將源語言文本通過文本機器翻譯模型翻譯為目標語言文本,其中語音識別系統和文本機器翻譯均基于Transformer在本文數據集上進行訓練.
2)Bérard等人[8]提出的基于帶有跨度的卷積神經網絡進行下采樣,然后通過BiLSTM進行序列建模的端到端語音翻譯系統(以下簡稱CNN+BiLSTM).
4.4 實驗與結果分析
為了驗證本文方法的有效性,采用不同方法在構建的數據集上進行對比實驗,不同方法語音翻譯實驗結果見表3.
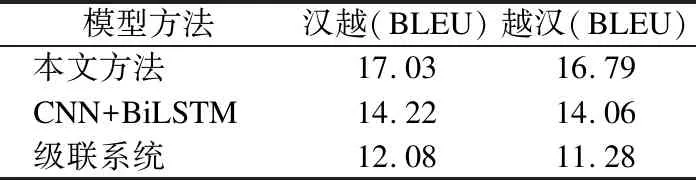
表3 不同方法的語音翻譯實驗結果Table 3 Results of different models
從表3數據可以看出,本文提出的方法與級聯系統相比,不存在錯誤傳播的問題,由于不需要大量語音識別語料訓練語音識別器,本文方法采用的端到端網絡架構更適合漢越雙語這樣的資源稀缺性的語言對,實驗結果表現出了相較級聯系統性能提升顯著.相比CNN+BiLSTM,由于LSTM使用細胞狀態向量表征上下文信息并帶有一定的遺忘機制,其對于局部依賴的建模要優于進行全局相似度計算的Transformer,但是由于本文方法采用了深層次的前編碼卷積網絡和基于距離懲罰的Transformer網絡,顯著提高了模型對于局部依賴的建模能力以及對于音頻頻譜圖的時頻信息提取能力,使得Transformer對于序列的編解碼能力獲得了充分的發揮,實驗結果證明本文方法相較CNN+BiLSTM在漢越和越漢語音翻譯上性能均得到了19%的提高.
為驗證提出模型各部分的有效性,分別將各層消去進行比較實驗,得到對比實驗結果見表4.

表4 消融實驗結果Table 4 Results of ablation experiment
分析表4可知,本文方法的各個部分對于語音翻譯具有實際作用,不使用前編碼深度特征提取時,漢-越、越-漢語音翻譯BLEU值均有顯著降低,由此可見在前編碼階段采用更深層次的卷積模型對音頻頻譜圖進行深層特征提取,對于后期Transformer進行序列建模的質量提升有明顯效果.不使用距離懲罰時,由于Transformer基于全局的相似度計算存在的局部依賴建模問題阻礙了模型性能的發揮,導致模型性能降低了約1個BLEU值.由此可見,本文提出的方法在幫助Transformer進行更好的序列表征以及局部依賴建模方面具有良好的效果.
為驗證卷積網絡深度對于模型性能的影響,進行了不同前編碼層次性能對比實驗,實驗結果見表5.

表5 前編碼卷積網絡深度性能對比Table 5 Results of different pre-encoder
從表5數據可以看出,前編碼深度特征提取部分層數不同對模型會產生一定的影響,其中Conv/2代表跨度為2的卷積層,實驗發現通過堆疊2層步長為2,4層步長為1的卷積層模型性能表現最佳,這可能由于第2組前編碼結構的感受野,恰好可以使得前編碼輸出的單個表征向量的信息完整覆蓋頻譜圖所有維度.而第3、4組前編碼結構可能存在過擬合的問題導致未取得最佳性能.由此可見,前編碼深度特征提取部分對于音頻頻譜圖時域頻域綜合特征的提取,可以幫助模型得到更好的音頻序列時頻表征,進而提高模型性能.
5 總 結
本文基于深度前編碼卷積網絡和Transformer的端到端語音翻譯模型,提出了在編碼階段前對音頻頻譜利用卷積神經網絡進行深度處理,可以輔助Transformer對于頻譜圖中時頻信息和局部依賴的建模.實驗結果也證明了提出方法的有效性,可以有效提升模型效果.深度前編碼對語音翻譯有很好的支撐作用.下一步研究中,擬針對漢越語音翻譯平行語料獲取難度較大的問題,結合語音識別語料庫相對豐富的特點,探索基于語音識別與機器翻譯多任務聯合學習方法,利用語音識別相關模型和語料,增強語音翻譯模型性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
