稠密特征編碼的遙感場景分類算法
2021-04-12 09:50:48李國祥馬文斌王繼軍
小型微型計算機系統 2021年4期
李國祥,馬文斌,王繼軍
1(廣西財經學院 教務處,南寧 530003) 2(廣西師范大學 廣西多源信息挖掘與安全重點實驗室,廣西 桂林 541004) 3(廣西財經學院 信息與統計學院,南寧 530003)
1 引 言
遙感圖像分類作為遙感圖像處理的重要研究方向,是遙感技術開展廣泛應用的一個重要技術支撐.隨著遙感技術的發展,遙感影像的空間分辨率不斷提高,其中所包含的幾何、紋理、結構,以及豐富的內容場景信息,為目標精準識別和檢索任務提供了重要參考,也為遙感分類提出了更大的挑戰.有效提高圖像解譯的性能,提取能夠有效代表圖像內容的特征,實現精準的特征表達,是下一步遙感圖像檢索,目標識別的重要前提.
近年來,眾多特征提取算法用于遙感圖像的分類與檢索,特征呈現出多樣化、精細化和深度化的特點,研究者也對遙感圖像場景分類中不同特征提取策略進行分類總結和定量評估[1].目前根據特征所表達的低中高層次的圖像語義,普遍將遙感圖像的特征分為3類:1)代表圖像底層語義的原始圖像基本特征,如一些能夠代表圖像全局或局部特征的描述子,如HU矩、紋理特征、經典描述子SIFT[2]、LBP等,以及眾多在原有特征描述子的基礎上開展的優化,SURF、Affine-SIFT[3]、HOG[4]、BRIEF.這些特征作為初始特征可以直接輸入分類器中進行分類.趙理君等[5]對遙感數據分類中的經典分類方法K近鄰、隨機森林、支持向量機和稀疏表達分類器做了細致的對比研究;2)代表圖像中層語義的編碼特征.這些是在圖像原始特征的基礎上通過編碼等方式形成更為細膩的圖像特征.其中BoVW模型作為該類特征的典型代表,自提出以來在圖像檢索、分類等領域得到了廣泛應用,它的主要思想是將特征描述子聚類成為若干個“詞袋”,根據各特征點聚類的歸屬形成一定維度的統計直方圖,該直方圖替代特征描述子作為分類器的特征輸入.以及其他對詞袋模型進行的改進編碼,例如,對每一個統計詞袋進行加權的TF~IDF[6],對圖像進行多尺度劃分的SPM[7],保存每一個特征點與最近聚類中心距離的VLAD[8]等等;3)特征則是基于卷積神經網絡的深度學習特征.隨著卷積神經網絡被大量引入遙感圖像處理領域,其全連接層的高維向量在遙感圖像分類中效果優異.一般將經過大規模圖像訓練的Alexnet、VGG16等CNN模型遷移至遙感數據集中進行參數精細調整,并提取某一全連接層作為深度特征,或者進一步編碼融合.龔希等[9]分別提取了VGG19的全連接層特征和卷積層特征,并將卷積層特征采用BOVW編碼,與全連接層特征共同形成新的特征向量.李亞飛等[10]在Alexnet基礎上修改了網絡結構,去掉了一部分卷積層和池化層,使用光譜特征向量、紋理特征矩陣、亮度、綠度和濕度等形成混合特征,作為CNN的輸入.張曉男等[11]將多種主流卷積神經網絡集成,通過使用BP神經網絡進行圖像復雜度度量,確定對于該類圖像所采用的卷積神經網絡,進而提高分類精確度、減少分類時間.同時,越來越多深度學習特征融合的方法應用在遙感圖像分類中.劉異等[12]將Fisher核編碼和CaffeNet全連接層特征結合到一起形成新的特征向量.FAN等[13]提取最后一層卷積層特征作為特征向量并進行BOW等編碼.
從目前的對于圖像檢索分類的研究來看,代表高層語義特征的深度學習方法較其他方法分類精度高,但是對于計算環境要求苛刻,即便是在高性能GPU運算的情況下,在大樣本數據集中所需要的時間也是動輒計算幾天,計算成本和時間成本在一定程度上限制了適用范圍.為此,本文以中低層語義特征為基礎,通過不同尺度稠密特征的提取和編碼,提升特征提取策略的表征能力,在一定程度上兼顧圖像分類速度和分類精確度的平衡.
2 DenseSIFT
傳統SIFT特征通常采用高斯差分函數構建圖像的多尺度空間結構,然后在高斯差分空間中檢測極值點并從中篩選出有效的特征采樣點,計算方式復雜.Dense SIFT 特征則不需要在高斯尺度空間上提取特征點,通過對圖像高斯平滑,建立一定尺寸和步長采樣窗口在圖像采集域內滑動均勻采樣,提取采樣窗口中心點坐標和窗口內每個像素8個方向上的梯度,形成與SIFT同等維度特征向量.稠密特征廣泛的應用于視頻追蹤[14]、人臉識別等[15]領域.為了進一步提升特征應對場景復雜變換的能力,我們對原圖進行尺度變換,在原圖與四倍下采樣之間對數等分生成5個不同尺度圖像,提取不同尺度下的稠密特征并將其合并成為特征陣列,最后利用Hellinger kernel實現原始特征在新的RootSift空間映射[16].
設x,y為不同尺度下稠密特征合并后的特征向量,且‖x‖=1,‖y‖=1,則二者的歐式距離可以表示為:
(1)
通過Hellinger映射:
(2)
對特征向量x,y取平方根,從而將相似性測量的歐氏距離映射至Hellinger距離:
(3)
最后將映射后的特征向量進行主成分分析,形成新的低維度的稠密穩健特征.這里我們將特征前兩個主分量可視化,如圖1所示,可見主分量可以有效的表達遙感圖像不同場景語義特征.

圖1 特征向量的可視化Fig.1 Visualization of feature vectors
3 稠密特征編碼的遙感圖像特征提取
3.1 Fisher核編碼
Fisher 核編碼是利用Fisher kernel形成圖像緊湊特征的表示,其本質是用似然函數的梯度向量來表達一幅圖像,即用高斯混合模型(GMM)輸出的向量表示一幅圖像.設圖像有T個描述子,則圖像可表示為X={xt,t=1…T}.因圖像特征獨立同分布,圖像的概率分布可表示為所有特征概率分布的乘積:
(4)
式中,λ={ωi,μi,σi,i=1…N},是GMM的模型參數,ωi是GMM第i個成分的權重,μi,σi是其均值和協方差.取對數后可表示為對數概率之和:
(5)
圖像特征xt的概率分布函數可表示為:
(6)
式中,pi是GMM中第i個成分的概率分布函數,該概率分布函數是多元高斯函數,ωi是其權重,公式如下:
(7)
此外,定義特征xt由第i個高斯分布生成的概率為:
(8)
根據上述公式,對公式(5)求導,其偏導數即可作為編碼后的特征向量:
(9)
式中,i表示GMM的第i個成分,d表示特征xt的第d維.因偏導計算涉及每個成分和特征的每個維度,所以UX的維度是(2D+1)*N-1.偏導計算公式如下:
(10)
(11)
(12)
引入3個Fisher矩陣對其歸一化:
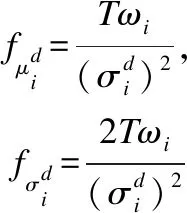
(13)
歸一化后的特征向量Fisher Vector為:
(14)
經過不同Gaussians數量編碼后的特征在分類效果上相對穩定,小數量Gaussians的編碼即可得到穩定特征,非常適合于簡單的線性核分類器,進一步降低樣本分類的計算時間.同時在編碼過程中一方面通過金子塔模型提取空間特征信息、編碼特征的L2 Normalization和Power normalization提升Fisher編碼效果[17],另一方面有效的特征降維和白化,同樣能夠明顯提升類分類精確度[18].
3.2 稠密特征編碼的特征提取算法
提取遙感圖像不同尺度下的稠密特征,對其映射變換并進行主成分降維和白化,形成低維度的非壓縮特征.在此之上利用Fisher編碼壓縮量化,形成緊湊的編碼特征,最后將其歸一化作為線性支持向量機的輸入,完成遙感影像的場景分類.算法流程如圖2所示.

圖2 算法流程圖Fig.2 Algorithm flow chart
4 實 驗
4.1 實驗數據集
為了驗證本文方法的有效性,本實驗在3個通用的遙感數據集上進行測試分析.第1個數據集為UC Merced Land Use Dataset[19],該數據集于2010年發布,每張圖片像素大小為256×256,21類不同的遙感場景,每一類100張,共計2100張.第2個數據集為WHU-RS19 Data Set[20],該數據集由武漢大學Yang等人提供,整個數據集包含19類場景,每一類約為50張,每個圖像尺寸為600×600,總共1005張.第3個數據集是NWPU-RESISC45數據集[21],于2017年發布,包含飛機、機場、棒球場等45個場景類別,每個場景類別包含700幅大小為256×256的圖像,共包含31500幅遙感圖像,場景類別豐富,類內多樣性和類間相似性較高,對遙感圖像場景分類方法具有更高的挑戰性.對于以上3個數據集每類場景分別隨機選取50%的圖像作為訓練數據集,剩余的圖像作為測試數據集,且數據集未通過旋轉、縮放、移位、翻轉等手段進行數據增強.
這里分別將本文算法(DRFV)與傳統特征編碼方法BOW,BOW+SPM,BOW+PCA,VLAD,也與深度學習的Alexnet[22],VGG16[21],INceptionresnetv2[23]方法做了對比.為保證實驗的可靠性,每一種算法隨機進行10次.深度學習方法設置訓練周期5,學習率0.0003,驗證頻率10.試驗硬件環境為:Xeon(R)CPU Gold-6128;軟件環境為Matlab 2019a.
4.2 實驗結果與分析
4.2.1 Gaussians數量對于精確度的影響分析
雖然不同的GMM數量所帶來的分類效果略有不同,但小數量的Gaussians即可得到較為穩定特征,一方面小數量GMM可以降低特征維度,另一方面整個算法減少參數選擇調優的過程.實驗中我們采用32-1024間6類Gaussians數量來編碼,表1顯示了不同Gaussians數量的分類效果,在不同的數據集中,隨著高斯模型數量的增加,分類精度有著不同程度的提高,但基本在256左右趨于穩定,當Gaussians數量提高至512時,3個數據集分類精度平均僅提高0.63%,而在增加至1024,UCM數據集的分類精度反而下降,WHU和NWPU數據集的分類精度也沒有明顯增加.同時Fisher編碼的特征維度是與Gaussians數量息息相關的,過為精細的特征,在數據樣本有限的情況下,反而容易引起不同圖像間的混淆.

表1 不同Gaussians數量的分類精確度Table 1 Classification accuracy of different Gaussians numbers
4.2.2 主成分分量對于分類的影響
眾多文獻都對主成分分量對于檢索或分類的影響進行了研究[24-26],其中SáNCHEZ[26]在PASCAL VOC 2007數據集中驗證了不同維度特征對于提高Fisher編碼分類準確度的有效性.鑒于遙感圖像不同于普通圖像,這里我們分別以圖1的前兩幅圖像為例,對其進行了主成分分量的貢獻度分析,并在3個實驗集中,對不同維度PCA特征的分類精度做了驗證,如圖3所示,可見遙感圖像前50維的特征分量貢獻度已經超過90%,結合3個實驗集中不同維度特征的分類精度可知,主成分分量在60-80左右時整體的分類精度已經趨于穩定,分量的繼續增加并沒有帶來分類精確度質的提升.因此,充分考慮在不同數據集圖像中實現較高的貢獻度和分類精度,我們的分類實驗采用80維特征.

圖3 不同主成分分量的分類精確度Fig.3 Classification accuracy of different principal components
4.2.3 運行時間對比
算法的時效性也是決定能否在大規模遙感圖像分類廣泛應用的重要因素.雖然深度學習在精度上略優于編碼算法,但是高昂的計算成本使得時間復雜度較大.由于計算時間是與數據集中圖像數量和分辨率成正比,所以這里我們僅選用UC Merced數據集為代表,在沒有GPU加速和并行優化處理的情況下,我們分別使用30%和50%作為訓練樣本比較不同算法的時間復雜度.深度學習方法中VGG16和InceptionResNetv2,30%訓練樣本耗時近10000秒,50%訓練樣本InceptionResNetv2高達25000秒,雖然在3種深度學習方法中Alexnet耗時最短,但也要1200秒左右,且都隨著訓練樣本的增加,計算時間增幅較大.本文算法則對兩個訓練集上時間相差不多,均為500秒左右,運算時間與其他編碼算法相近.

表2 不同算法在UC Merced 中運算時間(單位:秒)Table 2 Operation time of different algorithms in UC Merced
4.2.4 分類精度對比
這里分別在3個數據集中進行分類精度對比.本文采用平均分類精度、Kappa系數、混淆矩陣和運算箱型圖評價場景分類性能.總體分類精度的定義為:
(15)
式中,N代表總體樣本數,Z代表所有分類正確的樣本數.
混淆矩陣用于定量評估各類之間的混淆程度,矩陣的行和列分別代表真實和預測場景,矩陣中任意元素xij代表將第i種場景預測為第j種場景類別的圖像數:
Kappa系數由混淆矩陣計算得:
(16)
式中,N代表總體樣本數,K代表類別數,xij是混淆矩陣的對角元素,ai是混淆矩陣第i行元素總和,bi是混淆矩陣第i列元素總和.
表3顯示了不同算法的平均分類精度和Kappa值,在3個數據集中,本文算法的平均分類精確度遠遠超出傳統BOW系列算法和VLAD,尤其是在樣本規模較大的NWPU數據集中,超出BOW系列接近40%,超出VLAD近20%左右.與深度學習算法相比,在UCM中平均分類精度與其他3個深度學習算法分別相差1.26%、3.56%和1.06%,在WHU數據集,本文算法則超過了深度學習算法,達到最優分類精度91.12%.在NWPU數據集,限于樣本數量和硬件計算能力,InceptionresnetV2已無法在有效時間算出結果,VGG16在眾多算法中,分類精度最高,達到89.64%,本文算法則與Alexnet相近,達到了81.06%.因此,綜合不同數據集的平均分類效果來看,VGG16效果最好,其次是Alexnet和本文算法,二者僅相差0.74%,最后是其他算法.InceptionresnetV2對計算環境要求苛刻,限制了其在大數據集的應用范圍.

表3 不同數據集平均分類精度和Kappa值Table 3 Average classification accuracy and Kappa value of different data sets
多次隨機實驗的穩定性如圖4所示,在UCM和WHU數據集Alexnet和DRFV整體效果表現穩定,最大值都在90%以上.VGG16不同實驗結果偏離較大,其中WHU數據集的分類精度最大最小值相差近10%,且平均精度不高.InResNetV2表現一般,同樣存在分類穩定性的問題,還存在兩個異常偏低值.NWPU數據集中,VGG16和本文算法表現穩定,Alexnet不同的實驗有一定程度的偏差.其他算法在3個數據集的實驗表現一般,個別存在異常偏低值.因此,從多次隨機實驗結果的穩定角度來看,本文算法和Alexnet是明顯優于其他算法的.
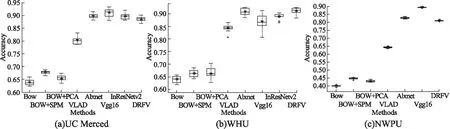
圖4 不同算法在不同數據集上的分類精度箱型圖Fig.4 Box graph of classification accuracy for different algorithms on different data sets
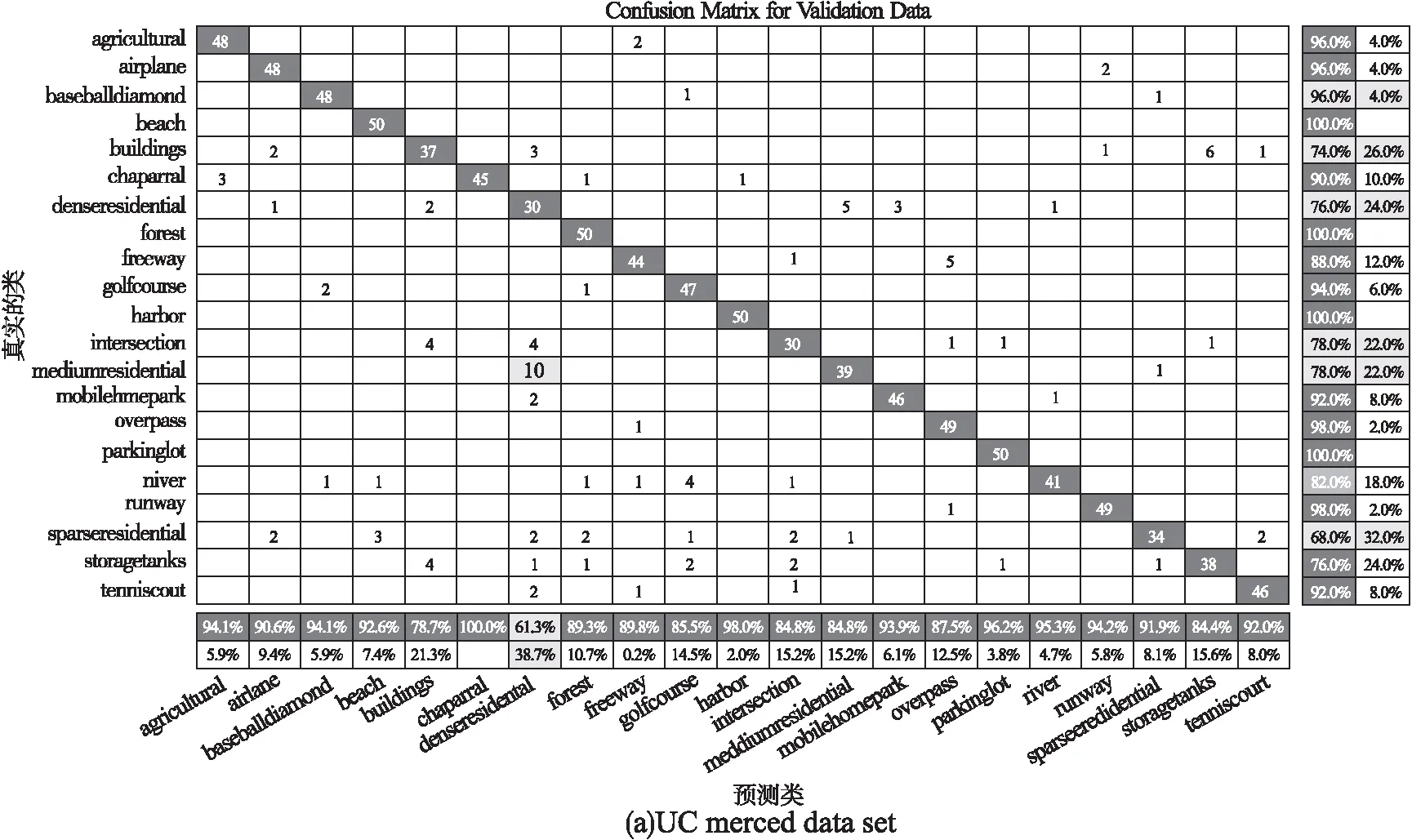
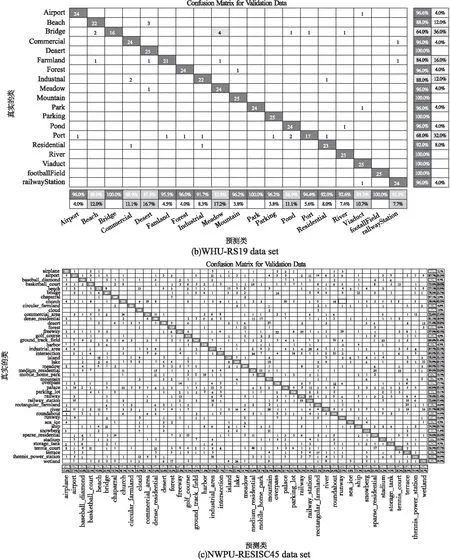
圖5 本文算法在不同數據集的混淆矩陣Fig.5 Confusion matrix of the algorithm in this paper on different data sets
圖5顯示了本文算法在3個數據集上的混淆矩陣,總體來看各類場景的分類準確率和召回率效果良好.但由于部分場景與其他場景有著高度的相似性,導致個別類召回率偏低.如UCM數據集的Bulidings、SparseResidential與DenseResidential、Forest等,WHU數據集Bridge、Port與Medow、Airport等,NWPU數據集的Palace、River、Tennis_court與Mountain、MediumResidential等,這幾類場景間的高度相似,容易造成分類時的混淆.
5 結 論
本文提出了一種低維度稠密特征編碼的場景分類算法,用于實現遙感圖像分類過程中計算復雜度和精確度之間的有效平衡.算法優勢在于通過一系列的尺度變換,特征空間映射、主成分降維和特征編碼,將中低層語義特征有效的結合在一起,既保持了中低層語義特征的高效穩定,也具有與高層語義特征相近的分類精度,實現在普通運算環境中遙感場景的高效準確分類.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
