基于多任務和卷積神經網絡的業務識別算法
2021-04-19 13:30:16趙季紅喬琳琳
西安郵電大學學報 2021年1期
趙季紅,喬琳琳,王 穎
(1.西安郵電大學 通信與信息工程學院,陜西 西安 710121; 2.西安交通大學 電子信息工程學院,陜西 西安 710049;3.北京郵電大學 信息安全中心,北京 100876)
隨著無線通信技術的飛速發展,要求未來的網絡能夠為各種場景提供不同的服務。網絡切片作為未來關鍵技術,可以將物理網絡劃分為多個虛擬網絡切片,從而提高網絡資源利用率,降低網絡運營商的成本和能耗,提高網絡用戶的體驗質量[1-2]。面向多用戶的網絡切片在建立的過程中,需要考慮網絡場景的復雜多變且新型業務不斷出現,而其中關鍵及難點問題之一是如何識別出各種網絡業務的類型。
網絡業務分類一直是業界和學術界關注的焦點。目前主要的業務分類方法可以歸納總結為基于端口識別的深度包檢測(Deep Packet Inspection,DPI)、基于統計特征和協議的業務分類方法[3]。此外,考慮效率低下和缺乏準確性,基于機器學習算法的方法已經被廣泛應用于網絡業務分類[4]。這些方法通常依賴于監督學習方法,如支持向量機(Support Vector Machines,SVM),k-近鄰(k-Nearest Neighbor,KNN),隨機森林(Random Forest,RF) 或依賴于無監督聚類方法,如k-均值。然而,上述相對簡單的方法無法捕捉到當今互聯網流量中存在的更復雜的模式,因此其準確性不高。
隨著深度學習方法在圖像分類和語音識別等領域的成功應用,其能夠學習復雜的模式和執行自動特征提取,研究人員提出了利用深度學習方法對流量進行分類[5]。文獻[6]使用再生內核希爾伯特空間(Reproducing Kernel Hilbert Space,RKHS)將每個流的時間序列特征轉換成二維圖像,產生的圖像被用作卷積神經網絡(Convolutional Neural Network,CNN)模型的輸入,將CNN模型與經典的機器學習方法進行了比較,包括SVM和決策樹,CNN模型的精度達到99%以上,優于經典的機器學習方法。文獻[7]同樣采用CNN模型進行流量分類,將許多統計特征重新排列成二維圖像作為模型的輸入,最終以高精度進行分類。但該模型需要觀察整個數據流獲得統計特征,不能用于在線應用程序。文獻[8]提出了使用CNN、長時記憶(Long Short-Time Memory,LSTM)模型對業務進行分類,當“CNN+LSTM”體系結構使用時間序列特征時,其精度能夠達到96%左右。雖然上述深度學習方法可以達到高精度,但其缺點主要是需要大量的標記訓練數據。在網絡業務分類任務中,標記數據是一項耗時及繁瑣的任務。此外,在受控環境中觀察到的數據流可能與實際流量有很大的不同,使得標記數據獲得的推斷不準確。文獻[9]解決了需要大量標記數據集的需求。此方法由半監督學習方法組成,利用CNN模型從采樣數據包中預測幾個統計特征,使用采樣數據包的時間序列特征,然后采用新的圖層替換最后幾層,最后使用少部分標記數據集進行重新訓練。其優點是不需要花費人工標記預訓練的數據集,當整個流程可用時,可以輕松地計算統計特征。但是此方法需要采用采樣數據包,在執行分類之前先觀察大部分流量,同樣不適合在線應用。
針對上述方法存在的問題,擬提出一種基于多任務學習的卷積神經網絡(Multi-Task Learning-Convolutional Neural Network,MTL-CNN)方法,在執行帶寬需求、持續時間和業務類別等3個任務的預測時,只有業務類別任務需要人為標記。對于任意的數據流,每個流的帶寬需求和持續時間都很容易計算,并不需人為標記。因此,通過在多任務學習框架中制定業務分類問題,就可以用大量的不需要標記的數據在CNN中訓練模型的帶寬需求和持續時間任務,所有任務共享模型參數,只需要少量的標記樣本數據就能進行業務類別預測,以期使不同類別識別效果更加均衡,提高分類準確率。
1 問題描述與系統模型
1.1 網絡業務分類問題
網絡切片中有諸多的業務類型,如虛擬線上/增強現實、超高清視頻、自動駕駛、遠程控制和遠程醫療手術、智慧城市、遠程抄表,等等,這些多樣的業務類型對網絡性能的要求也有著巨大的區別。如底層網絡發生故障時,可能引起失效的網絡切片業務類型并不單一,如何選取動態的恢復方法,就要及時在線判斷失效的業務類型[10]。根據網絡數據流的統計特征對網絡業務進行分類與識別,其本質就是根據業務傳輸的過程中在統計特征上的差異,以區分不同的業務類別。以往方法通過將統計特征作為輸入,根據輸入特征的不同訓練分類器。而帶寬需求和持續時間這兩個統計特征是需要觀察整個數據流計算獲得,因此,將其作為輸入只適用于離線應用。文中選擇帶寬需求和持續時間作為單獨的輔助任務進行輸出,可以在訓練的過程中計算獲得,同時主任務在訓練過程中共享模型參數,能夠實現高精度業務分類,從而滿足對業務在線分類的要求。
1.2 卷積神經網絡
CNN是由使用卷積計算的若干層組成的前饋神經網絡(Feedforward Neural Networks,FNN)。其由卷積層、池化層和全連接層組成,如圖1所示。卷積層的功能是對輸入數據進行特征提取。為了生成輸出,卷積層在整個輸入上使用相同的卷積核,通過在一層中使用相同的卷積核,可以使學習的參數數量大幅減少。此外,在整個輸入中使用這些卷積核也有助于模型更容易地提取平移不變特征,實現具有平移不變特征的網絡業務分類任務。在卷積層進行特征提取后,則需要通過池化層負責數據采樣,即選取特征以及過濾信息。全連接層位于卷積層和池化層的末端,常用于捕獲高級的特征,典型的CNN的具體架構如圖1所示。
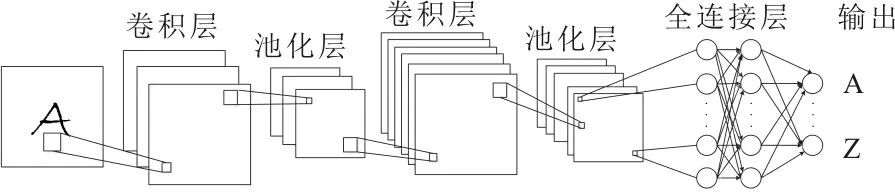
圖1 典型的CNN架構
1.3 多任務學習
MTL的目的是在任務非完全獨立的假設下同時執行若干個學習任務,是主任務使用相關任務的消息,提升泛化效果的一種機器學習類型。典型的MTL如自主駕駛,其中檢測危險物體和對危險距離評估是自主駕駛的兩項重要任務,基于這幾個任務是相關的并且可以共享參數,需要定義一種多任務學習方法聯合學習這些任務[11]。而多任務學習模型比幾個單任務學習模型更有效,考慮在MTL數據集中,所有任務都可以互相幫助,使得所有任務都能被更好地學習,因此,可以通過使用多任務學習方法提高業務分類任務的準確性。常規的多任務學習結構如圖 2 所示,其中,共享隱層中所有任務共享網絡參數,在對多個任務預測或分類時,訓練所需要的數據量與模型參數的數量都將減少,使模型更加高效,隨后各任務的分類結果在輸出層中被分別輸出。
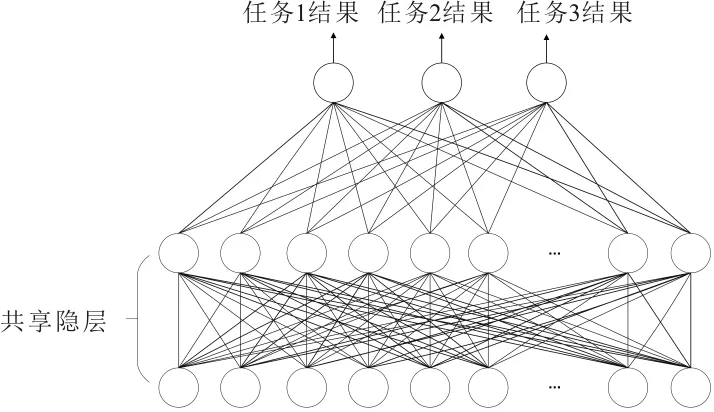
圖2 常規多任務學習架構
2 多任務業務分類方案
2.1 數據集
數據集來源采用了Arunan Sivanathan等人[12]公開的數據集,包含多個物聯網設備以及非物聯網設備獲取的數據流量,包括智能開關、智能音響、智能手機、智能醫療設備、打印機、筆記本電腦和攝像頭等。每種設備代表著不同的業務類型,并按照文獻[13]對數據集進行分類標注。為了評估多任務學習方法,且僅使用少量標簽數據提高主任務預測的準確率,實驗中只使用了800條標記樣本,并且對數據集進行了預處理。當采樣短流數據時,沒有足夠的數據包提供多任務分類器,因此,在預處理過程中刪除了所有短流數據。在評估中,短流是指那些在采樣前小于100個數據包的流[14]。對于特征的選擇和提取,網絡流量分類器通常使用一種或四種類別的輸入功能組合,如時間序列、標頭、有效負載和統計特征,考慮標頭信息無法實現高精度,現在已經很少采用;有效負載已被證明對于某些數據集和特殊流量類型以及加密方法比較有用,但是對于新的和更強大的加密協議,其作用有限;統計特征需要從整個流程中獲得,而對于取決于預測輸出的一些情況,如資源分配、路由決策等,一旦流量出現就必須進行在線預測,根據統計特征預測顯然不適用于在線分類。因此,所提算法為滿足在線分類的要求,僅觀察前k個數據包,使用前k個數據包的3個時間序列特征,即選取數據包長度、到達時間和方向作為特征值。
2.2 方法流程
提出了一種基于MTL-CNN的網絡業務識別算法,采用CNN作為共享層,其最重要的特征之一是移位不變性,因此適合于具有時間序列特征的業務分類任務。結合文獻[15]中提出的帶有屬性依賴層的MTL結構,在共享隱藏層之后添加了任務間相互獨立的屬性依賴層。該層通過對帶寬需求和持續時間兩個輔助任務,對網絡業務進行分類,多個任務之間共享特征和共同學習,同時允許每個子任務在屬性依賴層獨自優化提升性能。
輔助任務的選取有兩個特點。一個是其應該與網絡業務分類任務高度相關,另一個是不需要人為的標記大量數據,而且可以較為容易的獲取。帶寬需求和持續時間往往作為特征輸入對業務進行分類,并且可以通過觀察整個數據流計算獲得。因此,考慮使用帶寬需求和持續時間這兩項任務作為業務識別的輔助任務。在所提方法中,模型的輸入是一個具有兩個通道的長度為s的向量。第一個通道包含前k個數據包的到達時間,第二個通道包含數據包的長度和方向,其總體流程如圖3所示。
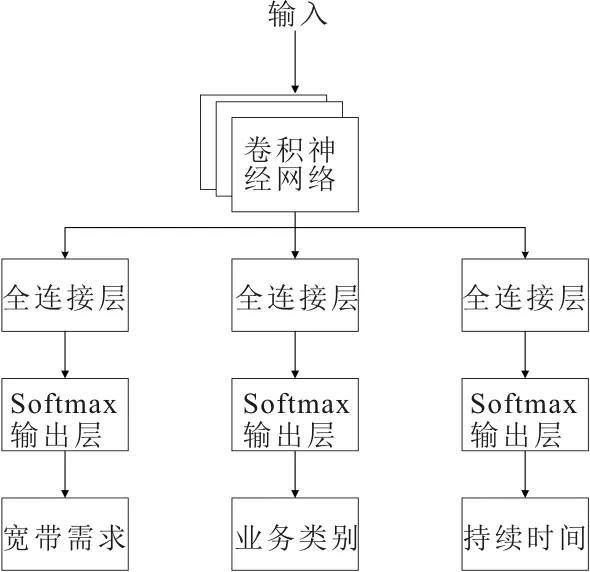
圖3 MTL-CNN流程
將3個時間序列特征輸入到共享層中,這里使用3層CNN作為共享層,對于該卷積層,使用Relu激活函數增加CNN各層之間的非線性關系,Relu函數實施的稀疏模型可以更好地挖掘相關特征并擬合訓練數據。該激活函數表達式為
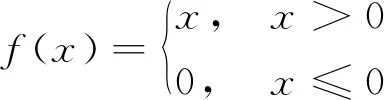
(1)
第三層輸出最后一個結果并將其輸入到屬性依賴層中。屬性依賴層由3個單獨的全連接層組成,分別將結果輸出到3個單獨的softmax輸出層中,最后輸出帶寬、持續時間和業務類別3個任務的分類結果。
2.3 目標函數
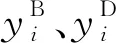
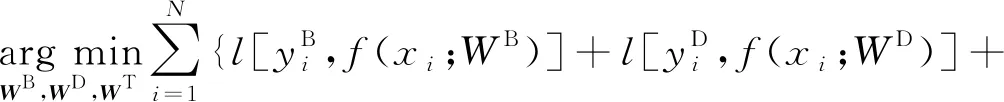
(2)
其中:l表示交叉熵損失函數;λ表示業務分類任務預測的重要性的權重。考慮主任務的訓練數據樣本比其他兩項輔助任務的訓練數據樣本要少得多,因此,可以增加λ稍微補償缺乏的標記數據。對于所有訓練數據,帶寬需求和持續時間標簽都是可用的,只有一小部分的數據樣本有業務類別標簽。在訓練過程中,將業務類別softmax層的輸入與掩碼向量相乘,以防止主任務對沒有業務類別標簽的數據樣本進行反向傳播。
3 仿真與性能分析
3.1 實驗環境配置
使用基于Python的Keras包對Arunan Sivanathan數據集實現多任務學習方法。在所有的實驗中,訓練階段僅需要幾分鐘時間,使用批處理優化和Adam優化器進行訓練,Adam參數設置模型學習率為0.001,衰減率為0.9。實驗在操作系統Windows 10專業版、CPU為Intel core i7 4790/3.6 GHz/4cores,16 GB內存以及開發環境為Python 3.7.0的環境下進行。為體現多任務學習在性能上的優勢,除對所提模型進行實驗外,在數據集相同的條件下還設計了3組對比實驗。
MTL-CNN僅對數據集中的800條數據進行業務分類標記,將時間序列特征輸入CNN共享層,在模型訓練后輸入到屬性依賴層,主任務通過屬性依賴層學習和共享輔助任務的參數,最后將3個任務分別輸出到3個獨立的softmax 輸出層。
單任務的卷積神經網絡(Single-Task Learning Convoluctional Netural Network,STL-CNN),該模型依然采用CNN模型捕獲內部信息進行訓練,但只有一個softmax 輸出層,即只預測業務類別一種任務。
Only-CNN,該模型將時間序列特征輸入CNN共享層,將結果直接輸出到3個獨立的softmax 輸出層,該模型與文中模型不同之處是不包含屬性依賴層。
RF[13]模型對8萬條樣本數據都進行了業務分類標注,以流信息和流頭部的數據包信息作為特征向量輸入,在RF模型中進行訓練以及預測業務類別,該模型的缺點是消耗較大的計算和存儲資源。
3.2 評價標準
可以利用準確率、精確率、召回率、虛警率和漏報率等指標從不同角度分析業務的分類效果[13,16]。為了從全局層面評價所提算法將多任務和CNN相結合對業務分類的效果,采用準確率(Accuracy)評估所提算法的整體性能。準確率指正確分類的數據流數量與所有數據流數量的比值,其定義[16]為
(3)
其中:TP與TN分別表示正確歸類的數據流,即TP表示屬于a類的數據流被正確歸為a類,TN表示不屬a類的被歸為非a類;FP與FN分別表示錯誤歸類,即FP表示不屬于a類的被歸為a類,FN表示屬于a類的歸為非a類。
3.3 結果分析
3.3.1 單一任務業務類別預測準確率
將數據集進行分類標注,根據物聯網設備和非物聯網設備將業務類別劃分為13種類型。表1顯示了在同一數據集下所有方法的每種業務類別識別的準確性。由表1可以看出,在13種業務類別的準確率中,智能嬰兒監視器和網絡攝像頭識別率相對較低,由于其屬于同一物聯網設備,設備行為比較相似導致業務區分度不高,所提MTL-CNN算法的準確率平均為95.60%。而對比算法STL-CNN與MTL-CNN,只對800條樣本數據進行了分類標記,考慮STL-CNN沒有其他的分類器,提取的特征只用于單一的業務分類,因此準確率最低,不包含屬性依賴層的Only-CNN的準確率約92.60%。說明MTL-CNN的屬性依賴層有助于該模型的學習能力,能夠提升該算法的區分業務類別的性能。
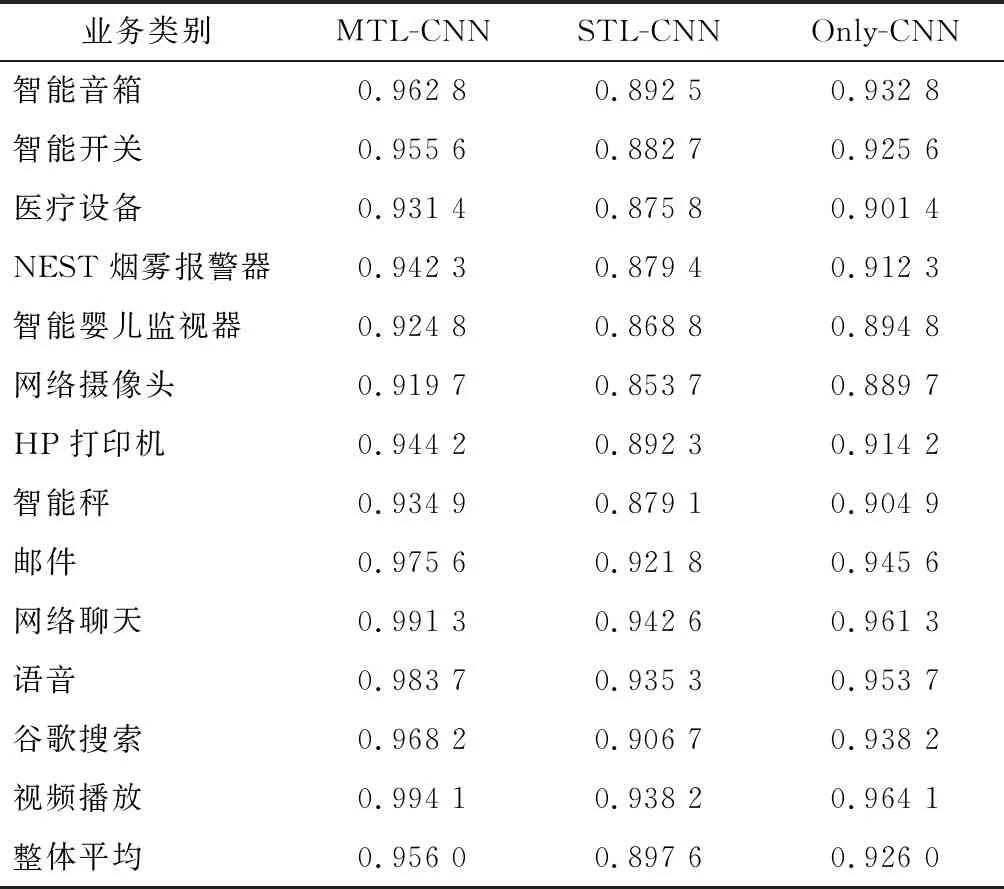
表1 業務類別識別準確率
3.3.2 每項任務識別率
為了測試每項任務的識別率,先將權重λ值設置為1,強調3個任務平等。該參數設置一方面是為了與單任務實驗做對比,另一方面是為了驗證使用少量標簽的主任務在訓練過程中確實受到了具有豐富數據的輔助任務的影響。每項任務識別準確率的測試結果如表2所示,關于輔助任務即帶寬和持續時間的準確率,MTL-CNN算法和不含共享層的Only-CNN算法差別較小,說明使用相同的數據集進行訓練是否有共享屬性層對預測輔助任務影響不大。而對于主任務預測,MTL-CNN算法明顯高于其他算法,與使用所有標記的數據集的RF算法相比,MTL-CNN算法僅用800條標記的數據預測業務類別,準確率仍高于RF算法。考慮采用帶寬和持續時間任務的大量數據改善了訓練過程,利用此數據訓練模型參數,通過共享參數加強了預測業務類別的準確率。因此,所提算法可以減少標記的數據量,且提高預測的準確率。
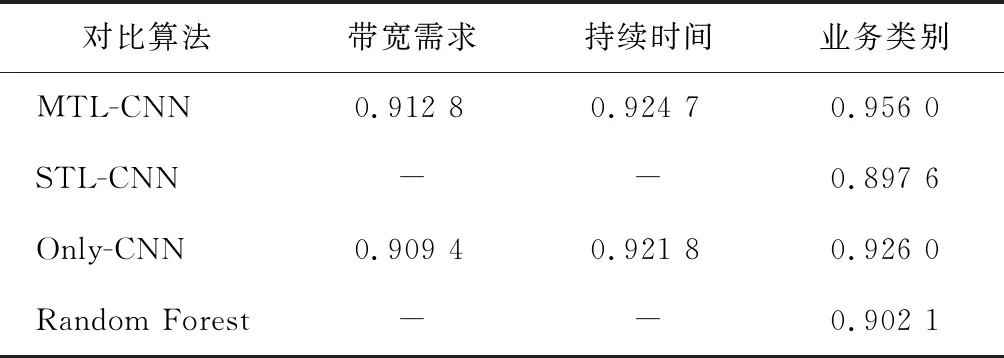
表2 每項任務識別準確率
3.3.3 不同λ取值的任務的準確率
不同λ取值的3個任務識別準確率如圖4所示。當在多任務學習中一項任務的訓練樣本數量明顯少于其他任務時,深度學習模型的共享參數在訓練過程中會受到具有大量數據的輔助任務的影響。增加主任務損失函數的權重,可以彌補訓練過程中主任務數據的不足,并增加主任務對訓練過程的影響。從圖4可以看出,增加λ有助于模型適應主任務即業務類別識別任務,當λ取10時,帶寬任務識別準確率達94.85%,持續時間任務識別準確率達92.58%,業務類別識別準確率97.65%,此時主任務達到最大準確率。同時,也可以觀察到,如果進一步增加λ值將降低所有任務的準確性。因此,對于多任務學習方法,合適的λ值有助于提高任務的準確率。
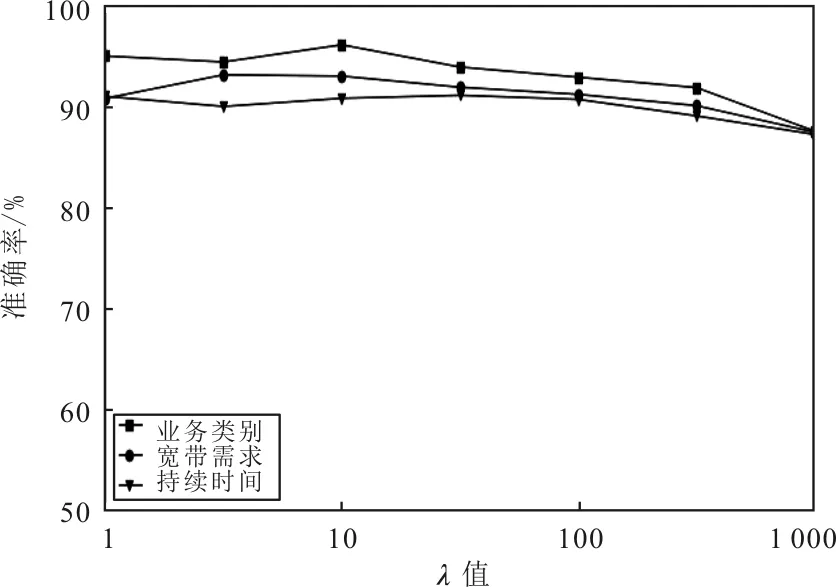
圖4 λ與準確率的關系
4 結語
提出了一種多任務學習和CNN的業務識別方法,用于預測業務類別以及流量的帶寬需求和持續時間。通過為帶寬需求和持續時間輔助任務提供足夠大的數據集,可以僅用少量標記樣本訓練業務類別預測任務。實驗結果表明,采用相同的數據集,所提算法顯著優于STL-CNN、Only-CNN和RF方法,其避免了大量標記數據樣本,并且有較高的識別準確率。但是要為輔助任務提供大量的數據,整個訓練時長仍有待改進,考慮數據樣本的限制,所提系統的模型仍然較為簡單,在未來的工作中,希望找到更適合的模型進行特征提取,以獲得更高的識別準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
