分支預測技術對性能影響研究
2021-04-20 02:36:16徐永新
電子技術與軟件工程 2021年1期
徐永新
(華為技術有限公司 江蘇省南京市 210012)
為了提升處理性能,現代CPU 采用多級流水線機制,經典的五級流水線分成取指,譯碼,執行,訪存,寫回等幾個階段。流水線機制可以有效提升指令的并行度,但是存在一些流水線沖突的場景,造成流水線效率的降低。這樣的流水線沖突包括結構沖突,控制沖突和數據沖突。
流水線的控制沖突也稱為分支沖突。程序執行過程中有許多分支跳轉的情況,流水線遇到分支跳轉時,并不知道后面要真正執行的指令在哪里,因為分支跳轉的目標地址還沒有被計算出來。這個時候流水線就需要采用某種策略,來預測后面將要執行的分支。如果預測對了,那么流水線的效率將能維持在較好的水平。反之,預測錯了,則錯誤的流水線處理結果都會被丟棄,重新從正確的目標地址取出指令重新執行,這將嚴重影響流水線的執行效率。
1 分支預測技術
1.1 靜態分支預測器
靜態分支預測是一種實現簡單的方法,比如預測永遠不發生跳轉,取指單元總是按順序取指,直到發現錯誤才丟棄不正確的中間狀態,重新取指。
靜態分支預測特點是實現簡單,但是預測的精度不高,在早期的CPU 設計中會使用這種方式。
1.2 動態分支預測器
現代處理器使用較多的是動態分支預測器,該類預測器能夠記錄分支的歷史跳轉信息,來預測將要執行的分支跳轉行為。如果由于程序執行的行為發生改變,預測器也會根據執行情況自動調整,從而擁有較好的預測準確度和自適應性。
動態分支預測使用分支歷史表BHT 來記錄最近一次或者幾次的執行情況。兩位飽和計數器是最常用的方向預測器。當計數值為11 時,分支轉移則計數器值保持不變,當計數值為00 時,分支不轉移則計數器保持不變,其他情況分支轉移則計數器加1,分支不轉移則計數器減1。根據飽和計數器來預測當前跳轉行為,并根據實際分支轉移情況更新飽和計數器的值。
將分支跳轉的指令地址和跳轉的目標地址都記錄下來的緩沖區叫做分支目標緩沖器BTB。程序計數器PC 值和BTB 中的分支指令地址進行比較,如果相等則表明當前是分支指令,如果同時預測會發生分支跳轉,則可以把BTB 中的目標地址作為下一條取指地址。
基于BHT 和BTB 的結構,衍生出一些改進的分支預測器,比如Gshare 預測器,Agree 預測器,Bi-Mode 預測器等等。
1.3 基于神經網絡的預測器
分支預測本質上是機器學習問題,神經網絡是一種比較有效的機器學習方法。神經網絡的輸入層是當前分支的地址所對應的分支歷史寄存器狀態,每個分支歷史狀態有相應的歷史權重,根據神經網絡算法得出輸出層的值,用來表示當前是跳轉還是不跳轉。如果預測成功對應的權重會增加,預測失敗則權重減少。基于神經網絡的預測器可以邊訓練邊預測。
基于神經網絡的預測器的特點是經過充分的訓練之后預測準確度比較高,但是訓練的過程耗時較長,并且由于需要做矩陣運算,其算法存在一定的時延問題。
2 分支預測對比實驗
為了展示分支預測機制對性能的影響,筆者設計了一組實驗,分別讓分支預測機制失效,分支預測機制成功,以及沒有分支指令等幾種情況作為對比,并測量出相應的性能數據。
在實驗中,程序的目標是統計出數組中的奇數數量,并計算出所有的奇數之和。元素個數為k 的數組內有n 個奇數,m 個偶數,被測程序需要遍歷數組統計奇數個數,并計算出所有奇數之和。循環查找的前后分別獲取cycles 值,其差值表示執行循環所消耗的cycle 數。其部分代碼片段如下:

上述代碼使用C++編譯器按照下面的編譯選項,編譯出可執行程序來驗證。

表1:實驗對比數據
g++ -O2 -g test.cpp -o test
2.1 分支預測成功實驗
為了保證分支預測成功,在初始化數組的時候,把數組的前n個元素都初始化成奇數,后m 個元素都初始化成偶數,這樣有規律的排列,可以保證分支預測機制能準確預測出分支的跳轉。代碼片段中需要注釋掉fisher_yates 函數。
初始化完畢之后的數據排列如下:

基于上述的規律數據,CPU 在執行條件判斷語句if ((data[i]% 2)== 1)時,將很快學到其規律,分支預測基本上是成功的。
2.2 分支預測機制失效實驗
為了讓分支預測機制失效,需要將有規律的數組變成一個隨機排列的數組。Fisher-Yate 算法是用來將一個有限集合生成隨機排列的算法。在隨機化奇數偶數排列之后,分支預測器將無法預測分支跳轉,從而讓分支預測機制失效。隨機化之后的數據排列呈現無規律的狀態:

基于上述的無規律數據,CPU 在執行條件判斷語句if ((data[i]% 2) == 1)時,無法通過歷史數據來判斷分支跳轉的規律,分支預測極大概率是失敗的。
2.3 無分支指令實驗
為了避免分支指令對性能造成的影響,編程中可以采用技巧,避免使用條件判斷語句。判斷奇數可以看數據的最低位是否為1,使用位運算來代替條件判斷。比如可以把循環里面的代碼改成如下的方式:

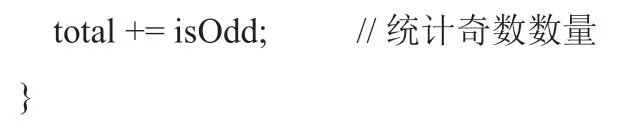
3 實驗數據
筆者在AMD Ryzen 5 4600H CPU 上運行測試程序,改變循環次數,分別針對無規律數據分支預測失敗,有規律數據分支預測成功,無規律數據無分支指令,有規律數據無分支指令這四種情況,測量出了一組執行時間cycle 值的對比數據。
表1中第一行表示數組大小,即循環次數分別為10000 到50000 次,其余的數字表示測得的對應情況的cycle 數。由實驗數據可知,分支預測失敗的情況下的執行時間基本上是預測成功的4.2倍左右。而沒有分支指令的情況下,有規律的數據和無規律的數據,對執行時間沒有影響,兩者對比數據沒有顯著的差別。
4 結語
通過對分支預測機制的介紹,以及實驗數據的展示,我們可以得出下面的結論:
(1)現代CPU 往往都有設計良好的分支預測機制,如果某段程序執行路徑不是關鍵瓶頸,則不必花時間去做精細的分支優化,交給CPU 和編譯器去做優化處理即可。
(2)如果某段程序代碼屬于關鍵執行路徑,則在大規模循環中需要優化分支判斷,讓分支條件的判斷是有規律的,這樣才能有效利用CPU 的分支預測機制。
(3)如果可以使用運算技巧來避免分支判斷,也可以消除無規律的分支判斷給流水線帶來的效率影響。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
四川勞動保障(2021年9期)2022-01-18 05:11:08
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
文苑(2018年21期)2018-11-09 01:23:06
電信科學(2016年10期)2016-11-23 05:11:56
中國衛生(2016年9期)2016-11-12 13:28:08
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
