基于半監督方法的腦梗死圖像識別
2021-04-20 14:07:42歐莉莉邵峰晶孫仁誠
計算機應用 2021年4期
歐莉莉,邵峰晶*,孫仁誠,2,隋 毅
(1.青島大學計算機科學技術學院,山東青島 266071;2.青島大學附屬醫院,山東青島 266071)
0 引言
近年來,隨著醫學成像技術不斷提高,各種醫學設備產生的大量醫學圖像,為醫學圖像識別研究提供了充分的數據來源。然而,由于醫學圖像數據具有多模態性、多維性和不確定性等特點[1],給醫學圖像識別帶來了很大挑戰。傳統的醫學圖像識別是由醫生對患者的超聲影像進行肉眼觀察診斷,其識別率低、耗時比較長,診斷結果也往往具有主觀性和低可靠性,難以滿足當下的醫學需求,而深度學習(Deep Learning)的出現促進了醫學圖像識別的進一步發展。深度學習作為機器學習的一個重要分支,其原理是模仿人腦的機制,自動學習數據的內在規律,利用分層網絡模型逐層地提取特征,這些特征能準確地反映數據信息,從而提高圖像識別的準確性。
生成對抗網絡(Generative Adversarial Network,GAN)是由Goodfellow 等[2]在2014 年提出的,并且在深度學習領域引起廣泛的研究熱潮。由于GAN 的生成能力比較強,人們逐漸將其應用于圖像領域,例如圖像合成[3]、圖像修復[4]、圖像識別、視頻檢索[5]、根據文字生成圖片[6]、圖像超分辨率[7]、灰度圖像上色[8]及X光圖像的生成[9]等方面。在圖像識別領域中,雖然基于GAN 的方法[10]具有很高的識別率,但是與監督學習方法一樣,在訓練時需要大量的標簽數據。當標簽數據不足時,會影響一些特定問題的識別效果。如:在對醫學圖像分析時,采集到的樣本需要先由經驗豐富的醫生進行標注,然后才能進行分析,但是這個過程要耗費大量的時間和人力,還會浪費無標簽樣本中的一些重要信息[11]。
本文針對這個問題,將半監督生成對抗網絡(Semi-Supervised GAN,SSGAN)[12]與深度卷積生成對抗網絡(Deep Convolutional GAN,DCGAN)[13]的特點相結合,構建半監督深度卷積生成對抗網絡(Semi-Supervised DCGAN,SS-DCGAN)模型,在該模型中將具有特征提取功能的卷積神經網絡加入到生成器與判別器中,用來提取圖片的特征信息。本文實驗中選用的是腦部磁共振(Magnetic Resonance,MR)圖像數據,其中只有少量的標簽數據,通過對比不同模型在該數據集上的實驗結果,證明半監督深度卷積生成對抗網絡具有一定的魯棒性。
1 生成對抗網絡
GAN 是一種深度學習模型,主要由生成器和判別器組成,生成器G與判別器D是一種博弈對抗關系。GAN 網絡中生成器與判別器是一種對抗關系,在模型訓練時需要對兩個網絡同時進行訓練[14],生成對抗網絡的基本框架如圖1所示。

圖1 GAN基本框架Fig.1 Base framework of GAN
生成器負責最大化地擬合服從某種簡單分布的隨機噪聲,使其盡可能地服從真實數據的分布,并生成偽樣本;判別器負責判斷輸入的數據是否為真實數據,若為真則輸出為1,否則為0。訓練時,生成器與判別器相互博弈,前者生成的偽樣本慢慢接近真實數據,后者的判斷能力慢慢增強。當判別器無法確定數據是真實數據還是生成數據時,生成器已經很好地學習到了真實數據的分布規律,即D(G(z))=0.5。式(1)為GAN模型的優化函數[2],由前后兩部分組成:
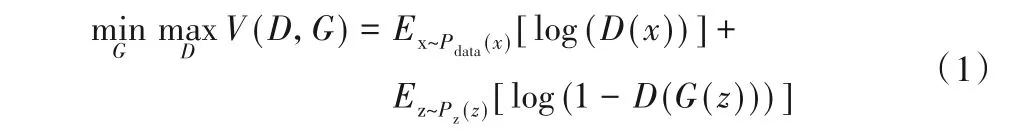
其中:x為真實數據,服從真實數據分布Pdata(x);z為隨機噪聲,服從先驗分布Pz(z);G(z)是將隨機噪聲z輸入到生成器所產生的偽樣本;D(x)和D(G(z))分別為判別器判斷x和G(z)為“真”的概率。
在判別器中,要提高判斷是真實數據還是生成數據的能力,需要對判別器的參數進行更新。對于真實數據就是要最大化D(x),即最大化log(D(x));對于生成數據G(z),要最小化D(G(x)),即最大化log(1-D(G(z)))。由此可以得出判別器的目標函數,如式(2)所示:

在生成器中,通過欺騙判別器來提高自身生成偽樣本的能力,就要對生成器的參數進行更新。要想使判別器判斷不出輸入的數據是否是偽樣本,就要使D(G(z))最大,即最小化log(1-D(G(z)))。因此,生成器的目標函數如式(3)所示:
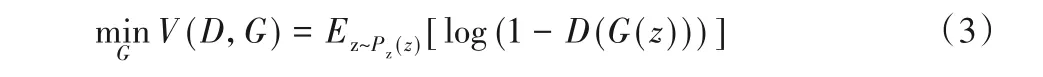
2 半監督生成對抗網絡
2016 年OpenAI 提出了GAN 的改進模型——半監督生成對抗網絡(Semi-Supervised GAN,SSGAN)[10]。本文將該網絡模型應用到腦部MR 圖像的識別上。相較于GAN 模型,SSGAN 使用標簽數據和無標簽數據共同訓練有類別信息的樣本。
SSGAN 模型的基本框架如圖2 所示。將隨機噪聲z輸入到生成器,并輸出生成樣本G(z);G(z)與有標簽、無標簽的腦部MR數據一同輸入到判別器中。假定對于一個K分類問題,將生成器生成的偽樣本記為y=K+1類,判別器最后將輸出K+1 維的分類結果。在SSGAN 訓練過程中,其損失函數采用監督學習與無監督學習相結合的方式,這種做法有助于提高半監督分類的準確率[15]。

圖2 SSGAN基本框架Fig.2 Base framework of SSGAN
為了能夠更好地獲取腦部MR 圖像的特征信息,本文還采用了將傳統的監督學習方法卷積神經網絡(Convolutional Neural Network,CNN)與無監督的GAN 相結合的深度卷積生成對抗網絡(Deep Convolutional GAN,DCGAN)[11]。該模型是由Alec Radford 于2015 年提出的,并首次將卷積神經網絡與生成對抗網絡結合在一起,利用卷積神經網絡的特征提取功能[16],來提高GAN模型訓練過程的穩定性。
DCGAN的主要貢獻表現在下列三個主要方面:
1)改變了普通卷積神經網絡在卷積之后接一層池化的結構,去掉池化層。判別器中池化層換成步長為1 的卷積層,而生成器中的池化層換為反卷積層。
2)刪除網絡中的全連接層,將卷積神經網絡連接到生成器判別器的輸入輸出層。
3)在生成器和判別器輸入層、中間層都使用批量歸一化(Batch Normalization,BN)。
除此之外,因為GAN 中使用的是不適合高分辨率生成的maxout[17]激活函數,而DCGAN 在生成器的輸出層使用Tanh激活函數,其他層均使用ReLU(Rectified Linear Unit)[18]激活函數;在判別器的每層都使用LeakyReLU[19]激活函數。
3 半監督深度卷積生成對抗網絡
半監督深度卷積生成對抗網絡(SS-DCGAN)的主要思想是:結合了SSGAN 和DCGAN 的特點,建立圖像識別模型SSDCGAN。在模型中將深度卷積神經網絡引入到生成器與判別器中。在訓練時,判別器作為分類器進行訓練。在該模型中不僅使用了標簽數據,還使用了大量的無標簽數據,主要是為了利用無標簽數據來提高標簽數據的分類精度。在訓練時,雖然無標簽數據不帶有類別信息,但卻有助于學習數據的整體分布,同時能夠提高模型的分類準確率。
在生成器中,首先,將服從某種特定分布的100 維隨機噪聲輸入到生成器中,經過Reshape 操作,得到一個三維張量,大小為4×4×1 024;然后將該三維張量經過6 次反卷積和上采樣,生成與真實數據大小及分布一致的樣本圖像。最后在輸出層輸出大小為128×128×3 的偽樣本圖像,其中128×128 代表圖像的分辨率,3 代表圖像通道數。在反卷積過程中,卷積核ω的大小為5×5,步長stride 為2,完成一次反卷積操作,都要進行批量歸一化處理。網絡的輸出層采用的是Tanh 激活函數,其余層采用的是ReLU激活函數。其結構如圖3所示。
在判別器中,采用的了17 層卷積神經網絡和3 個全連接層。首先,通過17 層卷積層對128×128×3 的圖像進行特征提取,再利用全連接層對特征信息進行整合,最后輸出分類結果。每完成一次卷積操作就要進行批量歸一化,在卷積過程中采用的是LeakyReLU 激活函數。它與ReLU 函數的不同之處在于,LeakyReLU 函數在負半軸保留了數值為0.2 的斜率,作用是:在訓練過程中,避免因出現梯度消失,模型無法收斂的情況。網絡的輸出層是全連接層,并通過Softmax 輸出歸一化類別概率。其結構如圖4所示。

圖3 SS-DCGAN生成器結構Fig.3 Generator structure of SS-DCGAN

圖4 SS-DCGAN的判別網絡Fig.4 Discriminator network of SS-DCGAN
4 基于SS-DCGAN的腦部MR圖像識別
基于上述模型結構,針對腦部MR 圖像識別中有標簽數據稀缺的問題,采用了一種基于GAN 模型的半監督方法來實現腦部MR 圖像的識別。該方法對網絡參數的更新是通過監督損失和無監督損失共同訓練,在生成器中,利用特征匹配來提高GAN 的學習能力,通過對抗訓練來提高圖像識別的準確率。
4.1 數據及預處理
本文所用數據來自青島大學附屬醫院神經科,是在有經驗臨床醫生的指導下選取的腦部MR 圖像,并將其分為正常(不患腦梗)和異常(患腦梗)兩種類別的圖像,在異常圖像中又根據其患腦梗病變的面積將其分為:腔隙性腦梗死(病變面積<1.5 cm)、小梗死(病變面積1.5~3 cm)、大梗死(病變面積>3 cm)。正常圖像的腦組織區域呈灰黑色,而異常圖像的腦組織會有部分灰白色區域,如圖5所示,圖5(b)中框中部分即為病灶區域。
為了使輸入圖像尺寸與模型相匹配,在輸入模型之前需要將裁剪后大小不一的圖像設置成相同的大小。考慮到模型訓練速度以及計算機性能等原因,選擇128×128 像素作為輸入圖像的尺寸大小。通過對初始樣本中的少量圖片進行數據增強,將它們以不同的角度逆時針翻轉(如10°、15°、20°、25°),從而使數據擴充到6 744 張,并將數據集的80%作為訓練集,20%作為測試集,即訓練集5 396 張,測試集1 348 張。其中訓練集分為標簽數據與無標簽數據,并且無標簽數據要遠多于標簽數據。

圖5 腦部MR圖像Fig.5 MR images of brain
4.2 SS-DCGAN模型訓練
在SS-DCGAN 中,對于一個K分類問題,將生成器生成的偽樣本添加到真實數據中,并記為第K+1 類,將數據x作為判別器的輸入,并輸出一個K+1 維的邏輯向量(l1,l2,…,lK+1),再通過softmax函數得出歸一化類別概率:

其中:Pmodel的最大值對應類別的預測標簽。
SS-DCGAN 模型的訓練過程就是損失函數的優化過程。在判別器中,要輸入三種類別的數據(有標簽數據、無標簽數據、生成數據),且都有其相應的損失函數,即有標簽數據損失Llabel、無標簽數據損失Lunlabel、生成樣本損失Lgen。
有標簽數據損失,即真實類標簽分布和預測類標簽的交叉熵損失,此表達式為:

無標簽數據損失,即無標簽數據來自真實數據,此時y≠K+1,該表達式為:
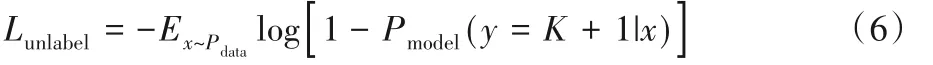
生成樣本的損失,即生成器生成的偽樣本被判別器判斷為假樣本的損失,此時y=K+1,該表達式為:

其中:x為數據圖像;y為有標簽數據的標簽,即y∈{1,2,…,K,K+1};x,y~Pdata表示輸入帶有標簽y的真實數據圖像x;x~Pdata表示x是真實數據分布中的無標簽數據;x~G表示x來自生成器生成的偽樣本;Pmodel(·|·)表示預測類概率。
在判別器的損失函數中:
1)有標簽樣本的損失Llabel,相當于一個標準的監督分類任務的訓練過程,對于一個K分類,優化網絡參數需要通過最小化標簽數據樣本和模型預測分布Pmodel(y|x)之間的交叉熵。
2)無標簽樣本損失Lunlabel,在訓練時就是要盡可能最大化無標簽數據來自真實數據的概率。
3)生成樣本損失Lgen,在訓練時就是要盡可能地最大化樣本來自生成樣本的概率。
判別器的訓練過程就是優化損失函數的過程。其中,對有標簽數據進行監督學習,對無標簽數據和生成樣本進行無監督學習。即,判別器的總損失函數LD是由監督損失函數Lsupervised和無監督損失函數Lunsupervised組成,公式如下:
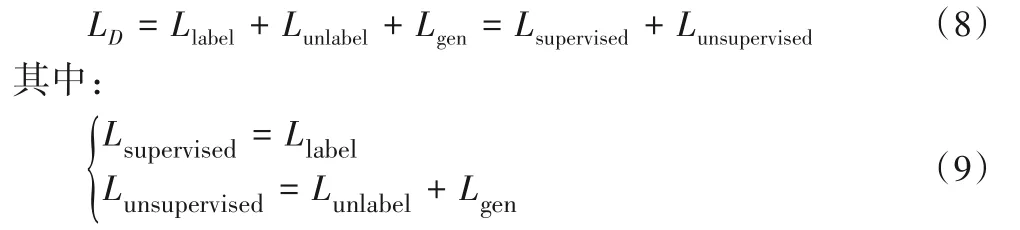
判別器會將生成樣本判別為假樣本,為了欺騙判別器,達到擴充樣本的目的,就需要生成器生成的偽樣本近似擬合真實數據。在本文并沒有采用原始GAN 中的方法來定義生成器的損失函數LG,而是采用特征匹配的方法[10],即:訓練過程中,G的損失函數為生成樣本與真實樣本特征匹配的結果,通過最小化損失函數,生成器實現最大化擬合真實數據的分布。其定義為:
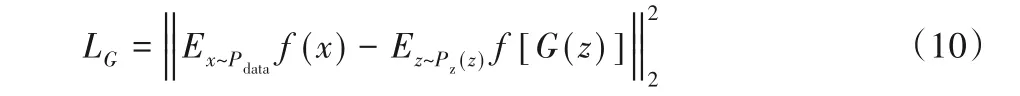
其中:f(·)表示判別器中間層的特征值;||·||2表示2-范數。
本文為了提高模型的學習能力,將監督和無監督損失相結合,共同來對判別器的參數進行調整,過程為:訓練時,判別器與生成器交替訓練,如果要更新一方的參數,就要固定另一方的參數。對判別器訓練時,參數的更新通過最小化標簽數據和模型預測分布之間的交叉熵,無標簽的真實數據和偽樣本需要通過GAN 的對抗訓練原理來進行參數的更新。訓練生成器時,采用的是特征匹配方法來擬合真實數據的分布。SS-DCGAN 模型是通過監督與無監督的聯合訓練來實現半監督分類功能。
SS-DCGAN模型的訓練過程如下:
1)將服從某種簡單分布的隨機噪聲z輸入到生成器,得到偽樣本G(z)。
2)判別器中輸入真實樣本x(有標簽、無標簽)和偽樣本G(z),并通過softmax輸出歸一化概率值D(x)和D(G(z))。
3)使生成器的參數不變,如果圖像為有標簽的真實數據圖像,則將Llabel作為損失函數;若真實圖像為無標簽數據圖像,則Lunlabel作為損失函數;若輸入圖像為生成器生成的偽樣本圖像,則Lgen作為損失函數。判別器的參數調整采用Adam梯度下降法。
4)保持判別器的參數不變,全連接層的輸出為中間層特征,生成器參數的調整是通過真實圖像與偽樣本的特征匹配。
5)以上4個步驟重復執行,當達到設定的epoch結束。
6)模型訓練完成后,將測試集輸入到判別器中,輸出圖像類別。
5 實驗與結果分析
本文實驗環境為Windows 10 系統,CPU 3.60 GHz,RAM 32.0 GB,Python版本為3.7。
實驗中數據加載方式為批處理,大小為16,epoch 為1 500。采用全局學習率為0.000 3、動量大小為0.5 的Adam優化器來優化損失函數[14]。為了充分驗證SS-DCGAN 模型圖像識別的有效性,在腦部MR 圖像上進行實驗。模型沒有對輸入的圖像進行預處理,只是將圖像做歸一化處理,再映射到[-1,1]的范圍上[14]。
將腦部MR 圖像在SS-DCGAN 模型上訓練1 500輪后判別器與生成器損失函數(D_loss 和G_loss)的變化曲線圖如圖6所示。

圖6 模型損失變化趨勢Fig.6 Loss trend of model
從圖6 可看出,隨著訓練次數的增加,判別器與生成器的損失都呈下降趨勢。在D_loss 損失圖中,在訓練初期出現急劇下降的趨勢,后期部分損失函數出現震蕩現象。而在G_loss 損失圖中,訓練時會出現大幅震蕩現象。原因是:兩個網絡訓練時進行博弈對抗,并不斷學習圖像的特征,后期兩個網絡的學習能力都逐漸增強,就會出現圖中所顯示的此消彼長的震蕩現象[9]。
圖7 為訓練情況下模型的分類準確率結果,其訓練情況下的平均準確率達到95.05%。
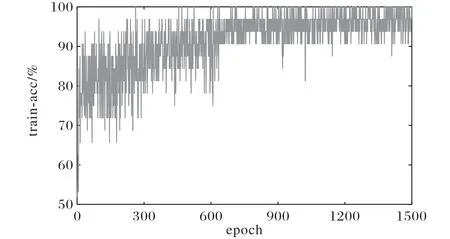
圖7 腦部MR圖像上訓練準確率變化趨勢Fig.7 Change trend of train_acc on MR images of brain
訓練結果表明,腦部MR圖像在SS-DCGAN模型上進行訓練時得到了較高的訓練準確率。為了測試SS-DCGAN 在標簽數據較少時的分類性能,將本文模型與監督學習的卷積神經網絡(CNN)[20]、半監督梯度網絡(Ladder Network)[21]以及ResNet32(Residual Network 32)進行對比實驗。將有標簽數據的數量依次分為25、50、100、250、600、1 200,在這6 種不同標注數量的樣本中采用的數據集都是來自訓練集。表1 為上述4 種方法在這6 種不同標注數量樣本下的平均準確率,表2為不同標注數量樣本的測試時間,圖8 為平均準確率的變化趨勢圖。
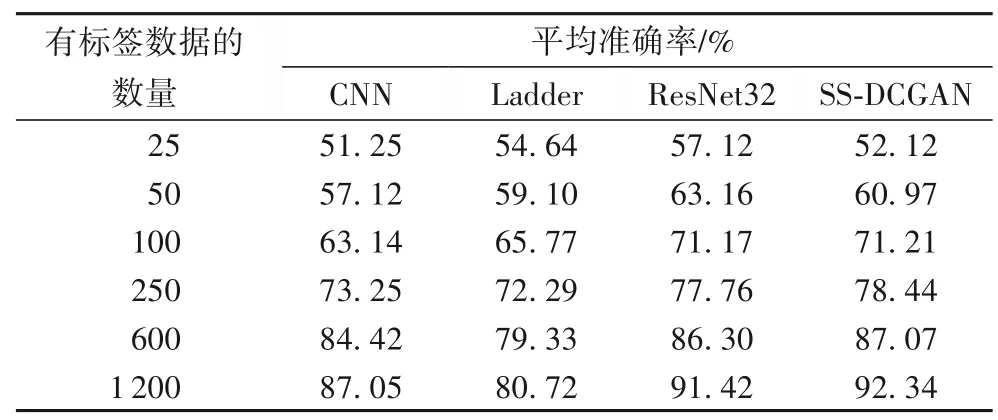
表1 不同標注數量樣本的平均準確率Tab.1 Average classification accuracy of samples with different numbers of labeled data

表2 不同標注數量樣本的測試時間Tab.2 Test time of samples with different number of labeled data
表1 中的數據是每個模型在相同數據集、epoch 為1 500的情況下經過6 次實驗得出的平均準確率,從中可以看出,SS-DCGAN 在有標簽數據較少時就能達到相較于其他方法不錯的準確率。例如:SS-DCGAN 在只有50 個標注樣本時就可以達到60.97%的平均準確率,但CNN想要達到與SS-DCGAN相當的準確率就需要50~100個標注樣本。SS-DCGAN相較于其他兩種模型,即半監督梯度網絡和ResNet32,都表現出優越的性能。但是盡管在相同數據集下,經過多次實驗,SSDCGAN 比ResNet32 的準確率高得并不是很多。所以為了排除實驗結果具有偶然性,同時也為了驗證SS-DCGAN 在同等條件下是否一直比ResNet32 優越,對Mnist、Cifar10、SVHN(Street View House Number)三個公開的數據集在SS-DCGAN和ResNet32 上都進行epoch 為1 000 的實驗,實驗結果如表3所示。通過對這三次實驗的結果分析可得:在不同的數據集上進行實驗,SS-DCGAN 對圖片的識別準確率要優于ResNet32,并且獲得更少的時間損耗。
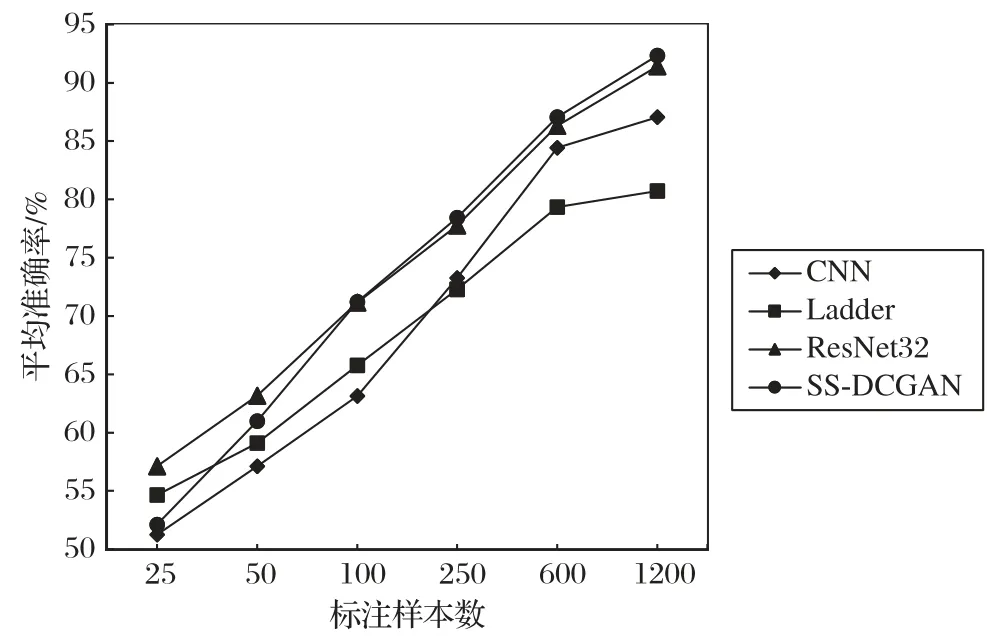
圖8 不同標注數量樣本分類結果Fig.8 Classification result of samples with different numbers of labeled data

表3 不同數據的準確率與訓練時間Tab.3 Accuracy and training time of different data
為了驗證本文所提模型的優越性,使用腦梗死數據集在多個改進的GAN 網絡模型上進行實驗,并且對每個模型分別進行了5 次實驗,對實驗結果求得平均值。實驗的最終結果如表4所示。

表4 不同模型的實驗結果對比Tab.4 Comparison of experimental results of different models
分析表4 可以得出,SS-DCGAN 模型的運行時間與GAN、CatGAN(Categorical GAN)、DCGAN 模型相差無幾,但準確率要高很多。
通過分析上述的實驗結果:SS-DCGAN 模型可以在腦部MR 圖像上獲得較好的識別效果;同時,在其他數據集上也驗證了該方法的有效性且準確率更高,表明本文所提模型具有一定的魯棒性與有效性。
6 結語
為了解決醫學圖像識別中有標簽數據不足的問題,結合了SSGAN 和DCGAN 的優點,建立半監督深度卷積生成對抗網絡模型。通過定義半監督損失函數,以及監督與無監督學習的聯合訓練,利用模型的判別器來識別腦部MR 圖像。在腦部MR 圖像數據集下,實驗結果表明,SS-DCGAN 在標簽數據不足時,能表現出比其他監督、無監督模型更好的性能,且比其他改進的GAN 模型實現效果要好。未來,我們將進一步優化網絡結構,使模型的運算更加高效,識別效果更加精準,并將其應用于其他醫學圖像識別中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
浙江人大(2014年5期)2014-03-20 16:20:28
浙江人大(2014年4期)2014-03-20 16:20:16
