機器學習在強對流監測預報中的應用進展*
2021-04-20 00:38:36周康輝鄭永光董萬勝
氣象 2021年3期
周康輝 鄭永光 韓 雷 董萬勝
1 國家氣象中心,北京 100081 2 中國海洋大學信息科學與工程學院,青島 266100 3 中國氣象科學研究院,北京 100081
提 要: 近年來,機器學習理論和方法應用蓬勃發展,已在強對流天氣監測和預報中廣泛應用。各類機器學習算法,包括傳統機器學習算法(如隨機森林、決策樹、支持向量機、神經網絡等)和深度學習方法,已在強對流監測、短時臨近預報、短期預報領域發揮了積極的重要作用,其應用效果往往明顯優于依靠統計特征或者主觀經驗積累的傳統方法。機器學習方法能夠更有效提取高時空分辨率的中小尺度觀測數據的強對流特征,為強對流監測提供更全面、更強大的自動識別和追蹤能力;能夠有效綜合應用多源觀測數據、分析數據和數值預報模式數據,為強對流臨近預報預警提取更多有效信息;能夠有效對數值模式預報進行釋用和后處理,提升全球數值模式、高分辨率區域數值模式在強對流天氣預報上的應用效果。最后,給出了目前機器學習方法應用中存在的問題和未來工作展望。
引 言
人工智能的迅速發展將深刻改變人類社會生活,改變世界。機器學習屬于人工智能范疇,是人工智能領域的一個重要分支,主要研究對象是如何在經驗學習中改善具體算法的性能。自1956年達特茅斯會議上,機器學習(machine learning)的概念被首次提出以來,成為數學、計算機科學、神經科學等多學科的活躍研究方向(萬赟,2016),其算法也被廣泛應用到大氣、海洋等眾多學科領域。傳統機器學習算法主要包括邏輯回歸、決策樹、隨機森林、人工神經網絡、支持向量機、貝葉斯分類器、聚類算法等。雖然其發展歷程跌宕起伏,經歷了多個發展高潮與低谷,但是在不同的發展時期,機器學習均展示了旺盛的生命力,在各個發展領域得到廣泛的應用。
Hinton and Salakhutdinov(2006)提出“深度學習(deep learning)”的概念,證明了深層神經網絡的可訓練性,展現了深層神經網絡更強大的特征提取和非線性擬合能力,奠定了此次人工智能發展浪潮的基礎。但該論文主要以理論分析為主,當時并未有重要的應用產生,因此在計算機學界并未立刻產生重大影響。在接下來的十年中,直到兩個標志性事件的出現,才使得深度學習分別取得了計算機領域內和全世界范圍內的認可。第一個事件是2012年Alex Krizhevsky與Geoffrey Hinton在國際上著名的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)圖像識別競賽中,用深度學習方法(即AlexNet)以絕對優勢取得第一名。2013年起幾乎所有參加該競賽的隊伍全部采用深度學習方法。在ILSVRC這種世界級的競賽中,一種方法幾乎能夠在一夜之間完全勝出,這在以前是無法想象的。另一事件是2016年基于深度學習的圍棋程序AlphaGo戰勝世界冠軍李世石,這不僅引起了全世界范圍內對人工智能技術巨大進步和未來發展潛能的關注,也引發了世界范圍內對人工智能產業的投資潮。目前,深度學習及其他人工智能技術仍在以前所未有的速度發展著。
根據訓練數據是否有標記信息,機器學習任務可分為監督學習和無監督學習。常見的無監督學習算法如聚類算法、主成分分析等算法。監督學習又可分為回歸和分類。回歸問題預測連續值,如氣溫、降水量;分類問題則預測的是離散值,如晴或雨。目前,機器學習,尤其是深度學習,在分類問題上取得了巨大的成功,如圖片分類競賽中其效果超越人類(Russakovsky et al,2015),在回歸問題中效果次之。無監督學習仍亟待更進一步突破(LeCun et al,2015)。
機器學習算法,特別是深度學習,需要大量的歷史數據進行建模并訓練,從而從歷史數據中學習到規律。天氣預報,經過長時間的發展,積累了海量歷史觀測數據、數值預報模式數據,具備“大數據”屬性,能夠為機器學習提供訓練所需的大量數據,因此,一直以來,機器學習在天氣預報領域有眾多成功應用(Karpatne et al,2019)。
強對流天氣預報主要關注時空尺度較小、發展劇烈的天氣現象,如冰雹、雷暴大風、短時強降水、龍卷等惡劣天氣。由于局地性強、發展迅速,強對流天氣具有極高的預報難度(鄭永光等,2015)。由于其強度強,易于造成嚴重的人員和財產損失(王秀榮等,2007),比如2015年“東方之星”翻沉事件(鄭永光等,2016a)和2016年江蘇阜寧EF4級龍卷事件(鄭永光等,2016b)。
由于強對流天氣系統的中小尺度特性,因此強對流天氣預報特別關注監測和臨近預報。對于天氣雷達、氣象衛星、閃電探測儀、自動氣象站等具備高時空分辨率的數據使用,提出很高的要求。然而,海量的觀測數據,已經很難完全由預報員主觀監測識別。傳統的客觀做法,根據物理機理、預報員經驗和統計結果,通過對觀測數據設置一定閾值,對強對流天氣進行識別和監測,通常會造成虛警率偏高(Schultz et al,2009;Harris et al,2010)。目前,強對流天氣臨近預報極大地依賴實況監測,以雷達或者衛星觀測結果進行線性或非線性外推預報為主,尤其缺乏對流生消演變的預報能力,因此應用效果具有較大的局限性(俞小鼎等,2012;鄭永光等,2015)。
與強對流監測和臨近預報不同的是,強對流短時(2~12 h預報)和短期預報(12~72 h預報)更側重于對數值預報模式的釋用。近年來,隨著高分辨率數值預報模式的發展,強對流天氣預報更多地依賴高分辨率數值模式預報。隨著時空分辨率越來越高,高分辨率數值模式預報信息量越來越大,對預報員的信息提取能力提出極高的要求。目前,很多強對流天氣(如雷暴大風、龍卷等)并沒有直接的模式輸出產品。經驗豐富的預報員需要從大量數據中,提取動力、水汽、能量、地形影響等強對流天氣形成條件,最終形成一份可用的強對流預報。
由此可見,強對流監測預報,目前仍大量依靠傳統的統計結果和預報員經驗。長期的應用結果表明,以上方法具有較大的局限性。首先,不同季節、不同地勢分布、不同氣候背景區域之間,強對流天氣發生發展條件與特征閾值范圍必然會存在差異,難以使用一套統一的特征物理量閾值組合來實現不同區域的分類強對流天氣的預報(王婷波等,2020);其次,天氣預報過程中需要使用大量數據,依靠預報員統計或者主觀提取特征物理量和閾值范圍,難以完全發現數據中有價值的細節信息或者細微差別,特別是一些中小尺度信息;再次,強對流天氣復雜多變,如果預報員對于強對流發生發展規律認識不夠深刻、全面,也會忽視其中的有效信息。傳統基于物理機理的統計模型等客觀方法,由于基于主觀認識建立,也難以避免地存在上述問題。
近年來,以深度學習為代表的機器學習算法的興起,有效結合各類氣象大數據,已經成為強對流天氣預報的有效手段(McGovern et al,2017;Reichstein et al,2019)。與淺層神經網絡、支持向量機等傳統機器學習算法相比,深度神經網絡不僅能夠為復雜非線性系統提供建模,更能夠為模型提供更高的抽象層次,從而提高模型的特征提取能力;其優勢在于能以更加緊湊簡潔的方式來表達比淺層網絡大得多的函數集合,并在圖像識別、語音處理等領域相比傳統方法的性能有了顯著提升(Krizhevsky et al,2012;LeCun and Bengio,1995;Szegedy et al,2013)。
本文梳理了機器學習在強對流天氣監測、短時臨近預報、短期預報等領域的應用和存在的問題,并給出了未來工作展望,以期更清晰地了解機器學習在強對流天氣領域的應用情況,為更好地結合物理機理、數值預報等來發展強對流天氣領域的機器學習技術提供參考。
1 機器學習在強對流監測中的應用
強對流天氣監測依賴于氣象衛星、天氣雷達、閃電定位儀、自動氣象站等具備高時空分辨率的中小尺度監測網, 是強對流預警預報的基礎。
1.1 云和降水分類
靜止氣象衛星觀測具有覆蓋范圍廣、時空分辨率高的特點,是監測強對流天氣的重要手段。目前,國內外利用衛星遙感技術,進行強對流云團識別的研究已經取得了一定的成果。
白慧卿等(1998)通過人工神經網絡方法進行了地球靜止氣象衛星(GMS)云圖中的4類云系[冷鋒、靜止鋒、雹暴云團、強對流復合體(MCC)]識別,識別準確率超過99%,優于貝葉斯方法,認為神經網絡方法更適合于云系的特征識別。Tebbi and Haddad(2016)利用支持向量機,輸入歐洲第二代靜止氣象衛星(Meteosat Second Generation,MSG)自旋增強可見光和紅外成像儀(spinning enhanced visible and infrared imager,SEVIRI)的12個頻譜參數,構建不分晝夜的云分類模型,并對比了神經網絡和支持向量機的分類效果,最終發現支持向量機具有更好的效果,其對于層云和對流云的分類臨界成功指數(CSI)達到0.55,命中率(POD)達到0.74.
Kim et al(2017a)利用Himawari-8衛星云圖,選取與對流云發展密切相關的相關因子(interest fields,IF),構建了隨機森林、極端隨機樹(extremely randomized trees,ERT)、邏輯回歸等模型,有效地識別了對流系統的上沖云頂特征,相對于傳統的紅外云圖紋理識別、紅外與水汽通道亮溫差等算法,有了明顯的提高。胡凱等(2017)利用遷移學習中的多源加權Tradaboost算法(內部采用極限學習機作為分類器)對環境與災害監測預報衛星(HJ-1A/B)的數據進行云的檢測,利用人工(多源)標注的大量厚云的樣本構成多源輔助樣本集,利用少量標注的薄云樣板構成目標樣本集。結果表明遷移學習可以充分利用容易獲得的大樣本厚云輔助樣本知識,對同類型有關聯的小樣本薄云分類器進行識別提高。
利用雷達進行對流降水的分類,同樣是監測對流發生發展的有效方式。王靜和程明虎(2007)利用BP神經網絡模型對單站雷達進行了三種降水類型(對流云降水、層狀云降水和混合云降水)的分類。Xu et al(2009)將臺風外圍螺旋云系降水的分割識別化為機器學習的分類問題,利用支持向量機,在雷達反射率圖像上,實現了云系降水區域類型的分割,為大風和強降水區域的監測提供了實時依據,算法效果優于最大熵、圖像邊沿檢測等傳統算法,具有更好的準確性和魯棒性。Gagne II et al(2009)基于多普勒雷達資料,利用集成K-means和決策樹算法,實現對流風暴識別和對流降水識別。K-means算法實現從線性對流系統中聚類分離出對流系統。決策樹則對對流風暴進行分類,將對流單體分為“孤立脈沖風暴”“孤立強風暴單體”“多單體風暴”,將線性對流系統實現“前導層狀云”“尾隨層狀云”“平行層狀云”的分類。
綜合利用衛星和雷達等多源數據,可以綜合獲取云和降水分類信息。匡秋明等(2017)提出了一種基于雷達、衛星、地面觀測等多源數據的多視角學習晴雨分類方法,該方法應用隨機森林方法分別對多視角進行樣本學習,得到晴雨分類模型。結果表明,與單獨使用衛星、雷達、地面觀測站等單一數據源相比,該方法提高了1 km×1 km和6 min時空分辨率晴雨分類的準確率,降低了漏報率和空報率。
1.2 定量降水估計與監測
利用衛星、雷達等遙感探測資料,進行定量降水估計,能夠有效提高降水觀測的時間和空間分辨率,同時對于無氣象觀測站點的區域,也是很好的補充。利用機器學習,能夠有效擬合遙感探測數據與降水量的非線性關系,實現更精確和精細的降水估計結果。
基于MSG衛星的成像儀SEVIRI探測的云頂頂高、云頂溫度、云相態和云水路徑等因子,Kühnlein et al(2014a;2014b)利用隨機森林、Meyer et al(2016) 利用4種機器學習算法(RF、神經網絡、平均神經網絡、SVM)進行定量降水估計。他們首先區分降水區與非降水區,然后實現對流降水與非對流降水區域劃分,最后對不同降水區域使用不同的降水反演因子,實現對中緯度地區全天候的定量降水估計。其中,各種降水區域的降水反演因子由機器學習通過衛星云圖和雨量計觀測到的降水量擬合得到(Ouallouche et al,2018)。在此基礎上,Lazri and Ameur(2018)將算法進行了升級,將支持向量機、神經網絡和隨機森林等算法進行了集成,同樣利用MSG-SEVIRI數據集,改進了訓練方式,將分類效果欠佳的樣本進行了二次訓練和預測,從而達到了比單個分類器更好的訓練效果,最終其分類準確率可達到97.4%。
Meyer et al(2017)認為,如果將衛星云圖上降水反演點周圍的紋理特征等信息加入機器學習模型,將能有效地改進定量降水估計,因此構建了基于MSG和GLCM(grey level co-occurance matrix)的神經網絡模型,結果卻發現,在增加了反演格點周圍紋理信息的情況下,可能由于神經網絡模型無法有效提取空間紋理信息等原因,降水反演效果并沒有明顯改善。
利用雷達Z-R關系進行定量降水估計仍然具有較大的改進空間。邵月紅等(2009)利用多普勒雷達的回波強度資料及相應的雨量計觀測資料,通過前向反饋(BP)神經網絡方法來估測臨沂地區的降雨量,對比了Z-R關系估測的降雨量,表明BP神經網絡估測精度要明顯優于固定Z-R關系式,BP神經網絡估測的降雨量與站點實測雨量吻合性較好,而固定Z-R關系式估測的降雨量存在不同程度的低估現象。Grams et al(2014) 在雷達估測降水的基礎上,引入快速更新循環分析場中的環境變量,對比了各種變量對于改善定量降水估計的作用,最后發現零度層高度和溫度遞減率對于改進雷達估測降水最為重要。利用決策樹,融合雷達觀測數據和數值分析場數據,得到比傳統固定Z-R關系更為精確的降水估算。
基于雙偏振雷達觀測利用機器學習方法更進一步提高了雷達估測降水的精度。Islam et al(2012) 集合并對比了支持向量機、神經網絡、決策樹、鄰近聚類等算法,利用雙偏振雷達觀測反射率因子、差分反射率因子、交叉相關系數、速度和譜寬等,實現了地面雜波、海浪雜波以及其他異常回波的識別,識別準確率可達98%~99%,在去除雜波的基礎上有效改進了雨量監測。
1.3 冰雹和雷暴大風監測
冰雹和雷暴大風往往在局地性極強的對流性系統中發展而來,由于局地性很強,現有觀測網依然難以完全捕捉(鄭永光等,2017),具有很大的觀測難度。在目前我國大范圍取消人工觀測的趨勢下(中國氣象局,2013),使得冰雹和雷暴大風的直接觀測數據更顯稀少。因此,采用雷達和衛星等觀測資料進行冰雹和雷暴大風的識別,既非常重要,也顯得很有必要。
目前氣象業務中,由單站雷達PUP(principal user processor)系統生成的強冰雹指數,通常強冰雹空報率過高。王萍和潘躍(2013)為了解決這個問題, 依據概念模型對強冰雹回波單體特點的描述, 設計并實現了 “懸垂度” 等多個特征提取算法。以此為基礎, 選用基于徑向基核函數的非線性支持向量機得到強冰雹識別模型, 將待測樣本遠離最優分類超平面的相對程度定義為新冰雹指數。試驗表明, 本方法較目前業務上普遍使用的冰雹指數法具有更高的命中率, 同時空報率大大降低。另外,為了區分短時強降水和冰雹天氣,王萍等(2016)利用決策樹算法,基于系統結構疏密性特征、移出率、液態水含量及累加液態水含量等特征,實現對冰雹和短時強降水的分類識別。試驗表明,本文方法對雷達站50 km以內范圍的雷暴系統產生的短時強降水擊中率達到89.1%,誤報率為9.5%;冰雹的擊中率為79.8%,誤報率為3.5%;平均臨界成功指數達到80.0%。
相對于冰雹探測,雷暴大風的探測可借助我國稠密的自動氣象站觀測數據,在大風觀測基礎上,利用雷達、衛星資料進行質量控制,能夠較好地實現雷暴大風的識別。李國翠等(2013)、周康輝等(2017)在地面氣象觀測站大風記錄的基礎上,結合多源數據(包括雷達、衛星、閃電、溫度、露點等觀測數據),利用模糊邏輯算法,實現對雷暴大風與非雷暴大風的有效識別,可在全國范圍對雷暴大風進行實時監測。楊璐等(2018)基于雷達基數據和加密自動氣象站數據,利用支持向量機算法建立了雷暴大風天氣的有效識別模型。
1.4 風暴識別和追蹤
基于衛星、雷達、閃電等觀測數據,利用機器學習算法,能夠有效實現對對流系統的識別和追蹤,提取對流系統的移動方向、移動速度等信息,為對流預警提供重要信息。
雷達觀測能夠提供近地面的風暴的三維結構特征,因此利用雷達數據可有效進行風暴的識別和追蹤。Lakshmanan et al(2000)利用遺傳算法,從雷達圖像中逐層識別,進而實現對風暴的識別,能有效分辨對流系統的分裂和合并情況。在此基礎上,Lakshmanan et al(2005)發展了中氣旋識別算法,在三維雷達圖像上識別風暴尺度的旋轉,并建立神經網絡,將中氣旋特征和環境條件特征作為輸入,進一步識別中氣旋風暴是否會發展成龍卷,在實際應用中取得了很好的效果。
Haberlie and Ashley (2018a;2018b)基于雷達拼圖數據,利用機器學習算法,構建了對流識別、追蹤算法。首先,將雷達回波進行分割,識別并分割水平尺度大于100 km的深對流系統的連續或半連續區域。將分割好的對流系統,根據降水人為主觀地為每個樣本分配下列標簽之一:(1)中緯度MCS,(2)無組織對流,(3)熱帶系統,(4)天氣系統,(5)地面雜波和/或噪音。然后訓練隨機森林,梯度增強(gradient boosting)和XGBoost,結果表明算法具有良好的對流云識別效果。最后,在此基礎上,利用空間匹配的方式,實現對MCS的追蹤。
基于閃電數據的雷暴識別,追蹤與外推算法也有一些嘗試。侯榮濤等(2012)、周康輝等(2016)分別利用K近鄰法(k-Nearest Neighbor,kNN)、密度極大值搜索算法等聚類算法,實現對閃電簇的識別,從而實現對雷暴活動區域的識別,進而分別利用路徑曲線擬合、Kalman濾波器等算法,實現對雷暴的追蹤與臨近預報。
1.5 深度學習在強對流監測中的應用
雷達、衛星等觀測數據本質屬于圖像的范疇,而深度學習近年來在圖像識別領域取得極大成功。因此,利用深度學習可以有效從雷達圖像、衛星云圖中識別出強對流天氣。
利用深度學習,可以有效利用雷達探測的三維空間數據,提取冰雹事件的三維結構特征,如冰雹在即將發生或者發展過程中,在雷達回波圖像上,具有很明顯的諸如三體反射、弱回波區(WER)、回波懸垂等特征。Wang et al(2018)利用深度學習算法,基于單站雷達的三維探測數據,輸入不同高度的雷達掃描切面,提取產生冰雹的對流云中的有界弱回波區等特征,從而取得比傳統方法更好的冰雹識別效果。
最近,鄭益勤等(2020)利用Himawari-8衛星圖像,構建了用深度信念網絡(DBN)進行強對流云團自動識別的方法,該方法可以有效識別處于初生到消散不同階段的強對流云團,并在一定程度上去除卷云。與單波段閾值法、多波段閾值法和支持向量機這三種方法相比,其提出的方法能夠提高強對流云團的識別精度(對流區域識別效果如圖1)。

圖1 2017年3月14日08時使用深度學習進行強對流云識別的結果(鄭益勤等,2020)(a)TBB08-TBB13,(b)初始識別結果,(c)閉運算后結果Fig.1 The identical results of convective storm of satellite images with deep learning method at 08:00 BT 14 March 2017 (Zheng et al, 2020)(a) TBB08-TBB13, (b) initial recognition result, (c) result of closed operation
深度學習也可以從氣象要素場中識別天氣系統。Lagerquist et al(2019)利用深度卷積神經網絡,從溫度、比濕、風場、位勢高度等變量中,成功實現對冷鋒和暖鋒識別,通過與人工標記的冷鋒和暖鋒對比后發現,如果誤差250 km以內算正確,其命中率達到73%,虛警率為35%,臨界成功指數達到52%。
2 機器學習在強對流臨近預報中的應用
2005年,世界氣象組織(WMO)定義的臨近預報(或稱為甚短時預報)為0~6 h的天氣預報,現已得到了廣泛認可(俞小鼎等,2012;Wilson et al,2010;Sun et al,2014)。不過我國預報業務通常將0~2 h的天氣預報稱為臨近預報(俞小鼎等,2012),因此,本文將0~2 h的預報稱為臨近預報,2~12 h稱為短時預報,12~72 h為短期預報。傳統的線性外推算法無法判斷對流的生消演變,利用機器學習算法,能夠從雷達反射率因子、衛星云圖等觀測數據中,提取對流初生、發展、消散等特征,從而為判斷對流演變起到一定作用。
2.1 基于雷達回波的外推預報
將機器學習應用于強對流臨近預報,最直觀的設想是利用機器學習改進雷達回波外推預報。傳統的外推方法,如TITAN(Dixon and Wiener,1993)、SCIT(Johnson et al,1998)以及光流法(Bechini and Chandrasekar,2017)等等,能夠有效判斷對流的移動趨勢,但是無法判斷對流系統的生消演變等特征,因此無法給出對流初生、增強或減弱等預報(Wilson et al,1998)。利用機器學習,一定程度上能夠克服上述問題。
Yu et al(2017)將過去時次的雷達回波反演的降水量、海拔、經緯度作為預報因子,構建隨機森林和支持向量機,進行0~3 h降水量預報,并對比了隨機森林和支持向量機的預報效果,結果表明兩種算法都能較好地實現0~3 h降水量預報,而支持向量機在此任務中表現更好。Foresti et al(2019)從10年的雷達組合反射率圖片中,識別和追蹤對流系統,提取包括位置、風場、凍結層高度和時間等變量作為預報因子,應用神經網絡,預報降水系統的加強與減弱。預報結果表明,神經網絡能夠有效預報對流系統的增強和減弱,預報均方根誤差相對拉格朗日外推降低20%~30%。
2.2 基于靜止氣象衛星資料的臨近預報
靜止氣象衛星能夠監測對流云形成初始階段的相關特征,如云體厚度快速增加、云頂溫度急劇下降、云頂相態的變化(Mecikalski et al,2010a;2010b)。因此,應用靜止氣象衛星監測數據,能夠有效實現對對流初生(CI)的監測預警(Mecikalski and Bedka,2006;Mecikalski et al,2013;Walker et al,2012)。
國內外研究人員開展了相關工作,基于靜止氣象衛星數據,開發了大量對流初生預報算法。但傳統方法很大程度上依賴于研究人員的物理認識、統計結果和經驗,針對衛星觀測數據的物理特性,設計對流初生的判據。如當前美國靜止氣象衛星的CI采用的判據包括10.7 μm通道亮溫低于0℃,10.7 μm通道亮溫時間變化趨勢小于-4℃/15 min等等。
基于衛星數據,應用機器學習方法能夠自動實現CI的預測。Han et al(2015)利用通信與海洋氣象衛星(COMS)成像儀數據,應用決策樹、隨機森林、支持向量機等方法,提取了衛星紅外、可見光、水汽等通道中的對流初生特征,成功實現了對流初生判斷與預報,對流初生預報的提前量達30~45 min。Bessho et al(2016)利用Himawari-8衛星中的多通道信息和通道變化趨勢,以及簡單的邏輯回歸模型,實現對快速發展的對流區域(RDCAs)的識別,為即將發展的對流提供提前告警信息。Lee et al(2017)利用決策樹、隨機森林、邏輯回歸等模型,基于Himawari-8成像儀的多通道數據,選取12個IF,提取其變化特征,進行對流初生的預報。
2.3 綜合多源資料的臨近預報
靜止氣象衛星具備對對流初生的觀測能力,觀測對流云頂的發生發展特征;天氣雷達觀測對流風暴的內部分布特征;數值模式預報數據可提供對流發展的環境條件。多源觀測數據表現形式、物理意義各異,如何將多源數據實現有效融合,也是當前面臨的挑戰之一。
機器學習算法能夠自動學習并提取特征,為多源數據融合提供了新的思路。如Mecikalski et al(2015)基于靜止氣象衛星數據結合數值模式數據,選取了25個相關要素,利用邏輯回歸和隨機森林,實現了歐洲地區的對流初生預報。 Ahijevych et al(2016)利用隨機森林,融合雷達、衛星云圖和數值模式數據,進行0~2 h的對流初生預報,模型有效探測了99%以上(總數550個)的初生系統。Han et al(2017)利用支持向量機算法,基于多普勒雷達數據和高分辨率分析場,自動提取雷暴發生發展特征,訓練了預報模型,基于多普勒雷達四維變分分析系統(VDRAS)預報場實現了雷暴的臨近預報(流程見圖2)。
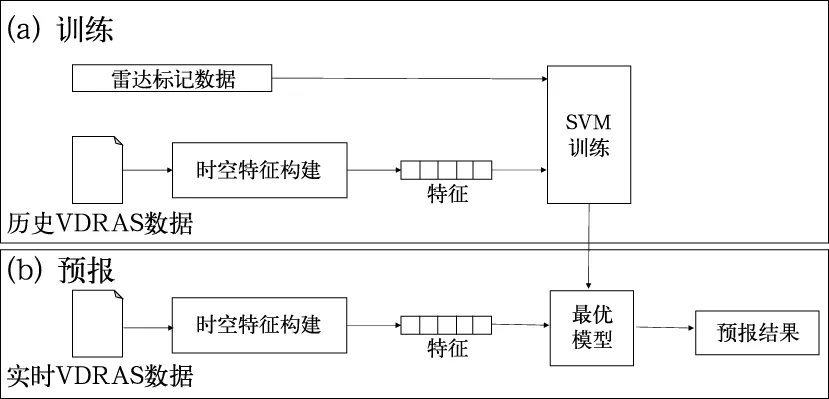
圖2 基于多源數據(雷達和VDRAS數據),利用支持向量機進行對流臨近預報的流程(Han et al,2017)Fig.2 Flow chart of SVM for convective weather nowcasting with VDRAS data (Han et al, 2017)
Marzban and Witt(2001)和Lagerquist et al(2017)利用機器學習算法,融合使用雷達資料追蹤的雷暴特征和對流系統附近的探空觀測特征,對對流性大風和冰雹進行臨近預報,結果表明,其不僅能夠有效預測對流單體內部的大風(提前0~15 min),而且能夠預測對流系統10 km以內范圍的陣風鋒大風(提前60~90 min),具有較好的實用價值。Czernecki et al(2019)利用隨機森林,融合了雷達數據、閃電數據和再分析數據的對流參數,進行大冰雹的預報。結果表明,雷達數據在冰雹預報中起到主要作用,而對流參數作用也不可被忽視。McGovern et al(2014)構建了時空決策樹模型,基于多源數據包括雷達、地面觀測數據、飛機觀測數據等,進行強對流天氣(龍卷和對流顛簸)的預測。其預測模型能夠清晰地顯示各個預報因子的作用,從而為更好地理解強對流發展原因,提供較好的思路。
Apke et al(2015) 則用機器學習方法分析了對流環境對于對流初生的作用,研究是否可以將對流參數引入,改進利用衛星進行對流初生的預報效果。他們應用主成分分析(PCA) 和二次判別分析(QDA)進行了相關性分析。結果發現,CAPE和CIN對于改進衛星的對流初生預報具有積極的作用。在高CAPE、低CIN的環境下,對流初生具有更好的預報性。用QDA方法驗證了,在實現衛星數據和數值模式預報數據融合應用的情況下,CI預報效果更好。
2.4 深度學習在臨近預報中的應用
利用深度學習強大的特征提取能力,能夠提取對流系統在雷達回波上生消演變特征,進而為預報其生消演變提供有效參考。Shi et al(2015;2017)、Kim et al(2017b)、Wang et al(2017)、郭瀚陽等(2019)、施恩等(2018)、吳昆等(2018)針對雷達回波外推問題,根據對流系統的演變特征,提出相適應的深度學習網絡,主要基于卷積神經網絡和循環神經網絡,自動學習對流系統的回波演變特征(典型深度學習網絡結構如圖3),實現了雷達回波的外推預報,并具備一定對流系統生消演變的預報能力,檢驗表明,在TS評分上優于光流法、TITAN等傳統外推方法。然而,目前深度學習外推隨著時間推移,其空間分辨率呈現明顯的下降,回波平滑問題較為嚴重,一定程度上影響業務應用效果。
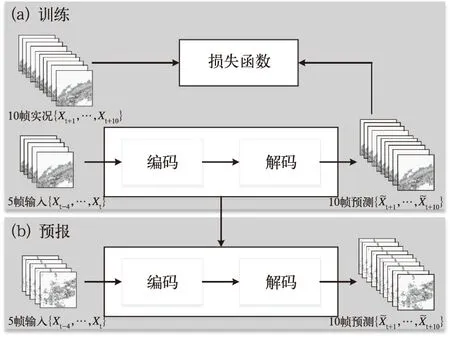
圖3 基于深度學習的雷達外推流程(郭瀚陽等,2019)(a)訓練過程, (b)預報過程Fig.3 Flow chart of radar reflectivity image extrapolation with deep learning method (Guo et al,2019)(a) training, (b) forcasting
深度學習也可提取VDRAS等快速變分同化分析場中的對流發生發展特征。Zhang et al(2017)基于雷達與實況再分析場,構建了深度卷積網絡,實現了對流區(雷達反射率>35 dBz)的有效臨近預報,由于算法自動提取了對流系統的時空演變特征,因此也具有對流發展的預報能力。
深度學習在融合多源觀測數據進行臨近預報方面,也存在巨大的潛力。深度學習能夠綜合提取多源觀測數據中時間、空間上的有效信息。Zhou et al(2020)構建深度學習三維語義分割模型,從雷達回波、衛星云圖、閃電密度等觀測數據中提取閃電的時空發生、發展特征,實現了有效的0~1 h的閃電預報,且具備一定的對對流生消演變的預報能力。S?nderby et al(2020)構建了深度學習模型Metnet,綜合使用卷積、LSTM(long short-term memory)、注意力機制等方法,利用衛星、雷達、降水等觀測數據,實現了更長時效(未來0~8 h)的降水預報模型。Metnet預報的時空分辨率可達到2 min、1 km,預測的1 mm降水準確率超過了快速更新同化高分辨率數值模式(HRRR),展示了深度學習方法巨大的應用潛力。
3 機器學習在強對流短時和短期預報中的應用
相對于臨近預報中主要使用實時觀測數據,短時和短期預報則更專注于數值預報模式的使用。目前,中央氣象臺強對流短期預報,主觀預報使用的主要是“配料法”。該方法由Doswell III et al(1996)提出,在我國有了較多的發展與應用(張小玲等,2010;俞小鼎,2011)。
配料法確定預報的基本構成要素或“配料”,構成要素一般是相對獨立的氣象變量,給預報員提供了天氣預報的清晰思路。基于不同天氣的物理模型和“配料法”,中央氣象臺預報員設計了不同類型強對流天氣發生發展的對流環境(水汽、動力、能量等方面)物理參數組合,給出了分類概率預報產品。強對流天氣“配料法”等主觀預報產品評估表明(吳蓁等,2011;唐文苑等,2017),預報員主觀統計提取對流特征并經過“配料組合”得出的強對流預報結果具有較好的有效性和預報能力,但必然也會存在一定的局限性。在觀測和模式預報產品越來越龐大的今天,預報員主觀分析,提取對流發生發展特征,難度越來越大。因此,有必要利用各種機器學習算法進行上述工作。
3.1 基于探空觀測的潛勢預報
探空數據能夠提供當地的大氣層結環境特征,為判斷短時預報時效內對流是否發生提供有效依據。Sánchez et al(1998)、趙旭寰等(2009)、陳勇偉等(2013)、楊仲江等(2013)利用探空數據,基于神經網絡建立了不同的地區的雷暴或冰雹預報模型,取得了較好的預報效果。Manzato(2013)同樣利用探空反演的對流指數因子,構建多個神經網絡模型,并用集成學習的思維、Bagging算法,實現集成學習,得到更有效的冰雹預報。
探空數據還能與其他數據進行綜合使用。Billet et al(1997),利用探空數據(T850、零度層溫度、平均風暴相對入流),結合雷達反演的VIL,構建回歸模型,進行對冰雹和直徑大于1.9 cm的大冰雹的概率預測。然而探空觀測僅能代表當前的大氣環境特征,因此預報的時效更短,更長時效的預報則依賴于數值天氣預報。
3.2 基于全球數值預報模式的潛勢預報
李文娟等(2018)將隨機森林算法應用于分類強對流的潛勢預測,建立了四分類(短時強降水、雷暴大風、冰雹和無強對流天氣)預報模型。選取物理意義明確的對流指數和物理量,開展強對流天氣的分類訓練,利用實時的NCEP預報場進行預報,結果表明整體誤判率為21.9%,85次強對流過程基本無漏報,模型尤其適用于較大范圍強對流天氣。 Herman and Schumacher(2018)利用NOAA全球集合預報系統數據,構建了隨機森林模型,能夠實現2~3 d的極端降水預報。為了應對極端降水的極端性,他們不僅將數值預報的對流指數和溫壓濕風等因子作為預報因子,同時選擇了眾多背景預報因子。背景預報因子包括1年和10年的格點ARI(average recurrence intervals)最大、最小、中位數值,1年和10年的區域ARI(average recurrence intervals)最大、最小、中位數值,以及經度和緯度值。Liu et al(2019),應用ERA-Interim再分析數據,用貝葉斯方法分析熱力和動力因子與高頻次閃電雷暴云的相關性,發現CAPE、CIN、底層風切變、暖云厚度等變量與高頻次閃電雷暴云最為相關,為高頻次閃電雷暴云的預報給予了啟發。
3.3 基于高分辨率數值預報模式的強對流天氣預報
高分辨率數值模式,具有更高的時空分辨率,能夠提供更精細的對流風暴系統結構特征,從而為強對流短時與短期預報提供更多的有效信息。Collins and Tissot (2015) 選取了43個高分辨率數值模式預報的預報因子,訓練了18個神經網絡模型,其中9個做了特征選擇,另外9個包含所有預測因子,展示了特征選取工作的重要性。最終得到預報效果最好的雷暴預報模型,其預報效果媲美于業務預報員。Gagne II(2016)基于CAPS(Center for Analysis and Prediction of Storms)的SSEF(Storm-Storm Scale Ensemble Forecast)集合預報模式,基于決策樹算法,構建了方便預報員理解的冰雹預測決策樹(圖4),能夠直觀展示通過決策樹算法從大量數據中提取的判斷流程。Whan and Schmeits(2018) 利用對流可分辨模式HARMONIE-AROME數值模式的大量對流參數作為預報因子,訓練了邏輯回歸、決策樹等模型,實現了荷蘭地區的降水預報,結果表明其對于降水量大于30 mm·h-1的短時強降水也具有較好的預報效果。
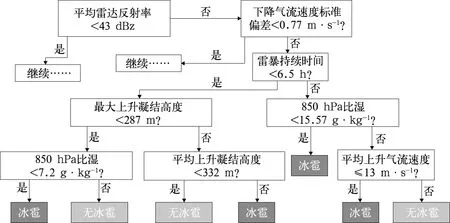
圖4 利用決策樹算法生成決策樹,實現對冰雹的自動化預報(Gagne II, 2016)Fig.4 Visualization of judging process in decide-tree for hail forecasting (Gagne II, 2016)
Gagne II et al(2015;2017)對快速更新的高時空分辨率的數值模式預報做了更精細化的處理,將NWP輸出的結果進行了風暴識別,將其識別結果與實況的雷達回波風暴單體進行匹配,然后對其是否發生冰雹進行預測。利用機器學習模型,從風暴的結構特征和對流參數特征,學習風暴單體是否會產生冰雹的特征,進而實現對冰雹的精細化預報。
3.4 深度學習在強對流短時和短期預報中的應用
短時預報可利用深度學習融合實況觀測數據和高分辨率數值模式數據。Geng et al(2019)和Lin et al(2019)利用數值預報模式WRF(Weather Research and Forecasting)和閃電觀測實況,構建了基于ConvLSTM(convolutional long short-term memory)的深度學習模型,用于提取數值模式數據和觀測數據的時空變化特征,進而實現未來6 h或12 h的閃電預報。由于深度學習能夠有效綜合提取觀測數據和數值預報模式數據的信息,因此其預報性能顯著優于單純依賴數值預報模式對流參數化方案的預報效果。而且,綜合應用觀測數據和數據預報模式數據的深度學習方法預報效果,也明顯優于使用單一數據的深度學習方法效果。周康輝等(2021)基于多源觀測數據和高分辨率數值天氣預報數據的特性,構建了一個雙輸入單輸出的深度學習語義分割模型,使用了包括閃電密度、雷達組合反射率拼圖、衛星成像儀6個紅外通道,以及GRAPES-3 km模式預報的雷達組合反射率等共9個預報因子。結果表明,深度學習模型能夠較好地實現0~6 h的閃電落區預報,具備比單純使用多源觀測數據、HNWP數據更好的預報結果。深度學習能夠有效實現多源觀測數據和NWP數據的融合,預報時效越長,融合的優勢體現的越明顯。
短期預報可使用深度學習對全球數值天氣預報模型進行釋用。Zhou et al(2019)建立了6層的卷積神經網絡,應用于分類強對流的潛勢預測。利用NCEP再分析資料計算的超過100個對流指數和物理量,開展強對流天氣的分類訓練。訓練好的模型接入實時的NCEP預報場進行預報。結果表明(如表1),其預報效果能夠為預報員給出有價值的參考。Zhou et al(2019)基于卷積神經網絡的分類強對流預報產品已經成為中央氣象臺強對流天氣預報重要的業務參考產品(張小玲等,2018)。
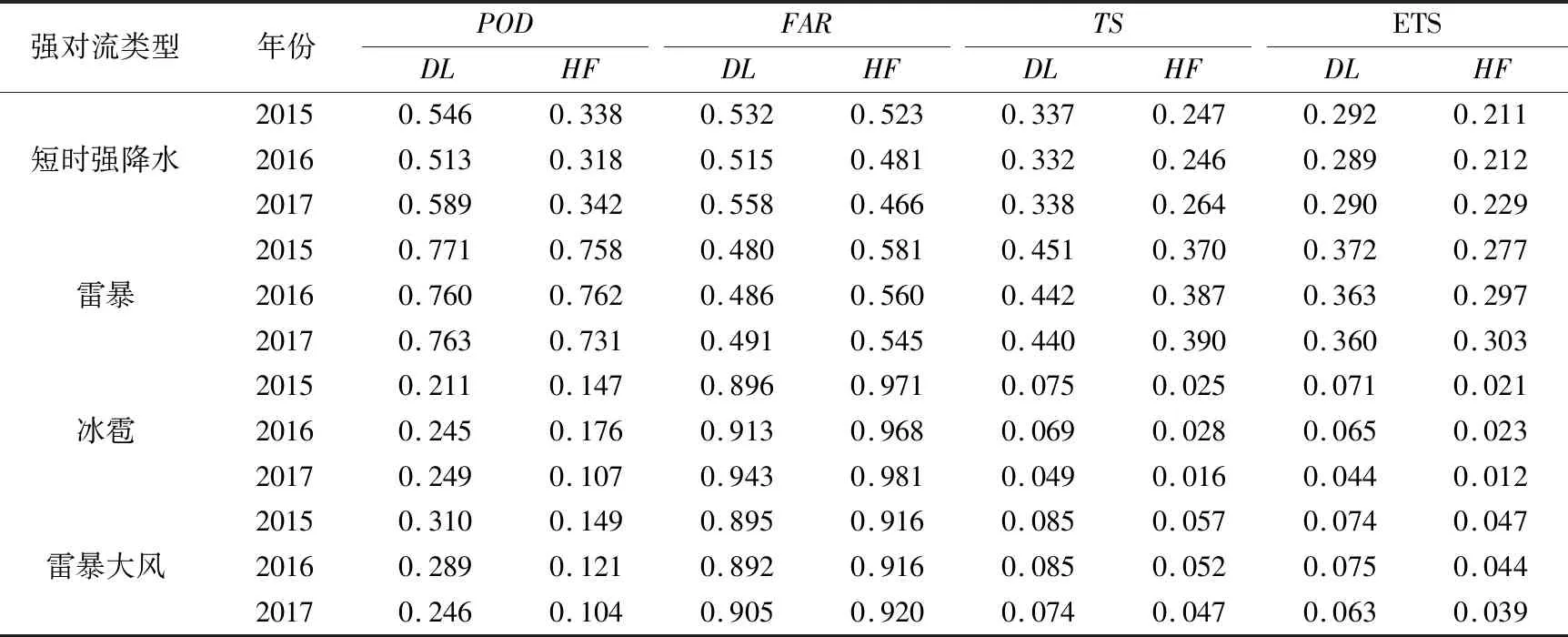
表1 2015—2017年4—9月08時起報的12 h基于卷積神經網絡的分類對流潛勢預報(DL)和預報員主觀預報(HF)的對比情況(Zhou et al, 2019)Table 1 Evaluation of deep CNN (DL) forecasts and human forecasts (HF) from April to September of 2015, 2016 and 2017 (12 h forecast was initiated at 08:00 BT; Zhou et al, 2019)
4 存在的問題和未來發展
目前,機器學習在強對流監測、強對流短時臨近預報與短期預報中,已經發揮了重要的積極作用,其應用效果往往優于原有的傳統經驗和方法。在樣本標記充足、標記準確的情況下(如對流云識別、雷達回波外推、閃電預報等),機器學習尤其是深度學習,能夠從海量數據中有效提取特征,進而進行有效預報;在樣本稀缺且樣本標記不確定性較大的情況下(如冰雹、龍卷等極端強對流天氣),不管是深度學習或傳統機器學習解決此類問題的能力有待進一步提高。總體而言,機器學習目前存在以下問題,未來在以下方面會繼續發展。
4.1 存在的問題
(1)相對對流天氣未發生(負樣本)頻率,對流天氣的發生(正樣本)頻率明顯偏低。因此存在嚴重的正負樣本不平衡問題。而且,由于對流系統尺度較小,觀測網絡經常存在漏觀測的情況,因此正負樣本不平衡的問題進一步突出。目前,有一些相關的算法可解決正負樣本不平衡問題,然而對于極端天氣事件,其樣本不平衡問題仍然非常顯著,對于機器學習模型的訓練屬于一大挑戰。
(2)由于機器學習各類算法,本質在于提取特征和標記的相互聯系,因此對于特征和標記的質量要求極高。特征和標記的質量越高,其算法分類的效果越好。因此,算法仍然非常依賴觀測數據、數值模式預報等輸入數據質量。而這些基本數據也是大氣科學發展的基礎,由此可見,機器學習在大氣科學中的應用效果,仍然與大氣科學的發展基礎息息相關。
(3)在強對流監測預報中,大部分問題可以歸為分類問題,如對流云識別、強對流天氣識別、對流初生預報、基于數值預報模式的強對流分類預報等。目前從各項研究結果看來,強對流監測預報中的分類問題,應用機器學習算法效果顯著(Zhou et al,2019; Wang et al,2018)。降水量預報屬于回歸問題,應用機器學習方法也有較明顯的改進(邵月紅等,2009;Meyer et al,2017))。深度學習雷達回波外推也屬于回歸問題,雖然檢驗指標優于傳統方法,但是始終存在圖像模糊的問題(Shi et al,2015;2017),應用效果仍待進一步改進。無監督學習,如聚類算法、主成分分析等,在強對流天氣領域應用場景有限。由此可見,借鑒目前深度學習等技術的發展趨勢,未來可側重用分類的思路解決強對流監測預報中的相關問題。
(4)根據“沒有免費的午餐定理(No Free Lunch Theorem)”(Wolpert and Macready,1997),沒有一種機器學習算法,包括深度學習,能夠在所有氣象應用場景中都取得最好的應用效果。因此,我們仍然需要全面了解各種機器學習的算法的優缺點,根據使用場景選取最合適的算法。未來,各種傳統算法依然會在各自擅長的領域中頻繁現身。此外,我們也可以使用多種機器學習算法集成的方法,以達到更好的預報效果。
(5)極端強對流天氣事件,比如阜寧龍卷(鄭永光等,2016b)、開原龍卷(張濤等,2020;鄭永光等,2020)、2017年5月7日廣州暴雨(田付友等,2018)等,一直以來,屬于天氣預報領域的重大挑戰。對于機器學習而言,由于極端天氣樣本極其稀缺,因此,直接構建這樣的預報模型可能具有較大的難度。這種大氣科學的難題,同樣也是機器學習的重要挑戰,必須通過熟練使用各類機器學習算法,嘗試采用遷移學習等方法對此問題進行研究。
(6)深度學習訓練過程涉及到大量的并行運算,因此,目前對于高端GPU顯卡或者云計算資源的使用不可或缺。對于深度學習網絡,其運算需求往往非常巨大。因此,可以預見,未來高性能計算能力建設中,高性能GPU并行計算能力或者云計算資源的建設應該會加速推進。
(7)目前,機器學習算法可以基于雷達或者衛星觀測資料提取對流初生等特征,進行有效的臨近預報。然而,其尚不能完全考慮大氣運動的基本物理規律,因此短期內不能代替數值預報模式進行基于物理方程的數值預報。
4.2 未來發展
盡管目前機器學習在強對流監測和預報中依然存在一些制約,但機器學習所展示出來的性能表現,表明其在未來應該會成為我們越來越有力的工具(Reichstein et al,2019)。未來機器學習應當會在以下幾個強對流天氣監測和預報方面進一步發展:
(1)利用機器學習方法進行多源數據的更有效融合應用,從而更好地實現強對流的監測和臨近預報。衛星、雷達、閃電、自動氣象站等觀測數據,各有優勢與劣勢,如果充分發掘各自的優點,進行綜合應用,最大化地體現觀測數據的優勢將成為未來強對流監測和臨近預報的一大挑戰。此外,高頻次的觀測數據還可以與高時空分辨率、快速更新同化的數值模型進行有效融合,實現臨近預報到短時預報的無縫過渡。
(2)如果能對風暴的不同階段的演變特征實現有效識別,將能更好地實現強對流天氣的提前預警。可以嘗試利用機器學習,進行中氣旋、上沖云頂、弓狀回波等特征的識別,相對于直接利用天氣現象作為標記,對于冰雹、雷暴大風、龍卷等強烈對流天氣能起到更加提前的預警效果。
(3)依托數值預報模式,利用機器學習,進行數值模式預報訂正和釋用,將進一步提升和改進預報水平。數值模式依靠大氣運動規律,對大氣運行進行計算,而機器學習通常只是擬合預報因子和標記間的相關關系,并不注重其物理規律。將數值模式與機器學習相結合,能實現物理規律和相關關系的更好結合,進一步提升模式預報結果的深度應用。機器學習算法如何與物理規律相結合進一步提升監測和預報能力依然任重道遠
(4)利用機器學習可實現強對流規律和物理原理的進一步認識。目前,除了決策樹等算法,大部分算法擬合過程猶如“黑箱”,雖然其預報效果較通常的統計方法或者主觀方法有所提升,但是其過程通常無法理解。目前,將深度學習特征提取過程可視化,也已經成為一個熱點研究方向(Yosinski et al,2015; Rudin,2019; McGovern et al,2019),通過這樣的可視化與解釋,應當會對氣象學者進一步理解中小尺度天氣現象有啟發。
5 結 論
強對流天氣監測和預報一直是氣象學中最具挑戰的領域之一。為了提升其水平,氣象學和相關領域的專家在不斷求索,迄今為止已經取得了重大進展(張小玲等,2018;McGovern et al,2017;Haupt et al,2018),但與窮究大氣變化規律的終極目標仍很遙遠(許小峰,2018)。以機器學習為代表的人工智能的運用,為強對流的監測和應用提供了新的途徑和方法(Karpatne et al,2019)。
盡管目前機器學習等人工智能技術在多個行業中的應用都如火如荼,但是機器學習并不是萬能的。機器學習在大氣科學領域的應用基礎仍然依賴于高質量的觀測數據、可靠的數值模式預報結果以及深刻的天氣原理認識,且要根據不同的應用場景結合物理機理選擇合適的機器學習方法。究其本質,機器學習只是一個工具,并不能替代基礎天氣觀測數據、數值預報模式、天氣學和大氣動力學基礎理論發展的研究。在利用人工智能技術發展天氣預報技術的同時,也需時刻牢記大氣科學基礎理論才是強對流天氣預報的基礎和土壤。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
中學生數理化·七年級數學人教版(2021年11期)2021-12-06 05:38:48
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
