基于遺傳規劃的紗線質量預測
2021-04-21 02:29:30王侃楓馬佳陸
商品與質量 2021年14期
王侃楓 馬佳陸
1.凱夫曼(上海)貿易有限公司 上海 200051;2.華東師范大學附屬第二中學 上海 201203
精梳毛紡紗線的條干不勻是織造效率和面料質量的重要影響因素。工廠如果能在紡紗工序進行之前預測紗線的條干不勻,在預測的條干不勻不理想的情況下,就能夠通過調整通過不斷調整原料配比和紡紗工藝參數直至預測的條干不勻達到期望的要求,從而可以節約成本和提高效率。本文使用遺傳規劃這一工具建立基于毛條的纖維性能、紗線工藝參數和成紗規格建立預測紗線不勻的經驗工程公式。并使來自工廠的實際生產歷史數據驗證所建立的經驗工程公式的預測精度。本文首先分析紗線條干不勻的影響因素,然后簡介遺傳規劃的原理,最后通過工廠實際生產數據建立預測條干不勻的經驗工程公式并驗證預測精度。
1 紗線條干不勻的影響因素
能過文獻檢索,我們發現以下因素對紗線條干不勻有影響[1-5]:
纖維細度(D)、細度不勻(CVD%)、纖維長度(H)、長度不勻(CVH%)、<30mm短纖維含量、卷曲、紗線號數、捻度、鋼絲圈重量、牽伸倍數和錠速
2 遺傳規劃(GP)原理簡介
遺傳規劃通過模擬自然界“自然選擇,適者生存”,即:具有較強生存能力的生物個體容易存活下來,并有較多的機會產生后代;有較低生存能力的個體則被淘汰,或者產生后代的機會越來越少,直至消亡。遺傳規劃用一個能反應所求解問題的包含函數和變量(或常量)的計算機程序表示一個生物個體,隨機產生一定規模的這些計算機程序即為初始種群。用“適應度”來表示每個個體生存的概率,適應度大的個體表示這個個體生存的概率大的。利用這些計算機程序模擬自然界“自然選擇,適者生存”的交叉/變異等遺傳操作[6-10]。遺傳規劃的操作流程即為:
隨機生成反映所求問題的初始群體,該群體包括由適合表示問題域的函數及變量(或常量)集合構成的一組計算機程序個體;
評價群體中個體的適應度;
根據適者生存、優勝劣汰原則,對群體中的個體施加遺傳操作,以產生更好的一代群體;
重復步驟②和③,直到滿足停止準則為止。停止準則為適應度值或遺傳的代數達到預先設定值。
2.1 生物個體及適應度表達方式
一般情況下,函數集合SF是由若干個函數所組成,即根據問題域的具體情況,F S可以是四則運算符和簡單數學函數,如三角函數、對數函數、指數函數,以及代數操作,布爾操作、條件運算、循環和遞歸的函數等。圖1所示的樹結構所表達的計算程序,即為一個生物個體。
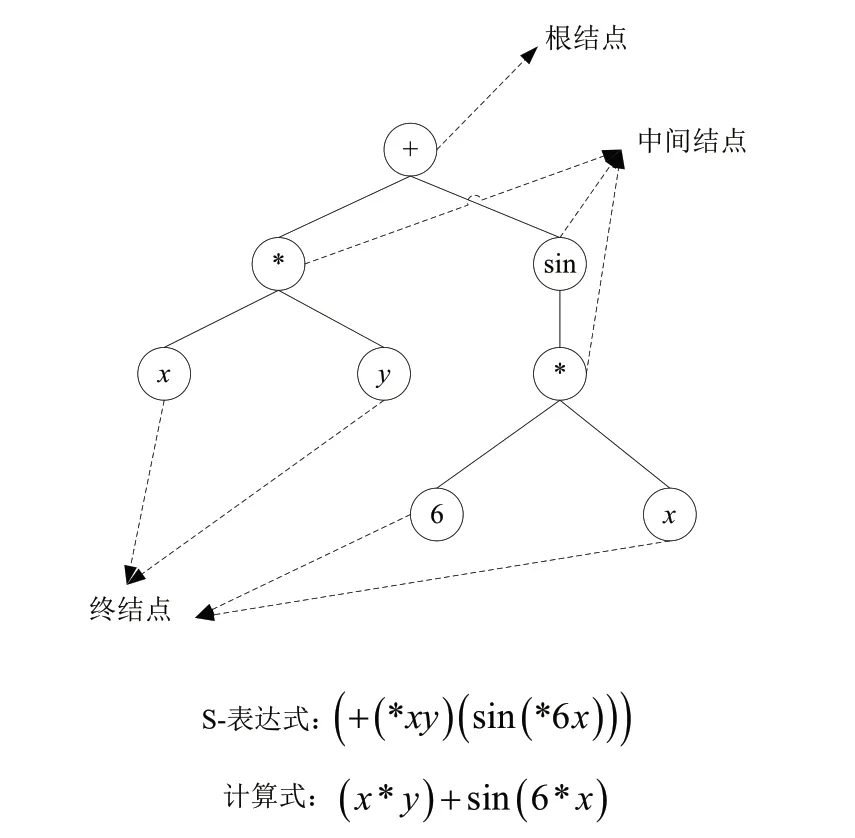
圖1 染色體的樹結構示意圖
本文將上節所分析的紗線條干不勻的影響因素作為自變量,紗線條干不勻作為目標函數。
2.2 適應度的定義
本文的適應度采用紗線條干不勻的預測值和實際值之間的絕對值來定義,預測值和實際值之間的絕對值越小,表示預測的精度越高,預測值越接近實際值。當適應度值達到預選設定值時,遺傳操作即停止。
2.3 遺傳操作
遺傳操作主要有交叉和變異。
(1)交叉。GP交叉操作的對象是兩個父代S-表達式(個體),交叉操作的結果產生兩個子代個體,其中每一個個體都含有來自兩個父代的部分基因。利用一定的方法選擇兩個父代個體需要交叉的部分。圖2所示即為交叉的原理。
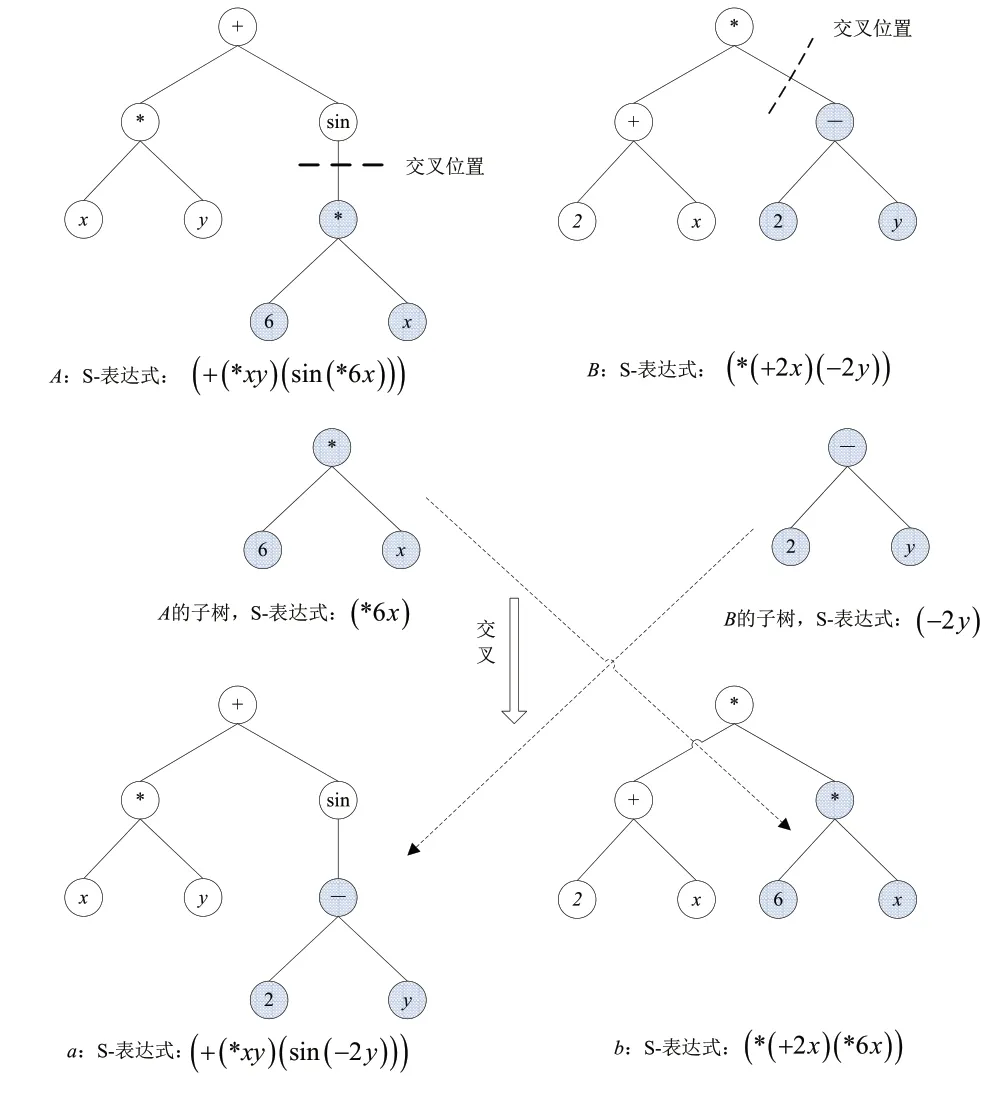
圖2 GP 的交叉操作
(2)變異。變異操作的對象是一個個體的S-表達式,產生的結果是一個新個體的S-表達式。變異操作的過程為:在一個S-表達式中隨機選擇一個變異點,刪除該結點以下的子樹部分,然后插入隨機產生的子樹。變異操作如圖3所示
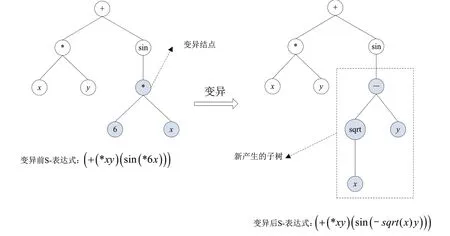
圖3 基本變異操作
3 實驗及驗證
根據本文第一節的分析,我們把所有影響紗線不勻的因素作為紗線不勻工程經驗公式自變量,如表1所示:
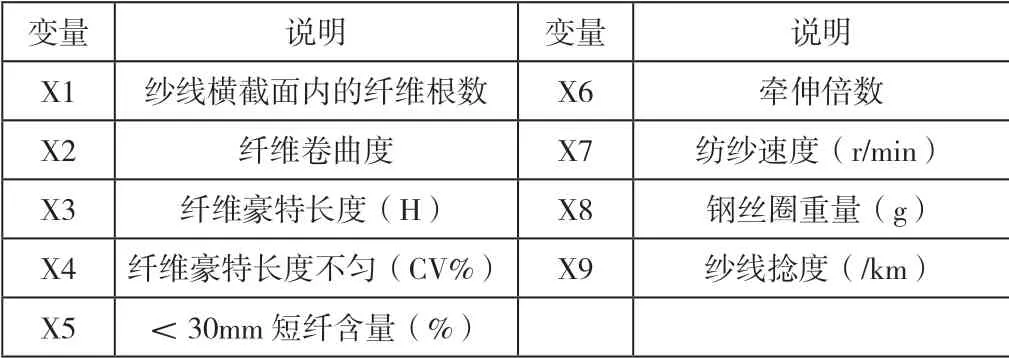
表1 紗線不勻工程經驗公式變量說明
我們收集了工廠2年內共184批的紗線數據,隨機抽取了144批作為訓練樣本,用于建立遺傳規劃的經驗工程公式,其余的40批作為測試樣本用以測試的工程公式的預測精度,所建立的經驗方程如下所示:
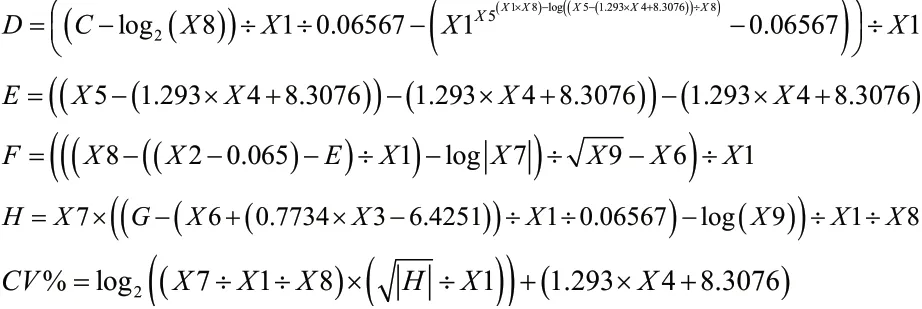
我們把40組用于測試的樣本輸入到工程公式中,得到的預測值和實測值之間的對比如圖4所示。預測值和實測值之間的相關系數和平方為0.9451。說明預測效果較好。

圖4 紗線不勻預測-實測對比
4 結語
本文簡單闡述了遺傳規化的原理,選取了影響紗線不勻的因素,利用實際生產數據建立了紗線不勻的經驗方式。并采用生產數據對經驗方程進行了認證,取得較好的結論。所以利用遺傳規化對紗線不勻預測是行之有效的方法。
