基于卷積神經網絡的業務識別
2021-04-22 07:38:42王佳妮王云峰夏振飛趙力強
無線電通信技術 2021年2期
王佳妮,王云峰,夏振飛,趙力強
(西安電子科技大學,陜西 西安 710071)
0 引言
網絡業務識別問題由來已久。傳統的業務識別在獲取特征時較困難,影響業務識別的精準度,而現有的特征選擇與提取方法需要研究者付出大量的時間和精力。因此簡化業務識別特征的提取方法是本文的研究重點。
文獻[1-4]使用支持向量機、樸素貝葉斯等方法對流量特征、有效載荷特征和混合特征進行分類。針對軟件定義網絡(Software Defiend Network,SDN)網絡,大多數業務識別方案主要運用人工提取特征的方法或者直接使用公開的數據集[5-6],但是存在特征提取較為復雜,特征提取工程的設計嚴重影響識別的精度等問題。深度學習則可以避免這類問題,在業務識別中具有許多優勢[7]。文獻[8]提出在業務識別中引入卷積神經網絡(Convolutional Neural Network,CNN)模型的方法,把分組序列轉化成圖像,獲得了較高的分類準確率。但考慮到實際情況下網絡采集到的樣本數有限,不利于模型的訓練,文獻[9]充分利用生成對抗網絡(Generative Adversarial Network,GAN)數據擴充的優勢,為樣本較少的類生成流量數據。因此,本文針對上述問題,研究了一種基于CNN的業務識別。
1 基于CNN的業務識別系統
1.1 系統模型
傳統的封閉式網絡架構無法同物聯網業務和垂直行業的差異化需求相適配。SDN作為一種新的網絡技術,在體系架構、運行方式上發生了很大變化。因此,本文利用SDN集中式控制的特點,在SDN的3層網絡架構中引入了CNN和GAN,設計了如圖1所示的基于CNN的業務識別系統模型。

圖1 系統模型Fig.1 System model
基礎設施層主要由交換機等組成,它們具有轉發功能。該層主要完成網絡中業務數據的轉發和原始數據包的采集,并將采集的數據包通過南向接口上傳到控制層。
控制層主要由控制器組成,完成網絡管理、網絡狀態獲取以及原始數據預處理等功能。控制層采用解析、截斷/填充、圖像生成、規范化以及業務標簽等功能模塊將原始數據預處理,轉換成二維的灰度圖像,從而構建樣本集,并通過北向接口上傳到應用層。
應用層包括面向用戶的許多業務和應用,業務識別與分類應用也部署在該層。其中一部分樣本集輸入到GAN模型中完成數據的增強產生生成樣本,再將混合樣本(即剩余的實測樣本與生成樣本的集合)共同輸入到CNN模型中完成模型的訓練。訓練后的業務識別模型可以直接通過北向接口進行調用。
1.2 場景模型
本文依托于SDN網絡,設計了具有3種特征明顯且特征相差較大的業務應用場景。業務1是高帶寬的視頻業務;業務2是對網絡要求低,數據量較少的萬維網業務;業務3是要求低時延的游戲業務。終端可以通過交換機接入到SDN網絡中,隨時享受3種業務的服務,交換機也可以獲取到業務數據流的原始數據信息。將數據預處理的過程部署在SDN控制層,充分利用了控制器集中管控的功能,使不同業務數據流的分流過程更方便,便于樣本集的建立。
2 基于CNN的業務識別方案
2.1 基于CNN的業務識別方案設計
2.1.1 CNN
CNN[10-11]是一種有深度學習能力的,可以深層次前向傳播的神經網絡,主要應用于計算機視覺等領域。二維CNN基本組成結構分為輸入層、卷積層、池化層、全連接層和輸出層,可以利用卷積核和池化層實現圖像特征的自動提取。CNN在減少學習參數數量方面有明顯的優勢,從而優化了反向傳播(Back Propagation,BP)算法,實現的方式主要有局部感知、參數共享及池化等[12]。
2.1.2 基于CNN的業務識別與分類模型
針對傳統的基于流統計特征的分類方法,特征選擇與獲取過程較為困難,且特征提取工程的設計過于復雜等問題,本文采用CNN模型自動完成特征的提取,業務識別與分類模型如圖2所示。

圖2 基于CNN的業務識別與分類模型Fig.2 Traffic identification and classification model based on CNN
在數據處理階段,為了使采集到的數據可以直接被CNN模型讀取,需要對其進行預處理,該過程主要包括原數據的解析、截斷/填充、規范化、圖像生成和業務標簽的標注。其中,解析是將采集到的數據按照會話標準進行劃分,再刪除數據包中多余的信息,如數據鏈路層數據、IP地址等;截斷/填充是將數據包中的字節數進行統一,多余的部分進行截斷,否則進行補零操作;圖像生成采用進制轉換的方式將數據包中的內容轉換成二維灰度圖像像素點的取值,從而得到帶有業務特征信息的灰度圖像;規范化是對圖像中像素點的數值進行歸一化,使CNN模型的處理更加方便;業務標簽通過提取包含業務類型名稱的字段對樣本進行標注。經過此過程,將原始數據轉換成帶有業務特征信息的二維灰度圖像,之后采用十折交叉驗證法[13],將生成的圖像數據集劃分成訓練集和測試集。
在訓練階段,將劃分后的訓練集輸入到業務識別模型中自動完成特征的提取,并根據提取的特征進行模型的訓練,不斷調整模型參數,生成業務識別模型。在此階段,CNN的層數設定、卷積層和池化層的連接順序、卷積核的大小與數量以及激活函數等的選擇等都會影響模型的訓練效果。
在應用階段,利用測試集對訓練階段得到的業務識別模型進行測試,驗證模型的可靠性,并將此模型實際部署到應用場景中。
2.1.3方案測試與結果分析
表1為3種業務的平均準確率,視頻業務的準確率相對Web和在線游戲來說較高,由于3種業務的樣本集不平衡,導致識別的準確率有一定的差距。在采集原數據時,視頻業務傳輸的數據包相對較多,可以用來構建的樣本數較多,模型訓練相對其他兩種較好。
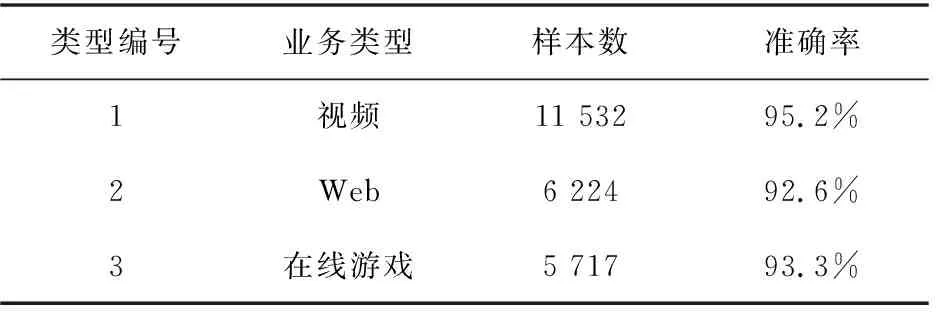
表1 3種業務類型準確率
CNN模型訓練集與測試集平均準確率如圖3所示。由圖3可以看出,在數據集樣本數小于10 000時,利用訓練樣本集測試的結果在90%以上,但是利用測試樣本集測試的結果在80%以下。原因主要是模型訓練過程出現過擬合的現象,使模型可以很好地契合訓練集,但在測試集上效果不佳,而隨著數據集樣本數量的不斷增大,模型在測試集上準確率明顯有所提高。由此可以看出在業務識別的研究中,亟待解決的問題是缺少足夠的數據集。下一節將針對這一問題給出解決方案并進行展開敘述。
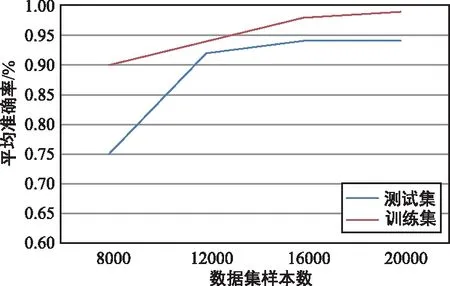
圖3 CNN 模型訓練集與測試集平均準確率Fig.3 Average accuracy of training set and testing set of CNN model
2.2 基于CNN-GAN 的業務識別方案設計
2.2.1 GAN
GAN是一種生成式深度模型,主要采用反向傳播的思想,不需要馬爾科夫計算過程,在無監督學習或者半監督學習中應用廣泛[14]。它由生成網絡和判別網絡組成[15]。
將隨機噪聲輸入生成網絡中,經過計算輸出一組數據;判別網絡接收輸出的數據,并根據之前學習的真實數據分布狀況,判斷接收數據是否是真實的數據,同時輸出一個概率,生成網絡學習真實樣本的分布狀況,生成盡可能逼近真實的數據;判別網絡也在提升自己與生成網絡的博弈能力,盡可能地識別出真假。
2.2.2 基于CNN-GAN的業務識別與分類模型
針對過擬合和數據不均衡的問題,在上一節的基礎上設計了如圖4所示的業務識別與分類模型。基于GAN的數據增強可以學習實測樣本數據的分布,生成一定數量的無限逼近實測樣本集的生成樣本集,再將混合樣本集輸入到CNN中進行模型的訓練與調整,即可構建出業務分類模型。
數據增強的具體過程如下:在GAN網絡中,隨機噪聲經過生成網絡生成輸出樣本,并輸入到判別網絡中進行判別,而判別網絡盡可能將生成樣本集與實測樣本集區分開,最后生成網絡與判別網絡之間不斷進行對抗博弈得到一個最優解,即生成網絡獲得實測樣本集的分布規律并生成了無限逼近于實測樣本集的數據,而判別網絡最終也無法對數據的真假做出判斷。

圖4 基于CNN-GAN的業務識別與分類模型Fig.4 Traffic identification and classification model based on CNN-GAN
2.2.3基于GAN的數據增強
本節中增強的樣本集是經過預處理得到的包含業務特征的二維灰度圖像組成的樣本集。GAN在本質上是由2個神經網絡組成,因此在使用GAN模型時,采用CNN搭建生成網絡與判別網絡。生成網絡由全連接層和反卷積層組成,先將噪聲輸入到模型中,經過全連接層的計算,使噪聲在維度上發生了變化,然后經過反卷積層得到輸出的結果,也就是生成圖像的樣本。判別網絡由卷積層和全連接層組成,卷積層提取圖像樣本特征,經過全連接層之后得到判別結果。
2.2.4 方案測試與結果分析
GAN模型根據實測的樣本,產生一定數量的生成樣本,樣本數量如表2所示。由表2可以看出,增加了生成樣本數量之后,樣本間的不平衡現象有所改善,業務識別的準確率有所提升。

表2 樣本集數目及準確率
如圖5所示,采用混合樣本之后,數據集樣本數達到了26 000多,每種業務的識別準確率提高到了96%左右。由此可見,在采用CNN-GAN模型使樣本數據增強的同時,也很好地解決了過擬合的問題,提高了業務識別的準確率。

圖5 數據集樣本數與準確率折線圖Fig.5 Line chart of data scale and accuracy
3 結束語
本文主要研究了一種基于CNN的業務識別方案。首先,對基于CNN的業務識別系統模型和實現場景進行了描述,提出一種基于CNN模型的業務識別方案,簡化了業務流特征的提取過程。為了更好地提高業務識別的準確率,在之前建立的系統模型基礎上,綜合考慮CNN與GAN各自的特性,將二者相互結合,探究了基于CNN-GAN的業務識別方案,有效解決了業務識別過程中出現的過擬合以及樣本數據不平衡等問題,為業務識別準確率的提升提供了一種可選方案。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
