基于時序分析的閥冷進閥溫度預測方法①
2021-04-23 12:59:44張朝輝梁家豪梁秉崗秦冠軍尹毅然
計算機系統應用 2021年4期
關鍵詞:模型
張朝輝,梁家豪,梁秉崗,秦冠軍,尹毅然,丁 笠,周 宇
1(中國南方電網有限責任公司超高壓輸電公司 廣州局,廣州 510663)
2(南京南瑞繼保電氣有限公司,南京 211106)
3(南京航空航天大學,南京 210016)
1 引言
目前,國內用電需求隨著社會的發展而不斷增長.直流輸電技術[1,2]正在朝著高電壓大容量的技術方向發展,由于國土遼闊,對其在長距離輸電、跨區域聯網及調度靈活等方面有著現實需求.電網在運行過程中,保證換流閥等關鍵設備穩定運行就顯得至關重要.換流閥等關鍵設備在電網運行過程中會不斷產生熱量,當設備的熱量不斷聚集,溫度就會不斷上升時則會影響電網的正常運行.電網中的換流閥等關鍵設備出現的故障對電力系統造成的影響也越來越大[3].因此,需要對電網中關鍵設備檢測數據進行預測,提高工作人員對設備的感知能力,能對關鍵設備未來出現的變化趨勢做相應的準備.這對電網的正常運行和提供可靠的供電具有實際意義.
由于人工在處理電網設備時會存在經驗不足和誤操作等客觀因素,因此對電的安全性,穩定性和智能化的要求越來越高.閥冷系統作為電網中冷卻系統的關鍵設備,以水為傳導介質,水有較高的熱導性,作為“載熱體”存在,將設備的熱量傳遞到水介質并將熱能帶出,達到物理降低設備溫度的目的.閥冷系統對高壓直流系統的安全運行起著至關重要作用[4].閥冷系統分為內冷水系統和外冷水系統兩個部分.內冷水系統是密閉式循環具有水循環、內冷水處理等功能[5].內冷水系統在換流閥運行時負責可靠高效通過水帶走設備運行產生的熱量,送到外冷水系統中.外冷水系統是開放式循環,具有水質軟化凈化、補水等功能[6].冷卻塔會對內冷水管道噴淋散熱,并通過風扇對外、內冷水交換將閥內冷水系統的熱量排至大氣環境中,兩者共同合作完成對換流閥的持續冷卻,可以達到對閥廳整個設備進行散熱的目的.
閥冷系統在降低設備溫度的過程中,其涉及的參數為出閥溫度,進閥溫度,出閥壓力,內冷水導電率.所有參數中最核心和最關鍵的參數是溫度,包括了出閥溫度和進閥溫度.閥冷系統中換流閥的進出閥溫度在運行過程中只要維持在合理范圍內,就能夠保證換流閥設備的穩定運行從而保證閥冷系統的穩定運行.由于換流閥的出閥溫度和進閥溫度具有很強的相關性,所以我們選取其中進閥溫度作為整個設備運行狀態的評價指標.如果設備熱量過度聚集導致換流閥的進閥溫度過高,可能會損壞相應設備.如果這個問題長時間不能夠妥善解決,就會產生嚴重的安全隱患,造成難以估計的后果.進閥溫度參數短期內有波動,但從長期來看,具有一定的變化趨勢,可以利用時序分析如ARIMA、SVM、GRU 以及ARIMA-SVM 混合等方法對進閥溫度進行預測,使運行工作人員提前預知進閥溫度變化趨勢.
2 相關工作
時序數據本質上是反應某個或者某些隨機變量隨時間不斷變化的趨勢,分析時序數據的核心是從這些數據里挖掘出某種規律,并利用規律對未來進行預估[7].時序數據分析方法從最早提出到現在經過漫長的發展,國內外研究學者提出了許多基于時序數據分析方法[8–11].時序分析方法主要有3 類方法,從最開始提出的傳統的時間序列預測方法,到將機器學習和時間序列預測結合的方法,以及要提高預測效率的基于參數模型的在線時間序列預測方法.無論是傳統的時間序列預測方法中還是應用到時序領域的機器學習方法以及基于參數模型的在線時間序列預測方法,目前,沒有一種單一模型能夠統一地對特定的時間序列數據做出最好的預測.因此混合模型應運而生,混合模型受益于各個模型的多樣性,減少單一模型使用風險,很好彌補單個模型的缺陷,可以提升時間序列預測精度.
經典的時間序列模型包括移動平均模型(Move-Average,MA)、自回歸模型(Auto-Regressive,AR)、自回歸移動平均模型(Auto Regressive Moving Average,ARMA),還有其對應的各種衍生出來的模型,如動態自回歸模型和向量化的自回歸模型[12].而Box和Jenkins[13]提出的“Box-Jenkins 方法”非常流行.該方法有3 步,第1 步對給定時間序列,確定參數模型中適當的p,q,d值,第2 步通過最有效的方法估計出參數模型的具體值,第3 步檢測模型的有效性并做出相應調整.
時間序列預測方法歸根到底在本質上與基于機器學習分類中的回歸分析有著許多相似之處.機器學習中許多方法都可以應用在時間序列預測方面,并且取得了不錯的效果,例如經典的支持向量機SVM,貝葉斯網絡BN,GRU 神經網絡.隨著人工神經網絡的不斷發展,以及神經網絡在時間序列中趨勢性分析有著獨特的特性,所以有人將神經網絡應用在時間序列預測上,取得很好的效果.進一步深度學習也被看作是實現時間序列預測的有效工具.Kim[14]直接用支持向量機來預測股票價格,并通過對比試驗來驗證該方法的可行性,Gestel 等提出把貝葉斯證據框架[15,16]應用到最小二乘支持向量機[17,18]應用到金融領域進行時間序列預測.Das和Ghosh 將貝葉斯網絡(BN)應用到氣象時間序列預測,并在后續時間做了大量的工作.在2017年,提出基于語義貝葉斯網絡的多元氣象時間序列預測網絡semBnet[19].隨著深度學習的流行,也被看作實現時間序列預測的有效工具.機器學習本質上是多層神經網絡,主要包括卷積神經網絡(Convolutional Neural Networks,CNN)和循環神經網絡(Recurrent Neural Networks,RNN)[20],其中RNN 能夠解決時間序列的延續性問題.RNN 可以處理整個時間序列所包含的信息,但存在長期依賴問題,即對長序列進行學習時,RNN 會出現梯度消失和梯度爆炸問題,無法學習到長時間跨度的關系.為了解決這個問題,Schmidhuber 教授在1997年提出長短期記憶網絡(Long Short-Term Memory,LSTM)能夠很好的解決這個問題,默認就可以記住長期的信息,實現長程記憶.
隨著計算機技術的發展和互聯網的普及,以及數據的急速增長給傳統時間序列預測方法和批處理機器學習預測方法帶來了極大的挑戰.在面對大數據的時候,傳統的方法的效率低下,因此利用在線學習方法來對時間序列數據預測成為新的趨勢,而且取得了不錯的效果.和傳統批處理學習方法相比,在線學習方法不需要處理整個數據集,只需要處理這個新的樣本,大大節約了時間提高效率.Anava 等[21]提出了基于參數模型的在線時間序列預測算法ARMA-ONS,能夠將傳統的時間序列模型和在線學習有效結合起來.
3 合并單元設備狀態研究
此章節主要針對閥冷系統的監測數據進行篩選和提取,并在此基礎上對閥冷數據進行簡單時序分析.
3.1 數據提取
本文工作的數據來源于中國南方電網從2017年到2019年收集的將近兩年的真實數據,包括PWR,出閥溫度,進閥溫度,進閥壓力,冷卻水流量,冷卻水導電率等相關記錄.進一步篩選和內冷水系統有關的數據,篩選和提取出進閥溫度,出閥溫度,進閥壓力,冷卻水導電率相關數據.因此針對這個4個指標,從MySQL數據庫混亂的原始數據里提取出來,這就需要一些數據預處理步驟,最后可以構建出一個適合進行時間序列分析工作的數據集.
中國南方電網的設備眾多,每個閥冷設備都有相應的監測數據,就需要對每個閥冷設備的監測數據進行分析.因此需要把數據按照各個設備進行劃分,并按照日期時間排列,以保證每個設備對應數據的完整性和時序性,最終構建出一個包含4個監測指標的數據表.
經過上面的數據預處理之后,獲得了可以進行下一步時序分析的數據集.
3.2 正常數據趨勢分析
由于整個數據的采集頻率為每半個小時采集一次而且時間跨度長達兩年,導致了整個數據集比較大,對整個數據進行趨勢分析只能從宏觀上觀察數據變化趨勢,我們對4個指標的數據分別按周、月對數據進行采樣,分析其內在的規律性和數據的趨勢變化.對預處理的后數據集采用隨機抽樣,隨機選取一周的數據進行分析,其數據隨時間變化如圖1所示.
圖1包含了4個子圖,分別描繪了進閥溫度,出閥溫度,進閥壓力,冷卻水導電率的變化趨勢.進閥溫度在32℃到40℃之間變化,相差8℃,而出閥溫度在38℃到49℃之間變化,溫度提升6℃到9℃.進閥壓力和冷卻水導電率,會隨機波動,值的波動幅度并不是很大,且進閥壓力和冷卻水導電率均在正常值范圍之內變化.進閥溫度,出閥溫度,進閥壓力和冷卻水導電率都在某個均值附近波動,可以初步判斷各個時間序列數據是平穩的,可以通過計算迪基-福勒檢驗進行單位根校驗,計算出相對應的p值為遠小于0.01,可以認為閥冷數據是時間平穩序列.
為了進一步發現閥冷變化趨勢以及數據的平穩性,我們對一個月的閥冷數據進行分析.從圖2可以看出,進閥溫度和出閥溫度的變化趨勢很相似,但總體的變化范圍有些不同,進閥溫度的變化范圍在22℃到36℃,而出閥溫度則在24℃到42℃之間波動.相差了2℃到6℃.
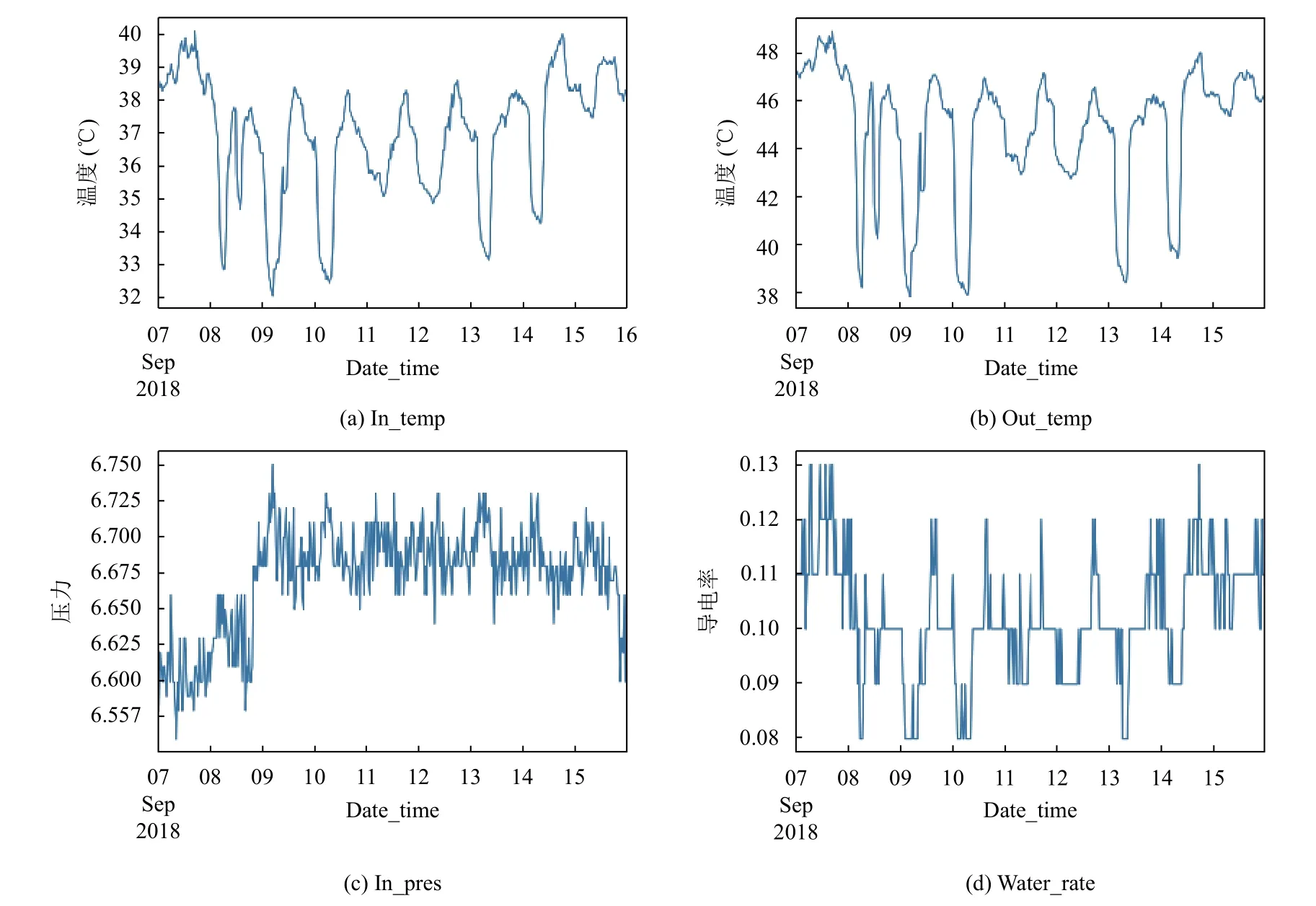
圖1 閥冷4個參數的周變化趨勢
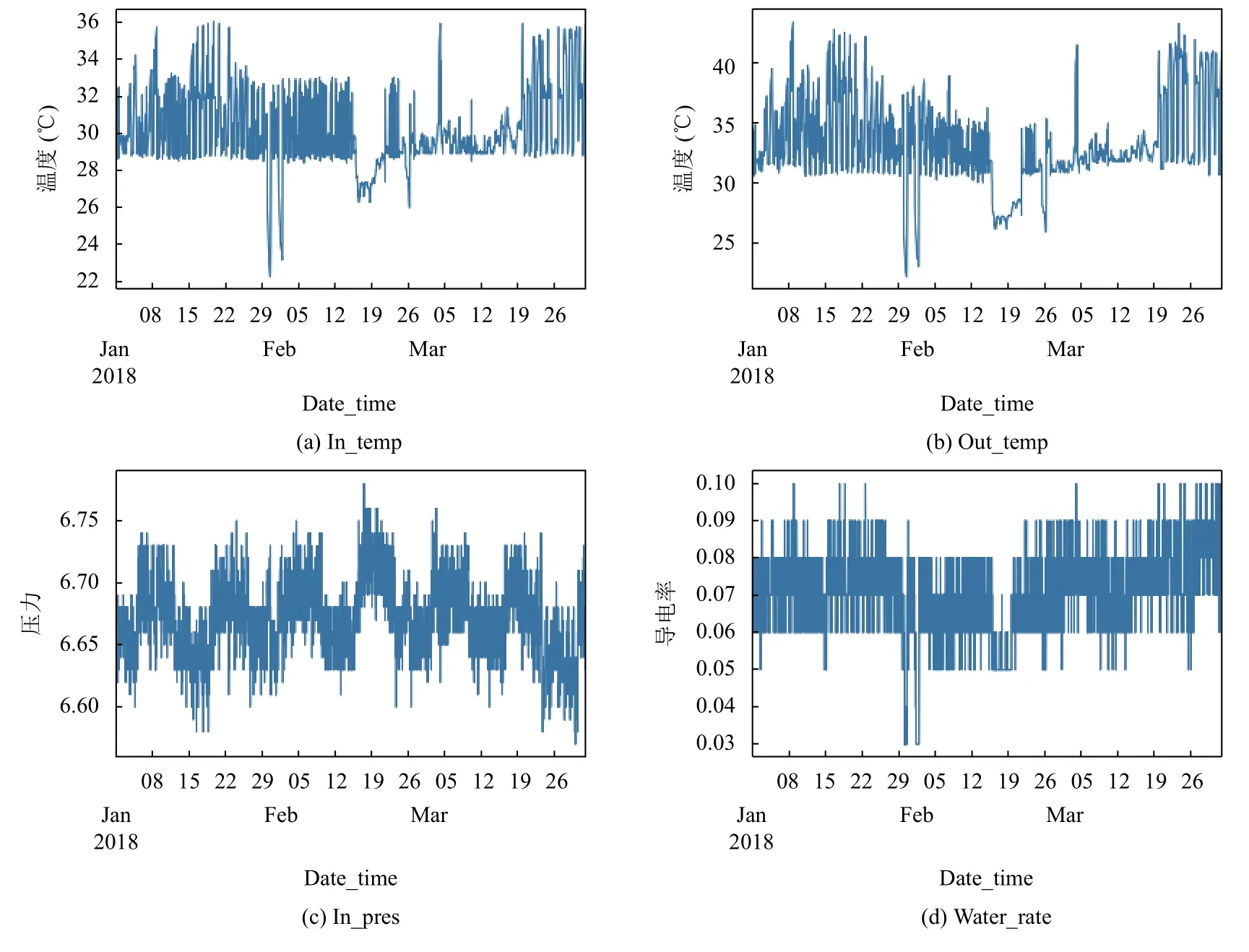
圖2 閥冷4個參數的月變化趨勢
從圖1和圖2可以發現進閥溫度在22℃到36℃的范圍內變化,出閥溫度都在24℃到42℃范圍內變化并且在各自對應的范圍內變化趨勢很是接近.通過相關性分析得到兩者關系是正相關,相關性系數接近于1.出閥溫度和進閥溫度的數據波動都在正常范圍之內,但是觀察數據出閥溫度略高一些,原因在于閥冷系統的循環水將帶走其產生的熱量.通過初步判斷各個時間序列數據是平穩的,再進一步通過計算迪基-福勒檢驗進行單位根校驗,計算出p值為遠小于0.01,最終判斷閥冷數據是時間平穩序列.
4 閥冷系統的分析方法
閥冷系統檢測到的數據,其具有多維度、實時性、線性和非線性并存等一些特點.以往傳統的時序分析方法是根據所研究時間序列的基本規律和自身特點,選取適當的時序模型并先確定時間序列模型的參數,在此基礎上,利用已求解出參數的模型對未來的時間序列進行預測.傳統時序模型在線性預測方面取得了很好的成果,但在面對處理復雜數據的時候,往往顯得力不從心,因此需要和基于機器學習的時間序列預測方法相結合.與神經網絡相比,SVM 具有豐富的理論基礎,并且神經網絡非常依賴參數,參數的好壞直接影響神經網絡的學習效果.SVM 可以很好彌補傳統時序分析方法的缺點的同時對線性預測效果并不理想.在對閥冷系統產生的時序數據預測,單獨的ARIMA模型或者SVM 模型很難完全把握時序數據的變化規律,考慮將二者結合起來的混合模型是個更好的解決方法,并和神經網絡GRU 進行對比實驗,以驗證混合模型的有效性.
在本文工作中,我們認為閥冷時間序列yt可以分解為線性部分Lt和非線性部分Nt.

線性部分Lt可以由ARMA(p,q)模型根據閥冷數據時間序列中過去的值計算得出,計算公式如下:
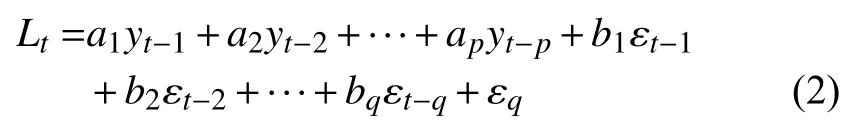
傳統時序模型ARMA 只能處理平穩時間序列,比AR 模型與MA 模型有較精確的估計,但其參數估算也相對比較繁瑣.如果是非平穩時間序列,則難以求得ARMA 模型參數的準確估值.非平穩時間序列并不能用ARMA 直接處理,需要經過差分處理將非平穩時間序列轉化成平穩時間序列.ARIMA 模型在ARMA 模型的基礎上多了一個差分步驟,如ARIMA(p,d,q)模型中參數d為0 就是ARMA 模型,差分用參數d表示.式(2)里線性部分Lt由 一個平穩序列{yt}和是一個白噪聲序列{εt} 組成,ai與bj分別是{yt}序列和{εt}序列的參數.平穩序列{yt}中的p稱為自回歸階數,{εt}序列中的q稱為移動平均階數.在實際應用中,很多時間序列是非平穩時間序列時,往往達不到嚴平穩的要求,而序列平穩性是時間序列變形分析建模的重要前提.需要對非平穩序列進行差分運算,一階差分是相鄰的時序值相減,二階差分是對一階差分后的序列再做一次差分運算,以此類推,可以得到n階差分.非平穩序列往往一次到兩次差分之后,就會變成平穩序列,達到可以建模分析的前提.如果時間序列在一階差分平穩化后,效果不夠明顯,再進行二階差分,直到獲得一個較好的平穩序列.自回歸滑動平均模型(ARMA)和差分整合移動平均自回歸模型(ARIMA)時序分析總的策略主要包含3 步,第1 步確定合適的p,d,q值,第2 步,通過最有效的方法評估模型中具體的參數值,第3 步要檢驗預測數據的準確性,擬合模型的適當性,最終不斷的適當改進模型達到準確預測數據的目的.AIC:赤池信息準則(Akaike Information Criterion).
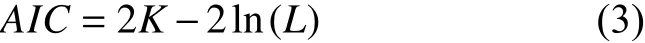
BIC:貝葉斯信息準則(Bayesian Information Criterion).
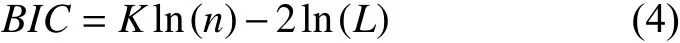
AIC準則和BIC準則用于確定ARIMA 模型中p,q值.其中,k為模型參數個數,n為樣本數量,L為似然函數.由于中國南方電網收集的閥冷數據本身就是時間平穩序列,因此可直接建立ARIMA(p,d,q)模型中將d設為0,ARIMA中d為0 其實就是ARMA 模型.首先初步確定適當的p,d,q的值,從低階到高階逐步試探方法來識別模型的參數,然后結合赤池信息度量(AIC)和貝葉斯信息度量(BIC)有效方法估計出ARIMA模型的具體參數值,最后驗證擬合模型的適當性,并適當改進改進該模型.AIC和BIC是為了找到ARIMA模型的合適參數,要在模型的參數個數和模型的擬合精度做出適當的取舍,能夠比較準確預測未來數據.最終確定ARIMA 模型參數p=1,d=0,q=2.ARIMA 模型對線性數據具有獨特的優勢,但缺點也比較明顯只能捕獲時間序列中線性關系,不能捕獲非線性關系.ARIMA模型在捕獲線性關系過程中,還獲得線性關系之外時間序列的殘差信息,為接下來SVM 分析做準備,可以進一步優化預測值.
殘差里會包括非線性關系,而 ARIMA 模型則沒有辦法捕獲非線性的信息而支持向量機(SVM)可以捕獲此類信息.所以殘差是提高預測準確性的重要因素,因此殘差分析就至關重要了.支持向量機(SVM)在非線性預測方面能夠取得很好的效果.SVM是以統計學理論為基礎的學習方法,其豐富的理論基礎保證了SVM在解決數據高維度和非線性方面具有不可比擬的優勢.ARIMA在捕獲線性部分之外獲得時間序列的殘差信息,殘差即非線性部分,殘差Nt作為SVM的輸入.

ARIMA 模型在t時刻得到,為ARIMA 模型捕獲的殘差部分,為SVM 模型的輸入,其表示為:
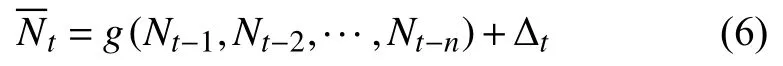
式中,G為非線性模型,?t是非線性部分的隨機誤差,n為輸入的長度.根據以上的分析可以得到最終的預測值為:
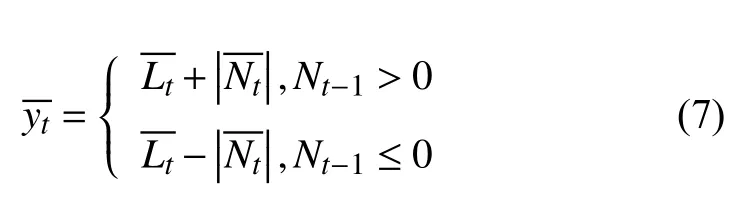
5 實驗評估
5.1 評估度量指標
根據數據分析結果,我們選取、確定了ARIMA、SVM、GRU和提出的ARIMA-SVM 混合時序性分析方法,嘗試建立預測模型,對閥冷系統時序數據進行預測分析.根據預測的結果需要評估模型的好壞,我們采用多個度量指標來評估數據的是否平穩時間序列以及模型的準確性.
均方根誤差公式表示如下:
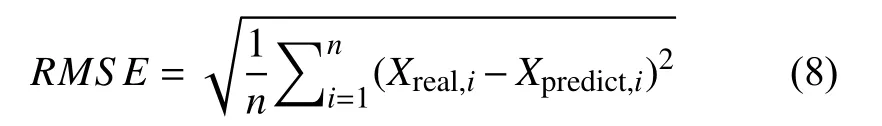
均方誤差公式表示如下:
平均絕對誤差表示如下:
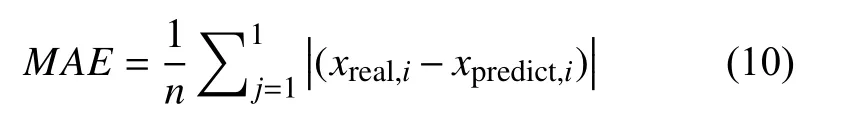
DF 檢驗(Dikey-Fuller test).DF 檢驗是一種常見的用于判斷時間序列平穩性的單位根檢測方法.若通過計算不存在單位根,時間序列就是平穩時間序列,反之,需要進行差分處理.時間序列的平穩性檢測是時間序列建模過程中非常重要的一步,使用DF 檢測方法可以檢驗之.
6 實驗
首先我們選取中國南方電網的一個閥冷系統真實數據,從2017年12月份到2019年7月份的真實數據中選取連續3個月的數據,我們選取的2018年1月到3月的數據,對這3個月的數據量進行實驗分析評估,閥冷數據采集的時間間隔為半個小時,數據的變化趨勢圖2所示.
從圖2中可以看到閥冷系統在平常正常工作狀態中,進閥溫度,出閥溫度,進閥壓力,冷卻水導電率趨于平穩,會產生隨機波動,但波動都在正常范圍之內.由于進閥溫度比較重要,所以我們預測輸入以進閥溫度為預測標準.
ARIMA 模型.第1 步確定合適的p,d,q值,在初步確定 ARIMA(p,d,q)由于閥冷數據都是時間平穩序列,所以ARIMA 模型中d=0.第2 步,通過根據AIC和BIC檢測方法確定ARIMA 模型中的p和q.第3 步要檢驗預測數據的準確性,擬合模型的適當性,最終不斷的適當改進模型達到準確預測數據的目的,最終ARIMA 模型參數為p=1,d=0,q=2.
實線為數據真實值,虛線為模型在測試集上的預測.從圖3而言,ARIMA 模型的進閥溫度預測結果和閥冷進閥溫度數據很是接近,但在峰值區域的預測效果有些欠缺.
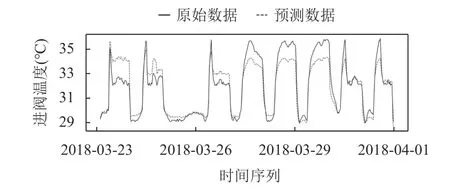
圖3 ARIMA 預測圖
SVM 模型.SVM 模型可以檢測非線性關系,以VC 理論和結構風險最小原理為基礎的,通過選擇適當的判別函數,希望SVM的測試誤差較小.用SVM 來單獨預測進閥溫度數據中的非線性關系.
SVM的預測性能主要和誤差懲罰因子C和選取核函數有關.優化誤差懲罰因子C和核函數能夠很好提升SVM的性能,確定懲罰因子C=10,選用徑向基函數(rbf)作為核函數.C懲罰因子是確定數據子空間時調節置信區間范圍.采用遺傳算法,對兩個參數優化.
實線為數據真實值,虛線為模型在測試集上的預測.從圖4而言,SVM 模型的進閥溫度預測很好擬合了真實閥冷進閥溫度的變化趨勢,但是和真實進閥溫度的真實值仍有差距.
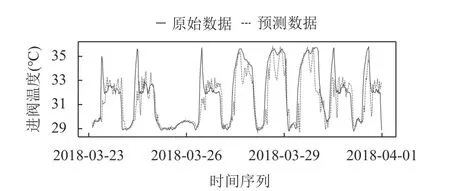
圖4 SVM 預測圖
GRU 神經網絡模型.為了進一步說明混合模型能夠在單一模型的基礎上提高預測精度,將混合模型和GRU 神經網絡做對比實驗.GRU在循環神經網絡的基礎上改進的變體,引入門控機制,自適應控制信息流動,可以捕捉時序數據之間的相互依賴關系,具有一定的優勢.GRU 神經網絡模型在訓練時涉及到許多超參數的設定,神經元數量m,時間步長T,批數據大小batchsize,迭代次數epoch 輪.神經元個數決定了神經網絡對時序數據的擬合程度,時間步長和批數據大小決定了模型訓練的結果.選擇ADAM 優化器對參數進行優化調整.
實線為數據真實值,虛線為模型在測試集上的預測.從圖5而言,GRU 模型的進閥溫度預測結果比ARIMA 模型預測結果更加接近真實的閥冷進閥溫度數據,在3個峰值區域的預測效果有些欠缺.
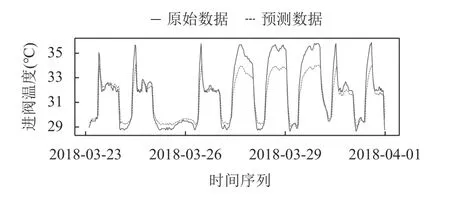
圖5 GRU 預測圖
ARIMA 模型可以很好捕獲時間序列中線性關系,但時序數據仍有非線性關系沒有捕捉.利用SVM 可以很好捕捉非線性關系,從ARIMA 獲得線性關系之外時間序列的殘差信息獲得非線性關系.進一步優化預測值.從而提出ARIMA-SVM 混合模型.
ARIMA-SVM 混合模型結合兩個模型的優點.首先使用 ARIMA 對進閥溫度時間序列進行預測,捕獲進閥溫度時間序列的線性變化趨勢,然后利用 SVM 對進閥溫度時間序列的非線性,以提高預測的準確性.在ARIMA 模型預測的同時獲得了殘差數據,將獲得的殘差部分作為SVM的輸入,根據SVM 模型的輸出進一步調整ARIMA的預測值,使得預測值更加接近真實值.
實線為數據真實值,虛線為模型在測試集上的預測.從圖6而言,ARIMA-SVM 混合模型的進閥溫度預測結果比ARIMA 模型預測結果更加接近真實的閥冷進閥溫度數據.ARIMA-SVM 混合模型結合兩個模型的優點.首先使用 ARIMA 對電網時間序列進行預測,捕獲電網時間序列的線性變化趨勢,然后利用 SVM 對電網時間序列的非線性,以提高預測的準確性.在ARIMA 模型預測的同時獲得了殘差數據,將獲得的殘差部分作為SVM的輸入,根據SVM 模型的輸出進一步調整ARIMA的預測值,使得預測值更加接近真實值.
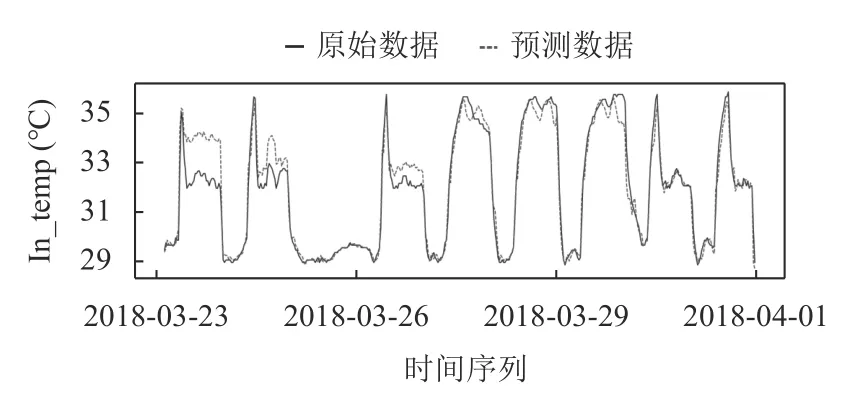
圖6 混合模型預測
為了能夠從整體評估各個模型的預測能力.計算出各個模型的均方根誤差、均方誤差和平均絕對誤差進行比較.結果如表1所示,根據本文選取的均方根誤差、均方誤差和平均絕對誤差3個評價指標來衡量預測結果的準確性,3個評價指標可以很好的衡量各個模型預測值和真實值之間的偏差和擬合精度,值越小說明精度越高,預測效果也越好.從表1可以看出ARIMA-SVM混合模型在整體的誤差上相比其他3個模型都有一定的優勢,能夠更好的預測出進閥溫度,提高預測精度.
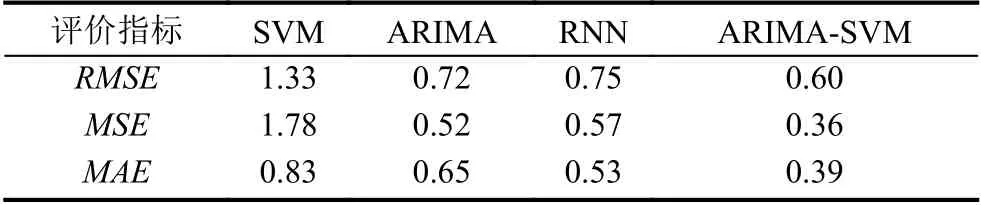
表1 各模型的評價指標
7 結語
高壓直流運行中換流閥會產生熱能,作為換流閥的關鍵設備和重要降溫設備,閥冷系統以水為介質將換流閥熱能帶出以達到冷卻目的.換流閥若要安全穩定地運行,將設備運行時的溫度維持在合理范圍內至關重要.進閥溫度和出閥溫度是閥冷系統最為關鍵的兩個參數.本文通過構建ARIMA 模型、SVM 模型、GRU 神經網絡模型以及ARIMA-SVM的混合模型對閥冷數據進行時序分析,針對進閥溫度這一關鍵參數進行預測.實驗結果表明,雖然某些地方有些許偏差,ARIMA 模型大體上能夠較好地預測進閥溫度但偏差比較大.SVM 模型可以預測數據的變化趨勢.GRU 神經網絡模型和ARIMA 模型相比預測值更加接近進閥溫度的真實值,但在3個評價指標上稍劣于ARIMASVM 混合模型.通過在ARIMA 模型分析線性數據的基礎上結合SVM 模型,進而提高進閥溫度預測準確性.在ARIMA 模型預測結果的基礎上利用捕獲的殘差信息做進一步優化,實驗結果表明將傳統時序模型與機器學習結合提出ARIMA-SVM的混合模型可以達到一個優化的結果.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
