針對心血管疾病預(yù)測的改進(jìn)算法模型
2021-04-23 05:50:20劉紀(jì)敏張楷第文龍日賈全秋謝創(chuàng)森
軟件導(dǎo)刊 2021年4期
關(guān)鍵詞:模型
劉紀(jì)敏,張楷第,文龍日,賈全秋,謝創(chuàng)森,王 菲
(1.山東科技大學(xué)智能裝備學(xué)院,山東泰安 271000;2.山東科技大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院,山東青島 266000;3.泰山科技學(xué)院大數(shù)據(jù)學(xué)院,山東泰安 271000)
0 引言
隨著高科技的發(fā)展以及個人健康管理需求的不斷增加,人類進(jìn)入了長壽時代,但高危疾病導(dǎo)致的突然死亡給很多家庭帶來巨大的痛苦。據(jù)統(tǒng)計(jì),山東省居民主要死亡原因中排名前三位的疾病分別為心血管疾病、惡性腫瘤和腦血管疾病。從年齡組來看,不同年齡組死因排序有所不同,14 歲以下兒童及青少年組排名前三位的死因分別為傷害、惡性腫瘤和先天異常,占該年齡組死亡人數(shù)的74.28%;15-44 歲青壯年組排名前三位的死因分別為傷害、惡性腫瘤和心血管病,占75.97%;45 歲以上中老年人組排名前三位的死因分別為心血管疾病、惡性腫瘤和腦血管疾病,占88.07%。通過分析,心血管疾病(Cardiovascular Disease,CD)導(dǎo)致的死亡率達(dá)到20%[1]。因心血管疾病與日常飲食習(xí)慣、運(yùn)動習(xí)慣有著密切關(guān)聯(lián),所以早期發(fā)現(xiàn)發(fā)病影響因素并進(jìn)行預(yù)防與治療對降低疾病發(fā)病率具有重要意義。雖然現(xiàn)代醫(yī)學(xué)技術(shù)發(fā)展迅速,但是針對高危疾病發(fā)病可能性預(yù)測與預(yù)防方面的技術(shù)仍然比較薄弱,缺乏標(biāo)準(zhǔn)的預(yù)測模型以及有效的疾病預(yù)測服務(wù)。
近年來,通過整合信息通信技術(shù)(Information and Communication Technology,ICT)與醫(yī)學(xué)技術(shù)預(yù)測疾病發(fā)病率并提高預(yù)測結(jié)果的精準(zhǔn)度成為疾病預(yù)測領(lǐng)域研究的焦點(diǎn)。如Jabbar 等[2]提出結(jié)合K-最近鄰算法(K-Nearest Neighbor,KNN)與遺傳算法的分類算法提高心血管疾病診斷精準(zhǔn)性;Mohan 等[3]對近年來心臟病預(yù)測相關(guān)研究內(nèi)容進(jìn)行了匯總;Choudhary 等[4]使用數(shù)據(jù)挖掘算法、決策樹、樸素貝葉斯、神經(jīng)網(wǎng)絡(luò)、關(guān)聯(lián)分類和遺傳算法從數(shù)據(jù)集中預(yù)測與分析心臟病。研究人員在一個數(shù)據(jù)集上進(jìn)行了一項(xiàng)實(shí)驗(yàn),使用神經(jīng)網(wǎng)絡(luò)和混合智能技術(shù)建立一個模型,結(jié)果表明,混合智能技術(shù)可提高預(yù)測精度。Sharma 等[5]在心臟病數(shù)據(jù)倉庫中使用K-均值聚類算法提取與心臟病相關(guān)數(shù)據(jù),并應(yīng)用MAFIA(Maximal Frequency Item Set Algorithm)算法計(jì)算對心臟病發(fā)作預(yù)測有重要意義的頻繁模式權(quán)重;Fadini等[6]將年齡、血壓、血管造影報(bào)告等13 個變量輸入神經(jīng)網(wǎng)絡(luò)模型中以預(yù)測心臟病發(fā)病率,并證明了該模型的可行性;Yan 等[7]提出利用神經(jīng)網(wǎng)絡(luò)和遺傳算法預(yù)測疾病的模型,并通過實(shí)驗(yàn)證明了該模型可提高疾病預(yù)測精準(zhǔn)度;Guru 等[8]提出在確定疾病影響因素的前提下,利用神經(jīng)網(wǎng)絡(luò)、反向傳播算法進(jìn)行疾病預(yù)測的模型。
研究發(fā)現(xiàn),雖然這些疾病預(yù)測模型在一定前提條件下達(dá)到了疾病預(yù)測的目的,但數(shù)據(jù)特征和維度過多等原因影響了預(yù)測模型的時效性和精準(zhǔn)度。研究人員大多注重提升疾病預(yù)測的正確率,而忽略了疾病預(yù)測的時效性,但時效性在臨床診斷中是極為重要的因素。過多的數(shù)據(jù)特征和維度在數(shù)據(jù)處理過程中會增加預(yù)測模型的結(jié)構(gòu)復(fù)雜度及模型訓(xùn)練時間復(fù)雜度,導(dǎo)致訓(xùn)練出的模型在預(yù)測疾病時的時效性不強(qiáng)。
因此,在保證預(yù)測準(zhǔn)確率的前提下,為提高疾病預(yù)測時效性,本文首先提出基于國家標(biāo)準(zhǔn)查體報(bào)告與心血管疾病影響因素的標(biāo)準(zhǔn)化心血管疾病影響因素提取方法,以提高采集醫(yī)療數(shù)據(jù)的標(biāo)準(zhǔn)性和通用性;其次,提出基于隨機(jī)森林與Relief 算法的疾病影響因素特征選擇方法,以降低疾病預(yù)測模型的結(jié)構(gòu)復(fù)雜度、提高時效性,并提出基于誤差反向傳播網(wǎng)絡(luò)的心血管疾病預(yù)測模型,以提高心血管疾病預(yù)測精準(zhǔn)度;最后,對傳統(tǒng)預(yù)測模型與改進(jìn)模型的實(shí)驗(yàn)結(jié)果進(jìn)行比較分析,證明了改進(jìn)模型的優(yōu)越性。
1 疾病預(yù)測相關(guān)技術(shù)研究
目前國內(nèi)醫(yī)療機(jī)構(gòu)的醫(yī)療數(shù)據(jù)管理系統(tǒng),如Hospital-InformationSystem(HIS)、Electronic Medical Record(EMR)等并未實(shí)現(xiàn)規(guī)范化與標(biāo)準(zhǔn)化。為解決這一問題,本文結(jié)合國家標(biāo)準(zhǔn)查體數(shù)據(jù)模型與山東省解放軍第九六〇醫(yī)院查體中心個人查體報(bào)告模型建立規(guī)范化、標(biāo)準(zhǔn)化的心血管疾病樣本數(shù)據(jù)模型。在心血管疾病發(fā)病影響因素特征選擇中,利用隨機(jī)森林和Relief 算法以更準(zhǔn)確地選取影響因素。在心血管疾病預(yù)測方面,利用神經(jīng)網(wǎng)絡(luò)(Artificial Neural Networks,ANN)和誤差反向傳播(Back Propagation,BP)神經(jīng)網(wǎng)絡(luò)模型對心血管疾病的發(fā)病可能性進(jìn)行研究。
1.1 個人查體標(biāo)準(zhǔn)數(shù)據(jù)模型
本文利用國家標(biāo)準(zhǔn)查體數(shù)據(jù)模型提出個人查體報(bào)告書,并基于該報(bào)告書建立心血管疾病發(fā)病相關(guān)因素標(biāo)準(zhǔn)化數(shù)據(jù)模型。根據(jù)個人查體報(bào)告書導(dǎo)出心血管疾病相關(guān)特征數(shù)據(jù)如表1 所示。
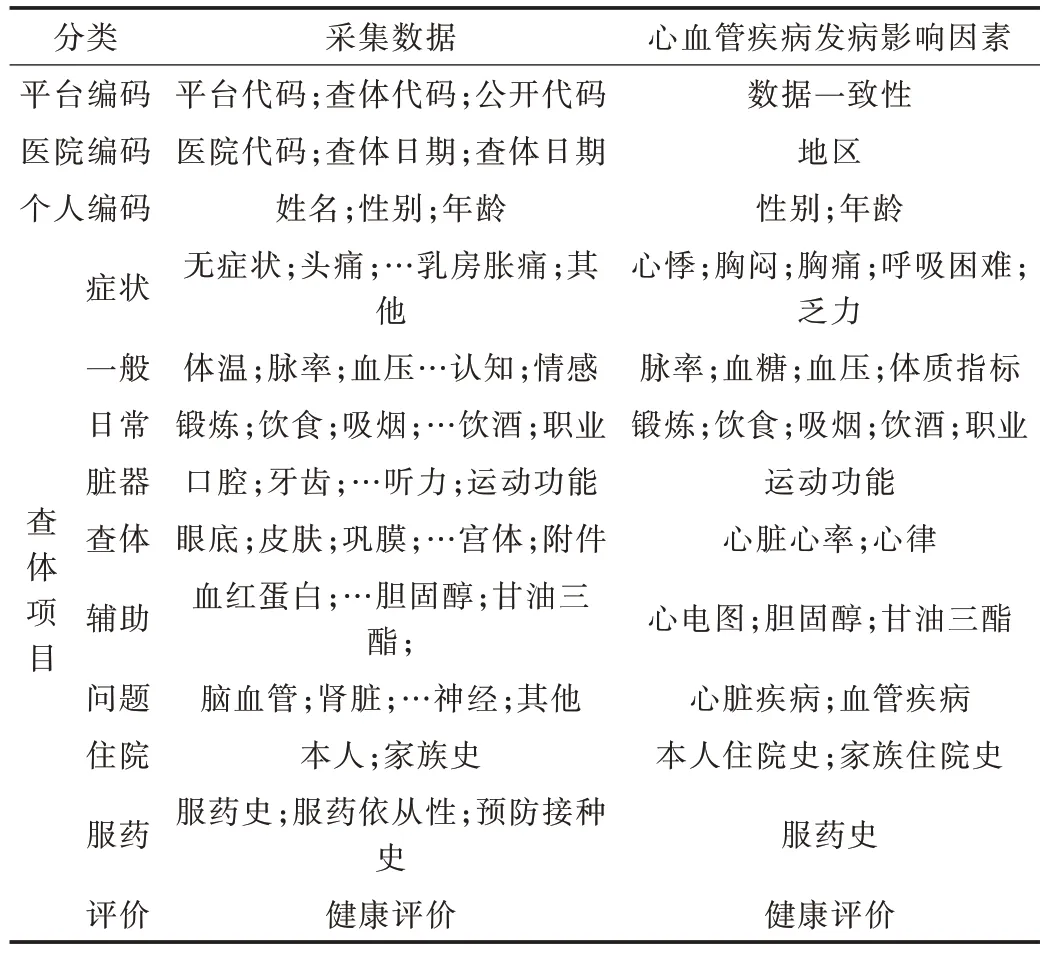
Table 1 The characteristic data related to cardiovascular diseases表1 心血管疾病相關(guān)特征數(shù)據(jù)
1.2 特征選擇方法
在心血管疾病發(fā)病影響因素較多的前提下,有必要在查體數(shù)據(jù)預(yù)處理特征集合中選擇有效特征以決定發(fā)病影響因素權(quán)重。特征選擇是從經(jīng)過預(yù)處理的特征集合中選擇有效特征,以降低數(shù)據(jù)維度、減少計(jì)算量。常見的特征選擇方法包括方差過濾、相關(guān)系數(shù)、遞歸特征消除、模型選擇等,本文采用隨機(jī)森林與Relief 相結(jié)合的算法進(jìn)行發(fā)病影響因素特征選擇。
隨機(jī)森林由多個決策樹構(gòu)成,決策樹中每一個節(jié)點(diǎn)都是關(guān)于某個特征的條件,從而將數(shù)據(jù)集按照不同響應(yīng)變量一分為二,利用不純度可以確定節(jié)點(diǎn)(最優(yōu)條件)。當(dāng)訓(xùn)練決策樹時,可計(jì)算出每個特征減少了多少樹的不純度。對于一個決策樹森林而言,可計(jì)算出每個特征平均減少了多少不純度,并把平均減少的不純度作為特征選擇值。隨機(jī)森林具有準(zhǔn)確率高、易于使用等優(yōu)點(diǎn)[9-11]。
Relief 算法的基本思路為從訓(xùn)練集D 中隨機(jī)選擇一個樣本R,然后從與R 同類的樣本中尋找k 點(diǎn)的最近鄰樣本H,并從與R 不同類的樣本中尋找k 最近鄰樣本M,最后按照公式更新特征權(quán)重,通過篩選屬性值達(dá)到降維的目的。為解決隨機(jī)森林求權(quán)重過程中存在的會將權(quán)重大的屬性賦予低權(quán)重值的問題,引入Relief 算法。Relief 算法可篩掉中、低影響度的屬性,而不會影響中、高影響度的屬性,從而避免在隨機(jī)森林中將影響度高的醫(yī)療屬性篩掉。但Relief 對中、低影響度的屬性區(qū)分不明顯,僅對高影響度的屬性區(qū)分明顯,因此選取隨機(jī)森林中權(quán)重值高的屬性加以保留[12-14]。
1.3 疾病預(yù)測模型
本文用于預(yù)測心血管疾病的醫(yī)療數(shù)據(jù)集是從UCI 的機(jī)器存儲庫中獲得的,為部分人的體檢數(shù)據(jù),共包含2 121 例樣本,其中包括13 條醫(yī)療屬性以及1 條標(biāo)簽屬性。13 條醫(yī)療屬性分別為:年齡、性別、胸部疼痛類型、靜息血壓、膽固醇、空腹血糖>120mg/dl、靜息心電圖測量、最高心跳率、運(yùn)動誘發(fā)心絞痛、運(yùn)動相對于休息引起的ST 抑制、運(yùn)動ST 段的峰值斜率、主要血管數(shù)目、血液疾病。
常用于研究疾病在群體中產(chǎn)生與發(fā)展趨勢的預(yù)測模型有回歸預(yù)測模型、時間序列預(yù)測模型、馬爾科夫預(yù)測模型、灰色系統(tǒng)預(yù)測模型等。由于BP 神經(jīng)網(wǎng)絡(luò)具有學(xué)習(xí)能力,能夠優(yōu)化學(xué)習(xí)進(jìn)度,在信號正向傳播過程中,輸入層將數(shù)據(jù)傳送給隱層,隱層將信息傳送給輸出層,若輸出的信息不正確,則將輸出結(jié)果轉(zhuǎn)化為輸入數(shù)據(jù)再反饋給隱層并重新輸入。在反向傳遞時,根據(jù)整體誤差不斷修正各個連接權(quán)值和閾值,使得最終整體誤差最小,或達(dá)到預(yù)設(shè)精度后再進(jìn)行預(yù)測[15-17]。
2 心血管疾病預(yù)測模型
2.1 改進(jìn)的特征選擇方法
特征選擇是指從經(jīng)過預(yù)處理的特征集合中選擇有效特征,在降低數(shù)據(jù)維度的同時,能夠減少計(jì)算量。但隨機(jī)森林的特征選擇雖然在特征變量特別多的數(shù)據(jù)集中表現(xiàn)良好,但在具有較少屬性值的醫(yī)療數(shù)據(jù)分析中效果不佳,其會對各種屬性賦予不等同于其重要性的權(quán)值,因此單純使用隨機(jī)森林會導(dǎo)致重要屬性被忽略。為此,本文引入Relief 算法,雖然Relief 算法對于中、低影響度的屬性區(qū)分不明顯,但對于高影響度的屬性區(qū)分明顯。兩種算法的結(jié)合使得隨機(jī)森林避免了重要屬性的缺失,也彌補(bǔ)了Relief算法無法區(qū)分中、低影響度屬性的缺點(diǎn),從而在保證重要屬性不丟失的情況下,對各種屬性按其重要程度賦予權(quán)值。
2.2 改進(jìn)的發(fā)病預(yù)測模型
2.2.1 屬性指標(biāo)定義
實(shí)驗(yàn)中所使用的心血管疾病相關(guān)屬性信息如表2 所示。

Table 2 Cardiovascular disease related attributes表2 心血管疾病相關(guān)屬性
屬性指標(biāo)中存在如性別、胸部疼痛類型、空腹血糖、靜息心電圖測量、運(yùn)動ST 段峰值斜率等文本型指標(biāo)需進(jìn)行文本轉(zhuǎn)換,對于二值類數(shù)據(jù),例如在性別特征中,包含男性和女性兩種取值,可將女性映射為0,男性映射為1。在空腹血糖指標(biāo)中,當(dāng)空腹血糖大于120mg/dl 時,將其映射為0;當(dāng)空腹血糖小于120mg/dl 時,將其映射為1。同理,在運(yùn)動性心絞痛屬性中,當(dāng)屬性值為真時,將其映射為0,反之映射成1。對于多值型屬性,如在胸部疼痛類型的數(shù)據(jù)特征中,可根據(jù)疼痛由重到輕,將典型心絞痛映射為0,非典型心絞痛映射為1,非心絞痛疼痛映射為2,無臨床癥狀映射為3。同理,在靜息心電圖測量、ST 段坡度值以及地中海貧血嚴(yán)重程度屬性中,將其映射成0~3,文本屬性數(shù)據(jù)化后的處理結(jié)果如表3 所示。
2.2.2 數(shù)據(jù)歸一化處理
數(shù)據(jù)集中不同屬性值的數(shù)量級與物理含義往往不一致,為加快訓(xùn)練速度,在訓(xùn)練樣本進(jìn)入訓(xùn)練模型之前,往往需要對訓(xùn)練數(shù)據(jù)進(jìn)行歸一化處理,使不同類型的屬性值均在同一數(shù)量級,以對各屬性值進(jìn)行綜合對比評價(jià)。由于每個特征屬性之間具有不同量綱,針對連續(xù)變化的數(shù)值型數(shù)據(jù),需要對其進(jìn)行數(shù)值歸一化處理,以消除不同量綱對各屬性綜合性能的影響。目前,常見的歸一化方法有最大最小值歸一化、零均值歸一化等,本文采用標(biāo)準(zhǔn)差標(biāo)準(zhǔn)化(Standard Scale)方法,使得處理后的數(shù)據(jù)符合標(biāo)準(zhǔn)正態(tài)分布,即均值為0,標(biāo)準(zhǔn)差為1,其轉(zhuǎn)化函數(shù)為。其中,μ為所有樣本數(shù)據(jù)均值,σ為所有樣本數(shù)據(jù)標(biāo)準(zhǔn)差。與最大最小值歸一化、零均值歸一化不同,標(biāo)準(zhǔn)差標(biāo)準(zhǔn)化方法是針對每一個特征維度進(jìn)行的,而不是針對樣本。處理結(jié)果如表4 所示。

Table 3 The results processed after the datamation of text attributes表3 文本屬性數(shù)據(jù)化后處理結(jié)果

Table 4 Results after normalization of index data表4 指標(biāo)數(shù)據(jù)歸一化后結(jié)果
2.2.3 特征選取
在大數(shù)據(jù)時代,海量的結(jié)構(gòu)化與非結(jié)構(gòu)化數(shù)據(jù)為醫(yī)療數(shù)據(jù)處理增加了一定難度,過多的數(shù)據(jù)特征和維度在數(shù)據(jù)處理中會增加BP 數(shù)據(jù)網(wǎng)絡(luò)的結(jié)構(gòu)復(fù)雜度,也會加大模型訓(xùn)練的時間復(fù)雜度,使訓(xùn)練出的模型無法為心血管疾病提供更準(zhǔn)確的預(yù)測。要通過較少的指標(biāo)屬性達(dá)到理想的預(yù)測精度,可運(yùn)用屬性降維算法來實(shí)現(xiàn)。從眾多醫(yī)療指標(biāo)中選擇與心血管疾病相關(guān)性較強(qiáng)的一些指標(biāo),同時過濾掉不相關(guān)及冗余指標(biāo)。分別采用隨機(jī)森林以及Relief F 求各個醫(yī)療屬性的權(quán)重及其排序,結(jié)果如表5 所示。

Table 5 The weights of medical attributes and their order表5 醫(yī)療屬性權(quán)重及其排序
隨機(jī)森林基于不純度的排序結(jié)果非常鮮明,除得分最高的幾個特征外,其余特征得分急劇下降。從表中可以看到,得分第5 的特征權(quán)重值比得分第1 的特征權(quán)重值小一倍,而其他特征選擇算法下降沒有這么劇烈。隨機(jī)森林是一種非常流行的特征選擇方法,其易于使用,一般不需要特征工程、調(diào)參等繁瑣的步驟。但是利用隨機(jī)森林求權(quán)重存在兩個缺陷,一是重要特征有可能得分很低,二是這種方法對特征變量類別越多的特征越有利[17]。因此,僅使用隨機(jī)森林進(jìn)行特征選擇會將重要的醫(yī)療屬性賦予低權(quán)重值,導(dǎo)致重要的醫(yī)療屬性被篩掉,從而影響對疾病的預(yù)測,大大降低了預(yù)測精度[18]。為克服隨機(jī)森林的缺陷,引入Relief F 算法可篩掉中、低影響度的屬性,而不會影響中、高影響度的屬性。由于在隨機(jī)森林訓(xùn)練中會將權(quán)重大的屬性賦予低權(quán)重值,而Relief F 對中低影響度的屬性區(qū)分不明顯,對高影響度的屬性區(qū)分明顯,因此保留隨機(jī)森林中權(quán)重值靠前的屬性,分別是cp、thalach、thal、oldpeak、age、trestlops,再取在Relief F 算法中權(quán)重排名前5 的屬性,分別是sex、restecg、thal、exang、ca。由Relief F 算法訓(xùn)練結(jié)果可發(fā)現(xiàn),sex 及restecg 屬性被賦予了較高權(quán)重值,而這兩個屬性在隨機(jī)森林訓(xùn)練中則被賦予了較低屬性值,因此保留sex與restecg 屬性。最終保留的屬性為:cp、sex、thalach、restecg、thal、oldpeak、exang、age、ca、restbps。
2.2.4 神經(jīng)網(wǎng)絡(luò)層數(shù)
由于三層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)簡單、易于實(shí)現(xiàn),因此疾病預(yù)測系統(tǒng)選擇三層結(jié)構(gòu)進(jìn)行相關(guān)測試,網(wǎng)絡(luò)中層數(shù)都被設(shè)定為1。
2.2.5 輸入層與輸出層節(jié)點(diǎn)數(shù)確定
本文采用神經(jīng)網(wǎng)絡(luò)技術(shù),首先要確定各神經(jīng)網(wǎng)單元數(shù)。神經(jīng)網(wǎng)絡(luò)輸入節(jié)點(diǎn)就是心臟病預(yù)測時的相關(guān)指標(biāo)數(shù)據(jù),本文所選數(shù)據(jù)通過特征選擇算法之后確定了10 個特征屬性。所以,確定輸入層節(jié)點(diǎn)數(shù)為10,輸出層節(jié)點(diǎn)數(shù)為1。
2.2.6 隱層神經(jīng)單元數(shù)
隱層單元數(shù)選擇是一個十分復(fù)雜的問題,也是神經(jīng)網(wǎng)絡(luò)研究的熱點(diǎn)問題之一。隱層節(jié)點(diǎn)數(shù)的確定與問題要求、輸入輸出單元數(shù)量及輸入輸出單元分布都有直接關(guān)系。節(jié)點(diǎn)數(shù)太多會增加訓(xùn)練時間,其中隱層神經(jīng)單元數(shù)可自行設(shè)定。一般而言,問題越復(fù)雜,需要的隱層單元數(shù)越多,隱層單元數(shù)越多,則越容易收斂,但隱層單元過多會增加計(jì)算量[19]。本文根據(jù)如下規(guī)則確定隱層神經(jīng)元數(shù)目:隱層神經(jīng)元數(shù)目大于輸入層神經(jīng)元與輸出層神經(jīng)元數(shù)目總和的一半,小于輸入層神經(jīng)元與輸出層神經(jīng)元數(shù)目總和[20]。對于不同的隱層,網(wǎng)絡(luò)識別率也不同。因此,統(tǒng)計(jì)出不同隱層神經(jīng)元個數(shù)對應(yīng)的網(wǎng)絡(luò)識別正確率,如圖1 所示。
2.2.7 學(xué)習(xí)率M
較高的學(xué)習(xí)率會導(dǎo)致網(wǎng)絡(luò)誤差較大,或呈現(xiàn)不規(guī)則離散狀態(tài),學(xué)習(xí)率過低會降低網(wǎng)絡(luò)訓(xùn)練效率,但能保證收斂于某個極小區(qū)間。因此,為使訓(xùn)練過程收斂速度快且較穩(wěn)定,通常在0.08~0.1 區(qū)間取值[21-22]。經(jīng)反復(fù)多次驗(yàn)證后,將識別率高的平均值篩選出來。通過研究得出結(jié)論,當(dāng)起始學(xué)習(xí)率取0.08 時,網(wǎng)絡(luò)所用時間越少,收斂速度越快。因此,網(wǎng)絡(luò)模型將原始識別率設(shè)置為0.08,如圖2 所示。

Fig.1 Correct rate of BP neural network with different number of hidden layer neurons圖1 不同隱層神經(jīng)元個數(shù)對應(yīng)的BP 神經(jīng)網(wǎng)絡(luò)正確率

Fig.2 Training time at different learning rates圖2 不同學(xué)習(xí)率下的訓(xùn)練時間
3 預(yù)測模型實(shí)驗(yàn)結(jié)果分析
在輸出部分,BP 神經(jīng)網(wǎng)絡(luò)的訓(xùn)練函數(shù)trainscg 值域一般區(qū)間為[-1,1],由于本文樣本數(shù)據(jù)的特殊性,都是0 和1,所以對于輸出的數(shù)據(jù),將輸出值大于等于0.6 的數(shù)據(jù)賦值為1,將輸出值小于0.6 的數(shù)據(jù)賦值為0。在正確率計(jì)算部分,將訓(xùn)練樣本與測試樣本的每一位逐一進(jìn)行比較,若一致即視為正確,若不一致則視為錯誤。
本文將經(jīng)過特征選擇篩選后的屬性帶入BP 模型預(yù)測結(jié)果,并與直接使用BP 神經(jīng)網(wǎng)絡(luò)算法進(jìn)行預(yù)測的結(jié)果相比較。改進(jìn)后的模型運(yùn)行速度得到了有效提升,大大縮短了運(yùn)行時間,提高了時效性。兩個模型運(yùn)算時間對比如圖3所示。
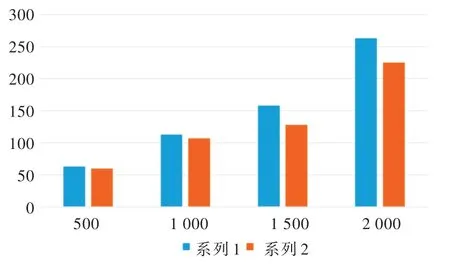
Fig.3 Comparison between operation time of the two models圖3 兩個模型運(yùn)算時間對比
在圖3 中,分別采用500、1 000、1 500 以及2 000 個例子作比較,系列一為直接使用BP 神經(jīng)網(wǎng)絡(luò)進(jìn)行心血管疾病預(yù)測所耗費(fèi)的時間,系列二為采用與特征選擇相結(jié)合的BP神經(jīng)網(wǎng)絡(luò)進(jìn)行心血管疾病預(yù)測所耗費(fèi)的時間。通過對比發(fā)現(xiàn),采用與特征選擇相結(jié)合的BP 神經(jīng)網(wǎng)絡(luò)模型可以大大提升預(yù)測速率,從而增強(qiáng)了數(shù)據(jù)從上傳到診斷的時效性,加快了診斷速率。
為防止過于追求時效性而忽略準(zhǔn)確性的情況發(fā)生,圖4、圖5 分別為采用經(jīng)過特征選擇的BP 神經(jīng)網(wǎng)絡(luò)與沒有經(jīng)過特征選擇的BP 神經(jīng)網(wǎng)絡(luò)預(yù)測心血管疾病的混淆矩陣。
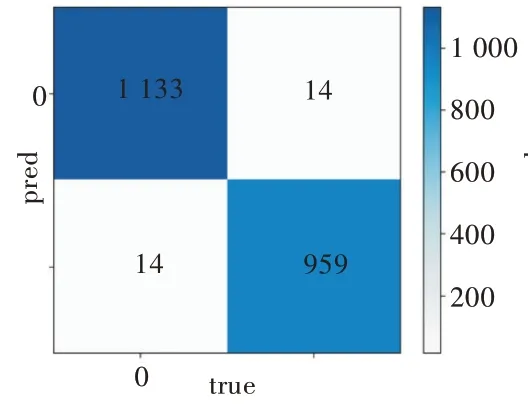
Fig.4 Confusion matrix without feature selection圖4 沒有經(jīng)過特征選擇的混淆矩陣
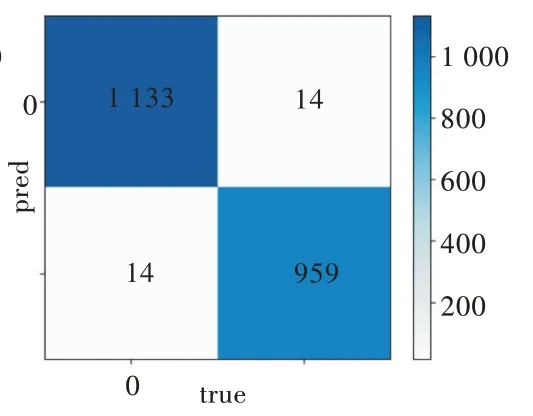
Fig.5 Confusion matrix selected by feature selection圖5 經(jīng)過特征選擇的混淆矩陣
在圖4 與圖5 中,混淆矩陣是對分類結(jié)果的矩陣表示。左上方單元格表示當(dāng)樣本實(shí)際為真時被分類為真的樣本數(shù)(即真實(shí)陽性),右下方單元格表示當(dāng)樣本實(shí)際為假時被分類為假的樣本數(shù)。其他兩個單元(左下方單元格和右上方單元格)表示錯誤分類的樣本數(shù)。具體來說,左下方單元格表示樣本實(shí)際為真(即假陰性)時分類為假的樣本數(shù),右上方單元格表示實(shí)際為假(即假陽性)時被分類為真的樣本數(shù)。一旦構(gòu)建了混淆矩陣,即可輕松計(jì)算出分類精度、靈敏度和特異性。分類精度=(TP+TN)/(TP+FP+TN+FN);靈敏度=TP/(TP+FN);特異性=TN/(TN+FP)。其中,TP、TN、FP 和FN 分別表示真陽性、真陰性、假陽性和假陰性。每個模型是根據(jù)分類精度、靈敏度以及特異性進(jìn)行評估的。對于每種算法,發(fā)現(xiàn)沒有經(jīng)過特征選擇的BP 神經(jīng)網(wǎng)絡(luò)分類精度為98.68%,靈敏度為98.78%,特異性為98.56%。經(jīng)過特征選擇的BP 神經(jīng)網(wǎng)絡(luò)分類精度為98.68%,靈敏度為98.78%,特異性為98.56%。
通過分析可以得到,經(jīng)過特征選擇后的BP 神經(jīng)網(wǎng)絡(luò)可在保持準(zhǔn)確率的同時,極大地提高時效性。
4 結(jié)語
本文應(yīng)用基于隨機(jī)森林與Relief 的特征選擇方法對心血管疾病屬性進(jìn)行權(quán)重排序,篩選出權(quán)重高的醫(yī)療屬性,應(yīng)用BP 神經(jīng)網(wǎng)絡(luò)算法對心血管疾病數(shù)據(jù)進(jìn)行預(yù)測并得到最終的患病結(jié)果,根據(jù)分類精度、靈敏度、特異性進(jìn)行評估。研究結(jié)果表明,經(jīng)過特征選擇后的BP 神經(jīng)網(wǎng)絡(luò)能夠在不影響預(yù)測準(zhǔn)確率的同時,得到更好的時效性,能準(zhǔn)確、有效地預(yù)測心血管疾病。此外,目前的文獻(xiàn)提出的模型用于預(yù)測心血管事件的風(fēng)險(xiǎn),但大多數(shù)都沒有經(jīng)過臨床驗(yàn)證來比較其預(yù)測效果,所以該模型目前對臨床疾病預(yù)測方面的價(jià)值尚不可知,更不用說在實(shí)踐中加以應(yīng)用。在大數(shù)據(jù)時代應(yīng)該關(guān)注現(xiàn)有心血管風(fēng)險(xiǎn)模型在臨床中是否可以保證預(yù)測效果,最后對最有前途的臨床預(yù)測模型進(jìn)行量化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
