一種結合GrabCut 與五幀差分法的ViBe 算法
2021-04-23 05:50:42熊玖朋李旭健潘紀成
軟件導刊 2021年4期
熊玖朋,李旭健,潘紀成
(山東科技大學計算機科學與工程學院,山東青島 266590)
0 引言
運動目標檢測(Motion Detection)是指將圖像序列或視頻中空間位置發生變化的物體作為前景提取出來并標示的過程。視頻序列中的運動目標(前景對象)檢測是許多計算機視覺應用中信息提取的主要步驟之一,包括交通監控、自動遠程視頻監控和人員跟蹤等。其被用于自動視頻監控系統和交通監控系統,在這些系統中,對人或車輛的準確分割對于執行可靠的跟蹤或識別任務至關重要[1]。運動目標檢測在交通監控、軍事等領域有著重要應用,也是目前計算機視覺和數字圖像處理研究的難點和熱點之一。
運動目標檢測有以下基本方法:光流法(optical flow)、幀間差分法(inter frame difference method)和背景減法(background subtraction)[2]。光流法即利用圖像序列中各像素在時間域上的變化,并根據上一幀與當前幀之間的相關性計算出物體運動信息的一種方法[3]。常用的光流法有:基于梯度的方法、基于匹配的方法、基于能量的方法、基于相位的方法和神經動力學方法等。光流法計算結果精確,但是計算量非常大,導致實時性差、實用性不強[4]。幀間差分法即對連續的多個幀進行差分運算,根據像素點灰度值差的絕對值與預設閾值的比較結果進行判斷。若絕對值超過閾值,則判斷該像素屬于前景,否則判斷其屬于背景。幀間差分法原理簡單,可快速檢測場景中的運動目標,同時對光照變化具有一定魯棒性,但存在容易出現空洞和重影等缺點。背景減法是目前使用最廣泛的檢測方法之一[5],其是一種對靜止場景進行運動分割的通用方法,可將當前獲取的圖像幀與背景圖像作差分運算,得到目標運動區域的灰度圖,之后對灰度圖進行閾值化處理提取運動區域,且為了避免環境光照變化的影響,背景圖像根據當前獲取的圖像幀進行更新。背景差分法算法簡單,在一定程度上可避免光照變化的影響,但其不能用于運動的攝像頭,且對背景圖像實時更新困難。為彌補以上所述背景減法的缺點,2009 年,Barnich 等[5]提出一種新的目標檢測方法——ViBe 算法。與GMM 和Codebook 算法相比,ViBe 算法初始化及時,響應速度快,有較強的實時性以及較好的抗噪性能,同時其在解決動態背景和模型初始化問題方面具有良好性能,算法具有的自適應更新機制可保證像素模型的生命周期以平滑的指數衰減形式存在,并且可在單個模型、可變速度和可接受的條件下處理每個像素的內存消耗。但是ViBe 也存在一些問題,如檢測的物體不完整、對光照突變非常敏感、對閃爍背景點處理效果不好等,因此容易造成大量誤檢[6]。
針對以上提到的ViBe 算法的不足,本文提出一種結合GrabCut 算法與五幀差分法的ViBe 算法,該算法減少了劇烈光照及顏色因素對ViBe 算法的影響,同時提高了ViBe算法對運動目標檢測的完整性。
1 ViBe 算法
ViBe 算法是一種像素級別的視頻前景提取算法。與大多數背景建模方式不同,ViBe 算法不需要等待幾個幀進行初始化,而是僅通過第一幀進行初始化[7]。其基本思想是:為檢測的每一幀圖像中的每個像素建立一個樣本集,該樣本集通過計算當前識別像素的樣本集與背景樣本集的交集來確定。該算法主要分為3 步:像素點建模、單幀初始化與模型更新[8]。
(1)像素點建模。假設每一個像素與其鄰域像素的像素值在空域上有相似的分布,在該假設成立的條件下,圖像中每一個像素模型都可用其鄰域中的像素來表示。鄰域范圍要足夠大,以此保證背景模型符合統計學規律。當輸入第一幀圖像時,像素背景模型如下:
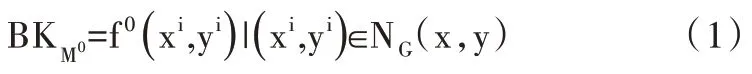
其中,NG(x,y)表示空域上相鄰的像素值,f0(x,y)表示當前點的像素值,(xi,yi)表示像素點(x,y)被初始化的次數。
(2)單幀初始化。當t=k 時,像素點(x,y)的背景模型為像素值為fk(x,y)。按照以下方式判斷該像素值是否為前景:
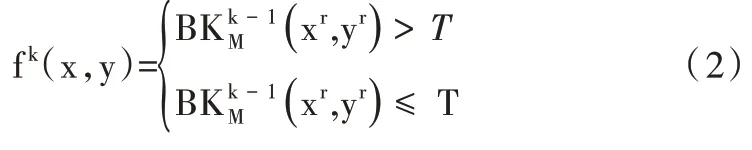
其中,r 為隨機數,T 為預設的閾值。當f(kx,y)滿足公式(2)時,則認為該像素點為背景。
(3)模型更新。Vibe 算法更新有兩種方式:時間上的隨機更新和空間上的隨機更新[9]。
時間上的隨機更新:在已建立的背景模型中隨機抽取一個背景模型,設為PG,如圖1 所示。P(x)表示圖像PG在x位置的像素點,周圍8 個像素點為其八鄰域。當獲得一幀新圖像Pt時,若在新圖像x 位置的像素Pt(x)被判斷為背景像素,則PG需要被更新。
空間上的隨機更新:在圖像PG中選取一個像素點PG(x),用該像素點八鄰域中的隨機一個像素替換掉PG(x)。
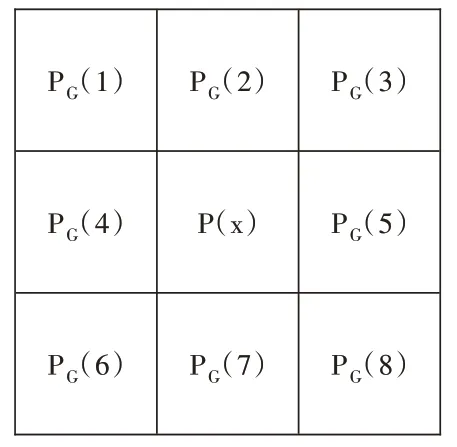
Fig.1 Eight neighborhood of pixel P(x)圖1 像素P(x)的八鄰域
2 GrabCut 算法
近年來,研究者們對圖像分割進行了大量研究,提出一些圖像分割算法。其中,GraphCut 算法受到了很多研究者關注[10-11]。GrabCut 算法是一種可有效從復雜背景中提取目標前景的交互式圖像分割算法,也是一種迭代的GraphCut 算法。GrabCut 算法僅需要使用圖像中的紋理信息和邊界信息,以及通過少量的用戶交互操作,即可有效從復雜背景中分割出前景目標。GrabCut 算法采用“不完全標記”,在給定的結果下,用戶所需的交互操作大大簡化,這意味著用戶可簡單地在對象周圍放置一個矩形來提取對象。
GrabCut 算法是在GraphCut 算法基礎上迭代而來的,相比GraphCut 算法,GrabCut 算法主要在3 個方面進行了改進:①GraphCut 的目標和背景模型是灰度直方圖,GrabCut則使用RGB 三通道的彩色圖像模型;②GraphCut 的分割是一次性完成的,而GrabCut 在GMM 參數學習估計過程中運用了可進化的迭代算法;③GrabCut 算法允許不完全標注。
因為GrabCut 算法采用彩色模型,所以需要一個額外的向量k={k1,k2,…,kn},其中k 指第k 個高斯分量,n 指第n個像素。整個圖像的Gibbs 能量表示為:
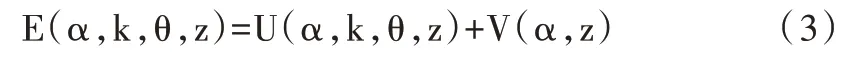
式中,E 為Gibbs 能量,U 為數據項,具體定義為:
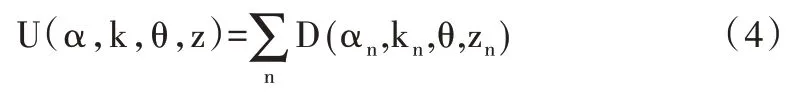
其中,式(4)中D 表示區域項,具體公式為:
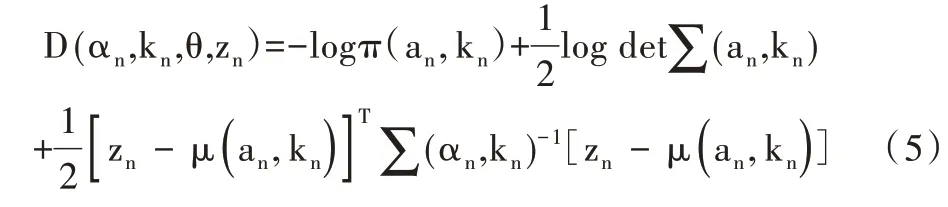
式(3)中V 為平滑項,由歐式距離求得:
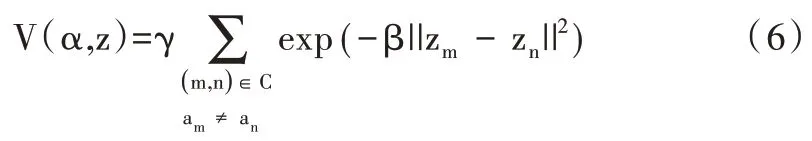
式(3)中θ 指圖像的灰度直方圖,可表示為:θ={h(z,α),α=(0,1)};z 則是圖像灰度值具體數值。
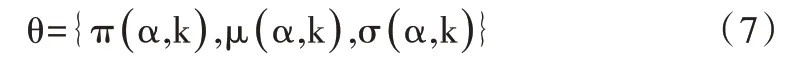
GrabCut 算法通過多次迭代求得,若想得到最優的分割圖像,則要求算法在每一次迭代時的GMM 參數越來越精確。詳細步驟如下[12]:
(1)用戶需要框選出存在“可能目標”的區域TU,區域TU中的像素初始化記為αn=1。
(2)未被選擇的部分即為背景區域TB,而區域TB中的像素初始化記為αn=0。
(3)通過K-means 算法初始化背景和前景中每一個像素的高斯混合模型分量。
(4)對每一個像素分配GMM 中的高斯分量:kn=
(6)分析Gibbs 能量項,建立一個圖,通過最大流最小切割定理算法進行分割:
重復步驟(3)—步驟(5),直到收斂。
3 五幀差分法
幀間差分法在研究過程中不斷發展,之前常用的二幀差分法及三幀差分法[13]計算簡單、容易實現,但是效果不太理想[14],而在三幀差分法基礎上改進的五幀差分法具有更好的效果,能夠在一定程度上減少重影和鬼影的出現。
五幀差分法基本思想為:首先選取連續五幀已初始化的圖像:fi-2(x,y)、fi-1(x,y)、fi(x,y)、fi+1(x,y)與fi+2(x,y)。對這五幀圖像進行高斯濾波后,再進行中值濾波處理,得到Ii-2(x,y)、Ii-1(x,y)、Ii(x,y)、Ii+1(x,y)與Ii+2(x,y)。將處理后的中間幀圖像Ii(x,y)與其他四幀圖像進行差分運算[15],可得:
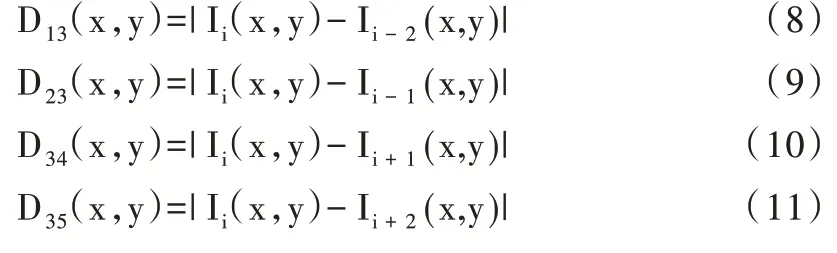
因為“與”運算在一定程度上能夠抑制重影的產生,所以由式(8)-式(11)得出的結果D13(x,y)、D23(x,y)、D34(x,y)和D35(x,y),將D13(x,y)和D35(x,y)、D23(x,y)和D34(x,y)分別進行“與”運算,得到D1、D2[16]。其中:
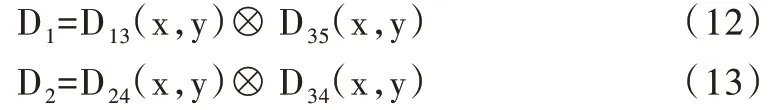
之后對D1、D2進行降噪處理,再分別用動態閾值進行二值化處理,最后將處理結果進行“與”運算得到D。
相比其他幀間差分法,五幀差分法在保證運算速度的同時,還避免了重影和空洞等問題,而D13、D23、D34和D35作為動態數值,會隨視頻幀的光照變化而變化,因此五幀差分法得到的結果受光照變化影響較小。在五幀差分算法中,對差分結果進行“與”運算及“或”運算也能確保最后的結果更加精確和完善。
4 結合GrabCut 與五幀差分法的ViBe 算法
ViBe 算法無法很好地適應劇烈光照、容易出現鬼影等,五幀差分法能夠在一定程度上克服這些缺點,所以本文將ViBe 算法與五幀差分算法相結合。首先,將通過ViBe算法獲得前景和通過五幀差分法獲得的前景進行“與”運算,得到前景目標分割結果,將上述操作獲得的分割結果進行高斯濾波處理,從而去除較大的噪聲點,使得到的分割結果更加準確。
然后,利用GrabCut 算法提取分割結果,提取過程如下:對利用ViBe 算法與五幀差分法提取出的分割結果進行數學形態學膨脹處理,擴展前景區域,找到目標前景區域的邊緣輪廓線,從而找到能夠完全包含前景目標的最小矩形框,以減少需要計算的區域,大幅提高GrabCut 算法運算效率[17]。
根據文獻[17],GrabCut 算法主要是先迭代學習、訓練GMM 參數,然后在確定的GMM 參數下對原圖像進行目標提取,但這種通過迭代估計確定GMM 參數的方式制約了算法效率。通過實驗發現,若能提前確定GMM 參數,則可減少原GrabCut 算法90%的時間,所以提前找到包含前景目標的最小矩形框,可大大提升原GrabCut 算法效率。此外,原GrabCut 算法是在RGB 顏色空間分割目標,這也是制約其效率的原因之一,而本文直接利用GrabCut 算法對ViBe算法結合五幀差分法檢測出的大致區域進行分割,會再次提升GrabCut 算法效率,使算法能夠滿足視頻處理要求。
ViBe 算法與五幀差分法相結合獲得的分割結果一般為較完整的目標,但在個別惡劣條件下,當一個前景目標的檢測實驗結果為多個分割結果的組合時,可將任意兩個分割結果最小矩形框的中心點連線,根據與中心點垂直方向的夾角大小進行判斷。若夾角大小小于所預設的閾值,則認為這兩部分的分割結果為同一目標,將其劃分在同一矩形框內。具體算法流程如圖2 所示。
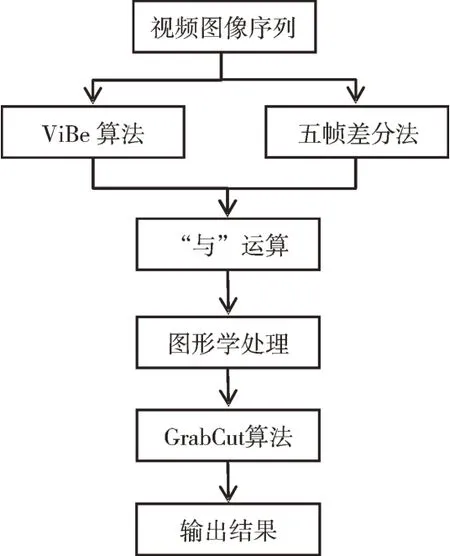
Fig.2 Improved algorithm flow圖2 改進算法流程
5 實驗結果分析
本文實驗在Windows10 操作環境與QT 4.11.1+Opencv4.1.2 環境下,采用2014DATDBASE 中的“Baseline”數據集進行實驗。ViBe 算法各個參數設置如下:相似閾值R=20,匹配數目閾值min=20,時間采樣閾值rate=16。
如圖3 所示,圖(a)分別是第137 幀、第425 幀、第777 幀原始圖像,圖(b)為相應幀原始圖像ViBe 算法的實驗結果,圖(c)為本文算法實驗結果。

Fig.3 Experimental comparison between ViBe algorithm and the algorithm in this paper圖3 ViBe 算法與本文算法實驗對比
根據實驗結果,采用原ViBe 算法進行檢測時,因汽車影子處運動速度較快,在檢測時會被判定為運動目標,從而出現鬼影,左側車輛經過樹蔭也會受到光照變化影響出現鬼影,并且由于樹葉反光等原因,檢測時會出現斑點狀鬼影,而本文算法減少了鬼影的產生。ViBe 算法與五幀差分法相結合對于光照等不利因素更具有魯棒性,而本文算法檢測出的目標更完整,減少了殘缺目標。與GrabCut 算法的結合,也能更準確地提取出檢測目標,進一步提高了目標提取的完整性與準確性。因此,本文算法在檢測精度上較為理想。在檢測速度上,因為GMM 背景差分算法運行時間為ViBe 算法的3 倍左右,本文算法運行時間介于兩者之間,相比原ViBe 算法較慢。然而,本次實驗證明,本文算法可滿足視頻的實時處理要求。綜上所述,本文算法仍能實現運動目標的完整檢測。
6 結語
針對原ViBe 算法存在的易受光照影響出現鬼影、檢測前景目標不夠精確等問題,本文提出一種結合了五幀差分法與GrabCut 算法的ViBe 算法。首先將五幀差分法與ViBe算法相結合獲得前景,五幀差分法可增強ViBe 算法對光照變化的魯棒性,然后對分割結果進行高斯濾波處理,最后使用GrabCut 算法進行提取,以更精確地提取出檢測目標。實驗結果證明,多種方法相結合提升了ViBe 算法的精確度,可在一定程度上避免光照變化的影響,但是多種方法的結合也一定程度上降低了算法效率,這將是接下來需要研究的一個重要問題。
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年6期)2021-06-09 05:57:08
現代國際關系(2021年2期)2021-04-13 01:59:16
當代陜西(2020年14期)2021-01-08 09:30:42
中國外匯(2019年11期)2019-08-27 02:06:32
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
太空探索(2016年10期)2016-07-10 12:07:01
