融合用戶長短期偏好的基于強化學習的推薦算法
2021-04-25 05:23:24杜子文
現代計算機 2021年6期
杜子文
(四川大學計算機學院,成都610065)
0 引言
隨著科技的進步與互聯網的蓬勃發展,推薦系統在人們的生活中占據了重要的地位[7-10]。其中基于強化學習的推薦系統由于具有靈活的推薦策略以及考慮了用戶的長期交互體驗從而吸引了越來越多的研究者的關注。例如,用戶在TikTok 上瀏覽視頻,推薦系統根據用戶的瀏覽記錄來改變推薦視頻的策略,從而推薦出不同的視頻,同時提高了用戶的瀏覽體驗,以便盡可能地將用戶留在TikTok 中。
基于強化學習的推薦算法的關鍵就是要捕捉用戶的偏好[1-4]。現有的基于強化學習的推薦算法編碼用戶的近期交互記錄來得到用戶的短期偏好并且將用戶的人口統計信息作為用戶的長期偏好[10-11],從而將短期偏好和長期偏好進行融合得到用戶的動態偏好。這種做法存在以下兩個問題:
(1)忽略了用戶的長期偏好是在隨著用戶的交互記錄的變化而變化的。
(2)沒有細粒度的建模用戶的長期偏好,即用戶每個時期的偏好對用戶當前交互的商品產生的影響是不同的。
因此本文提出一種細粒度地建模用戶長期偏好并且融合用戶長短期偏好的基于強化學習的推薦模型,名稱為LSR。本模型使用分層注意力的方法[5]首先在底層編碼用戶對不同商品的關注度,融合每個時期加權后的商品嵌入得到用戶的每個時期的偏好,然后在高層編碼用戶對不同時期偏好的關注度,再融合加權后的每個時期的偏好進而得到用戶的長期偏好;同時使用自注意力的方法融合用戶近期交互的商品得到用戶的短期偏好,最終將短期偏好和長期偏好融合得到用戶的動態偏好,即用戶的狀態,然后采用深度Q 網絡的方法[6]將推薦的商品與用戶的狀態融合送入多層感知機,得到累積獎勵值。我們的貢獻主要有以下三個:
(1)我們提出了一個融合用戶長短期偏好的基于強化學習的推薦模型,該模型可以細粒度地建模用戶的長期偏好,從而提高模型的推薦效果。
(2)我們采用分層注意力的方法來區分用戶對不同商品的關注度以及對不同時期偏好的關注度,細粒度地建模用戶的長期偏好。
(3)我們在真實的數據集上與baseline 進行對比,驗證了本模型的有效性。
1 強化學習
1.1 馬爾科夫決策過程
基于強化學習的推薦算法將推薦任務視為一個馬爾科夫決策過程,通過try-error 機制來獲取最優的推薦策略。我們可以用一個五元組來描述馬爾科夫決策過程:
(1)狀態空間S:狀態st代表用戶u在t時刻的偏好。st={Il,Is},其中Il代表了用戶的長期偏好,Il中包含了用戶在當前會話之前的所有會話中交互的商品。Is代表了用戶的短期偏好,Is中包含了用戶在當前會話中交互的所有商品。兩個集合中的商品都是按照時間順序排列的。
(2)動作空間A:動作at表示推薦系統在t時刻向用戶u推薦的一個商品it。
(3)狀態轉移概率P:當用戶u交互商品it后,我們就將這個商品it添加到Is集合中,得到下一個狀態st+1。
(4)當前獎勵值rt:用戶u會對商品it有不同的反饋,例如點擊、收藏、購買等,用戶通過不同的反饋行為來評價這次推薦系統推薦商品it的效果。我們根據用戶給出的反饋計算得到當前的獎勵值rt。
(5)折扣因子γ:折扣因子γ衡量當前獎勵值rt在累積獎勵值Q中占據的比重。折扣因子γ的取值范圍為[0,1],當折扣因子越接近1,表示當前獎勵值rt在累積獎勵值Q中占據的比重越小;當折扣因子越接近0,表示當前獎勵值rt在累積獎勵值Q中占據的比重越大。其中Q=rt+γrt+1+γ2rt+2+…。
1.2 問題定義
根據用戶u在t時刻的交互記錄st,我們的模型LSR 需要向用戶u推薦一個商品it,這個商品it可以使得推薦平臺獲得的累積獎勵值Q最大。
2 模型
在下文中,我們首先對模型進行概括描述,然后介紹模型中編碼用戶短期偏好和編碼用戶長期偏好以及深度Q 網絡的技術細節。
2.1 模型概述
圖1 展示我們的模型的整體結構。為了得到用戶動態的長期偏好,我們將用戶在當前會話之前的所有會話中交互的商品進行融合得到隨著用戶交互歷史記錄改變而發生變化的長期偏好。為了細粒度地對用戶的長期偏好建模,我們采用分層注意力的方法編碼用戶對不同商品的關注度,得到用戶對不同會話的偏好{pS1,…,pSj,…,pSn},其中pSj是用戶的第Sj會話的嵌入向量,用戶的長期交互記錄中一共有Sn個會話。然后我們編碼用戶對不同會話的關注度,從而細粒度地建模得到了用戶的長期偏好plong。同時,我們仍采用注意力的方法對用戶當前會話中的商品進行融合得到用戶的動態的短期偏好pcur。然后將長期偏好plong和短期偏好pcur進行融合得到用戶的動態偏好,即用戶的狀態st。然后我們采用一般的深度Q-learning 方法[6]中的?-greedy策略來選擇推薦系統要執行的動作at,即推薦系統向用戶推薦的商品it,然后將用戶狀態st和商品it送入到深度Q-network 神經網絡得到在狀態st下采取動作it所獲得的累積獎勵值Q(st,at;θ)。然后將商品it加入到當前會話中得到下個時刻的狀態st+1。
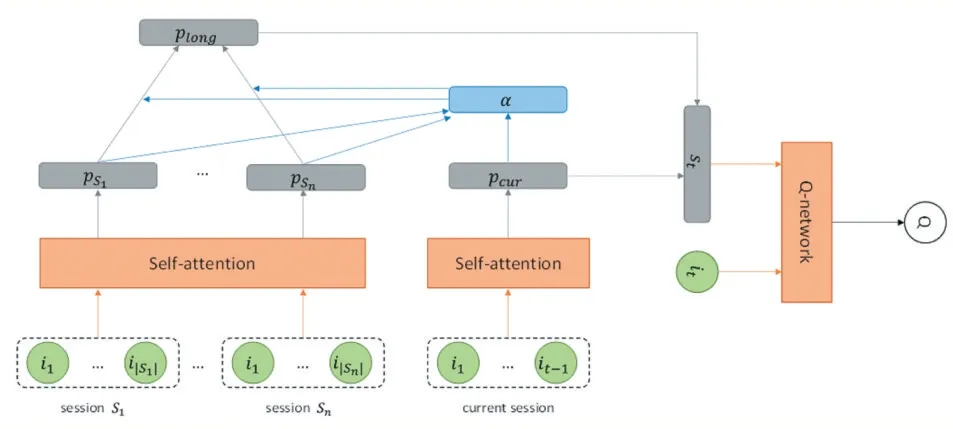
圖1 模型
2.2 編碼用戶短期偏好
由于用戶對當前會話中的商品具有不同的關注度,因此我們采用自注意力的方法[5]對當前會話中的商品{i1,…,it-1}進行融合得到用戶的短期偏好pcur。自注意力的方法包含三部分,分別是查詢矩陣qn×d,索引矩陣kn×d和值矩陣vn×d。自注意力的計算公式如下:
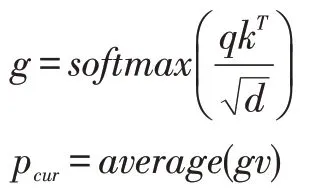
其中,d是商品的嵌入維度大小,n是當前會話中用戶交互商品的個數。g是計算得到的注意力系數,g∈Rn×d。pcur是 用 戶 的 短 期 偏 好 嵌 入 向 量,pcur∈R1×d,average(?)為求平均操作。在本文中查詢矩陣q,索引矩陣k和值矩陣v都是相同的,即都是包含了當前會話中用戶已交互的商品的嵌入,如下:
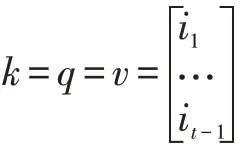
其中,i1×d是商品的嵌入向量。在本文中,我們將每個商品作為一個單詞,每個會話作為一個句子,采用Word2Vec 的方法[12]對商品進行預訓練得到低維的稠密的商品嵌入向量i。
2.3 編碼用戶長期偏好
考慮到用戶對歷史會話中的商品的關注度不同,于是我們仍然采用自注意力的方式對不同會話內的商品進行融合得到用戶不同會話的嵌入表達{pS1,…,pSj,…,pSn}。融合用戶對不同會話中商品的關注度的計算公式如下:
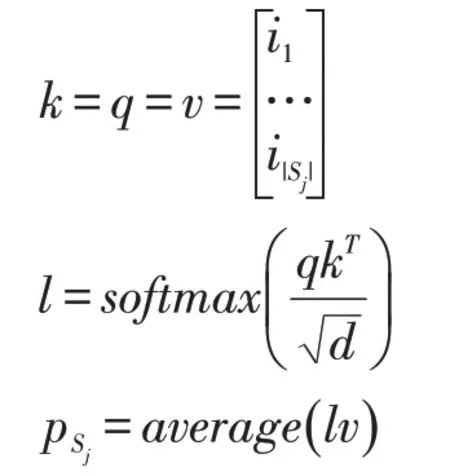
其中d是商品i的嵌入維度,l∈R|Sj|×d,pSj是用戶的第Sj會話的嵌入向量,pSj∈R1×d,由于用戶對不同會話的關注度也是不同的,于是我們再次采用注意力的方法建模用戶短期偏好對于不同會話的關注度。我們將短期偏好pcur作為查詢向量,將不同會話的嵌入向量作為索引向量和值向量,計算得到用戶對于不同會話的注意力得分α,然后將注意力得分α與每個會話的偏好進行融合得到用戶的長期偏好plong∈R1×d。計算公式如下:
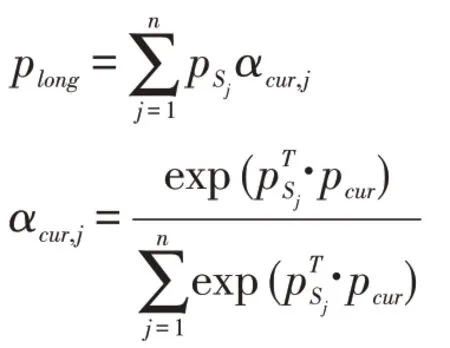
2.4 Q-network
在得到用戶的長期偏好plong和短期偏好pshort后,我們將長期偏好和短期偏好進行拼接操作得到用戶的動態偏好,也就是用戶的狀態st∈R1×2d。然后將用戶的狀態st和推薦系統向用戶推薦的商品it一起送入深度Q-network 神經網絡中,計算得到在狀態st下,執行動作at,所獲得的累積獎勵值Q∈R。我們采用一般的DQN 的五層全連接神經網絡來得到累積獎勵值Q(st,at;θ),其中θ為網絡的參數。
2.5 損失函數
在真實的推薦系統中,狀態空間和動作空間是巨大的,因此對于每一個狀態-動作對,估計其狀態值函數Q(s,a)是很困難的。另外很多狀態-動作對并沒有出現過,因此很難去得到這些狀態-動作對所對應的狀態值函數。因此,我們需要使用近似函數來估計狀態值函數,即Q( )s,a≈Q(s,a;θ)。由于狀態動作值函數是高度非線性的,于是我們采用深度神經網絡作為近似函數。在本文中,我們利用貝爾曼方程來訓練模型。我們采用隨機梯度下降的方法最小化下面的損失函數:
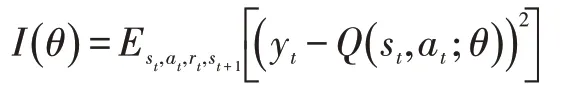
其中yt=Est+1[rt+γQ(st+1,at+1;θ)|st,at]。rt是根據用戶的反饋計算得到的當前獎勵值。
2.6 訓練過程
本模型采用基本的DQN 的訓練過程,我們的訓練過程可以分為兩個部分,分別是樣本存儲階段和采樣訓練階段。我們首先介紹樣本存儲階段:在t時刻,推薦系統觀察用戶的交互記錄st,根據用戶u 的交互記錄,采用ε-greedy策略,以小概率隨機選擇一個商品進行推薦或者以一個大概率推薦對應累積獎勵值最大的商品。接著用戶給出反饋,例如點擊、收藏、購買等行為。我們將反饋計算得到獎勵值。然后我們將商品添加到用戶的交互記錄中更新用戶的狀態,得到用戶的下一個時刻的狀態,并將樣本(st,at,rt,st+1)存儲起來;采樣訓練階段:在訓練樣本存儲后,我們隨機選擇batch size 大小的訓練樣本,然后采用隨機梯度下降的方法最小化損失函數。
3 實驗
3.1 實驗目的
我們在兩個真實的數據集上進行了實驗,并驗證了兩個問題:
(1)我們的模型與baseline 相比,推薦效果如何。
(2)我們的模型中細粒度建模用戶長期偏好的有效性。
我們首先介紹實驗的設置,然后我們會根據實驗結果回答以上兩個問題,最后我們研究了模型中關鍵超參數的影響。
3.2 實驗設置
我們采用了MovieLens(1M)數據集和MovieLens(100k)數據集。數據集的統計信息如表1。
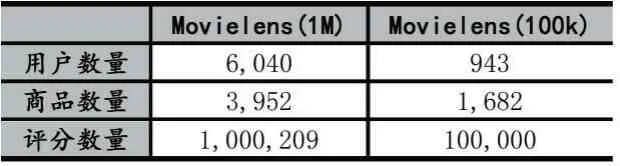
表1 實驗數據集說明
由于我們的模型沒有解決冷啟動的問題,因此我們過濾掉了交互商品數量少于3 個的用戶。過濾后的每個數據集我們都選取80%的數據作為訓練集,剩余20%的數據作為測試集。我們將每個商品作為一個單詞,每個會話作為一個句子,采用Word2Vec 的方法預訓練得到商品的低維稠密的嵌入向量,其中我們按天數來劃分會話,每一天都是一個會話。折扣因子γ=0.99 。我們將用戶對商品的評分作為當前獎勵值rt。
(1)Baselines
①GRU4Rec[13]:該模型使用循環神經網絡的方法將用戶交互的商品進行融合,然后給用戶推薦商品。
②DQN[6]:該模型融合了用戶的短期偏好,并且使用深度神經網絡來近似獲得累積獎勵值。
③DEERS[10]:該模型使用GRU 分別對用戶的正反饋信息和負反饋信息融合得到用戶的短期偏好,利用DQN 的訓練方式來進行訓練。
④LSR-short:該模型是我們LSR 模型的變體。該模型沒有考慮用戶的長期偏好,只采用注意力的方式融合了用戶當前會話交互過的商品。
⑤LSR-long:該模型是我們LSR 模型的變體。該模型沒有細粒度地建模用戶對不同會話時期的偏好,而是將用戶的每個會話的偏好以求平均的方式得到用戶的長期偏好。在建模短期偏好時,方法和LSR-short保持一致。
(2)評價指標
本文采用了兩個評價指標來衡量模型的推薦效果,分別是Recall和MRR。Recall評價的是所有測試樣例中真實樣例在top-k 列表中出現次數的情況的比例。MRR評價的是所有測試樣例中真實樣例在top-k列表中被正確排序的情況的比例。這兩個評價指標的計算公式如下:
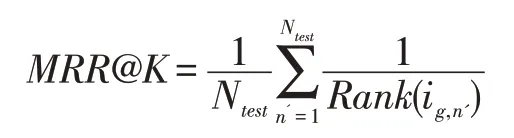
其中Rank(ig,n')是商品ig在第n' 個測試會話中的排名。
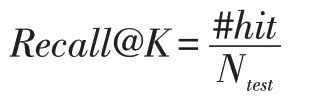
其中Ntest和#hit分別是測試會話的數量和測試商品出現在top-k 推薦列表的個數。值得注意的是,所有的評價指標的取值范圍都是[0,1],值越大表示推薦效果越好,值越小表示推薦效果越差。
3.3 實驗結果
實驗結果展示在表2 和表3 中。我們從表中有以下的發現:
(1)我們的模型LSR 在兩個數據集上的表現是最好的。LSR 模型的效果比GRU4Rec 模型的效果好,表明強化學習優秀的序列決策能力以及融合用戶長期短期偏好可以提高模型的推薦效果。LSR 模型比DQN模型和DEERS 模型的效果好,表明了融合用戶長短期偏好可以提高模型的推薦效果。
(2)DQN 模型的效果比GRU4Rec 模型的效果好,說明了強化學習的優秀的序列決策能力可以提高模型的推薦效果。
(3)DEERS 模型的效果比DQN 模型的效果好,表明了融合用戶的負反饋信息得到用戶的短期偏好可以提高模型的推薦效果。
(4)LSR-short 模型效果比DEERS 效果差,因為LSR-short 模型沒有考慮用戶的長期偏好以及沒有融合用戶的負反饋信息,因此效果差。但是LSR-short 模型比DQN 模型效果好,因為LSR-short 模型采用注意力的方法,編碼了用戶對不同商品的關注度,但是DQN模型是將不同商品平等看待,沒有區分不同商品對當前用戶的貢獻不同。
(5)LSR-long 模型效果比DEERS 效果差,因為LSR-long 模型沒有細粒度的建模用戶的長期偏好。從LSR-long 模型的效果比LSR-short 模型的效果好可以看出,建模用戶的長期偏好是可以提高模型的推薦效果的。
(6)LSR 模型的效果比LSR-short 模型的效果好,說明融合用戶長短期偏好可以提高模型推薦效果。LSR 模型比LSR-long 模型效果好,說明細粒度地建模用戶的長短期偏好可以提高模型的推薦效果。這也驗證了我們實驗的兩個目的。
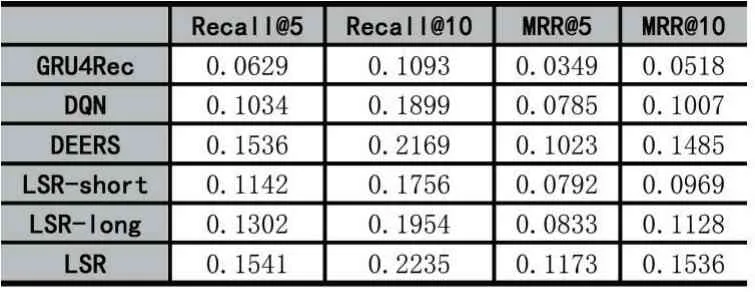
表2 所有模型在MovieLens(1M)數據集上的表現
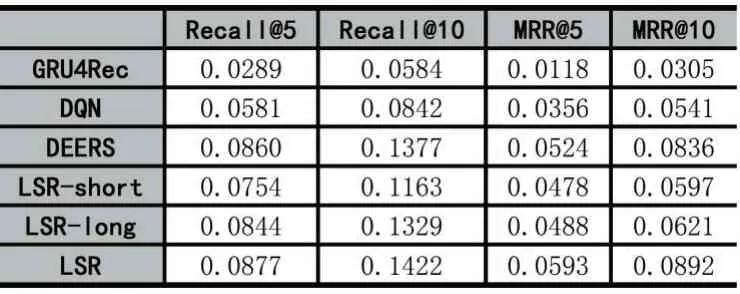
表3 所有模型在MovieLens(100k)數據集上的表現
3.4 超參數分析
我們在這個章節驗證了超參數商品維度d對模型效果的影響。結果如圖2 所示。
從圖2 可以看出商品的維度d可以影響到模型的效果。隨著d的增大,模型的效果先提高再下降。當d比較小的時候,網絡的參數少,模型會出現欠擬合的問題,從而導致最后的效果不好;當d過大時,網絡的參數會增多,模型會出現過擬合的問題,因此模型的效果會降低。從圖2 可以看出,對于MovieLens(1M)數據集來說,d=100 時,模型的效果表現最好;對于Movie Lens(100k)數據集來說,當d=128 時,模型的效果表現最好。
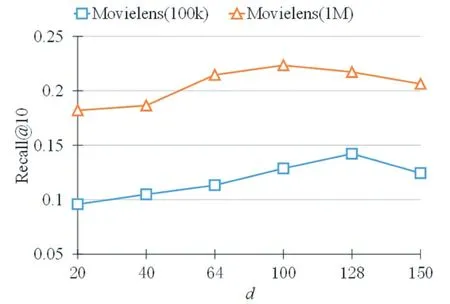
圖2 超參數分析——d 是商品的嵌入維度
4 結語
本文提出了一個融合用戶長短期偏好的基于強化學習的推薦模型,該模型細粒度地建模了用戶的長期偏好,從而提高了模型的推薦效果。本模型編碼了用戶對于不同商品的關注度以及不同會話的偏好關注度。在實際應用中,商品還有很多屬性信息,因此如何編碼用戶對商品不同的屬性的關注度是本文的未來的關注點。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年12期)2021-11-30 02:58:01
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
商用汽車(2016年11期)2016-12-19 01:20:16
Coco薇(2016年8期)2016-10-09 02:11:50
商用汽車(2016年6期)2016-06-29 09:18:54
