國產(chǎn)BWDSP的并行通信接口設計
2021-05-10 07:14:46蔡恒雨寧成明鄭啟龍
小型微型計算機系統(tǒng) 2021年5期
關鍵詞:模型
蔡恒雨,寧成明,侯 璇,鄭啟龍,2
1(中國科學技術大學 計算機科學與技術學院,合肥 230026)
2(中國科學技術大學 國家高性能計算中心,合肥 230026)
1 引 言
高性能計算設備進入了快速發(fā)展期,如DSP、ASIC和FPAG等硬件系統(tǒng)都在快速發(fā)展,并且逐漸走向成熟.隨著時代的發(fā)展,人類產(chǎn)生的數(shù)據(jù)越來越多,采用單個計算設備往往無法處理這些數(shù)據(jù),通常使用分布式計算設備對這些數(shù)據(jù)進行處理和分析.
美國德州儀器(TI)是一家知名的數(shù)字信號處理器設計和生產(chǎn)公司.它生產(chǎn)的TMS320[1]系列數(shù)字信號處理器系列具有功能豐富和成本低等特點,已經(jīng)廣泛應用于各行各業(yè).亞德諾(ADI)公司設計了定點DSP芯片如ADSP2111/2115等,浮點DSP芯片如虎鯊TS101和TS201S[2]等,目前也獲得了廣泛使用.Motorola公司也設計了定點DSP處理器MC56001和浮點DSP芯片MC96002.BWDSP系列處理器[3]是由中國電子科技集團公司第38研究所研制的一款具有完全自主知識產(chǎn)權的芯片,可以實現(xiàn)高性能計算,在圖像處理,視頻處理,自然語言處理和雷達信號處理[4]等領域具有廣泛應用.其中雷達信號處理,在我國軍工業(yè)的發(fā)展中具有十分重要的意義.
分布式系統(tǒng)的發(fā)展中,高性能數(shù)據(jù)通信協(xié)議和并行編程發(fā)揮著重要作用.RapidIO協(xié)議[5]作為一種嵌入式系統(tǒng)的數(shù)據(jù)通信協(xié)議,具有成本低和傳輸速度快的特點,廣泛應用于各種嵌入式系統(tǒng)的互聯(lián).該協(xié)議可以用于DSP和DSP之間,板卡和板卡之間的互聯(lián),支持的信號傳輸速率可以達到1.25GHz、2.5GHz和3.125GHz.同時出現(xiàn)了許多大規(guī)模的并行計算機系統(tǒng),如SMP[6]、MPP和DSM等,而并行計算通信技術在并行計算機系統(tǒng)中具有重要意義,通常分為數(shù)據(jù)并行和任務并行機制.各種并行計算通信標準層出不窮,如基于消息傳遞的MPI[7]和基于共享內(nèi)存的OpenMP[8].MPI是一種基于消息傳遞的數(shù)據(jù)通信接口,提供了豐富的數(shù)據(jù)通信能力,如點對點通信和群集通信接口.通過MPI編程接口,用戶可以輕松的編寫并行程序,充分使用分布式計算系統(tǒng)的并行計算能力.基于MPI標準誕生了MPICH和OpenMPI兩個重要的實現(xiàn).由于MPICH具有更好的可移植性的特點,現(xiàn)階段比較流行的是MPICH2.MPICH2[9]支持多種數(shù)據(jù)通信協(xié)議,在消息傳遞基礎上擴展了對共享內(nèi)存的實現(xiàn),提供了數(shù)據(jù)通信和同步控制功能,還可以用于發(fā)現(xiàn)內(nèi)存一致性錯誤[10].
BWDSP芯片具有較強的計算能力,適合處理計算密集型任務.雖然BWDSP虛擬平臺提供了數(shù)據(jù)通信接口和同步功能,用戶使用并不方便.本文在BWDSP虛擬平臺基礎上,借鑒主流并行編程庫MPICH,設計了優(yōu)化的并行通信庫MPIRIO,提高在BWDSP虛擬平臺上進行編程的方便性和靈活性,同時提升并行任務處理效率.本文接下來的組織如下:第2部分介紹MPI協(xié)議和BWDSP虛擬平臺;第3部分介紹并行計算通信MPIRIO的設計及其在深度學習的應用;第4部分介紹MPIRIO的相關實驗和性能評估;第5部分是總結(jié).
2 MPI協(xié)議與BWDSP虛擬平臺
2.1 MPI協(xié)議
2.1.1 MPI協(xié)議結(jié)構
MPI作為一個主流的并行通信庫,已經(jīng)獲得廣泛應用,發(fā)展出MPICH和OpenMPI兩個主要分支.本文主要以MPICH2為例進行分析,其體系結(jié)構可以分為4層架構,自下而上分別是通信協(xié)議層,CH3層,ADI層和API層,其中通信協(xié)議層具體有SSM通信協(xié)議,SCTP通信協(xié)議和TCP通信協(xié)議[11]等.MPICH2不僅支持消息傳遞機制,并且擴展了對共享內(nèi)存通信的支持.
MPICH2的上層(MPI/API層)與環(huán)境無關,它主要是提供用戶接口,并處理與環(huán)境無關的MPICH數(shù)據(jù)結(jié)構.MPICH2新定義了MPID層,即抽象設備接口層ADI3,為上層應用提供一種與具體設備無關的通信接口.并在ADI3下面又抽象出一層通道接口CH3層,提供了CH3接口供開發(fā)者實現(xiàn)自己的通信接口.在本文中,主要是基于BWDSP虛擬平臺使用的RapidIO協(xié)議設計相關并行通信接口.
2.1.2 MPI通信接口
MPI提供了兩種類型的數(shù)據(jù)通信接口,即阻塞型通信接口和非阻塞型通信接口.同時提供了4種數(shù)據(jù)的發(fā)送模式,4種發(fā)送模式的相應函數(shù)具有相同的調(diào)用參數(shù),但是對于消息的發(fā)送和接收的狀態(tài)要求不同.結(jié)合兩種類型和4種模式,可以形成8種點對點通信函數(shù),其函數(shù)名與對應通信類型如下:
1)MPI_Send():阻塞標準通信類型;
2)MPI_Bsend():阻塞緩存通信類型;
3)MPI_Ssend():阻塞同步通信類型;
4)MPI_Rsend():阻塞就緒通信類型;
5)MPI_Isend():非阻塞標準通信類型;
6)MPI_Ibsend():非阻塞緩存通信類型;
7)MPI_Issend():非阻塞同步通信類型;
8)MPI_Irsend():非阻塞就緒通信類型.
MPI標準提供的群集通信函數(shù)主要包括MPI_bcast()、MPI_scatter()、MPI_reduce()和MPI_gather()等.MPI_bcast()函數(shù)提供消息的廣播功能,即發(fā)送節(jié)點將消息發(fā)送到所有其他節(jié)點.MPI_scatter()函數(shù)提供消息的分發(fā)功能,即將發(fā)送方的數(shù)據(jù)分成多個部分,每個部分發(fā)往不同的接收方節(jié)點.MPI_bcast()函數(shù)提供消息的聚集功能,即所有節(jié)點都向一個接收節(jié)點發(fā)送消息.MPI_reduce()函數(shù)提供消息的規(guī)約功能,即所有節(jié)點都發(fā)送消息,將這些消息按照某種操作運算后發(fā)送到接收節(jié)點.
2.2 BWDSP虛擬平臺
2.2.1 BWDSP體系結(jié)構
BWDSP系列處理器是由中國電子科技集團公司第38研究所研制32位DSP處理器,其體系結(jié)構采用分簇式架構.每個處理器上有4個簇,每個簇上有4個支持MAC操作的乘法器,其最高可達30GOPS的運算能力.BWDSP的指令系統(tǒng)支持SIMD和VLIW類型的操作,可以用一條指令同時實現(xiàn)多個數(shù)據(jù)運算操作.
BWDSP芯片的最大工作主頻為 500MHz,指令周期為2ns.芯片內(nèi)部數(shù)據(jù)讀取位寬可以達到512比特,數(shù)據(jù)寫位寬可以達到256比特.由于其體系結(jié)構特點和計算能力較高,適用于深度學習應用和高性能計算領域.基于BWDSP芯片設計分布式計算平臺,提供并行編程庫具有重要意義.
2.2.2 RapidIO協(xié)議
RapidIO協(xié)議作為嵌入式系統(tǒng)互聯(lián)的數(shù)據(jù)通信協(xié)議,具有傳輸速率快和成本低的特點,適合未來高性能嵌入式設備之間的相互連接.該協(xié)議的3層體系結(jié)構自下而上為物理層,傳輸層和邏輯層,主要包括兩種設備,分別是終端設備和交換設備.其中邏輯層位于最上面,定義了數(shù)據(jù)包的格式和語義信息;傳輸層位于中間,主要定義數(shù)據(jù)包的調(diào)度和路由機制;物理層位于最下面,主要包括物理鏈路的傳輸特性、流量和錯誤管理等.
一個事務的完整過程是,RapidIO發(fā)送設備會發(fā)出請求數(shù)據(jù)包,交換設備收到該請求包后,會判斷是否由自己操作,如果是則直接處理該數(shù)據(jù)包.否則,會根據(jù)數(shù)據(jù)包中目標地址結(jié)合路由表信息,通過合適出口進行轉(zhuǎn)發(fā).當接收設備收到事務包后,會對數(shù)據(jù)包進行判斷和處理,并發(fā)送響應數(shù)據(jù)包.響應數(shù)據(jù)包的傳輸過程類似請求數(shù)據(jù)包,可以將其視為一種反向的“請求數(shù)據(jù)包”.
2.2.3 BWDSP虛擬平臺框架
基于BWDSP芯片設計了BWDSP虛擬平臺,該虛擬平臺采用RapidIO協(xié)議作為數(shù)據(jù)交換協(xié)議,實現(xiàn)BWDSP芯片之間的通信功能,為深度學習[12]應用和其他高性能計算應用提供基本通信原語和同步控制.
BWDSP單板卡系統(tǒng)的整體設計是采取4個BWDSP模型與1個RpaidIO交換模型組成,其整體結(jié)構圖如圖1所示.BWDSP模型分別連接到交換模型的4個端口上,將交換模型的剩余端口用于互聯(lián)其他單板卡,或者存儲模型,或者交換模型.外部存儲器模型可以是Flash或者DDR等,實現(xiàn)BWDSP對存儲器中信息的快速讀寫.BWDSP虛擬平臺向外提供了數(shù)據(jù)傳輸接口MRIO_send()和MRIO_recv()函數(shù),實現(xiàn)BWDSP芯片之間的數(shù)據(jù)傳輸.
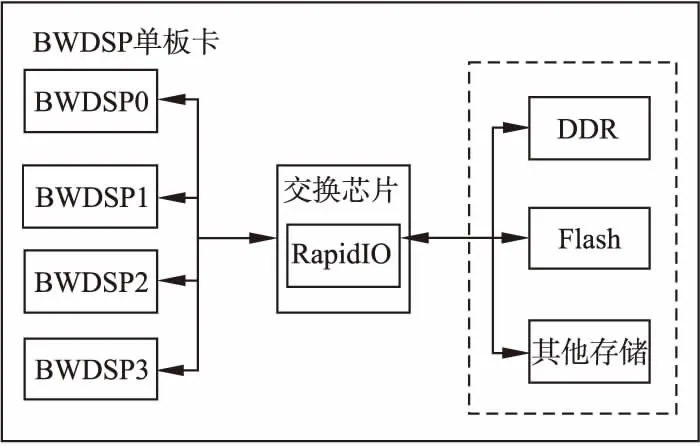
圖1 BWDSP虛擬平臺框架
BWDSP虛擬平臺中傳輸?shù)腞apidIO數(shù)據(jù)包長度為r_lenByte,BWDSP模型的時鐘頻率為b_freHz,數(shù)據(jù)總線的位寬為b_widthBit.RapidIO交換模型的時鐘頻率為r_freHz,數(shù)據(jù)傳輸速率為r_speedGbs.虛擬平臺中的交換芯片在每個工作周期中,可以完成對數(shù)據(jù)包的轉(zhuǎn)發(fā)或者處理.當BWDSP虛擬平臺的BWDSP模型和RapidIO交換模型協(xié)同工作時,r_fre和b_fre的關系滿足公式(1),r_speed和r_fre的關系滿足公式(2).當傳輸?shù)腞apidIO數(shù)據(jù)包長度為276字節(jié)時,BWDSP虛擬平臺數(shù)據(jù)傳輸速率可以達到4.416Gbs.
(1)
r_speed=r_fre×r_len×8
(2)
3 MPIRIO的設計與實現(xiàn)
3.1 MPIRIO的設計
MPI作為一個主流的并行通信庫,已經(jīng)獲得廣泛應用.同時MPI提供的群集通信函數(shù)適合深度學習模型的并行訓練,充分利用訓練數(shù)據(jù),并提高訓練速度.因此設計了基于BWDSP和RapidIO的并行計算通信庫MPIRIO,使深度學習模型更好的部署在BWDSP虛擬平臺上.MPIRIO借鑒MPI的分層結(jié)構,通過在CH3通道接口層之下增加RapidIO通信協(xié)議實現(xiàn),將該協(xié)議實現(xiàn)命名MRIO.
深度學習模型中存在多級并行性,如一個batch通常包含多條數(shù)據(jù),一條數(shù)據(jù)通常用矩陣表示等.MPIRIO需要設計優(yōu)化的群集通信算法[13],提升并行通信能力,使用BWDSP平臺提供的并行計算能力.
3.1.1 MPIRIO工作機制
MPIRIO類似MPI標準,通過將一個大型計算任務分成多個小任務進行解決.通常并行任務的處理過程分為劃分、映射、通信和聚集4個步驟.
主機(CPU)將任務分發(fā)到BWDSP板卡上的各個BWDSP芯片上,各芯片完成自己的任務后,通過RapidIO交換模型進行通信,直接將數(shù)據(jù)進行交換完成相應計算任務,無需再將數(shù)據(jù)發(fā)送回主機端.當獲得最終計算結(jié)果后,選擇其中某個BWDSP芯片將數(shù)據(jù)傳回主機.其工作機制如圖2所示,可以減少數(shù)據(jù)傳輸時間,同時降低對主機計算資源的占用率,此時主機可以調(diào)度其他計算任務.該工作機制實現(xiàn)了雙重計算和通信的重疊,首先是各BWDSP計算和BWDSP之間通信的重疊,其次是主機計算和BWDSP之間通信的重疊.
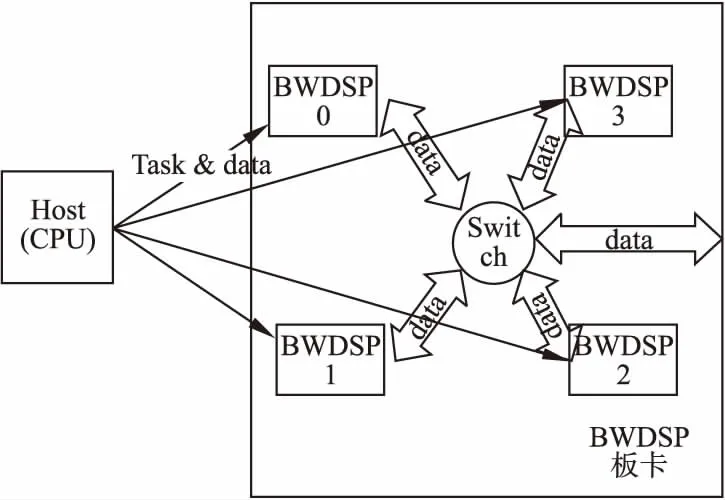
圖2 MPIRIO工作機制圖
深度學習模型中數(shù)據(jù)并行模式通常是各計算設備對數(shù)據(jù)進行處理,然后將結(jié)果返回給參數(shù)服務器,由參數(shù)服務器將更新后的參數(shù)再重新分發(fā)給各計算設備.采用MPIRIO之后可以實現(xiàn)計算設備之間相互通信,從而直接進行模型參數(shù)的交互,在計算設備上對參數(shù)進行更新,降低通信開銷.模型并行中考慮流水線實現(xiàn)方式,即各個BWDSP計算完本設備上的模型層后將結(jié)果數(shù)據(jù)保存并傳給下一個BWDSP,同時開始計算下一次的輸入數(shù)據(jù).
3.1.2 MPIRIO通信流程
根據(jù)MPI通信標準,設計如下6個MPIRIO函數(shù)(此處忽略函數(shù)相關參數(shù)介紹):
1)MPIRIO_Init():MPIRIO通信系統(tǒng)初始化;
2)MPIRIO_Finalize():MPIRIO通信系統(tǒng)銷;
3)MPIRIO_Comm_rank():獲得當前進程在通信域中標號;
4)MPIRIO_Comm_size():獲得通信域中進程數(shù);
5)MPIRIO_Send():進行消息的發(fā)送;
6)MPIRIO_Recv():進行消息的接收.
MPIRIO需要提供一些通信管理函數(shù),如判斷發(fā)送和接收結(jié)束等.MPIRIO的數(shù)據(jù)通信流程如圖3所示.發(fā)送方調(diào)用MPIRIO_Send()函數(shù)發(fā)送數(shù)據(jù)后,通過一系列的函數(shù)調(diào)用會到達BWDSP芯片提供的MRIO_send()函數(shù),該函數(shù)根據(jù)數(shù)據(jù)包中的目標ID將數(shù)據(jù)包相關信息送到接收方的expected/unexpected隊列中.接收方調(diào)用MPIRIO_Recv()函數(shù)后,經(jīng)過一些列函數(shù)調(diào)用到達BWDSP芯片提供的MRIO_recv()函數(shù),該函數(shù)會從芯片的expected/unexpected隊列中查找,相應的數(shù)據(jù)發(fā)送請求是否到達.如果需要的數(shù)據(jù)已經(jīng)到達,則將數(shù)據(jù)交付給上層應用進行相應的處理.
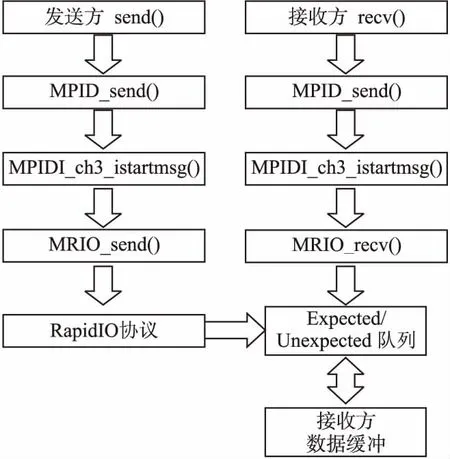
圖3 MPIRIO通信流程圖
3.1.3 MPIRIO群集通信函數(shù)
深度學習模型中存在大量計算并行性,需要MPIRIO提供優(yōu)化的broadcast,reduce和gather等群集通信功能.
MPI提供的broadcast算法采用類似二叉樹的傳播方式,不考慮進程在節(jié)點中的位置,只根據(jù)進程rank進行傳播,設共有N個進程,時間復雜度近似為O(log2N),如圖4上半部分所示.本設計中,BWDSP芯片上只能啟動一個進程進行計算,故將一個BWDSP單板卡看成一個節(jié)點,將多個BWDSP單板卡互聯(lián)構成多板卡系統(tǒng).MPIRIO的廣播算法是由發(fā)送方將數(shù)據(jù)傳到相連的switch中,由該switch采用復制分發(fā)向各個輸出端口進行轉(zhuǎn)發(fā),時間復雜度近似為O(log4N),算法示意圖如圖4下半部分所示.
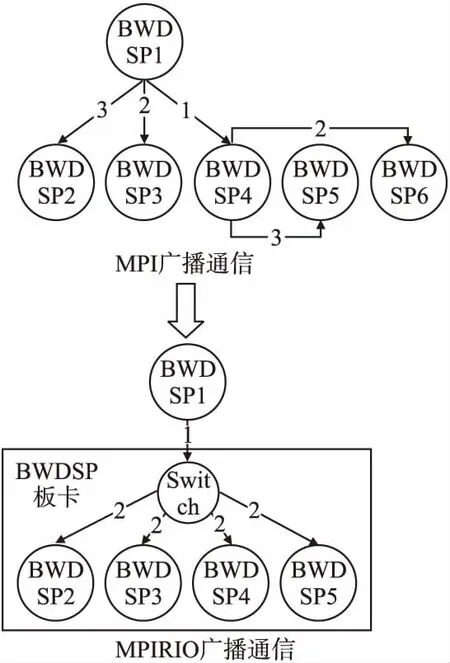
圖4 MPI和MPIRIO廣播通信示意圖
MPIRIO考慮到深度學習模型的參數(shù)更新機制,通過reduce操作可以將各計算設備得到的參數(shù)梯度值進行聚合規(guī)約.MPIRIO利用RapidIO交換模型在gather聚合過程中,將多個設備的參數(shù)梯度值封裝在一個數(shù)據(jù)包中進行傳輸,從而降低數(shù)據(jù)傳輸量,如圖4所示.MPI標準提供的gather操作數(shù)據(jù)包傳輸量大約N×log4N,而MPIRIO的數(shù)據(jù)包傳輸量大約(N-1)×4/3,時間復雜度可以參考MPIRIO的廣播算法.MPIRIO的reduce操作也可以采用類似的機制實現(xiàn).
設計全局通信域MPIRIO_COMM_WOLD和局部通信域MPIRIO_COMM_LOCAL,分別用于全局和局部的群集通信中.BWDSP虛擬平臺初始化后,形成的整個拓撲結(jié)構作為全局通信域.在初始化過程中,為每個RapidIO交換模型分配一個標識符,每個RapidIO交換模型相連的BWDSP模型組成一個局部通信域,即每個BWDSP單板卡作為一個局部通信域.
算法1描述了MPIRIO的廣播操作MPIRIO_Bcast()函數(shù)的具體實現(xiàn)過程.
算法1.MPIRIO_Bcast()函數(shù)算法
輸入:數(shù)據(jù)緩沖區(qū),數(shù)據(jù)個數(shù),發(fā)送方ID,通信域等
輸出:數(shù)據(jù)傳輸是否成功狀態(tài)
1.系統(tǒng)首先會感知整個系統(tǒng)的狀態(tài),這部分功能由MPIRIO_Init()函數(shù)實現(xiàn),獲得整個系統(tǒng)的拓撲結(jié)構.
2.if(發(fā)送方ID==通信域中rank標識位)
執(zhí)行3中MRIO_send()函數(shù),并且在調(diào)用MRIO_send()函數(shù)時提供的數(shù)據(jù)包為廣播類型數(shù)據(jù)包
else
執(zhí)行MRIO_recv()函數(shù),準備接收發(fā)送方發(fā)送的數(shù)據(jù)包
3.MRIO_send()對接收到的數(shù)據(jù)包進行解析,并調(diào)用相應的處理邏輯
if(數(shù)據(jù)包類型==單播數(shù)據(jù)包)
根據(jù)目標方ID查找路由表,并進行數(shù)據(jù)轉(zhuǎn)發(fā)
elseif(數(shù)據(jù)包類型==廣播數(shù)據(jù)包)
if(該數(shù)據(jù)包標識符之前未出現(xiàn)過)
for(循環(huán)RapidIO交換模型的每個端口)//排除輸入該信息的端口
復制該數(shù)據(jù)包并從循環(huán)到的端口轉(zhuǎn)發(fā)出去
else
不對該數(shù)據(jù)包進行處理,直接丟棄
算法2描述了MPIRIO的聚集操作MPIRIO_Gather()函數(shù)的具體實現(xiàn)過程.
算法2.MPIRIO_Gather()函數(shù)算法
輸入:發(fā)送數(shù)據(jù)緩沖區(qū),數(shù)據(jù)個數(shù),接收數(shù)據(jù)緩沖區(qū),接收方ID,通信域等
輸出:數(shù)據(jù)傳輸是否成功狀態(tài)
1.系統(tǒng)首先會感知整個系統(tǒng)的狀態(tài),這部分功能由MPIRIO_Init()函數(shù)實現(xiàn),獲得整個系統(tǒng)的拓撲結(jié)構.
2.if(發(fā)送方ID==通信域中rank標識位)
執(zhí)行MRIO_recv()函數(shù),準備接收發(fā)送方發(fā)送的數(shù)據(jù)包
else
執(zhí)行3中MRIO_send()函數(shù),并且在調(diào)用MRIO_send()函數(shù)時提供的數(shù)包為聚集類型數(shù)據(jù)包
3.MRIO_send()對接收到的數(shù)據(jù)包進行解析,并調(diào)用相應的處理邏輯
if(數(shù)據(jù)包類型==單播數(shù)據(jù)包)
根據(jù)目標方ID查找路由表,并進行數(shù)據(jù)轉(zhuǎn)發(fā)
else if(數(shù)據(jù)包類型==聚集數(shù)據(jù)包類型)
對應數(shù)據(jù)包標志位計數(shù)器gather_count++
if(gather_count==(連接設備端口數(shù)-1))
將RapidIO交換模型中緩存的數(shù)據(jù)封裝,從剩余的端口號port轉(zhuǎn)發(fā)
else
則將該數(shù)據(jù)包的數(shù)據(jù)部分放入RapidIO交換模型中緩存
3.1.4 MPIRIO同步控制
MPIRIO中需要考慮多種不同優(yōu)先級和數(shù)據(jù)長度的包進行傳輸,設計不同優(yōu)先級的數(shù)據(jù)流.規(guī)定優(yōu)先級高的數(shù)據(jù)流可以先進行數(shù)據(jù)傳輸,在優(yōu)先級相同情況下,較短的數(shù)據(jù)包先進行發(fā)送.通過優(yōu)先級傳輸方式,可以降低系統(tǒng)阻塞的概率,提高數(shù)據(jù)傳輸速率.由于RapidIO交換協(xié)議支持的數(shù)據(jù)包長度最大為276字節(jié),其中有效數(shù)據(jù)部分為250字節(jié),故上層應用發(fā)送的數(shù)據(jù)包長度過長時,BWDSP虛擬平臺的通信接口會將數(shù)據(jù)包進行拆分,分成多個具有相同標識符的RapidIO數(shù)據(jù)包進行發(fā)送.
BWDSP通信代碼庫提供通信同步的底層原語,上層利用該原語實現(xiàn)通信過程的同步控制.深度學習中的參數(shù)調(diào)整,需要先得到舊的參數(shù)值和參數(shù)更新值后,才能將舊的參數(shù)調(diào)整為新的參數(shù),并且每一批次的訓練數(shù)據(jù)在各個計算設備上的處理順序要保持一致.MPIRIO的通信同步過程需要考慮底層RapidIO交換模型提供的發(fā)送響應機制,RapidIO采用類似握手協(xié)議機制實現(xiàn)同步控制,MPIRIO在RapidIO的基礎上設計了MPIRIO_Barrier()函數(shù).MPIRIO_Barrier()函數(shù)作為MPIRIO的同步路障函數(shù),其實現(xiàn)如圖5所示.
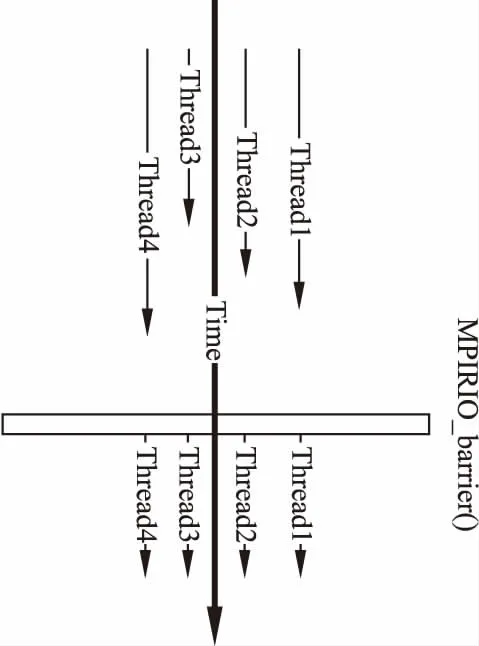
圖5 MPIRIO_Barrier實現(xiàn)示意圖
算法3描述了MPIRIO的同步路障操作MPIRIO_Barrier()函數(shù)的具體實現(xiàn)過程.
算法3.MPIRIO_Barrier()函數(shù)算法
輸入:全局通信域
輸出:函數(shù)執(zhí)行成功標志
1.系統(tǒng)首先會感知整個系統(tǒng)的狀態(tài),這部分功能由MPIRIO_Init()函數(shù)實現(xiàn),獲得整個系統(tǒng)的拓撲結(jié)構.
2.MPIRIO_Barrier()函數(shù)的內(nèi)部實現(xiàn)
各個BWDSP芯片執(zhí)行到該函數(shù)后,會將共享內(nèi)存區(qū)域的barrier_count++
if(barrier_count==全局通信域中size標識位)
該BWDSP芯片繼續(xù)執(zhí)行
通知其他因為barrier而等待的BWDSP芯片繼續(xù)執(zhí)行
else
該BWDSP芯片等待,收到其他BWDSP芯片的通知后繼續(xù)執(zhí)行
3.1.5 MPIRIO性能分析和優(yōu)化
MPIRIO需要提供基本性能分析功能,可以對系統(tǒng)中的數(shù)據(jù)傳輸量和傳輸時間等進行統(tǒng)計,估計系統(tǒng)流量的程度,并將統(tǒng)計結(jié)果返回給用戶.設計了MPIRIO_time()函數(shù),該函數(shù)通過記錄各個進程開始執(zhí)行時的時鐘周期數(shù)cl_start,系統(tǒng)統(tǒng)計時的時鐘周期數(shù)cl_end,結(jié)合系統(tǒng)時鐘頻率cl_frequence可以得出進程運行時間t_thread,其公式如公式(3)所示.同時設計了MPIRIO_traffic()函數(shù),該函數(shù)可以記錄系統(tǒng)中傳輸?shù)乃袛?shù)據(jù)包的數(shù)量pkt_number.結(jié)合MPIRIO_time()函數(shù),可以得到系統(tǒng)過去時間的平均流量程度sys_flow,如公式(4)所示,其中N代表BWDSP模型的數(shù)量,ti_thread是考慮到不同BWDSP模型的執(zhí)行時間.
(3)
(4)
考慮底層的BWDSP虛擬平臺經(jīng)過擴展互聯(lián)后,可能形成圖型拓撲結(jié)構,需要設計動態(tài)路由方案,針對數(shù)據(jù)通信進行優(yōu)化.對點對點通信進行最佳路由選擇,同時對群集通信實現(xiàn)負載均衡[14].
BWDSP虛擬平臺以RapidIO作為交換模型,采用分布式路由算法.故本文采用最小生成樹算法[15]實現(xiàn)負載均衡,該算法是在MPIRIO_Init()函數(shù)中實現(xiàn)的.MPIRIO_Init()函數(shù)首先感知整個BWDSP虛擬平臺系統(tǒng)的拓撲結(jié)構,然后根據(jù)拓撲結(jié)構信息采用Prim算法獲得最小生成樹結(jié)構,并相應的修改虛擬平臺中RapidIO交換模型路由表信息.圖6上半部分是BWDSP平臺原來的拓撲結(jié)構,圖6下半部分是最小生成樹算法生成的拓撲結(jié)構.
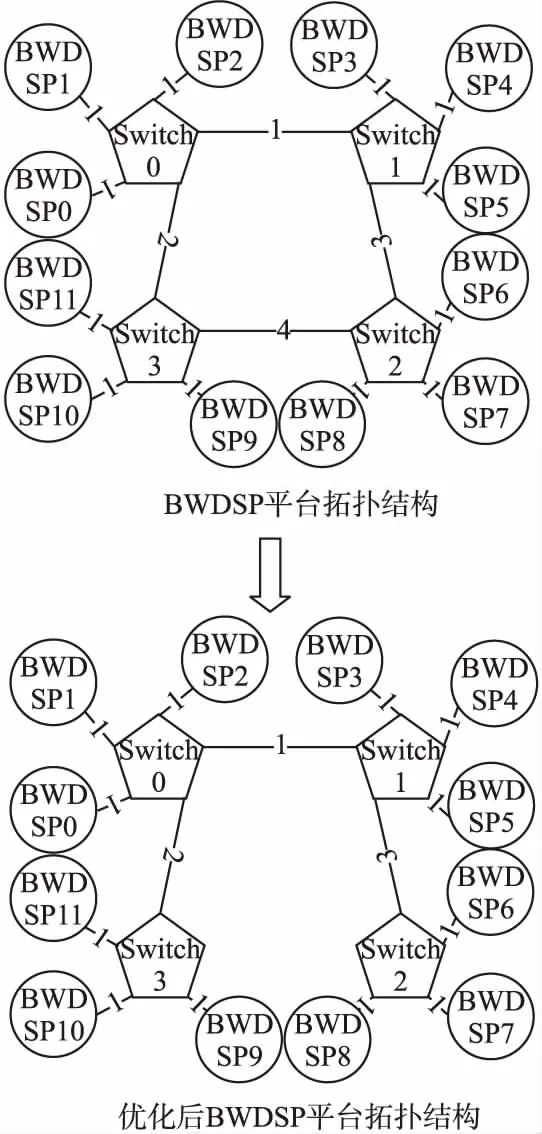
圖6 BWDSP平臺優(yōu)化前后拓撲結(jié)構
3.2 MPIRIO卷積運算分析
MPIRIO并行計算通信庫除了用于常規(guī)的并行計算任務,如矩陣乘法,蝶形求和等基本算法,還應該為深度學習應用服務,使深度學習應用在BWDSP虛擬平臺上的部署成為可能.BWDSP平臺本身提供了深度學習算子庫bwdnn,包括卷積算子、池化算子和softmax算子等.
由于深度學習模型通常較大,難以部署在單個BWDSP芯片上,通常需要部署在多個BWDSP芯片構成的BWDSP平臺上.MPIRIO使各個BWDSP上的深度學習模型層與層之間更好的通信,包括前向傳播時中間結(jié)果的傳遞和反向傳播時梯度和損失信息的傳遞.
神經(jīng)網(wǎng)絡中卷積運算[16]的本質(zhì)是乘加運算,包括一維卷積運算、二維卷積運算和三維卷積運算.以二維卷積為例進行分析,由于輸入數(shù)據(jù)與卷積核通道數(shù)一樣,所以二維卷積運算輸出數(shù)據(jù)是二維矩陣.卷積運算填充方式為“VALID”,則輸出數(shù)據(jù)維度OH和OW滿足公式(5),卷積運算相關參數(shù)介紹如下:
1)IH:輸入數(shù)據(jù)高度;
2)IW:輸入數(shù)據(jù)寬度;
3)CI:輸入數(shù)據(jù)/卷積核通道數(shù);
4)OH:輸出數(shù)據(jù)高度;
5)OW:輸出數(shù)據(jù)寬度;
6)KH:卷積核高度;
7)KW:卷積核寬度;
8)SH:卷積步長高度;
9)SW:卷積步長寬度.
(5)
BWDSP進行卷積運算優(yōu)化時,采用im2col[17]方式實現(xiàn).即將卷積運算的輸入數(shù)據(jù)和卷積核分別轉(zhuǎn)化為二維矩陣和一維矩陣,再進行矩陣相乘.BWDSP芯片內(nèi)部有16個乘加器,可以同時進行16個乘加運算.進行數(shù)據(jù)劃分時,將輸入矩陣以16個滑動窗口數(shù)據(jù)為一組分配給BWDSP模型,充分利用BWDSP和MPIRIO提供的并行化能力.
4 實驗及評估
實驗過程是通過在不同BWDSP虛擬平臺拓撲結(jié)構下,對MPIRIO的點對點通信函數(shù)和群集通信函數(shù)功能進行測試.使用MPIRIO對常規(guī)并行計算任務,如矩陣乘法和蝶形求和算法進行測試,同時對深度學習中常見的卷積運算進行測試.最后將MPIRIO與MPICH實現(xiàn)的通信功能進行對比,主要是從數(shù)據(jù)傳輸和時間進行分析,并與已有工作進行對比分析.
4.1 MPIRIO基本性能實驗
在不同BWDSP虛擬平臺拓撲結(jié)構下,測試了MPIRIO設計的點對點通信函數(shù)MPIRIO_Send()和MPIRIO_Recv()函數(shù),群集通信函數(shù)MPIRIO_Bcast()、MPIRIO_Reduce()、MPIRIO_Gather()和MPIRIO_Scatter()函數(shù)的數(shù)據(jù)傳輸性能和實現(xiàn)原理.如表1所示是在8個和16個BWDSP模型下數(shù)據(jù)傳輸測試結(jié)果,其中數(shù)據(jù)量單位是字節(jié),時間單位是微秒.由于每個BWDSP上只能執(zhí)行一個進程,故MPIRIO的測試中進程意義等于BWDSP模型.
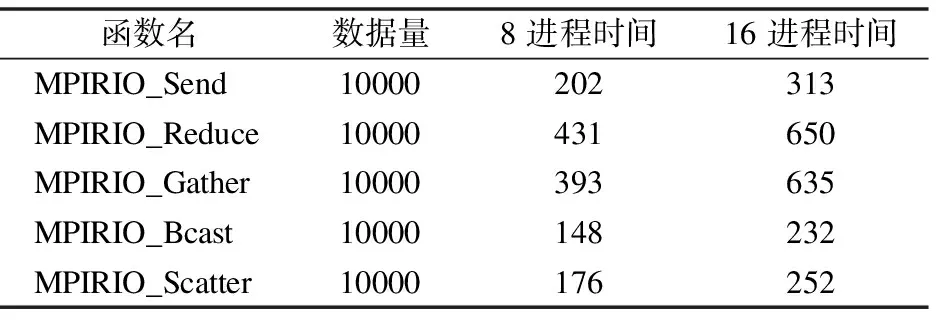
表1 MPIRIO在8和16進程數(shù)據(jù)傳輸測試
從表1中可以看出,數(shù)據(jù)傳輸時間受系統(tǒng)拓撲結(jié)構影響,系統(tǒng)拓撲結(jié)構越大越復雜,則數(shù)據(jù)傳輸時間越長.以基本的點對點通信分析,在8個進程控制的情況下,數(shù)據(jù)傳輸量10K左右的情況需要時間202微秒.在16個進程控制的情況下,傳遞相同數(shù)據(jù)量需要時間313微秒,這是因為系統(tǒng)拓撲結(jié)構變得復雜,數(shù)據(jù)在通信時需要經(jīng)過更多的RapidIO交換模型.在相同數(shù)據(jù)傳輸量的情況下,規(guī)約操作需要的時間最長,這是因為MPIRIO可以在RapidIO交換模型中對數(shù)據(jù)進行規(guī)約操作,此部分時間被考慮在數(shù)據(jù)傳輸時間中.其次是聚集操作,在RapidIO交換模型中會對數(shù)據(jù)包進行封裝消耗部分時間,從而減少數(shù)據(jù)包的傳輸量.廣播操作則是在RapidIO交換模型處對數(shù)據(jù)包進行復制轉(zhuǎn)發(fā),在一定程度上會降低數(shù)據(jù)通信時間.
對MPIRIO的路障函數(shù)和性能統(tǒng)計等函數(shù)進行了測試,都可以正確實現(xiàn)功能,實現(xiàn)各BWDSP模型的協(xié)同工作.
4.2 MPIRIO常規(guī)計算任務實驗
常規(guī)并行計算任務有矩陣乘法和蝶形求和算法等,對MPIRIO實現(xiàn)常規(guī)并行計算任務進行實驗和分析.對于矩陣乘法,我們采用不同方法進行測試,包括基本分片乘法和類Fox乘法實驗(基本分片乘法用1表示,類Fox乘法用2表示).測試結(jié)果均正確,表明MPIRIO可以正常實現(xiàn)矩陣乘法,MPIRIO矩陣乘法實驗結(jié)果如表2所示,是在8個進程下進行測試,時間單位是微秒.
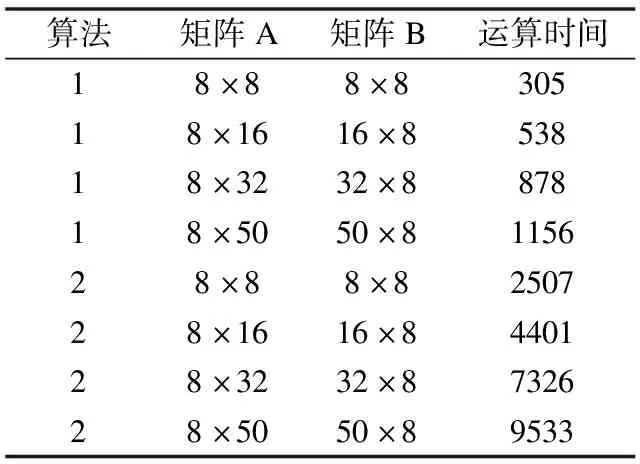
表2 MPIRIO在8進程矩陣乘法時間
矩陣A和矩陣B進行矩陣基本分片乘法,各個BWDSP模型上擁有矩陣B的所有數(shù)據(jù).BWDSP0號模型擁有矩陣A的數(shù)據(jù),將矩陣A按照BWDSP模型數(shù)分成8份,通過MPIRIO_Scatter()函數(shù)進行散射.各個BWDSP模型接收到A的分塊數(shù)據(jù)后,跟矩陣B進行相乘,分別得到部分矩陣相乘結(jié)果.然后由BWDSP0模型執(zhí)行規(guī)約算法,獲得各個BWDSP模型上的部分矩陣相乘結(jié)果,最后BWDSP0模型上擁有整個矩陣相乘結(jié)果.設矩陣A數(shù)據(jù)為m×n,矩陣B的數(shù)據(jù)為n×m,數(shù)據(jù)傳播速率為s,BWDSP模型計算能力為c,讀寫數(shù)據(jù)帶寬b,則基本分片乘法時間t_s如公式(6)所示.
(6)
矩陣A和矩陣B進行矩陣類Fox乘法,BWDSP0模型擁有矩陣A和矩陣B的數(shù)據(jù),通過MPIRIO_Scatter算法將矩陣A按行和矩陣B按列分片發(fā)往各個BWDSP模型.各個BWDSP模型完成部分矩陣運算后,將自身的矩陣B分片向下一進程發(fā)送,得到新的矩陣B分片與自身的矩陣A分片進行運算.當每個BWDSP模型完成A分片和所有B分片的運算后,BWDSP0模型執(zhí)行規(guī)約算法獲得整個矩陣相乘結(jié)果,其時間t_c如公式(7)所示.
(7)
從表2可以看出,當矩陣乘法數(shù)據(jù)在8×8矩陣到8×50矩陣規(guī)模時,時間處于增加狀態(tài).由于進程啟動等開銷,以及數(shù)據(jù)傳輸過程中對緩存資源的占用開銷等,使得矩陣乘法時間并不是按倍數(shù)進行增加.同時可以看出矩陣乘法2相比較矩陣乘法1,時間消耗明顯增加了,這是由于采用了時間換空間的思想,增加了不同BWDSP模型之間數(shù)據(jù)傳輸開銷.
蝶形求和算法是一種求解全局和的算法,在MPI并行編程中,是一個基本測試用例.MPIRIO中可由用戶編寫算法實現(xiàn)蝶形求和,還可以使用MPIRIO_Reduce()函數(shù)中MPIRIO_SUM實現(xiàn)類似全局求和功能.分別測試兩種算法的時間開銷(自編寫算法用1表示,MPIRIO_Reduce實現(xiàn)用2表示),測試結(jié)果如表3所示,數(shù)據(jù)量單位是字節(jié),時間單位是微秒.設BWDSP模型數(shù)為N,則MPIRIO_Reduce()算法的時間復雜度約為O(log2N).實驗結(jié)果表明,采用Reduce規(guī)約算法實現(xiàn)蝶形求和算法優(yōu)于自編寫算法,因為自編寫算法需要通過多次點對點通信實現(xiàn),并且需要更復雜的同步控制.規(guī)約算法在RapidIO交換模型中對數(shù)據(jù)進行規(guī)約處理,減少了數(shù)據(jù)包的傳輸.
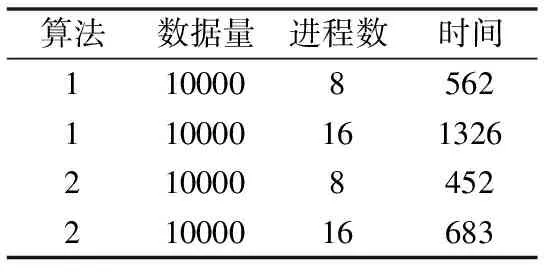
表3 MPIRIO蝶形求和
4.3 MPIRIO卷積運算實驗
MPIRIO的設計目標之一,是為深度學習模型在BWDSP平臺上的部署服務.神經(jīng)網(wǎng)絡中主要的卷積算法,可以使用MPIRIO在BWDSP平臺上運行.針對卷積算法,使用im2col方法進行優(yōu)化,將輸入數(shù)據(jù)和卷積核都轉(zhuǎn)化為矩陣形式,然后結(jié)合矩陣相乘算法進行實現(xiàn).
卷積運算測試結(jié)果如表4所示,其中卷積運算輸入數(shù)據(jù)填充方式統(tǒng)一為“VALID”,步長為1,時間單位為微秒.測試是在8個BWDSP模型下進行,并將卷積運算數(shù)據(jù)平均分配給各BWDSP模型.
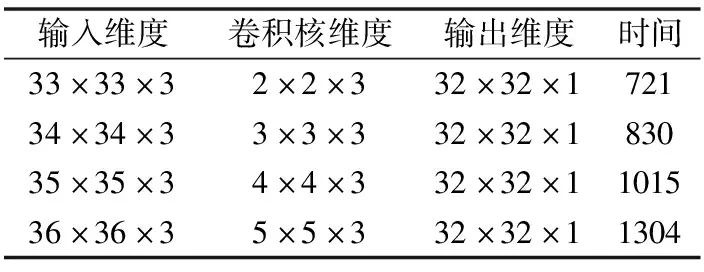
表4 MPIRIO卷積運算測試
以表4中第4條數(shù)據(jù)分析,其輸入數(shù)據(jù)維度為36×36×3,卷積核維度為5×5×3,數(shù)據(jù)填充方式.根據(jù)公式(5)知輸出數(shù)據(jù)應該為32×32×1維,與表格中輸出數(shù)據(jù)維度一致,表明通過MPIRIO可以編程實現(xiàn)卷積運算.MPIRIO將表4中第4條卷積運算數(shù)據(jù),轉(zhuǎn)化為16×75與75×1的矩陣相乘,并使用基本分片乘法測試得到時間,故用MPIRIO設計卷積運算類似于設計矩陣乘法.
4.4 MPIRIO與MPICH對比實驗
MPICH2作為主流的并行編程庫,與其進行對比具有重要意義.硬件環(huán)境為Intel Core i5-2400 CPU @ 3.10GHz,操作系統(tǒng)為ubuntu 16.04 LTS,內(nèi)存8GB,配置并行編程庫MPICH2,設為環(huán)境1;Intel Core i7-6700HQ CPU @ 2.60GHz,操作系統(tǒng)windows10,內(nèi)存8GB,軟件環(huán)境為Visual Studio 2017,配置并行編程庫MPICH2,設為環(huán)境2.測試MPICH2的點對點通信函數(shù)和群集通信函數(shù)性能,并與MPIRIO的通信函數(shù)進行對比,測試結(jié)果如表5所示,其中數(shù)據(jù)量單位為字節(jié),時間單位為微秒.
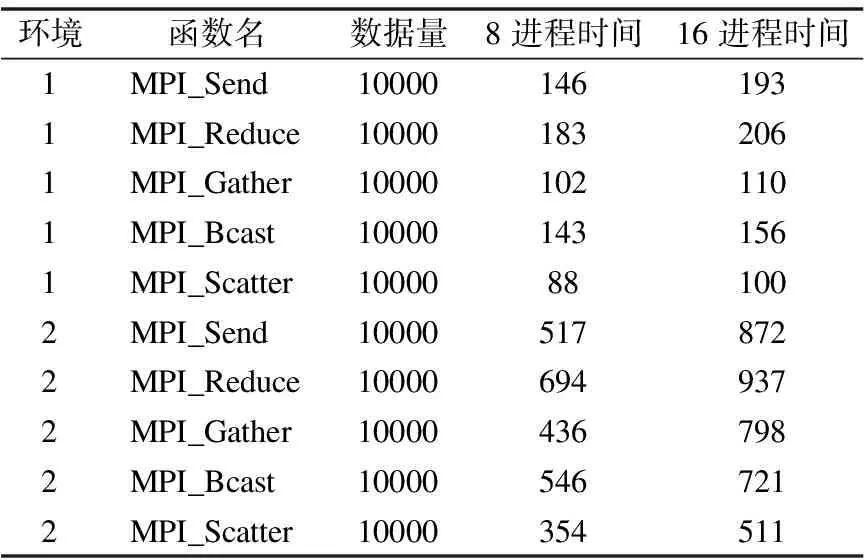
表5 MPICH2通信函數(shù)測試
為了正確對比,表1和表5中時間都是在系統(tǒng)頻率為1MHz下的測試結(jié)果.環(huán)境1中MPICH2通信時間普遍比MPIRIO的時間短,這是因為MPICH2是在單機上進行測試,而MPIRIO是分布式的BWDSP虛擬平臺上進行測試,數(shù)據(jù)通過RapidIO交換模型時需要時間,從而會使得數(shù)據(jù)通信時間略長.可以發(fā)現(xiàn)MPICH2中點對點通信在8進程和16進程時間差距較大,因為點對點通信采取阻塞通信方式,故循環(huán)向其他進程發(fā)送消息需要較長時間,隨著進程數(shù)的增加通信時間相應增加.
環(huán)境2中各函數(shù)通信時間相比MPIRIO和環(huán)境1是最多的,主要是因為本實驗選型i5CPU是4核心,而i7CPU核心數(shù)是2核心,在一定程度上i5并發(fā)性高于i7.另一方面是因為ubunt系統(tǒng)下直接采用MPICXX進行編譯,優(yōu)于windows下visual studio編譯MPI程序.由于上述等因素,MPIRIO的通信時間也比環(huán)境2的通信時間低.
修改MPICH2源碼,在其通信函數(shù)中對發(fā)送和接收數(shù)據(jù)包數(shù)量進行統(tǒng)計.通過MPICH2群集通信數(shù)據(jù)包數(shù)量統(tǒng)計,對比MPIRIO的群集通信函數(shù)數(shù)據(jù)包數(shù)量,表明MPIRIO群集通信函數(shù)進行了優(yōu)化.MPICH2和MPIRIO的群集通信數(shù)據(jù)包數(shù)量統(tǒng)計情況,如表6所示,數(shù)據(jù)量單位是字節(jié).
表6中的數(shù)據(jù)包數(shù)量是各個進程發(fā)送和接收的數(shù)據(jù)包數(shù)量之和,在相同的8進程數(shù)情況下,MPIRIO的群集通信數(shù)據(jù)包數(shù)量比MPICH2少,這是因為MPIRIO的群集通信操作進行了優(yōu)化.由于采用不同CPU進行測試,發(fā)送的數(shù)據(jù)包的數(shù)量是一樣的,故該測試不區(qū)分環(huán)境1和環(huán)境2.MPIRIO群集通信接口的實現(xiàn)在MPI的基礎上進行了修改,并擴展了RapidIO交換模型的功能,使其可以適應MPIRIO設計的廣播、聚集和規(guī)約等算法的需求.
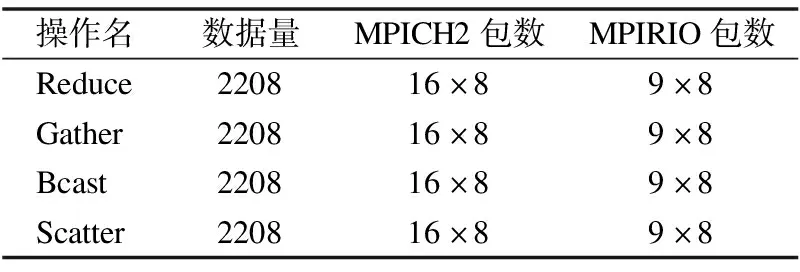
表6 MPICH2和MPIRIO群集通信數(shù)據(jù)包數(shù)量
4.5 實驗總結(jié)
綜合上述實驗結(jié)果和分析,基于 BWDSP虛擬平臺的并行計算通信庫MPIRIO,符合MPI標準規(guī)范,可以實現(xiàn)BWDSP芯片之間的點對點通信和群集通信,并對群集通信函數(shù)進行了優(yōu)化.MPIRIO可以用于常規(guī)并行計算任務,結(jié)合BWDSP體系結(jié)構特點對卷積運算進行了優(yōu)化.最后通過與MPICH的對比實驗,表明本文設計的MPIRIO群集通信優(yōu)化算法可以正常工作.
本文研究與文獻[3]的研究存在相應聯(lián)系,但也具有差異性.兩者都是基于單核BWDSP芯片構成的多核平臺展開研究,同時考慮了深度學習在平臺上的部署運行問題.但是本文工作是以未來實際生產(chǎn)的單板卡和多板卡為原型,設計相應的并行通信接口,方便用戶對常規(guī)并行任務的處理,再此基礎上分析深度學習中卷積運算并行性特點,并對其進行支持.而文獻[3]則是以多個DSP直接相連作為平臺原型,并且在此基礎上研究流水線,三緩沖區(qū)等技術,加速深度學習運行.
5 總 結(jié)
本文在BWDSP虛擬平臺的基礎上,借鑒了已有的MPI標準,設計了并行計算通信庫MPIRIO.MPIRIO是以RapidIO交換模型作為通信協(xié)議,并在RapidIO握手協(xié)議機制的基礎上實現(xiàn)了通信的同步控制.在MPICH提供的通信函數(shù)接口基礎上,本文設計了優(yōu)化的群集通信函數(shù),主要目標是減少通信中數(shù)據(jù)包的傳輸量.同時在復雜系統(tǒng)拓撲結(jié)構下,采用最小生成樹算法獲得最優(yōu)拓撲結(jié)構,使系統(tǒng)平均傳輸性能較好.本文提供的MPIRIO通信接口,通過將BWDSP,RapidIO和MPI三者相結(jié)合,相比BWDSP虛擬平臺提供的基本通信原語,提升了用戶編程并部署任務在虛擬平臺上的方便性和靈活性,同時提高了整個系統(tǒng)的運行效率.
本文通過實驗和對比實驗,證明了MPIRIO的可用性,并分析了MPIRIO相比MPI標準所做出的部分優(yōu)化.在未來的工作中,進一步完善并行通信庫MPIRIO,提供更多的MPI規(guī)范標準接口,如向量化的通信接口.設計更加優(yōu)化的路由選擇和數(shù)據(jù)調(diào)度算法,并提升MPIRIO的可移植性,使其可以適應新的硬件平臺.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
