相似性與置信系數為基礎的推薦系統評分預測
2021-05-10 07:14:50王佳偉沈昱明
小型微型計算機系統 2021年5期
蘇 湛,王佳偉,艾 均,沈昱明
(上海理工大學 光電信息與計算機工程學院,上海 200093)
1 引 言
用戶在互聯網上尋找合適內容的時候,往往會遇到海量的信息和物品,像是電影、書籍、商品等等.為了解決這類問題,推薦算法經常使用不同類型模型進行推薦系統中的評分預測或鏈路預測(將評分考慮成邊連接,分值考慮成邊權重)進行預測,然后預測權重或評分最高的物品推薦給用戶.在此基礎上,可以節省用戶搜索物品所花費的時間.鏈路預測(包括評分預測)方法通常分為基于內容的算法[1]和協同過濾算法[2,3].
現實推薦系統中的評分預測通常結合基于內容的方法和協同過濾算法,以達到最佳的預測準確度.前者是充分利用用戶的個人數據、物品內容、物品特征,根據用戶以前喜歡的內容推薦對象[4].后者通過使用目標用戶的歷史評分生成推薦.
一般來說,推薦算法[5]通常分為3類,包括基于用戶的算法[6]、基于物品的方法[7]和基于模型的方法[8].基于用戶的算法在興趣愛好或評分方面找出與目標用戶相似的鄰居,然后選擇相似鄰居喜歡的物品,并將其推薦給目標用戶[9].
相比之下,基于物品的算法會找出目標用戶喜歡的物品,找出與其相似的物品,然后過濾掉相似度低的物品,并向目標用戶推薦相似的物品[10].此外,基于模型的算法首先基于歷史數據構建模型,并使用該模型進行預測[11].
在這個過程中,相似鄰居的選擇有著重要的影響.許多學者對這一課題做了大量的研究.Ma等人提出了一種基于奇異值分解(SVD)符號的聚類方法來收集用戶評分以外的社會信任信息,有效地解決了冷啟動問題[12].Nikolaos Polatidi 等提出了一種基于協同過濾算法的多層次方法,通過共同評分的物品的數量,劃分為不同的計算方法,更細膩地計算用戶之間的相似性[13].徐毅等提出一種新的基于概率矩陣分解的推薦算法,運用信任關系與相似度獲取用戶之間的加權關系,從而提出一種融合用戶信任度與相似度的推薦算法[14].
Liu等提出了一種新的節點相似度計算模型,即共同影響集.所提出的鏈路預測算法使用兩個不相連節點的共同影響集來計算兩個節點之間的相似度得分[15].尹永超等通過節點與其對應節點的鄰居節點的結構相似度來計算節點對之間的連接概率,從而預測兩個節點之間產生連接的可能性[16].
另一方面,由于物品和用戶之間的復雜性,推薦系統通常被建模為復雜網絡[17-19]模型.因此,人們通過網絡科學進行了各種各樣的探索以完成預測和推薦[20,21].以用戶和物品為節點,以用戶和物品之間的評分為邊,利用復雜網絡中的中心性、社團發現[22]等方法,對推薦系統進行建模和分析,并基于此對用戶評分進行預測.
除了推薦系統之外,鏈路預測可以應用于更多相關領域.例如,研究人員可以使用鏈路預測算法向社交網絡中的個人推薦潛在朋友.在生物網絡中,鏈接預測算法可用于發現蛋白質之間缺失的連接,以防止高成本的實驗[23].在這些預測過程中,預測的不單單是評分,而是節點間是否存在邊.
通過對用戶或物品的復雜網絡進行建模,結果表明,該方法可以提高鏈路預測或評分預測的準確度,避免某類型的冷啟動問題.例如,Ai和Su等人提出了一種基于空間分布模型的鏈路預測方法[20],基于物品共享標簽相似度避免了物品冷啟動問題.在這類方法中,還可以利用用戶節點的屬性和用戶評分的行為對復雜網絡進行建模,并基于多因素社區檢測預測鏈路及其權重[24].作者認為,通過建立復雜網絡模型和社區檢測可以提高推薦系統預測的準確度.
另一方面,該領域中一些研究揭示了聚類也是一種有效的預測輔助方法.V.Subramaniyaswamy提出了一個基于語義的上下文挖掘推薦框架.在用戶聚類過程中,采用自適應k近鄰(AKNN)算法,通過選擇合適屬性提高預測準確度[25].除此以外,該文作者認為該方法能有效地解決了系統的可擴展性、稀疏性和冷啟動問題.
一般的聚類方法比如kNN都是以一種指標作為聚類的指標,這樣就受到單一指標的局限性,并且如果為每一用戶進行聚類就需要花費大量的時間.
在現有的大多數工作中,用戶之間的相似性是選擇鄰居的關鍵.領域內現有方法大多基于相似性選最高值選擇k個鄰居或kNN對鄰居相似性進行聚類,選擇其中的部分鄰居是常見的方法.然而,該類型算法往往所需較多的鄰居才能到達評分預測準確度的最優值,在大規模的推薦系統中,更多鄰居意味著系統計算時間大增.同時,基于單一因素選擇鄰居必然存在一定誤差,從而影響評分預測準確性的進一步提升.
本文的主要科學問題和貢獻是針對目標節點與潛在鄰居間的相似性和置信系數兩個因素對其鄰居進行聚類,從而為目標用戶找到更加有效的鄰居進行推薦系統評分預測.并通過研究復雜網絡模型中的不同聚類和社團檢測算法對評分預測過程中鄰居選擇的影響,研究了如何對鄰居聚類的有效方法進行進一步的簡化,以降低計算復雜度.本文的研究表明,在鄰居選擇中考慮相似度和置信度系數的情況下,最優評分預測準確性需要的鄰居數量減少60%,并且最優預測準確性在鄰居數量更少的情況下,準確性也得到提高.
2 算法設計
2.1 推薦系統定義與評分預測算法步驟
在本文研究的方法中,有m個用戶和n個物品,它們分別構成了兩個集合:用戶集合U={u1,u2,…,um}和物品集合O={o1,o2,…,on},每個用戶對其使用過的物品評分組成矩陣R={riα}∈Rm,n,其中riα表示用戶i對物品α的評分值,評分范圍在[1,5]之間取整數.為了方便知道某位用戶是否對某件物品進行評分,設立矩陣A={aiα}∈Rm,n,aiα若為1表示用戶i評價過物品α,為0則表示用戶i沒有評價過物品α.根據上面的信息構建一個用戶-物品網絡,ki和kα分別表示用戶節點和物品節點的度值.
在上述推薦系統中,本文算法包含的主要流程如圖1所示.
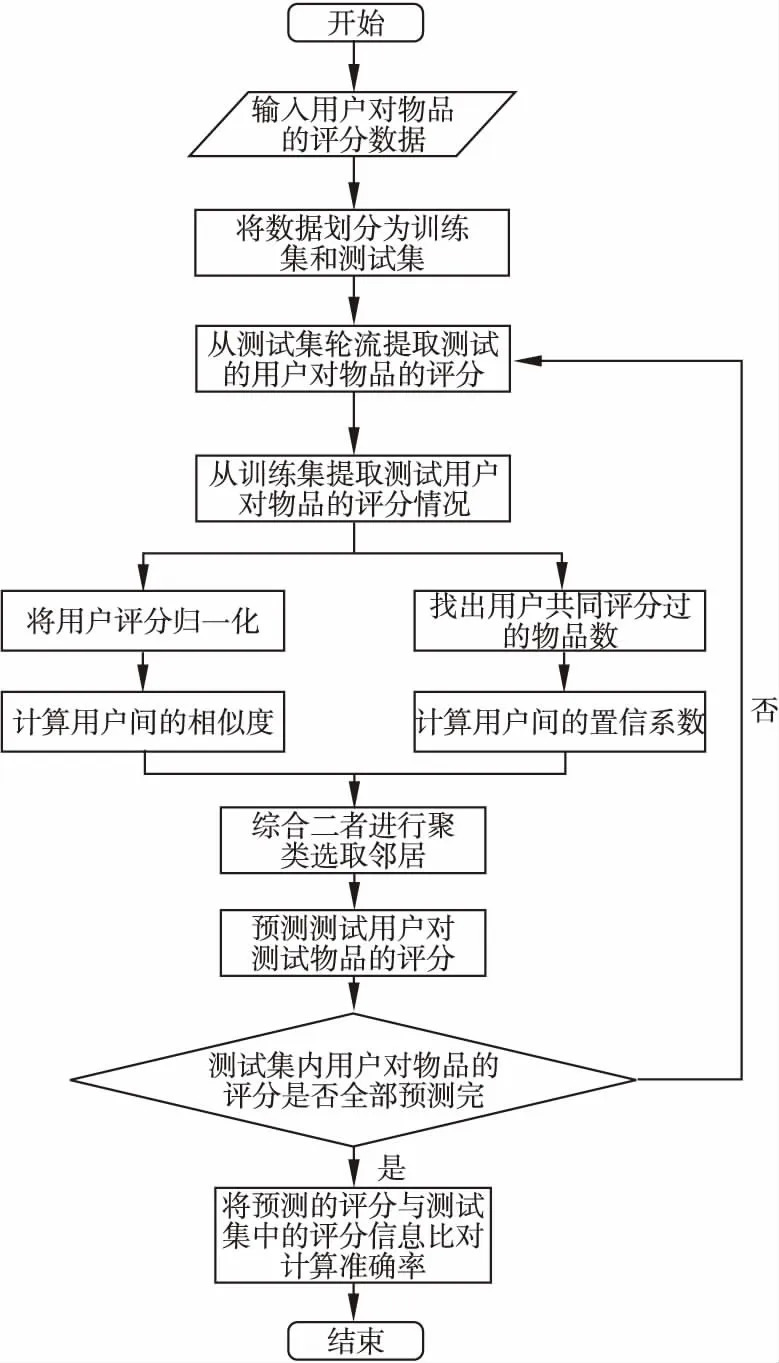
圖1 推薦系統評分預測流程圖
針對每個劃分好的數據集,算法和核心步驟包括:1)從訓練集中提取用戶對物品的評分,然后進行歸一化;2)基于歸一化數據計算用戶之間相似性與相似性的對應置信系數;3)基于相似性和置信系數結果對用戶進行聚類;4)選擇相似性和置信系數都較大的用戶社團作為鄰居;5)基于鄰居預測目標用戶對某物品的評分.
通過對給定集合中用戶對物品的評分進行預測,算法對測試集中評分預測的結果可以用來度量算法預測結果誤差,誤差越小,算法性能越好.在實際系統中,對目標用戶未評分的物品集合進行評分預測,再將預測評分最高的若干項物品推薦給該目標用戶,就完成了推薦系統的推薦任務.
該算法中的步驟3)與步驟4)是其核心,與以往算法單獨依據相似性進行鄰居選擇不同,本文算法應用相似度和置信系數兩個參數進行鄰居的選擇研究.
基于相似度和置信系數,本文通過聚類方法對目標用戶的潛在鄰居進行分類,選出相似性核置信系數均較高的那一組用戶作為鄰居.隨后對鄰居聚類方法進行了進一步改進研究,以找出聚類效果最佳且時間復雜度較低的方法.最后在MovieLens數據集上對設計的多種方法進行了驗證.
2.2 相似度和置信系數的定義
2.2.1 評分的歸一化
相似度計算需要用戶對物品的評分.但不同的用戶可能對同一商品有不同的評分習慣.例如,一些用戶有更高的要求,他們通常只會給出較低的評分.而另一些用戶更隨和一些,他們往往會給予更高的評分.為了減少來自用戶的偏差,從[26]中采用了歸一化的評分公式.
(1)
2.2.2 用戶間相似度
本文中所用的相似性計算公式是李林志提出的基于傳播的相似性公式[27]:
(2)
該相似性計算公式中ki表示用戶的度,kα表示物品的度.歸一化后用戶i和用戶j對共同評價過的電影α的評分越相近,共同評分過的電影越多,用戶i和用戶j越相似.例如有用戶i,j,k3人,他們對電影的評分記錄中最高分都為5分,最低分都為1分.他們對某部電影α的評分為3、3、5分.如果從這一條數據預測用戶i對這部電影α的評分,通過公式(1)可以計算出歸一化后的值為:eiα=0,ejα=0,ekα=1.通過公式(2)的計算結果可以看出用戶j對用戶i的影響為1,用戶k對用戶i的影響為0,用戶j對這部電影的評分比用戶k的評分更可靠一點.從公式的計算結果看出這符合用戶評分的含義.
在原來相似度公式的基礎上結合置信度系數f(n)得到新的相似度:
(3)
2.2.3 用戶間置信系數
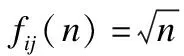
2.3 基于相似性與置信系數雙因素鄰居選擇的評分預測
2.3.1 基于K-Means的雙因素鄰居聚類選擇算法
其次考慮使用K-Means聚類來選取鄰居.K-Means聚類是一種常用的“無監督學習”的算法,其目的是將n個觀測值分成k個聚類,其中每個觀測值都屬于最近均值聚類.在其中一個集群中假設可信鄰居用戶,因為他們的相似性和信任系數應該相對高于其他鄰居.
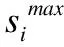
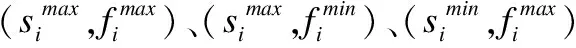
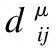
(4)
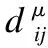
如圖2所示Kmeans-2聚類結束后,樣本集Xi會分成兩個簇C1和C2,簇的質心分別為μ1和μ2,質心為μ2的簇C2相似度和置信系數較大,本文中選取C2內的數據作為評分預測鄰居選擇的范圍.圖2是以用戶1為對象進行聚類后的鄰居分布情況,圓形淺色節點為C2中的節點,菱形深色節點為C1的節點.圖3是以用戶1為對象進行聚類后的網絡局部圖,深色節點屬于C2,淺色節點屬于C1.
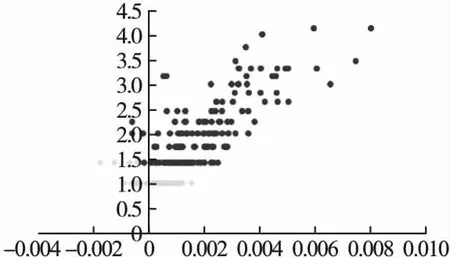
圖2 以用戶1為參照點進行K-Means聚類分布圖
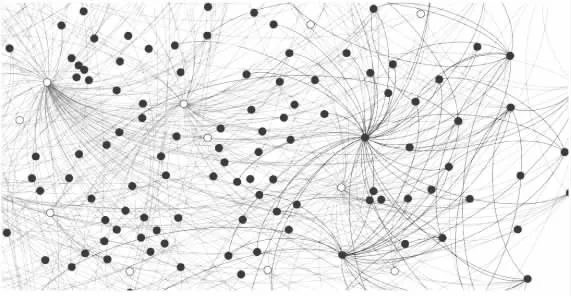
圖3 以用戶1為參照點進行K-Means聚類后的網絡局部圖
Kmeans-2聚類后C2內是否有充足的鄰居這是一個重要的問題,文中將樣本集Xi每次C2內的數據點數進行統計,依據數據點數出現的次數.可以從圖4中看出聚類后C2內至少有42個鄰居,因此Kmeans-2聚類后C2內有足夠的鄰居用來進行預測.
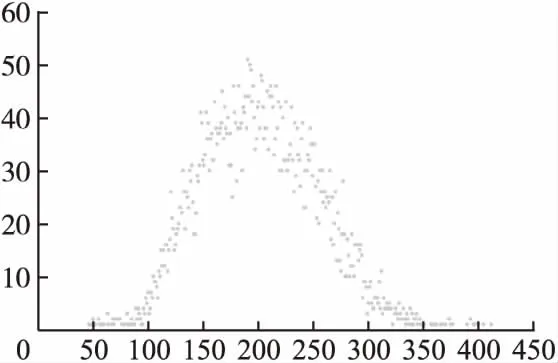
圖4 針對各用戶聚類后C2內鄰居數分布點圖
2.3.2 針對K-Means鄰居聚類方法的改進研究
在對用戶i進行聚類之后,C1中仍然有兩種類型的鄰居.本文稱C1中相似度和置信系數較小的鄰域為次要鄰居.相比之下,其他C1鄰居根據其與目標用戶更高的相似度和置信度被稱為主要鄰居.換句話說,C1被分為兩個子組.
為了詳細分析兩類鄰居對預測結果的影響,進一步提高預測準確度,提出了基于Kmeans-2算法的主次鄰居平衡方法.
2.3.3 降低聚類算法的時間復雜度
由于在上述的聚類過程中,每個用戶都需要進行K-Means聚類,因此該算法比其他算法需要更多的時間來完成.為了減少時間消耗,本文提出了如下改進算法.
由于每個用戶必須都需要重新進行聚類,因此K-Means聚類必須重復多次.降低復雜性的一種方法是在圖2中為一組鄰居設置閾值.任何相似度大于相似度閾值且置信系數大于置信系數閾值的鄰居都被歸為C1.該方法是對潛在鄰居進行無迭代聚類,在實驗部分稱為簡單聚類.在本文的工作中,本文選擇了閾值來保持最大的40%和30%的相似性和置信系數.所以C1的鄰居數與其他方法大致相同.
此外,如果本文把所有的目標用戶和他們的鄰居放在一起考慮,計算復雜度會大大降低.因此提出了一種基于整體的聚類方法.所有用戶的所有鄰居都放置在一個二維空間中,僅僅一次聚類就確定C1和C2.此方法在實驗部分標記為All-Kmeans.
2.3.4 目標用戶對物品的評分預測
通過相似度計算,通過公式(5)可以得到目標用戶和目標物品之間的預測評分.值得注意的是,相似性是由公式(3)的方法給出的.
(5)
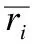
此外,在上面公式的基礎上還可以進一步考慮1級和2級鄰居,為此提出了公式(6):
(6)
其中n1是用戶i鄰居中主要鄰居的數量,n2是用戶i鄰居中次要鄰居的數量,W1和W2是設定的權值,它們之和為1.
3 實驗和結果分析
3.1 數據集和預測準確性度量
為了驗證本文提出的方法的有效性,本文利用MovieLens的數據進行了實驗.該數據集包含671個用戶、9125部電影和100004個用戶的電影評分記錄.用戶的評分從1-5不等.此外,數據集被隨機分成10組,并使用折10交叉驗證,以確保結果在統計學上是可靠的[29].最終結果是10倍交叉驗證中所有實驗的平均值.本文從1,3,5,10,20,30,…,140-150中選擇參考鄰居的數量.
為了進行預測準確度的比較,文中引用了現有文獻中基于用戶的UOS和Pearson-RF方法.UOS方法是2017年發布的推薦系統中的鏈路預測方法.該方法將觀點傳播原理引入到鏈路預測中,考慮用戶的評分習慣,根據用戶的共享評分計算用戶的相似度.Pearson-RF方法是一種改進的Pearson協作過濾算法[28],于2019年發表.近幾年的方法僅僅考慮了相似性和置信系數作為預測的重要因素,而沒有對潛在鄰居進行聚類.因為UOS在2018的文獻[30]中與領域內的各種新方法進行了橫向比較,故可以作為參照,從理論上進一步推斷本文算法的性能.
為了檢驗這些算法的有效性,本文使用了平均絕對誤差(MAE)[31]和均方根誤差(RMSE)[28].通過比較算法給出的實際評分和預測評分,發現MAE和RMSE越小,算法的效率越高.由于RMSE對預測誤差進行平方處理,因此會對誤差進行更嚴厲的懲罰.
(7)
(8)
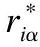
3.2 結果和分析
如圖5所示,本文所有提出的方法,包括Kmeans-2、Kmeans0、Kmeans-2-30、All-Kmeans和Simple-clustering,都只需要非常少的鄰居作為參考,就可以得到準確的預測結果.而Pearson-RF在預測中比UOS[29]更準確.
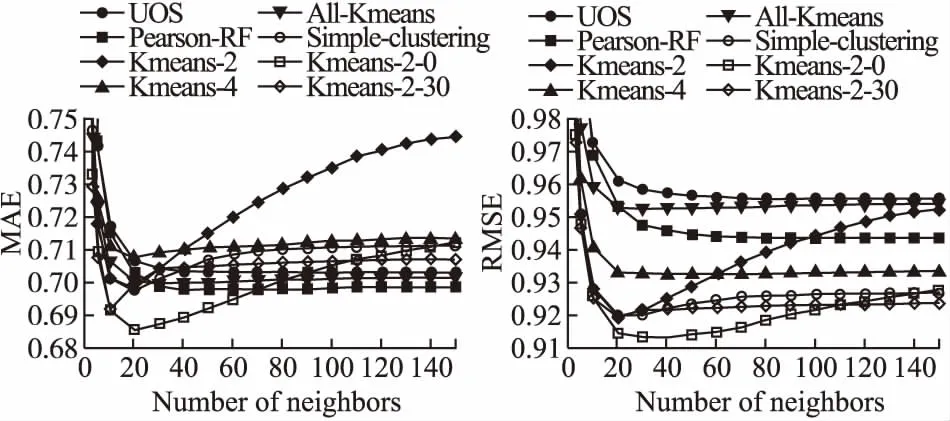
圖5 各方法的MAE和RMSE結果圖
令人驚訝的是,大多數算法只需要20個鄰居就可以在MAE和RMSE中達到最佳準確度.相比之下,在MAE和RMSE中,UOS需要60個鄰居和140個鄰居,Pearson-RF則需要50個鄰居和130個鄰居.
總之,與其它的方法相比,通過聚類的方法在鄰居較少的情況下達到了最優準確度,也就是說,Kmeans-2與Pearson-RF相比都將預測最優準確度的必要的鄰居數量減少了60%和84.6%.與Pearson-RF相比,Kmeans0將必要的鄰居數量分別減少了60%和69.2%,以做出最準確的預測.如果不需要計算復雜度并且使用簡單的聚類,那么改進后的數目與Kmeans-2相同.
然而,本文所提出的方法不僅在所需鄰居的數量上具有明顯的優越性,而且在預測準確度上也有所提高.也就是說,在MAE值方面,Kmeans-2和Simple-clustering只需要20個鄰居的就能與Pearson-RF需要50個鄰居的預測準確度相同.在RMSE方面與Pearson-RF相比,Kmeans2和Simple-clustering的預測準確性分別提高了2.59%和2.49%.
在另一方面,Kmeans-2-0作為目前最佳的預測方法,與Pearson-RF相比,MAE和RMSE的預測準確性分別提高了1.71%和3.07%,所需鄰居減少了60%.
對于Kmeans-2和簡單聚類這3種方法,RMSE結果要優于Pearson-RF,而MAE結果幾乎相同.這種現象背后的原因表明,基于鄰居聚類的鄰居選擇可以避免推薦系統評分預測中的較大誤差.
從曲線上看Pearson-RF如果只有20個鄰居不足以得到最小的預測誤差,由此推斷用本文方法選擇的20個鄰居更可靠.
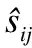
為了進一步探究公式(6)中的權重,圖6給出了進一步的實驗.這里使用Kmeans-2方法,將w1和w2設置為一對(w1,w2),即(1.0,0.0),(0.9,0.1),(0.8,0.2),(0.7,0.3),(0.5,0.5),(0.0,1.0),(1.2,0.1)和(0.8,0.1).
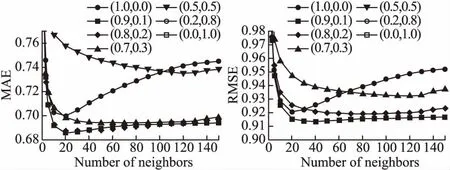
圖6 不同權重的算法MAE和RMSE結果圖
實驗表明,給主次鄰居給予不同權重,這種做法可以進一步提高預測準確度.具體地說,圖6中的最讓人接受的方法是通過w1=1.0和w2=0.0和來實現的.然而,在實驗中圖5中的結果相對較好的結果出現在當w1=0.9和w2=0.1時.因此,根據鄰居的不同的重要性來區分他們是很重要的.
在一定范圍內,主要鄰居的權重越高,預測效果越好.當權重超過一定范圍時,預測結果就會變差,特別是只參考主要鄰居,不考慮次要鄰居的時候,這時預測結果不是最佳結果.這種現象說明了次要鄰居在預測結果中的重要性.低權值的次要鄰居可以用來補償修正主要鄰居的預測趨勢.
4 總結與展望
鄰居的有效選擇一直是評分預測和推薦算法中的一個重要課題.本文探討了基于用戶相似度和置信系數,提出了一種相似性與置信系數為基礎的的推薦系統評分預測算法.
實驗表明,即使在所需鄰居數減少60%的情況下,該推薦算法仍可以達到最優評分預測準確度,揭示了置信系數和相似度這兩個因素對于可靠鄰居選擇的重要性.通過基于置信系數和相似度的聚類,在所需鄰居大量減少的情況下,該方法比對比方法預測的準確度高1%-3%.更重要的是,該方法能有效地減少了評分預測中的大誤差.
研究表明,在預測和推薦中,兩個用戶之間共同評分的物品數量與其相似度同樣重要.為了給目標用戶選擇最可信的鄰居,用戶間的置信系數和相似性都是必要的因素.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
