基于鐵路數據服務平臺的多源數據融合架構研究
2021-05-10 13:39:52馬小寧孫思齊王沛然
鐵路計算機應用 2021年4期
鄒 丹,王 喆,馬小寧,孫思齊,王沛然
(中國鐵道科學研究院集團有限公司 鐵路大數據研究與應用創新中心,北京 100081)
數據融合是大數據領域一個重要的研究方向,指集成多個數據源以產生比單一數據源更有價值的信息的過程。數據融合最早產生于軍事領域,后來廣泛應用于多影像復合、無人駕駛、圖像分析與理解、目標檢測與識別等領域[1]。目前,鐵路行業在跨系統多源數據融合方面的研究相對較少,在多源數據融合的過程中,面臨著數據不準確、不一致、不完整、數據要素分散等問題[2],為解決這些問題和提高數據融合效率[3],需要構建統一的多源數據融合架構。
本文基于鐵路數據服務平臺(簡稱:平臺),提出鐵路多源數據融合架構,以數據流為主線,將鐵路數據融合的主要工作環節與平臺功能建立對應關系,構建鐵路數據融合模型,為實施跨專業、跨系統的數據融合提供參考。
1 鐵路數據服務平臺簡介
鐵路數據服務平臺是鐵路行業自主研發的一站式鐵路大數據解決方案。該平臺是鐵路數據集中管理、大數據分析的公共基礎設施,面向鐵路數據的采集、存儲、處理、分析和共享,采用分布式架構構建。平臺可實現海量結構化與非結構化數據接入、PB 級數據離線分析、TB 級數據實時分析、數據多維分析、自助分析、數據可視化等功能。此外,建立了數據資產管理制度和標準化管理流程,規范常態化數據資產管理活動,保證數據獲取和使用的一致性、準確性和安全性。
鐵路數據服務平臺主要功能包括:
(1)多源異構數據匯集:匯集數據的類型分為結構化、半結構化、非結構化數據,采集方式包括實時采集與離線采集;
(2)大數據管理:運用主數據、地理信息、元數據管理方法,構建企業級數據資產目錄;采用大數據存儲與清洗技術,合理安排數據存儲,保證高質量數據;
(3)大數據分析:采用批處理、流計算、內存計算等分布式計算方法,構建大數據平臺在線數據分析計算環境;
(4)大數據共享:實現大數據交換共享、數據申請審批和接口調用權限管理和接口自動配置,支持細粒度的數據共享管理。
2 多源數據融合架構
鐵路多源數據融合涉及3 項主要任務:(1)對鐵路數據進行集中匯集;(2)根據數據融合的目的與要求進行數據梳理和預處理,選擇合適的層次完成數據融合;(3)將數據融合的結果進行共享。
為了使這些任務能夠在鐵路數據服務平臺上落地實施,將鐵路數據融合架構劃分為上下2 層,如圖1 所示。
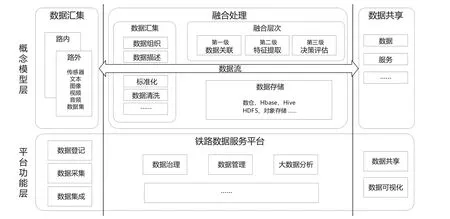
圖1 鐵路數據融合架構
上層為概念模型層,以數據在平臺中的流轉為主線,包括數據匯集、融合處理和數據共享。下層為平臺功能層,數據匯集對應鐵路數據服務平臺的功能模塊為數據登記、數據匯集;融合處理對應平臺功能模塊為數據清洗、數據管理、數據分析等;數據共享對應平臺的數據開放共享、數據可視化等功能模塊。
2.1 數據匯集
數據匯集是數據融合的基礎,為實現跨行業、跨系統的數據融合,首先需要將不同業務線、不同系統、不同類型的數據采集并集中到鐵路數據服務平臺中。
由于多源數據存在數據庫類型多樣、網絡環境復雜、數據歸屬權分散等問題[4],需要對現有系統進行詳細的數據源調查,調查內容主要包括:系統名稱,部署層級,業務主管部門,系統研發及運維單位,部署網絡,數據類型,數據產生周期及數據量,詳細的數據表結構說明等。
根據數據源調查結果,與各業務系統的開發單位進行深入對接,制定詳細接口方案。接口方案需要考慮接口類型、數據量、數據實時性、數據傳輸效率、數據傳輸安全性、硬件及網絡環境等,制定數據匯集策略和實施計劃;接口應具有較好的通用性及可擴展性。
2.2 融合處理
融合處理是整個數據融合架構中最重要的部分,主要解決多源數據不準確、不完全、不一致等問題,按照融合數據的具體需求,采用不同的融合層次及方法,并存儲數據的過程。
2.2.1 數據預處理
匯集后的數據一般不能直接融合,需要先進行數據預處理,數據預處理主要分為以下幾類:
(1)數據管理:數據管理是對數據進行描述和組織的過程,主要通過鐵路數據服務平臺的元數據管理和數據分類功能模塊實現。元數據管理記錄數據結構和對數據變換處理的過程,實現數據的血緣分析及影響度分析;數據分類通過構建鐵路數據分類和標簽體系,實現鐵路數據的多維度組織和管理;
(2)數據標準化:通過構建數據元標準,開展數據質量管理,達到統一量綱、消除數據差異、建立數據關聯等目的;數據標準化包括數據元標準化、數據質量標準化、數據管理流程標準化等;
(3)數據清洗:主要包括數據去噪、數據填充等,清除垃圾數據,解決數據沖突,提高數據質量,以保證數據分析的準確性,取得預期的大數據綜合應用的成果。
2.2.2 鐵路數據融合層次
結合鐵路業務特點以及基于鐵路數據服務平臺已開展的數據處理工作,將數據融合分為3 個層次,如圖2 所示。
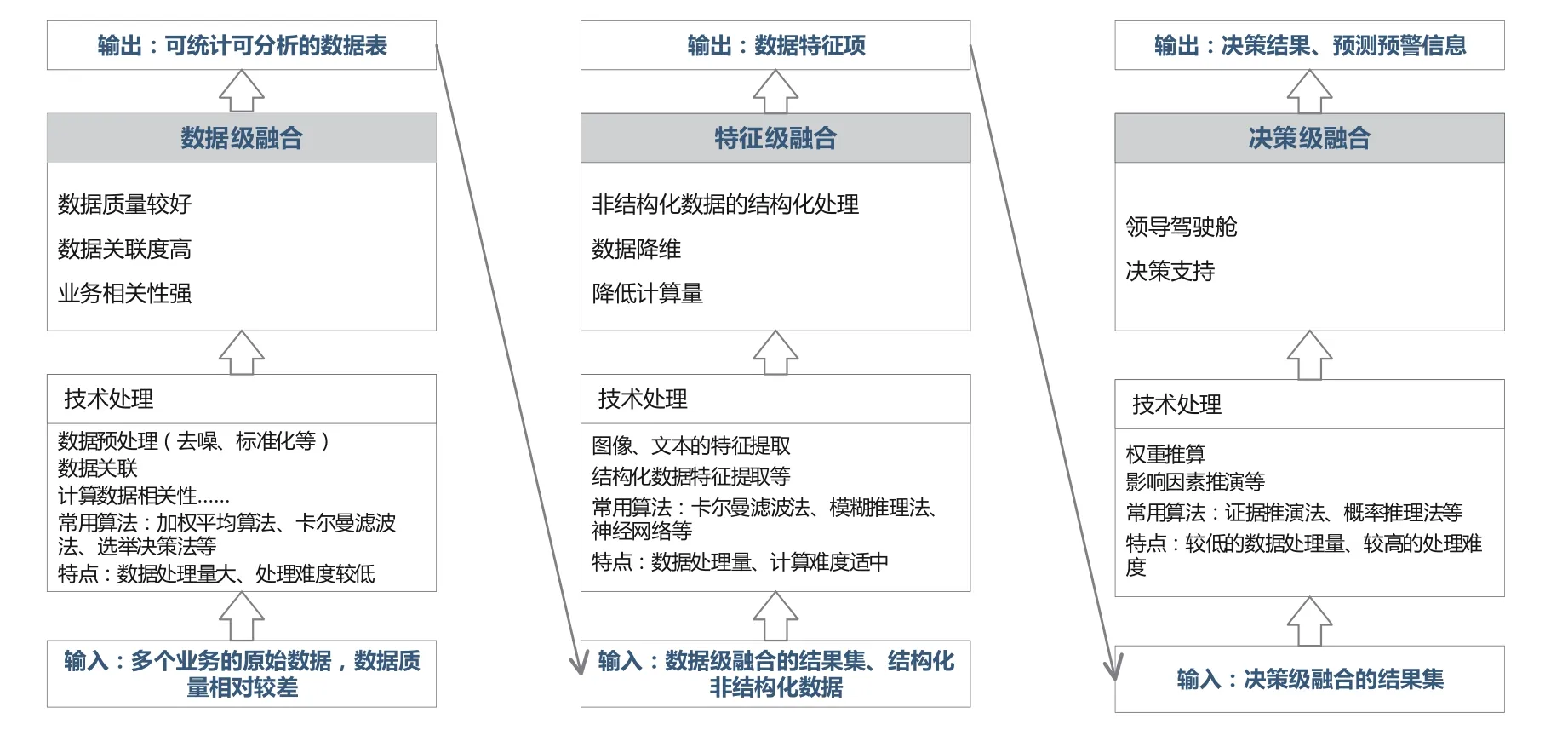
圖2 數據融合層次
(1)數據級融合
數據級融合的輸入項是來自多個業務系統的原始數據,通過分析數據表間的關聯關系,將關聯度較高的數據進行關聯,形成新的數據集,并不斷迭代這個過程。數據級融合結果可作為“特征級融合”的輸入項。
數據級融合屬于低層級融合,其特點是數據處理量大,處理時間長,實時性較差,但融合過程比較簡單,處理難度較小[5]。
(2)特征級融合
特征級融合是對信息進行特征提取,并對提取后的特征進行融合。特征級融合的輸入可以是數據級融合的結果,也可以是原始數據集。在特征提取方面,鐵路數據服務平臺的人工智能模塊可對文本、圖像等非結構化數據進特征提取。這些特征項可作為結構化數據與其他結構化數據進行特征項融合,融合結果可作為“決策級融合”的輸入項。
特征層融合數據處理量適中,利于實時處理,處理難度適中。特征級融合可用來對數據降維,降低分析及數據處理難度,提取的特征可作為“決策級融合”的輸入項。
(3)決策級融合
決策級融合是對特征數據、結論數據進行融合判定,獲得聯合推斷結果。決策級融合需要借助特征級融合的結果,一般不用來直接處理原始數據。決策層融合的優點是具有較好的容錯性,所需的信息量小,數據通信量低,但融合難度大,對融合算法要求較高[6]。
決策層融合一般用于決策支持,需要按照明確的決策目標進行算法的構建和迭代優化,部分決策結果還需要結合專家經驗進行綜合評定后,才能得到所需的決策和評估結果。
2.2.3 融合算法對比分析
表1 列出了幾種常用的數據融合算法,對其特點和適用性進行對比。這些數據融合算法存在互補性,在實際處理過程中,會使用其中一種或多種算法,或基于這些算法構建新的算法模型[7]。

表1 常用數據融合算法比較
2.2.4 數據存儲
鐵路數據服務平臺根據數據的不同特點提供多種數據存儲組件。對于有實時共享需求或應用查詢需求的熱數據、溫數據,主要存放在數據倉庫或HBase 中;對于歷史全量冷數據,主要存放在Hive中用于離線分析。對于非結構化數據的存儲,提供HDFS 文件系統和對象存儲組件,滿足不同數據量的數據文件存儲需求;對于零碎的中小文件,將這些數據存放在對象存儲組件中,而數據量較多的大文件,則會將數據存放在HDFS 文件系統中。
2.3 數據共享
數據共享是將數據融合處理后生成的數據或結論以服務的形式進行提供。目前,鐵路數據服務平臺提供2 種方式的數據共享:(1)利用鐵路數據服務平臺的開放共享模塊,發布融合結果,數據使用者申請通過審批后可獲取數據;(2)利用鐵路數據服務平臺的可視化模塊,將數據融合的結果直接生成可視化圖表進行展示。
不同層次的數據融合產生的數據量不同:數據級融合,產生的數據量較大、數據屬性豐富,可以用于通過數據開放共享模塊進行數據共享;特征級融合的特征結果數據量相對適中,既可以利用數據開放共享模塊共享數據結果,又可按不同特征維度生成可視化圖表進行展示;決策級融合,產生的數據量較小,但其計算結果可為運輸生產提供決策參考,適于以可視化方式制作領導駕駛艙,為分析、決策、指揮提供支持。融合結果的共享形式由使用者的需求決定,鐵路數據服務平臺本身具備兼容性和可擴展性,能夠在未來支撐更多的數據共享方式,提供更合理更有價值的數據融合成果。
3 結束語
為了解決數據融合面臨的問題,提升數據融合效率,提出基于鐵路數據服務平臺的數據融合架構,對數據融合過程中所涉及的數據匯集、融合處理和數據共享展開研究。重點研究數據融合處理過程,基于鐵路數據服務平臺功能,對數據預處理,融合層次及相關數據融合算法進行研究,對實現鐵路數據跨系統、跨專業的大數據融合,具有一定的參考價值。
隨著鐵路數據匯集范圍的逐步擴大,集中存儲的數據資源將越來越豐富,在數據融合方面,將結合鐵路業務場景開展具體的深入研究。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
云南畫報(2021年12期)2021-03-08 00:50:54
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
鐵道通信信號(2018年7期)2018-08-29 01:17:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
通信電源技術(2016年4期)2016-04-04 02:58:04
