基于CTM模型的在線輕問診醫生推薦研究
2021-05-11 19:06:39張錦紅張云華
智能計算機與應用 2021年2期
張錦紅 張云華

摘要:本文采用CTM主題模型對現有的在線醫生專家推薦模型進行優化,首先利用患者提出的健康問題,得到問題-主題概率分布,然后根據醫生歷史回答的所有問題得到醫生-主題概率分布,接著對得到的兩項分布用杰卡德相似系數計算方法計算相似度,進而將主題相似度高的醫生列表推薦給患者。實驗階段先對好大夫在線輕問診模塊的過敏反應科的數據進行采集和處理,再進行建模與測試,結果證實本文提出的醫生推薦方法比該科室現存推薦方法更高效。
關鍵詞:CTM;專家推薦;在線輕問診
【Abstract】ThispaperusestheCTMtopicmodeltooptimizetheexistingonlinedoctorexpertrecommendationmodel.Firstly,thepaperusesthehealthquestionsraisedbythepatienttoobtainthequestion-topicprobabilitydistribution,secondlyobtainsthedoctor-topicprobabilitydistributionbasedonallthequestionsansweredbythedoctor'shistory.ThenthepaperusestheJackardsimilaritycoefficientcalculationmethodtocalculatethesimilarityoftheobtainedtwodistributions,finallyrecommendsalistofdoctorswithhightopicsimilaritytothepatient.Intheexperimentalstage,thedataoftheAllergicReactionsDepartmentoftheDoctorOnlineInquiryModuleiscollectedandprocessed,andmodelingandtestingareperformed.Theresultsconfirmthatthedoctorrecommendationmethodproposedinthisarticleismoreefficientthantheexistingrecommendationmethodinthedepartment.
【Keywords】CTM;expertrecommendation;onlinelightconsultation
作者簡介:張錦紅(1996-),女,碩士研究生,主要研究方向:軟件工程、智能信息處理;張云華(1965-),男,博士,研究員,主要研究方向:軟件工程、系統仿真、智能信息處理。
0引言
隨著互聯網技術的快速發展及廣泛應用,醫療也不再局限于線下看醫生,很多輕微疾病用戶會選擇在互聯網上咨詢疾病問題。此時,患者會在就醫網站上訴說自己的身體狀況,醫生根據患者的病情描述回答患者的問題并同步給出健康問題解決方案[1],可以達到資源合理配置的效果。雖然就目前來講在線醫療輕問診醫生推薦研究取得了很大的突破,但有些方面仍然亟待優化,主要包括以下3點:
(1)當患者根據自身的健康狀況在網絡上尋求幫助時,往往因為信息量過大、且在描述上有失精準而顯得無所適從。再者,部分患者幾乎不了解相關醫學知識,就可能在選擇合適醫生進行輕問診上存在困難,而選定醫生也因為患者問詢診治領域與自身專業方向并不匹配,如此就失去了在線醫療解決身體小疾患的意義。
(2)當前已推出不少提供患者和醫生在線溝通的互聯網平臺,但醫生卻要在大量的咨詢中耗費精力篩選自己可以解答的問題,醫生資源得不到充分利用,大大降低了在線輕問診的效率。
(3)目前在線醫療輕問診平臺中,用戶不能及時得到解答服務,從尋求幫助到得到方案需要的時間具有不確定性[2]。因此,通過科學合理的專家推薦方法來充分利用醫生資源以及提升用戶滿意度就顯得尤為必要[3]。
綜合前面問題所述,本文擬研究面向在線患者輕問診的醫生推薦主題模型,通過利用患者提出的待匹配健康問題與醫生專家的歷史回答健康問題的主題提取以及主題相似度的匹配,當患者提問時將合適的醫生推薦給患者,并將患者的病情推送給專業的醫生做病理解析,在一定程度上能夠確保患者快捷、高效地獲得健康問題解決方案,同時提高在線醫療輕問診服務的效率和準確性及有效性[4]。
1研究綜述
與傳統的關鍵字檢索相比,社區問答系統能更好地滿足用戶對快速、準確獲取信息的需求。因此,對問題的精準處理可以有效幫助社區問答系統抽取出更好的答案[5]。
主題識別主要通過共詞分析和概率模型來實現,并抽取詞匯來對主題進行表征[6]。迄今為止,主題模型已經發展了20余年,作為篇章級別文本語義理解的重要工具,pLSA(probabilisticLatentSemanticAnalysis)就成為早期概率主題模型的典型代表。隨后,Blei等人在2003年提出的LDA模型則標志著對主題模型的研究進入熱潮。
隱含狄利克雷分布(LatentDirichletAllocation,LDA)是常見的主題模型。由于LDA是非監督學習模型,本身不可直接用于分類,需將其嵌入到適合的分類算法中。許多學者基于LDA模型建立主題模型,包括Blei和Lafferty提出的相關主題模型(CTM)[7]、Li和AndrewMcCallum用無向圖表示文檔隱含主題結構的PAM模型[8]以及RosenZvi等人提出的作者主題模型(ATM)[9]等等。
其中,CTM主題模型可以很好地展現主題間的相關性,并且文本主題數目對CTM模型的性能相當重要。LDA主題模型采用狄利克雷分布(Dirichletdistribution)模擬文檔生成過程,CTM用對數正態分布替換LDA的狄利克雷分布對文檔集隱含的主題進行提取,并引入協方差矩陣來描述主題間的相關性,解決了LDA主題之間不相關的問題[10]。
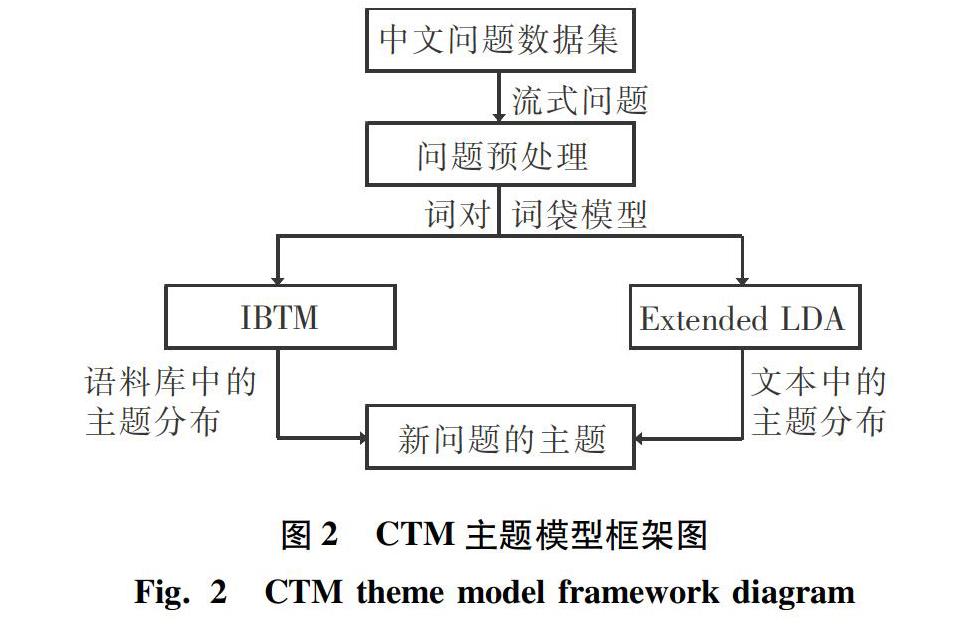
CTM主題模型的框架如圖2所示。此模型假定某個詞匯擁有豐富的語義信息,某個主題的語句會含有和此主題相關的詞匯。便可以通過探索語料庫中頻繁組合出現的詞匯組來挖掘深層次的主題信息。利用這一方法,把待分析的文檔建模成為擁有潛在主題信息的隨機混合模型,模型中的語句含有的每個主題特征取決于語句中單詞的特定分布,即為主題-詞匯分布。
2基于CTM構建在線輕問診醫生推薦模型
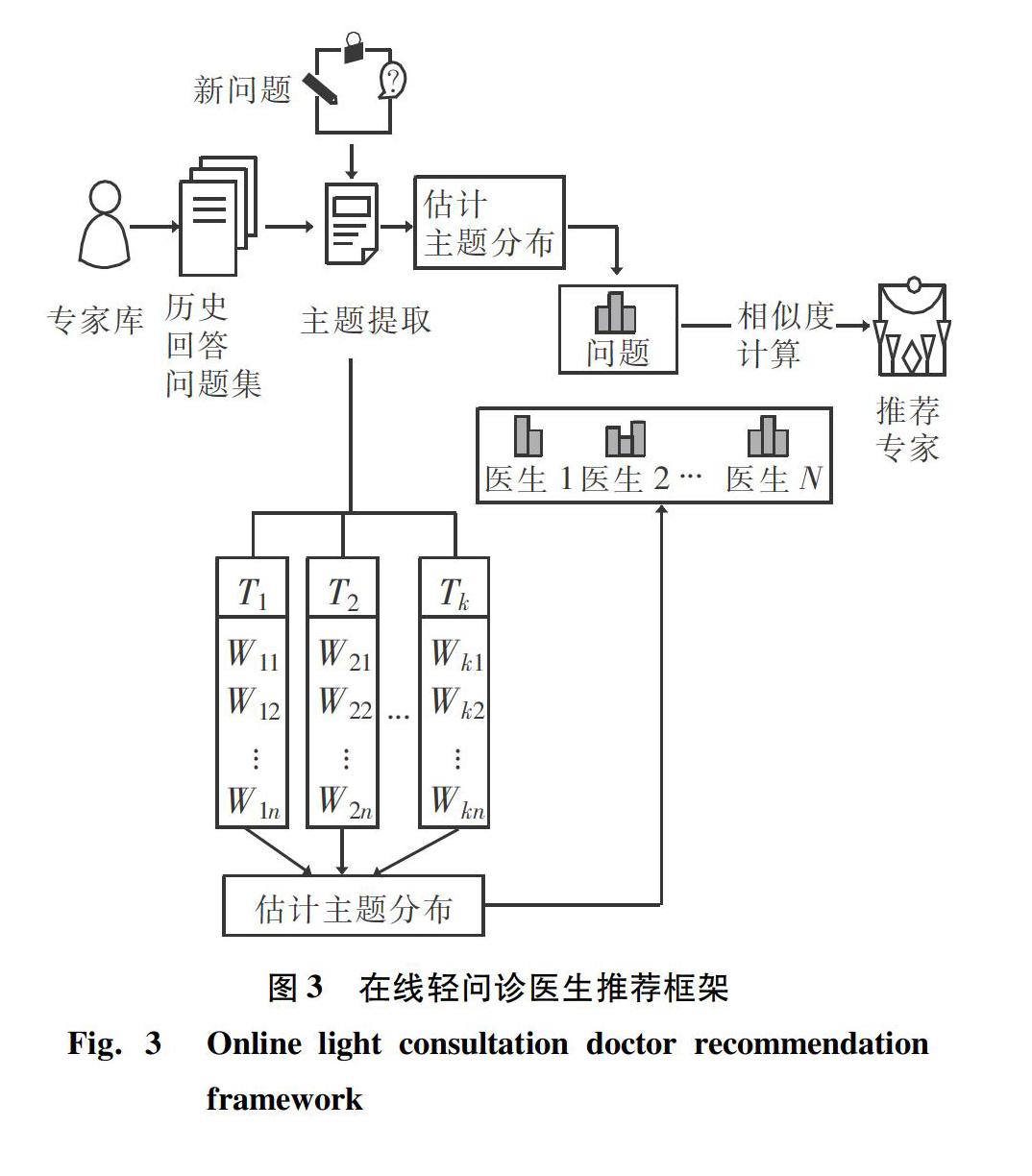
常規的推薦算法大體上是根據問題和醫生的二元關系來建立推薦模型,與傳統的推薦算法相比,本文擬要建立的是問題-專長-醫生的三元關系模型。三元模型能最大化地提高醫生回答效率以及改善用戶體驗。當對文本進行提取時,對于健康問題的主題之間則會存在相關性,語句中包含的每個主題并非是完全獨立的,本文選用的CTM模型就能很好地解決這個問題。本次研究分3個步驟完成在線輕問診醫生的推薦,整體的步驟流程框架如圖3所示[11]。
2.1醫生專長信息提取
醫生專長信息提取主要思想是采集某科室中某醫生歷史回答問題集合進行建模,在此基礎上進行監督學習,從而得到該醫生回答問題的主題信息,對醫生來說,該主題即是其在某科室的專長。為找到醫生專長,本文用到的是CTM主題模型,其模型如圖4所示。
圖4中,K表示某科室內醫生以往回答健康問題的集合,D表示某個問題的長度,矩形框表示進行迭代的次數,Wd,n表示第d個問題中的第n個詞,問題庫中所有詞構成集合V,Wd表示問題d中所有Nd個詞構成的Nd維向量,主題β是V上的分布。每個醫生的過往回答健康問題集合都對應一個主題混合比例向量θd,θd是主題上的分布,既反映了問題庫d中單詞取主題集中每個主題的概率,也考慮了使用多項式分布η=log(θi/θk)進行自然參數化處理[12]。
2.2待匹配健康問題主題提取
由于患者的醫學涉獵較為有限,一個健康問題的醫學專用術語并不明確,很難清晰地得到含蘊其間的醫學主題。基于此,通過訪問待匹配健康問題科室的問題集合文本,從中提取該科室涉及到的醫學主題,可以得到訪問科室健康問題的主題分布,即可推斷待問答健康問題所含有的醫學主題。因為健康問題是流動的,即使一句簡單的問題也可能涉及到多個醫學主題,為了獲得健康問題主題分布,本文采用增量吉布斯采樣(IncrementalGibbsSample)對訪問科室內健康問題集合進行參數估計,獲取健康問題-主題的概率分布θ以及主題-詞項的概率分布β。
2.3醫生推薦
在線輕問診醫生推薦的目的是為患者提出的健康問題高效地匹配到專業的醫生,當提取到科室醫生的專長信息以及輕問診健康問題的主題時,只需要計算相關的主題相似度,就能夠為提出問題的患者找到最適宜的醫生專家。本文采用的是杰卡德相似系數(JaccardSimilarity)計算方法,系數越大,表明醫生專長與待回答輕問診健康問題的內容就越相似。主要步驟為:
Step1從科室醫生名單中獲取某位醫生的專長關鍵詞記為U。
Step2選取一個訪問該科室的健康問題,記問題關鍵詞集合為V。采用杰卡德相似系數方法計算醫生回答問題庫與待回答輕問診問題的相似度,即集合U和集合V的交集元素/并集元素。
Step3選取下一個訪問該科室的健康問題,重復Step1和Step2,直到所有訪問該科室的健康問題遍歷完畢。
Step4選取下一個醫生,重復Step1和Step2,直到所有醫生遍歷完畢。至此,得到了該科室醫生與健康問題的主題相似度集合,根據集合中最大的前n個數給輕問診問題匹配合適的n個醫生。
3實驗結果與結果分析
3.1數據收集與處理
考慮到數據的真實有效以及規模性,本文的數據來源為知名互聯網醫療網站好大夫。皮膚科中的過敏反應科是比較常見并且涉及到的健康問題比較輕微的科室,尋求在線輕問診解決健康問題的患者比較普遍。因此本文采用網絡爬蟲技術收集該網站截止到2020年11月15日的所有過敏反應科醫生在線輕問診的過往回答問題為研究樣例,其中過敏反應科醫生為235位,健康問題為最新產生的30萬條輕問診問題,問題中的28736條被患者接受。
在好大夫網站采集到的原始數據存在著噪聲,需在做處理后才能將其用于分析和主題挖掘。在使用CTM模型對健康問題集合進行建模前,通過利用中文分詞、醫學專業詞識別、停用詞過濾等方法對每個健康問題集合進行預處理,這樣就降低了問題集的空間維度,從而提高了建模效率[13]。對于中文分詞,因為健康問題集合數據龐大,本文采用的是統計分詞的算法,基于統計學的機器學習模型對數據進行訓練[14]。對于醫學專業詞識別,考慮到健康問題中涉及到例如藥名、疾病名稱等醫學健康詞匯,因此就要在用戶詞典中添加從互聯網收集到的醫學詞庫,旨在能夠高效識別涉及到的醫學方面用語[15]。對于停用詞過濾,是因為分詞后得到的問題集還是會存在大量的冗余,比如“在”、“的”等詞匯,這些詞匯對于文本語義分析以及主題的提取并無用處,而且還會降低建模效率。針對這個問題,本文使用哈工大停用詞表來篩選語料中的高頻通用詞和低頻詞,以獲得噪聲較小的數據集,藉此來提高建模的效率[16]。
3.2模型構建
截止到2020年11月15日,好大夫在線過敏反應科的235名醫生全都參與過最新的30萬個問題。選取25萬個健康問題作為訓練集,其余的5萬個健康問題作為測試集。好大夫在線從用戶的健康提問和醫生對問題的解答中自動識別出關鍵詞來作為主題,這就完善了用戶因為不了解醫學專有名詞而導致的健康狀況不明確等問題。對過敏反應科以往回答過的過敏反應問題集的主題標簽進行統計,合計獲取了13026個主題標簽。使用停用詞過濾后,選取出現頻率最多的前600個主題作為模型訓練的主題標簽。
把這600個主題分布在235名過敏反應科醫生的健康問題集合上,通過CTM模型訓練,獲取到每一位過敏反應科醫生在各個主題上的概率分布,即獲取醫生專長,部分實驗結果如圖5所示。
圖5中的每個子圖就是一個過敏反應科醫生的主題分布,其中主題標識為橫坐標,醫生與主題的分布概率為縱坐標,每個點的大小反映了分布概率的大小。通過觀測實驗結果,可以發現不同的醫生存在不同的專長分布,并且有些醫生可以解答多個主題的健康問題,有些醫生卻僅會解答某個主題的健康問題,還存在一些醫生對多個主題雖都有涉及,但卻未能提取出特別擅長的主題。
3.3模型測試
使用訓練后的模型對600個主題測試集進行主題分布預測,其中主題標簽為橫坐標,測試問題集里面的健康問題為縱坐標。經過CTM主題模型訓練得到每個健康問題在主題標簽庫上的概率分布情況,部分實驗結果如圖6所示。
圖6中的每個子圖反映的是測試集中的一個健康問題在主題上的概率分布情況。從分布情況來看,有些患者提出的健康問題主題特點明確,只涉及少數的主題,有些患者提出的健康問題涉及到多個主題并且概率都偏高,表明這些醫學主題之間都將存在相關性,而本文采用的CTM模型能有效解決該問題。
3.4結果分析
對于本文提出的在線醫生推薦模型的效果測評,先將測試集中的5000個健康問題隨機分成5組,即每1000個為一組,使用本文方法產生醫生推薦列表,其中限制的在線醫生數量為8,對5組問題集分別計算準確率、召回率和MRR[17]。結果見表1。
由表1中數據可以看到,5個分組的推薦情況都相對穩定,準確率和召回率都在40%左右,變化浮動小,并且兩者相差較小。存在一些組的MRR值變化較大,容易被極端值所影響,經分析是由于235名過敏反應科醫生參與網站回答醫療的時間跨度很大,有些醫生注冊網站時間久、回答的問題規模比較大,所以主題分布更高效清晰,還有一些醫生新近加入網站,在線回答問題量偏少,仍無法完全提取得到其專長。由于新醫生主題分布不明顯,容易排在推薦醫生列表的后面,如果某個患者采納的是新加入醫生的解答,那么就會對MRR值產生影響。
為了驗證本文提出的在線醫生推薦的有效性,對過敏反應科使用該方法與好大夫在線已存在的指標展開對比,對比結果見表2。
由表2中數據分析可知,準確率為過敏反應科問題采納次數/過敏反應科問題總數,召回率為過敏反應科醫生回答總次數/所有醫生回答總次數,回答采納比為過敏反應科問題采納次數/過敏反應科醫生回答總次數。結合好大夫網站現有指標對比發現,本文提出的專家推薦系統從準確率、召回率以及回答采納比都優于好大夫在線過敏反應科的現有指標,充分證實了該系統對在線醫生推薦的高效性。
4結束語
目前的在線醫生推薦研究中,現有的一些方法忽略了醫生專長之間有關聯以及描述的健康問題主題之間的關聯性,導致獲取的主題分布繁雜且無側重。對于在線醫生推薦,不僅要關注模型的主題詞提取效果和分類準確性,同時還需要考慮模型能否兼顧主題之間的聯系。在這種情景下,本文采用的CTM模型可以很好地解決這個問題:先用模型訓練患者提出的健康問題,得到問題-主題概率分布,其次利用科室內的每個醫生歷史回答問題集合得到醫生-主題概率分布,接著對得到的2項分布用杰卡德相似系數計算方法計算相似度,稍后將杰卡德相似系數大的、即主題相似度高的醫生列表推薦給患者。最后,通過對好大夫在線過敏反應科的數據進行建模與測試,實驗結果充分證明了本文提出的醫生推薦方法比網站該科室現存推薦方法更高效。
對于本文提出的推薦模型也存在不足,例如有一些醫生注冊該網站時間不長,回答患者問題的積累量偏少,其專長無法得到完全提取,會導致該新醫生即便很適合回答某個健康問題,但因為自身的主題分布不明顯,而排在該問題推薦醫生列表的后面將無法反饋給患者。后續亟需對這個問題進行特殊的處理,即對新加入醫生的專長進行優化提取,以此來提高系統整體效率和用戶滿意度。另外,本文提出的方法默認患者是知道自己的健康問題屬于哪個科室,在該科室有醫生能幫助自己,所以針對一些對自身疾病存在盲區的患者,需要配合健康問題和醫院科室選擇的系統結合使用。
參考文獻
[1]林悅.“互聯網+智慧醫療”現狀及發展展望[J].中國醫療器械信息,2019,25(18):15-16.
[2]刁必頌.基于在線患者咨詢數據的在線醫生推薦系統研究[D].北京:北京理工大學,2016.
[3]朱利,岳愛珍.健康問題和醫生匹配機制的研究[J].西安交通大學學報,2014,48(12):57-62,139.
[4]楊曉夫,秦函書.基于電子病歷利用矩陣乘法構建醫生推薦模型[J].計算機與現代化,2019(06):81-86,97.
[5]朱龍霞.面向中文問答系統問題分析與答案抽取方法研究[D].石家莊:河北科技大學,2018.
[6]張金柱,于文倩.基于短語表示學習的主題識別及其表征詞抽取方法研究[J/OL].數據分析與知識發現:1-13[2020-10-22].https://kns.cnki.net/kcms/detail/10.1478.g2.20201022.1158.002.html.
[7]JURCZYKP,AGICHTEINE.Discoveringauthoritiesinquestionanswercommunitiesbyusinglinkanalysis[C]//SixteenthACMConferenceonInformationandKnowledgeManagement,CIKM2007.Lisbon,Portugal,November.DBLP,2007:919-922.
[8]BOUGUESSAM,DUMOULINB,WANGShengrui.Identifyingauthoritativeactorsinquestion-answeringforums:thecaseofYahoo!answers[C]//Proceedingsofthe14thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.LasVegas,Nevada,USA:ACM,2008:866-874.
[9]BLEIDM,LAFFERTYJD.Correlatedtopicmodels[C]//AdvancesinNeuralInformationProcessingSystems.Vancouver,BritishColumbia,Canada:dblp,2005,18:147-154.
[10]史盛楠.CTM主題模型在學科主題識別與學科文獻分類中的應用研究[D].曲阜:曲阜師范大學,2019.
[11]潘有能,倪秀麗.基于Labeled-LDA模型的在線醫療專家推薦研究[J].數據分析與知識發現,2020,4(4):34-43.
[12]楊正良.優化特征選擇的CTM模型在文本分類中的應用研究[D].武漢:華中師范大學,2016.
[13]丁勇,程家橋,蔣翠清,等.基于主題和關鍵詞特征的比較文本分類方法[J/OL].計算機工程與應用:1-9[2020-11-02].http:///KCMS/detail/11.2127.tp.20201026.0911.002.html.
[14]李國壘,陳先來,夏冬,等.中文病歷文本分詞方法研究[J].中國生物醫學工程學報,2016,35(4):477-481.
[15]王月瑤.面向醫療文本檢索的查詢重構技術研究與實現[D].上海:華東師范大學,2018.
[16]王凡,夏晨曦.中文醫學摘要主題建模方法評估[J].醫學信息學雜志,2018,39(2):60-64.
[17]單國棟,肖彥翠,王皓.基于主題模型的中外期刊文獻挖掘對比研究[J].長春大學學報(自然科學版),2019,29(3):23-29.
