一種RNN-T與BERT相結合的端到端語音識別模型
2021-05-11 19:47:17郭家興韓紀慶
智能計算機與應用 2021年2期
郭家興 韓紀慶

摘要:端到端語音識別模型由于結構簡單且容易訓練,已成為目前最流行的語音識別模型。然而端到端語音識別模型通常需要大量的語音-文本對進行訓練,才能取得較好的識別性能。而在實際應用中收集大量配對數據既費力又昂貴,因此其無法在實際應用中被廣泛使用。本文提出一種將RNN-T(RecurrentNeuralNetworkTransducer,RNN-T)模型與BERT(BidirectionalEncoderRepresentationsfromTransformers,BERT)模型進行結合的方法來解決上述問題,其通過用BERT模型替換RNN-T中的預測網絡部分,并對整個網絡進行微調,從而使RNN-T模型能有效利用BERT模型中的語言學知識,進而提高模型的識別性能。在中文普通話數據集AISHELL-1上的實驗結果表明,采用所提出的方法訓練后的模型與基線模型相比能獲得更好的識別結果。
關鍵詞:語音識別;端到端模型;BERT模型
【Abstract】Theend-to-endspeechrecognitionmodelhasbecomeoneofthemostpopularspeechrecognitionmodelsduetoitssimplestructureandeasytraining.However,itusuallyneedsalargenumberofspeech-textpairsforthetrainingofanend-to-endspeechrecognitionmodeltoachieveabetterperformance.Inpracticalapplications,itisverylaboriousandexpensivetocollectalargenumberofthepaireddata,resultinginthemodelcannotbewidelyused.ThispaperproposesamethodofcombiningtheRecurrentNeuralNetworkTransducer(RNN-T)modelwiththeBidirectionalEncoderRepresentationsfromTransformers(BERT)modeltosolvetheaboveproblems.ItreplacesthepredictionnetworkpartintheRNN-TwiththeBERTmodelandfine-tunestheentirenetwork,thustheRNN-Tmodeleffectivelyuseslinguisticinformationtoimprovemodelrecognitionperformance.TheexperimentalresultsontheChinesemandarindatasetAISHELL-1showthat,comparedwiththebaselinesystem,thesystemusingtheproposedexpansionmethodachievesbetterrecognitionresults.
【Keywords】speechrecognition;end-to-endmodel;BERTmodel
作者簡介:郭家興(1995-),男,碩士研究生,主要研究方向:語音識別;韓紀慶(1964-),男,博士,教授,博士生導師,主要研究方向:語音信號處理、音頻信息處理。
0引言
近年來,各種基于深度神經網絡的端到端模型在語音識別(AutomaticSpeechRecognition,ASR)領域正逐漸成為研究熱點。不同于傳統的語音識別模型,端到端模型不再需要將輸入語音幀和給定文本標簽進行一一對齊,其僅包含一個單獨的序列模型,可以直接將輸入的語音特征序列映射為識別的文本序列,簡化了識別的過程。同時模型不依賴語言模型和發音詞典,降低了對專家知識的要求[1-3]。目前,端到端語音識別模型主要包括基于注意力機制的編解碼模型[4-5]、連接時序分類(ConnectionistTemporalClassification,CTC)模型[6-7]、基于循環神經網絡轉換器(RecurrentNeuralNetworkTransducer,RNN-T)的模型[8-9]三種。其中,RNN-T模型是由Graves等人針對CTC的不足所提出的改進方法。相比于CTC,RNN-T可以同時對輸入和輸出序列的條件相關性進行建模,而且對輸入和輸出序列的長度沒有限制。這使得RNN-T模型更加適合語音任務,因此本文擬圍繞RNN-T模型來展開研究工作。
時下的大量研究表明[10-14],端到端語音識別模型仍然存在著語料資源有限所導致訓練不充分等一系列問題。而收集大量語音-文本對非常困難,這導致端到端語音識別模型在實際應用中的表現欠佳。最近的工作表明,可以使用純文本數據來改善其性能。文獻[5]用詞級語言模型組成RNN輸出網格,文獻[8]用外部語言模型對搜索算法進行重新打分。文獻[15-16]在波束搜索期間合并了字符級語言模型,而文獻[17]采用知識遷移的方法,先對大規模外部文本訓練語言模型,再將該語言模型中的知識遷移到端到端語音識別系統中。這些方法在解碼階段將端到端模型與其它語言模型結合在一起,可以有效改善語音識別模型的性能,但是都需要額外的步驟來集成和微調單獨的語言模塊,因此都不是真正意義上的端到端模型。
為了解決上述問題,同時考慮到BERT(BidirectionalEncoderRepresentationsfromTransformers)模型[18]是目前對語言學信息建模最好的模型,本文提出一種將RNN-T模型與BERT模型進行聯合優化的方法,就可以高效利用BERT模型所提供的語言學信息,也是一種真正的端到端模型。
1提出方法
1.1RNN-T模型及其局限性分析
1.1.1基于RNN-T的端到端語音識別模型
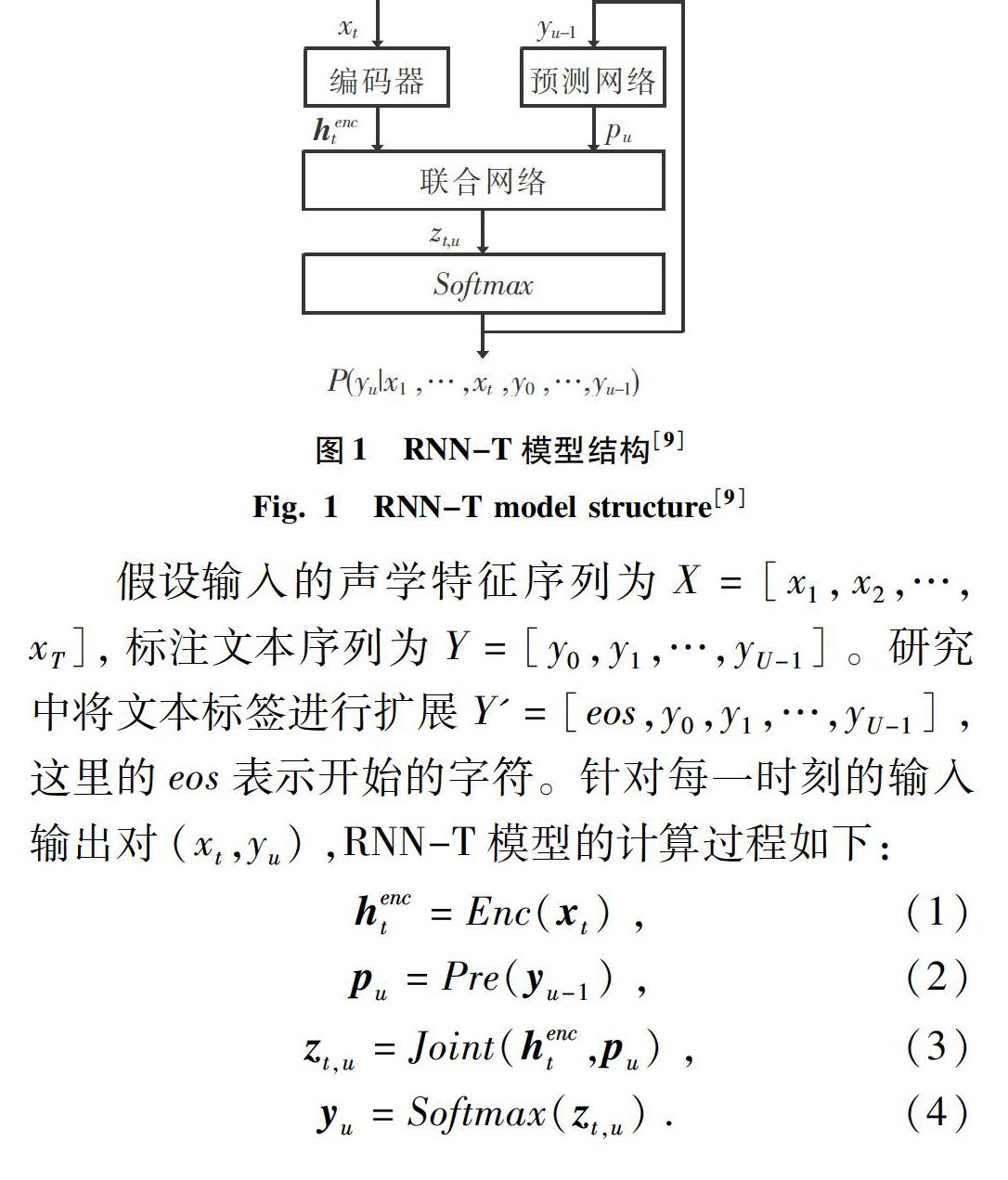
基于RNN-T的端到端語音識別模型能夠很好地將聲學信息和語言學信息進行聯合優化,在端到端語音識別任務中取得了目前最好的性能,通常由3部分構成:編碼器(Encoder)、預測網絡(PredictNetwork)和聯合網絡(JointNetwork)。其中,編碼器的功能就類似于傳統語音識別系統的聲學模型,通過將輸入的聲學特征序列轉化為發音基元序列,預測網絡給出對應的語言學信息,聯合網絡的作用是結合語言學信息和發音基元序列產生對應的轉錄文本,整個模型結構如圖1所示。
RNN-T模型不僅解決了CTC中輸出之間的條件獨立性假設,以及缺少語言建模能力的不足,還使用了共同建模的思路來對語言模型和聲學模型進行聯合優化;同時,模型具有在線解碼等諸多優點,是一種比較有前景的模型。因此,本文首先搭建基于RNN-T結構的端到端語音識別基線模型。
1.1.2RNN-T模型的局限性分析
RNN-T模型也存在不足。一方面,由于在RNN-T模型中,聲學建模與語言學建模已被整合在一個網絡中,其僅用一個目標函數進行優化,這就要求訓練數據必須同時包含輸入和輸出序列。然而在實際應用中配對數據的獲取十分困難。另一方面,RNN-T模型并不能像CTC一樣與傳統的WFST結合,在第一遍解碼中,未能利用大型語言模型的好處,而RNN-T的預測網絡所提供的上下文信息,只能在一定程度上緩解這種劣勢。
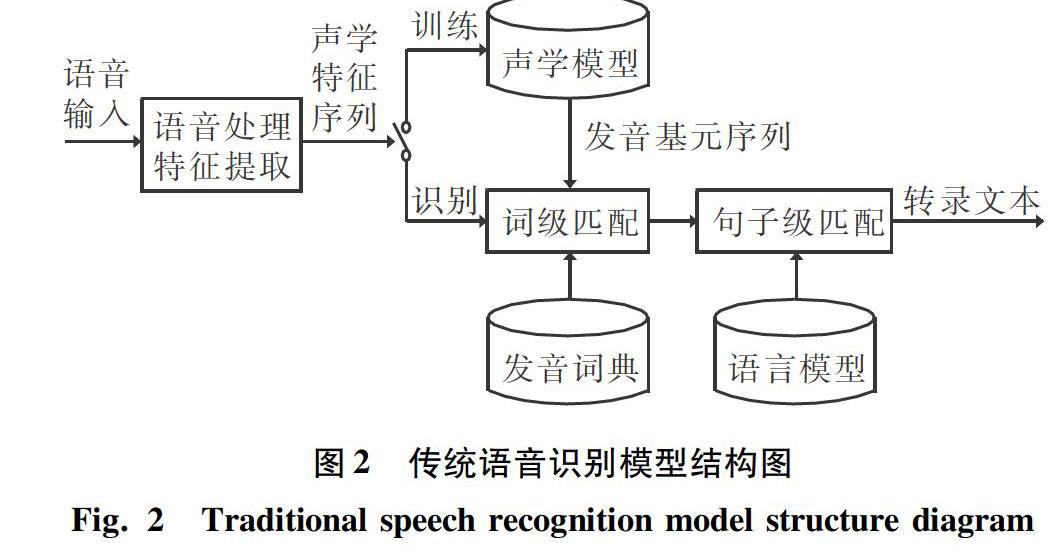
實際上傳統的語音識別模型也會出現上述問題。傳統語音識別模型結構如圖2所示。由圖2可知,在傳統語音識別模型中,通常采用獨立的聲學模型和語言模型分別建模聲學信息和語言學信息。首先,使用聲學模型去識別每一個發音基元,將輸入的聲學特征序列轉化為發音基元序列;然后,在發音詞典和語言模型的幫助下,通過搜索算法在發音基元序列中得到一條最佳路徑,這條最佳路徑就對應了識別的轉錄文本序列。對于容易出錯的詞,語言模型沒有見過或者很少見過這種搭配,導致搜索算法計算出的概率得分很低。所以要提高語音識別模型的識別準確率,就必須重新擴充語言模型部分,旨在使模型對容易出錯的詞也能計算出一個比較高的概率得分。因此傳統的語音識別模型可以利用比訓練集的轉錄文本多幾個數量級的純文本數據,來單獨訓練語言模型部分,以更新語言學的知識,從而保持聲學模型部分不動。然而,通過擴充語言模型的方式并不適用于RNN-T模型,因為在RNN-T模型中訓練數據和擴充數據都必須是平行的文本和語音對。
1.2用BERT模型替換預測網絡
根據1.1節中的分析,RNN-T模型在實際應用中表現不好是因為缺乏訓練數據,進而導致模型的語言學信息建模不充分。而RNN-T的預測網絡所提供的上下文信息,只能在一定程度上緩解這種劣勢。鑒于傳統語音識別方法可以直接用大量文本數據單獨訓練語言模型部分,從而擴充模型的語言學信息,在RNN-T模型中,編碼器部分相當于聲學模型,預測網絡相當于語言模型。參考傳統語音識別方法的經驗,直觀有效的方法就是對預測網絡進行擴充。因此,本文提出使用更強大的語言模型來替換RNN-T模型的預測網絡部分,以在推理時提供更具表示性的語言學信息。
BERT模型是目前對語言學信息建模最好的語言模型[20],與其它語言模型不同,BERT采用雙向語言模型的方式,能夠更好地融合上下文的信息。同時,預訓練的BERT模型在實際使用時,只需要根據具體任務額外加入一個輸出層進行微調即可,而不用為特定任務來修改模型結構。本文使用BERT模型來替換RNN-T模型的預測網絡部分,使聯合網絡在進行解碼的過程中,通過BERT模型引入外部的語言學信息來進行輔助解碼。網絡結構如圖3所示。替換后的模型在進行解碼時,由預測網絡提供當前時刻的上下文向量變為由BERT模型提供對應信息。
1.3微調RNN-T模型
1.2節中介紹的將BERT模型與RNN-T模型進行結合的方法,通過使用BERT模型替換RNN-T模型的預測網絡部分,實現了在推理時利用BERT模型提供的語言學信息。
然而實驗結果表明,直接替換的方法會導致模型的識別性能下降,這是因為BERT沒有參與訓練,只是在RNN-T模型進行解碼時提供相應信息,從而導致了BERT模型和RNN-T的編碼器部分不匹配。例如,t-1時刻聯合網絡預測的字符為“新”,而BERT模型預測下一個字符是“冠”,但語料庫中并沒有這個詞,這就導致聯合網絡沒有見過BERT模型提供的信息,從而出現錯誤。
解決方法是微調RNN-T模型。具體來說,就是在用BERT模型替換掉RNN-T的預測網絡部分后,再用訓練語料庫重新訓練一遍整個模型。在這個過程中BERT模型參與了訓練,使聯合網絡逐漸適應BERT模型提供的信息,進而使編碼器和BERT模型相互匹配。
2實驗與結果分析
2.1實驗數據
實驗基于2種普通話語料庫:AISHELL-1[21]和AISHELL-2[22]。其中,AISHELL-1包含180h語音數據,AISHELL-2包含1000h語音數據。使用Kaldi提取40維的FBank特征,每個特征都被重新調整為在訓練集上具有零均值和單位方差。
在實驗中,本文使用AISHELL-1訓練RNNT模型,將AISHELL-2的轉錄文本作為文本數據集,訓練BERT模型。
2.2模型結構和實驗設置
在基線RNN-T模型中,編碼器由5層雙向長短時記憶(BidirectionalLongShort-TermMemory,BLSTM)網絡組成,每層有700個單元,正向和反向各有350個單元。預測網絡由700個門控循環單元(GatedRecurrentUnit,GRU)的單層組成,聯合網絡結合了聲學和語言學信息,由700個單元的單向前饋網絡組成,使用tanh作為激活函數。
在實驗設置方面,模型采用聲學特征作為輸入,標注文本作為輸出序列,實現端到端的語音識別模型;模型直接進行解碼,以提取輸出字符序列,而無需使用單獨的發音模型或外部語言模型;采用字錯誤率(CharacterErrorRate,CER)作為語音識別效果的評價指標。
2.3實驗結果與分析
本文的實驗結果見表1。RNNTransducer是使用AISHELL-1數據集訓練的基線模型。RNNTransducer*模型是用BERT模型替換RNN-T模型中的預測網絡部分,并在推理時提供語言學信息的結果,可以發現字錯誤率大幅度上升。這是因為BERT模型并沒有參與訓練,只是在RNN-T模型解碼時提供相應信息,導致BERT模型和RNN-T的編碼器部分不匹配。RNNTransducer+Bert是用AISHELL-1數據集對整個模型進行重訓練的結果,相當于對聯合網絡進行微調,使編碼器部分與BERT模型之間相互匹配。與基線模型比較后可知,本文提出的方法相對降低了5.2%的字錯誤率,提高了模型的識別性能。
3結束語
本文針對基于RNN-T的端到端語音識別模型,提出了一種與BERT模型進行結合的方法。該方法通過用BERT模型替換RNN-T中的預測網絡部分,對整個網絡進行微調,從而使RNN-T模型在訓練和解碼過程中能夠有效利用BERT提供的語言學信息,進而提高模型的識別性能。最后,在AISHELL中文普通話數據集上對所提出的方法進行了評估,實驗結果表明,該方法能夠獲得更好的ASR性能。
參考文獻
[1]韓紀慶,張磊,鄭鐵然.語音信號處理[M].2版.北京:清華大學出版社,2013.
[2]ALTER.語音識別進化簡史:從造技術到建系統[J].大數據時代,2019(9):50-59.
[3]PRABHAVALKARR,RAOK,SAINATHTN,etal.Acomparisonofsequence-to-sequencemodelsforspeechrecognition[C]//Interspeech.Stockholm,Sweden:dblp,2017:939-943.
[4]GRAVESA,GOMEZF.Connectionisttemporalclassification:Labellingunsegmentedsequencedatawithrecurrentneuralnetworks[C]//Proceedingsofthe23rdInternationalConferenceonMachineLearning.NewYork,USA:ACM,2006:369-376.
[5]MIAOY,GOWAYYEDM,METZEF.EESEN:End-to-endspeechrecognitionusingdeepRNNmodelsandWFST-baseddecoding[C]//2015IEEEWorkshoponAutomaticSpeechRecognitionandUnderstanding(ASRU).Dammam:IEEE,2015:167-174.
[6]GRAVESA.Sequencetransductionwithrecurrentneuralnetworks[J].arXivpreprintarXiv:1211.3711,2012.
[7]RAOK,SAKH,PRABHAVALKARR.Exploringarchitectures,dataandunitsforstreamingend-to-endspeechrecognitionwithRNN-transducer[C]//2017IEEEAutomaticSpeechRecognitionandUnderstandingWorkshop(ASRU).Okinawa,Japan:dblp,2017:193-199.
[8]CHANW,JAITLYN,LEQ,etal.Listen,attendandspell:Aneuralnetworkforlargevocabularyconversationalspeechrecognition[C]//2016IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Shanghai:IEEE,2016:4960-4964.
[9]BAHDANAUD,CHOROWSKIJ,SERDYUKD,etal.End-to-endattention-basedlargevocabularyspeechrecognition[C]//2016IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Shanghai:IEEE,2016:4945-4949.
[10]KARITAS,WATANABES,IWATAT,etal.Semi-supervisedend-to-endspeechrecognition[C]//Interspeech.Hyderabad,India:dblp,2018:2-6.
[11]BASKARMK,WATANABES,ASTUDILLORF,etal.Self-supervisedSequence-to-sequenceASRusingunpairedspeechandtext[C]//Interspeech.Graz,Austria:dblp,2019:3790-3794.
[12]RENDUCHINTALAA,DINGS,WIESNERM,etal.Multi-modaldataaugmentationforend-to-endASR[C]//Interspeech.Hyderabad,India:dblp,2018:2394-2398.
[13]HORIT,ASTUDILLOR,HAYASHIT,etal.Cycle-consistencytrainingforend-to-endspeechrecognition[C]//ICASSP2019-2019IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Brighton,UK:IEEE,2019:6271-6275.
[14]HAYASHIT,WATANABES,ZHANGYu,etal.Back-translation-styledataaugmentationforend-to-endASR[C]//2018IEEESpokenLanguageTechnologyWorkshop(SLT).Athens:IEEE,2018:426-433.
[15]MAASA,XIEZ,JURAFSKYD,etal.Lexicon-FreeconversationalspeechrecognitionwithNeuralNetworks[C]//ConferenceoftheNorthAmericanChapteroftheAssociationforComputationalLinguistics:HumanLanguageTechnologies.Colorado,USA:ACL,2015:345-354.
[16]HORIT,WATANABES,ZHANGYu,etal.AdvancesinjointCTC-attentionbasedend-to-endspeechrecognitionwithadeepCNNencoderandRNN-LM[C]//Interspeech.Stockholm,Sweden:dblp,2017:949-953.
[17]BAIYe,YIJiangyan,TAOJianhua,etal.Learnspellingfromteachers:Transferringknowledgefromlanguagemodelstosequence-to-sequencespeechrecognition[C]//Interspeech.Graz,Austria:dblp,2019:3795-3799.
[18]DEVLINJ,CHANGMingwei,LEEK,etal.Bert:Pre-trainingofdeepbidirectionaltransformersforlanguageunderstanding[J].arXivpreprintarXiv:1810.04805,2018.
[19]HOCHREITERS,SCHMIDHUBERJ.Longshort-termmemory[J].Neuralcomputation,1997,9(8):1735-1780.
[20]JIANGD,LEIX,LIW,etal.Improvingtransformer-basedspeechrecognitionusingunsupervisedpre-training[J].arXivpreprintarXiv:1910.09932,2019.
[21]BUHui,DUJiayu,NAXingyu,etal.Aishell-1:Anopen-sourcemandarinspeechcorpusandaspeechrecognitionbaseline[C]//201720thConferenceoftheOrientalChapteroftheInternationalCoordinatingCommitteeonSpeechDatabasesandSpeechI/OSystemsandAssessment(O-COCOSDA).Seoul,SouthKorea:IEEE,2017:1-5.
[22]DUJiayu,NAXingyu,LIUXuechen,etal.AISHELL-2:TransformingmandarinASRresearchintoindustrialscale[J].arXivpreprintarXiv:1808.10583,2018.
