基于電網運行數據集的有功網損評估優化
2021-05-12 10:51:30張軍宣鐵鋒吳磊
現代計算機 2021年7期
關鍵詞:發電機
張軍,宣鐵鋒,吳磊
(上海電力大學自動化工程學院,上海200090)
0 引言
有功損耗可以衡量電網的運行效率。對電網損耗的準確預估可以有效提高電力系統運行效率[1-3]。本文通過一種基于改進概率神經網絡的粒子群算法[4-5]來提高電網運行數據分類的有效性,從而更準確地評估電力系統的有功網損。依據模擬電網運行參數和實時數據,依次采用改進PNN 和改進K-means 算法對數據進行潮流計算[6,11-13],得到有效的電網有功損耗評估方法。由仿真結果可知,對電網損耗進行改進PNN 算法聚類分析,能夠降低網損評估誤差。
1 電網的有功網損評估模型
電力系統的有功網損是電網在電能傳輸工程中產生的電能損失。電能的損耗量是電力系統運行的經濟技術指標,降低網絡傳輸損耗,提高電能利用率,是有關電力部門的重要工作內容。
將發電機的開機個數、有功功率、無功功率,表示為電力系統運行的典型參數。運行方式與電力系統數據一一對應,對典型數據集進行潮流計算,最后可得電力系統典型運行方式下的網損。

式(1)中,F 代表總網損,k 表示典型方式的個數,plossi表示每組典型方式的網損,t 表示采樣間隔,Ci表示出現每組典型方式的概率。
選取發電機的開機個數、有功功率、無功功率,作為表征電力系統運行狀態的數據集。

其中xt為t時刻電網的運行數據。
xKJT表示t 時刻開機方式數據項,發電機運行時數值為1,發電機停止運行時數值為0。
xPGT表示t 時刻各發電機有功功率組成的向量。
xQGT表示t 時刻各發電機無功功率組成的向量。
2 基于改進粒子群算法的概率神經網絡
2.1 PNN的基本原理
概率神經網絡被廣泛應用于非線性濾波,模式分類中。此網絡用于檢測和模式分類時,可以得到貝葉斯最優化結果。如圖1 所示PNN 的結構圖和徑向基網絡函數結構類似,只是在第二層中有些差異。

圖1 PNN的網絡模型
2.2 建立改進PSO-PNN算法的運行數據集
采用基于粒子群優化的概率神經網絡對電網運行數據集進行聚類,步驟如下:
(1)提取電力大數據集各時間段的關鍵屬性數據。即發電機的開機個數,發電機的有功功率,發電機的無功功率,生成特征狀態下的電力系統運行方式數據集,表示待聚類數據集[1],即:

(2)在數據集里隨機選取A 作為初始點,假定最小個數為m,距離參數向量為R=XKG,XPG,XQG,其中XKG,XPG,XQG分別對應發電機的開機個數、有功功率、無功功率。
(3)對于數據Xt={ XKGT1,XPGT1,XQGT1}和數據Xt={ XKGT2,XPGT2,XQGT2},若滿足下式要求則認為Xt2在Xt1的R 鄰域內。

(4)采用步驟3 中的距離公式,判斷此初始點鄰域內的數據量,若數據量小于m,則判斷A 不是典型樣本,繼續(2)步驟;如果此數據量大于m,則判斷A 是典型樣本[1]。
(5)對于典型樣本,依據(7)式來計算聚類中心C1。

(6)把C1作為聚類中心,比較C1與數據對象xi的間距,若小于r,則xi歸為此類別中;否則判別下一個數據,直到判斷所有數據對象,同時以C1為聚類中心的數據歸為一類。
(7)產生第一個類別T1后,把此類數據刪除,并且此類數據不參與下次分類,保證數據的簡練。
(8)分類結果的前70%選取為訓練樣本數據,后30%的結果作為待確定類別的數據,調用ind2vec 函數,將類別轉換為PNN 可以使用的目標向量。
(9)采用粒子群尋優法尋找最優徑向徑函數的分布常數,范圍為30-260。
(10)調用newpnn,構建并訓練PNN,最終得到分類數據結果。
3 仿真算例分析
以燃氣輪機仿真平臺為模擬電網數據平臺。電力系統的運行方式由發電機的開機個數、有功功率、無功功率來表征。同時建立電力系統運行數據集,用改進PSO-PNN 聚類算法對運行數據進行聚類[1]。發電機組開機方式按照該機組實際狀態選取。若發電機運行,則數據項為1,若發電機停運,則數據項為0;仿真軟件及仿真平臺模擬負荷如圖2 所示。
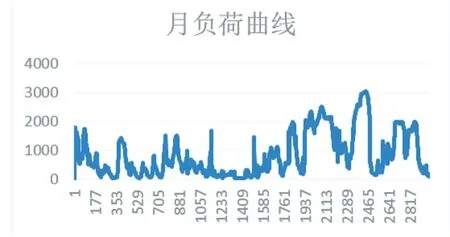
圖2 某地區單月負荷曲線圖
分別采用普通K-means 聚類算法,改進K-means聚類算法和基于粒子群算法的改進PNN 聚類算法對運行數據集進行聚類分析[1-2]。
首先對運行數據集進行K-means 聚類,圖3 為8個特征方式的聚類結果,圖4 為16 類的運行結果。

圖3 K-means聚類方法數據集聚類方式(類別數8)
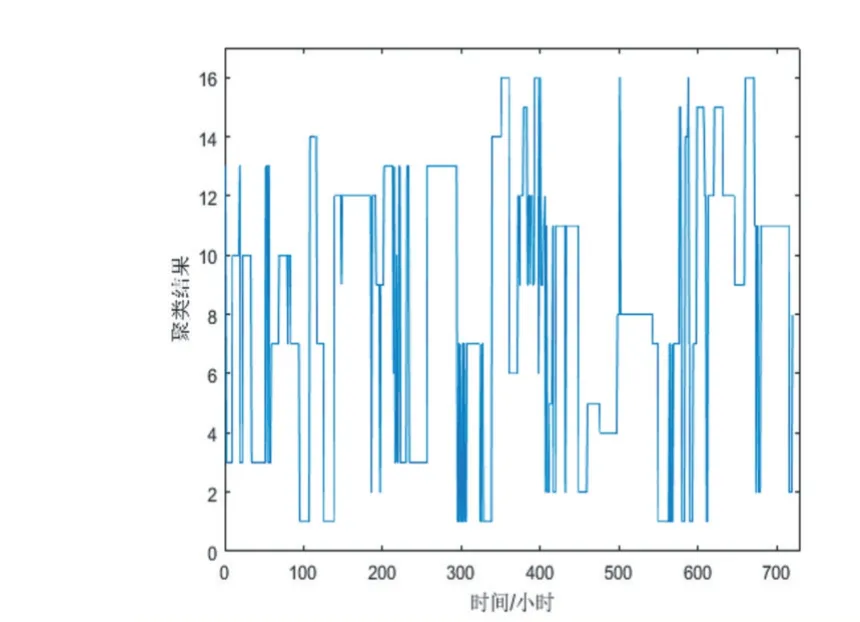
圖4 K-means聚類方法數據集聚類方式(類別數16)
有聚類分析可知,類別數為8 時,連續60 個運行方式被歸為一類,每組方式的間隔為1 小時,3 天內連續的電網運行數據被歸為一類,這對后期計算電網損耗會產生很大的誤差,當聚類數為16 時,依舊存在連續30 個運行方式被分成同一類,表明通過提高算法分類數無法解決關鍵數據屬性被淹沒的問題。
對數據集進行改進K-means 聚類,類別數為8 和16,如圖5、6 所示。
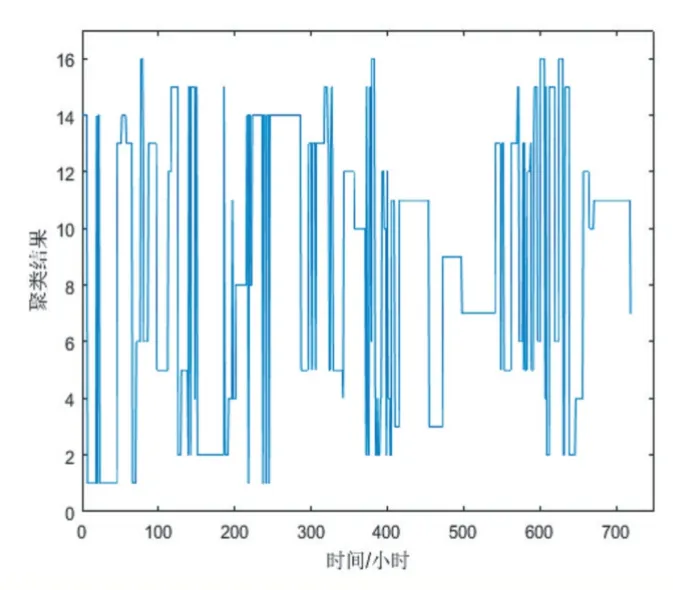
圖5 改進K-means聚類方法數據集聚類方式(類別數8)
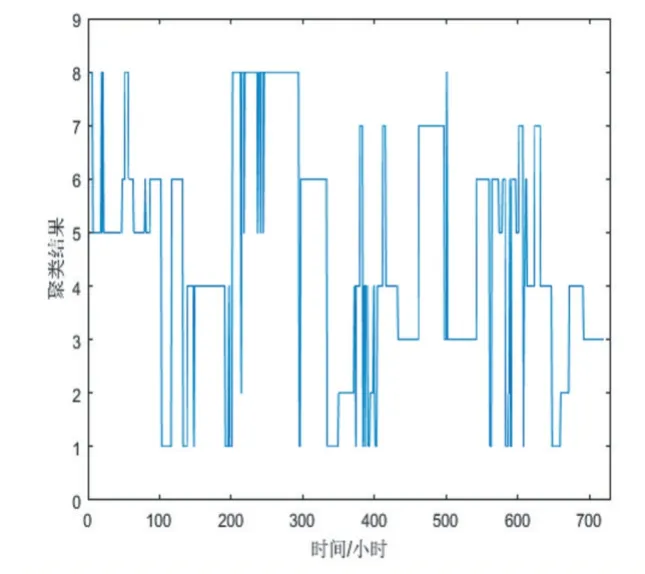
圖6 改進K-means聚類方法數據集聚類方式(類別數16)
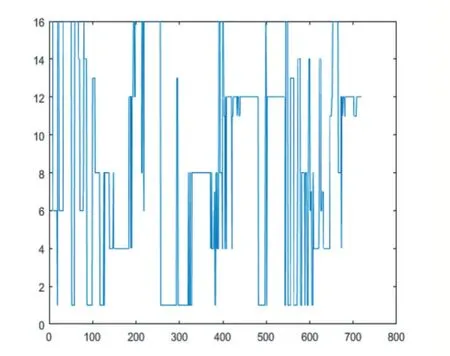
圖7 基于粒子群算法的改進PNN聚類方式
由數據分析可知,選用改進K-means 算法不能有效聚類。說明僅僅增加算法的迭代次數會增加誤差,也不能得到有效的分類。
最后采用基于粒子群算法改進概率神經網絡對運行數據集進行聚類。
采用帶斥力因子的改進粒子群算法對PNN 中的spread 參數尋優。
粒子的速度和位置更新公式為
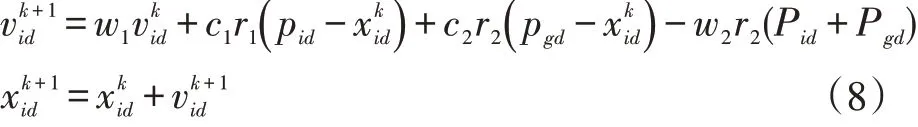
如圖7 所示,基于粒子群算法的改進PNN 算法可以明顯提高分類的細化程度,從而提高分類的有效性。隨著電網節點規模的增大,各節點出力的數據所對應的聚類屬性也相應的增加,從而產生高維聚類問題,導致掩蓋了一些關鍵數據屬性,通過本文所提的算法,可以有效解決這一問題。電力系統特征運行方式體現了電網數據屬性對網損評估的影響。
對模擬數據進行潮流計算,把不同發電機數據屬性作用下的網損作為實際網損量。比較不同算法的網損結果。
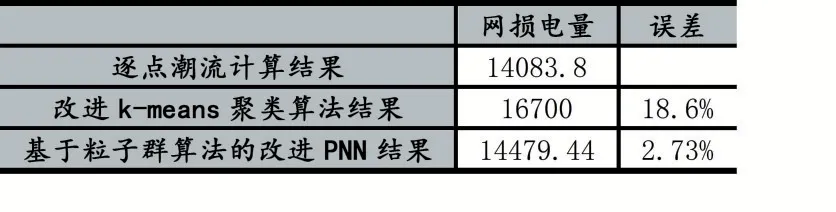
表1 不同算法網損評估比較
4 結語
本文用改進PSO-PNN 算法評估電網網損,對電網損耗評估進行整合。
(1)依據發電機數據屬性和負荷屬性,并用改進PNN 算法進行驗證,分析結果表明,本文算法能夠有效降低網損評估。
(2)比較K-means 聚類算法,選用改進K-means的聚類結果,作為改近PNN 算法的測試數據集,增加了數據集聚類的準確性,同時采用粒子群最優算法,選取了最優的spread 參數,使得聚類效果最優。
猜你喜歡
故事作文·高年級(2021年12期)2021-12-21 02:32:35
大電機技術(2017年3期)2017-06-05 09:36:02
軍事文摘(2016年16期)2016-09-13 06:15:49
廣西電力(2016年6期)2016-07-10 12:03:37
通信電源技術(2016年5期)2016-03-22 01:09:38
智能建筑電氣技術(2015年5期)2015-12-10 05:52:30
電測與儀表(2015年13期)2015-04-09 11:57:12
電測與儀表(2015年2期)2015-04-09 11:29:14
水電站機電技術(2014年6期)2014-09-26 12:07:48
水電站機電技術(2014年1期)2014-09-26 11:59:45
