基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型構(gòu)建
2021-05-12 02:59:46王鈺,劉磊
電子設(shè)計(jì)工程 2021年8期
王 鈺,劉 磊
(北京科東電力控制系統(tǒng)有限責(zé)任公司,北京 100085)
目前,網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)具有數(shù)量龐大、種類多、結(jié)構(gòu)復(fù)雜等問題[1]。傳統(tǒng)的數(shù)據(jù)分類方法對(duì)相近數(shù)據(jù)不能準(zhǔn)確分類,給數(shù)據(jù)的搜索和查詢帶來(lái)困擾,將海量的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)進(jìn)行精準(zhǔn)劃分成為當(dāng)前數(shù)據(jù)管理的一大難題[2-3]。文中通過構(gòu)建基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型,明確模型的工作流程,采用特征擴(kuò)展算法生成數(shù)據(jù)特征向量空間,通過計(jì)算數(shù)據(jù)的權(quán)值和表達(dá)能力準(zhǔn)確分類,能夠處理相近數(shù)據(jù),根據(jù)數(shù)據(jù)的特征量進(jìn)行準(zhǔn)確分類,有助于加強(qiáng)對(duì)數(shù)據(jù)的管理且對(duì)數(shù)據(jù)的處理速度較快,適合未來(lái)互聯(lián)網(wǎng)的發(fā)展。
1 網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型
基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型如圖1 所示。
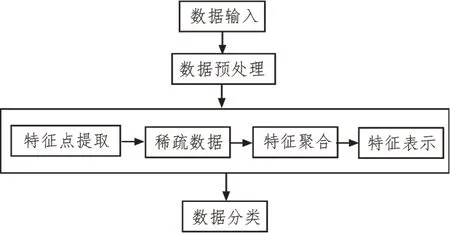
圖1 網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型
從圖1 可以看出,對(duì)于網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù),其特征分類包括以下步驟:
1)對(duì)于輸入網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù),提取其特征點(diǎn),得到的數(shù)據(jù)特征點(diǎn)集合為F。
2)根據(jù)特征擴(kuò)展算法,利用稀疏分解算法稀疏網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù),得到的稀疏數(shù)據(jù)集合為D,集合F和集合D的關(guān)系為:F=nD。
3)聚合所有的稀疏數(shù)據(jù),生成數(shù)據(jù)集W,則W=Pooling(F)。
4)采用平方根聚合方法對(duì)數(shù)據(jù)進(jìn)行聚合處理,聚合計(jì)算的公式為:
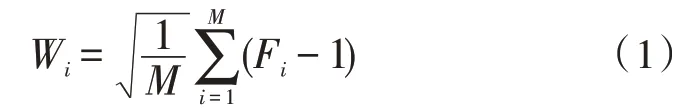
其 中,Wi表示稀疏數(shù)據(jù)W的第i個(gè)元素,m為輸入網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)中的特征點(diǎn)總數(shù);Fi表示稀疏數(shù)據(jù)Wi在特征點(diǎn)集合F中的第i個(gè)特征點(diǎn),在對(duì)所有稀疏數(shù)據(jù)進(jìn)行聚合后,得到的數(shù)據(jù)稀疏向量表示為:
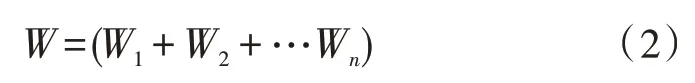
根據(jù)稀疏數(shù)據(jù)的表達(dá)進(jìn)行網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)的分類,采用概念樹、權(quán)值計(jì)算和表達(dá)計(jì)算,表現(xiàn)網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)的特征,根據(jù)數(shù)據(jù)特征進(jìn)行分類和保存[4-5]。
5)將保存的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)進(jìn)行編號(hào),方便提取和查詢。
基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型具有以下優(yōu)點(diǎn):首先模型將網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)特征映射到向量空間,有利于特征擴(kuò)展和表現(xiàn);其次,通過精準(zhǔn)計(jì)算,能夠減少分類誤差,且計(jì)算速度較快,提升了數(shù)據(jù)關(guān)聯(lián)度處理能力;最后,數(shù)據(jù)分類后在各個(gè)數(shù)據(jù)庫(kù)上標(biāo)注類別和編號(hào),有利于后期的數(shù)據(jù)調(diào)取和查詢[6-7]。
2 基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類方法
2.1 特征擴(kuò)展算法
輸入:網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù),生成待測(cè)數(shù)據(jù)文件。
輸出:網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)特征擴(kuò)展之后的特征向量空間[8-10]。
1)對(duì)于待測(cè)網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)中的任一個(gè)特征項(xiàng),計(jì)算特征項(xiàng)的最小置信度和最小支持度,計(jì)算公式如式(3)和式(4)所示。
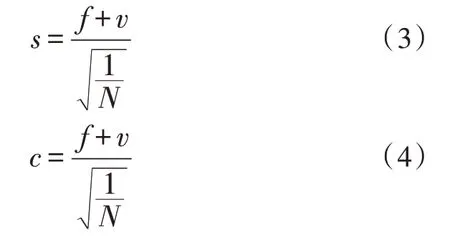
式中,f表示總體真值;v表示標(biāo)準(zhǔn)真值;N表示待測(cè)網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)總數(shù)量;
2)將具有最小執(zhí)行度和最小支持度的特征項(xiàng)生成查詢特征共現(xiàn)集,將查詢特征共現(xiàn)集中的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)定義為規(guī)則特征項(xiàng),計(jì)算每個(gè)項(xiàng)的規(guī)則度,規(guī)則度H的計(jì)算方式如式(5)所示。
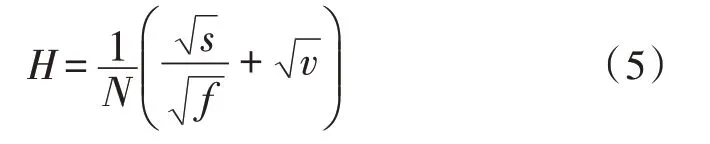
3)若H值大于設(shè)置的規(guī)則度閾值,則可認(rèn)為該規(guī)則特征項(xiàng)為規(guī)則項(xiàng);若在查詢特征共現(xiàn)集中存在唯一規(guī)則項(xiàng),將執(zhí)行步驟4);若存在兩個(gè)或兩個(gè)以上規(guī)則項(xiàng),將執(zhí)行步驟5);
4)將唯一規(guī)則項(xiàng)列入特征空間集中;
5)匹配網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)特征;
6)特征空間集中的數(shù)據(jù)生成特征向量空間,繼續(xù)計(jì)算下一組網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)[11-13]。
2.2 網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類
經(jīng)過特征擴(kuò)展后的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)特征向量存在較多的干擾因素,由于網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)之間的相似度,影響了網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)的特征表達(dá)能力,數(shù)據(jù)分析能夠提升數(shù)據(jù)的表達(dá)能力,更利于實(shí)現(xiàn)數(shù)據(jù)分類和查詢[14-15]。
首先,概念樹通過數(shù)據(jù)的屬性分析進(jìn)行其數(shù)據(jù)的概念描述,定義網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)的屬性權(quán)值公式如式(6)所示。

其中,n為該數(shù)據(jù)在概念樹中的位置;I為概念樹的編號(hào)總集;Deep表示該數(shù)據(jù)在概念樹中的重要性;在公式中加1 的目的在于調(diào)節(jié)網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)的權(quán)值,使權(quán)值始終為正,避免權(quán)值為負(fù)導(dǎo)致的復(fù)雜計(jì)算[16]。
由于數(shù)據(jù)具有相似性,相似數(shù)據(jù)間差別不大,為對(duì)數(shù)據(jù)進(jìn)行精準(zhǔn)分類,在計(jì)算過網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)的權(quán)值后,對(duì)其表達(dá)能力進(jìn)行計(jì)算,如式(7)所示:
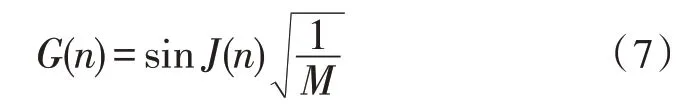
根據(jù)網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)的表達(dá)能力,將其特征值充分表達(dá),根據(jù)表達(dá)特征值的不同進(jìn)行合理分類。
3 實(shí)驗(yàn)與研究
文中實(shí)驗(yàn)研究利用構(gòu)建的網(wǎng)構(gòu)軟件平臺(tái)作為實(shí)驗(yàn)研究中心,以網(wǎng)構(gòu)系統(tǒng)為關(guān)鍵計(jì)算單元進(jìn)行平臺(tái)開發(fā),集成符合FIPA 標(biāo)準(zhǔn)的網(wǎng)構(gòu)測(cè)試數(shù)據(jù)分類空間,對(duì)該空間進(jìn)行自主性開發(fā)與自適應(yīng)演化檢測(cè)。采用Spring 平臺(tái),支持實(shí)驗(yàn)中的分類模型自適應(yīng)設(shè)計(jì)操作,同時(shí)供給模型構(gòu)建圖形化界面、構(gòu)架代碼研發(fā)、分類模型管理等工具,在模型構(gòu)建的過程中時(shí)刻連接外部接口API。構(gòu)建的實(shí)驗(yàn)檢測(cè)平臺(tái)框架如圖2 所示。
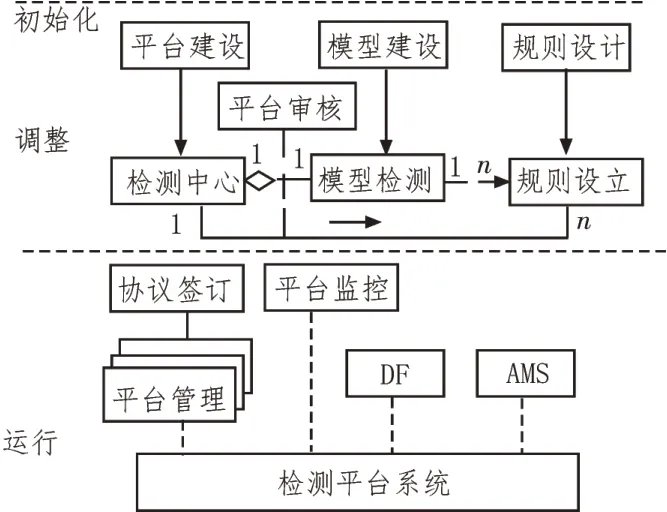
圖2 實(shí)驗(yàn)檢測(cè)平臺(tái)框架圖
實(shí)驗(yàn)過程中的操作平臺(tái)分為兩個(gè)層次:實(shí)驗(yàn)運(yùn)行層與構(gòu)建結(jié)果檢驗(yàn)層。平臺(tái)內(nèi)部包含AMS 部件,負(fù)責(zé)內(nèi)部平臺(tái)實(shí)驗(yàn)數(shù)據(jù)信息間的通訊、數(shù)據(jù)分類信息管理以及平臺(tái)運(yùn)轉(zhuǎn)生命周期的管理。
在實(shí)驗(yàn)組集中引入特征項(xiàng)共現(xiàn),有效擴(kuò)展測(cè)試數(shù)據(jù)的測(cè)試特征。獲得深層模型的測(cè)試含義,利用數(shù)據(jù)共現(xiàn)模型對(duì)網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)進(jìn)行平臺(tái)共享操作,將共享功能與實(shí)驗(yàn)檢測(cè)平臺(tái)的網(wǎng)絡(luò)任務(wù)相連。在大規(guī)模的數(shù)據(jù)實(shí)驗(yàn)收集中,對(duì)于兩個(gè)經(jīng)常出現(xiàn)的測(cè)試指標(biāo),應(yīng)將其轉(zhuǎn)錄至統(tǒng)一平臺(tái)窗口單元中等待檢測(cè)處理。當(dāng)經(jīng)過檢測(cè)處理后的單元窗口產(chǎn)生數(shù)據(jù)共組現(xiàn)象時(shí),則表示被檢測(cè)的測(cè)試指標(biāo)在意義上有著較為密切的關(guān)聯(lián)。共現(xiàn)概率越高,表明數(shù)據(jù)間的相互關(guān)聯(lián)系數(shù)越高。
依照關(guān)聯(lián)程度對(duì)經(jīng)過分類模型分類后的數(shù)據(jù)相似度進(jìn)行對(duì)比,并構(gòu)建實(shí)驗(yàn)對(duì)比圖。將數(shù)據(jù)共現(xiàn)模型引入分類特征擴(kuò)展中,挖掘訓(xùn)練集特征組合與樣本集特征組合間的關(guān)系。利用FP 算法計(jì)算特征項(xiàng)組合共現(xiàn)數(shù)值,將特征項(xiàng)組合看作事務(wù)項(xiàng),測(cè)試數(shù)據(jù)看作事務(wù),可以在給定的最小支撐度閾值與置信度閾值之下找出組合的特征項(xiàng)數(shù)據(jù)間的關(guān)聯(lián)關(guān)系原則,關(guān)聯(lián)關(guān)系下的關(guān)系原則可表示特征項(xiàng)數(shù)據(jù)的共現(xiàn)程度,由此獲取相應(yīng)的分類程度。分類數(shù)據(jù)相似度對(duì)比如圖3 所示。
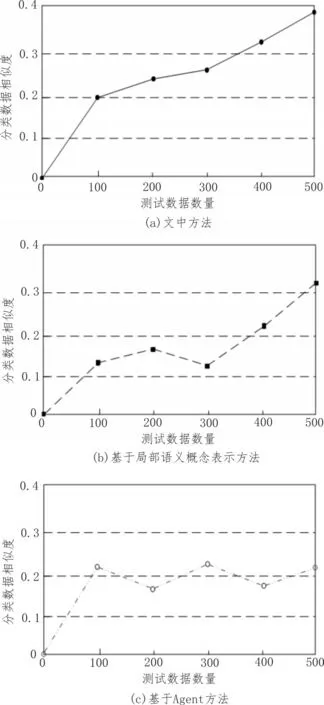
圖3 分類數(shù)據(jù)相似度對(duì)比圖
根據(jù)圖3,文中基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型構(gòu)建方法的分類數(shù)據(jù)相似度明顯優(yōu)于傳統(tǒng)方法的分類數(shù)據(jù)相似度。由于文中構(gòu)建方法引用DF 部件在測(cè)試數(shù)據(jù)內(nèi)部調(diào)節(jié)網(wǎng)構(gòu)軟件的組件形式,結(jié)合EBDI 結(jié)構(gòu)綁定分類模型關(guān)系,根據(jù)模型實(shí)體測(cè)試信念以及動(dòng)作更改信念組成分類集合與動(dòng)作集合,時(shí)刻掌握網(wǎng)構(gòu)軟件的調(diào)整狀態(tài)。在算法操作伊始,轉(zhuǎn)變選擇函數(shù)操作意圖,及時(shí)反映測(cè)試數(shù)據(jù)的測(cè)試環(huán)境,排除測(cè)試阻礙因素,具有良好的數(shù)據(jù)共現(xiàn)數(shù)值。隨時(shí)調(diào)整測(cè)試指標(biāo),將標(biāo)準(zhǔn)指標(biāo)與測(cè)試數(shù)據(jù)相融合,在特征擴(kuò)展的環(huán)境中分析擴(kuò)展特征項(xiàng)與數(shù)據(jù)集合間的關(guān)系,提高對(duì)關(guān)系的管理力度。實(shí)施動(dòng)態(tài)演化運(yùn)行機(jī)制,給出一致性操作原則與分類管理原則,固定分類模型的構(gòu)建步驟,防止步驟錯(cuò)亂導(dǎo)致模型構(gòu)建失誤。由此,獲取嚴(yán)謹(jǐn)科學(xué)的模型構(gòu)建數(shù)據(jù),提升其最終測(cè)試的分類相似度。
在分析所構(gòu)建模型的分類相似度后,研究文中方法的召回率。在實(shí)驗(yàn)空間中輸入特征共現(xiàn)集數(shù)值,設(shè)置關(guān)聯(lián)規(guī)則抽取閾值,并管理閾值的設(shè)置范圍,控制閾值數(shù)值處于10~100 之間。在經(jīng)過測(cè)試數(shù)據(jù)特征擴(kuò)展后,對(duì)信息進(jìn)行分類并將其輸出至特征向量空間中。在測(cè)試數(shù)據(jù)集中的任意一個(gè)特征項(xiàng)組合中,若在實(shí)驗(yàn)查詢的過程中產(chǎn)生共現(xiàn)集,則表示該過程存在唯一的一個(gè)規(guī)則項(xiàng)信息。
此時(shí),提升設(shè)定的閾值參數(shù)數(shù)值,直至其數(shù)值大于標(biāo)準(zhǔn)閾值參數(shù)數(shù)值,執(zhí)行關(guān)聯(lián)規(guī)則右部的特征項(xiàng)信息。在接收控制檢驗(yàn)的實(shí)驗(yàn)空間中配置SVM分類器,同時(shí)提升分類器的操作效率,防止因設(shè)備改變而產(chǎn)生的數(shù)據(jù)分類失敗狀況。交叉驗(yàn)證處于不同位置空間測(cè)試數(shù)據(jù)分類模型的運(yùn)行狀態(tài),當(dāng)運(yùn)行狀態(tài)的動(dòng)力供給量較小時(shí),將分類模式調(diào)整為低級(jí)模式,當(dāng)運(yùn)行狀態(tài)的動(dòng)力供給量較大時(shí),將分類模式調(diào)整為高級(jí)模式。由于測(cè)試的數(shù)據(jù)設(shè)計(jì)網(wǎng)構(gòu)軟件的內(nèi)部系統(tǒng)運(yùn)行操作,為此,在對(duì)測(cè)試數(shù)據(jù)進(jìn)行調(diào)整后方可執(zhí)行檢測(cè)指令。
在實(shí)現(xiàn)以上操作后,對(duì)分類得出的召回率進(jìn)行對(duì)比,得到召回率對(duì)比如表1~3 所示。

表1 文中方法召回率

表2 基于局部語(yǔ)義概念表示的方法召回率

表3 基于Agent方法的召回率
從表中可以看出,文中基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型構(gòu)建方法召回率指標(biāo)均高于其他兩種模型構(gòu)建方法,表示文中方法的分類性能更高,有利于分類模型的構(gòu)建。文中在分類模型構(gòu)建的同時(shí)調(diào)節(jié)算法分析狀態(tài),動(dòng)態(tài)綁定模型信息,具有良好的模型掌控性能,可在產(chǎn)生分類準(zhǔn)則的前提下執(zhí)行分類指令,提升整體分類標(biāo)準(zhǔn),獲取更高的分類結(jié)果。
4 結(jié)束語(yǔ)
文中構(gòu)建的基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型能夠有效解決數(shù)據(jù)的分類問題,不僅為數(shù)據(jù)的提取和查詢,而且為其他領(lǐng)域數(shù)據(jù)的管理提供了借鑒方法,拓寬了特征擴(kuò)展的應(yīng)用領(lǐng)域,更促進(jìn)了我國(guó)大數(shù)據(jù)技術(shù)的發(fā)展。實(shí)驗(yàn)結(jié)果表明,文中基于特征擴(kuò)展的網(wǎng)構(gòu)軟件測(cè)試數(shù)據(jù)分類模型構(gòu)建方法可及時(shí)調(diào)節(jié)分類模型信息,利用特征項(xiàng)尋找共現(xiàn)指標(biāo),由此獲取較優(yōu)的分類效果,具有良好的發(fā)展前景。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52

- 電子設(shè)計(jì)工程的其它文章
- 基于DSP 曼徹斯特編解碼的過套管電纜通信系統(tǒng)設(shè)計(jì)
- 電力企業(yè)分級(jí)分類的分布式云存儲(chǔ)系統(tǒng)的研究與實(shí)現(xiàn)
- 基于時(shí)空大數(shù)據(jù)挖掘的網(wǎng)絡(luò)輿情研判方法研究
- 基于STC89C52 單片機(jī)的自動(dòng)換氣扇系統(tǒng)設(shè)計(jì)
- 基于WindowsCE 的電網(wǎng)大型設(shè)備運(yùn)輸狀態(tài)實(shí)時(shí)監(jiān)測(cè)系統(tǒng)設(shè)計(jì)
- 基于Mesh 網(wǎng)絡(luò)和深度學(xué)習(xí)的城市智慧停車