深度學(xué)習(xí)說話人識別中語音特征參數(shù)提取研究
2021-05-13 07:16:00張興明楊凱
現(xiàn)代計算機(jī) 2021年8期
張興明,楊凱,2
(1.四川大學(xué)視覺合成圖形圖像技術(shù)國防重點(diǎn)學(xué)科實(shí)驗(yàn)室,成都610065;2.四川川大智勝軟件股份有限公司,成都610045)
0 引言
近年來隨著深度學(xué)習(xí)技術(shù)的迅猛發(fā)展和計算機(jī)硬件設(shè)備的計算能力大幅提升,生物特征識別技術(shù)的研究進(jìn)展迅猛。部分生物特征識別技術(shù)已趨于成熟,逐漸在從學(xué)術(shù)研究階段走向商業(yè)應(yīng)用階段。在眾多生物特征識別技術(shù)中,聲紋識別技術(shù)相比于其他生物特征識別技術(shù),它有著其獨(dú)特的優(yōu)勢:安全性高、隱私性弱、采集便捷、非必須接觸等。正是由于聲紋識別所具有的這些獨(dú)特優(yōu)勢及其應(yīng)用價值,使得越來越多的研究者投入到聲紋識別技術(shù)的研究中。
近年來,得益于深度學(xué)習(xí)技術(shù)強(qiáng)大的學(xué)習(xí)能力,使得基于深度學(xué)習(xí)的說話人識別研究成為說話人識別領(lǐng)域的一個研究熱點(diǎn)。2014 年Google 提出了d-vector[1]識別模型,它將Filterbank 特征參數(shù)作為模型輸入,使用DNN 網(wǎng)絡(luò)構(gòu)建了一個簡單的識別模型,將最后一個隱藏層作為說話人特征。它僅使用一個簡單的網(wǎng)絡(luò)模型,就取得了不錯的識別效果。d-vector 對說話人識別研究貢獻(xiàn)巨大,它掀起了基于深度學(xué)習(xí)的說話人識別研究熱潮。通過閱讀相關(guān)文獻(xiàn),發(fā)現(xiàn)大多數(shù)研究使用的是單一的傳統(tǒng)語音特征作為模型輸入數(shù)據(jù),x-vector[2]識別模型使用24 維Filterbank 特征參數(shù),h-vector[3]識別模型使用20 維的MFCC 特征參數(shù),百度在2017 年提出的deepSpeaker[4]系統(tǒng)使用的是64 維的Filterbank 特征。還有少數(shù)研究使用神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)語音特征。Chen Nanxin 等人[5]提出的j-vector 識別模型使用深度神經(jīng)網(wǎng)絡(luò)來作為一個特征提取器,通過訓(xùn)練后該特征提取器可以學(xué)習(xí)得到語音特征。2018 年Ravanelli 等人[6]提出使用SincNet 來進(jìn)行說話人識別,該網(wǎng)絡(luò)直接從原始語音信號中自動學(xué)習(xí)語音特征,不依賴于傳統(tǒng)的手工特征。仲偉峰等人[7]提出了一種深淺層特征融合的方式來提取語音特征用于說話人識別,他們使用深度神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)語音的深層特征,然后將深層特征與淺層特征相結(jié)合一同作為語音特征。本文采用融合特征的方式來進(jìn)行特征參數(shù)提取,并設(shè)計了多種融合方式,以找到合適的特征提取方案,用于后續(xù)的說話人識別研究。
1 語音特征參數(shù)提取
在基于深度學(xué)習(xí)的說話人識別中,首先我們需要將語音信號轉(zhuǎn)換成可以作為模型輸入的數(shù)據(jù),且該輸入數(shù)據(jù)還必須要攜帶較多的說話人信息。之前的研究多采用的是單一的傳統(tǒng)語音特征參數(shù)來作為模型的輸入數(shù)據(jù)。常用于說話人識別的傳統(tǒng)特征有:梅爾倒譜特征參數(shù)、Filterbank 特征參數(shù)和語譜圖特征參數(shù)。
1.1 傳統(tǒng)語音特征參數(shù)
梅爾頻率倒譜系數(shù)(Mel Frequency Cepstrum Coefficient,MFCC)是基于人耳聽覺特性設(shè)計的,梅爾頻率倒譜頻帶劃分是在Mel 刻度上等距劃分的,頻率的尺度值與實(shí)際頻率的對數(shù)分布關(guān)系更符合人耳的聽覺特性,所以可以使得語音信號有著更好的表示。Filterbank 特征參數(shù)的提取方法就是在梅爾倒譜特征參數(shù)提取過程中去掉最后一步的離散余弦變換。與梅爾倒譜特征參數(shù)相比,F(xiàn)ilterbank 特征參數(shù)保留了更多的原始語音信息,且提取該特征參數(shù)時計算耗時較短。頻譜圖特征參數(shù)表示隨著時間變化,頻率與能量之間的關(guān)系,可以直觀的看到靜態(tài)和動態(tài)的信息。
1.2 多特征融合參數(shù)
既然大多數(shù)研究者大多使用了單一特征參數(shù)來進(jìn)行說話人識別研究,同時也證明了這種單一特征參數(shù)的方式是有效的,那么將這些單一特征進(jìn)行融合而生成的融合特征,其包含了更多的不同類型、不同維度的特征參數(shù),理論上,這些特征參數(shù)更加有利于模型從中提取出更加深層(抽象)的說話人特征。基于這樣的假設(shè),本文采取了多種特征融合方式,生成多種融合特征,來進(jìn)行對比研究。
1.3 數(shù)據(jù)處理及特征提取
對語音信號進(jìn)行分析,提取特征參數(shù)時,首先要進(jìn)行分幀和加窗處理。語音信號具有短時平穩(wěn)性,對語音信號的分析和處理須建立在“短時”的基礎(chǔ)上,即將一段語音信號分為多幀來分析其特征參數(shù),幀長一般取為10-30 毫秒。為了使幀與幀之間平滑過渡,保持其連續(xù)性,前一幀和后一幀會保留重合部分。后一幀對前一幀的位移量,簡稱為幀移。本文選取的幀長為25 毫秒,幀移為10 毫秒。分幀之后就要進(jìn)行加窗操作,本文采用漢明窗函數(shù)來進(jìn)行加窗操作。
語音進(jìn)行預(yù)處理之后就可以開始提取語音的特征參數(shù),本文提取了7 組不同的特征參數(shù)來進(jìn)行特征參數(shù)提取研究,它們分別是:20 維的MFCC 特征參數(shù)、20維的Filterbank 特征參數(shù)、128 維的語譜圖特征參數(shù)、40 維的MFCC 與Filterbank 融合特征參數(shù)、128 維的MFCC 與語譜圖融合特征參數(shù)、128 維的Filterbank 與語譜圖融合特征參數(shù)、128 維的全融合特征參數(shù)。各特征信息說明見表4。
2 說話人識別模型
本文為研究適合于深度學(xué)習(xí)說話人識別的語音特征參數(shù),基于卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)[8]構(gòu)建了一個淺層的說話人識別模型。整個模型由輸入層、卷積層、特征維度轉(zhuǎn)換層、平均池化層和全連接層構(gòu)成。其中,卷積層用于提取說話人的深層(抽象)特征,平均池化層用于將幀級特征轉(zhuǎn)換為語句級特征,全連接層主要用于特征降維。在訓(xùn)練時,以交叉熵作為損失函數(shù),最后一層采用Softmax 作為激活函數(shù),進(jìn)行一個多分類模型訓(xùn)練;在預(yù)測時,去除Softmax 層,將最后一個隱藏層得到的向量用來表示該語句對應(yīng)說話人的特征向量。根據(jù)輸入特征的參數(shù)維度的不同,模型的參數(shù)設(shè)置也有細(xì)微的不同。
輸入特征參數(shù)為128 維時的識別模型的結(jié)構(gòu)及其參數(shù)設(shè)置如表1 所示。
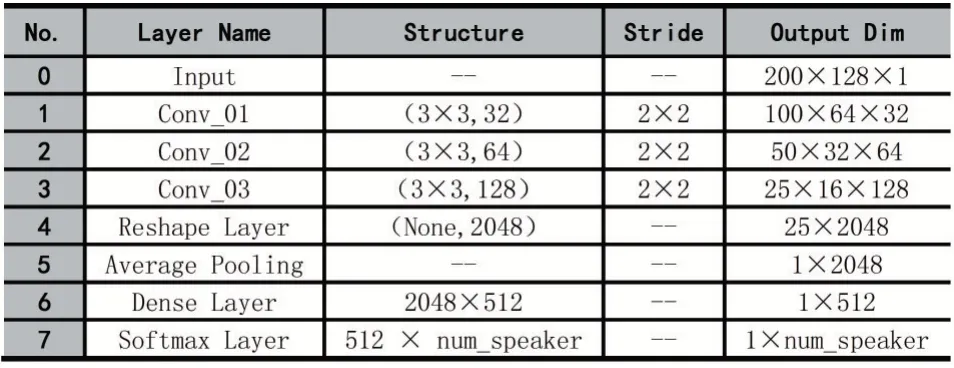
表1 128 維輸入特征時的識別模型參數(shù)配置
輸入特征參數(shù)為20(40)維時的識別模型的結(jié)構(gòu)及其參數(shù)設(shè)置如表2 所示。
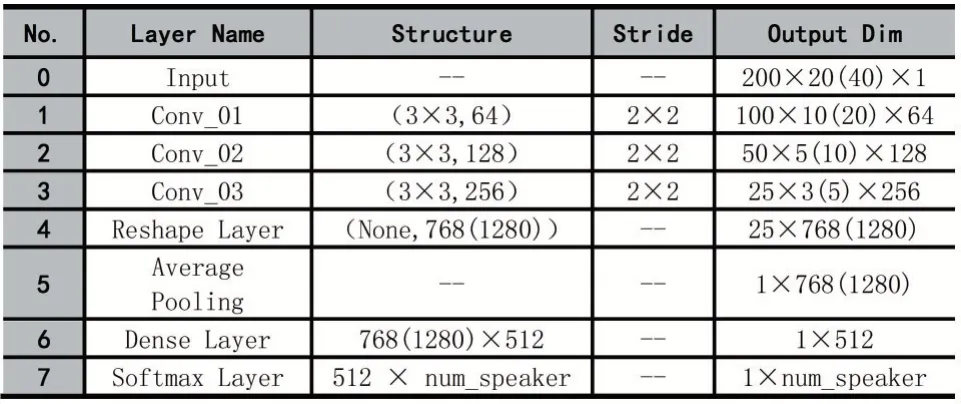
表2 20(40)維輸入特征時的識別模型參數(shù)配置
3 實(shí)驗(yàn)及結(jié)果分析
為了研究不同的語音特征參數(shù)作為模型輸入時對模型性能的影響,本文首先對數(shù)據(jù)集進(jìn)行處理,得到最終的實(shí)驗(yàn)數(shù)據(jù)集;然后設(shè)計不同的語音特征,提取出各自的特征參數(shù);接著搭建說話人識別模型,將不同的語音特征作為模型的輸入,經(jīng)過訓(xùn)練得到不同的模型;最后對各個模型進(jìn)行測試和分析,得出結(jié)論。
3.1 實(shí)驗(yàn)數(shù)據(jù)
本文實(shí)驗(yàn)數(shù)據(jù)采用Free ST Chinese Mandarin Corpus 公開數(shù)據(jù)集[9]。該數(shù)據(jù)集一共有855 個說話人的語音數(shù)據(jù),每個說話人120 條語音數(shù)據(jù),共計102600 條語音數(shù)據(jù)。對數(shù)據(jù)進(jìn)行預(yù)處理,首先檢查每條語音是否有效,去除其中損壞語音;接著進(jìn)行語音端點(diǎn)檢測(Voice Activity Detection),去除語音中的靜音部分,盡可能使每條語音中包含較多的說話人信息,本文使用的VAD 工具為:Google WebRTC VAD[10];最后去除時長小于1 秒的語音數(shù)據(jù),得到最終的數(shù)據(jù)集,包含854 位說話人,共計101974 條語音數(shù)據(jù)。為準(zhǔn)確驗(yàn)證不同語音特征對說話人識別效果的影響差異,將數(shù)據(jù)集按照8:2 的比例劃分為訓(xùn)練集和測試集(訓(xùn)練集和測試集中的說話人沒有任何交集)。訓(xùn)練集和測試集的統(tǒng)計如表3 所示。
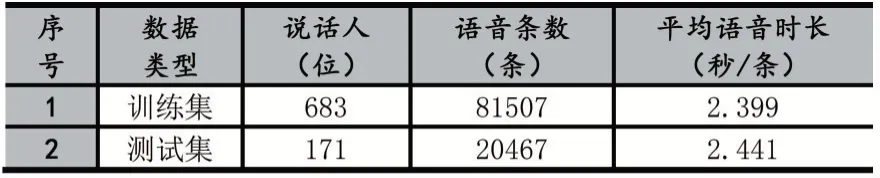
表3 數(shù)據(jù)集統(tǒng)計結(jié)果
3.2 實(shí)驗(yàn)評價標(biāo)準(zhǔn)
實(shí)驗(yàn)采用準(zhǔn)確率(Acc)、F1 值和等錯誤率(EER)對識別結(jié)果進(jìn)行評價。準(zhǔn)確率(Acc)和F1 值的計算方式如下:
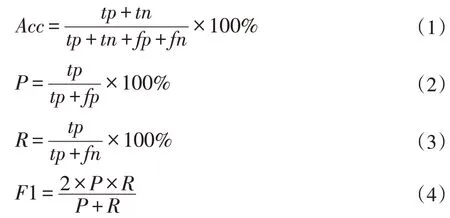
其中,tp 為模型正確將受試語音(該語音為注冊者語音)識別為注冊者的個數(shù);tn 為模型正確將受試語音(該語音非注冊者語音)識別為非注冊者的個數(shù);fp 為模型錯誤將受試語音(該語音非注冊者語音)識別為注冊者語音的個數(shù),fn 為模型錯誤將受試語音(該語音為注冊者語音)識別為非注冊者語音的個數(shù)。
在評定說話人識別系統(tǒng)時,有兩個非常重要的指標(biāo):錯誤拒絕率(False Rejection Rate,F(xiàn)RR)和錯誤接受率(False Acceptance Rate,F(xiàn)AR),其計算方式如下:

其中,Nfr和Nfa分別指測試中錯誤拒絕次數(shù)和錯誤接受的次數(shù),Ntarget和Nnon_target分別指測試中總的類內(nèi)測試(真實(shí)測試)次數(shù)和類間測試(冒認(rèn)測試)次數(shù)。當(dāng)系統(tǒng)中的閾值一定,F(xiàn)RR 與FAR 便確定。EER 為FRR等于FAR 時的錯誤率。
3.3 實(shí)驗(yàn)設(shè)置
實(shí)驗(yàn)采用TensorFlow 深度學(xué)習(xí)框架搭建了基于卷積神經(jīng)網(wǎng)絡(luò)的說話人識別模型。為了研究不同的語音特征參數(shù)作為模型輸入時對識別結(jié)果的影響,本文共設(shè)計了7 組不同的語音特征數(shù)據(jù)來作為模型的輸入數(shù)據(jù),訓(xùn)練7 個說話人識別模型。其詳細(xì)的信息如表4所示。
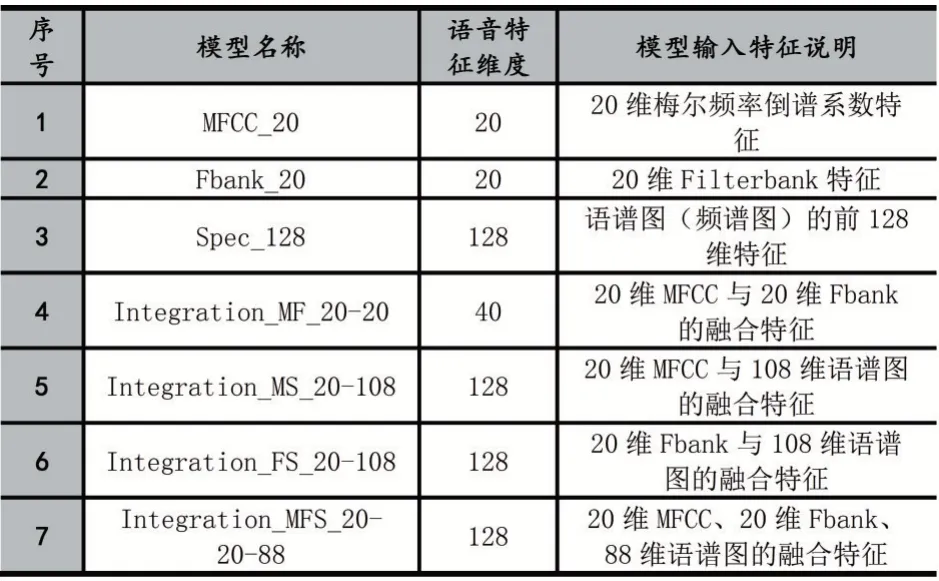
表4 模型及其對應(yīng)輸入的語音特征說明
訓(xùn)練集設(shè)置:訓(xùn)練集中共683 位說話人,為了保證訓(xùn)練出的模型可靠,以及便于觀察模型訓(xùn)練過程,進(jìn)一步將訓(xùn)練集按照8:2 的比例劃分為訓(xùn)練集和驗(yàn)證集,劃分后訓(xùn)練集共65163 條語音數(shù)據(jù),驗(yàn)證集共16344 條語音數(shù)據(jù)。
測試集設(shè)置:測試集中共171 位說話人,對每一位說話人進(jìn)行驗(yàn)證測試,即共有171 組測試。對于某一個說話人的測試,本文隨機(jī)選擇該說話人的1 條語音作為注冊語音,再隨機(jī)選取該說話人的50 條語音(不包含注冊語音)和150 位其他說話人的語音(3 條/人)作為驗(yàn)證語音,共計500 條驗(yàn)證語音。為了保證測試結(jié)果的準(zhǔn)確、可靠,本文采用隨機(jī)選取的方式選取了3組測試集。在后續(xù)的測試中,將這3 組測試集分別經(jīng)過每一個模型測試。
3.4 實(shí)驗(yàn)結(jié)果及分析
模型訓(xùn)練結(jié)束之后,根據(jù)之前的實(shí)驗(yàn)設(shè)置分別對每個模型在3 組測試集上進(jìn)行測試,以3 組測試結(jié)果的平均值作為該模型最終的測試結(jié)果。測試結(jié)果采用3.2 小節(jié)中所提到的公式計算,測試結(jié)果如表5 所示。

表5 模型測試結(jié)果
使用單語音特征參數(shù)作為模型的輸入數(shù)據(jù)時,128維的語譜圖特征:Spec_128 的效果最佳,在F1 得分和準(zhǔn)確率上均高于20 維的MFCC 特征與20 維的Filterbank 特征,在等錯率上也比其他兩項(xiàng)特征值的結(jié)果低。Spec_128 與MFCC_20 特征相比,在F1 分值上分別高1.56%,在準(zhǔn)確率上高出0.38%,在等錯率上降低了0.38%;Spec_128 與Fbank_20 特征相比,在F1 分值上高了3.83%,在準(zhǔn)確率上高了0.8%,在等錯率上降低了1.26%。使用多特征融合參數(shù)作為模型的輸入數(shù)據(jù)時,由三類單特征融合后形成的融合特征:Integration_MFS_20-20-88 具有最優(yōu)的效果,無論是與單特征相比,還是與其他融合特征相比,均取得了最優(yōu)的測試結(jié)果。與Integration_MF_20-20 特征相比,在F1 分值上高了4.57%,在準(zhǔn)確率上高出0.38%,在等錯率上降低了1.18%。與比Integration_MS_20-108 特征相比,在F1 分值上高了1.06%,在準(zhǔn)確率上高出0.22%,在等錯率上降低了0.29%。與比Integration_FS_20-108 特征相比,在F1 分值上高了2.41%,在準(zhǔn)確率上高出0.52%,在等錯率上降低了0.77%。
上面通過在三組測試集上的計算均值的方式給出了各個模型的測試結(jié)果,接下來觀察各個模型分別在三組不同測試集上的表現(xiàn)。在3 組測試集上分別繪制出DET 曲線,其繪制出的結(jié)果如圖1、圖2、圖3 所示。
通過在三組不同測試集上繪制出的DET 曲線,可以明顯看到,在三組測試集上,由MFCC 特征、Filterbank 特征、頻譜圖特征融合而成的128 維特征:Integration_MFS_20-20-88 均取得了最小的等錯率值。也再次證明了Integration_MFS_20-20-88 是最優(yōu)結(jié)果。
通過以上分析,可以得出結(jié)論:由MFCC 特征、Filterbank 特征、頻譜圖特征融合而成的128 維特征:Integration_MFS_20-20-88 能夠包含更多的淺層的說話人信息,有利于基于卷積神經(jīng)網(wǎng)絡(luò)的說話人模型從這些淺層信息中抽取出深層的說話人信息,從而得到一個優(yōu)秀的說話人識別模型。該語音特征可以用于后續(xù)的基于深度學(xué)習(xí)的說話人識別研究。
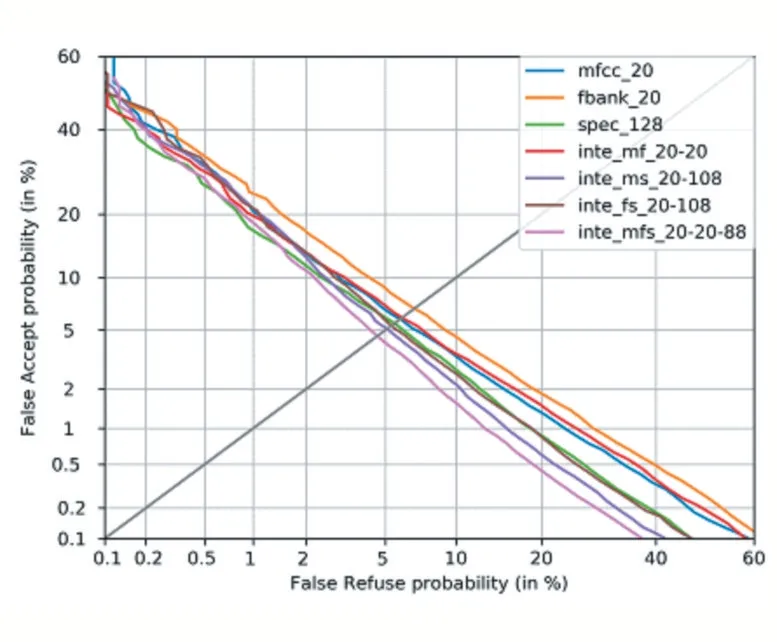
圖1 測試集1的DET曲線
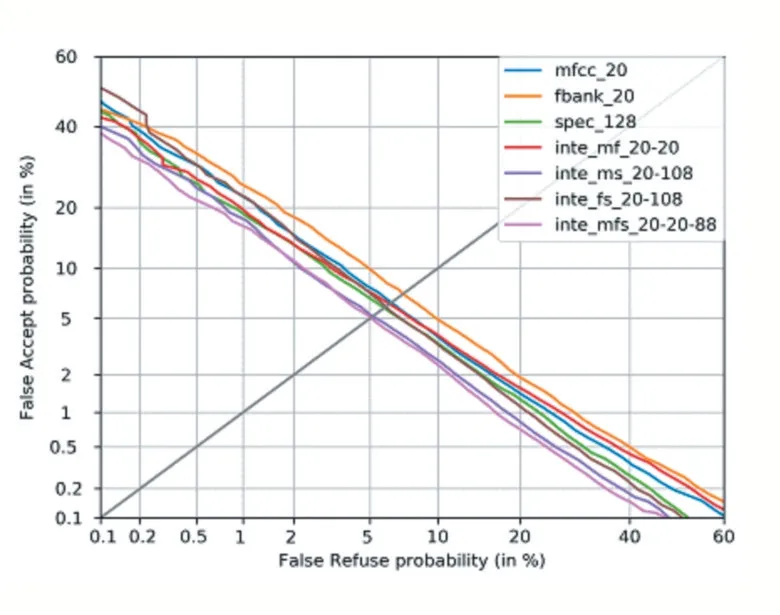
圖2 測試集2的DET曲線

圖3 測試集3的DET曲線
4 結(jié)語
本文研究了深度學(xué)習(xí)說話人識別中用于模型構(gòu)建時輸入的語音特征參數(shù),得到了可以用于深度學(xué)習(xí)說話人識別中作為輸入的語音特征:Integration_MFS_20-20-88。通過理論分析和實(shí)驗(yàn)證明了該特征方案是有效的。但這只是做了一小部分工作,后續(xù)還會在以下方面進(jìn)行深入研究:①該融合特征只在基于卷積神經(jīng)網(wǎng)絡(luò)構(gòu)建的說話人識別模型上驗(yàn)證了其有效,還并未在其他的神經(jīng)網(wǎng)絡(luò)來進(jìn)行驗(yàn)證,后續(xù)還會進(jìn)一步測試該特征在其他網(wǎng)絡(luò)上的有效性;②由于本文構(gòu)建的說話人識別模型比較簡單,所以取得的測試結(jié)果都未達(dá)到一個較高的水平,后續(xù)也將會在模型結(jié)構(gòu)上進(jìn)行深入研究。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
