面向法律文本的三元組抽取模型
2021-05-17 05:31:24陳彥光孫媛媛王治政張書晨
計算機工程 2021年5期
陳彥光,王 雷,孫媛媛,王治政,張書晨
(1.大連理工大學 計算機科學與技術學院,遼寧 大連 116024;2.遼寧省人民檢察院第三檢察部,沈陽 110033)
0 概述
隨著中國司法信息的不斷公開化,最高人民法院生效裁判文書全部在中國裁判文書網上公布,除法律有特殊規定的以外。在中國裁判文書網上的大量開源刑事判決書文檔中蘊藏著重要的法律信息,但對于這些通過自然語言形式記錄的刑事判決書文檔,機器無法直接進行深層含義的理解,而自動化信息提取技術能將非結構化的自然語言文本轉化為結構化的三元組形式,挖掘出文本中具有一定潛藏價值的內容,并通過命名實體識別(Named Entity Recognition,NER)和關系抽取將非結構化的刑事判決書文本處理為結構化的三元組。刑事判決書中的案件事實描述文本s被表示為多個<e1,r,e2>三元組的形式,其中,e1和e2分別表示三元組的頭實體和尾實體,r表示兩個實體之間的關系類型[1]。
知識圖譜以結構化的形式表示知識,通過對非結構化文本中難以理解的信息進行挖掘與分析,提高非結構化文本的查詢性能及可解釋性,通常作為搜索引擎、問答系統等實際應用中的底層支撐技術。目前,知識圖譜的相關研究受到學術界和工業界的廣泛關注,研究人員提出了許多知識圖譜構建方法,但構建出的知識圖譜多數面向通用領域,其中三元組抽取是知識圖譜構建過程中的關鍵步驟。本文提出一個面向法律文本的三元組抽取模型,對非結構化的案件事實描述文本進行結構化表示。將三元組的抽取過程看作二階段流水線結構,先進行命名實體識別,再將識別結果應用于關系抽取階段得到相應的三元組表示。
1 相關工作
非結構化文本中的三元組抽取可分為命名實體識別和關系抽取兩個階段。命名實體識別用于提取文本中具有特定含義的實體短語,如人名、地名以及專有名詞等。關系抽取對于文本中給定的實體對,通過上下文語義理解識別出實體之間的關系類型。
早期的命名實體識別工作主要包括基于規則和詞典的命名實體識別方法與基于統計的命名實體識別方法。基于規則和詞典的命名實體識別方法需要語言學專家和領域學者歸納規則模板和領域詞典,通過匹配算法完成命名實體識別。基于統計的命名實體識別方法學習標注語料的訓練過程并分析文本的語言特征,主要包括基于支持向量機(Support Vector Machine,SVM)的命名實體識別方法[2]、基于隱馬爾科夫模型(Hidden Markov Model,HMM)的命名實體識別方法[3]以及基于條件隨機場(Conditional Random Field,CRF)的命名實體識別方法[4]等。但這些早期工作對特征選擇的要求較高,較大程度地依賴詞典以及特征工程。隨著深度學習技術的不斷發展,使用神經網絡進行命名實體識別的方法逐漸成為當前中文命名實體識別的主要研究方向[5-7]。由于基于神經網絡的命名實體識別模型可以自動化地學習文本特征,從而減少對手工特征的依賴。目前主流的用于命名實體識別的神經網絡模型為雙向長短期記憶網絡結合條件隨機場(Bidirectional Long Short-Term Memory+Condition Random Field,BiLSTM+CRF)。近些年,在司法領域,許多學者對基于法律文書的命名實體識別方法開展了大量的相關研究工作[8-10]。
關系抽取工作一般可分為基于機器學習的關系抽取方法和基于深度學習的關系抽取方法。基于機器學習的關系抽取方法將關系抽取轉化為分類任務,對兩個實體之間的關系類型進行預測,該類方法先整合詞性特征、實體類型、句法依存關系以及WordNet 語義信息等語言學特征,再通過最大熵模型[11]、支持向量機模型[12-14]等基于統計模型的分類器對關系進行分類。隨著深度學習技術的發展,研究人員提出了許多基于深度學習的關系抽取方法,通過對輸入文本及實體位置信息等進行向量化表示,利用神經網絡模型自動提取文本特征,預測實體對之間的關系類型,主要包括基于卷積神經網絡的關系抽取方法[15-17]、基于循環神經網絡的關系抽取方法[18-19]以及兩者相結合的關系抽取方法[20]。隨著自注意力機制研究的深入[21-22],一些學者將Transformer 架構[23]應用于關系抽取任務,利用基于Transformer 的雙向編碼器表示(Bidirectional Encoder Representations from Transformer,BERT)[24]進行關系抽取[25]并取得了較好的效果。
近年來,預訓練語言模型研究發展迅速,基于上下文信息捕捉單詞的語義知識,通過在大規模語料上進行預訓練,從而實現文本上下文相關特征的表示。在預訓練語言模型研究中,一般通過特征集成和模型微調方式實現對預訓練模型參數的遷移。特征集成方式將語言模型學習到的文本表示當作下游任務的輸入特征進行應用,例如文獻[26]提出的ELMo 可在變化的語言語境下對詞進行復雜特征建模。模型微調方式以整個預訓練語言模型為基礎,通過加入任務輸出部分并對整個模型參數進行微調實現預訓練模型的應用,例如:文獻[24]提出的BERT 模型通過Transformer 編碼器堆疊而成,實現對文本的雙向特征表示,在11 項自然語言處理任務中取得了最佳成績;文獻[27]提出的自回歸預訓練模型XLNet,在多項自然語言處理任務中取得了明顯的性能提升。
2 司法三元組抽取模型
對于案件事實描述文本s,本文提出的司法三元組抽取模型能夠將與其具有等價語義的三元組以<e1,r,e2>的形式進行預測。司法三元組抽取模型以BERT 預訓練語言模型為基礎,搭建一個二階段的流水線結構,主要包括實體識別模塊和關系抽取模塊兩部分。實體識別模塊用于對案件事實描述中具有特定含義的實體短語進行定位和分類,關系抽取模塊旨在預測非結構化文本中每一對實體之間的關系類型。在關系抽取模塊中,為強調給定實體對的位置和內容,借鑒文獻[1]工作,在文本表示中加入實體信息的整合過程。針對流水線結構中的冗余實體對信息所造成的影響,通過加入實體對篩選過程以減少無用信息的累積,并在關系抽取模塊訓練時,在訓練集中適當增加負樣本,以增強模型魯棒性,本文提出兩種策略來完善關系抽取模塊的訓練過程。此外,為進行有監督的模型訓練以及驗證模型在刑事判決書文本上的三元組抽取性能,本文以刑事判決書中的案件事實描述部分為數據基礎,通過自然語言處理工具進行機器粗標與人工標注相結合的方式,構造一個面向涉毒類刑事案件的實體關系提取數據集。
司法三元組抽取模型的整體架構如圖1 所示,其中,wi表示輸入文本的向量化表示,hi表示經過BERT模型編碼得到的上下文語義向量,N表示輸入序列長度,Trm 表示BERT 模型中的Transformer 編碼器單元。司法三元組抽取模型針對涉毒類案件刑事判決書文本進行研究,通過實體識別模塊和關系抽取模塊,實現對涉毒類刑事案件的結構化三元組抽取。
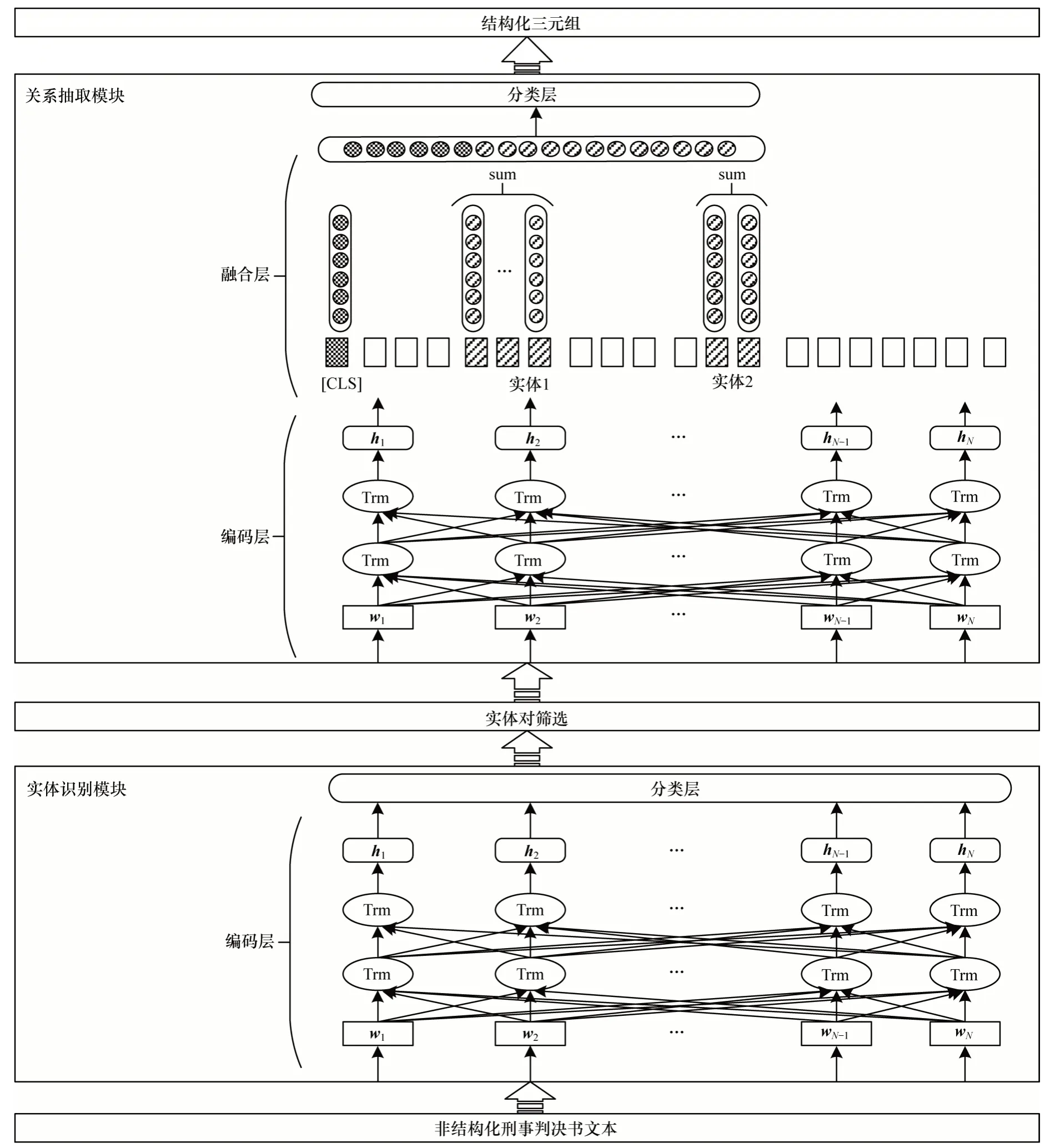
圖1 司法三元組抽取模型的整體架構Fig.1 The overall architecture of legal triplet extraction model
2.1 預訓練語言模型
BERT 模型由多層雙向Transformer 編碼器堆疊而成,通過在大規模語料上進行無監督預訓練獲得文本的特征表示。BERT 模型的輸入部分可對單句及句子對進行表示,對于給定的字符,輸入向量包括詞嵌入信息、位置信息和分句信息3 類信息表示,并且在BERT 原始模型中具有‘[CLS]’、‘[SEP]’和‘[MASK]’3 種特殊字符:‘[CLS]’符號置于每個輸入序列的首位,其對應的輸出向量為該序列的向量表示,可直接用于分類任務;‘[SEP]’符號用于句子對作為輸入時分隔序列中的兩個句子,針對單句子作為輸入的情況,將‘[SEP]’符號置于句子尾;‘[MASK]’符號應用在預訓練階段的覆蓋語言模型中。
BERT 模型通過覆蓋語言模型(Masked Language Model,MLM)任務以及下一句預測(Next Sentence Prediction,NSP)任務完成對模型參數的預訓練。在覆蓋語言模型任務中,輸入序列的部分字符通過‘[MASK]’符號被隨機覆蓋,該任務的目標是通過上下文文本預測被覆蓋的字符,得到字符的雙向上下文表示。下一句預測任務針對句子對輸入,預測兩句是否為文本中的連續語句,以此捕捉句子對之間的關系。在經過大規模語料預訓練后,針對特定任務,還需使用任務相關的數據集對BERT 模型進行微調,從而得到適用于具體任務的模型參數。
2.2 實體識別模塊
實體識別模塊是司法三元組抽取模型的主要模塊之一,將刑事判決書案件事實描述部分中的命名實體全部標記處理,具體包括人名、地名、時間、毒品類型和毒品重量5 類實體。針對輸入文本中的每個字符,實體識別模塊將預測該字符是否屬于實體的一部分并給出實體類型,由此將實體識別過程轉化為字符級的分類任務,預測指定字符的實體位置和實體類型,通過在以BERT 模型為基礎的編碼層上添加一個多分類器進行實現。
按照BERT 的輸入格式,將案件事實描述文本處理為向量,作為實體識別模塊的輸入,該向量包含詞嵌入、位置信息以及分句信息三部分。此外,在句首和句尾分別插入‘[CLS]’符號和‘[SEP]’符號。在模型微調過程中,使用編碼層最后一層的隱層向量作為序列的特征表示,并通過多標簽分類器對序列中的每個字符進行預測。標簽序列x的分布可表示為:

其中,HER為編碼層最后一層的隱層向量表示。
在實體識別模塊中,在BERT 模型的基礎上添加字符級多分類器形成實體識別模塊的模型結構。為使實體識別模塊可以利用BERT 模型預訓練階段學習的文本特征,并學習下游的實體識別任務,還需對整個模型進行微調。首先通過載入預訓練后的BERT 模型權重對實體識別模塊進行初始化;然后利用面向涉毒類刑事案件的實體識別數據集對實體識別模塊進行有監督訓練,完成相應參數的微調。由此得到的實體識別模塊既包含預訓練階段的通用文本特征知識,又對法律實體識別任務進行了學習。對于訓練樣本{(si,xi)}|Ni=1,其中,si和xi分別代表實體識別模塊訓練集中第i條樣本的真實標簽和預測標簽,N為訓練集中的樣本數,使用交叉熵作為損失函數對實體識別模塊的參數θER進行學習:
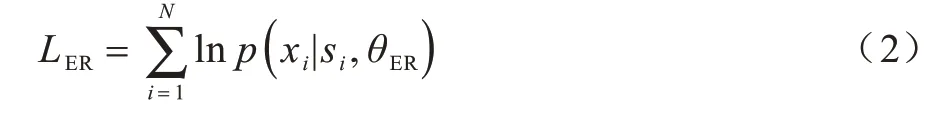
2.3 實體對篩選過程
實體對篩選過程的作用是減輕流水線結構中的冗余實體信息所造成的影響。該過程對實體識別模塊的結果進行整合,選擇可能具有關系的實體對并過濾不可能形成三元組的實體。在對司法三元組進行抽取的流水線中,實體對篩選過程置于實體識別模塊后及關系抽取模塊前。首先對文本中通過實體識別模塊提取出的實體進行兩兩組合,形成實體對集合;然后通過關系類型分析,得出可能形成三元組的實體類型組合規則;最后依照這些規則對實體對集合進行篩選,得到可能存在關系的實體對,輸入關系抽取模塊中預測其關系。
2.4 關系抽取模塊
關系抽取模塊旨在通過上下文囊括的語義信息判斷文本中給定的實體對存在的關系類型。為實現關系抽取模塊的功能,給定一個描述文本s以及兩個目標實體e1和e2,在文本中插入實體定位字符以供模型獲取實體信息。實體定位字符分別為‘[E11]’、‘[E12]’、‘[E21]’和‘[E22]’4 個字符。針對三元組的頭實體e1,將字符‘[E11]’和‘[E12]’分別置于e1的首部和尾部,確定e1的具體位置。針對三元組的尾實體e2,按照相同的方式,在e2首尾插入‘[E21]’和‘[E22]’字符進行定位。
關系抽取模塊由編碼層、融合層和分類層三部分組成,編碼層用于提取文本特征及實體特征,融合層可將實體對的特征信息與上下文特征進行整合,分類層用于對文本中的每個實體對存在的關系類型進行預測。
2.4.1 編碼層
編碼層以BERT 模型為基礎對文本進行向量表示,分別對輸入序列和實體對進行特征提取。將學習到的‘[CLS]’符號所對應的特征向量作為整個序列s的全局特征,通過Hs進行表示。將BERT 模型最后一層的隱層向量看作是序列中每個字符的編碼向量,以h進行表示。為得到序列中的實體特征,對與頭實體e1和尾實體e2相關的字符進行向量表示:

其中,E1和E2分別為實體e1和e2所對應的特征向量,m1和m2、n1和n2分別對應兩個實體e1、e2在序列s中的開始和結束位置。
2.4.2 融合層
融合層用于對編碼層輸出的序列特征Hs和實體特征E1、E2進行整合,從而在序列特征中加入相應的實體對信息。為能夠更好地學習各特征向量之間的關系,添加可訓練的參數矩陣Ws和We,以對序列特征和實體特征所占的權重進行動態調整。在經過特征向量融合后,序列特征Hs和實體特征E1、E2將整合為一個新的序列表示向量S,其中包含序列s的全局文本信息以及其中的實體信息,具體表示為:
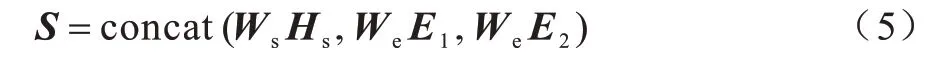
2.4.3 分類層
分類層基于最終的序列表示S對關系類型進行分類,通過Softmax 分類器對文本中給定實體對存在的關系類型分布y進行預測:
p(y|s)=Softmax(S) (6)
在關系抽取模塊中,以BERT 模型為基礎,通過加入特征融合層和關系分類層形成關系抽取模塊的模型結構。首先載入經過預訓練的BERT 模型權重作為關系抽取模型的初始權重,使得關系抽取模型具備預訓練階段學習的知識;然后通過在面向涉毒類刑事案件的關系抽取數據集上進行監督訓練,并對模型參數進行微調,實現可用于法律文書關系抽取任務的模型。在訓練過程中,通過交叉熵損失函數對關系抽取模塊參數θRE進行學習:
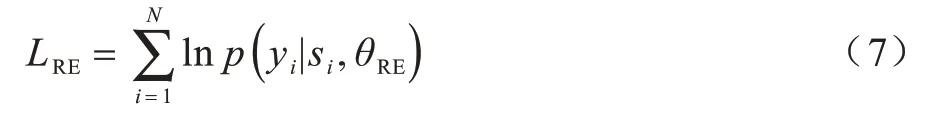
3 實驗與結果分析
3.1 數據集構建
為實現中國司法領域的信息抽取,以涉毒類刑事判決書文本為基礎,將其中的案件事實描述部分使用規則提取,在此基礎上通過自然語言處理工具進行機器粗標與人工標注相結合的模式,標注出涉及到的法律實體及其之間的關系類型。選取涉毒類刑事案件中最具代表的販賣毒品、非法持有毒品和容留他人吸毒3類案件作為研究主體,將1 750份刑事判決書中的案件事實描述文本作為原始語料,在此基礎上進行標注形成數據集。
針對命名實體識別任務,使用BIO 標注策略區分實體邊界并預設人名、地名、時間、毒品類型和毒品重量5 類實體。司法領域實體識別數據集中共包括19 321 個實體。針對關系抽取任務,參考《中華人民共和國刑法》并結合3 類涉毒類案件的判決依據,預定義持有(possess)、販賣(給人)(sell_drug_to)、販賣(毒品)(traffic_in)和非法容留(provide_shelter_for)4 種關系類型,這4 種關系涵蓋了3 類涉毒類案件中的犯罪行為。
將1 750 條經過實體關系標注的案件事實描述文本以4∶1 的比例進行隨機劃分,分別作為司法領域實體關系提取的訓練集和測試集。訓練集和測試集中實體與關系的統計情況分別如表1 和表2所示。
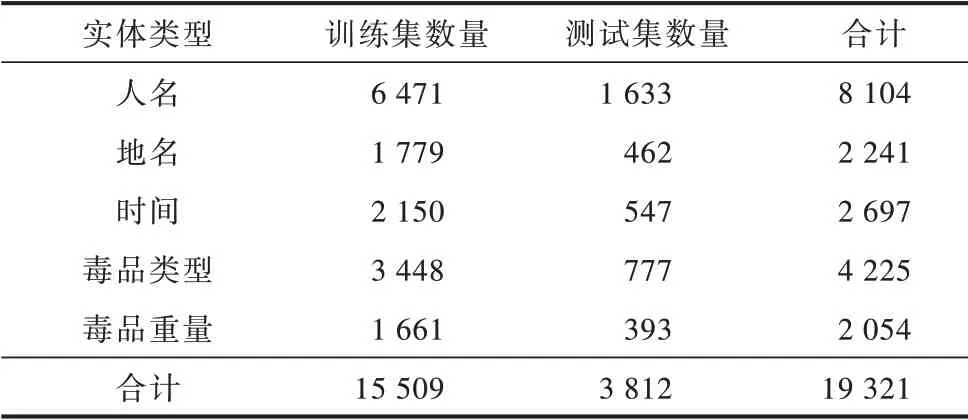
表1 數據集中實體類型的統計情況Table 1 Statistics of entity types in the dataset
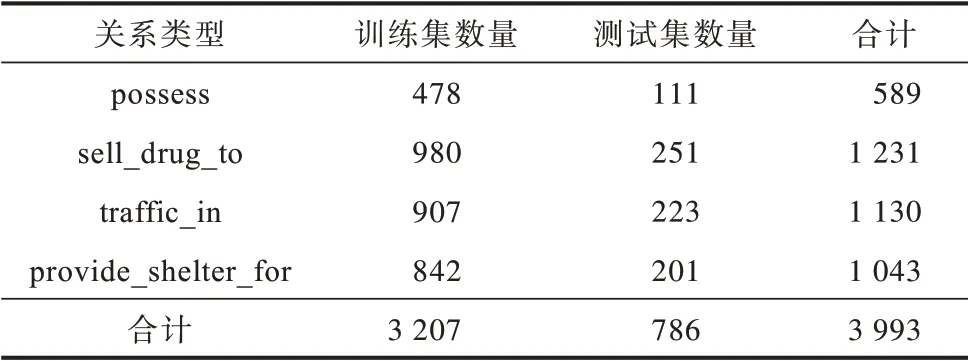
表2 數據集中關系類型的統計情況Table 2 Statistics of relation types in the dataset
3.2 數據預處理與參數設置
由于本文三元組抽取模型采用流水線結構,因此會產生大量不存在關系類型的實體對,這些冗余的實體對將會對關系抽取模塊的識別性能造成影響。為使關系抽取模塊能更好地學習這種無關系類型的實體對特征,在訓練過程中將不存在關系類型的實體組合作為負樣本,以一定的比例添加到訓練集中。
此外,本文還考慮關系方向性,即三元組<e1,ra,e2>和<e2,rb,e1>,這兩個三元組的實體集合是一致的,但頭尾實體位置互換,因此其存在的關系類型ra和rb是不同的,對于這一類頭尾實體位置互換的三元組所存在的兩個關系ra和rb,本文稱其互為反向關系。關系的方向性對關系抽取模塊的訓練也有一定的影響,尤其在關系類型販賣(給人)和非法容留中較為明顯,由于在這兩種關系中,頭實體和尾實體對應的實體類型都為人名且表達形式相近,因此會對關系類型的預測產生影響。為使關系抽取模塊能更好地學習關系的方向性,在訓練過程中,將訓練集中正樣本所對應的反向關系作為負樣本添加到訓練集中。
在實驗設置上,命名實體識別模塊使用谷歌開源的中文BERT(BERT-Base,Chinese)模型,在此基礎上進行微調完成對法律實體的識別,關系抽取模塊分別使用中文BERT(BERT-Base,Chinese)模型和RoBERTa 模型進行實驗,其他參數設置如表3所示。

表3 實體識別模塊與關系抽取模塊的參數設置Table 3 Parameters setting of entity recognition module and relation extraction module
3.3 結果分析
在實驗中,三元組抽取模型性能由精確率(P)、召回率(R)以及F1 值(F)進行評估。評價指標的計算方式如下:

其中,ncorrect_num表示司法三元組抽取模型對所有實例抽取正確的三元組個數,npredict_num表示司法三元組抽取模型預測出的三元組總數,ntrue_num表示實際的三元組總數。其中,抽取出的三元組只有在兩個實體e1和e2以及關系r都預測正確的情況下才被判定為正確的三元組。
實驗采用3 組不同的神經網絡模型組合作為基線模型:組合模型1 中實體識別使用雙向長短期記憶網絡結合條件隨機場的模型(BiLSTM+CRF),關系抽取應用雙向門循環單元結合注意力機制的模型(BiGRU+ATT);組合模型2 中實體識別使用本文模型,關系抽取使用BiGRU+ATT;組合模型3 中實體識別使用BiLSTM+CRF,關系抽取使用本文模型。不同的模型組合對三元組的抽取效果如表4 所示,可以看出,本文提出的司法三元組抽取模型優于其他的組合模型,相比基于循環神經網絡的組合模型1的F1 值提高了28.1 個百分點。由組合模型3 的F1值高于組合模型2 的F1 值這一結果可以看出,本文關系抽取模塊相比實體識別模塊更有助于抽取性能的提升。
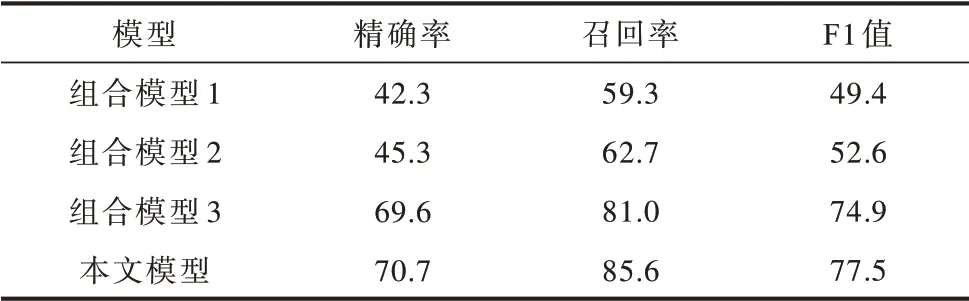
表4 組合模型與本文模型的三元組抽取結果對比Table 4 Comparison of triplet extraction results of the combination models and the proposed model %
由于流水線結構中會產生大量不存在關系類型的實體對,因此為使關系抽取模塊更加全面地學習這些無關系類型的實體對特征,在訓練階段通過添加負例樣本完善關系抽取模型的訓練過程。
3.3.1 正負樣本比例對三元組抽取的影響
在實驗中正負樣本的比例對三元組的抽取效果產生了一定的影響。通過采用相同的隨機種子,隨機篩選不同比例的負樣本添加到關系抽取模塊的訓練集中,確定用于訓練關系抽取模塊的最佳正負樣本比例,分別選取正負樣本比例為無負樣本、1∶2、1∶3、1∶5 和1∶7 進行對比實驗,結果如表5 所示。
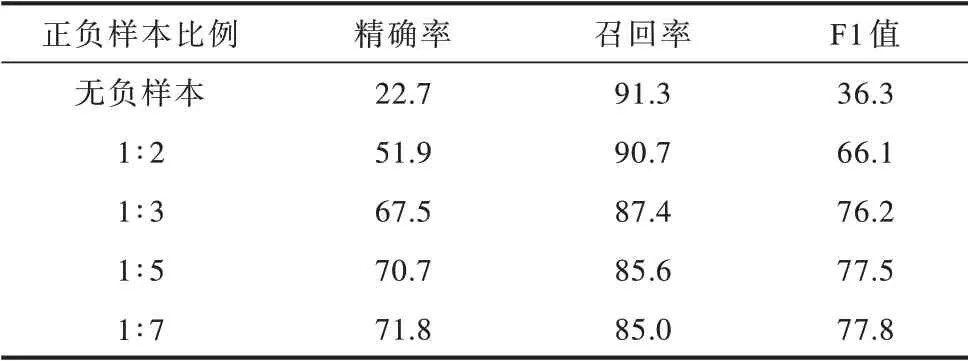
表5 基于不同正負樣本比例的三元組抽取結果對比Table 5 Comparison of triplet extraction results based on different positive/negative instance ratios %
隨著關系抽取任務的訓練集中負例樣本占比逐漸增加,三元組抽取模型的整體抽取性能不斷提升,F1 值由無負樣本的36.3%提升至正負樣本比例為1∶7 的77.8%,提高了41.5 個百分點。這也證明了添加適當比例的負樣本對關系抽取模塊的訓練過程具有積極作用,由實驗結果中精確率的大幅提升也可看出,關系抽取模塊通過負樣本學習可更全面地學習不存在關系類型的實體對所具有的特征,能夠更好地分辨出無關系類型的實體對。
3.3.2 反向關系對三元組抽取的增益效果
為驗證反向關系對三元組抽取結果的影響,通過將正樣本的反向關系作為負樣本添加到訓練集中,使關系抽取模塊對關系方向性進行更好的學習,并選擇具有不同正負樣本比例的訓練集分別進行實驗,結果如表6 所示,其中,“√”表示添加反向關系,“×”表示未添加反向關系。
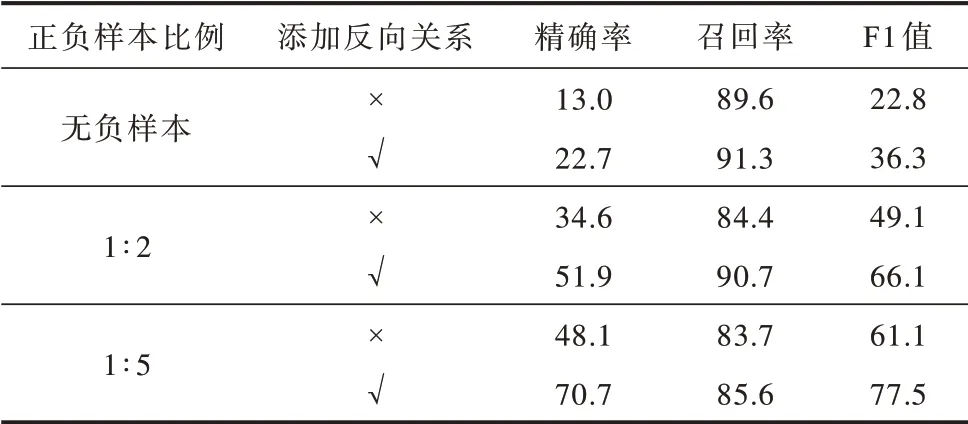
表6 添加反向關系的三元組抽取結果對比Table 6 Comparison of triplet extraction results of adding inverse relation %
由實驗結果可以看出,關系方向性對關系抽取模塊的訓練過程十分重要,通過將正樣本的反向關系添加到訓練集中,使得本文模型對三元組抽取的精確率和召回率都有所提升,在無負樣本、正負樣本比例為1∶2 和1∶5 的條件下,F1 值分別提高了13.5、17.0 和16.4 個百分點。由此說明將正樣本的反向關系作為負樣本進行模型訓練這一策略能有效提升關系抽取模塊的預測能力,有助于模型更好地區分具有相似頭尾實體的實體對特征。
3.3.3 不同預訓練語言模型對三元組抽取的影響
本文對關系抽取模塊所使用的預訓練語言模型進行對比實驗,結果如表7 所示,可以看出使用基于RoBERTa 模型的關系抽取模塊可更好地進行關系預測,在三元組抽取結果上達到79.6%的F1 值。

表7 在1∶5 正負樣本比例下不同預訓練語言模型的三元組抽取結果對比Table 7 Comparison of triplet extraction results of different pretrained language models with the positive/negative instance ratio of 1∶5 %
4 結束語
本文建立一種將非結構化刑事判決書文本轉化為結構化三元組形式的司法三元組抽取模型。該模型將預訓練的BERT 模型作為主體,在此基礎上分別對實體識別模塊和關系抽取模塊進行微調,并搭建三元組抽取的流水線結構,實現對非結構化文本的信息提取。實驗結果表明,該模型相比基于循環神經網絡的組合模型的F1 值提高了28.1 個百分點,并通過加入兩項針對關系抽取模塊的訓練策略能提升三元組抽取性能。下一步將繼續優化本文模型的三元組抽取效果,并以此為基礎構建司法知識圖譜進行表示學習及知識推理等工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
