復雜網絡的雙曲空間表征學習方法*
2021-05-18 11:28:30羿舒文楊林濤
軟件學報 2021年1期
王 強 ,江 昊,羿舒文,楊林濤,奈 何,聶 琦
1(武漢大學 電子信息學院,湖北 武漢 430072)
2(華中師范大學 物理科學與技術學院,湖北 武漢 430079)
近年來,以Internet 為代表的信息技術的發展,已使我們處于由無處不在的網絡構成的世界中.此外,網絡結構數據分布在各種相關領域數據中,包括分子結構網絡、生物蛋白質交互網絡、推薦系統、社交網絡、引文網絡等等.這些數據結構都可以通過網絡來描述實體及實體之間的交互關系,網絡結構數據是我們生產、生活中常見的一種數據形式.其中,復雜網絡是一類具有冪率度分布、強聚類、小世界特性的網絡.對復雜網絡的分析有利于網絡數據結構的潛在信息挖掘,這將促進一系列應用,如節點分類、社區發現、鏈路預測等[1-6].例如,可以通過“推特、微博”用戶關注所形成的社交網絡進行“朋友推薦”,通過生物蛋白質代謝網絡發現潛在的蛋白質功能.
復雜網絡的分析具有極強的現實意義,但直接對大規模、稀疏的鄰接矩陣進行分析需要較高的時間復雜度和空間復雜度,難以進行并行計算[2].另一方面,在機器學習浪潮下,復雜網絡學科與機器學習的結合成為當下熱點研究問題,很多機器學習算法試圖將網絡結構數據引入作為特征輸入.該輸入數據一般可以被表示為包含特征信息的向量形式,傳統方法使用網絡的統計參數、核函數或通過精心設計的特征來描述鄰居結構信息,但這些設計代價昂貴且不能自適應學習過程[6].
為了解決這些困難和挑戰,大量研究使用表征學習來編碼網絡結構信息.網絡表征學習通過假設網絡節點位于低維空間,在該空間中學習網絡節點的低維向量表示,低維向量將進一步用于處理后續任務.表征學習的目標是通過優化網絡節點的向量表示來實現保留網絡結構信息的降維表達,向量空間中節點的位置和節點間距離可以表征網絡的高階拓撲信息.如圖1 所示,GCN[7]是一種用于網絡結構數據的神經網絡架構,隨機初始化的3 層GCN 也可以生成網絡中節點的鄰近特征表征.
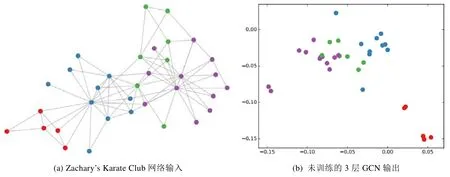
Fig.1 Example of embeddings obtained from an untrained 3-layer GCN model with random weights applied to the Zachary’s karate club network[7]圖1 使用未訓練的3 層GCN 嵌入Zachary’s Karate Club 網絡示例[7]
大部分的網絡表征學習針對的是圖數據,通過圖計算形式實現降維表達.而復雜網絡的表征學習針對具有冪率度分布、強聚類、小世界特性的網絡,其研究有利于降低網絡數據維度,使網絡數據可以與機器學習相結合,更好地分析網絡節點間聯系,為各種后續實際應用提供解決方案.近年來,在網絡表征學習領域涌現出大量的研究成果,其中一些研究表明,雙曲空間可以很好地描述具有近似樹狀層次結構的復雜網絡.雙曲空間具有負常數曲率,是樹狀圖的連續近似空間,無限樹在雙曲空間中也有近乎等距的嵌入[8].復雜網絡的雙曲幾何模型嵌入理論將復雜網絡幾何化,同時又不損失復雜網絡中的無標度、小世界等特性,是一種可以解釋復雜網絡拓撲特征和生長機制的新型模型.為了更好地分析與應用該類模型,本文圍繞復雜網絡的雙曲空間表征學習方法展開系統性介紹和總結,以供后續研究參考.
本文第1 節對網絡表征學習及其分類進行總結,將網絡表征學習分為矩陣分解、隨機游走、深度自編碼機和圖神經網絡的方法.第2 節在介紹雙曲空間的基礎上,對已有的復雜網絡雙曲空間生成模型和嵌入方法進行總結.第3 節從復雜網絡雙曲空間表征學習的應用出發,結合雙曲空間特征,概括了其主要應用場景.第4 節給出不同的雙曲空間表征學習方法性能評估結果.第5 節總結全文,指出復雜網絡的雙曲空間表征學習的特征優勢,并對未來研究方向做出展望.
1 網絡表征學習
1.1 網絡表征學習定義
網絡表征學習是一個降維表達的過程,將高維的網絡結構數據轉換為低維的節點向量表示,向量可作為節點特征用于后續網絡應用.表1 給出了本文所用符號的含義,網絡表征學習的目標是:對網絡G中每個節點vi,學習一個實值向量表示zi∈?d(d<<|V|).部分方法會用到節點屬性或連邊屬性,如m維節點屬性可通過X∈?|V|×m的實值矩陣來表示.通過網絡表征學習形成保留網絡結構信息的低維實值向量,可以用于重構出原網絡、有效支撐網絡推斷和提高后續應用算法執行效率.

Table 1 Notations used in this paper表1 本文所用符號
1.2 網絡表征學習分類及特征
網絡表征學習方法眾多,按照不同的分類標準,可得到不同的結果.本文根據不同方法的技術特點,把網絡表征學習分為基于矩陣分解、隨機游走、深度自編碼機、圖神經網絡的方法:矩陣分解的方法將網絡信息使用矩陣表示,然后通過分解該矩陣獲取節點向量表示[9-11];隨機游走方法將網絡信息通過采樣一系列隨機游走的路徑表示,然后將深度學習方法應用到采樣路徑中進行圖嵌入,以保持路徑所攜帶的圖屬性[1,12];深度自編碼機將網絡信息編碼到表征空間,然后譯碼重構,使得重構誤差最小化;圖神經網絡通過在圖上定義近似卷積等操作,將神經網絡應用于圖信息處理.表2 對每種方法的特征及適用性進行描述[13-28].
基于矩陣分解、隨機游走、深度自編碼機和圖神經網絡的網絡表征學習方法的相關研究層出不窮,它們一般都是通過某種策略將實體對象嵌入到低維歐氏向量空間中,該策略的目標是捕獲語義信息,如節點近似度或節點間最短路徑等信息.但是,歐幾里德對稱模型不能很好地反映復雜的數據模式,比如分類數據中潛在的層次結構[29].為了解決這一問題,非歐幾里德流形表示學習成為新的發展趨勢.實際上,許多復雜網絡都呈現出冪率度分布和潛在的樹狀結構,該結構的存在通常可以追溯到層次結構.為了利用這種結構特性來學習更有效的表示,許多研究建議不在歐幾里德空間中計算嵌入,而是在雙曲空間中計算嵌入[30-32],即曲率為負常數的空間.

Table 2 Comparison of network representation learning methods表2 網絡表征學習方法比較
關于網絡表征學習,已有大量綜述文獻[1-6,9,11,12],但描述的方法大多以網絡特征提取和表示為目標,將網絡嵌入到低維歐氏空間中.本文主要聚焦于雙曲空間中的復雜網絡表征學習,亦屬于網絡表征學習中的一類,但該類方法來源于對復雜網絡形成過程和規律的研究,所表征的節點向量具有獨特的物理含義.該類方法認為:雙曲空間是復雜網絡潛在的幾何度量空間,將雙曲空間幾何性質與復雜網絡的特征相結合,形成復雜網絡的生成模型,而相應的表征學習則是對原始坐標的逆向推斷.下一節將介紹雙曲空間基本性質、雙曲空間適合表達近似樹狀結構的復雜網絡的原因、從雙曲空間到實際網絡的生成過程以及從實際網絡到雙曲空間的嵌入方法.
2 復雜網絡的雙曲空間表征學習
2.1 雙曲空間概述
非歐幾何的誕生,源自于對歐幾里德第五公設的討論與研究.雙曲幾何是非歐幾何的一種特例,在雙曲幾何中,前4 條公設保留,第5 公設修改為“過已知直線外一點至少可以作兩條直線與已知直線平行”.雙曲空間由于具有負常數的曲率,無法等度量地嵌入到歐氏空間中,難以直觀表達.有研究學者為此建立了很多等價模型,這里我們介紹常用的3 種模型:雙曲面模型、克萊因模型和龐加萊球模型.圖2(b)和圖2(c)所示為克萊因模型和龐加萊圓盤模型(二維龐加萊球模型)中的過給定點的平行線.
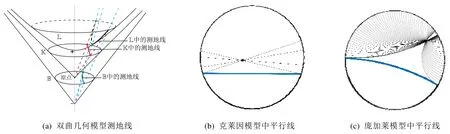
Fig.2 Examples of hyperbolic geometric models圖2 雙曲幾何模型示例
2.1.1 雙曲空間表達模型
(1)雙曲面模型
雙曲面模型將n維雙曲空間視為n+1 維閔可夫斯基空間中的偽球面,n+1 維閔可夫斯基空間是內積為公式(1)的實值空間:

n維雙曲面模型中的點可由n+1 維閔可夫斯基空間中的點表示,如公式(2)所示:

如圖2(a)所示,雙曲面模型中的每一條測地線都是Ln和過原點的平面的交線,兩點間的測地距離如公式(3)所示:
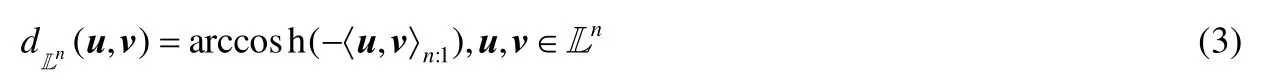
(2)克萊因模型
如圖2(a)所示,將Ln中的每個點通過原點發散出的射線映射到xn+1=1 的超平面上,可得克萊因模型:

即:該過原點的平面與Ln相交形成雙曲面模型中的測地線,與xn+1=1 的超平面相交形成克萊因模型中的測地線.克萊因模型和雙曲面模型互為映射:
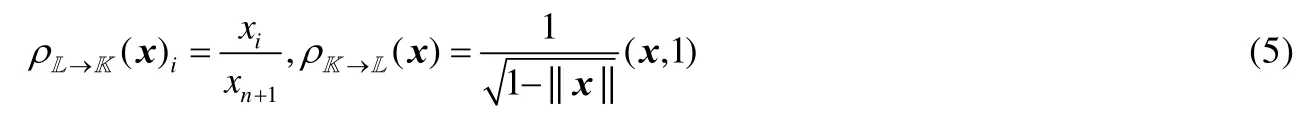
克萊因模型中的測地線距離為

(3)龐加萊球模型
如圖2(a)所示,將Ln中的每個點通過(0,0,…,0,-1)發散出的射線映射到xn+1=0 的超平面上,可得到龐加萊球模型:

同樣,雙曲面模型與龐加萊球模型互為映射:
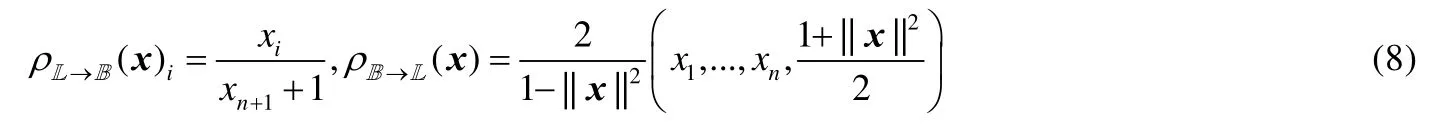
龐加萊球模型中的測地線距離為
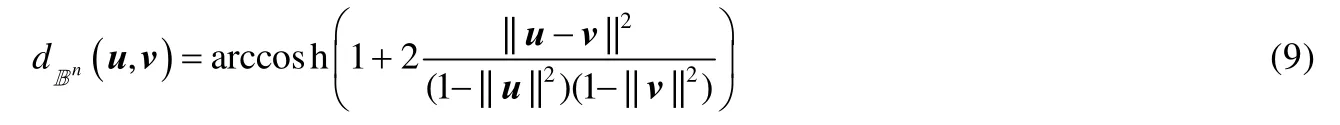
龐加萊圓盤模型為龐加萊球模型在二維下的具體體現.龐加萊圓盤模型具有保角性,即模型中雙曲線之間的歐幾里德角與其雙曲值相等;龐加萊圓盤模型中的距離與歐氏空間中的不同,從圓盤中心出發的雙曲距離rh與歐氏距離re之間具有如下關系:

然而,在擴展的龐加萊圓盤中,徑坐標r使用雙曲距離表示,即:

在曲率為K=-ζ2<0,ζ>0 的擴展龐加萊圓盤中,(ri,θi)和(rj,θj)之間的測地線距離dij通過雙曲余弦定理表示為
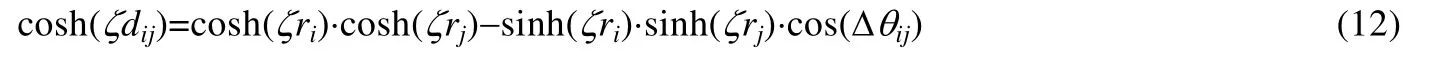
其中,Δθij=π-|π-|θi-θj||.若ζri和ζrj足夠大,滿足,則測地線距離可通過下式近似計算:
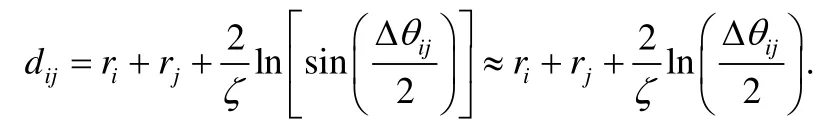
復雜網絡的雙曲幾何模型多采用擴展的龐加萊圓盤模型表征雙曲空間,該模型直觀,可視化效果好,二維表達下更容易分析幾何空間中潛在的物理含義.若非特別說明,本文所提及的龐加萊圓盤或雙曲圓盤均指擴展的龐加萊圓盤模型.
2.1.2 雙曲空間基本屬性
雙曲空間具有負常數的曲率,其指數擴張速度遠大于歐氏空間的多項式擴張.
如表3 所示,在曲率為K=-ζ2<0,ζ>0 的龐加萊圓盤中,圓周長L和面積S均隨半徑r以eζr增長.

Table 3 Characteristic properties of Euclidean,spherical,and hyperbolic geometries表3 歐氏空間、球面空間和雙曲空間的固有屬性
除了上述固有屬性外,雙曲空間中還有一系列幾何定理,這些屬性和定理可供復雜網絡的雙曲空間模型使用.下面給出幾個常見定理.
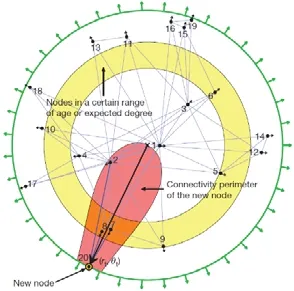
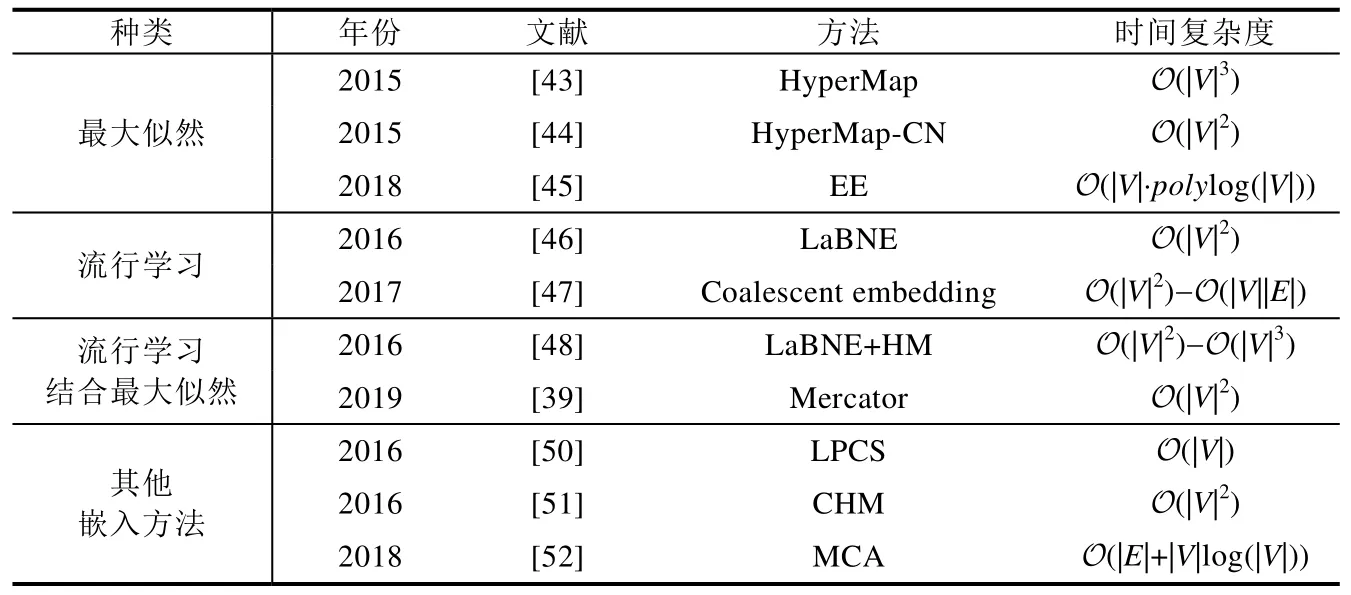
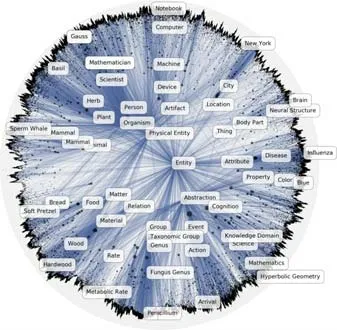
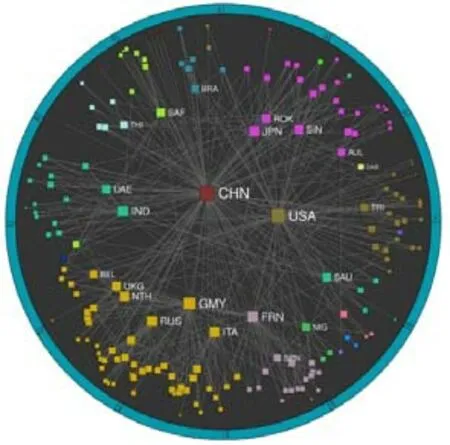
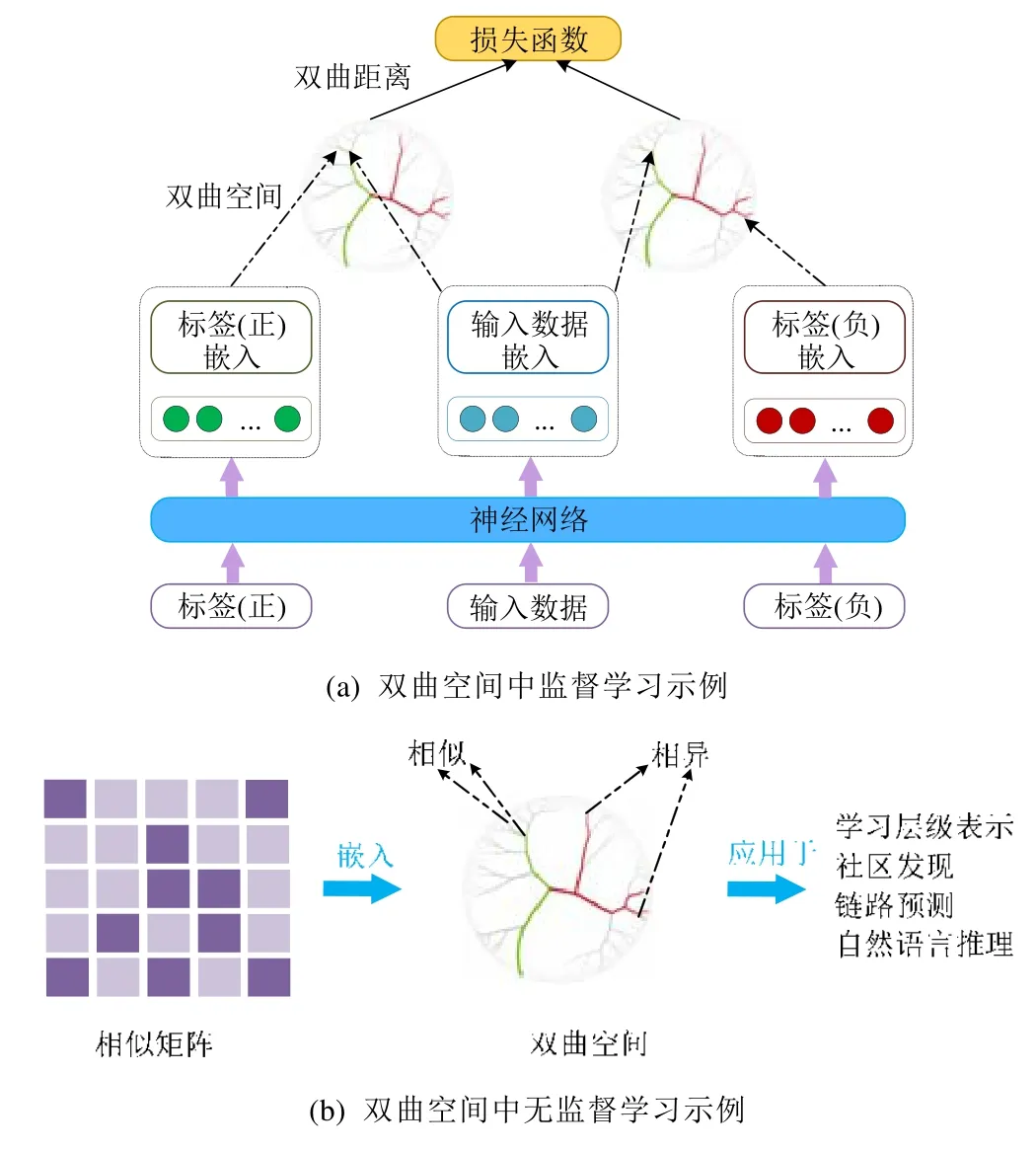
定理1.在非歐幾何中,三角形ΔABC的面積S與量π-(∠A+∠B+∠C)成正比:S=M[π-(∠A+∠B+∠C)].特別地,任意三角形的面積是有界的:S 定理2.在雙曲空間的三角形ΔABC中,a,b,c分別為∠A,∠B,∠C所對的邊長,則有: ? 雙曲余弦定理:cosh(c)=cosh(a)?cosh(b)-sinh(a)?sinh(b)?cos(∠C). 定理3.設a為DR={z||z| 定理4.如圖3 所示:設l是一條給定的非歐直線,記d(z,l)是點z到l的非歐距離,d>0 是任意給定的正數.集合D={z∈U:d(z,l) Fig.3 Hypercycle of hyperbolic space圖3 雙曲空間的超圓周 2.1.3 雙曲空間與復雜網絡的聯系 雙曲空間適合嵌入具有冪率度分布的復雜網絡,與雙曲空間的特性關系密切.冪率度分布的復雜網絡具有近似樹狀的層次結構,而雙曲空間是樹網絡的連續版本,對于n進制的樹,圓盤周長和面積可分別類比于距離根節點r跳的節點數(n+1)nr-1和不超過r跳的所有節點總數[(n+1)nr-2]/(n-1).如果令圓盤所表示的雙曲空間曲率滿足,則雙曲空間圓周和圓面積以eζr增長,與n進制樹增長速率nr保持一致.故樹狀結構可視為離散的雙曲空間.例如,雙曲空間的任何鑲嵌細分(如圖4 所示)自然定義了由多邊形邊的某些子集形成的一類樹的等距嵌入[31].已有研究表明:任何有限樹都可以通過任意低失真嵌入到有限雙曲空間中,而歐氏空間以多項式速率擴張,無限維的歐氏空間也無法滿足任意低失真嵌入有限樹[33,34]. Fig.4 Examples of hyperbolic space embedding圖4 雙曲空間嵌入示例 由于復雜網絡的無標度性質和近似樹狀結構與雙曲空間的負曲率和指數擴張高度貼合,基于雙曲空間生成模型的嵌入方法作為一類基于幾何模型的網絡表征學習方法誕生.該模型通過將復雜網絡嵌入到雙曲空間的龐加萊圓盤模型中,通過圓盤的徑向坐標表示節點流行性,角坐標間距離表示節點間相似性,將網絡的生長解釋為流行性和相似性的競爭,可以很好地解釋復雜網絡中無標度、小世界、強聚類等拓撲特征[32].本文首先描述復雜網絡雙曲空間的生成模型,然后介紹基于該模型的嵌入方法及無模型的嵌入方法,最后引入嵌入后的應用、性能對比及研究展望. 對復雜網絡的拓撲結構和動態演化過程的刻畫,是復雜網絡研究領域內的基礎性問題之一,由此引發的復雜網絡生成模型的研究具有很長一段歷史.起初,關于復雜網絡結構的假設形成規則網絡和隨機網絡兩個極端,較著名的研究是ER 隨機圖模型[35],該模型假設網絡中每條連邊獨立且連接概率相同,可以生成稀疏、存在巨片、平均距離較短的網絡,但該模型無法解釋實際網絡中出現的聚類特性和度分布非均勻性;規則的最近鄰網絡和ER 隨機圖模型都不能解釋許多實際網絡同時具有的強聚類、小世界特征,WS 小世界模型[36]作為一種完全規則網絡向完全隨機網絡的過渡模型誕生,該模型通過在規則網絡中引入少量隨機性產生具有小世界特征的網絡,包括較短的平均距離和高聚類系數;文獻[37]中指出,ER 隨機圖模型和WS 小世界模型忽略了實際網絡中的增長特性和優先連接特性,提出了BA 無標度網絡模型,該模型生成的網絡具有冪率度分布和較短的平均距離,但無法解釋很多現實網絡中的強聚類效應.在上述這些網絡模型中,連邊關系都是獨立的,而現實網絡并非如此.例如社交網絡中,如果兩個人具有共同好友,則他們將比陌生人更容易產生聯系.當網絡引入幾何模型時,這些拓撲特征就很容易得到解釋.最近,復雜網絡的雙曲空間生成模型被提了出來,該模型假設復雜網絡處于雙曲幾何空間中,節點間連接概率受空間中的距離影響,幾何空間中的三角不等式可以解釋現實網絡的強聚類效應.通過調整模型參數,可轉化為隨機網絡、BA 網絡模型等[32,38].本節首先介紹復雜網絡幾何空間生成模型的基本思想,然后對復雜網絡雙曲空間的各類生成模型展開介紹. 2.2.1 復雜網絡幾何空間的生成模型基本思想 復雜網絡幾何空間的生成模型一般認為網絡存在潛在的幾何空間,網絡由節點和連邊組成,在幾何空間中布點,然后根據一定的概率進行連邊即可生成不同拓撲結構的網絡.不同的生成模型在幾何空間的選擇、節點間連接概率的設計和網絡生成過程這3 方面有所不同.一般認為,連接概率受到幾何空間中的距離和節點的內在固有屬性兩方面的影響,節點固有屬性通過設計節點來隱藏變量表現.根據網絡生成過程,可以將生成模型分為靜態模型和動態模型:靜態模型中,節點和連邊一次性生成,不隨時間變化;動態模型中,網絡中的節點會增加或刪減,連邊在節點加入或移除時發生變化. 2.2.2 多種雙曲空間生成模型 (1)S1生成模型 S1生成模型是一種簡單的復雜網絡幾何生成模型[39],由Krioukov 等人在文獻[40]中提出.該文認為,復雜網絡存在隱藏的幾何度量空間.提出了S1生成模型,通過模型參數控制生成網絡的度分布、聚類系數,并且生成的網絡可具有無標度、強聚類、自相似、小世界特性. S1生成模型中,假設節點均勻分布在半徑為|V|/2π的圓環上,每個節點對(vi,vj)之間的連接概率受到幾何空間中的距離dij和節點拓撲相關固有屬性dc(i,j)的影響,表現為p(dij/dc(i,j)).令κ為與節點度相關的隱藏變量,則dc(i,j)∝κiκj.該式保證節點平均度,連接概率的具體形式可見后文表5.為了生成符合冪率度分布的網絡,可令κ滿足概率分布. (2)H2生成模型 由于雙曲空間是指數擴張的,空間本身就是一個連續版本的“樹”,這與復雜網絡的樹狀結構高度吻合.Krioukov 等人在文獻[30]中提出了H2生成模型,該模型是S1生成模型的等價模型.該文認為,無標度復雜網絡的節點分布在二維有界的雙曲圓盤上.將節點連邊表示能量為隱藏雙曲距離的非相互作用費米子,使用費米狄拉克統計解釋雙曲距離與連接概率的關系,如公式(13)所示: 其中,β=1/T,T為溫度系數,影響生成網絡的聚類系數.T→0 時,公式(13)轉化為,此時聚類系數最大化;隨著T的增大聚類系數降低,T→1 時,聚類系數趨近于0;T→∞時,圖為經典隨機圖.該模型生成網絡的度分布滿足公式(14),由此可生成具有任意冪率指數度分布、聚類系數的復雜網絡: (3)雙曲空間的隨機幾何圖生成模型 基于S1和H2生成模型,文獻[31]進一步提出研究復雜網絡的幾何框架,該文假設復雜網絡是一種嵌入在雙曲空間中的隨機幾何圖,從而非常容易解釋網絡異質性(無標度分布現象)和高聚集性. 如圖5 所示,與經典的隨機幾何圖類似,雙曲空間中的隨機幾何圖首先需要在半徑為R的雙曲圓盤上撒N個點,然后以每個點P為圓心、以r=R為半徑作雙曲圓,落在圓內的點均與P點相連接形成網絡,連接概率可表示為公式(15),通過該模型生成的網絡則同時可具備無標度和高聚集性: Fig.5 Example of a random geometric graph in hyperbolic space[31]圖5 雙曲空間的隨機幾何圖生成模型示例[31] 在該模型中,只有距離小于R的節點對才產生連接,距離較遠則無連接.Krioukov 等人進一步提出軟化連接模型,任意兩點的連接概率與H2模型相同,當β趨近于無窮大時,該模型退化為標準的雙曲空間隨機幾何圖模型.一般情形下,節點間連接概率隨著彼此雙曲距離的增大而減小,R為閾值;當雙曲距離超過R時,連接概率減小速率加快.文獻[38]對雙曲空間的隨機幾何圖模型進行了詳細分析,證明該模型可擴展為6 種不同的模型,見表4. Table 4 Expansion of random geometric graph model in hyperbolic space表4 雙曲空間隨機幾何圖模型擴展 (4)PSO 動態生長模型 前面提到的模型都是靜態模型,網絡中的節點和連接都是一次建立,不隨時間變化的.文獻[32]提出了一個在雙曲空間下的動態生長模型(popularity-similarity-optimization model,簡稱PSO). 如圖6 所示,PSO 生長模型建立在擴展的龐加萊圓盤上,生成網絡過程如下:(1)t=0 時刻,網絡為空;(2)t≥0時刻,坐標為(rt,θt)的新節點t加入,其中,rt=ln(t),θt為[0,2π]的隨機值;(3)t≤m時,新節點t連接到所有已存在的節點;(4)t>m時,新節點連接到m個雙曲距離最近的節點,可轉化為求解m個sΔθst最小的節點,其中,是控制網絡平均節點度的參數,s Fig.6 Example of PSO model[32]圖6 PSO 模型示例[32] 該模型中,網絡的生長過程表現為流行性和相似性的競爭,每個節點徑坐標為ln(s),s為誕生時間,代表流行性特征,s越小,節點誕生越早,新節點連接它的概率越大;Δθ為相似性特征,Δθ越小,節點越相似,連接概率越大.在上述模型中,流行性與相似性對節點連接具有同樣的影響力,可引入流行性與相似性的權重調節參數λ∈[0,1],使得新節點連接時最小化sλΔθst.改進后的模型即為流行性的衰減模型,在t時刻,新節點加入時,對于已存在的節點s 其中,Rt是t時刻雙曲圓盤半徑. 相比于靜態的雙曲空間隨機幾何圖模型,該動態模型具有一些優點. (a)動態模型中節點根據時間逐個加入網絡,可以模擬實際網絡動態生長情況; (b)動態模型將雙曲坐標賦予了實際含義,徑坐標表示的是節點的流行性,角坐標相對差值表示節點間的相似性,節點間的連接產生則表現為實際網絡中流行性與相似性的競爭; (c)該模型可以擴展為偏好依附網絡模型、適應度網絡模型等. PSO 模型存在進一步變體GPA(geometric preferential attachment)模型和nPSO(nonuniform PSO)模型,以便產生具有軟社區[41]或所需社區結構[42]的雙曲合成網絡. (5)GPA 模型 由于PSO 模型及前述雙曲空間中的靜態模型均假設節點角坐標均勻分布在0~2π范圍內,節點間連接概率隨雙曲距離的增大而減小,故沒有角區域包含空間上緊密相連的節點集群以形成明確的社區結構.文獻[41]提出了GPA 生成模型,通過使雙曲圓盤中不同角域具有不同的吸引力來形成社區.該模型僅修改了PSO 模型中的角坐標生成機制,在每個節點加入網絡中時,先根據均勻分布選取角坐標的候選位置φ1,φ2,…,φi,對每個候選點計算其引力大小,然后根據公式(17)的概率選取角坐標: 其中,引力Ai(φj)為離候選點(ri,φj)距離小于ri的已存在節點個數;Λ≥0 為模型參數,代表初始引力,節點角度分布的異質性是其減函數. (6)nPSO 模型 GPA 模型通過調整PSO 模型中角坐標的分布來形成社區結構,但該模型不能明確控制社區的個數和規模.文獻[42]提出了nPSO 模型,通過高斯混合分布生成角坐標,可調整社區數量和規模,高效地生成高聚類網絡. 表5 總結了上述幾種幾何生成模型的設計特點. Table 5 Comparison of geometric space generation models for complex networks表5 復雜網絡幾何空間的生成模型比較 Table 5 Comparison of geometric space generation models for complex networks (Continued 1)表5 復雜網絡幾何空間的生成模型比較(續1) Table 5 Comparison of geometric space generation models for complex networks (Continued 2)表5 復雜網絡幾何空間的生成模型比較(續2) 2.3.1 基于生成模型的嵌入方法 復雜網絡的雙曲空間生成模型能夠構建跨越多種拓撲結構和動態特性的類似于真實網絡的合成網絡,我們是否可以逆轉這種合成,并給定一個真實網絡,將網絡映射(嵌入)到雙曲空間中,在某種程度上與生成模型保持一致?這種嵌入是否存在高效的后續應用?這些問題成為當下的研究熱點,引出了大量研究成果.其中,基于生成模型的嵌入方法假設網絡由給定的生成模型產生,逆向推斷最可能生成該網絡的生成模型參數,主要可分為基于最大似然估計的嵌入方法、基于流形學習的嵌入方法和兩者結合的嵌入方法. 一般來說,復雜網絡雙曲空間的嵌入方法要求輸入為連通圖G=(V,E),因為與網絡中巨片不連通的部分沒有相應的鄰接信息,可以被嵌入到雙曲空間中的任意位置.由于生成模型中徑坐標與節點度高度相關,不同的嵌入方法對于徑坐標一般均根據模型采用直接推斷方法來估計. 對于靜態隨機幾何圖模型,一般采用公式(18)來估計雙曲圓盤最大半徑,用公式(19)來估計每個節點的徑坐標: 對于動態PSO 模型,一般重現其生長過程,根據ri=2λln(i)+2(1-λ)ln(N)指定徑坐標,其中,i={1,2,…,N}為按節點度降序排列的節點編號,λ=1/(γ-1),γ為度分布冪指數. 上述基于生成模型的嵌入方法由此轉變為一個角坐標參數估計問題.基于最大似然估計的嵌入方法根據似然函數推斷每個節點在隱藏的幾何空間中的坐標,該問題為NP-Hard 問題[39],只能通過啟發式方法獲取可能的近似解,該類方法的計算復雜度和嵌入精確度依賴于選擇的啟發式方法和生成模型.基于流形學習的嵌入方法具有一些快速算法,但其中使用矩陣分解的一類方法在應用于大規模網絡嵌入時仍然具有O(N2)的復雜度.另外,基于流行學習的嵌入方法一般在歐氏空間中計算,只能通過龐加萊圓盤的保角性完成角坐標的近似推斷,徑坐標推斷則需要使用上述方法來計算得出.將流行學習與最大似然估計結合所形成的嵌入方法一般先通過流行學習方法近似估計嵌入坐標初值,然后通過最大似然估計法提高嵌入精度.本節將對不同的嵌入方法展開介紹. (1)基于最大似然估計的嵌入方法 最大似然估計的目標是找到生成模型與觀測網絡的最佳匹配,實際是在根據觀測網絡解析參數估計問題.在貝葉斯準則下,該估計問題的后驗概率為 其中,Prob(A,{ri,θi};Model)表示Model生成坐標{ri,θi}和觀測網絡鄰接矩陣A的聯合概率,Prob(A;Model)表示Model生成觀測網絡鄰接矩陣A的先驗概率.公式(21)表示Model生成坐標{ri,θi}的先驗概率,公式(22)表示Model在坐標{ri,θi}下生成鄰接矩陣A的條件概率: 如果公式(21)的先驗概率已知,則可使用貝葉斯估計最大化公式(20)來獲得最佳估計.然而,在大部分情況下先驗信息未知,一般通過最大化似然函數公式(22),或其對數形式公式(23)來推斷嵌入坐標: 基于最大似然估計的嵌入方法通過不同的策略最大化該似然函數來推斷角坐標. ? HyperMap HyperMap[43]是一種基于最大似然估計的雙曲空間無權網絡嵌入方法,通過重現PSO 模型生長過程完成角坐標的推斷.具體過程如下. 1)節點按照度從大到小重整為i=1,2,…,N; 2)節點i=1 誕生,隨機角坐標θ1∈[0,2π]; 3)節點i=2,3,…,N的角坐標通過最大化來獲取. ? HyperMap-CN 在HyperMap 中,度大的節點先生成,且在生成時僅考慮與度更大的節點是否存在連接對其在雙曲空間中坐標的影響,導致度大的節點嵌入的角坐標并不精確.HyperMap-CN[44]通過修改HyperMap 中的似然函數,引入共同鄰居信息來推斷節點嵌入坐標.經過調整后,節點坐標推斷更加精確,但計算復雜度由HyperMap 的O(N3)增大到O(N4).為了減小計算量,Papadopoulos 等人進一步提出混合模型,僅對度大的節點i(ki≤kspeedup)使用修改后的似然優化,并且可采用加速的啟發式方法估計角坐標.對于度大的節點i,先僅考慮i的鄰居節點j(j ? EE 在HyperMap 和HyperMap-CN 的基礎上,文獻[45]提出一種可應用于大規模網絡的雙曲空間靜態隨機幾何圖模型高效嵌入方法,該方法具有擬線性的時間復雜度.與HyperMap 相似,該方法采用貪婪策略完成嵌入.與對網絡全局的嵌入結果同時優化相比,采用貪婪策略,每次最優化一個節點的嵌入坐標相對容易.在得到模型的全局參數估計后,該方法先嵌入網絡的核心部分,即度較大的節點.通過引入共同鄰居信息,優化隨機幾何圖階躍模型的似然來獲取節點對的角度差,然后借助彈性嵌入方法完成網絡核心部分嵌入.對于其他度較小的節點,先根據已嵌入的鄰居節點估計角坐標初值,然后在初值附近隨機采樣多個坐標點,選取似然最優值作為最終結果. (2)基于流行學習的嵌入方法 基于流行學習的嵌入方法以Laplace 特征映射為代表,原始用于高維數據的降維.該類方法一般針對高維情形下的數據稀疏、難以計算等“維數災難”問題,通過某種策略將原始高維空間轉換為低維子空間,在子空間中,數據密度提高,結構簡化,便于后續應用計算.但這類方法降維的子空間一般為歐氏空間,雙曲嵌入只能通過該相似子空間推斷角坐標,而徑坐標及其他參數的推斷則根據具體模型計算得出. ? LaBNE 基于網絡中互相連接的節點在雙曲空間中彼此靠近的基本思想,針對無向、無權、單一組成成分的網絡,Alanis-Lobato 等人提出了基于Laplace 譜分解的龐加萊圓盤嵌入方法LaBNE(Laplacian-based network embedding)[46].定義由節點度組成的對角陣D,網絡的鄰接矩陣A,則網絡的Laplace 矩陣為L=D-A;Y=[y1,y2]為N×2 矩陣,該矩陣的第i行為節點嵌入歐氏圓盤坐標.最小化,使彼此連接的節點坐標靠近,同時加入約束條件YTDY=I來避免節點聚集(I為單位陣).最終,Y的求解可以轉換為求解廣義特征值問題.基于龐加萊圓盤模型的保角性,角坐標可以通過θ=arctan(y2/y1)計算得到. ? Coalescent embedding 基于LaBNE,文獻[47]衍生出一類基于流行學習的雙曲空間嵌入方法.該類方法通過節點度、共同鄰居和節點間最短路徑等局部拓撲信息定義了RA(repulsion-attraction)規則和EBC(edge betweenness centrality)規則.首先,基于該規則對無權網絡加權;然后,使用流行學習方法,如Isomap、拉普拉斯特征映射獲取近似角坐標;最后,引入角度均勻化調整,使角坐標滿足生成模型關于節點分布的基本假設.通過此流程,提高了LaBNE 嵌入的精確性,并提供了一系列嵌入方法. (3)流行學習與最大似然估計結合的嵌入方法 ? LaBNE+HM HyperMap 方法基于搜索求解最大似然估計來完成雙曲空間嵌入,該方法嵌入精度高,但是計算量大,對于大規模的網絡則只能通過啟發式方法求解;LaBNE 方法基于Laplace 譜分解,計算速度相對較快,但卻高度依賴于拓撲信息,僅考慮使有連接的節點彼此靠近,無法保證無連接的節點彼此遠離,在網絡平均度高、聚類系數高時才能獲得較為精確的嵌入結果.LaBNE+HM[48]將兩者的優勢相結合,先使用LaBNE 近似估計嵌入初值,再根據網絡特征調整搜索范圍,采用HyperMap 精確求解,在保證嵌入精度的前提下,縮短了HyperMap 求解時間. ? Mercator Mercator[39]將流行學習與最大似然相結合,在觀測網絡和S1模型間求解最佳匹配.該方法不僅推斷節點角坐標次序及具體值,還推斷節點隱藏期望度和模型全局參數,并且可以將任意度分布網絡嵌入到S1模型中.Mercator 提供兩種模式:在快速模式下,首先根據S1模型統計分析推斷得到全局參數β、μ和每個節點i的隱藏期望度變量κi,然后使用拉普拉斯特征映射估計角坐標θi,基于推斷的β、μ、κi以及節點間有無連邊進一步調整角坐標;精確模式將快速模式嵌入結果作為初值,基于最大似然估計理論,使用洋蔥分解[49]從中心節點開始,在節點鄰居角坐標均值處局部搜索優化角坐標,最后根據優化后的角坐標更新隱藏期望度. (4)其他嵌入方法 ? LPCS 與前述流行學習或最大似然估計的嵌入方法有所不同,LPCS[50]是一種基于社區結構的雙曲空間嵌入方法,通過將社區結構信息引入,使不同社區的節點具有一定的相對角度,相同社區的節點彼此靠近以完成嵌入.該方法基于EPSO[43]生成模型,具有線性時間復雜度,適用于具有一定社區結構的冪率度分布網絡,具體按照如下步驟完成嵌入. 1)檢測層次性社區; 2)從節點數量最多的社區開始,利用社區親密度指數對頂層社區進行排序,該指數考慮了社區內部和社區之間的連邊比例; 3)根據高層社區的順序,遞歸地對低層社區進行排序,直至到達層次結構的底層; 4)為每一個底層社區分配一個與社區節點大小成比例的角度范圍,以不重疊的角度范圍覆蓋整個社區.在相關底層社區的角度范圍內,隨機均勻采樣節點的角坐標. CHM[51]采用與LPCS 類似的方法得到雙曲空間嵌入初值,然后使用最大似然估計優化初值,提高精確度. ? MCA 具有稀疏、強聚類、小世界、異質性的復雜網絡通常可以通過最小生成樹實現高效導航.MCA[52]方法定義相似性依附機制,通過不斷生長的最小生成樹滿足最低彎曲度策略,有效地近似雙曲圓盤中節點角坐標,完成雙曲空間嵌入.該方法具有近似線性復雜度,同時,嵌入精度超過HyperMap-CN,低于Coalescent Embedding.具體過程如下. 3)基于Prim 最小生成樹構造方法依次排列最低排斥度節點,將節點序列通過角度等距調整或斥力-引力等距調整使角坐標分布在[0,2π]. 表6 對上述幾種復雜網絡雙曲空間嵌入方法的時間復雜度進行了簡單總結. Table 6 Comparison of embedding of complex networks to hyperbolic space表6 復雜網絡雙曲空間的嵌入方法比較 2.3.2 無生成模型的嵌入方法 由于表達信息的能力是學習和泛化的先決條件,因此提高嵌入方法的表示能力非常重要,這樣它就可以用于各種實際數據的復雜模式之中.盡管歐氏空間嵌入取得了成功,但最近的研究結果表明,來自多個領域(如生物學、網絡科學、計算機圖形學或計算機視覺)的許多類型的復雜數據(例如圖數據)都顯示出高度非歐幾里德潛在結構[53].在這種情況下,歐幾里德空間沒有提供最強大或最有意義的幾何表示.為了更好地學習數據的層次結構和復雜模式,近期涌現了許多無生成模型的雙曲空間嵌入方法[8,29,34,54-59].這些方法一般通過雙曲距離刻畫數據間相似度來將其嵌入到雙曲空間中,利用雙曲空間對數據的表達能力,在貪婪路由、層級表示學習、知識問答、鏈路預測、最短路徑長度預測、機器翻譯等應用上取得性能上的提升. 通過將復雜網絡嵌入到雙曲空間中,高維稀疏的網絡結構信息轉化為低維稠密的實值向量,具有一般嵌入方法降低計算復雜度的特點.另外,每個節點被表示為潛在幾何空間中確定位置的坐標,幾何空間中的距離度量決定節點間存在連接的可能性,因此可將幾何工具和方法論應用到網絡研究中,以有效解釋現實網絡中的物理現象.例如,幾何空間中的三角不等式給出了現實網絡中聚類效應的合理解釋[60]. 由于復雜網絡雙曲空間模型的物理含義和低維向量表示便于進行高效計算,基于該模型的嵌入將有益于很多圖分析的應用.本節將圍繞基于復雜網絡雙曲空間模型嵌入后的各類應用展開介紹. 近年來,因雙曲空間嵌入對潛在層次結構的有效捕獲,將數據嵌入雙曲空間表示受到越來越多的關注[8,34,56-58].這種層次結構捕獲的能力可能與雙曲空間的關鍵特性密切相關,即:空間容量隨徑向呈指數增長,而在非歐氏空間中呈緩慢的多項式增長.樹狀結構數據幾何形狀的增長方式與雙曲空間保持一致,因此可以通過雙曲空間精確捕捉樹狀的層次結構.如圖7 所示:文獻[56,57]將WordNet 等網絡嵌入到低維雙曲空間中,學習其層次結構,與高維歐氏空間相比具有更優的重構誤差和鏈路預測能力;文獻[58]將問答系統嵌入到雙曲空間中,發現其潛在的層次結構,對問答系統進行快速而高效的排序檢索;文獻[61]將單詞和句子嵌入到雙曲空間中,保留了單詞的共現頻率信息和句子短語選區信息. Fig.7 Example of embedding for learning hierarchical representation in hyperbolic space[56]圖7 雙曲空間中層次結構發現示例[56] 在復雜網絡的龐加萊圓盤嵌入結果中,雙曲距離較近的節點存在較大的連接概率.雙曲空間隨圓盤半徑呈指數增長,位于龐加萊圓盤中心附近的節點有大量的連接,而外圍的節點只靠近角坐標相近的節點.文獻[62-64]研究表明:真實網絡在龐加萊圓盤中嵌入的節點角坐標不是均勻分布的;相反,它們以一種異構的方式分布,節點在某些角坐標附近的集群化揭示了節點之間存在大量連接的區域,該區域組成一個社區[32,41,42,65-68].另外,文獻[69]的研究也說明,具有強模塊化的網絡嵌入到雙曲圓盤中表現出同一社區內節點角度的高度一致性.基于這種思想,根據雙曲模型嵌入結果的聚類[70]或角坐標劃分[64]可以設計快速而高效的社區發現算法,如圖8 所示,相同顏色的節點組成一個社區.基于復雜網絡雙曲圓盤嵌入的社區劃分操作簡單、高效,劃分結果直觀、明確. Fig.8 Example of community detection in hyperbolic space[64]圖8 雙曲空間中社區發現示例[64] 從腦神經網絡到社交網絡、互聯網和交通網絡,信息或能量的傳遞是許多復雜系統的關鍵功能.已有研究結果表明:即使不具備系統的全局知識,網絡中的節點仍能執行有效的信息路由.雙曲嵌入為網絡中每個節點提供了幾何空間坐標,故可以借助坐標進行高效的貪婪路由.在信息轉發時,不需要提前計算路由,每個節點只需知道目的節點坐標和鄰居節點坐標,通過計算雙曲距離,每次選取最接近目的節點的鄰居節點作為下一跳轉發節點,該應用說明,雙曲模型具有可導航性[54,62,71,72].如圖9 所示:由于雙曲空間龐加萊圓盤模型中的測地線(紅色虛線)為弧形,故貪婪路由的中繼轉發節點更偏向于靠近圓盤中心的樞紐節點(藍色實線為轉發路徑).大規模圖中,計算最短路徑較為困難[73],貪婪路由僅需要嵌入后的少量局部信息計算雙曲距離,就可以獲取接近最短的轉發路徑,是一種高效的路由方法. Fig.9 Example of greedy routing in hyperbolic space[62]圖9 雙曲空間中貪婪路由示例[62] 由于復雜網絡具有路徑多樣性,結合雙曲嵌入,大量不相交路徑分布于雙曲空間通過源目的節點的測地線附近[62],類似于貪婪路由的單路徑搜索亦可擴展到多路徑搜索. 復雜網絡的異構性導致每個節點的結構和功能有所不同,精確估計網絡中的關鍵節點在網絡優化、藥物研發、輿情控制等方面具有廣泛的應用前景.網絡的介數中心性這一經典的關鍵節點排序指標需要計算所有節點對的最短路徑,在無權網絡中,用布蘭德斯的算法計算介數中心性具有O(|V||E|)的時間復雜度.而在雙曲空間中,通過貪婪路由近似最短路徑,只需要計算所有節點對的雙曲距離即可估算出介數中心性,具有O(|V|2)的時間復雜度[73].類似的研究工作包括文獻[74]提出的雙曲空間中快速計算接近度中心性方法和文獻[75]提出的雙曲流量負載中心性(hyperbolic traffic load centrality)方法. 鏈路預測是指通過已知的各種信息,預測給定網絡中尚不存在連邊的兩個節點之間產生連接的可能性.鏈路預測模型可以幫助我們理解網絡結構,并且具有很多實際的應用價值,比如指導蛋白質交互實驗、建立推薦系統等[50].很多鏈路預測方法基于節點相似性,其基本假設是:相似性越大的節點之間,存在鏈接的可能性越大.復雜網絡的雙曲空間模型中明確定義了與雙曲距離密切相關的連接概率,僅僅只需要根據嵌入坐標計算節點對的雙曲距離,就可以進行鏈路預測.該思想操作簡單,并且可以獲得高精度預測結果,在部分網絡上性能甚至優于Common-neighbors(CN)和Katz index(Katz)等經典鏈路預測方法[32,43,44,50,67,76]. 本文所述研究大多都是靜態網絡的雙曲空間嵌入,但是現實網絡一般都具有復雜的動態演變過程,比如社交網絡中不斷有新用戶加入和用戶交友行為產生.隨著網絡的演化,網絡的表征也需要隨之更新.已有的雙曲空間中網絡演化的分析方法將動態網絡視為由多個靜態網絡快照組成,分時段對靜態快照嵌入雙曲空間來研究網絡演化規律[64].但這類方法將靜態網絡嵌入算法直接應用到動態演化網絡上會遇到一系列問題,比如:由于缺乏增量嵌入方法,即使網絡變化很小也必須重新嵌入;由于一些隨機噪聲的存在,不同時段的嵌入結果可能不夠穩定、前后差異較大等.因此,雙曲空間中的網絡演化分析仍然是未來研究的重要課題之一. 關系的多重性是現實網絡的共同特征,比如社交網絡中,人與人之間的關系多種多樣.現實的多層網絡往往不是單層網絡的隨機組合,分析不同網絡層次之間的關聯性,對于理解現實網絡具有重大意義.通過將每一層網絡嵌入到雙曲空間中,節點層與層之間的坐標會表現出顯著的相關性,這些相關性揭示了多層網絡隱藏的幾何關聯,可以應用于層間鏈路預測、貪婪路由、社區發現[67].另外,在相互作用的多層網絡中,部分節點的失效會導致與之依賴的節點失效,從而產生級聯失效現象,這種級聯失效往往會導致整個相互依賴系統的崩潰.在網絡科學研究中,滲流理論是研究復雜網絡魯棒性與網絡團簇演變的一個重要手段.已有研究結果表明:當層間角坐標的相關性較高時,滲流變換平滑,網絡魯棒性較強;當相關性較低時,滲流變換易發生突變,網絡魯棒性較弱[69,77].多層網絡的雙曲空間嵌入,可以對層間關聯性及魯棒性進行分析,有助于設計網絡保護策略和更健壯、更可控的相互依賴系統. 許多復雜的網絡,如Internet、社交和生物網絡,往往具有節點的異構度分布.這些分布可以用冪律衰減來描述:它們在度變量重新標度的情況下保持不變.這表明可能存在對網絡結構的某種變換,使其統計特性保持不變[78].重整化變換按照一定的規則將網絡中的數個節點合并為超級節點,抓取網絡中的部分屬性.通過重整化變換,可將復雜結構簡單化,便于分析網絡結構特征.例如,該變換揭示了某些網絡具有自相似嵌套的層次結構[79].已有研究結果表明:通過對復雜網絡雙曲空間嵌入的結果進行重整化,使相同徑坐標下角坐標彼此靠近的節點合并,可實現網絡規模縮小和多尺度貪婪路由[80]. 圖的二維可視化問題研究遍布網絡科學、數據挖掘、生物科學等各個領域.復雜網絡雙曲空間的表征學習為可視化提供了極大的便利,將每個節點通過二維實值向量表示,研究者們可以很容易地獲得高維數據的可視化表達.并且,利用復雜網絡雙曲空間模型的物理含義,該可視化表達對社區發現、層次結構提取、流行性相似性分析以及其他潛在網絡結構發現都具有重大意義. 基于雙曲空間對樹狀結構數據的精確表示和高效捕獲層次結構的能力,雙曲空間的嵌入已經應用到各類領域中,包括自然語言處理[34,56,61]和網絡科學[43,44,46]等.相比于高維的歐氏空間,這些方法僅只需要低維的雙曲空間,便能夠在各自的后續任務中取得更佳性能[81,82].例如,文獻[81]將支持向量機(support vector machine,簡稱SVM)與雙曲空間相結合,提出了雙曲支持向量機,通過雙曲面模型進行超平面劃分,在合成網絡與現實網絡的節點多分類任務上取得性能上的提升.文獻[29,59,82]將雙曲空間與神經網絡相結合,分別引入雙曲神經網絡、雙曲注意力網絡、雙曲圖卷積網絡,在機器翻譯、圖分析、可視化問答等任務上取得性能上的提升. 本文介紹了多種復雜網絡雙曲空間的表征學習方法,不同方法在坐標推斷精確度、后續任務性能以及算法執行時間上存在一定的差異.通過將各種方法應用于合成網絡和真實網絡,來給出其性能對比結果.其中,合成網絡通過PSO 模型生成,節點數均為1 000,冪律度分布冪指數γ=2.5,平均度,溫度系數T=0.1,0.3,0.5,0.7,0.9,每組參數合成5 個網絡.圖10 給出了實驗結果,a、b、c組分別對應平均度為4、8、12 的合成網絡.C-score衡量角坐標正確排序的節點對比例;HD-correlation 為所有節點對真實和推斷的雙曲距離之間的皮爾遜相關系數;GR-score 衡量嵌入后貪婪路由的性能,當GR-score 為1 時,所有節點對貪婪路由均可成功且為最短路徑;Time為嵌入算法執行時間.各指標的詳細定義參見文獻[47]. Fig.10 Performance evaluation of hyperbolic embedding in synthetic networks圖10 合成網絡雙曲嵌入的性能評估 除了合成網絡,本文還將不同的表征學習方法應用于真實網絡,表7 給出了不同真實網絡數據的相關特征和來源,所有的真實網絡均經過去除自環、重邊、取最大連通片的處理過程. Table 7 Overview of the considered real-world network data表7 真實網絡數據概覽 由于真實網絡數據無法獲知雙曲空間原始坐標,只能根據推斷坐標分析其性能差異,故無法計算C-score 和HD-correlation 指標,這里使用連接概率和對數似然替代分析.圖11 給出了真實網絡雙曲嵌入的性能對比結果. Fig.11 Performance evaluation of hyperbolic embedding in real-world networks圖11 真實網絡雙曲嵌入的性能評估 本文介紹了現有的復雜網絡的雙曲幾何模型、嵌入方法以及應用任務.相對于其他網絡模型,雙曲幾何模型具有以下優勢:(1)雙曲空間的指數擴張使得空間容量大、易于表達樹狀層次結構數據;(2)雙曲幾何模型能夠近似網絡的樹狀分支,產生具有冪率度分布和自相似性的網絡;(3)雙曲幾何空間中的三角不等式說明與某節點A相連的兩個節點B和C之間容易產生連接,可以解釋現實網絡中出現的強聚類效應;(4)復雜網絡的雙曲空間模型將網絡映射到雙曲幾何空間中,通過雙曲距離編碼節點間連接概率,使得模型參數可以反映節點的流行性和相似性;(5)復雜網絡的雙曲空間嵌入是一個網絡降維過程,便于后續應用的高效計算,其嵌入坐標可以作為機器學習算法輸入;(6)該模型提供了一種新的強有力的網絡可視化方法,社區結構可以通過角區域集聚性來加以表征. 相對于歐氏空間的多項式擴張,指數擴張的雙曲空間具有更大的容量,更適合表達樹狀結構、層次結構的數據.通過將數據嵌入到雙曲空間,可以近似捕獲其潛在的層次結構.徑坐標與節點度高度相關,可用于發現度相關結構、網絡自相似結構、快速比較和分析節點流行性、快速層級劃分等任務;角坐標間距離與節點相似性相關,可用于快速社區劃分、相似節點融合、多層網絡關聯性及魯棒性分析、鏈路預測等任務.雙曲幾何模型在具有較強可解釋性的同時,還能通過幾何工具和方法研究數據結構.其強大的層次結構表達能力使得雙曲幾何的嵌入不僅能夠應用于傳統的復雜網絡圖分析任務,還為表征學習及其后續應用開辟了新的方向.如圖12(a)所示:可以將雙曲空間嵌入應用于監督學習,對象可以是具有層次結構的文本符號數據或圖像數據,研究其分類、層次表達等相關問題;類似地,對于無監督學習,可以構建相似矩陣完成雙曲嵌入,如圖12(b)所示. Fig.12 Example of machine learning combined with hyperbolic space圖12 雙曲空間與機器學習結合應用示例 雖然復雜網絡的雙曲幾何模型已經取得了豐富的研究成果,但是仍在以下幾個方面面臨著巨大挑戰. (1)動態變化網絡的生成.現實生活中,大量網絡的結構具有動態性,現有的雙曲幾何模型主要是靜態的,雖然PSO 模型能夠刻畫一類網絡的動態生成過程,但仍存在許多現實網絡無法通過PSO 模型動態重現.因此,如何在雙曲幾何模型的框架下模擬現實網絡的動態變化過程,是亟待解決的問題; (2)多層次、多關系網絡的生成.在已有的研究中,復雜網絡的雙曲幾何模型成功地描述了從生物系統到信息系統和社會系統等各種復雜系統的形成過程,然而目前的研究對象大多是單一層次的網絡,僅有少數多層網絡雙曲空間的生成模型[67],許多現實網絡具有多層次、多關系的網絡結構.這些網絡的不同層之間一般不是隨機連接的,如何挖掘層間關聯關系,形成多層次、多關系網絡的雙曲幾何模型,是復雜網絡雙曲空間表征學習面臨的重要挑戰; (3)高維雙曲空間的嵌入.目前,基于生成模型的雙曲空間嵌入方法大多將復雜網絡嵌入到二維的雙曲空間中,現實數據中,實體之間的關系往往更加復雜,難以在二維雙曲空間中精確表示.提升雙曲空間的嵌入維度,可以增強模型的表達能力和適應性,高維雙曲空間嵌入方法的研究,是未來的一個重要方向; (4)更大規模、更高速率的嵌入方法.已有的雙曲空間嵌入方法僅僅能夠應用于小規模網絡,而實際場景中的網絡動輒上億節點,因此,克服大規模網絡嵌入面臨的存儲、計算復雜度等困難,推廣雙曲空間嵌入方法到大規模網絡中,將開辟更加廣泛的應用領域; (5)與神經網絡、機器學習相結合,將適合使用雙曲空間表示的數據、距離,轉移到雙曲空間中.雙曲空間相較于歐氏空間具有更強的樹狀結構表達能力,如何調整神經網絡、機器學習的模型,充分發掘雙曲空間的表達能力,是未來的一個開放性研究問題.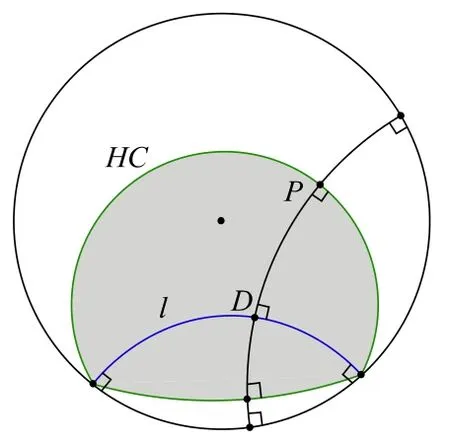
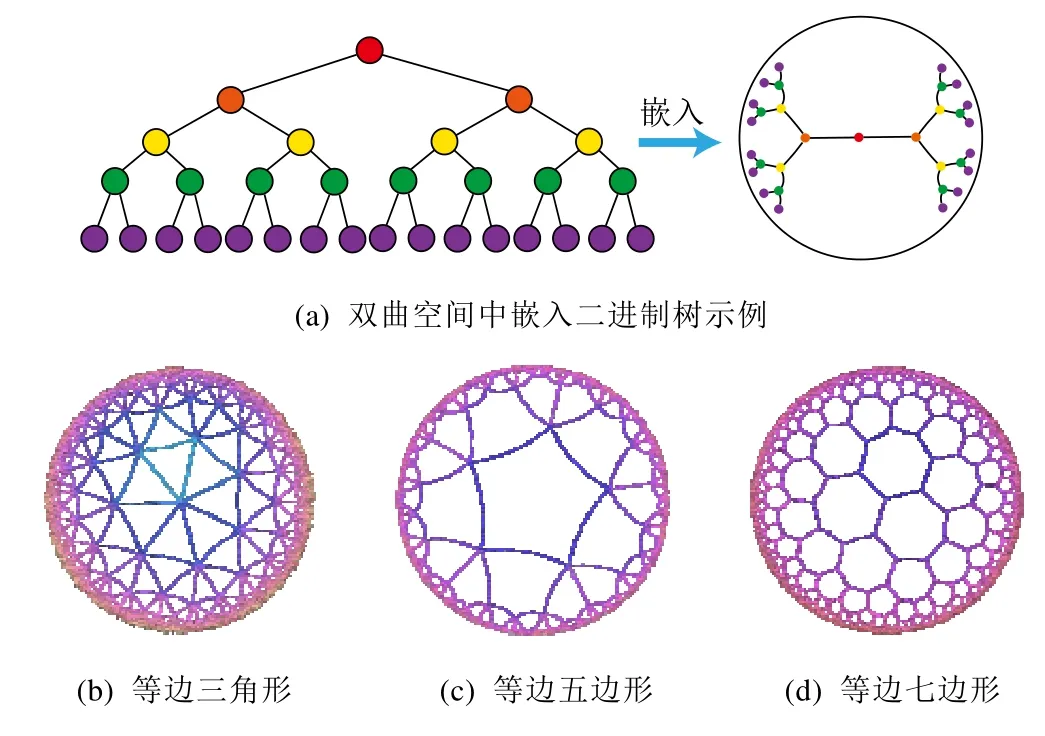
2.2 復雜網絡雙曲空間的生成模型

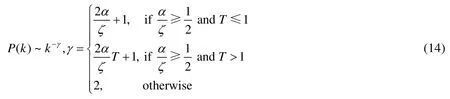







2.3 復雜網絡雙曲空間的嵌入方法
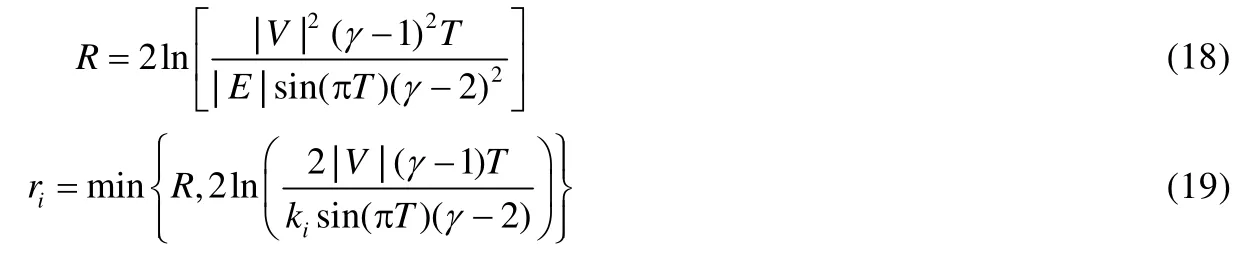
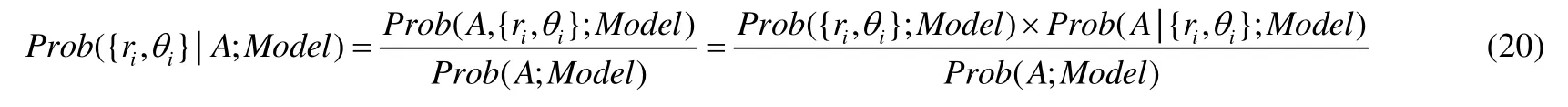
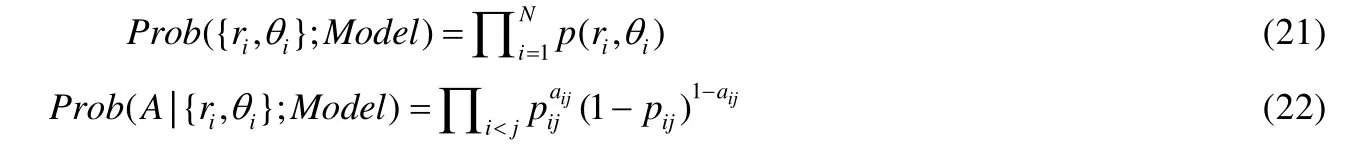
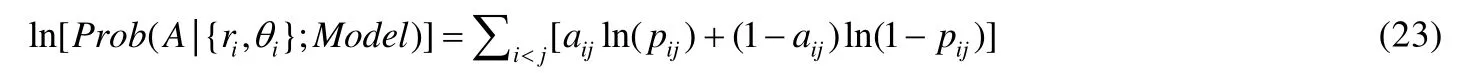
3 復雜網絡雙曲空間模型的應用
3.1 基于雙曲徑坐標的層次結構發現
3.2 基于雙曲角坐標劃分的社區發現
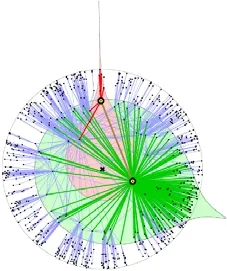
3.3 基于雙曲距離度量的路徑搜索
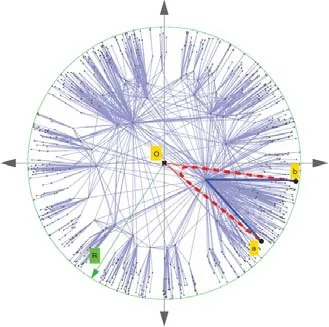
3.4 基于雙曲距離度量的關鍵節點發現
3.5 基于雙曲距離度量的鏈路預測
3.6 基于雙曲坐標的網絡演化分析
3.7 基于雙曲坐標的多層網絡關聯性及魯棒性分析
3.8 基于雙曲坐標的復雜網絡幾何重整化
3.9 基于雙曲空間表達模型的可視化
3.10 雙曲空間結合機器學習
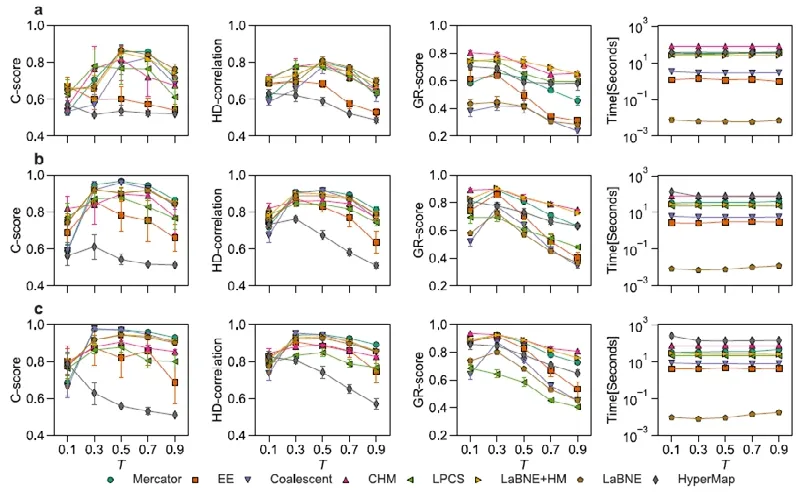
4 復雜網絡雙曲空間表征學習方法的性能評估
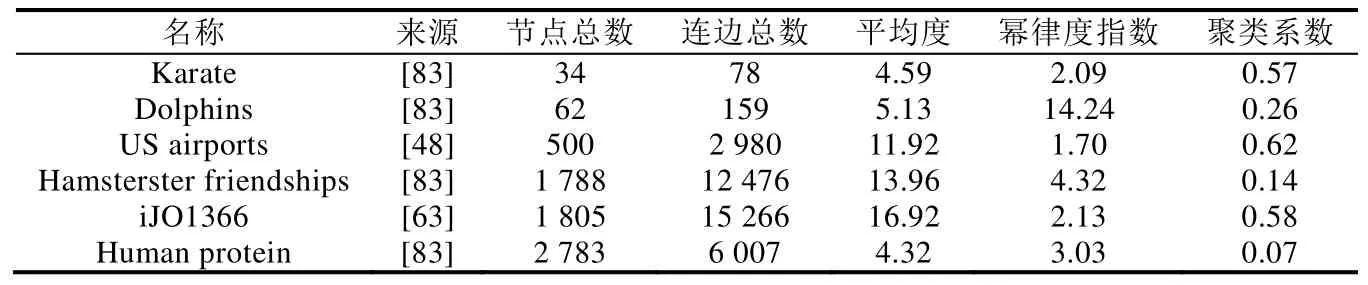
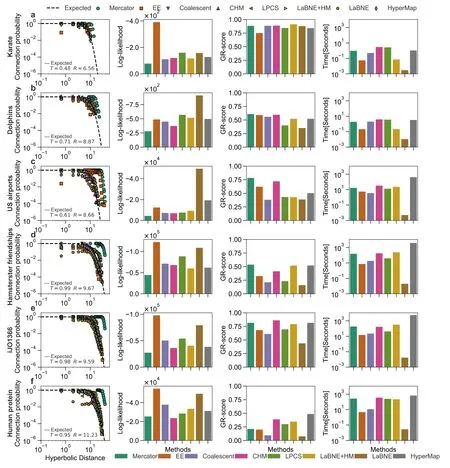
5 結論及展望
 猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24兒童故事畫報(2019年5期)2019-05-26 14:26:14光學精密工程(2016年6期)2016-11-07 09:07:19Coco薇(2016年2期)2016-03-22 02:42:52核科學與工程(2015年4期)2015-09-26 11:59:03Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24兒童故事畫報(2019年5期)2019-05-26 14:26:14光學精密工程(2016年6期)2016-11-07 09:07:19Coco薇(2016年2期)2016-03-22 02:42:52核科學與工程(2015年4期)2015-09-26 11:59:03Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56
