基于重采樣與屬性約簡的多模態(tài)選擇性集成學(xué)習(xí)
2021-05-20 07:02:40張友強楊愛光
計算機工程與設(shè)計 2021年5期
關(guān)鍵詞:分類
江 峰,李 瑞,張友強,楊愛光
(青島科技大學(xué) 信息科學(xué)技術(shù)學(xué)院,山東 青島 266061)
0 引 言
集成學(xué)習(xí)的目的是訓(xùn)練多個不同的個體分類器,并通過某種組合策略(例如,投票)將這些個體分類器集成在一起,從而生成泛化能力更強的集成分類器[1,2]。如果只是選擇一部分的個體分類器來生成集成分類器,那么這種集成學(xué)習(xí)策略就稱為“選擇性集成”[3]。選擇性集成算法需要對個體分類器進行擾亂,按照擾亂手段的不同,可以將現(xiàn)有集成算法分成兩大類:基于單模態(tài)擾亂的選擇性集成算法(簡稱“單擾亂算法”)和基于多模態(tài)擾亂的選擇性集成算法(簡稱“多擾亂算法”)。單擾亂算法只利用一種策略來將數(shù)據(jù)集打亂,以得到多個不同的個體分類器[4,5]。多擾亂算法則利用多種策略來將數(shù)據(jù)集打亂,以得到多個不同的個體分類器[6]。相對于單擾亂算法而言,多擾亂算法具有顯著的優(yōu)勢,即更容易實現(xiàn)個體分類器的多樣性。正是由于上述優(yōu)勢,多擾亂算法得到了廣泛研究與應(yīng)用[7,8]。
本文針對多擾亂算法進行研究,利用兩種策略分別將數(shù)據(jù)集的樣本與特征空間打亂,從而得到一種選擇性集成算法SE_RSAR。該算法的大體思路如下:①通過隨機的重復(fù)采樣策略將數(shù)據(jù)集的樣本空間打亂,產(chǎn)生多個采樣集;②對任意一個采樣集Sample,通過基于相對決策熵的屬性約簡策略先對Sample進行約簡,然后利用約簡后的采樣集訓(xùn)練一個個體分類器;③從第②步所生成的所有個體分類器中,利用貪婪機制[9]挑選出若干個性能較好且差異性較大的個體分類器;④通過投票,把第③步所挑選出的個體分類器組合在一起,得到集成分類器。
實驗采用KNN算法來訓(xùn)練個體分類器,并在UCI數(shù)據(jù)集上將SE_RSAR算法與現(xiàn)有的同類型集成學(xué)習(xí)算法性能相比較。實驗結(jié)果表明,SE_RSAR算法能夠取得更好的分類效果。
1 粗糙集的基本知識
本節(jié)引入與粗糙集理論相關(guān)的一些主要概念。在粗糙集中,一般使用信息系統(tǒng)來存儲數(shù)據(jù)(關(guān)于信息系統(tǒng)的詳細定義可參考文獻[10,11])。當我們將一個信息系統(tǒng)中的屬性集分成條件屬性集和決策屬性集時,就得到了另外一個概念:決策表(關(guān)于決策表的詳細定義也可參考文獻[10,11])。
在粗糙集領(lǐng)域,“知識”代表著一種分類的能力,知識通常由不可分辨關(guān)系來刻畫。不可分辨關(guān)系作為粗糙集理論的基礎(chǔ),假定關(guān)于論域的某類知識,并采用屬性和屬性值來描述論域中的對象,若兩個對象(或?qū)ο蠹?存在相同的屬性及屬性值,則稱它們之間存在不可分辨關(guān)系。給定一個決策表DT=(U,C,D,V,f) 和任意的條件屬性子集B(其中,B?C), 論域U上的二元關(guān)系IND(B)={(x,y)∈U×U∶?b∈B,f(x,b)=f(y,b)} 被稱為不可分辨關(guān)系。不可分辨關(guān)系本身也是一種等價關(guān)系。對于論域U中的任意一個元素u,u在不可分辨關(guān)系IND(B) 下所屬的等價類被定義成: [u]B={v∈U∶(u,v)∈IND(B)}。
利用不可分辨關(guān)系,可以進一步定義正區(qū)域、粗糙度、屬性依賴度等概念,其中,D的B-正區(qū)域是指U中所有根據(jù)關(guān)系U/IND(B) 可以準確劃分到U/IND(D) 中的等價類去的對象集合,具體定義見文獻[10-12],另外,粗糙度和屬性依賴度的具體定義也同樣見文獻[10-12]。
2 基于相對決策熵的屬性約簡
屬性約簡是粗糙集理論中的一個重要研究課題,它是指在保持分類能力不變的前提下,將決策表中不影響決策或者分類的多余屬性去掉。在Pawlak提出的經(jīng)典粗糙集模型中,通常使用代數(shù)表達式來定義粗糙集中的許多基本概念。粗糙集理論認為,知識的粗糙性可以通過集合之間的包含關(guān)系和代數(shù)中的等價關(guān)系來描述。但是,用這種方式很難從本質(zhì)上來理解知識的粗糙性。為了深入刻畫粗糙集中信息與粗糙度之間的關(guān)系,許多研究人員將信息熵引入到粗糙集中[13]。本文將在粗糙集中引入一種新的信息熵——相對決策熵,并利用其來進行屬性約簡[14,15]。
與已有文獻中所提出的關(guān)于信息熵的定義不同,相對決策熵的定義與粗糙度這一概念有關(guān)[15]。
定義1 相對決策熵:給定決策表DT=(U,C,D,V,f), 令U/IND(D)={D1,…,Dm} 表示不可分辨關(guān)系IND(D)對U的劃分。對任意B?C,D相對于B的決策熵RDE(D,B) 定義為
其中,γB(D) 表示決策屬性集D對B的依賴度,ρB(Di) 表示集合Di在關(guān)系IND(B)下的粗糙度, 1≤i≤m。
在定義1的基礎(chǔ)上,可以進一步定義基于相對決策熵的屬性約簡和基于相對決策熵的屬性重要性,具體定義可參考文獻[15]。
接下來,我們給出一個啟發(fā)式屬性約簡算法(即算法1),用于在給定的決策表中計算出基于相對決策熵的約簡。
算法1: 基于相對決策熵的約簡計算
輸入: 決策表DT=(U,C,D,V,f)
輸出: 約簡R
算法初始化: 令Core←?,R←?
(1) 計算劃分U/IND(C),U/IND(D) 和U/IND(C∪D)。
(2) 計算相對決策熵RDE(D,C)。
(3) 對每個a∈C, 反復(fù)執(zhí)行:
(3.1) 計算相對決策熵RDE(D,C-{a});
(3.2) 如果RDE(D,C-{a})>RDE(D,C), 則令Core←Core∪{a}。
(4) 令R←Core。
(5) 如果R=?, 則令Temp←RDE(D,C)+1, 否則,令Temp←RDE(D,R)。
(6) 當Temp≠RDE(D,C) 時, 反復(fù)執(zhí)行:
(6.1) 對每個b∈C-R, 反復(fù)執(zhí)行:
(I) 計算RDE(D,R∪{b});
(II) 計算b相對于R和D的重要性SGF(b,R,D)=RDE(D,R)-RDE(D,R∪{b})。
(6.2) 從C-R中選擇重要性最大的屬性bmax(如果有多個屬性同時具有最大的重要性,則選擇使得γ{bmax}(D) 值最大的bmax)。
(6.3) 令Temp←RDE(D,R∪{bmax}),R←R∪{bmax}。
(7) 對每個ai∈R(其中,下標i的取值從 |R|-1 逐步遞減到|Core|), 反復(fù)執(zhí)行:
計算RDE(D,R-{ai}), 如果RDE(D,R-{ai})=RDE(D,C), 則將元素ai從集合R中移去。
(8) 返回約簡R。
在算法1中,我們采用一種預(yù)先對論域U進行計數(shù)排序,然后再計算劃分U/IND(B) 的策略(其中,B?C是任意一個屬性子集),以此使得計算U/IND(B) 的時間復(fù)雜度為O(|B|×|U|)。 最壞情況下,算法1的時間復(fù)雜度為:O(|C∪D|2×|U|), 空間復(fù)雜度為O(|C∪D|×|U|)。
3 SE_RSAR算法
Bagging、Boosting和RSM(random subspace me-thod) 是3個非常具有代表性的單擾亂算法,其中,前面兩個算法利用“樣本空間擾亂”這種策略來將數(shù)據(jù)集打亂;第三個算法則利用“特征空間擾亂”這種策略來將數(shù)據(jù)集打亂。通常,單擾亂算法在提升個體分類器的多樣性方面存在不足。針對這一不足,本文設(shè)計出多擾亂算法SE_RSAR[16-18],利用兩種策略分別將數(shù)據(jù)集的樣本與特征空間打亂。SE_RSAR算法可分成4個階段:①樣本空間打亂階段。通過隨機的重復(fù)采樣策略將數(shù)據(jù)集的樣本空間打亂,產(chǎn)生多個采樣集;②特征空間打亂階段。對任意一個采樣集Sample,通過基于相對決策熵的屬性約簡策略先對Sample進行約簡[19],然后利用約簡后的采樣集訓(xùn)練一個個體分類器;③貪婪搜索階段。從第②階段所生成的所有個體分類器中,利用貪婪機制挑選出若干個性能較好且差異性較大的個體分類器;④投票階段。通過投票,把第③階段所挑選出的個體分類器組合在一起,得到集成分類器。
SE_RSAR算法的第③階段利用貪婪機制[20]挑選出若干個性能較好且差異性較大的個體分類器,具體過程如下:首先,利用給定的驗證集去驗證每一個待選的個體分類器的性能,根據(jù)這些個體分類器的性能從高到低對它們進行排序,并將性能最好的一個個體分類器挑選到分類器集合E中[21];其次,從所有剩下的待選個體分類器中挑選出當前最優(yōu)的個體分類器加入到E中,挑選標準為:相對于其它的待選個體分類器,將最優(yōu)個體分類器加入到E中之后,由E中個體分類器所組合而成的集成分類器具有最好的性能;第三,重復(fù)執(zhí)行第二步,每次挑選出當前最優(yōu)個體分類器加入到E中之后,都把由E中元素所組合而成的集成分類器的性能保存起來。通常,集成分類器的性能一開始會不斷地增加,在獲得最高值之后將會逐漸地下降;第四,將那些在集成分類器的性能獲得最高值之后加入到E中的個體分類器從E中剔除。
下面,給出SE_RSAR的偽代碼。
算法2: 多擾亂算法SE_RSAR
輸入: 給定的訓(xùn)練集與驗證集;待選的個體分類器數(shù)量M。
輸出: 集成分類器EC。
算法初始化: 將集合E、R和B都初始化為空集, 并且將變量num初始化為0。
(1) 對每一個i∈{1,2,…,M}, 循環(huán)執(zhí)行下面的語句:
(1.1) 針對給定的訓(xùn)練集,通過隨機的重復(fù)采樣策略對其進行采樣, 得到一個采樣集Si;
(1.2) 使用算法1在集合Si上產(chǎn)生一個約簡ri, 將ri作為一個元素加入到集合R, 并且利用ri對Si進行特征選擇, 從而得到特征選擇之后的采樣集Sri;
(1.3) 在采樣集Sri上通過預(yù)先確定的分類算法訓(xùn)練一個個體分類器bi, 并且將bi作為一個元素加入到待選個體分類器集合B中。
(2) 對每一個i∈{1,2,…,M}, 循環(huán)執(zhí)行下面的語句:
(2.1) 針對給定的驗證集, 通過約簡ri對其進行特征選擇, 從而得到特征選擇之后的驗證集Vri;
(2.2) 計算個體分類器bi在驗證集Vri上的分類精度。
(3) 將B={b1,…,bM} 中的所有待選個體分類器按照其分類精度從高到低進行排序。
(4) 挑選出B中排在第一位的個體分類器b1, 將b1作為選中的個體分類器加入到集合E中, 并從集合B中剔除b1。
(5) 如果集合B包含兩個或兩個以上的元素, 則循環(huán)執(zhí)行下面的語句:
(5.1) 對于B中的任意一個個體分類器b, 將E∪{b} 中所有的個體分類器組合成一個集成分類器, 并驗證該集成分類器在給定驗證集上的分類精度Pb;
(5.2) 挑選出B中的個體分類器bmax, 挑選標準為: 由E∪{bmax} 中個體分類器所組合而成的集成分類器的分類精度Pbmax最大。令E←E∪{bmax},B←B-{bmax}, Array[num]←Pbmax, num←num+1。
(6) 把Array中值最大的元素的下標賦值給變量h, 并且將集合E中所有下標在h之后的個體分類器都從E中剔除。
(7) 通過投票, 把E中的個體分類器組合在一起, 得到集成分類器EC。
(8) 返回集成分類器EC。
4 實驗結(jié)果
為了驗證SE_RSAR算法的性能,我們在8個UCI數(shù)據(jù)集上進行了實驗,其中,基分類器采用1NN(1-最近鄰)分類算法來訓(xùn)練。表1給出了這8個UCI數(shù)據(jù)集的詳細信息。
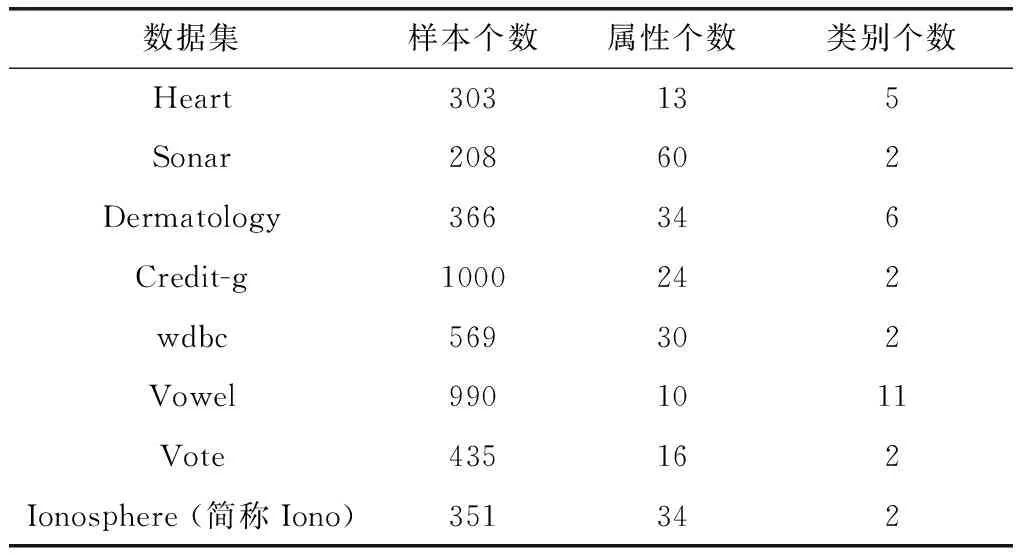
表1 8個UCI數(shù)據(jù)集
本文所采用的分類評估指標為:分類精度(Accuracy)。分類精度的具體定義如下:對于給定的測試集T,分類器正確分類的樣本數(shù)量與T中總的樣本數(shù)量之比。假設(shè)當前考慮的是一個二分類問題,分類精度可以通過表2所示的混淆矩陣來進行計算,即

Accuracy=(TP+TN)/(TP+FN+FP+TN)
我們采用Java語言實現(xiàn)了SE_RSAR算法。實驗中,對于數(shù)據(jù)集中的連續(xù)型屬性,我們預(yù)先使用等寬離散化算法進行離散化處理,其中,區(qū)間數(shù)設(shè)置為5。對于一個給定的數(shù)據(jù)集T,我們將T隨機分為一個訓(xùn)練集(T中50%的數(shù)據(jù))和一個測試集(剩余50%的數(shù)據(jù))。另外,由于SE_RSAR 算法需要使用一個驗證集來選擇一組性能較好且差異性較大的個體分類器,因此,我們還從訓(xùn)練集中隨機選取60%的樣本作為驗證集。對于SE_RSAR算法,我們還需要設(shè)定待選個體分類器的數(shù)量,在實驗中,待選個體分類器的數(shù)量統(tǒng)一設(shè)置為30。
在實驗過程中,我們分別采用了兩種不同的采樣方法來獲取采樣集:無放回采樣和有放回采樣。在使用無放回采樣時,我們采取了3種不同的采樣比例(90%、95%和98%)來對訓(xùn)練集進行隨機采樣。在使用有放回采樣時,我們同樣采取了3種不同的采樣比例(90%、95%和100%)來對訓(xùn)練集進行隨機采樣。表3給出了在使用無放回采樣時SE_RSAR算法在各個數(shù)據(jù)集上以及不同采樣比例下的分類性能。表4則給出了在使用有放回采樣時SE_RSAR 算法在各個數(shù)據(jù)集上以及不同采樣比例下的分類性能。

表3 無放回采樣時SE_RSAR算法的性能/%
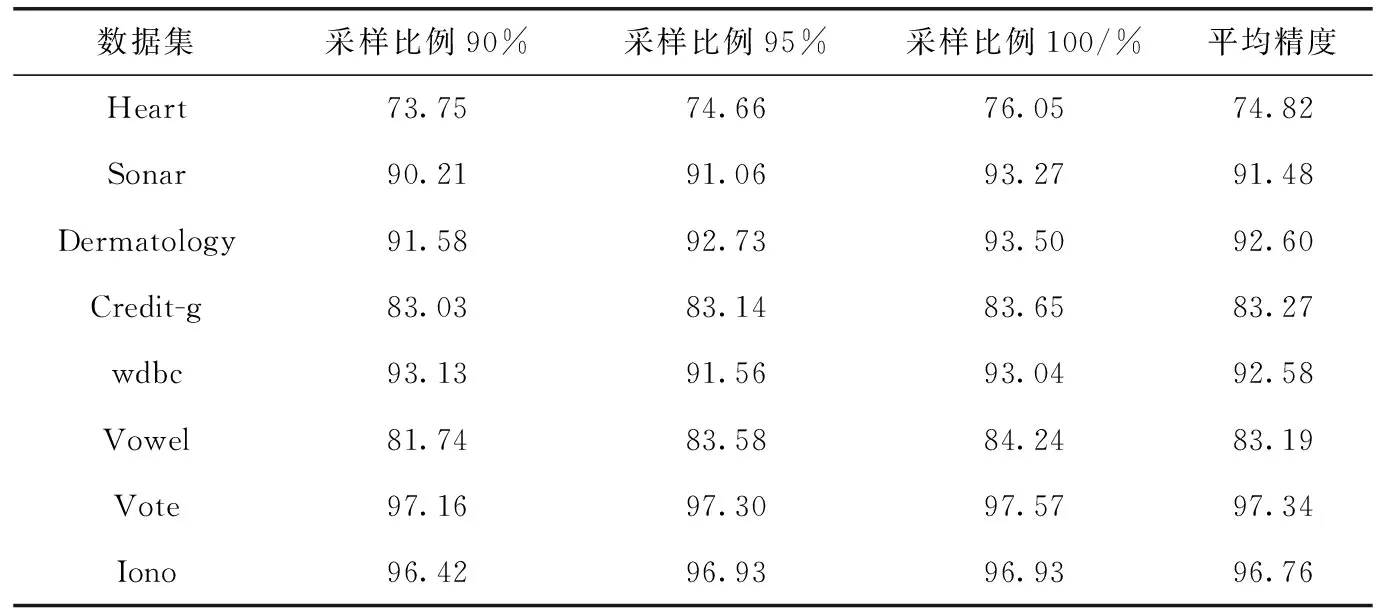
表4 有放回采樣時SE_RSAR算法的性能/%
在表3和表4中,第2列-第4列的實驗結(jié)果都是在重復(fù)執(zhí)行100次之后,取這100次實驗結(jié)果的平均值。另外,最后一列結(jié)果為第2-第4列結(jié)果的平均值,即SE_RSAR算法在3種不同采樣比例下的平均精度。
從表3可以看出,對于無放回采樣而言,95%的采樣比例在5個數(shù)據(jù)集上取得了最高的分類精度,90%的采樣比例則在兩個數(shù)據(jù)集上取得了最高的分類精度,98%的采樣比例只在“Vowel”數(shù)據(jù)集上取得了最高的分類精度。上述結(jié)果表明,95%的采樣比例比較適合于無放回采樣。另外,從表4可以看出,對于有放回采樣而言,100%的采樣比例在7個數(shù)據(jù)集上取得了最高的分類精度,而90%的采樣比例只在數(shù)據(jù)集“wdbc”上取得了最高的分類精度。上述結(jié)果表明,100%的采樣比例比較適合于有放回采樣。
如果將表3和表4中的數(shù)據(jù)進行對比,我們可以看出,SE_RSAR算法在無放回采樣下的性能要優(yōu)于其在有放回采樣下的性能,這是因為在大部分數(shù)據(jù)集上(除了“Sonar”數(shù)據(jù)集之外),采用無放回采樣的SE_RSAR算法,其平均精度要高于采用有放回采樣的SE_RSAR算法。
接下來,我們將SE_RSAR算法與兩種常用的單模態(tài)集成算法(Bagging和RSM)以及一種多模態(tài)集成算法(Bagging-RSM)進行對比,以驗證SE_RSAR算法的性能。為了確保比較的公平性,這里SE_RSAR算法將同樣采用在Bagging和Bagging-RSM中所使用的自助采樣方法,即對訓(xùn)練集進行有放回并且采樣比例為100%的采樣。對于Bagging、RSM和Bagging-RSM,我們直接使用WEKA[22]中所提供的算法來進行實驗,所有參數(shù)均設(shè)置為WEKA中的默認值。
在表5中,我們給出了不同算法的分類結(jié)果。
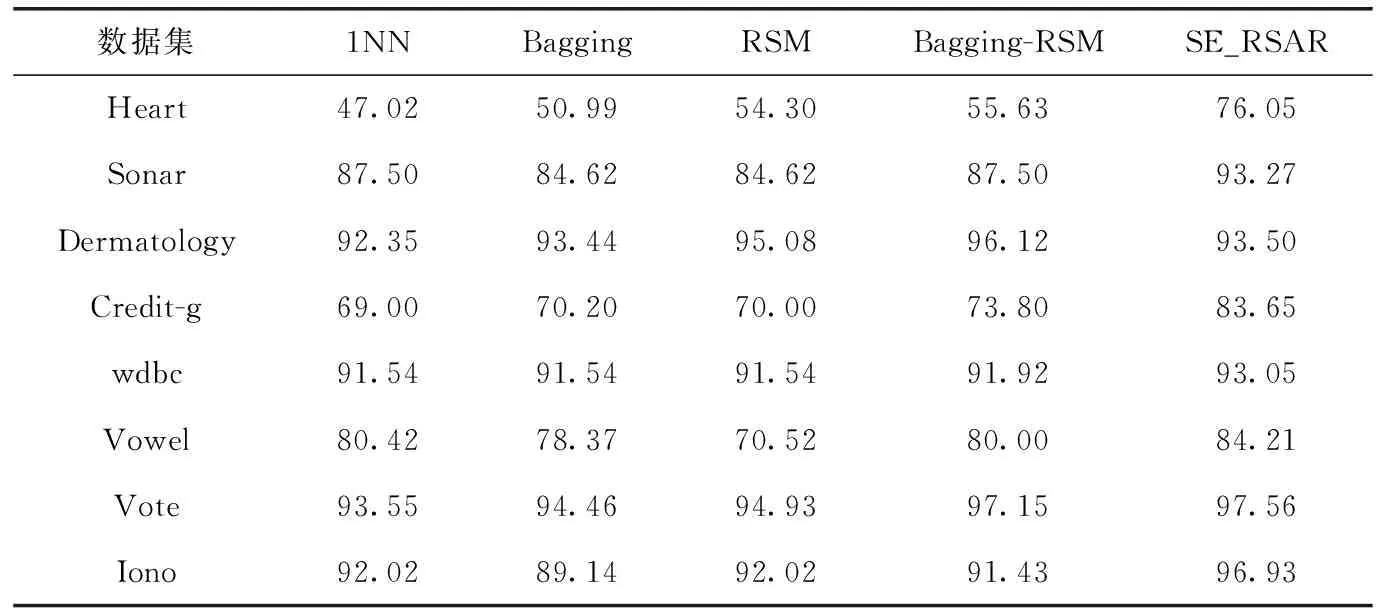
表5 不同算法的分類精度對比/%
在表5中,1NN表示不使用集成方法,而是直接采用單個分類器來進行分類。從表5可以看出,SE_RSAR算法在7個數(shù)據(jù)集上的分類精度都要優(yōu)于其它算法,唯一的例外是數(shù)據(jù)集“Dermatology”,不過,在該數(shù)據(jù)集上,SE_RSAR 算法的性能仍然要比Bagging和1NN方法好。因此,從總體上看,本文提出的SE_RSAR算法其性能要優(yōu)于現(xiàn)有的集成學(xué)習(xí)方法。另外,可以看出,在“Iono”,“Sonar”和“ Vowel”這3個數(shù)據(jù)集上,Bagging的性能比單分類器算法1NN還要差,而在其它數(shù)據(jù)集上,Bagging相對于1NN而言其性能提升得也不明顯。上述結(jié)果表明,單模態(tài)的集成方法很多時候不足以提升集成學(xué)習(xí)的整體性能。
5 結(jié)束語
為了增加個體分類器之間的差異性,本文提出一種基于重采樣[23]和屬性約簡[24]的多模態(tài)選擇性集成學(xué)習(xí)方法。該方法利用重采樣技術(shù)來擾亂樣本空間,并通過基于相對決策熵的屬性約簡方法來擾亂特征空間,通過這種多模態(tài)的擾亂策略可以有效提升個體分類器之間的差異性。另外,我們還提出了一種基于貪婪機制的個體分類器選擇方法,可以進一步提升集成分類器的性能。實驗結(jié)果表明,本文所提出的SE_RSAR算法其性能要優(yōu)于當前的單模態(tài)及多模態(tài)集成算法。
基于相對決策熵的屬性約簡方法是在Pawlak的經(jīng)典粗糙集模型下所提出的。由于經(jīng)典粗糙集模型只能用于處理離散型屬性,因此,SE_RSAR算法需要利用一個離散化過程將所有連續(xù)型屬性轉(zhuǎn)換為離散型屬性。但是,屬性的離散化可能會導(dǎo)致信息丟失。在下一步的工作中,我們將考慮把SE_RSAR算法擴展到鄰域粗糙集模型[25-27]中,該模型可以同時處理連續(xù)型和離散性屬性,從而不需要對連續(xù)型屬性進行離散化處理。
猜你喜歡
西北民族大學(xué)學(xué)報(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
